Reactors: A Case for Predictable, Virtualized Actor Database Systems
The requirements for OLTP database systems are becoming ever more demanding. Domains such as finance and computer games increasingly mandate that developers be able to encode complex application logic and control transaction latencies in in-memory databases. At the same time, infrastructure engineers in these domains need to experiment with and deploy OLTP database architectures that ensure application scalability and maximize resource utilization in modern machines. In this paper, we propose a relational actor programming model for in-memory databases as a novel, holistic approach towards fulfilling these challenging requirements. Conceptually, relational actors, or reactors for short, are application-defined, isolated logical actors that encapsulate relations and process function calls asynchronously. Reactors ease reasoning about correctness by guaranteeing serializability of application-level function calls. In contrast to classic transactional models, however, reactors allow developers to take advantage of intra-transaction parallelism and state encapsulation in their applications to reduce latency and improve locality. Moreover, reactors enable a new degree of flexibility in database deployment. We present ReactDB, a system design exposing reactors that allows for flexible virtualization of database architecture between the extremes of shared-nothing and shared-everything without changes to application code. Our experiments illustrate latency control, low overhead, and asynchronicity trade-offs with ReactDB in OLTP benchmarks.
💡 Research Summary
The paper addresses the growing demands of modern OLTP workloads—such as high‑frequency trading, online gaming, and real‑time analytics—that require both low transaction latency and high scalability on multi‑core, often virtualized, hardware. Traditional database architectures fall into two extremes. Shared‑nothing systems (e.g., H‑Store, HyPer) achieve good data locality but suffer from costly cross‑partition coordination when transactions span multiple partitions. Shared‑everything systems (e.g., Silo, DORA) simplify coordination but encounter contention and poor NUMA locality on many‑core machines. Moreover, developers have little expressive power to reason about intra‑transaction parallelism, while infrastructure engineers must re‑engineer the deployment configuration to tune performance, often requiring code changes.
To bridge this gap, the authors introduce relational actors, called reactors, as a new logical abstraction for in‑memory relational databases. A reactor is an application‑defined logical actor that encapsulates one or more relational tables (its “state”). Within a reactor, developers can issue ordinary declarative SQL queries; across reactors, communication is performed exclusively through asynchronous function calls that return futures/promises. A transaction may involve a sequence of intra‑reactor statements and nested cross‑reactor calls, yet the entire transaction is guaranteed serializability, preserving the ACID guarantees that OLTP users expect. In effect, reactors expose a compute‑oriented view of the data: developers can deliberately place data close to the code that processes it, and they can explicitly express parallelism by launching multiple asynchronous calls that can execute concurrently on different cores.
The paper’s second major contribution is ReactDB, a prototype in‑memory database that materializes reactors and provides a virtualized deployment layer. ReactDB introduces two orthogonal concepts:
- Containers – logical memory regions that host one or more reactors. Containers can be pinned to specific NUMA nodes or cores, allowing fine‑grained control over memory locality.
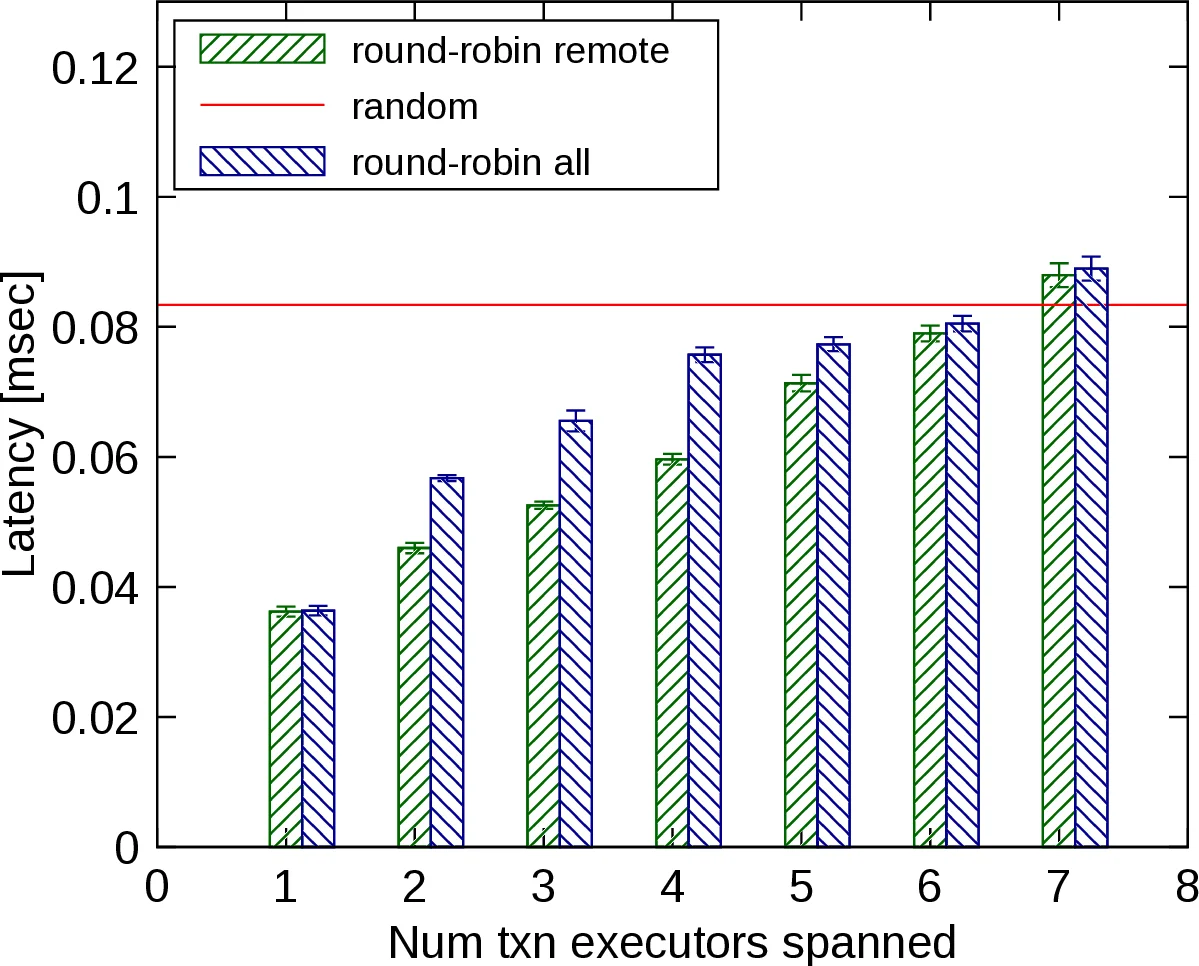
- Transaction Executors – worker threads that run transactions. Executors can be configured to own a container (exclusive access) or share it (multiple executors concurrently accessing the same reactors). By mixing ownership and sharing across containers, the system can emulate anything from a pure shared‑nothing architecture (each container owned by a dedicated executor) to a pure shared‑everything architecture (all containers shared among many executors), simply by editing a configuration file.
This separation of concerns enables infrastructure engineers to experiment with different architectural topologies—e.g., varying the number of containers, the mapping of containers to cores, or the degree of sharing—without touching application code. The authors argue that this flexibility is crucial for workloads whose optimal deployment may shift over time as data size, request patterns, or hardware characteristics evolve.
To illustrate the programming model, the authors present a digital currency exchange use case. The classic approach would encode risk‑checking logic in a monolithic stored procedure that scans a global “providers” table, computes exposure, and decides whether to accept a new order. In the reactor formulation, the system defines an Exchange reactor and a set of Provider reactors. The Exchange reactor asynchronously invokes calc_risk on each Provider reactor, aggregates the results, and conditionally calls add_entry on the appropriate Provider. This makes the parallelism explicit: all risk calculations run concurrently, reducing the critical path latency. Moreover, each Provider’s data resides locally within its own reactor, improving cache locality and eliminating cross‑partition network hops. The transaction still enjoys serializability because the underlying engine coordinates the asynchronous calls and resolves any conflicts before commit.
The experimental evaluation uses standard OLTP benchmarks (TPC‑C, YCSB) under several deployment configurations. Key findings include:
- Latency control – By exploiting asynchronous calls, the system can achieve average transaction latencies in the 30‑40 µs range on a modern multi‑core server, a substantial improvement over synchronous designs.
- Scalability trade‑offs – Shared‑nothing configurations reduce contention and scale well when the workload is partitionable, while shared‑everything configurations benefit from higher cache reuse for workloads with many cross‑reactor accesses.
- Low overhead – The bookkeeping required for reactors (metadata, future objects, container management) adds less than 5 % to the overall transaction cost, confirming that the abstraction does not impose prohibitive runtime penalties.
- Programmability – Different program formulations (synchronous vs. asynchronous, fine‑grained vs. coarse‑grained reactors) allow developers to tune the latency‑throughput trade‑off without rewriting the underlying database engine.
The authors summarize their contributions as: (1) a novel logical abstraction (reactors) that blends relational semantics with an asynchronous actor model while preserving serializability; (2) the design of ReactDB, which decouples logical data placement from physical deployment; (3) empirical evidence that reactors enable microsecond‑level latency control and flexible performance tuning across classic OLTP benchmarks.
The paper also acknowledges limitations. ReactDB is currently an in‑memory prototype; durability, recovery, and integration with persistent storage are not fully addressed. The cost of managing a large number of futures under heavy contention could become significant, suggesting a need for more sophisticated scheduling or batching mechanisms. Future work includes extending the model to durable storage, exploring automated reactor placement algorithms, and investigating hybrid consistency models that relax serializability where appropriate.
In conclusion, the reactor model offers a compelling middle ground between the rigid partitioning of shared‑nothing systems and the contention‑prone sharing of traditional databases. By making intra‑transaction parallelism an explicit first‑class construct and by virtualizing the underlying architecture, ReactDB empowers both developers and operators to achieve predictable, low‑latency OLTP performance on modern hardware without sacrificing the strong correctness guarantees that enterprise applications demand.
Comments & Academic Discussion
Loading comments...
Leave a Comment