Bayesian Methods for Analysis and Adaptive Scheduling of Exoplanet Observations
We describe work in progress by a collaboration of astronomers and statisticians developing a suite of Bayesian data analysis tools for extrasolar planet (exoplanet) detection, planetary orbit estimation, and adaptive scheduling of observations. Our …
Authors: Thomas J. Loredo, James O. Berger, David F. Chernoff
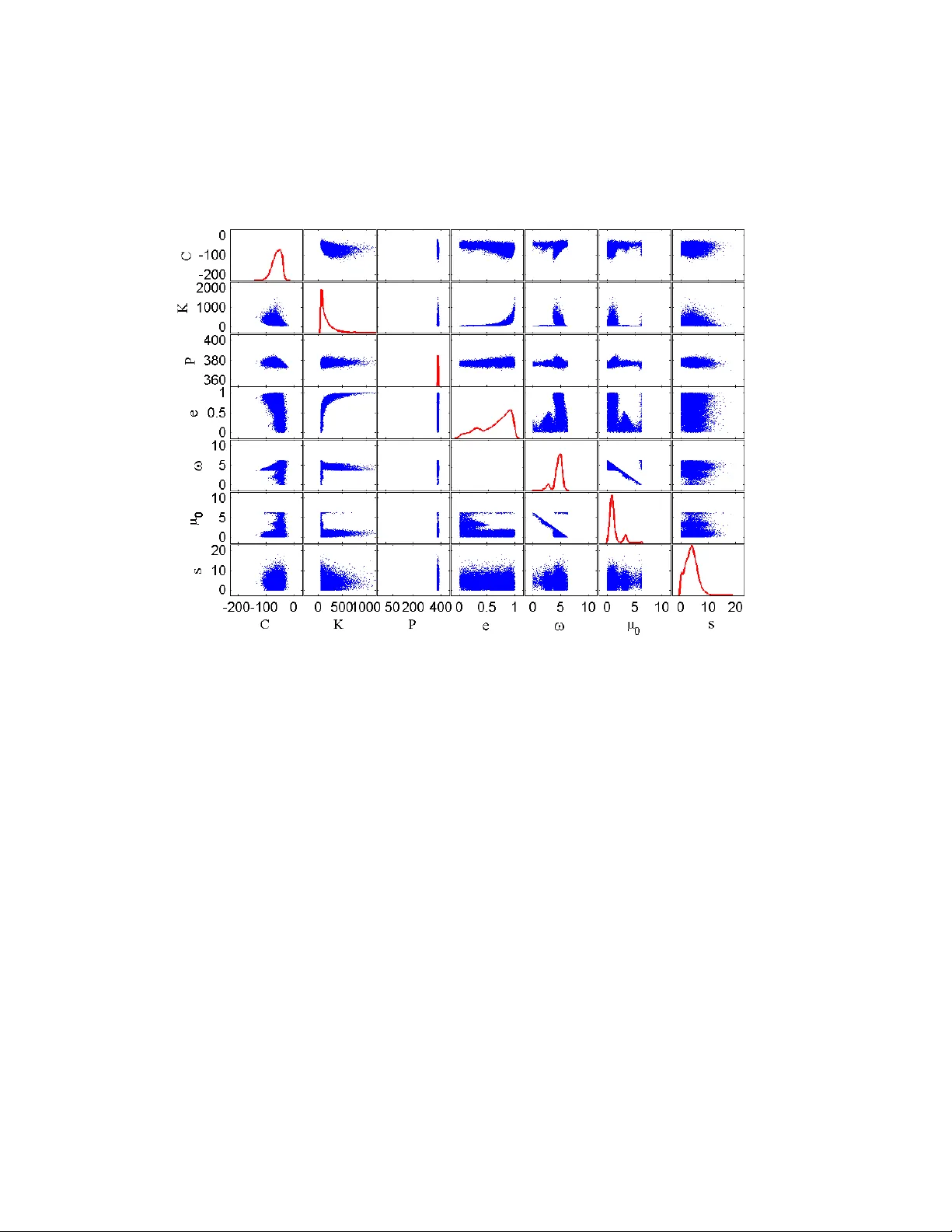
Ba y esian Metho ds for Analysis and Adaptiv e Sc heduling of Exoplanet Observ ations Thomas J. Loredo a , James O. Berger b , Da vid F. Chernoff a , Merlise A. Clyde b , Bin Liu c a Dep artment of Astr onomy, Cornel l University b Dep artment of Statistic al Scienc e, Duke University c Kuang-Chi Institute of A dvanc e d T e chnolo gy Abstract W e describ e work in progress b y a collab oration of astronomers and statisti- cians developing a suite of Ba yesian data analysis tools for extrasolar planet (exoplanet) detection, planetary orbit estimation, and adaptiv e scheduling of observ ations. Our w ork addresses analysis of stellar reflex motion data, where a planet is detected by observing the “w obble” of its host star as it re- sp onds to the gra vitational tug of the orbiting planet. Newtonian mechanics sp ecifies an analytical mo del for the resulting time series, but it is strongly nonlinear, yielding complex, multimodal lik eliho o d functions; it is even more complex when m ultiple planets are present. The parameter spaces range in size from few-dimensional to dozens of dimensions, dep ending on the n um- b er of planets in the system, and the t yp e of motion measured (line-of-sigh t v elo cit y , or p osition on the sky). Since orbits are p erio dic, Bay esian gener- alizations of p erio dogram metho ds facilitate the analysis. This relies on the mo del being linearly separable, enabling partial analytical marginalization, reducing the dimension of the parameter space. Subsequen t analysis uses adaptiv e Marko v chain Mon te Carlo metho ds and adaptive imp ortance sam- pling to p erform the integrals required for both inference (planet detection and orbit measuremen t), and information-maximizing sequential design (for adaptiv e sc heduling of observ ations). W e present an o verview of our current tec hniques and highlight directions b eing explored by ongoing research. Keywor ds: Ba yesian statistics, sequential design, activ e learning, Mon te Carlo metho ds, extrasolar planets Pr eprint submitte d to Elsevier Octob er 29, 2018 1. Introduction In the last fifteen y ears astronomers hav e discov ered ab out 500 planetary systems hosted b y nearby stars; new systems are announced almost weekly and the pace of discov ery is accelerating. The data are no w of sufficient quan tity and qualit y that exoplanet science is shifting from b eing discov ery- orien ted to focusing on detailed astrophysical mo deling and analysis of the gro wing catalog of observ ations. Making the most of the data requires new statistical to ols that can fully and accurately account for diverse sources of uncertain ty in the context of complex models. Planets are small and shine in reflected light, making them m uch dimmer than their host stars. With current technology it is not p ossible to directly image exoplanets against the glare of their hosts except in rare cases of nearb y systems with a large planet far from its host star. The v ast ma jority of exoplanets are instead detected indirectly . The most pro ductiv e technique to date is the r adial velo city (R V) metho d , which uses Doppler shifts of lines in the star’s sp ectrum to measure the line-of-sight velocity comp onen t of the reflex motion of the star in resp onse to the planet’s gravitational pull. Suc h “to-and-fro w obble” can b e measured for planets as small as a few Earth masses, in close orbits around Sun-like stars. Space-based telescopes will so on enable high-pr e cision astr ometry capable of measuring the side- to-side reflex motion (the Hubble Sp ac e T elesc op e Fine Guidance Sensors ha ve already performed suc h measurements for a few exceptional systems). Another indirect technique measures the diminution of light from the star when a planet tr ansits in fron t of the stellar disk. This requires a fortuitous orbital orientation, but large, space-based transit surv eys monitoring man y stars are making the transit metho d increasingly pro ductiv e. 1 Astronomers are using these tec hniques to build up a census of the nearby p opulation of extrasolar planetary systems, b oth to understand the diversit y of suc h systems, and to lo ok for potentially habitable “Earth-lik e” planets. Here w e fo cus on analysis of reflex motion data. Motiv ated b y the needs of astrometric and R V campaigns being planned in 2000, Loredo & Chernoff (2000 (LC00), 2003 (LC03)) describ ed Ba yesian approaches for analyzing 1 During the review of this manuscript, the Kepler mission announced the discov ery of o ver 1000 candidate exoplanet systems, observed to ha ve p eriodic, transit-like even ts; it is exp ected that o v er 90% of these ma y b e confirmed as exoplanets by follow-up R V and other observ ations. 2 observ ations of stellar reflex motion for detection and measurement of exo- planets, and for adaptive scheduling of observ ations (see also Loredo 2004 (L04) for a p edagogical treatmen t of adaptive sc heduling). This work adv o- cated a fully nonlinear Ba yesian analysis based on Keplerian mo dels for the reflex motion (i.e., ob jects in elliptical orbits around a cen ter of mass). LC00 noted that a subset of the orbital parameters app ear linearly and (with ap- propriate priors) could b e marginalized analytically , reducing dimensionality and simplifying subsequent analysis. Building on the w ork of Jaynes and Bretthorst (see Bretthorst 2001 and references therein), they describ ed the close relationship b et w een this approac h and p erio dogram-based metho ds already in use for planet detection, dubbing the Ba y esian counterpart a Ke- pler p erio do gr am (Scargle indep enden tly developed similar ideas at the same time, calling the resulting tool a Kepler o gr am ; see Marcy et al. (2004)). They also describ ed ho w Monte Carlo p osterior sampling algorithms could enable implemen tation of fully nonlinear Ba y esian exp erimen tal design algorithms for adaptiv e sc heduling of exoplanet observ ations. Unfortunately , although n umerous exoplanets w ere disco v ered b y the time of LC00 and LC03, none of the data w ere publicly av ailable, and the virtues of the approac h could not b e demonstrated with real data. By 2004 several observing teams were at last releasing high-quality exo- planet R V data, fueling new in terest in Ba yesian algorithms. Indep enden tly of earlier work, Cumming (2004) explored the connections b et ween conv en- tional p erio dogram metho ds and the Bay esian approach (alb eit hamp ered b y an incorrect marginal likelihoo d calculation); Cumming and Dragomir (2010) later extended this w ork, repro ducing the Kepler p erio dogram of LC00. F ord (2005, 2008) and Gregory (2005) applied classic p osterior sam- pling techniques (Metrop olis random walk (MR W) and parallel temp ering Mark ov c hain Mon te Carlo (MCMC), resp ectiv ely) to orbit mo deling; Gre- gory’s approach uses a control system to tune the prop osal parameters in a pilot run, and he has recen tly augmented his algorithm to include pa- rameter up dates based on genetic algorithms (Gregory 2011). Balan & La- ha v (2008) applied an early , approximate adaptiv e MR W algorithm to the problem. T uomi (2011) used the more rigorous adaptiv e MR W algorithm of Haario et al. (2001) for p osterior sampling; to calculate marginal lik eliho o ds needed for comparing planet and no-planet mo dels, he used the algorithm of Chib and Jeliazko v (2001) that estimates marginal lik eliho o ds from MCMC output. The w ork in progress that w e describe here builds on our o wn previous 3 w ork and these more recent efforts, aiming to dev elop algorithms with sig- nifican tly improv ed computational efficiency and less complexity for users in terms of algorithm tuning. Our motiv ation is t wofold: (1) T o enable more thoroughgoing analysis of all exoplanet data, including thousands of datasets with absen t or ambiguous evidence for planets (whose analysis is imp ortan t for accurate p opulation-lev el inferences); (2) T o enable in tegra- tion of planet detection and orbit estimation results for individual systems in to other statistical tasks, including p opulation-lev el modeling (via hierar- c hical or multi-lev el Ba y esian modeling), and adaptiv e sc heduling of future observ ations. This paper provides an o v erview of our work, aiming to in tro duce statis- tician readers to exoplanet data analysis, and astronomer readers to new algorithms for Bay esian computation. F or simplicity , w e fo cus on analysis of R V data, although we are applying our metho ds to astrometric data as w ell. W e b egin b y describing the lik eliho o d function and priors for Keple- rian reflex motion mo dels; these functions underly all subsequent estimation, detection, prediction, and design calculations. W e then describ e an orbital parameter estimation pipeline, including optimal sc heduling of new observ a- tions to impro ve parameter estimates. Finally , we describ e planet detection calculations, fo cusing on a new adaptiv e imp ortance sampling algorithm we ha ve developed sp ecifically for calculating marginal lik eliho o ds needed for Ba yesian comparison of exoplanet mo dels. 2. Likelihoo d F unctions and Priors for Keplerian Reflex Motion Mo dels T o remo ve the imprin t of Earth’s rotation and revolution from measure- men ts of stellar motions, astronomers refer R V and astrometric measurements to the solar system barycenter, which serv es as the origin of an inertial refer- ence frame (one exp eriencing no accelerations). The motion of an exoplanet system with resp ect to an inertial frame can b e separated into the motion of the system’s center of mass (COM), which mo ves at a constan t v elo cit y , and the relativ e motions of the star and planets with respect to the COM. T o mo del the relativ e motions, we assume that the star and planets ha ve small sizes compared to their separations (allowing us to ignore asphericity and tidal forces), and that non-gra vitational forces are negligible. F or a single-planet system, Newtonian ph ysics predicts that the star and planet eac h mo ve in congruen t, coplanar, p eriodic Keplerian orbits, so-named 4 b ecause the orbits ob ey a v ersion of Kepler’s laws: (1) each orbit is an ellipse with fo cus at the COM; (2) the v ector from the COM to a b o dy sweeps out area at a constant rate; (3) for given masses, orbits of differen t p erio d ha ve the square of the p erio d prop ortional to the cub e of the ellipse’s semima jor axis. F or the v ast ma jority of systems we are only able to observ e the star’s orbit, but the planet’s orbit is a scaled version of the star’s, larger by a fac- tor equal to the star-planet mass ratio. If the star and planet masses are kno wn, three additional parameters suffice to describ e the relative motion in the orbital plane: the semimajor axis , a , and e c c entricity , e , of the ellipse (with the masses, these fix the orbital p eriod), and an angle specifying the star’s p osition along the orbit at some reference time (e.g., the mean anomaly parameter, M 0 , defined below). T o describ e the motion with resp ect to an arbitrary inertial frame, we also need the COM velocity , and three addi- tional geometric parameters to sp ecify the orbit’s orientation in space (e.g., via Euler angles). In practice, the stellar mass may be estimated to a few p ercen t accuracy from sp ectral data, but the planet mass is unknown; in fact, measuring the masses of planets is a prime scientific goal of exoplanet observ ations. The orbital p erio d , τ , is then an additional free parameter. F or a multiple planet system, in general there is no simple description of the motion. But so long as the star is m uch more massive than any of the planets, and if the orbits are not resonan t (e.g., with commensurable p eriods), then the motion of each planet may b e well approximated by a Keplerian orbit ab out the COM of the host star and any closer planets (the resulting hierarch y of COM-referenced co ordinates are called Jacobi co or- dinates). Suc h mo dels for multiple-planet systems are called m ulti-Kepler mo dels. Our w ork considers only Keplerian and m ulti-Kepler models, but as- tronomers can calculate more accurate multiple-planet orbits using N -bo dy algorithms, and suc h to ols are needed for mo deling systems with resonant orbits. Returning to the single-planet case, calculating the (v ector) v elo cit y of the star at a giv en time, t , and pro jecting it along the line of sigh t, pro duces a simple expression for the radial v elo cit y as a function of an angular coordinate called the true anomaly , φ ( t ). The true anomaly sp ecifies the p osition of the star on its elliptical orbit via an angle measured with resp ect to p eriapsis (the p oin t of closest approac h to the COM), with the vertex for the angle b eing the focus of the ellipse (at the COM). Figure 1 sho ws the geometry . 5 The predicted radial v elo cit y at time t is, v ( t ) = K ( e cos ω + cos[ ω + φ ( t )]) + γ , (1) where the first term is the Keplerian contribution, and γ is a systemic veloc- it y parameter that combines the pro jected COM velocity and other constant offsets in the velocity measurement. Here K is the velo city semi-amplitude , and ω is the ar gument of p eriapsis , one of three angular parameters con v en- tionally used to specify the three-dimensional orientation of the orbit with resp ect to the frame of measurement (the other t w o are nonidentifiable with R V data). Equation (1) app ears simple, but significant complication is hidden in φ ( t ): it v aries in time in a complicated manner, and dep ends nonlinearly on three of the orbital parameters. In fact, no simple, direct form ula for φ ( t ) is kno wn; it ma y b e calculated implicitly using tw o other angular coordinates for the orbital p osition. First is the me an anomaly , M , another angle with v ertex at the fo cus, but measuring the planet’s p osition pro jected (orthogonal to the semi-ma jor axis) on a circle circumscribing the orbital ellipse. Fig- ure 1 displa ys this p eculiar construction, whic h makes M ( t ) express Kepler’s second la w by v arying uniformly in time: M ( t ) = 2 π t/τ + M 0 , where M 0 is the me an anomaly at ep o ch t = 0, a free parameter. Second is the e c c entric anomaly , E , an angle defined lik e M , but using the center of the ellipse as the v ertex; it is also sho wn in the figure. The mean and eccen tric anomalies are related via a famous transcenden tal equation, Kepler’s equation: E − e sin E = M . (2) Once E is found from M (at a particular time of in terest), φ is given by tan φ 2 = 1 + e 1 − e 1 / 2 tan E 2 . (3) The time dep endence of the true anomaly th us dep ends on τ , e , and M 0 . T o estimate the radial v elo cit y of a star at a giv en ep o c h, astronomers mak e high-resolution measuremen ts of the star’s sp ectrum, with instrumen- tation that imp oses a n umber of calibration lines on the sp ectrum. Multiple sp ectra, spaced closely in time, ma y b e taken to facilitate a v eraging to reduce uncertain ties. A complicated joint analysis of all lines (stellar and calibra- tion) in all sp ectra yields an estimate of the stellar line Doppler shift, with 6 ae a r E M A C P F L H Figure 1: Geometry of an elliptical orbit (green curve) with eccen tricit y e = 0 . 6 and semima jor axis a , viewed looking down on the orbital plane. F is the fo cus (the center of mass), P is at p eriapsis, and C is at the center of the orbit, and of the circumscribing circle of radius a (dotted blue curv e). L represents the lo cation of the ob ject (planet or star) at a p oin t on its orbit, at a distance r from F . φ is the true anomaly for L , M is the mean anomaly , and E is the eccentric anomaly . uncertain ty summarized by a standard deviation; the uncertain t y typically corresp onds to a line shift of a tin y fraction of the width of a sp ectral pixel, corresp onding to velocities of 1–10 m s − 1 . But there is an additional source of v elo cit y uncertaint y . Stellar surfaces are in constant turbulen t motion at high v elo cities. Stars are not spatially resolved in R V observ ations, so the measured velocity is an a verage ov er the stellar surface (and o ver the short time span of a single ep o c h’s observ ations). Most of the turbulent motion gets av eraged a wa y , but a small, random stel lar jitter comp onen t remains, with a s tandard deviation, s , that v aries from star to star and that is typically a few m s − 1 (see W righ t 2005 for a compilation of jitter measurements for 7 apparen tly planet-free stars). F urther, stars rotate; if starsp ots are presen t, effectiv ely masking part of the stellar surface, a small part of the rotational motion—“starsp ot jitter”—will con tribute to the R V measuremen t (Mak aro v et al. 2009). An R V data set is thus comprised of a set of N velocity estimates and as- so ciated uncertain ties, { v i , σ i } , at times t i (not regularly spaced), where the measuremen ts ma y b e modeled as the sum of the systemic and Keplerian stel- lar v elo cit y , and instrumen tal and jitter noise. W e describ e the uncertain ty in b oth noise con tributions with normal probabilit y distributions. The resulting lik eliho o d function is, L ( O , γ , s ) = " N Y i =1 1 2 π p σ 2 i + s 2 # exp − 1 2 χ 2 ( O , γ , s ) (4) where the quan tity in the exp onent is the familiar go o dness-of-fit statistic, χ 2 ( O , γ , s ) ≡ X i [ d i − v ( t i ; O , γ )] 2 σ 2 i + s 2 . (5) Here O denotes the fiv e orbital parameters ( K , τ , e, ω , M 0 ) that sp ecify the Keplerian contribution to the velocity curv e, v ( t ). When we consider multiple- planet mo dels (in Section 4), a separate set of O parameters appears for each planet, but there is only one γ and one s p er system. Con ven tional analyses of R V data first use a Lomb-Scargle p eriodogram (LSP; Blac k & Scargle 1982) to identify candidate p erio ds, and then use a nonlinear minimizer to find a b est-fit orbit b y minimizing equation (5). Jitter is not handled as a free parameter ( χ 2 minimization cannot b e used to esti- mate such v ariance parameters); instead, the instrumental uncertain ties are scaled to make the minimum χ 2 equal to the num b er of degrees of freedom (i.e., reduced χ 2 of unit y), with the excess v ariance attributed to jitter. Un- certain ties are typically estimated either via the observed Fisher information matrix (whose inv erse is asymptotically a co v ariance matrix estimate under regularit y conditions), or using Wilks’s theorem to select χ 2 con tours (which b ound confidence regions of sp ecified asymptotic co v erage under regularit y conditions). There are sev eral shortcomings of suc h con v entional pro cedures. The lik eliho o d function is alw a ys highly multimodal, and due in part to the rel- ativ e sparsity of R V data sets, there are often multiple viable modes. Also, 8 the b est-fit parameters often lie on or near parameter space b oundaries (es- p ecially for e ). These features violate the regularity conditions for use of the Fisher information or Wilks’s theorem; the resulting confidence regions can hav e grossly incorrect cov erage. Quantities of key astrophysical interest, including the semima jor axis and the planet mass, are nonlinear functions of the parameters in the velocity mo del; propagating the uncertainties into suc h low er-dimensional nonlinear spaces is nontrivial. Uncertaint y propaga- tion into predictions (for future observ ations) and p opulation-lev el analyses is similarly challenging. Also, there is no go o d w ay to incorp orate prior in- formation in to the analysis, in particular, prior information on the scale of jitter. Finally , the LSP is closely related to least-squares fitting of a sin usoid to the data. It is not optimal for iden tifying candidate orbits of non-negligible eccen tricity (in which case the v elo cit y curv e can b e v ery non-sinusoidal). Ba yesian methods can address these shortcomings. Multiplying the like- liho od function by a prior densit y , π ( O , γ , s ), and normalizing, pro duces a p osterior densit y in parameter space, p ( O , γ , s | D ), with D denoting the data. F rom a set of samples of ( O , γ , s ) dra wn randomly from the posterior, one can straigh tforwardly address a wide v ariet y of inference tasks without relying on unjustifiable asymptotic appro ximations. Manipulation of the p osterior can pro duce a p eriodogram-like quan tity that improv es sensitivity to eccen- tric orbit signals ov er the LSP . Some Bay esian inferences may dep end on the c hoice of prior when the data are particularly sparse. But this dep endence is useful: once data sets from many systems are av ailable, p opulation prop- erties can b e learned via the dep endence of system inferences on the prior; this is called hierarc hical or multi-lev el Bay esian mo deling. Th us for ini- tial system-by-system inference, we adopt interim priors , motiv ated in part b y approximate p opulation prop erties, and b y conv enience. Once enough systems ha v e b een discov ered and analyzed, join t analysis of many in terim inferences can b e used to learn the system-lev el prior. During the 2006 Astrostatistics Program hosted by the Statistical and Mathematical Sciences Institute (SAMSI), astronomers w orking on Bay esian metho ds for exoplanet science (including our team) settled on “default” in- terim priors for R V mo del parameters. They are motiv ated b y basic ph ysical constrain ts and approximate p opulation-lev el kno wledge, but attempt to b e otherwise relatively uninformative (e.g., approximately flat or log-flat, but b ounded where necessary to b e prop er). See F ord & Gregory (2007) for de- tails. When it is useful, in our w ork w e sometimes modify default priors, e.g., using a slightly differen t K prior to facilitate analytic dimensional reduction. 9 Our curren t completed calculations use an uninformativ e jitter prior for com- parison with previous w ork, but w e are also p erforming calculations with an informativ e jitter prior (based on the jitter study of W righ t 2005). This can b e imp ortan t for obtaining realistic Ba yes factors comparing mo dels with differen t num b ers of planets (including no planet); without an informative jitter prior, evidence for a planet can b e mask ed when a noninformativ e prior allo ws significant residuals to b e interpreted as jitter. Before dev eloping algorithms to implemen t the required calculations, it is imp ortan t to understand the structure of the likelihoo d function. The first thing to note is that the v elo cit y signal mo del, equation (1), is a linear mo del with resp ect to t w o parameters, K and γ . Com bined with the Gaussian form of the likelihoo d function, this implies that the dependence of the lik eliho od function with resp ect to K and γ is multiv ariate normal, pro vided other parameters are held fixed. If the prior for the linear parameters is approxi- mately flat or normal, any needed in tegrals with resp ect to these parameters ma y b e p erformed analytically (the result can b e cast in terms of well-kno wn w eighted linear least squares solutions). In fact, a simple reparameterization can reduce the nonlinear dimension- alit y further. Let A 0 = γ , A 1 = K cos ω , and A 2 = − K sin ω . Then the v elo cit y equation may b e written as v ( t ) = A 0 + A 1 [ e + cos φ ( t )] + A 2 sin φ ( t ) . (6) A single-planet mo del now has three linear parameters, A ≡ ( A 0 , A 1 , A 2 ), three nonlinear orbital parameters, θ ≡ ( τ , e, M 0 ), and the jitter parameter. If w e adopt a flat or normal in terim prior on A , w e can analytically marginal- ize ov er the amplitudes, effecting a significant dimensional reduction. (A flat amplitude prior corresp onds to a prior that rises linearly with K ; if desired, this can b e adjusted to another prior later in the calculation via imp ortance resampling.) The likelihoo d function has relativ ely simple behavior with resp ect to A . T o gain insigh t into its behavior as a function of the nonlinear parameters, Figure 2 displays slices of the amplitude-marginalized log-likelihoo d func- tion along the τ , e , and M 0 dimensions, based on 24 R V observ ations of the single-planet system HD 222582 obtained o ver a 683 d time span with instrumen tation at the Keck observ atory (V ogt et al. 2000; V00). The likeli- ho od function is highly m ultimo dal with resp ect to τ , relatively smooth with resp ect to e (but for many datasets p eaking on or near a b oundary), and 10 m ultimo dal with resp ect to M 0 . Computational algorithms must be capable of handling these complications. Readers familiar with p erio dogram metho ds for time series analysis will recognize the structure exhibited in the τ slice in Figure 2. In fact, for e = 0 (in which case M 0 is noniden tifiable), the logarithm of the marginal lik eliho o d function for τ is prop ortional to the LSP to a go o d appro ximation (this follo ws from results in Bretthorst 2001). Accordingly , we interpret the log marginal likelihoo d function for nonlinear parameters, L m ( τ , e, M 0 ) (p ossibly including jitter when important), as a generalization of the LSP; w e dub it a Kepler o gr am or K-gram. If w e n umerically in tegrate the marginal lik eliho o d o ver e and M 0 (w eighted b y a flat prior), its logarithm offers a 1-D summary of the evidence for a planet as a function of candidate p eriod. W e dub this a Kepler p erio do gr am . 3. Orbital P arameter Estimation and Adaptiv e Sc heduling The pip eline w e currently use for orbital parameter estimation takes ad- v an tage of dimensional reduction to facilitate adaptive p osterior sampling for exploring exoplanet models. W e calculate the marginal lik eliho o d func- tion for the nonlinear parameters, i.e., the exp onen tial of the Keplerogram, and p osterior sampling is done in the reduced-dimension nonlinear param- eter space. Once samples are av ailable, they can b e readily augmen ted to the full dimensional space (i.e., with amplitude parameter samples added) b y dra wing samples from the conditional multiv ariate normal distribution for A giv en the nonlinear parameters. If w e wish to adjust the in terim prior, im- p ortance w eights ma y b e assigned to the samples at this step. The samples are then used for subsequen t inferences. T o initialize a p osterior sampler, w e fix the jitter to a trial v alue, and explore the ( τ , e, M 0 ) dep endence of the marginal p osterior via an adaptive grid in τ (refining the grid in regions of high p osterior densit y), supplemen ted b y a crude grid or quadrature in ( e, M 0 ) in promising τ regions. W e use this exploration to build a simple, approximate ( τ , e, M 0 ) sampler, used for dra wing initial v alues for rigorous p osterior sampling. F or t w o-planet mo dels, w e follow this pro cedure for the first planet, and then for each mem b er of a small set of approximate samples for the first planet’s parameters, rep eat the pro cedure for a single-planet mo del for the residuals from the candidate mo del for the first planet. This lets us build candidate multi-Kepler mo dels via a tractable sequence of single-planet fits. The kno wn multiple-planet 11 Figure 2: “Slices” of the marginal lik eliho o d function, L m ( τ , e, M 0 ), for orbital parameters of a single-planet mo del for 24 R V observ ations of HD 222582. 12 systems w ere first detected using such a “hieararchical” approach, in the con text of the p erio dogram/ χ 2 minimization approac h. W e are exploring a few different metho ds for p osterior sampling of the marginal p osterior for the nonlinear parameters. A particularly promising and simple method we are using is ter Braak’s differ ential evolution Markov chain (DEMC) metho d (ter Braak 2006). This is a p opulation-based adaptive MCMC algorithm that w eds ideas from ev olutionary computing and MCMC. It ev olves several chains of samples in the nonlinear parameter space, all of them targeting the marginal p osterior density (in contrast to the b etter- kno wn parallel temp ering algorithm, where all c hains but one explore an- nealed v ersions of the p osterior, pro ducing samples that are not useful in final inferences). The c hains in teract at ev ery step in a wa y that preserves fair and asymptotically indep enden t sampling in eac h c hain; but the in ter- action effectiv ely tunes the size and shap e of the prop osal distribution to matc h features of the target. Figures 3 depicts one DEMC up date step. The algorithm enables exploration of multiple mo des by differen t c hains (partly via hopping betw een modes for eac h c hain) pro vided the initial p opulation includes samples from the imp ortan t mo des. W e attempt to ensure this b y building the initial p opulation using the K-gram. The aim of the algorithm is to use a small-sized p opulation to define adaptiv e Metrop olis-Hastings pro- p osals for updating each c hain, with the final output b eing the samples in all c hains. Figures 4 and 5 show selected results from this approach, for a single- planet mo del for the 24 Keck R V observ ations from HD 222582. Figure 4 (top panel) shows the data as (red) diamonds, at times earlier than ∼ 1400 d (the ≈ 3 m s − 1 error bars are smaller than the symbols). The dashed black curv e sho ws the b est-fit orbit rep orted b y V00, with a p erio d of 579.5 d and a high eccen tricit y , e = 0 . 71. W e used our pipeline to initialize and evolv e a p opulation of 10 chains for 20,000 steps; con vergence and mixing w ere assessed via the Gelman-Rubin R statistic (readily calculated from DEMC parallel c hains) and b y insp ection of trace plots and auto correlation func- tions. The thin blue curv es show the v elo cit y curv es for 20 mo dels c hosen at random from the p osterior samples (after thinning by a factor of ten). A wide v ariet y of orbits are consistent with the data; no single orbit fairly represen ts the p ossibilities (in fact, the b est-fit orbit seems not v ery represen- tativ e). Figure 5 shows pairwise scatterplots and marginal histograms (along the diagonal) of the p osterior samples for the nonlinear orbital parameters, summarizing the parameter uncertain ties. Sample p oin ts are transparently 13 Proposal Candidate for update Proposed displacement Figure 3: Illustration of the differen tial ev olution MCMC algorithm. Filled circles sho w 15 p oin ts comprising an evolving p opulation in a tw o-dimensional parameter space. Blue circle indicates a p oin t c hosen at random from the 15 for p ossible up dating. Green circles indicate pair of p oin ts chosen at random from the 14 remaining p oin ts; these determine a prop osal displacement, defined as a fraction of the displacemen t b et w een them. Red diamond indicates the proposed up date to the blue point, found using the scaled displacemen t. It will b e accepted or rejected via the Metropolis-Hastings rule. colored, indicating time in the Marko v chain; blue p oin ts are early in the c hain, green and y ellow p oin ts at in termediate times, and orange and red p oin ts at late times. F or this analysis the initial p opulation was dra wn from the marginal distribution with e = 0; its logarithm is essen tially the LSP . The separation of the blue “co ol” p oints from later p oin ts shows that the p eriod for the p eak of the LSP was in the general vicinit y of the global mo de but did not accurately lo cate it; all c hains soon lea v e the vicinit y of the initial p opulation (this burn-in phase of the chain would normally b e discarded for final inferences; we hav e k ept it in this figure for illustration, but discarded burn-in samples in later figures). The DEMC algorithm is able to adapt to the p osterior and find and explore the local mode in a few thousand iterations (the burn-in time shortens to a few h undred steps with a more sophisticated initialization using the full K-gram). P osterior samples enable straightforw ard propagation of uncertain ties into non trivial inferences. F or example, w e can easily create samples from the (marginal) p osterior distribution for the physically imp ortan t derived pa- rameters a and m p sin i (where i is the inclination of the orbital plane to the 14 600 800 1000 1200 1400 1600 1800 2000 2200 2400 JD - 2450000 − 500 0 500 1000 1500 V elo cit y (m/s) 0 1 2 3 4 5 6 Expected Info Gain (bits) 1500 1600 1700 1800 1900 2000 2100 2200 JD - 2450000 − 500 0 500 1000 1500 V elo city (m/s) 0 1 2 3 4 5 6 Expected Info Gain (bits) Figure 4: Results from single-planet mo deling of 24 R V observ ations of HD 222582 rep orted in V00 (as revised in B06). Sho wn are observ ations (red diamonds, several o verlapping), b est-fit velocity mo del (thick dashed black curv e), 20 representativ e mo dels from p osterior (thin blue curves), 300 samples from predictive distribution for v elo cit y at six ep ochs (magen ta p oin ts), and relativ e exp ected information gain vs. future observing time (green curve, right axis). Time is barycentric Julian day relativ e to 2,450,000. Bottom panel expands the later half of the plot. 15 Figure 5: Parameter estimation results from single-planet mo deling of 24 R V ob- serv ations of HD 222582 rep orted in V00. Shown are pairwise scatter plots and marginal histograms (along the diagonal) for τ , e , M 0 ; color indicates time in Mark ov c hain (early to late in sp ectral sequence from blue to red). 16 plane of the sky; m p and i are not separately identifiable in mo dels for R V data) by ev aluating them for eac h p osterior sample. They also enable us to tac kle problems requiring prediction under uncertaint y , including adaptiv e sc heduling of future observ ations (LC00, LC04, L04). F rom a v ailable data, D , w e can calculate a p osterior predictiv e distribution for the v alue of a future datum at time t , d t ; p ( d t | D ) = Z p ( P | D ) p ( d t |P ) d P , (7) where P denotes all of the parameters in the currently considered mo del. The first factor in the integrand is the p osterior distribution for P . The second factor is the probability for a future measured v alue, giv en v alues for the parameters; this is just a normal distribution centered at the predicted v elo cit y . The predictive distribution can b e easily ev aluated or sampled from using p osterior samples. T o optimally sc hedule a new observ ation, w e must sp ecify some mea- sure of the v alue a new observ ation would hav e for our observ ational goals; this is the utility function in the decision-theoretical form ulation of adaptive sc heduling, describ ed in LC03. F or a general-purp ose measure of the v alue of new data for a v ariet y of goals, w e app eal to information theory: we seek new data that will make the updated posterior most informativ e ab out the parameters, i.e., leading to the largest exp ected decrease in the uncertaint y , quan tified b y Shannon entrop y (or, equiv alen tly here, by Kullbac k-Leibler div ergence). A straightforw ard calculation shows that the posterior uncer- tain ty is exp ected to decrease the most if w e observe at the time for whic h the pr e dictive uncertain t y—the entrop y of p ( d t | D )—is greatest: w e learn the most by sampling where we kno w the least. This is called maximum entr opy sampling (Sebastiani & Wynn 2000). W e use posterior samples to calculate a straightfor ward Mon te Carlo esti- mate of the en tropy in the predictiv e distribution as a function of time, S ( t ). The green curve in Figure 4 (expanded in the b ottom panel) shows S ( t ) for times spanning ab out one orbit following the observ ations rep orted in V00, in units of bits of information gain, relativ e to the information that would b e gained b y rep eating the last observ ation (one bit of information roughly cor- resp onds to reducing the volume of a join t credible region by one half, a very significan t information gain). S ( t ) essentially measures the vertical spread of the predicted velocity curves at time t . T o reveal more detail in the pre- dictiv e distribution as a function of time, w e sho w (magenta) p oin t clouds of 17 Figure 6: Relativ e exp ected information gain for a single future observ ation of HD 222582, for times ≈ 14 orbits after original observ ations (green curv e, righ t axis), with 15 represen tative v elo cit y mo dels (thin blue curves). samples of d t from p ( d t | D ) at six different times (the times are dithered o v er an in terv al of ± 5 d to spread the p oin ts). The points reveal the predictiv e distribution to b e complicated, esp ecially in regions of high uncertaint y . It can b e highly skew and ev en multimodal; clearly the predictiv e uncertainties w ould not b e w ell-describ ed b y normal distributions (whic h underlie classical exp erimen tal design theory). The entrop y curve shows that observ ations at the optimal time ( t ≈ 1870 d) are m uch more informative than observ ations ev en a small fraction of a p erio d earlier or later. Figure 6 is a similar plot, but extending the S ( t ) curv e further in to the future, ov er ab out 14 orbits. It sho ws that the most information will b e gained b y following up the initial observ ations within the time of the subse- quen t orbit or t w o. There are definitely preferred times in later orbits, but the maximum exp ected information gain is decreasing, and the maximum and minim um of the exp ected information gain are conv erging. These fea- tures are in accord with intuition: the significan t uncertainties in the orbital p eriod and shape imply that our abilit y to predict decreases with time, un til after man y orbits we cannot ev en confidently predict the n um b er of orbits that ha ve passed. A t late times, our predictions b ecome so p o or that no candidate observing time is clearly preferable to another. 18 W e would lik e to see ho w adaptive sc heduling can improv e results com- pared to non-optimal scheduling. LC03 and L04 rep orted results of a few sim ulations demonstrating the sup eriority of adaptiv e scheduling to informal or random sampling. F ord (2008) p erformed a more extensive simulation study , fo cusing on the significan tly simpler case of circular orbits, even more con vincingly demonstrating the b enefits of the approach, though still with sim ulated data. A more con vincing demonstration would use real data, for example, com- paring results from subsequent observing of HD 222582 with an optimized sc hedule to results from a non-optimized schedule. Butler et al. (2006; B06) rep orted 13 subsequent observ ations, at times not c hosen to optimize infor- mation gain. Figure 7 is similar to Figure 4, but extending the S ( t ) curv e farther in the future, o ver about 4 orbits, cov ering the span of the new obser- v ations of B06. While a few observ ations were not far from a lo cal optim um, man y observ ations were at times offering muc h less exp ected information gain than optimal times. T o see what might ha v e b een gained with optimal observing, we sim ulate a new observ ation at the first (global) optimal time, up date in terim inferences, calculate a new en tropy curv e, and rep eat for a few cycles. W e do not kno w the true orbit of HD 222582 to use for the sim u- lations; as a reasonable surrogate, we use the b est-fit orbit rep orted by B06 using all 37 observ ations. Figures 8 and 9 show p osterior samples summarizing inferences with new data. Figure 8 shows results from using the 24 V00 observ ations and adding just three new, optimal observ ations (for 27 total observ ations). Figure 9 sho ws results adding all 13 non-optimal observ ations from B06 instead of the three optimal observ ations (for 37 total observ ations). The p osterior distri- bution based on three new optimal observ ations is dramatically more precise than the initial in terim posterior (displa yed in Figure 5), and is also m uch more precise than the p osterior based on 13 non-optimal observ ations (and it is con v erging on the surrogate “true” parameter v alues). This clearly demon- strates the p oten tial of adaptive observing for improving orbital parameter estimates. W e are p erforming similar calculations for other hea vily-observed systems to more fully assess the b enefits of the approac h. 4. Planet Detection Via Mo del Comparison T o detect a planet, w e must compare h ypotheses with no planet (i.e, with just γ and s parameters), to h yp otheses sp ecifying a single planet. The com- 19 1500 2000 2500 3000 3500 4000 JD - 2450000 − 500 0 500 1000 1500 V elocity (m/s) 0 1 2 3 4 5 6 Expected Info Gain (bits) Figure 7: Relativ e exp ected information gain for a single future observ ation of HD 222582 for times ≈ 4 orbits after after the observ ations of V00 (thic k green curv e, right axis), with 20 represen tative velocity models (thin blue curv es, left axis). Red diamonds indicated the the subsequen t 13 observ ations of B06, at times indicated b y vertical dashed red lines. parison must accoun t for the fact that b oth the no-planet and single-planet mo dels are c omp osite ; w e do not know the b est (or true) parameter v alues a priori, and they remain uncertain (alb eit less so) even after fitting the best data sets. T o detect additional planets, w e must similarly compare m ulti- Kepler mo dels to the single-planet mo del. T o optimally sc hedule observ a- tions for planet detection (as opp osed to orbit estimation, treated ab o ve), w e m ust incorp orate mo del uncertaint y into prediction and exp erimen tal design calculations. In Ba y esian parameter estimation, the data influence inferences via the lik eliho o d function, the probability for the data considered as a function of the parameters sp ecifying a simple (p oin t) h yp othesis for the data. F or com- paring riv al parametric models, Bay es’s theorem similarly indicates that the data influence mo del choice through a lik eliho o d—i.e., a probability for the data giv en a hypothesis—but no w the lik eliho o d is for a h yp othesis specifying a model as a whole, i.e., a comp osite h ypothesis. This quan tit y ma y fairly b e called simply the likelihoo d for a mo del (as a whole); more con ven tionally it is called the mar ginal likeliho o d , referring to how it is calculated from the 20 Figure 8: Orbital parameter p osterior samples for HD 222582 based on 24 early observ ations and three simulated new observ ations at optimal times. 21 Figure 9: Orbital parameter p osterior samples for HD 222582 based on 24 early and 13 new, non-optimal actual observ ations (bottom). 22 lik eliho o d function for the mo del’s parameters (and helping to distinguish it linguistically from the likelihoo d function). The marginal likelihoo d is the in tegral of the pro duct of a mo del’s prior and lik eliho o d, o v er the en tire pa- rameter space. Suc h in tegrals are often challenging if the dimension of the parameter space is greater than a few. F or R V data, the no-planet mo del is only tw o-dimensional, and the mar- ginal lik eliho o d in tegral o v er ( γ , s ) is easy to calculate. Already for the single- planet mo del, the parameter space is seven-dimensional and the lik eliho o d is highly structured; direct n umerical cubature ov er all seven dimensions is c hallenging. If w e are willing to adopt in terim priors allowing analytical amplitude marginalization, n umerical cubature is needed only o ver the three- dimensional nonlinear parameter space (with a fourth dimension added when jitter uncertaint y is imp ortan t). This is tractable via cubature. But adding a second or third planet mak es marginal likelihoo d calculation via cubature in tractable. The marginal likelihoo d needed for mo del comparison is just the normal- ization constan t for the p osterior distribution used for parameter estimation. W e can sample the p osterior distributions for multi-planet mo dels with the approac h of Section 3. But the normalization constant do es not app ear (and is not needed) in MCMC algorithms, so this ability do es not directly help us (although there are indirect wa ys to use MCMC output to estimate marginal lik eliho o ds; see Clyde et al. 2007). W e hav e dev elop ed a new metho d for estimating marginal likelihoo ds, based on marrying ideas from adaptiv e imp ortance sampling, mixture mo d- els, and sequential Mon te Carlo (SMC) metho ds. At present w e ha ve imple- men ted it as a general-purp ose ab-initio algorithm, without taking adv antage of any analytical marginalization or results from MCMC-based p osterior ex- ploration. Denote the full parameter space as P , and let q ( P ) = π ( P ) L ( P ); the marginal lik eliho od is Z = R q ( P ) d P . Supp ose w e could construct an im- p ortance sampling density , Q ( P ), that resembles the target, q ( P ), but that w e could cheaply sample from and ev aluate. Then we could easily get accu- rate Z estimates via the usual imp ortance sampling algorithm. The problem is that it is difficult to construct suc h imp ortance samplers (see, e.g., Oh & Berger 1993, W est 1993). Instead of attempting to build an efficient importance densit y Q ( P ) ab initio, w e build a se quenc e of samplers, Q n ( P ), approximating anne ale d ver- sions of the target, starting with a nearly flattened target, and ending with the actual target. Eac h sampler is built using a mixture of multiv ariate 23 Studen t- t distributions with M comp onen ts (setting the degrees of freedom to a small v alue such as 5). The num b er M , the comp onen t w eights, and the lo cations and scale matrices for each component are calculated using sam- ples from the previous step’s sampler. In outline, we start with a disp ersed imp ortance density , Q 0 ( P ), and we set the initial annealed target density , q 0 ( P ), equal to Q 0 . The algorithm then cycles through the following steps (starting with n = 1) un til an acceptably small importance sampling v ariance is ac hieved: 1. Anneal the target from q n − 1 to q n = Q 1 − β n 0 q β n , where β n is a sequence of “in verse temp eratures” increasing from 0 to 1 according to an annealing sc hedule (we use b oth standard rules of thum b for the sc hedule and adaptiv e schedules; in our examples they work ed equally w ell). 2. Sample parameter v alues {P i } from Q n − 1 ; assign them w eights w i = q n ( P i ) /Q n − 1 ( P i ). 3. Refine Q n − 1 to Q n , in tended to approximate q n : (a) Revise the Studen t- t comp onen t parameters and mixture weigh ts using the Exp ectation-Maximization (EM) algorithm to minimize the Kullback-Leibler divergence b et ween Q n and q n , estimated using the samples and sample w eights. (b) Delete mixture comp onen ts with small mixture w eights. (c) Merge comp onen ts that ha ve large mutual information. (d) Split components with large w eigh ts by duplicating them, revising their parameters via the EM algorithm, and keeping the split if the m utual information b et ween the revised comp onents is low. The final sampler can b e used to estimate Z , and the imp ortance-w eighted samples can b e used for parameter estimation; the algorithm th us ma y b e able to replace our K-gram/DEMC parameter estimation pip eline in cer- tain settings. W e call the algorithm anne aling adaptive imp ortanc e sampling (AAIS). Liu et al. (2011; L11) provides a detailed description; here w e high- ligh t some illustrative results. Figure 10 shows AAIS in operation on a highly multimodal t w o-dimensional target with kno wn marginal lik eliho od. The target consists of a mixture of 10 biv ariate normals, all well-separated and with v ery differen t cov ariance matrices. The initial importance sampler, Q 0 ( P ), is a set of 10 biv ariate t distributions spread randomly across the space; it is illustrated by the con- tours and crosses in the left panel. The annealing sc hedule has β n v arying from 0.01 to 1 for n = 1 to 8. W e draw samples (red dots) from Q 0 , in tended 24 Figure 10: Three stages of the AAIS algorithm in op eration on a mixture of 10 w ell-separated biv ariate normals with differing scales and correlations. F rom left to righ t, the annealed target has a temp er of β n = 0 . 01, 0.11, and 1, corresp onding to steps n = 1, 3, and 8. to appro ximate q 0 ; anneal the target to q 1 ; use q 1 to w eight the samples; and then use the w eighted samples to adjust Q 0 to a new sampler, Q 1 , intended to approximate q 1 , as outlined ab ov e. The middle panel shows the third step ( β 3 = 0 . 11), revealing that Q 2 is capturing the features of the annealing target. The righ t panel shows that in eight steps all mo des are lo cated and w ell-mo deled. The final imp ortance sampler, Q 8 , has an efficiency of 94%, and estimates Z to 0.25% accuracy with 2000 samples (the accuracy estimate is from the usual imp ortance sampling v ariance). Figure 11 sho ws AAIS results from a t wo-planet fit to 30 R V observ ations of HD 73526, a system kno wn to contain tw o planets with orbital perio ds of 188 d and 377 d (Tinney et al. 2006). The panel sho ws parameter estimates for the orbit of the second (longer-p erio d) planet; the sampling efficiency of the final sampler is ≈ 65%; similar or higher efficiencies were obtained for single-planet and no-planet mo dels. The Ba yes factor (ratio of marginal lik eliho o ds) for the single-planet mo del vs. the no-planet mo del is 6 . 5 × 10 6 ( ± 3%); for t wo-planet vs. one-planet it is 8 . 2 × 10 4 ( ± 4%); this indicates v ery strong evidence for tw o planets around HD 73526. T o pro vide confidence in the estimates and uncertain ties, we hav e v alidated AAIS b y applying it to a v ariety of m ultiv ariate test integrands more complicated than the illustra- tiv e tw o-dimensional case ab o v e, including integrands designed to mimic key features of R V lik eliho o d functions; L11 describes some of these cases. W e are con tin uing to refine our K-gram/DEMC pipeline and the AAIS algorithm. W e are exploring how the algorithms compare for parameter esti- mation, and ho w the K-gram may b e used to accelerate the AAIS algorithm 25 Figure 11: AAIS parameter estimates from an analysis of data from HD 73526; sho wn are pairwise scatterplots and marginal histograms (curves, along the diago- nal) for the orbital parameters of the longer-p erio d planet in a tw o-planet mo del. Renamed parameters (follo wing L11) are: P = τ , C = γ , µ 0 = M 0 . (via dimensional reduction and a “smart start”). Our main longer-term goal is to generalize the adaptive scheduling approach describ ed in Section 3 for orbit estimation, instead optimizing the timing of future observ ations for b oth planet detection and orbit estimation sim ultaneously . This requires in- corp orating AAIS in the calculation (to handle planet n umber uncertain ty), and considering non-greedy , m ultiple-step sc heduling designs. A cknow le dgments : W e are grateful to t w o referees whose commen ts helped impro ve the man uscript, and to the editors for relaxing page constraints to allo w us to address the referees’ questions. W ork reported here w as funded in part by NSF gran ts DMS-042240, AST-0507481, and AST-0507589, and b y the NASA Sp ac e Interfer ometry Mission via JPL sub con tracts and the 26 SIM Science Studies program. References [1] S.T. Balan, O. Lahav, EXOFIT: Orbital parameters of extrasolar plan- ets from radial v elo cities, Mon. Not. R oy. Astr on. So c. 394 (2009) 1936– 1944. [2] D.C. Blac k, J.D. Scargle, On the detection of other planetary systems b y astrometric techniques, Astr ophys. J. 263 (1982) 854–869. [3] G.L. Bretthorst, Generalizing the Lom b-Scargle p erio dogram, in: A. Mohammad-Djafari (Ed.), Ba y esian Inference and Maximum En tropy Metho ds in Science and Engineering, volume 568 of Americ an Institute of Physics Confer enc e Series , 2001, pp. 241–245. [4] R.P . Butler, J.T. W right, G.W. Marcy, D.A. Fisc her, S.S. V ogt, C.G. Tinney, H.R.A. Jones, B.D. Carter, J.A. Johnson, C. McCarthy, A.J. P enny, Catalog of nearby exoplanets, Astr ophys. J. 646 (2006) 505–522. [5] S. Chib, I. Jeliazko v, Marginal likelihoo d from the Metrop olis-Hastings output, J. Amer. Statist. Asso c. 96 (2001) 270–281. [6] M.A. Clyde, J.O. Berger, F. Bullard, E.B. F ord, W.H. Jefferys, R. Luo, R. P aulo, T. Loredo, Curren t c hallenges in Ba yesian mo del c hoice, in: G. J. Babu & E. D. F eigelson (Ed.), Statistical Challenges in Modern Astronom y IV, volume 371 of Astr onomic al So ciety of the Pacific Con- fer enc e Series , 2007, p. 224. [7] A. Cumming, Detectabilit y of extrasolar planets in radial velocity sur- v eys, Mon. Not. R oy. Astr on. So c. 354 (2004) 1165–1176. [8] A. Cumming, D. Dragomir, An integrated analysis of radial v elo cities in planet searc hes, Mon. Not. R oy. Astr on. So c. 401 (2010) 1029–1042. [9] E.B. F ord, Quantifying the uncertaint y in the orbits of extrasolar plan- ets, Astr onom. J. 129 (2005) 1706–1717. [10] E.B. F ord, Adaptive sc heduling algorithms for planet searches, As- tr onom. J. 135 (2008) 1008–1020. 27 [11] E.B. F ord, P .C. Gregory, Ba yesian model selection and extrasolar planet detection, in: G. J. Babu & E. D. F eigelson (Ed.), Statistical Challenges in Mo dern Astronomy IV, volume 371 of Astr onomic al So ciety of the Pacific Confer enc e Series , 2007, pp. 189–206. [12] P .C. Gregory , A Ba yesian analysis of extrasolar planet data for HD 73526, Astr ophys. J. 631 (2005) 1198–1214. [13] P .C. Gregory, Ba y esian exoplanet tests of a new metho d for MCMC sampling in highly correlated mo del parameter spaces, Mon. Not. R oy. Astr on. So c. 410 (2011) 94–110. [14] H. Haario, E. Saksman, J. T amminen, An adaptiv e Metrop olis algo- rithm, Bernoulli 7 (2001) 223–242. [15] B. Liu, J. Berger, M.A. Clyde, J.I. Cro oks, T.J. Loredo, D.F. Cher- noff, Adaptive annealed importance sampling for m ulti-mo dal p osterior exploration and mo del selection with application to extrasolar planet detection (2010) (in preparation). [16] T.J. Loredo, Ba yesian adaptive exploration, in: G. J. Eric kson & Y. Zhai (Ed.), Ba yesian Inference and Maxim um Entrop y Metho ds in Science and Engineering, v olume 707 of A meric an Institute of Physics Confer- enc e Series , 2004, pp. 330–346. [17] T.J. Loredo, D.F. Chernoff, Bay esian metho dology for the Space Inter- ferometry Mission, in: Bulletin of the American Astronomical So ciet y , v olume 32 of Bul letin of the A meric an Astr onomic al So ciety , 2000, p. 767. [18] T.J. Loredo, D.F. Chernoff, Ba y esian adaptive exploration, in: F eigel- son, E. D. & Babu, G. J. (Ed.), Statistical Challenges in Astronomy , Springer, 2003, pp. 57–70. [19] V.V. Mak arov, C.A. Beic hman, J.H. Catanzarite, D.A. Fisc her, J. Le- breton, F. Malb et, M. Shao, Starsp ot jitter in photometry , astrometry , and radial v elo cit y measurements, Astr ophys. J. L ett. 707 (2009) L73– L76. [20] G.W. Marcy, P .R. Butler, S. F rink, D. Fischer, B. Opp enheimer, D.G. Monet, A. Quirrenbac h, J.D. Scargle, Discov ery of planetary systems 28 With SIM, in: S. Un win & S. T uryshev (Ed.), Science with the Space In terferometry Mission, 2004, pp. 3–6 (collection of SIM Science T eam pro ject summaries; full prop osal for this pro ject at http://sim.jpl. nasa.gov/scienceMotivations/exoplanets/ ). [21] M.S. Oh, J.O. Berger, In tegration of multimodal functions by Monte Carlo imp ortance sampling, J. Amer. Statist. Asso c. 88 (1993) 450–456. [22] P . Sebastiani, H.P . Wynn, Maxim um entrop y sampling and optimal Ba yesian exp erimen tal design, Journal of the Roy al Statistical So ciety , Series B: Statistical Metho dology 62 (2000) 145–157. [23] C. ter Braak, A Mark o v Chain Mon te Carlo version of the genetic algo- rithm Differential Evolution: easy Bay esian computing for real parame- ter spaces, Statistics and Computing 16 (2006) 239–249. [24] C.G. Tinney, R.P . Butler, G.W. Marcy, H.R.A. Jones, G. Laughlin, B.D. Carter, J.A. Bailey, S. O’T o ole, The 2:1 resonant exoplanetary system orbiting HD 73526, Astr ophys. J. 647 (2006) 594–599. [25] M. T uomi, Ba yesian re-analysis of the radial velocities of Gliese 581. Evi- dence in fa vour of only four planetary companions, Astr on. & Astr ophys. 528 (2011) L5+. [26] S.S. V ogt, G.W. Marcy, R.P . Butler, K. Apps, Six new planets from the Kec k Precision V elo cit y Surv ey, Astr ophys. J. 536 (2000) 902–914. [27] M. W est, Approximating p osterior distributions by mixtures, J. Roy . Statist. So c. Ser. B 55 (1993) 409–422. [28] J.T. W righ t, Radial velocity jitter in stars from the California and Carnegie Planet Search at Keck Observ atory , Pub. Astr on. So c. Pac. 117 (2005) 657–664. 29
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment