An Implementation of List Successive Cancellation Decoder with Large List Size for Polar Codes
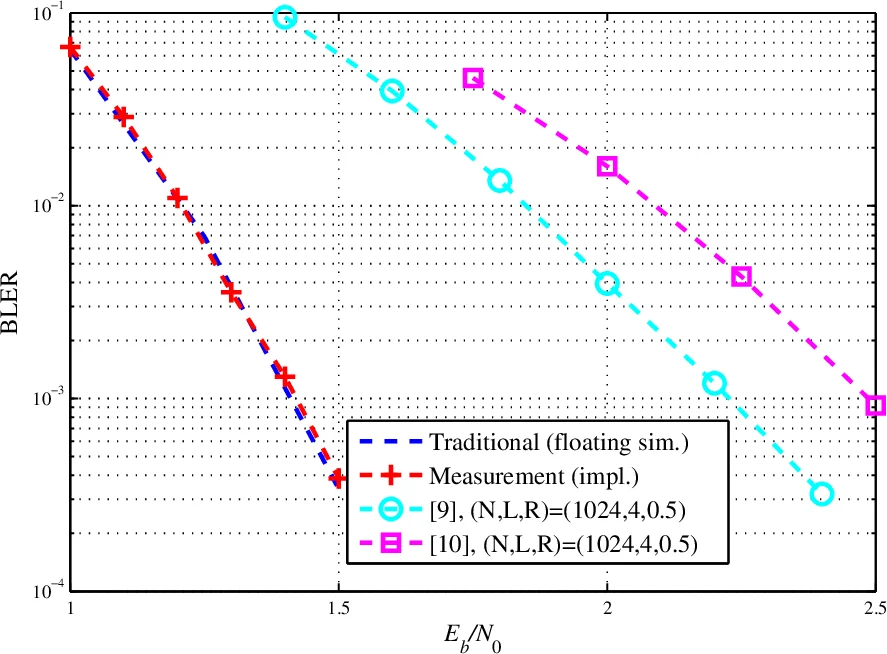
Polar codes are the first class of forward error correction (FEC) codes with a provably capacity-achieving capability. Using list successive cancellation decoding (LSCD) with a large list size, the error correction performance of polar codes exceeds other well-known FEC codes. However, the hardware complexity of LSCD rapidly increases with the list size, which incurs high usage of the resources on the field programmable gate array (FPGA) and significantly impedes the practical deployment of polar codes. To alleviate the high complexity, in this paper, two low-complexity decoding schemes and the corresponding architectures for LSCD targeting FPGA implementation are proposed. The architecture is implemented in an Altera Stratix V FPGA. Measurement results show that, even with a list size of 32, the architecture is able to decode a codeword of 4096-bit polar code within 150 us, achieving a throughput of 27Mbps
💡 Research Summary
Polar codes are the first class of forward error correction (FEC) codes that can provably achieve channel capacity. When decoded with a list successive cancellation decoder (LSCD) using a large list size (L ≥ 16), polar codes outperform many well‑known FEC schemes such as LDPC and turbo codes. However, the hardware complexity of LSCD grows roughly with O(L²) because each decoding step requires L × L crossbars for data alignment and a 2L‑input sorter to keep the list size constant. This quadratic growth quickly exhausts the resources of field‑programmable gate arrays (FPGAs), making large‑list implementations (e.g., L = 32) practically infeasible.
The authors address this problem by proposing two low‑complexity techniques and integrating them into a unified LSCD architecture that can be mapped onto an Altera Stratix V FPGA. The first technique, called Parallel‑F Serial‑G (PFSG) computation, exploits the observation that during the processing of F‑nodes (the “combine” operation in the decoding tree) no data permutation is required. Consequently, all F‑node calculations for the L paths can be performed in parallel without any crossbars, using a one‑to‑one mapping between LLR memory banks and processing elements (PEs). G‑node calculations, which do require partial‑sum information, are executed serially across the L paths. This hybrid parallel‑serial schedule reduces the overall latency to roughly (L + 1)/2 times that of a conventional SCD, i.e., about half the latency of a naïve serial mapping for large L. Memory usage is further optimized by grouping the L LLR banks into Lβ blocks (β being a power of two) and sharing them across cycles, thereby lowering the number of required RAM blocks.
The second technique, Low‑Complexity List Management (LCLM), tackles the expensive list pruning step. Traditional LSCD expands each surviving path into two candidates at every decoded bit, leading to 2L candidates that must be sorted. Multi‑bit decoding (MBD) can expand a whole subtree of M = 2^m bits at once, but this generates up to 2^M candidates per path, which is still prohibitive. LCLM combines MBD with Selective Expansion (SE): the set of information bits A is split into an unreliable subset Au and a reliable subset Ar based on pre‑computed reliability metrics. Only bits in Au are fully expanded; for bits in Ar the decoder selects the minimum‑cost continuation among the 2^Mr possibilities (Mr = |Ar|). The path metric update for an expanded path becomes
γ_LCLM = min_{v∈Ar}
Comments & Academic Discussion
Loading comments...
Leave a Comment