Off the Beaten Track: Using Deep Learning to Interpolate Between Music Genres
We describe a system based on deep learning that generates drum patterns in the electronic dance music domain. Experimental results reveal that generated patterns can be employed to produce musically sound and creative transitions between different g…
Authors: Tijn Borghuis, Aless, ro Tibo
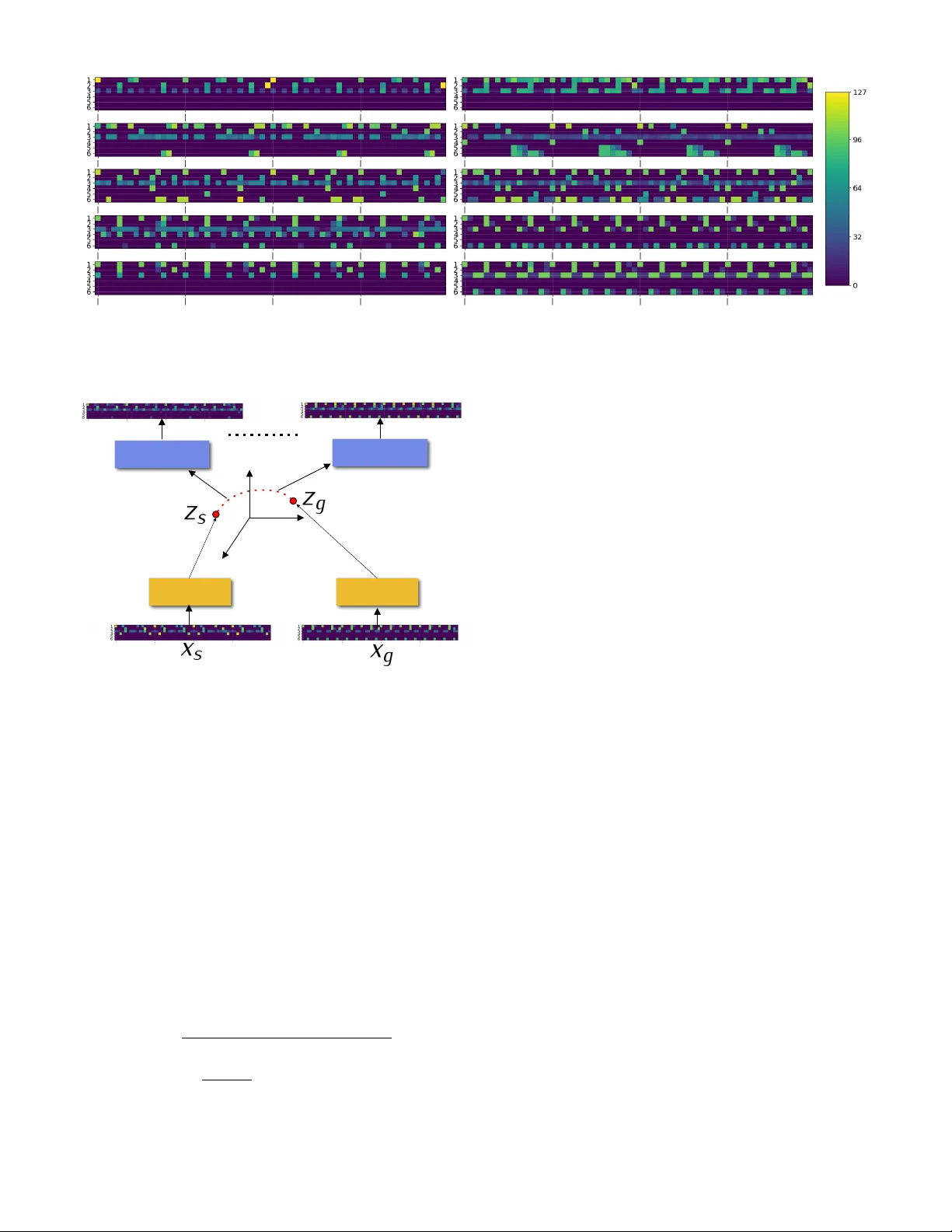
1 Off the Beaten T rac k: Using Deep Lear ning to Inter polate Between Music Genres Tijn Borghuis, Alessandro Tibo , Simone Conforti, Luca Canciello, Lorenz o Brusci, P aolo F rasconi F Abstract —We describe a system based on deep lear ning that gener- ates drum patter ns in the electronic dance music domain. Experimental results rev eal that generated patterns can be employ ed to produce musically sound and creativ e transitions between diff erent genres, and that the process of generation is of interest to practitioners in the field. Index T erms —Music generation, Electronic music, V ariational autoen- coders, Generativ e adversarial networks. Automatic music generation is a fast growing area with applications in diverse domains such as gaming [1], virtual environments [2], and entertainment industry [3]. A thor- ough account of goals and techniques is presented in [4]. Electronic dance music (EDM) is one of the domains where automatic generation appears to be particularly promising due to its heavily constrained repetitive structure, charac- terized by clearly defined stylistic forms [5]. In this domain, a typical task of “traditional” Disk-Jockeys (DJs) operating in dance clubs and radio stations is to obtain seamless tran- sitions between the consecutive tracks of a given playlist. When the individual song tracks are entirely pre-recor ded, the main tools available to DJs are a combination of an accurate synchronization of beats-per -minute (BPM) via beatmatching, and a perceptually smooth crossfading (i.e. gradually lowering the vol ume of one track while incr easing the volume of the other track), occasionally with the help of equalizers and other effects such as reverbs, phasers, or delays, which ar e commonly available in commercial mixing consoles. However , since the early 1990’s, it has become increasingly common for DJs to take advantage of samplers and synthesizers that can be used to generate (compose) on- the-fly novel musical parts to be combined with the existing pre-r ecorded material. Artists such as DJ Shadow and DJ Spooky have indeed demonstrated that the line demarcating • T . Borghuis is with Eindhoven University of T echnology (NL). E-mail: v.a.j.bor ghuis@tue.nl • A. Tibo is with University of Florence (IT). E-mail: alessandro.tibo@unifi.it • S. Conforti is with University of Basel (CH) and Conservatorio G.F . Ghedini di Cuneo (IT). E-mail: simone.conforti@unibas.ch • L. Canciello is a fr eelance composer and sound designer and was with Mu- sica Combinatoria, Krakow (PL) during the development of this project. E-mail: info@lucacanciello.com • L. Brusci is with Musica Combinatoria, Krakow (PL). E-mail: lorenzo.brusci@musi-co.com • P . Frasconi is with University of Florence (IT). E-mail: see http://ai.dinfo.unifi.it/paolo DJing and electronic music composition can be extremely blurry [6]. In this paper , we explore the automation of track tran- sitioning when the consecutive tracks belong to different genres. Previous attempts to automate track transitioning are limited to time-stretching and crossfading [7], essentially mimicking the human work of a traditional DJ. While these approaches can effectively achieve the goal of a seamless mix between pre-r ecorded tracks (particularly when the tracks stay within the same musical genre), they hardly fit the contemporary scenario where DJs and composers are seeking artistically interesting results also by using in a creative way transitions spanning differ ent genres. W e thus advocate a radically differ ent perspective where novel musical material is automatically generated (composed) by the computer in order to smoothly transition from one genre to another . The hope is that by exploring this smooth musi- cal space in an automatic fashion, we can create materials that are useful to musicians as novel elements in com- position and performance. In this new approach, we thus take transitions be compositional devices in their own right. Depending on length, transitions serve different functions in dance music: they could be momentary sound effects on a short time scale, or comparable to frequency sweeps on longer time scales, or on even longer scales to act as an automatically generated foundation on top of which musical layers can be added, both in live performance and post- production. Building a general interpolation tool that encompasses the whole set of instruments is beyond the scope of this paper . Genre in the domain of EDM is mainly determined by the basic rhythm structur e of drum instruments. Hence, by taking these drum patterns as the musical material for an experiment, the complexity associated with other aspects such as harmony , melody and timbre [8], that are relevant for genre in other musical domains, can be sidestepped. At the same time, the domain r emains suf ficiently complex and suitable for significant real-world usage by music profes- sionals such as DJs, producers, and electronic musicians. T o investigate the potential of deep learning for transi- tioning between dance music genres, we designed a learning system based on variational autoencoders [9], we trained it on a dataset of rhythm patters from different genres that we created, and then we asked it to produce interpolations between two given rhythm patterns. Such transitions consist of a sequence of rhythm patterns, starting from a given 2 pattern from one genre and ending in a given goal pattern (possibly from another genre). The connecting patterns in between are new rhythm patterns generated by the trained system itself. Along the same vein, we also developed an au- tonomous drummer that smoothly explores the EDM drum pattern space by moving in the noise space of a generative adversarial network [10]. W e constructed an experimental software instrument that allows practitioners to create in- terpolations, by embedding the learning system in Ableton Live, a music softwar e tool commonly used within the EDM production community . Finally , the proposed process for creating interpolations and the resulting musical materials were thoroughly evaluated by a set of musicians especially recruited for this resear ch. G E N E R AT I V E M A C H I N E L E A R N I N G Many machine learning applications are concerned with pattern recognition problems in the supervised setting. Recently , however , a rather differ ent set of problems has received significant attention, where the goal is to generate patterns rather than recognize them. Application domains are numerous and diverse and very often involve the generation of data for multimedia environments. Examples include natural images [11], videos [12], paintings [13], text [14], and music [8], [14], [15]. Pattern generation is closely related to unsupervised learning, where a dataset { x (1) , . . . , x ( n ) } of patterns, sam- pled from an unknown distribution p , is given as input to a learning algorithm whose task is to estimate p or to extract useful information about the structure of p such as clusters (i.e. groups of similar patterns) or support (i.e. regions of high density , especially when it consists of a low- dimensional manifold). In pattern generation, however , we are specifically interested in sampling new patterns from a distribution that matches p as well as possible. T wo important techniques for pattern generation are generative adversarial networks and (variational) autoencoders, briefly reviewed in the following. Generative Adver sarial Networks Generative Adversarial Networks (GANs) [10] consist of a pair of neural networks: a generator , G : R d 7→ R m , parame- terized by weights w g , and a discriminator , D : R m 7→ { 0 , 1 } , parameterized by weights w d . The generator receives as input a vector z ∈ R d sampled from a given distribution q and outputs a corresponding pattern G ( z ) ∈ R m . W e can interpret z as a low-dimensional code for the generated pattern, or as a tuple of coordinates within the manifold of patterns. The discriminator is a binary classifier , trained to separate true patterns belonging to the training dataset (positive examples) from fake patterns produced by the generator (negative examples). T raining a GAN is based on an adversarial game where the generator tries to produce fake patterns that are as hard to distinguish from true patterns as possible, while the discriminator tries to detect fake patterns with the highest possible accuracy . At the end of training we hope to reach a game equilibrium where the generator produces realistic patterns as desired. The discriminator is no longer useful after training. Equilibrium is sought by minimizing the following objective functions, for the discriminator and for the generator , respectively: J d ( w d ) = E x ∼ p [ L ( D ( x ) , 1)] + E z ∼ q [ L ( D ( G ( z )) , 0)] (1) J g ( w g ) = E z ∼ q [ L ( D ( G ( z )) , 1)] (2) where L denotes the binary cross-entropy loss, q can be either a uniform distribution on a compact subset of R d or , alternatively , a Gaussian distribution with zero mean and unit variance. Since p is not accessible, the expectation in Eq. (1) is replaced by its empirical value on the training sample. In practice, fake data points are also sampled. Op- timization typically proceeds by stochastic gradient descent or related algorithms where a balanced minibatch of real and fake examples is generated at each optimization step. A utoencoders and V ariational Autoencoder s Autoencoders also consist of a pair of networks: an encoder , E , parameterized by weights w e , that maps an input pattern x ∈ R m into a latent code vector z = E ( x ) ∈ R d , and a decoder , D , parameterized by weights w d , mapping latent vectors z ∈ R d back to the pattern space R m . In this case, the two networks are stacked one on the top of the other to cr eate a composite function D ◦ E : R m 7→ R m , and the overall model is trained to repr oduce its own inputs at the output. Since typically d m , the model is forced to develop a low-dimensional representation that captures the manifold of the pattern associated with the data distribution p . T raining is performed by minimizing the objective J ( w e , w d ) = E x ∼ p [ L ( D ( E ( x )) , x )] (3) where the parameters w e and w d are optimized jointly and L an appropriate reconstruction loss. V ariational autoencoders (V AEs) [9] also consist of an encoder and a decoder , but they bear a probabilistic inter- pretation. T o generate a pattern, we first sample a vector z ∈ R d from a prior distribution p ( z ) (usually a multivariate Gaussian with zero mean and unit variance), and we then apply z as input to the decoder , in order to obtain p ( x | z ) . The encoder in this case produces an approximation q ( z | x ) to the intractable posterior p ( z | x ) . Specifically , q ( z | x ) is a multivariate Gaussian whose mean µ ( x ) and diagonal covariance σ ( x ) are computed by the encoder network E receiving a pattern x as input. A V AE is then trained to minimize the difference between the Kullback-Leibler divergence KL( q ( z ) || p ( z )) = Z q ( z ) log p ( z ) q ( z ) dz (4) = 1 2 d X j =1 1 + log σ 2 j ( x ) − µ 2 j ( x ) − σ 2 j ( x ) and the log conditional likelihood log p ( x | z ) = − E x ∼ p [ L ( x, D ( z ))] . (5) Deep and Recurrent Networks All the above networks (generator and discriminator for GANs, decoder and encoder for V AEs) can be constructed by stacking several neural network layers. In particular , our encoder for the V AE was based on three bidirectional 3 Dense Layers 128 512 384 64 32 4 64x6 Reshape Fig. 1. Architecture of the v ariational autoencoder used to inter polate drum patter ns. T op: Encoder; Bottom: Decoder. long-short-term-memory (LSTM) [16] recurr ent layers with tanh nonlinearities, followed by four fully connected layers with ReLU nonlinearities, ending in a representation of size d = 4 . LSTM layers were used to capture the temporal str uc- ture of the data and, in particular , the correlations among note-on MIDI events within a drum pattern. Convolutional layers could have also been employed and we found that they produce similar reconstruction errors during training. W e developed a slight aesthetic preference towards LSTM layers in our preliminary listening sessions during the de- velopment of the V AE, although differ ences compared to convolutional layers were not very strong. The decoder simply consisted of five fully connected layers with ReLUs. W e used logistic units on the last layer of the decoder and a binary cross-entr opy loss for comparing reconstr uctions against true patterns, where MIDI velocities were converted into probabilities by normalizing them in [0,1]. Details on the architectur e are visible in Figure 1. The discriminator and the generator networks for the GAN had essentially the same architectures as the encoder and the decoder for the V AE, respectively , except of course the GAN discriminator terminates with a single logistic unit and for the V AE we used a slightly smaller (two- dimensional) noise space, in order to exploit the “swirling” explorer described below in the “autonomous drumming” subsection. Electronic Dance Music Dataset One of the authors, who is a professional musician, used his in-depth knowledge of EDM to compose a collection of drum patterns representative of three genres: Electro, T echno, and Intelligent Dance Music (IDM). In all patterns, the following six instruments of a Roland TR-808 Rhythm composer drum machine were used: bass drum, snare drum, closed hi-hat, open hi-hat , rimshot, and cowbell. The TR-808 (together with its sisters TR-606 and TR-909), was integral to the development of electronic dance music and these six in- strument sounds are still widely used in EDM genres today which makes them suitable for our interpolation approach. All patterns are one measure (4 bars) long, and quantized to 1/16th note on the temporal scale. At the intended tempo of 129 BPM, it takes 7.44s to play one measure. Patterns were constructed with the help of the Ableton Live music produc- tion software, and delivered in the form of standard MIDI files. After checking for duplicates, a data set consisting of 1782 patterns resulted, which is summarized in T able 1. Each drum pattern was repr esented as a two- dimensional array whose first and second axes are as- sociated with the six selected drum instruments and the temporal position at which a MIDI note-on event occurs, respectively . Note durations were not included in the repre- sentation as they are irr elevant for our choice of percussive instruments. The duration of four measures results in a 6 × 64 array for each pattern. V alues (originally in the integer range [0,127], then normalized in [0,1]) correspond to MIDI velocities and were used during dataset constr uction mainly to represent dynamic accents or ghost (echoing) notes that may be present in some musical styles. In our repr esenta- tion, a zero entry in the array indicates the absence of a note-on event. T ABLE 1 Electronic Dance Music Dataset Style # of patterns Playing time IDM 608 4 , 525 s (1h 15m 25s) Electro 690 5 , 135 s (1h 25m 35s) T echno 484 3 , 602 s (1h 0m 2s) T otal 1 , 782 13 , 261 s (3h 41m 1s) G E N E R AT I N G I N T E R P O L AT I O N S Both techniques discussed above were used to generate sequences of drum patterns that interpolate between genr es. Using V AEs for start-goal interpolations When using V AEs, it is straightforward to create an interpo- lation between a starting pattern x s and a goal pattern x g as follows (see also Figure 3): 1) Apply the encoder E to the endpoint patterns to ob- tain the associated coordinates in the manifold space of the autoencoder: z s = E ( x s ) and z g = E ( x g ) ; 2) For a given interpolation length, L , construct a sequence of codes in the manifold space: h z 0 = z s , z 1 , . . . , z L = z g i 4 Fig. 2. T en sample dr um patter ns in the EDM dataset. Instruments from the top are (1): bass dr um, (2): snare drum, (3): closed hi-hat, (4): open hi-hat, (5): r imshot, (6): cowbell. Pix el intensities correspond to MIDI velocities . T op row: Electro-Funk; mid two rows: IDM; bottom two rows: T echno. Encoder Encoder Decoder Decoder Fig. 3. Building transitions by interpolating drum patter ns in their repre- sentation space. 3) Apply the decoder D to each element of this sequence, to obtain a sequence of patterns: hD ( z 0 ) , . . . , D ( z L ) i ; note that (unless the autoen- coder underfits the dataset) D ( z 0 ) ≈ x s and D ( z L ) ≈ x g . Linear and spherical interpolation In the case of linear interpolation (LERP), the sequence of codes is defined as z i = (1 − µ i ) z s + µ i z g (6) for µ i = i/L , i = 0 , . . . L . In the case of spherical interpola- tion (SLERP), the sequence is z i = z s sin( θ (1 . 0 − µ i )) + z g sin( θ µ i ) sin( θ ) (7) where θ = arccos( h | s z g k z s kk z g k ) . [17] offers a thorough discus- sion of the benefits of SLERP in the case of image generation. W e found that SLERP interpolations produced musically more adventurous and expressive results and thus we used them in our experimental evaluation. Crossfading vs. interpolation in the representation space W e remark the significance of performing the interpola- tion in the r epresentation space: rather than generating a weighted average of two patterns (as it would happen with crossfading, which consists of a linear combination as in Eq. 6 but using identity functions instead of E and D ), we generate at each step i a novel drum pattern from the learned distribution. T o help the reader with a visual analogy , we show in Figure 4 the difference between interpolation in pat- tern space (crossfading) and in repr esentation space using two handwritten characters from the MNIST dataset. P attern novelty A quantitative measure of quality and novelty of patterns generated by models such as V AEs or GANs is not readily available. W e observed however that several of the patterns produced by interpolating between start and goal patterns in our dataset are genuinely new . In Figure 5 we visualize the result of two-dimensional principal components analysis (PCA) showing all training set patterns and those generated by interpolating between a subset of them. It can be seen that trajectories tend to respect the distribution of the train- ing data but include new data points, showing that novel patterns are indeed generated in the transitions. A software instrument for start-goal interpolations The trained V AE (in the form of a T ensorflow model) was embedded as a plugin in Ableton Live Suite 9 for Mac OS, a program that is widely used by performing and producing musicians in EDM, and that enables the construction of soft- ware instruments via the programming environment Max for Live . During performance, musicians first specify a start and a goal pattern (chosen from the dataset), and the length of the interpolation. This can be conveniently done within the Live user interface. The controller (a small Python script) then produces the required sequence of patterns using the V AE and the resulting MIDI notes are sent to Live to be render ed in audio with a user -specified soundset. The whole process is fast enough for real-time usage. 5 Fig. 4. T op: Interpolation in the patter n space (i.e., crossf ading) between tw o MNIST characters; Bottom: interpolation in the representation space. Fig. 5. PCA plot of training data (black dots) and a set of possible star t- goal inter polations obtained with a deep LSTM V AE (labeled by the genres of the star t and goal patterns). Using GANs for autonomous drumming In the case of GANs, Step 1 of the procedur e we used to create start-goal interpolations with V AEs is not readily available. W e attempted to “invert” the generator network using the procedur e suggested in [18] but our success was limited since training patters are largely not reproducible by the generator . Although unsuitable for start-goal inter- polations, we found that GANS are very effective to create an autonomous drummer by exploring the noise space in a smooth way . Exploration can be designed in many ways and here we propose a very simple approach based on the following complex periodic function f ( t, ω 1 , ω 2 , ω 3 , ω 4 ) . = e ω 1 j t − e ω 2 j t 2 + j e ω 3 j t 3 + e ω 4 j t 4 (8) for t ∈ [0 , 2 π ] and constants ω 1 = 2 , ω 2 = 19 , ω 3 = − 20 , ω 4 = 20 . Using a GAN with d = 2 , the real and the imaginary part of f are used to form the two components of vector z . The resulting “swirl” in noise space is illustrated in Figure 6. E VA L UAT I O N E X P E R I M E N T S Although patterns generated by V AEs and GANs are novel, we still need to establish that they do add something Fig. 6. Swirl in GAN noise space associated with Eq. 8. new to the current practice of EDM and that they are of interest to its practitioners. T o this end, we designed three experiments where we asked pr ofessional musicians to assess the quality of the generated patterns. The identification experiment aims to verify if practitioners ar e able to tell start- goal interpolations apart from start-goal crossfades; the task experiment aims to assess how much musicians appreciated and were able to make use of the drum interpolation as a compositional tool; the robot experiment aims to rate the aesthetic quality of the autonomous drumming produced by the GAN when generating patterns by swirling in the repr esentation space. The goal was to answer the following questions: Q1 : Are musicians able to tell interpolations and crossfades between genres apart during listening sessions? Q2 : How do practitioners rate the novelty , adequacy , and style of the “instrument” for creating interpolations between genres? Q3 : Are the drum tracks generated by moving or interpo- lating smoothly in the repr esentation space of V AEs and GANs useful as a material for musicians in composition and performance? Identification experiment The goal of the experiment was to answer Q1. Subjects were asked to listen to pairs of transitions, a crossfade and an interpolation. Both straight and mixed pairs were formed, in which starting and goal patterns were identical or different, respectively . Three drum patterns for each of the three genres were chosen from the dataset. Nine differ ent transitions using these patterns were specified in a design 6 that includes a transition for each possible pair of genres in both directions, as well a transition within each of the three genres. Interpolations and crossfades had a length of 6 mea- sures (24 bars, 44.7s playing time). For interpolations, the endpoints were the V AE’s reconstructions of the start and goal pattern. Crossfades were produced using a standard function (equal power) of Logic Pro X. The difference between an interpolation and a crossfade was explained to the subjects in the visual domain using an animated version of Figure 4. Every subject was asked to tell apart 6 pairs, preceded by one practice pair to get acquainted with the procedur e, and received no feedback on the correctness of their answers. T ask experiment The goal of the experiment was to answer Q2 and Q3. W e used the creative product analysis model (CP AM) [19], that focuses on the following three factors : Novelty , Resolution, and Style. Each factor is characterized by a number of facets that further describe the product. For each facet, there is a 7-point scale built on a semantic differ ential: subjects are asked to indicate their position on the scale between two bipolar words (also referr ed to as anchors). Novelty involves two facets: Originality and Surprise. Resolution considers how well the product does what it is supposed to do and has four facets: Logicality , Usefulness, V alue, and Understandability . Style considers how well the product presents itself to the customer and has three facets: Or ganic- ness, W ell- craftedness, and Elegance. In this experiment, subjects were allowed to choose start and goal patterns from those available in the dataset in order to create their own interpolations using our Ableton Live interface. In this experiment, subjects were allowed to choose start and goal patterns fr om those available in the dataset in order to create their own interpolations using our Ableton Live interface. Robot experiment The goal of the experiment was to answer Q3. W e used in this case the Godspeed questionnaire [20] a well-known set of instruments designed to measur e the perceived quality of robots, based on subjects’ observations of a robot’s behavior in a social setting. They consist of 5-point scales based on semantic differentials. In our case, observation is limited to hearing the artificial agent drum and thus we chose to measure only two factors: Animacy (three facets: Lively , Organic, Lifelike) and Perceived Intelligence (three facets: Competent, Knowledgeable, Intelligent). A long interpolation of 512 bars (124 measures) was generated using the trained GAN, by “sweeping” the code space with a complex function. Six segments of 60 bars each were selected from the MIDI file, 9 measures preceded and followed by half a measure (2 bars) for leading in and out. These MIDI files were render ed into sound using an acoustic drum soundset in Logic Pro X (Drum Designer/Smash kit), where the parts of the rimshot and cowbell wer e transposed to be played by toms. Acoustic rather than electronic drum sounds were used to facilitate the comparison with human drumming. Subjects were instr ucted that they were going to listen to an improvisation by an algorithmic drummer , pre- sented with one of the 6 audio files (distributed evenly over the subject population), and asked to express a judgment on animacy and perceived intelligence. Experimental procedure The experiments were conducted with subjects active in the wider field of electronic music (DJs, producers, instrumen- talists, composers, sound engineers), that were familiar with the relevant genres of EDM. Their experience in electronic music ranged from 2–30 years (median 7 years, average 8.75). They were recruited by the authors from educational institutes and the local music scenes in Krakow (PL), Cu- neo and the wider Firenze area (IT), and Eindhoven (NL). Experiments took place in a class room or music studio setting, where subjects listened through quality headphones or studio monitors. All audio materials in the experiment were prepared as standard stereo files (44.1 kHz, 16 bits). R E S U LT S W e now present and discuss the experimental results. Identification experiment This experiment was conducted with 19 subjects using 18 distinct stimulus pairs. 13 identification errors were made in 114 pairs. For each pair correctly identified by a subject 1 point was awarded (0 for a miss). Subjects achieved an average score of 2 . 68 ± 0 . 8 and 2 . 63 ± 0 . 58 (out of 3) for straight and mixed interpolations, respectively . In total they achieved a score of 5 . 32 ± 1 . 03 (out of 6). A Chi-squared test confirms that participants scored better than chance χ 2 (19) = 25 . 92 (critical value 5 . 99 ). Clearly , subjects are able to tell interpolations and crossfades apart in a musical context. T ask experiment Fifteen subjects with knowledge of the means of EDM pro- duction were invited to construct an interpolation with the Ableton Live interface as described above (six of them had previously participated in the Identification experiment). W e asked them to rate their experience (process and result) on the CP AM scales. Figure 7(a) summarizes the results in a set of box plots, one for each of the facets. Median scores for all facets are 6 (for V alue even 7). The average scores for the facets of the factor Resolution ( Logicality 6; Usefulness 6.13; V alue 6.5; Understandability 5.8) are generally slightly higher than those for the factors Novelty ( Originality 6.13; Surprise 5.94 ) and Style ( Organic 5.82; Well-craftedness 6.06; Elegant 5.88). Although we did not use the CP AM to compare different solutions for generating transitions between drum tracks, subjects judged the process for cre- ating interpolations and its results against their background knowledge of existing techniques such as crossfades. The relatively high scores on all facets indicate that developing the current prototype into an interpolation instrument will be of value to practitioners in the field. 7 4 4 . 5 5 5 . 5 6 6 . 5 7 Originality Surprise Logicality Usefulness V alue Understandability Organicness W ell-craftedness Elegance 1 2 3 4 5 Lively Organic Lifelike Competent Knowledgeable Intelligent (a) (b) Fig. 7. (a): T ask experiment bo x plots (n=16, 7-point scale); (b): Robot experiment bo x plots (n= 38, 5-point scale). Robot experiment W e asked 38 subjects to listen to a drum track produced by the trained GAN and to rate the robotic drummer on the scales for Animacy and Perceived Intelligence. Figure 7(b) summarizes the result in a set of box plots for the aspects. The median score on all aspects is 4, with the exception of Lifelike where it is 3. A verage scor es ar e higher for the aspects of Per ceived Intelligence ( Competent 4.24; Knowledgeable 3.95; Intelligence 3.84) than for those of Animacy ( Lively 3.89; Organic 3.45; Lifelike 3.13). Comments written by the subjects indicate that they judged Perceived Intelligence mainly with respect to the construction and evolution of the patterns, whereas for Animacy the execution of the patterns was more prominent: absence of small variations in timing and timbre of the drum hits pushed their judgments towards the anchors Stagnant, Mechanical, and Artificial. This could be addressed with standard techniques to “humanize” se- quenced drum patterns by slightly randomizing the note on- sets and velocities, and rotating between multiple samples for each of the instruments, but for this experiment we used the patterns output by the GAN without such alterations. Even though this measurement just sets a first benchmark for further development, the high scores for Competent and Knowledgeable are encouraging as they suggest that the deep learning process has captured the genres in the dataset to a large extent. C O N C L U S I O N Our tool has already potential applications. First, it can be used to improve the process of producing (and delivering) libraries of drum patterns as the trained network can gener- ate a large number of patterns in the style repr esented by the training data. Second, it can support the workflows of dance musicians in new ways. Generated interpolation tracks can be recorded inside the tool to create fragments to be used in post-production or during live performance as a foundation on which a DJ or instrumentalist can layer further musical elements. In addition, V AEs or GANs can be trained on materials created by individual users, providing users with a highly customized software instrument that “knows” their personal style and is able to generate new drum tracks in this style for post-production or in performance. There are several directions that can be followed to fur- ther enrich the drumming space, including the generation of tempo for tracks that require tempo that varies over time, and the generation of additional information for selecting drum sounds in a wide soundset. A more ambitious direc- tion is to extend our approach for generating whole sets of instruments (bass lines, leads, pads, etc.) in EDM, which involves not only note onsets but also pitch and duration. R E F E R E N C E S [1] D. Plans and D. Morelli, “Experience-driven procedural music generation for games,” IEEE T ransactions on Computational Intel- ligence and AI in Games , vol. 4, no. 3, pp. 192–198, 2012. [2] P . Casella and A. Paiva, “Magenta: An architecture for real time automatic composition of backgr ound music,” in Intelligent V irtual Agents . Springer , 2001, pp. 224–232. [3] J.-I. Nakamura, T . Kaku, K. Hyun, T . Noma, and S. Y oshida, “Automatic background music generation based on actors’ mood and motions,” The Journal of V isualization and Computer Animation , vol. 5, no. 4, pp. 247–264, Oct. 1994. [4] P . Pasquier , A. Eigenfeldt, O. Bown, and S. Dubnov , “An Introduc- tion to Musical Metacreation,” Computers in Entertainment , vol. 14, no. 2, pp. 1–14, Jan. 2017. [5] A. Eigenfeldt and P . Pasquier , “Evolving structur es for electronic dance music,” in GECCO ’13 . ACM, 2013, pp. 319–326. [6] M. Katz, Capturing sound: how technology has changed music . Berke- ley: University of California Press, 2004. [7] D. Clif f, “Hang the DJ: Automatic sequencing and seamless mixing of dance-music tracks,” HP Laboratories, T ech. Rep. 104, 2000. [8] N. Boulanger-Lewandowski, Y . Bengio, and P . Vincent, “Modeling T emporal Dependencies in High-Dimensional Sequences: Appli- cation to Polyphonic Music Generation and T ranscription,” in Proceedings of the 29th International Conference on Machine Learning (ICML 2012) , Jun. 2012. [9] D. P . Kingma and M. W elling, “Auto-encoding variational Bayes,” in Proc. ICLR ’14 , 2014. [10] I. Goodfellow , J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde-Farley , S. Ozair , A. Courville, and Y . Bengio, “Generative adversarial nets,” in Advances in neural information processing systems , 2014, pp. 2672–2680. [11] A. Radford, L. Metz, and S. Chintala, “Unsupervised represen- tation learning with deep convolutional generative adversarial networks,” in Proc. of the 4th International Conference on Learning Representations , 2016. [12] C. V ondrick, H. Pirsiavash, and A. T orralba, “Generating videos with scene dynamics,” in Advances In Neural Information Processing Systems , 2016, pp. 613–621. [13] A. Elgammal, B. Liu, M. Elhoseiny , and M. Mazzone, “CAN: Creative Adversarial Networks, Generating ”Art” by Learning About Styles and Deviating from Style Norms,” in Proc. of the 8th International Conference on Computational Creativity , Jun. 2017. 8 [14] L. Y u, W . Zhang, J. W ang, and Y . Y u, “SeqGAN: Sequence Gener- ative Adversarial Nets with Policy Gradient,” in Proc. of the 31st AAAI Conference on Artificial Intelligence , San Francisco, CA, Feb. 2017. [15] L.-C. Y ang, S.-Y . Chou, and Y .-H. Y ang, “MidiNet: A Convo- lutional Generative Adversarial Network for Symbolic-domain Music Generation using 1D and 2D Conditions,” in Proc. of the 18th International Society for Music Information Retrieval Conference , Suzhou, China, Oct. 2017. [16] S. Hochreiter and J. Schmidhuber , “Long short-term memory ,” Neural computation , vol. 9, no. 8, pp. 1735–1780, 1997. [17] T . White, “Sampling generative networks: Notes on a few ef fective techniques,” arXiv preprint , 2016. [18] A. Creswell and A. A. Bharath, “Inverting The Generator Of A Generative Adversarial Network (II),” ArXiv e-prints 1802.05701 , Feb. 2018. [19] S. Besemer and K. O’Quin, “Confirming the three-factor creative product analysis matrix model in an american sample,” Creativity Research Journal , vol. 12, no. 4, pp. 287–296, 1999. [20] E. C. C. Bartneck, D. Kuli ´ c and S. Zoghbi, “Measurement instru- ments for the anthropomorphism, animacy , likeability , perceived intelligence, and perceived safety of robots,” International Journal of Social Robotics , no. 1, pp. 71–81, 2009.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment