A Spherical Probability Distribution Model of the User-Induced Mobile Phone Orientation
This paper presents a statistical modeling approach of the real-life user-induced randomness due to mobile phone orientations for different phone usage types. As well-known, the radiated performance of a wireless device depends on its orientation and…
Authors: Andres Alayon Glazunov, Per Hjalmar Lehne
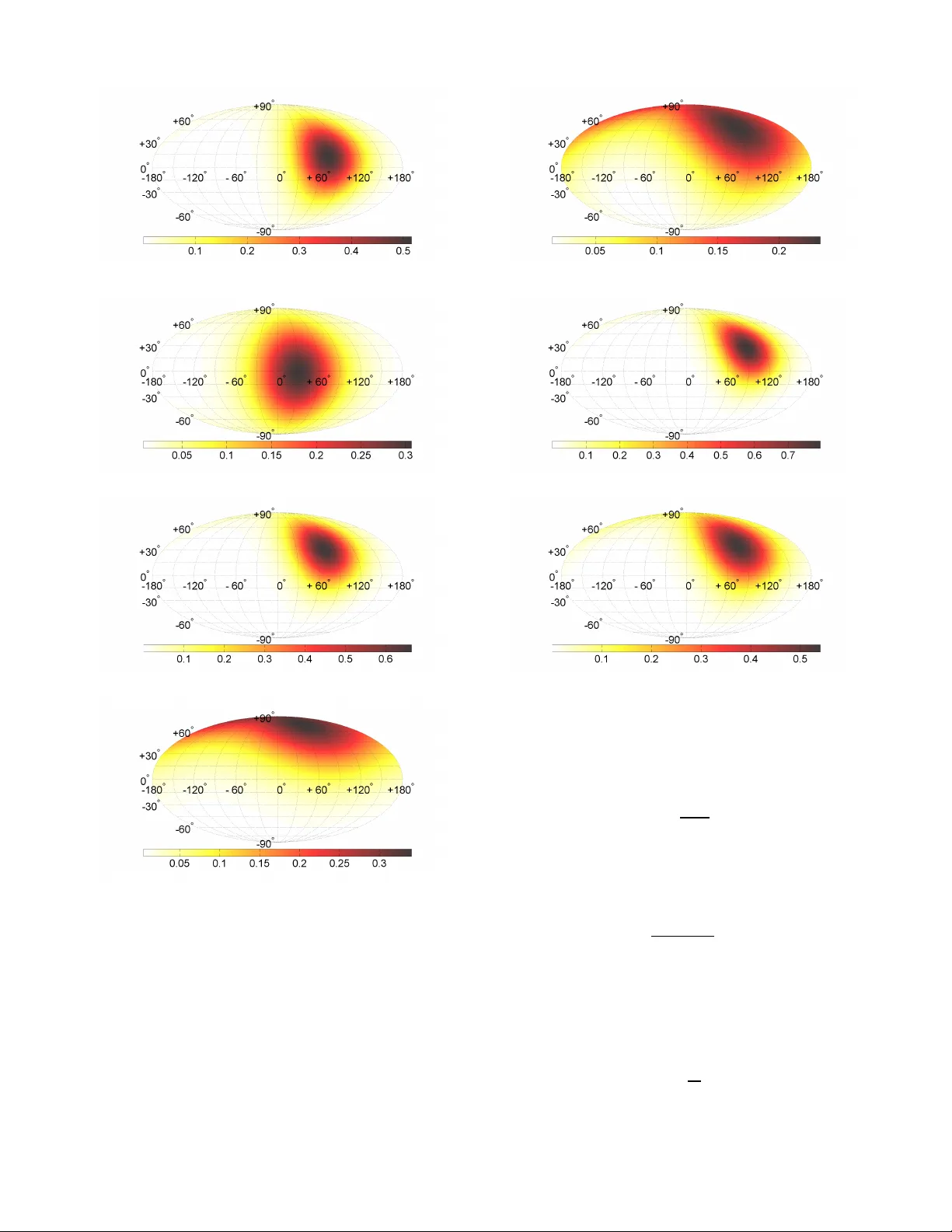
SUBMITTED TO JOURN AL 1 A Spherical Probability Distrib ution Model of the User -Induced Mobile Phone Orientation Andrés Alayón Glazunov , Senior Member , IEEE , and Per Hjalmar Lehne Abstract —This paper presents a statistical modeling approach of the real-life user -induced randomness due to mobile phone orientations for differ ent phone usage types. As well-known, the radiated performance of a wireless device depends on its orientation and position relati ve to the user . Theref ore, r ealistic handset usage models will lead to more accurate Over-The-Air characterization measurements for antennas and wireless devices in general. W e introduce a phone usage classification based on the network access modes, e.g., voice (circuit switched) or non- voice (packet switched) services, and the use of accessories such as wired or Bluetooth handsets, or a speaker-phone during the network access session. The random phone orientation is then modelled by the spherical von Mises-Fisher distribution for each of the identified phone usage types. A finite mixture model based on the individual probability distribution functions and heuristic weights is also presented. The models are based on data collected from built-in accelerometer measurements. Our appr oach offers a straightforward modeling of the user -induced random orientation for different phone usage types. The models can be used in the design of better handsets and antenna systems as well as for the design and optimization of wireless networks. I . I N T R O D U C T I O N User-induced randomness of the phone orientation has been known to influence the performance of wireless devices, such as mobile phones. User-induced randomness is understood here as the variation of the usage positions of wireless devices in real-life situations. Currently , fixed usage type positions are largely based on the hypothesis that certain phone orientations should dominate depending on the services accessed. Howe ver , they do not fully describe the actual span of possible usage positions of a mobile phone. These are needed for de vising realistic Over-The-Air (O T A) performance testing of wireless devices capable of providing satisfactory Quality-of-Service (QoS) to end users [1]. The device performance is sensitive to the propagation en vironment which in turn depends, among other things, on the usage mode of the device, e.g., device orientation in voice or non-voice modes [2], [3]. In O T A testing, two edge en vi- ronments can be defined: the RIMP (Rich Isotropic MultiPath) en vironment and the Random-LOS (Random Line-OF-Sight) This work has been supported in part by a project within the VINNO V A funded Chalmers Antenna Systems VINN Excellence Centre (CHASE) at Chalmers, and by T elenor . Andrés Alayón Glazunov is with the Department of Electrical Engi- neering, Uni versity of T wente, P .O. Box 217, 7500 AE Enschede, The Netherlands and he is also af filiated with the Department of Electrical Engineering (E2), Chalmers Univ ersity of T echnology , Gothenburg, Sweden (e-mails: a.alayonglazunov@utwente.nl, andres.glazunov@chalmers.se). Per Hjalmar Lehne is with T elenor Research, Fornebu, Norway (e-mail: per- hjalmar .lehne@telenor .com) Great part of this work was inspired by the late Prof. Per-Simon Kildal. en vironment. In RIMP , the transmit signal reaches the receive antenna isotropically through various propagation paths. On the other hand, in Random-LOS there is only one path, i.e., the direct signal path between the transmit and recei ve an- tennas that is subjected to user-induced randomness. In RIMP , performance is independent from the device orientation; yet, it depends on the device usage, e.g, po wer absorption, impedance mismatch/detuning or both, as a result of the user body and different usage positions. In Random-LOS, randomness is induced mainly by the usage position and orientation relative the base station. This results in a random Angle-of-Arriv al (AoA) and polarization of the incoming wa ves. Hence, the characterizations of wireless devices can be readily done in terms of polarization deficiencies of antennas and their impact on throughput performance as shown in [4], [5]. The O T A performance in RIMP can be tested in reverberation chambers. On the other hand, OT A performance in “pure-LOS" has been traditionally characterized in anechoic chambers. Hence, performance in Random-LOS can be measured in anechoic chambers too. It has already been demonstrated that random device ori- entation af fects the propagation characteristics [6]. In the re- cently introduced Random-LOS O T A characterization method, which uses the eponymous channel model, the effect of user- induced randomness on the system performance is naturally integrated [7]–[9]. Initial work pertaining the characterization of the user-induced randomness has been presented in [10], [11]. Howe ver , currently av ailable OT A tests do not take into account the user-induced randomness, but only fixed usage types, due to non-existing probabilistic usage models of modern versatile (smart) mobile phones. In order to fill the aforementioned knowledge gap we present here the first systematic model addressing the user - induced mobile phone orientation randomness for voice and non-voice applications. The relev ance of making such a model follows from the fact, among other things, that there is a need to produce O T A tests of antennas and wireless devices that incorporate actual user orientation in a realistic and relev ant manner . The scope of this paper is therefore to use collected accelerometer sensor data from smart phones and analyze them in order to suggest a proper model for the device orientation [11]. The underlying method of collecting data from smart phones for this purpose, can also be adapted for use in, e.g., network optimization to improv e use experience based on knowledge about usage modes, ho wev er this is outside the scope of the current work. The contributions of this paper are summarized as follows: • W e suggest an approach to extract relev ant data from ac- SUBMITTED TO JOURNAL 2 T ABLE I. Binary category classification of accelerometer data used to define phone usage type. Bit 0 1 Service V OICE NON-V OICE W ired-Headset NO YES Speaker-Phone OFF ON Bluetooth-Headset OFF ON celerometer measurements obtained with Android phones by combining outlier removal with duplicate data re- mov al. • W e introduce a usage type classification that follo ws a user’ s access to network services in terms of the two possible modes: v oice (meaning circuit switched) or non-voice (meaning packet switched) and with the corresponding use of speaker and wired- or Bluetooth- headset following the user’ s natural behaviour . That is no pre-defined usage type positions are in vestigated, but the focus is on a users’ s real-life handling of the phones. • W e propose the von Mises-Fisher (vMF) distribution, i.e., the equi valent of the Gaussian distrib ution defined on the unit sphere [12] to model the statistical probability distribution function of the orientation of mobile phones for each specific usage type. • An easy-to-use finite mixture model (FMM) is presented based on individual vMF distributions and on heuristic mixing probabilities corresponding to different phone usage types. The provided vMF distributions as well as the vMF FMM can be used to reproduce the desired random realizations of the user-induced orientations of the mobile phones and used as an input to further analysis, e.g., OT A characterization of mobile phones, or wireless network simulations. • The e xtracted model parameters corresponding to the phone usage types classification are mapped to the classi- fication of a phone’ s orientation in spherical coordinates giv en in [11]. Then, in order to harmonize our study with the existing fixed usage type definitions, e.g., defined by 3GPP we infer corresponding usage types from the ana- lyzed accelerometer data. In this way , the provided model becomes more useful for the objective of standardized O T A methods. The remainder of the paper is org anized as follows: In Section II we present a description of the data collection and classification corresponding to dif ferent usage of a mobile phone for v oice and non-voice service types, here we also present a straightforward method to select data representativ e of user-induced randomness. In Section III we introduce the von Mises-Fisher directional distribution model of the device orientation and validation procedure based on Quantile- Quantile plots (Q-Q plots). Section IV presents an analysis of the modelling results. Also here we suggest a finite mixture model for the identified phone usage types. A mapping of phone usage types to typical usage positions, assumed by 3GPP , is provided too. Conclusions and future work are outlined in Section V. Fig. 1. Gravity acceleration vector in the device coordinate system. T ABLE II. Estimated parameters corresponding to the von Mises-Fisher directional probability distribution function, i.e., the concentration parameter ˆ κ , and the mean direction vector ˆ µ in Cartesian co-ordinates and the corre- sponding orientation angles in spherical coordinates, ˆ φ µ and ˆ θ µ . Heuristic finite mixture model (FMM) weights π i j k l and the number of samples N s , i j k l used to compute them. Ph. Usage vMF Distribution Parameters FMM { i j k l } ˆ κ ˆ µ x ˆ µ y ˆ µ z ˆ φ µ , [ ◦ ] ˆ θ µ , [ ◦ ] π i j k l N s , i j k l 0000 3 . 23 0 . 27 0 . 93 0 . 24 73 . 97 76 . 37 0 . 5433 47988 0001 1 . 88 0 . 87 0 . 50 − 0 . 01 29 . 88 90 . 75 0 . 0494 4365 0010 4 . 17 0 . 23 0 . 82 0 . 52 74 . 01 58 . 51 0 . 0262 2312 0100 2 . 10 0 . 08 0 . 30 0 . 95 75 . 69 17 . 85 0 . 2253 19903 1000 1 . 37 − 0 . 04 0 . 65 0 . 76 93 . 73 40 . 85 0 . 0694 6134 1010 4 . 99 − 0 . 06 0 . 88 0 . 47 93 . 78 62 . 01 0 . 0365 3221 1100 3 . 39 0 . 08 0 . 80 0 . 59 84 . 44 53 . 73 0 . 0499 4405 I I . A C C E L E R A T I O N D AT A C O L L E C T I O N A N D I N T E R P R E T A T I O N A. Measur ements and data classification Modern smart phones of fer ample opportunities in their sensor capabilities. In this paper we use the built-in 3D linear acceleration sensors (i.e., the accelerometer) to determine the device orientation. The acceleration vector components are giv en in the device local coordinate system and deliv ers values in m/s 2 . The measured values include the gravity acceleration vector . If the phone is stationary the length of the vector is g = 9 . 8m / s 2 (or other more exact value that depends on the actual geographical location). The device local coordinate system definition for Android phones is shown in Fig. 1 [13], where the positi ve direction is defined as the direction of increased acceleration. This means that the gravity acceleration vector is pointing away from the Earth’ s centre. A smart phone application (app) has been installed onto a number of phones, and the data has been uploaded to a server which aggre gates the data automatically into a searchable database [10]. This app records sensor values from the phone in the background while the smart phone is active, i.e., during a phone call or non-voice session. The app collects samples approximately once per second. The phones belonged to ordinary users, and no instruction of specific behaviour was giv en, since we wanted to record the normal usage. Once installed and registered, the app was running as a background service on the phone, and was not interacting in any way with SUBMITTED TO JOURNAL 3 the user . Hence, during a service session the user behaves naturally , i.e., carries out with her common behaviour while using the mobile phone. The data is further classified into four binary and self- explanatory categories as shown in T able. I. The voice service in this context means circuit switched (CS) voice, not V oIP services like Skype or V iber which belong to the non-voice services. The value 0 is prescribed to the voice service, and to the NO and OFF specifications, while at the same time prescribing the value 1 to the non-v oice service, and to the YES and ON specifications we get a 4 − bit binary representation of the data giving 16 possibilities in total, out of which only some mak e practical sense. For example, a user that during v oice service doesn’t use a wired-headset, a speaker phone or a Bluetooth-headset can be denoted as phone usage type: 0000 . Another user, that during non-voice service, uses a wired-headset, a speaker phone and a Bluetooth-headset can be denoted as phone usage type: 1111 . The likelihood of observing phone usage type 0000 is high since it corresponds to the traditional w ay to talk ov er the phone. On the other hand phone usage type 1111 doesn’t really make sense in a practical scenario. B. Acceleration data modelling and estimates The gravity acceleration vector is used to estimate the accelerometer orientation [14]. The collected acceleration data is modelled by two terms a = R g + a e , (1) where each data sample i is actually a 3D vector a i = ( a x i , a y i , a z i ) , g has the same magnitude as the gravity ac- celeration vector , but is directed in the opposite direction, i.e., upwards. If there are no other forces than gravity acting upon the device, i.e., the de vice is still or moving at a uniform rectilinear velocity , then a e = 0 . In this case, the measured acceleration is just the projection of the v ector g into the local coordinate system of the device. Hence, the change of direction of the vector g is determined by the rotation matrix R , such that k R g k = g , where the symbol k x k denotes the Euclidean norm of vector x . Additiv e errors are modelled by a e since the actual non-inertial mov ement pattern (due to acceleration or deceleration) of the user is not known. The true distribution of a e is not known either nor are the distributions of the elements of the rotation matrix R . The above physical arguments lead us to the following observations: first, the acceleration data samples can be con- sidered random ; secondly , there may be outliers (i.e., samples that are much larger or smaller than the rest of the samples), and thirdly , ambiguity in acceleration data samples can be reduced by choosing those which magnitude is close to the magnitude of the gravity acceleration vector , i.e., k a k ≈ g . Follo wing these observations we seek to remove outliers from data samples that are much larger or much smaller than g . T o identify and remove outliers from the data we use the 1 . 5 IQR-rule . A data sample a i is considered an outlier if k a i k > Q 3 + 1 . 5 I Q R or k a i k < Q 1 − 1 . 5 I Q R , where I Q R = Q 3 − Q 1 is the Inter-Quartile Range, Q 1 and Q 3 are the Fig. 2. Example of empirical Cumulativ e Distribution Function of the magni- tude of the measured acceleration k a k (upper subplot) and the corresponding empirical Probability Distribution Function of the three cartesian components of the orientation vector ρ . Plots corresponding to the raw data and to data after removing outliers are shown for voice service users that used no wired- headset, no speaker-phone and no Bluetooth-headset, i.e. usage type: 0000 . 25% − and the 75% − quartiles, respectiv ely . W e use the f act that the size of the I Q R is an indication of the spread of the middle half of the data. In our case it should be concentrated in a very narrow region around Q 2 , the 50% − quartile, i.e., the median. Removing the outliers will hav e a filtering ef fect on the measurement data, which is a desirable ef fect since it improv es the quality of the data. Other errors, e.g., due to hardw are impairments, noise etc., are not considered here. Their impor- tance will become apparent only for very accurate estimations of the user location [15], [16]. Another aspect related to the data quality or the number of useful samples, i.e., measurements coming from completely random user positions. For example, in realistic situations, it is unlikely to observe a large number of identical consecutiv e acceleration values. This is because, the movement pattern of a user is not completely stationary . Stationarity of users is outside the analysis presented here. Howe ver , we suggest, as a first step tow ard reducing measurement artifacts to take into account only unique acceleration samples . In this way , we remove duplicate data that cannot be clearly understood or that is not representati ve for the general usage patterns of mobile phones. In the future, as the size of data base increases, especially with measurements coming from a large number of different users, more sophisticated data processing will become necessary . Hence, in this paper we remove data artifacts following two criteria: a data sample must not be an outlier, i.e., the acceleration vector can’t be much larger or smaller than g and it’ s components must be unique. Next we present a statistical distribution model for user-induced mobile phone orientation. I I I . S P H E R I C A L M O D E L O F T H E D E V I C E O R I E N T AT I O N A N D V A L I DA T I O N P RO C E D U R E The actual orientation of a device is giv en by the θ and φ angles as shown in Fig. 1. W e propose here an equiv alent way that we believe is more meaningful and useful. SUBMITTED TO JOURNAL 4 (a) (b) (c) (d) Fig. 3. 3D von Mises-Fisher probability distribution function represented on a 2D Mollweide map projection for voice users, more specifically for phone usage types; a) 0000 , b) 0001 , c) 0010 and d) 0100 . See T able. I and T able. II for phone usage type and distribution parameter specification, respectively . A. The von Mises-F isher (vMF) dir ectional distribution Indeed, from the physical considerations stated above we can see that the actual orientation of the device is giv en by the orientation of the gravity acceleration v ector in the de vice local coordinate system x y z . In this case the tip of the “random" vector g defined in this x y z -system will lay on the sphere with radius g . Hence, it is enough to define the vector indicating the orientation of the mobile phone device, i.e., an orientation (a) (b) (c) Fig. 4. 3D von Mises-Fisher probability distribution function represented on a 2D Mollweide map projection for non-voice users, more specifically for phone usage types: a) 1000 , b) 1010 , and c) 1100 . See T able. I and T able. II for phone usage type and distribution parameter specification, respectively . vector . For acceleration data sample i we define it as ρ i = a i k a i k , (2) where ρ i = ( ρ i x , ρ i y , ρ i z ) with k ρ i k = 1 . A useful model describing the statistical distribution of a unit vector ρ ∈ R 3 is the von Mises-Fisher (vMF) probability distribution function (pdf) [12] f ( ρ ; µ , κ ) = κ 4 π sinh ( κ ) e xp ( κ µ T ρ ) , (3) where the parameter µ with k µ k = 1 , is the mean direction and κ > 0 , is the concentration parameter . The distribution is rotationally symmetric around the mean direction µ , which provides the direction of concentration of data. The higher the spread of the data, the lower is κ , and viceversa. For uniformly distributed points on the sphere (i.e., isotropically distributed), κ = 0 and (3) becomes f ( ρ ) = 1 4 π ; no mean direction can be defined in this case. The maximum-likelihood estimators of the two parameters ˆ µ and ˆ κ are kno wn and are computed follo wing the results provided in [17]. For the sake of completeness of exposition the estimators are giv en in appendix A. SUBMITTED TO JOURNAL 5 There are known algorithms to generate random vectors ρ following the distribution (3) [18]. In our computations we use the MA TLAB r script provided in [19]. (a) (b) (c) (d) Fig. 5. Q-Q plots for voice users, more specifically for phone usage types; a) 0000 , b) 0001 , c) 0010 and d) 0100 . See T able. I and T able. II for phone usage type and distribution parameter specification, respectively . B. Q-Q plots for the vMF dir ectional distribution The vMF distribution parameters, ˆ µ and ˆ κ , i.e., the esti- mates of the mean direction and the concentration parameter, respectiv ely , fully define our model of the directional data. (a) (b) (c) Fig. 6. Q-Q plots for non-voice users, more specifically for phone usage types; a) 1000 , b) 1010 , and c) 1100 . See T able. I and T able. II for phone usage type and distribution parameter specification, respectively . Howe ver , we need to assess how well the model fits our data. An illustrativ e way is just plotting the normalized acceleration vectors or orientation v ectors (2). Ho wev er , gi ven the large number of measurement points this is not a very practical way . Besides, we need a more meaningful approach. In this paper we use the so-called Quantile-Quantile plot or Q-Q plot for short. A Q-Q plot is a graphical method showing the quantiles of one probability distribution against the quantiles of another probability distribution. Hence, two probability distrib utions can be definitely compared and if two data samples come from the same probability distribution or data comes from the same theoretical probability distribution as the model then the Q-Q plot is a straight line. It is worthwhile to note that the Q-Q plot only gives an approximate idea of the underlying distribution. In our analysis we use the Q-Q plot concept for directional statistics introduced in [20]. It is straightforward to implement, to interpret and it has many other advantages therein. The applicability of the method, i.e., the new quantile definition is restricted to the class of directional probability distributions with bounded density , admit a unique median direction, and SUBMITTED TO JOURNAL 6 are rotationally symmetric about the mean direction, which are satisfied by the vMF distribution. Due to practical reasons, we consider in this paper the empirical version for computing the pr ojection quantile , i.e., ˆ c τ . For a gi ven quantile τ ∈ [ 0 , 1 ] , the corresponding projection τ − quantile is obtained in three steps: (1) estimate the median µ by an estimator ˆ µ , (2) project all observations onto ˆ µ , i.e., the projected population is ρ T ˆ µ and (3) use a traditional definition of univ ariate quantiles for determining the ˆ c τ . I V . D A TA P RO C E SS I N G , M O D E L FI T T I N G R E S U LT S A N D A N A L Y S I S The analysis includes data that has been collected from 11 users which used 7 different smart phone models from 4 different brands. Disclosing further details is outside the scope of this paper since we focus on the orientation statistics. A. Data pr e-pr ocessing Prior to proceeding with the model fitting, the accelerometer data was e xtracted following the binary categories giv en in T able. I. Then, outliers were removed following the 1 . 5 IQR- rule and duplicate data entries were removed by taking unique values. The same procedure was applied to all phone usage types that could be extracted from the collected data. The phone usage types are listed in the first column in T able. II. An example of the results of the data processing is giv en in Fig. 2. The upper subplot shows the Cumulativ e Distribution Function (CDF) of the magnitude of the acceleration k a k corresponding to the voice service for users that used no wired- headset, no speaker-phone and no Bluetooth-headset. Results are presented for the raw data as downloaded from the app and data that has been processed as explained above. As expected, the applied outlier elimination rule and selecting unique values mov ed the distribution of k a k tow ard the median, i.e., the gravity acceleration g . The three lower subplots in Fig. 2 sho w the Probability Distribution Function (PDF), or rather , the normalized his- togram of ρ i x , ρ i y , ρ i z components of the corresponding normalized acceleration vector , i.e., the phone orientation vector (1). As can be seen the data processing efficiently remov ed as turned out to be duplicated values in the vicinity of ρ i x = ρ i y = 0 and for ρ i z = 1 . It is worthwhile to recall that corresponding acceleration values where removed prior normalization. Hence, we expect the processed data be more representativ e of the user-induced randomness due to device orientation. The presented approach should be considered as a straightforward, yet approximate, identification procedure of useful random data samples. B. von Mises-F isher distribution fitting Fig. 3 and Fig. 4 show the 3D vMF directional PDFs represented on a 2D Mollweide map projection corresponding to voice and non-voice phone usage types, respectively . The functions where generated using (3) and using the distribution parameters estimates (see Appendix A) giv en in T able. II. The presented plots provide a full spherical coverage of the (a) (b) Fig. 7. φ - θ plots showing the location and spreading of the different usage types. Size of squares are inversely proportional to the concentration factor κ ; a) voice b) non-voice. See T able. I and T able. II for phone usage type and distribution parameter specification, respectiv ely . The circles show the OT A test positions as defined by the 3GPP and explained in T able. III. statistical distribution for both voice and non-v oice phone usage. W e can clearly see the main direction for each usage type, i.e., the mean phone orientation in the different usage orientations. As explained abov e, the lower the κ parameters the less concentrated values of the orientations around the mean orientation and viceversa. Fig. 5 and Fig. 6 sho w the Q-Q plots corresponding to sample vMF distributions v .s. theoretical (simulated) vMF distributions computed with estimated parameters gi ven in T able. II. Each plot in Fig. 5 and Fig. 6 should be con- sidered in juxtaposition with corresponding plots in Fig. 3 and Fig. 4, respectiv ely . The estimated projection quantiles ˆ c τ where obtained for quantiles τ = { 0 . 05 , . . ., 0 . 95 } taken in 0 . 01 steps. Hence, the leftmost point corresponds to τ = 0 . 05 ( 5% - quantile), while the rightmost point corresponds to τ = 0 . 95 ( 95% -quantile). By visual inspection we immediately realize that the proposed vMF model only approximately describes the directional distribution of the data. The best fits correspond to phone usage type 0000 , 0010 and 1010 , followed by less so models corresponding to phone usage type 1000 , 1100 and 0100 and the worst fitting is for phone usage type 0001 . The main reason that may lead to discrepancies between the model and the data samples is the fact that the underlying true empirical distribution is not well-described by a single cluster . Therefore, future models should take into account multiple clusters and a possible correlation between them. Howe ver , the presented results may be considered as a first-order approxi- SUBMITTED TO JOURNAL 7 T ABLE III. O T A test conditions as defined by the 3GPP [21]. Index 3GPP test condition Comment 1 XY -plane V ertical upright 2 XZ-plane V ertical sideways 3 Free space data mode (FS-DMSU) Horizontal, screen up 4 Face down Horizontal. screen down 5 Free space data mode portrait (FS-DMP) Portrait, tilted 6 Free space tilted down Portrait, downtilted 7 Free space data mode landscape (FS-DML) Landscape, tilted 8 Free space landscape, tilted down Landscape, downtilted 9 Left/right hand phantom data mode portrait (LH/RH-DMP) Portrait, tilted 10,11 Beside head and hand right/left (BHHR/BHHL) Cheek right and cheek left T ABLE IV. Matching phone usage types and CTIA/3GPP test conditions. Ph. Usage { i j k l } 3GPP T est Cond. Comment 0000 1 V oice, no wired or wireless headset. V ertical upright 0001 10 V oice, Bluetooth on. V ertical slant 0010 5,9 V oice, speakerphone. Portrait, tilted 0100 3 V oice, wired headset. Horizontal screen up 1000 5,9 Non-voice, no wired or wireless headset. Portrait, tilted 1010 1,5,9 Non-voice, speakerphone. Portrait, vertical to tilted 1100 5,9 Non-voice, wired headset. Portrait, tilted mation describing the user-induced mobile phone orientation randomness. And as shown above, for some specific cases, the vMF is indeed an excellent fit to the statistical distribution of the orientation of the mobile phone. C. F inite mixtur e model for user induced randomness The vMF distribution is indeed a straightforward model that together with parameters provided in T able. II gi ves an easy way to simulate different phone orientations following the algorithm in [18]; also the MA TLAB scripts av ailable in [19] can be used. Howe ver , we need more, we need a model with as much flexibility as needed to accurately describe the real life data. The concept of a finite mixture model (FMM) provides us with the desired model flexibility [22]. W e may define an FMM of vMF distributions describing different phone usage type as the device orientation vector ρ with the PDF f mix ( ρ ; γ ) = Í 1 i = 0 Í 1 j = 0 Í 1 k = 0 Í 1 l = 0 π i j k l f ( ρ ; µ i j k l , κ i j k l ) Í 1 i = 0 Í 1 j = 0 Í 1 k = 0 Í 1 l = 0 π i j k l , (4) where f ( ρ ; µ i j k l , κ i j k l ) is the vMF distribution with mean direction µ i j k l and concentration parameters κ i j k l and the weights π i j k l ≥ 0 satisfy the probability normalization 1 Õ i = 0 1 Õ j = 0 1 Õ k = 0 1 Õ l = 0 π i j k l = 1 . (5) The parameter γ = { µ i j k l , κ i j k l , π i j k l } with i , j , k , l = { 0 , 1 } , (6) denotes the parameter matrix of the FMM. The number of components is itself a parameter of the model. The drawback is that estimating the parameters of the vMF FMM is not a tri vial task and requires a rather sophisticated approach to solving the task at hand [22]. Here, we propose a heuristic approach exploiting the knowledge about the data that we already hav e. Indeed, since we define the phone usage types, we can then in turn compute the frequency of observing data that correspond to a certain phone usage type π i j k l as π i j k l = N s , i j k l Í 1 i = 0 Í 1 j = 0 Í 1 k = 0 Í 1 l = 0 N s , i j k l , (7) where N s , i j k l denotes the number of samples used to estimate the vMF distrib ution parameters. Clearly , (7) satisfies the normalization (5). Assuming a vMF FMM that includes all the practical phone usage types, we can then obtain the heuristic weights as gi ven in T able. II. T erms with missing v alues are just replaced by 0 in the summations in (4), (5) and (7). In this way we hav e now computed all the values of the FMM parameter matrix γ in (6). The PDF of the vMF FMM is now fully defined, which can be straightforwardly simulated following standard algorithms, e.g., the composition method algorithm [23]. In addition to the above model, other mixture models can be generated with the same procedure when applied to subsets of phone usage types according to T able. II. For example, it may be interesting to consider usage types when no headsets nor speaker phone are used. In that case the vMF FMM distribution is computed by with the help of the parameters corresponding to phone usage types 0000 and 1000 in T a- ble. II. It is worthwhile to note that in this case the weights π 0000 and π 1000 do not sum up to 1 . Howe ver , the formulation of the vMF FMM (4) guaranties that the renormalized weights π 0000 π 0000 + π 1000 and π 1000 π 0000 + π 1000 do sum up to 1 as required. SUBMITTED TO JOURNAL 8 Hence, differentiating the most common phone usages for the two main services enables a systematic modelling of the de vice orientation, with applications to O T A testing, to wireless network analysis and optimization, to radio wa ve propagation and indoor localization. D. Mapping phone usage types to typical usage positions In [11], the concept of user modes was introduced. The hypothesis is that certain ways of holding the phone should dominate depending on the services accessed. For voice usage it is expected that use of handsfree, whether wired, bluetooth or loud-speaker , would be different than without. W e see from the vMF distribution parameters in T able II that this is the case. T raditional usage for v oice calls would be holding the phone to either right or left cheek, while handsfree usage could include a number of modes. For non-voice usage, we could expect that some kind of slant holding positions, either portrait or landscape mode would be typical, but also having the phone lying horizontally on a flat surface. Industry and standards organizations CTIA and 3GPP has dev eloped test plans for OT A performance measurements of user equipment [21], [24]. Here, fixed orientation conditions for Equipment Under T est (EUT) has been defined, including a number of EUT orientation angles. These correspond to our definition of user modes, and some anticipated modes are drawn in the φ - θ coordinate system in Fig. 7 together with the found statistics from T able II. The user modes corresponding to the CTIA and 3GPP orientation angles are sho wn in the same figures and explained in III. F or voice usage, we see that an upright position tending towards left cheek is common without handsfree (usage type 0000 ), while handsfree usage results in more slant positions. Use of wired handsfree is near to horizontal flat mode. For non-voice usage, most usage types maps to portrait orientation, except the use of speaker which shows a vertical position. The statistics analysis in [11] showed that there are multiple clusters, especially for usage type 0000 , and that is missed here, as discussed in subsection IV -B. T wo quite visible peaks on left cheek and right cheek was visible, where the left position was most common. The preference for left cheek is only visible by the centre position of the 0000 usage type. The CTIA and 3GPP defined orientation angles are not giv en as distrib utions, but as fixed points. As can be seen from T ables III and IV -A, only some of the definitions seem relev ant. For example, for voice usage this are 3 , 5 / 9 and 10 , while for non-voice usage it is basically 5 / 9 . Orientations corresponding to test conditions 2 , 4 , 6 − 8 and 11 are not observed. It is worthwhile to note that the model is not handling distributions with multiple maxima. V . C O N C L U S I O N S A N D F U T U R E W O R K In this paper we have shown how smart-phone sensors can be used to model a wireless device usage in real-life situations without the intervention of the experimenter . This information can hav e a profound repercussion on the design of better handsets, but also to improv e wireless network performance. Indeed, the proposed von Mises-Fisher directional distribu- tion provides a statistical model for the phone’ s orientation ov er the full sphere for different phone usage types , e.g., voice or non-voice services used in combination with wired or Bluetooth handsfree connection or a speaker . Also different mixes of phone usage types can be studied and simulated based on their individual distributions by the finite mixture model approach. The heuristic weights of the mixture model are computed as the frequency of observ ation of data sam- ples belonging to the different phone usage types. Hence, statistical distributions describing phone usage types in voice and non-voice modes can be generated and incorporated, e.g., in Random-LOS O T A performance analysis, channel model generation and wireless network design and optimization. The model is based on analysing the acceleration (gra vity) vector data obtained from accelerometer sensor readings in real life. Ho wev er , the analysis of the data collected from the users may not be fully representativ e of the actual user- induced mobile phone orientation randomness since data is limited to 11 users so far . Howe ver , the number of users reporting their accelerometer data will increase in the future, e.g., by means of crowdsourcing. This will provide a more representativ e data set of the phone usage types and therefore improv e the randomness characterization of the users. Also, in future analysis more sophisticated data pre-processing (i.e., before the statistical parameters are estimated) will be needed in order to fine-tune the statistical models of the different phone usage types. F or example, the finite mixture model could be applied to each usage type separately to identify clustering ef fects that might have been gone unnoticed by removing duplicate data, i.e., the pre-processing approach we hav e used in our analysis. A P P E N D I X A Let χ ρ = { ρ 1 , . . . , ρ N } be a set of points drawn from f ( ρ ; µ , κ ) (3). The estimates ˆ µ and ˆ κ that maximize the log- likelihood function L ( χ ρ ; µ , κ ) = N ln κ 4 π sinh ( κ ) + N Õ i = 1 κ µ T ρ i , (8) subject to the condition that µ T µ = 1 and κ ≥ 0 are given by [17] ˆ µ = Í N i = 1 ρ i k Í N i = 1 ρ i k , (9) ˆ κ = A − 1 3 ( ¯ R ) , (10) where ¯ R = N − 1 k N Õ i = 1 ρ i k , (11) A 3 ( κ ) = I 3 / 2 ( κ )/ I 1 / 2 ( κ ) , (12) SUBMITTED TO JOURNAL 9 where I ν denotes the modified Bessel function of the first kind of order ν [25]. Hence, ˆ κ is the solution to A 3 ( κ ) − ¯ R = 0 , that is obtained numerically by the Newton’ s method κ 0 = ¯ R ( 3 − ¯ R 2 ) 1 − ¯ R , (13) κ k = κ k − 1 − A 3 ( κ k − 1 ) − ¯ R 1 − A 3 ( κ k − 1 ) 2 − 2 κ k − 1 A 3 ( κ k − 1 ) , (14) where κ 0 is the initial value and the iteration usually conv erges after two steps, and thus ˆ κ = κ 2 . R E F E R E N C E S [1] A. A. Glazunov , V . M. K olmonen, and T . Laitinen, “MIMO over-the- air testing, ” in LTE-Advanced and Next Generation W ireless Networks: Channel Modelling and Propagation , G. Roche, A. A. Glazunov , and B. Allen, Eds., Hoboken, NJ, USA: W iley , 2012, pp. 411–442. [2] P .-S. Kildal and K. Rosengren, “Correlation and capacity of MIMO systems and mutual coupling, radiation efficiency , and diversity gain of their antennas: Simulations and measurements in a reverberation chamber , ” IEEE Communications Magazine , vol. 42, no. 12, pp. 104– 112, December 2004. [3] P .-S. Kildal, C. Orlenius, and J. Carlsson, “O T A testing in multipath of antennas and wireless devices with MIMO and OFDM, ” Pr oceedings of the IEEE , vol. 100, no. 7, pp. 2145–2157, July 2012. [4] A. Razavi, A. A. Glazunov , P . S. Kildal, and J. Y ang, “Characterizing polarization-mimo antennas in random-los propagation channels, ” IEEE Access , vol. 4, pp. 10 067–10 075, 2016. [5] A. Razavi and A. A. Glazunov , “Probability of detection functions of polarization-mimo systems in random-los, ” IEEE Access , vol. 5, pp. 25 635–25 645, 2017. [6] E. Mellios, Z. Mansor , G. Hilton, A. Nix, and J. McGeehan, “Impact of antenna pattern and handset rotation on macro-cell and pico-cell prop- agation in heterogeneous L TE networks, ” in Antennas and Pr opagation Society International Symposium (APSURSI), 2012 IEEE , July 2012, pp. 1–2. [7] P .-S. Kildal, “Rethinking the wireless channel for O T A testing and network optimization by including user statistics: RIMP, pure-LOS, throughput and detection probability , ” in International Symposium On Antennas And Propa gation (ISAP), , vol. 1, Oct 2013, pp. 1–9. [8] P .-S. Kildal and J. Carlsson, “New approach to O T A testing: RIMP and pure-LOS reference environments and a hypothesis, ” in 7th European Confer ence on Antennas and Propagation (EuCAP) , April 2013, pp. 315–318. [9] P .-S. Kildal, A. Glazunov , J. Carlsson, and A. Majidzadeh, “Cost- effecti ve measurement setups for testing wireless communication to vehicles in reverberation chambers and anechoic chambers, ” in 2014 IEEE Conference on Antenna Measurements Applications (CAMA) , Nov 2014, pp. 1–4. [10] P . H. Lehne, K. Mahmood, A. A. Glazunov , P . Grønsund, and P .-S. Kildal, “Measuring user-induced randomness to evaluate smart phone performance in real en vironments, ” in 9th Eur opean Confer ence on Antennas and Propa gation (EuCAP) , April 2015, pp. 1–5. [11] P . H. Lehne, A. A. Glazunov , K. Mahmood, and P .-S. Kildal, “ Analyzing smart phones’ 3d accelerometer measurements to identify typical usage positions in voice mode, ” in 10th Eur opean Conference on Antennas and Pr opagation (EuCAP) , April 2016, pp. 1–5. [12] K. V . Mardia and P . E. Jupp, Dir ectional statistics . John Wile y & Sons, 2009, vol. 494. [13] “ Android sensor event, ” http://dev eloper .android.com/reference/android/ hardware/SensorEvent.html, accessed: 2015-10-13. [14] D. Mizell, “Using gravity to estimate accelerometer orientation, ” in W earable Computers, 2003. Pr oceedings. Seventh IEEE International Symposium on , Oct 2003, pp. 252–253. [15] J. Blum, D. Greencorn, and J. Cooperstock, “Smartphone sensor reli- ability for augmented reality applications, ” in Mobile and Ubiquitous Systems: Computing, Networking, and Services, ser . Lecture Notes of the Institute for Computer Sciences, Social Informatics and T elecommu- nications Engineering, K. Zheng, M. Li, and H. Jiang, Eds. Springer Berlin Heidelberg, 2013, vol. 120, pp. 127–138. [Online]. A vailable: http://dx.doi.org/10.1007/978- 3- 642- 40238- 8_11 [16] Z. Ma, Y . Qiao, B. Lee, and E. Fallon, “Experimental ev aluation of mobile phone sensors, ” in Signals and Systems Confer ence (ISSC 2013), 24th IET Irish , June 2013, pp. 1–8. [17] S. Sra, “ A short note on parameter approximation for von mises- fisher distributions: and a fast implementation of ß s ( x ) , ” Computational Statistics , vol. 27, no. 1, pp. 177–190, 2012. [18] A. T . W ood, “Simulation of the von mises fisher distribution, ” Com- munications in Statistics - Simulation and Computation , vol. 23, no. 1, pp. 157–164, 1994. [Online]. A vailable: http://dx.doi.org/10.1080/ 03610919408813161 [19] http://www .mathworks.com/matlabcentral/fileexchange/ 52398- sphericaldistributionsrand. [20] C. Ley , C. Sabbah, and T . V erdebout, “ A new concept of quantiles for directional data and the angular mahalanobis depth, ” Electron. J . Statist. , vol. 8, no. 1, pp. 795–816, 2014. [Online]. A vailable: http://dx.doi.org/ 10.1214/14- EJS904 [21] T echnical Specification Group Radio Access Network; Universal T er- r estrial Radio Access (UTRA) and Evolved Universal T errestrial Radio Access (E-UTRA); V erification of radiated multi-antenna r eception per- formance of User Equipment (UE) (Release 14) , 3GPP Std. 3GPP TR 37.977 V14.2.0, Dec. 2016. [22] G. McLachlan and D. Peel, Finite mixture models . John Wiley & Sons, 2004. [23] D. P . Kroese, T . T aimre, and Z. I. Botev , Handbook of Monte Carlo Methods . John Wile y & Sons, 2013, vol. 706. [24] T est Plan for 2x2 Downlink MIMO and T ransmit Diversity Over-the- Air-P erformance , CTIA Std. V ersion 1.1, Aug. 2016. [25] I. S. Gradshteyn and I. M. Ryzhik, T able of inte grals, series, and pr oducts . Associated Press, 6th ed., 2000.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment