Dialogue Learning with Human Teaching and Feedback in End-to-End Trainable Task-Oriented Dialogue Systems
In this work, we present a hybrid learning method for training task-oriented dialogue systems through online user interactions. Popular methods for learning task-oriented dialogues include applying reinforcement learning with user feedback on supervised pre-training models. Efficiency of such learning method may suffer from the mismatch of dialogue state distribution between offline training and online interactive learning stages. To address this challenge, we propose a hybrid imitation and reinforcement learning method, with which a dialogue agent can effectively learn from its interaction with users by learning from human teaching and feedback. We design a neural network based task-oriented dialogue agent that can be optimized end-to-end with the proposed learning method. Experimental results show that our end-to-end dialogue agent can learn effectively from the mistake it makes via imitation learning from user teaching. Applying reinforcement learning with user feedback after the imitation learning stage further improves the agent’s capability in successfully completing a task.
💡 Research Summary
This paper addresses two persistent challenges in task‑oriented dialogue systems: (1) the error propagation inherent in modular pipeline architectures, and (2) the distribution mismatch that arises when a model pretrained on static corpora is deployed for online interaction. To mitigate these issues, the authors propose a hybrid learning framework that combines imitation learning through human teaching with reinforcement learning (RL) based on simple binary feedback.
The system architecture is fully end‑to‑end and consists of six main components: (i) a bidirectional LSTM utterance encoder that transforms each user turn into a continuous vector; (ii) a dialogue‑level LSTM that updates a latent dialogue state sₖ using the current utterance encoding and the previous system action; (iii) a slot‑tracking module that, given sₖ, produces a probability distribution over candidate values for each goal slot via a single‑layer MLP with softmax; (iv) a symbolic knowledge‑base (KB) query generator that fills a predefined API template with the most probable slot values and receives a summarized result (e.g., number of matches, availability); (v) a policy network that takes as input the latent state sₖ, the log‑probabilities of slot candidates vₖ, and the KB result encoding Eₖ, and outputs a distribution over system actions; and (vi) a template‑based natural language generator that renders the selected action into a user‑facing response. All components are differentiable, allowing joint optimization.
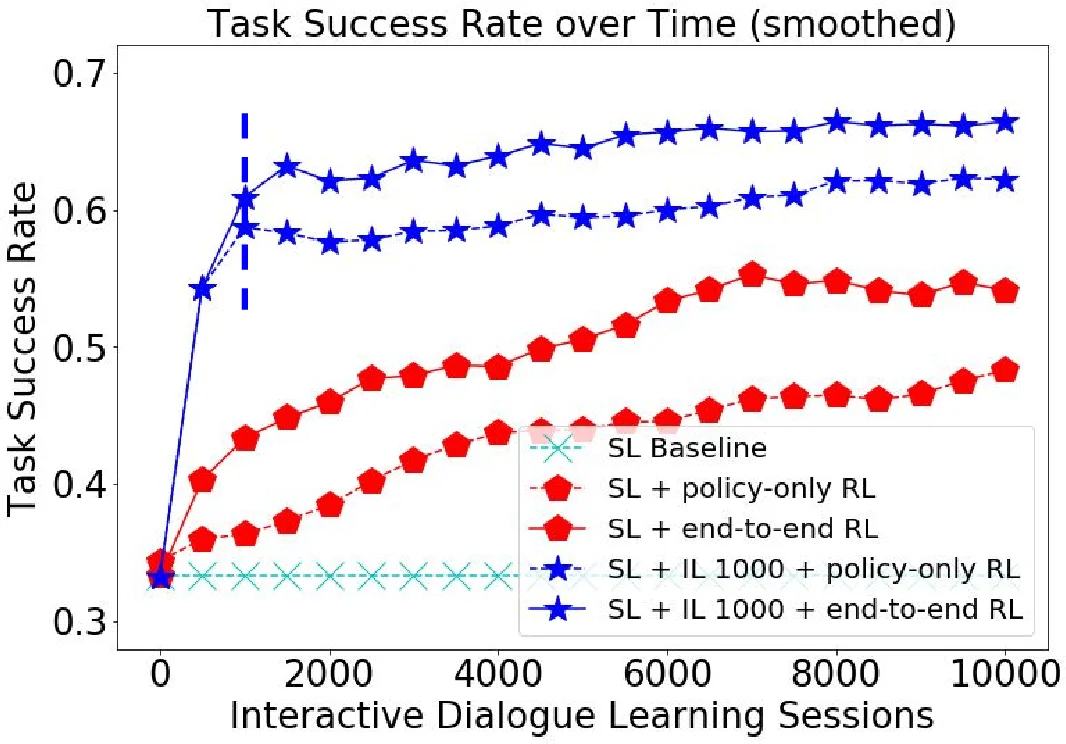
Training proceeds in three stages. First, supervised pre‑training uses a large corpus of annotated dialogues. The loss is a weighted sum of cross‑entropy terms for slot prediction and action prediction, enabling the model to learn a reasonable initial policy πθ(a|s). Second, the model engages in interactive dialogues with real users. Whenever the agent makes an error (e.g., predicts an incorrect slot value or selects an inappropriate action), the user provides a correction—explicitly demonstrating the correct slot values and the appropriate system action for that turn. These corrected turns are aggregated into the training set (DAgger‑style) and the model is re‑trained on the expanded dataset. This imitation learning phase dramatically expands the state coverage, allowing the agent to recover from rare or unseen states that would otherwise cause cascading failures. Third, after a sufficient number of teaching cycles, the system switches to a lightweight RL phase. At the end of each dialogue the user supplies a binary success/failure signal, which is incorporated into a reward function that also penalizes long dialogues. Policy gradients (e.g., REINFORCE) are then used to fine‑tune πθ, improving overall task success without requiring further detailed annotations.
Experimental evaluation is conducted on two domains (movie ticket booking and restaurant reservation). Metrics include slot‑accuracy, action‑accuracy, and overall task success rate. Results show that the imitation‑learning stage alone raises slot‑accuracy by roughly 12 % and action‑accuracy by about 9 % compared to the baseline pretrained model, indicating that human teaching effectively repairs the distribution shift. Adding the RL fine‑tuning yields an additional 5–10 % boost in task success and reduces average dialogue length by about 1.2 turns, demonstrating that sparse binary feedback can still refine the policy after the state space has been adequately explored.
Key contributions are: (1) a novel hybrid learning paradigm that leverages human teaching to bridge the offline‑online distribution gap; (2) an end‑to‑end differentiable architecture that jointly learns NLU, belief tracking, policy, and response generation, eliminating the need for hand‑crafted interfaces between modules; (3) empirical evidence that a small amount of human correction, followed by lightweight RL, yields substantial performance gains while keeping annotation costs low.
Limitations include reliance on template‑based NLG, which restricts linguistic variability, and the practical requirement of an interface for real‑time human teaching in deployment settings. Future work is suggested to explore neural generation methods for more natural responses and to develop automated suggestion mechanisms that further reduce the burden on human teachers.
Comments & Academic Discussion
Loading comments...
Leave a Comment