Global SNR Estimation of Speech Signals using Entropy and Uncertainty Estimates from Dropout Networks
This paper demonstrates two novel methods to estimate the global SNR of speech signals. In both methods, Deep Neural Network-Hidden Markov Model (DNN-HMM) acoustic model used in speech recognition systems is leveraged for the additional task of SNR e…
Authors: Rohith Aralikatti, Dilip Margam, Tanay Sharma
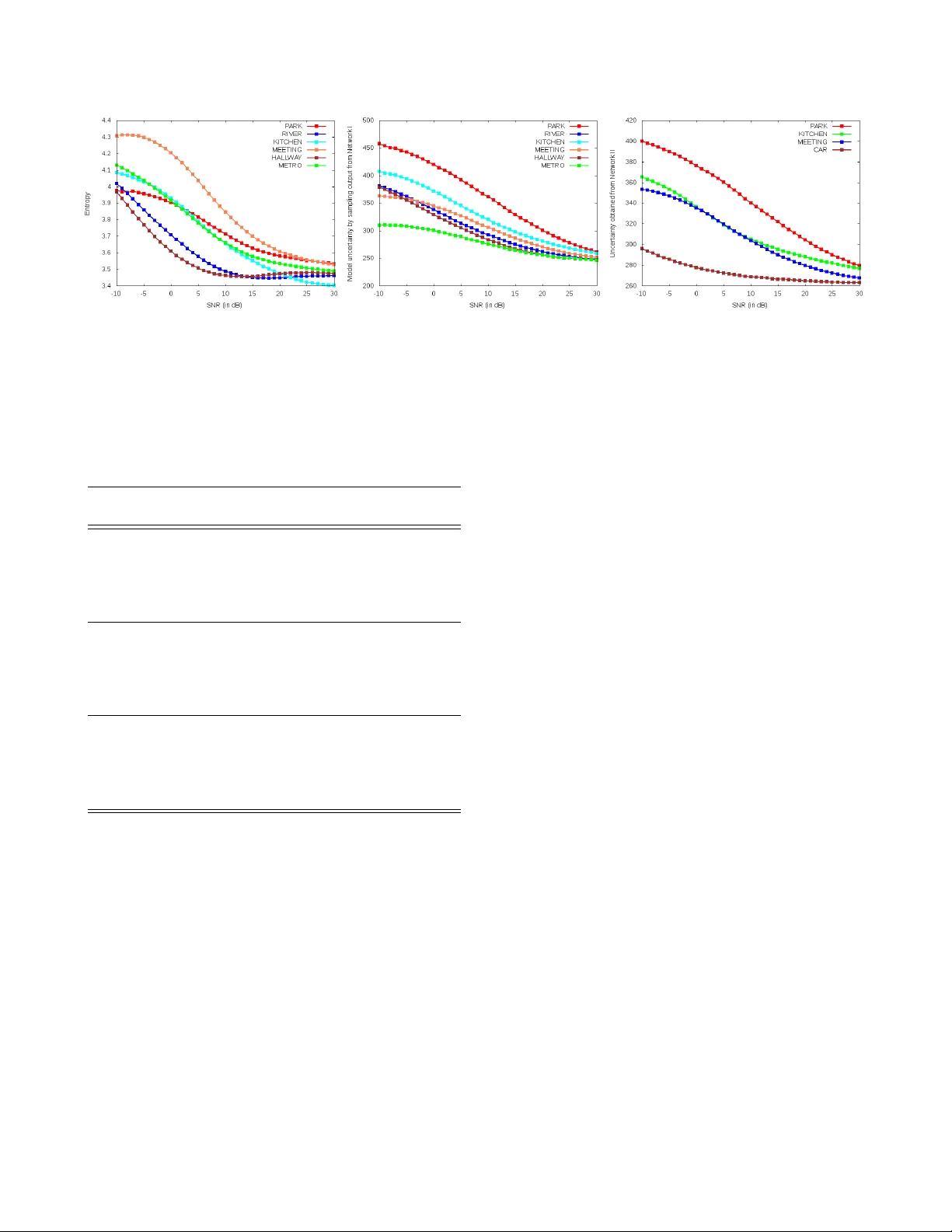
GLOB AL SNR ESTIMA TION OF SPEECH SIGNALS USING ENTR OPY AND UNCER T AINTY ESTIMA TES FR OM DR OPOUT NETWORKS Rohith Aralikatti, Dilip K umar Mar gam, T anay Sharma, Abhinav Thanda, Shankar M V enkatesan Samsung R&D Institute India, Bangalore { r .aralikatti,dilip.margam,tanay .sharma,abhinav .t89,s.v enkatesan } @samsung.com ABSTRA CT This paper demonstrates two no vel methods to estimate the global SNR of speech signals. In both methods, Deep Neural Network-Hidden Marko v Model (DNN-HMM) acous- tic model used in speech recognition systems is le veraged for the additional task of SNR estimation. In the first method, the entrop y of the DNN-HMM output is computed. Recent work on bayesian deep learning has shown that a DNN-HMM trained with dropout can be used to estimate model uncer- tainty by approximating it as a deep Gaussian process. In the second method, this approximation is used to obtain model uncertainty estimates. Noise specific regressors are used to predict the SNR from the entrop y and model uncertainty . The DNN-HMM is trained on GRID corpus and tested on dif fer - ent noise profiles from the DEMAND noise database at SNR lev els ranging from -10 dB to 30 dB. Index T erms — SNR Estimation, Dropout, Entropy , Deep Neural Networks 1. INTR ODUCTION Signal-to-noise ratio (SNR) estimation of a signal is an im- portant step in many speech processing techniques such as robust automatic speech recognition (ASR) ([1, 2]), speech enhancement ([3, 4]), noise supression and speech detection. The global signal-to-noise ratio (SNR) of a signal x ( t ) in dB is defined as follows. S N R dB ( x ) = 10 log 10 P ow er ( s ) P ow er ( n ) The signal x ( t ) = s ( t ) + n ( t ) where s ( t ) represents the clean signal and n ( t ) is the noise component. State-of-the-art ASR has achieved very low error rates with the advent of deep learning. Howe ver , performance of ASR systems can still be improv ed in noisy conditions. Ro- bust ASR techniques such as noise-aware training [1] and re- lated methods ([5],[2]) require an estimate of the noise present in the speech signal. Recently , it has been shown that incorporating visual fea- tures (extracted from lip movements during speech) can lead to improved word error rates (WER) during noisy en viron- ment ([6],[7]). In [8], both audio and visual modalities are used for speech enhancement. W ith the proliferation of voice assistants and front facing cameras in smartphones, using vi- sual features to improve ASR seems feasible. This raises the crucial question - when should the camera be turned on to make use of features from the visual modality? In such sce- narios, we can benefit from accurate SNR estimation by turn- ing on the camera in noisy en vironments. In this paper, we present two novel methods to estimate the global SNR (at an utterance lev el) of a speech signal. Both methods require training a DNN based speech classifier on noise free audio using alignments generated from a GMM- HMM model trained for ASR. The first method estimates SNR by computing the entropy of the DNN’ s output. The second method uses model uncertainty estimates obtained by using dropout during inference as shown in [9]. In section 2, we present related work that has been done. Section 3 de- scribes the entropy based SNR estimator . Section 4 describes the dropout based SNR estimator . Section 5 describes the ar- chitecture of the network, the training procedure and the ex- periments done. Section 6 presents the results of the paper . The final section 7 has the conclusion. 2. RELA TED WORK SNR estimation has been an active area of research. In [10], the authors use specific handcrafted features such as signal energy , signal v ariability , pitch and voicing probability to train noise specific regressors that compute SNR of an input signal. In [11], the amplitude of clean speech is modelled by a gamma distribution and noise is assumed to be normally distributed. SNR is estimated by observing changes to the parameters of the gamma distribution upon addition of noise. The NIST -SNR measurement tool uses a sequential GMM to model the speech and non-speech parts of a signal to esti- mate the SNR. In [12], a v oice activity detector (V AD) is used to classify frames as either voiced, unv oiced or silence and the noise spectrum is estimated from this information. After sub- tracting the noise spectrum from the input signal to obtain the clean signal, SNR is estimated. In [13], computational audi- tory scene analysis is used to estimate speech dominated and noise dominated portions of the signal in order to obtain SNR. Estimation of instantaneous SNR is also a subtask in many speech enhancement methods ([8, 14, 15, 16]). In [17], a neural network is trained to output the SNR in each frequency channel using amplitude modulation spectrogram (AMS) features which are obtained from the input signal. In [18], the peaks and valleys of the smoothened short time power estimate of a signal are used to estimate the noise power and instantaneous SNR. 3. ENTR OPY B ASED SNR ESTIMA TION In this method, a neural network which is trained as a part of ASR system to predict the posterior distribution of HMM states is used. The Shannon entropy of the posterior distribu- tion is computed. In information theory , Shannon entropy is realisation of the average uncertainity of encoding machine. Similarly in our case the posterior distribution obtained from DNN which is trained as a part of ASR system, acts as an encoding distribution for encoding machine. Whenev er the feature vector of clean signal is forwarded through DNN it is expected to giv e meaningful posterior distribution. But when a feature vector of a noisy signal is forwarded through the neural network, the posteriors are expected to be arbitrary , which in most cases lead to higher entropy value. This comes from the assumption that addition of noise to the speech sig- nal results in arbitrary features. Let F i denote the i th input frame of utterance U and Y (of dimension d ) denote the output of DNN. The entropy for giv en input F j is computed as shown in equation 1. H ( F j ) = − d X i =0 P [ Y i ] log P [ Y i ] (1) Entr opy ( U ) = m X i =0 H ( F i ) m (2) S N R ( U ) = f 1 ( E ntr opy ( U )) (3) Where P [ . ] denotes softmax activ ation, Y i is i th dimen- sion of Y . The average entropy of all input frames for a giv en utterance is used as a measure of the entropy for an utterance. A polynomial regressor f 1 ( . ) is trained on utter- ance lev el entropy values to predict the SNR of speech sig- nal. The advantage of this method is that it can work on any kind of noise which can randomize the speech signal. The DNN-HMM based ASR systems which are sensitiv e to noisy conditions, can take advantage of entropy values to estimate the SNR with low computational ov erhead. In figure 1, it is clearly seen that with increase in noise, the average entropy increases. 4. SNR ESTIMA TION USING DR OPOUT UNCER T AINTY 4.1. Bayesian uncertainty using dropout Gal and Ghahramani showed in [9] that the use of dropout while training DNNs can be thought of as a bayesian approx- imation of a deep Gaussian process (GP). Using the abov e GP approximation, estimates for the model uncertainty of DNNs trained using dropout are derived. More specifically , it is shown that uncertainty of the DNN output for a giv en input can be approximated by computing the variance of multiple output samples obtained by using dropout during inference. The use of dropout during inference, results in different out- put every time the forward pass is done, for a giv en input. The variance of these output samples is the uncertainty for the giv en input. The above method is used to obtain uncertainty estimates for the DNN that was trained as a part of DNN-HMM based ASR system as explained in section 6. This DNN is referred as dropout network through out this paper . If the input is cor- rupted by noise, it is expected that the model uncertainty de- riv ed from dropout will be higher . The model uncertainty for giv en input F j is computed as shown in equation 4. M U ( F ) = d X i =0 V ar [ Y i ] (4) uncer tainty ( U ) = m X i =0 M U ( F i ) m (5) S N R ( U ) = f 2 ( uncer tainty ( U )) (6) S N R ( U ) = f 3 ( uncer tainty ( U ) , E ntr opy ( U )) (7) Where M U stands for model uncertainty per frame. The av- erage variance over all input frames is used as a measure of uncertanity for an utterance. The SNR of the utterance is es- timated as shown in equation 6, where f 2 ( . ) is polynomial regressor trained to predict SNR from uncertainty value. The the regressor f 3 ( . ) is trained on both uncertainty and entropy of utterance to output SNR value. W e ha ve compared the per - formance of all three regressors in table 1. 4.2. Fast dropout uncertainty estimation It may not alw ays be feasible to run the forward pass multiple times per input frame in order to obtain output samples. Given the input frame and the weights of the dropout network, it should be possible to algebraically deri ve the variance and expectation of the output layer . The uncertainty of the model is the consequence of un- certainty added because of dropout in each layer of network. Follo wing equations depicts how the uncertainity of model can be computed mathematically . For mathematical simplic- ity let us consider the neural network with one layer . The output of the one layer network with ReLU activ ation func- tion is: Y = ReLU ( W · ( D ◦ F ) + b ) . Where ◦ denotes hadamard product, D denotes the dropout mask. The vari- ance of i th dimension of output is giv en as sho wn in equation 8. V ar [ Y i ] = V ar [ ReLU ( W T i ( D ◦ F ) + b ))] = V ar [ R eLU ( m − 1 X j =0 W ij D j F j )] (8) = V ar [ R eLU ( A i )] Where A i = P m − 1 j =0 W ij D j F j . W i denote i th row of matrix W , m is the dimension of F . The dropout variable D i being a bernoulli v ariable with probability of success p , V ar [ D i ] = p (1 − p ) . V ar [ A i ] = m − 1 X j =0 W 2 ij F 2 j V ar [ D j ] = p (1 − p ) m − 1 X j =0 W 2 ij F 2 j (9) Since all the dropout bernoulli random v ariables are indepen- dent of one another , the equation 9 follows. The dif ficulty comes in computing the V ar [ Y i ] because it inv olves a non- linear ( R elu ) activ ation function. T o compute the V ar [ Y i ] one has to integrate the Y i s over all possible dropout distrib u- tions ( 2 m possibilities), which will increase the computational complexity . One can proceed from here using the T aylor first order approximation of m variables. In [19] it is assumed that sum of activ ation values follows normal distribution fol- lowing the central limit theorem, but this assumption did not hold good empirically in our case because of multiple layers in network. Howe ver , the variance of the output is some comple x non- linear function of the input and the dropout network weights. Therefore it must be possible to train another DNN to learn this non-linear relationship so that the uncertainty can be es- timated by a single forward pass of this second network. This second neural network from now on will be referred to as the variance network in this paper . The variance network ex- plained in section 5.1.1 w as able to succesfully learn the map- ping from the input frame to the output (dropout uncertainty), as shown in the figure 3. 5. EXPERIMENTS A DNN-HMM based ASR system is trained on the Grid cor- pus [20] ( 95% of it is used for training, 5% for testing), which has 34 speakers and 1000 utterances per speaker . The Mel scale filter-bank features of 40 dimension, with 5 contextual frames on both sides are used as input features. The dura- tion of 25 ms and shift of 10 ms is used in feature extraction process. The activ ation function used is ReLU, along with dropout with p = 0 . 2 ( p is probability of dropping a neuron) is used in all hidden layers. The output of DNN is of dimen- sion 1415 corresponding to number of HMM states. There are six hidden layers with 1024 neurons in each layer . This DNN which is also reffered to as dropout network in this paper is used for estimating entropy and variance in all our experi- ments, except for section 4.2. 5.1. Entropy method and dropout uncertainty method W e experimented on 16 different noise types from the DE- MAND noise dataset, where noise is added to the test set of utterances. W e observe that there is a strong correlation be- tween a verage entropy and SNR as shown in figure 1. Similar kind of results for av erage dropout uncertainty estimates ver- sus the SNR are obtained, where model uncertainty increases with increase in noise as shown in the figure 2. The variance has been computed by taking 100 output samples per input frame, but we obtained similar results when we reduced the number of samples to 20 per input frame. Figure 2 shows the variation in model uncertainty with respect to SNR for same six arbitrarily chosen noises as in figure 1. The variance computation was done on the output samples obtained from the DNN before the application of softmax to obtain probabilities. This gave better results, since the soft- max function tends to exponentially squash the outputs to lie between 0 and 1 and this causes the variance along many of the dimensions of the output to be ignored. Using the ReLU non-linearity also gav e better results as compared to the sigmoid and tanh non-linearity . This is ex- pected, as both the sigmoid and tanh tend to saturate and this does not allo w the variance (or model uncertainty) to be prop- agated to the output layer . 5.1.1. V ariance network (fast dr opout uncertainty estima- tion) This is the network used for fast dropout uncertainty estima- tion. The variance network is trained on uncertainty estimates obtained from the dropout network. The training is done on utterances from the GRID corpus mixed with noise from the DEMAND [21] dataset using the previously trained dropout network. The training is done on utterances mixed with 12 types of noise at 40 dif ferent SNR levels (from -10 dB to 30 dB). The testing is done on different utterances from the GRID corpus mixed with noise samples not exposed to the network during training. V ariance network is able to succesfully learn the mapping from the input frame to the output uncertainty . The plots shown in the figure 3 shows the variation of output uncer- tainty for the four types of noise (CAR, P ARK, KITCHEN, MEETING) which were not used during training. 6. RESUL TS T o obtain the SNR of an input signal, we have trained noise specific linear regressors to obtain the SNR value given the Fig. 1 . Plot depicts the relationship between av eraged entropy of utterance (defined in equa- tion 2) with SNR v alue of utterance for test ut- terances for six arbitrarily chosen noise types. Fig. 2 . Figure shows the relationship between av eraged uncertainity of utterance (as in equa- tion 5) and SNR value of utterance for test ut- terances for six arbitrarily chosen noise types. Fig. 3 . Figure shows the relationship between output of variance network and noisy input speech with different SNR values for four un- seen (not used in training) noises. T able 1 . The Mean Absolute Error (MAE) of our SNR esti- mation methods is compared against pre-existing methods Noise Method SNR (dB) type -10 -5 0 5 10 DKITCHEN NIST 15.55 10.58 6.66 5.08 4.73 W AD A 9.34 5.35 1.31 0.93 0.67 f 1 8.67 8.48 7.98 6.93 7.44 f 2 2.58 2.06 2.73 3.37 2.7 f 3 3.08 2.85 3.57 4.34 4.02 NP ARK NIST 17.32 12.64 8.71 6.94 6.91 W AD A 7.83 4.13 2.31 1.89 2.25 f 1 7.06 6.22 5.01 4.38 4.44 f 2 2.34 2.01 1.86 1.62 1.28 f 3 2.43 2.11 1.9 1.61 1.35 OMEETING NIST 17.25 12.97 10.46 9.26 11.3 W AD A 12.11 8.44 6.61 6.08 6.39 f 1 4.51 2.54 3.17 3.69 4.28 f 2 1.98 1.46 1.79 1.98 1.95 f 3 2.32 1.24 1.68 2.12 2.12 uncertainty obtained from variance network and/or entropy . The mean-absolute-error (MAE) for three different types of noise at different SNR le vels are shown in T able 1. W e hav e compared the result of the three re gressors ( f 1 , f 2 and f 3 ) described previously with well known SNR estima- tion methods, namely the NIST STNR estimation tool and the W ADA SNR estimation method described in [12]. It is observed that the re gressor trained on dropout uncertainty per- formed better than the entropy based regressor . Indeed, it is observed that the regressor trained on both the dropout un- certainty and entropy perfomed worse than just re gressing on the network uncertainty . Ho we ver , all three regressors have produced better SNR estimates than either W AD A or NIST , partiicularly at low SNR le vels. Though we clearly see a correlation between the en- tropy/dropout uncertainty and the noise in the signal, to finally obtain the SNR value of the signal we have to train a noise specific regressor on top of the entropy/dropout un- certainty values. The possibility of directly predicting SNR independent of the background noise is something that needs further research. In [10], the authors propose using a DNN to find out which of the noise types most closely resemble the input and use the corresponding regressor to estimate SNR. Howe ver , since dropout netw ork is trained on clean audio, irrespectiv e of the type of noise in the speech signal, the trend of increasing uncertainty with increasing noise did hold ev en in unseen noise conditions. The variance network, which is trained on specific noise types in order to av oid the computa- tional costs of taking samples during inference, clearly main- tained this trend even in unseen noise conditions as shown in figure 3 7. CONCLUSION In this paper , we hav e sho wn that it is possible to extract use- ful information from the uncertainty (either from entropy or from bayesian estimates) and predict the SNR of a speech signal. Pre vious research in deep learning based speech pro- cessing has not made use of uncertainty information to the best knowledge of the authors. Using the above uncertainty information to better design and improv e the performance of current ASR and speech enhancement algorithms will be pos- sible future directions of research. Another possible improve- ment that can be done is to in vestigate the possibility of pre- dicting instantaneous SNR instead of global SNR. The meth- ods proposed in this paper for SNR estimation do not impose any conditions on the type of noise corrupting the signal. This leav es open the possibility of applying similar noise estima- tion techniques to non-speech signals. 8. REFERENCES [1] Michael L Seltzer , Dong Y u, and Y ongqiang W ang, “ An in vestigation of deep neural networks for noise robust speech recognition, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2013 IEEE International Confer- ence on . IEEE, 2013, pp. 7398–7402. [2] Kang Hyun Lee, Shin Jae Kang, W oo Hyun Kang, and Nam Soo Kim, “T wo-stage noise aware training using asymmetric deep denoising autoencoder, ” in Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE In- ternational Confer ence on . IEEE, 2016, pp. 5765–5769. [3] Y ariv Ephraim and David Malah, “Speech enhance- ment using a minimum mean-square error log-spectral amplitude estimator , ” IEEE T ransactions on Acoustics, Speech, and Signal Pr ocessing , vol. 33, no. 2, pp. 443– 445, 1985. [4] Elias Nemer, Rafik Goubran, and Samy Mahmoud, “Snr estimation of speech signals using subbands and fourth- order statistics, ” IEEE Signal Pr ocessing Letters , v ol. 6, no. 7, pp. 171–174, 1999. [5] Y ong Xu, Jun Du, Li-Rong Dai, and Chin-Hui Lee, “Dynamic noise a ware training for speech enhancement based on deep neural networks, ” in F ifteenth Annual Confer ence of the International Speech Communication Association , 2014. [6] Abhinav Thanda and Shankar M V enkatesan, “Multi- task learning of deep neural networks for audio vi- sual automatic speech recognition, ” arXiv preprint arXiv:1701.02477 , 2017. [7] Abhinav Thanda and Shankar M V enkatesan, “ Audio visual speech recognition using deep recurrent neural networks, ” in IAPR W orkshop on Multimodal P attern Recognition of Social Signals in Human-Computer In- teraction . Springer , 2016, pp. 98–109. [8] Pascal Scalart et al., “Speech enhancement based on a priori signal to noise estimation, ” in Acoustics, Speech, and Signal Pr ocessing, 1996. ICASSP-96. Conference Pr oceedings., 1996 IEEE International Confer ence on . IEEE, 1996, vol. 2, pp. 629–632. [9] Y arin Gal and Zoubin Ghahramani, “Dropout as a bayesian approximation: Representing model uncer- tainty in deep learning, ” in international confer ence on machine learning , 2016, pp. 1050–1059. [10] Pa vlos Papadopoulos, Andreas Tsiartas, and Shrikanth Narayanan, “Long-term snr estimation of speech signals in known and unknown channel conditions, ” IEEE/ACM T ransactions on Audio, Speech, and Language Process- ing , vol. 24, no. 12, pp. 2495–2506, 2016. [11] Chanwoo Kim and Richard M Stern, “Robust signal- to-noise ratio estimation based on waveform amplitude distribution analysis, ” in Ninth Annual Conference of the International Speech Communication Association , 2008. [12] Juan A Morales-Cordovilla, Ning Ma, V ictoria S ´ anchez, Jos ´ e L Carmona, Antonio M Peinado, and Jon Barker , “ A pitch based noise estimation technique for rob ust speech recognition with missing data, ” in Acoustics, Speech and Signal Processing (ICASSP), 2011 IEEE In- ternational Confer ence on . IEEE, 2011, pp. 4808–4811. [13] Arun Narayanan and DeLiang W ang, “ A casa-based sys- tem for long-term snr estimation, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 20, no. 9, pp. 2518–2527, 2012. [14] Jinkyu Lee, Keulbit Kim, Turaj Shabestary , and Hong- Goo Kang, “Deep bi-directional long short-term mem- ory based speech enhancement for wind noise reduc- tion, ” in Hands-free Speech Communications and Mi- cr ophone Arrays (HSCMA), 2017 . IEEE, 2017, pp. 41– 45. [15] Israel Cohen, “Relaxed statistical model for speech en- hancement and a priori snr estimation, ” IEEE T ransac- tions on Speech and Audio Processing , vol. 13, no. 5, pp. 870–881, 2005. [16] Y ao Ren and Michael T Johnson, “ An improved snr es- timator for speech enhancement, ” in Acoustics, Speech and Signal Pr ocessing, 2008. ICASSP 2008. IEEE Inter- national Confer ence on . IEEE, 2008, pp. 4901–4904. [17] J ¨ urgen Tchorz and Birger K ollmeier , “Snr estimation based on amplitude modulation analysis with applica- tions to noise suppression, ” IEEE T ransactions on Speech and Audio Pr ocessing , vol. 11, no. 3, pp. 184– 192, 2003. [18] Rainer Martin, “ An efficient algorithm to estimate the instantaneous snr of speech signals., ” in Eur ospeech , 1993, vol. 93, pp. 1093–1096. [19] Sida W ang and Christopher Manning, “Fast dropout training, ” in Pr oceedings of the 30th International Con- fer ence on Machine Learning (ICML-13) , 2013, pp. 118–126. [20] Martin Cooke, Jon Barker , Stuart Cunningham, and Xu Shao, “ An audio-visual corpus for speech percep- tion and automatic speech recognition, ” The Journal of the Acoustical Society of America , vol. 120, no. 5, pp. 2421–2424, 2006. [21] J Thiemann, N Ito, and E V incent, “Demand: Diverse en vironments multichannel acoustic noise database (2013), ” .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment