Qualitative Judgement of Research Impact: Domain Taxonomy as a Fundamental Framework for Judgement of the Quality of Research
The appeal of metric evaluation of research impact has attracted considerable interest in recent times. Although the public at large and administrative bodies are much interested in the idea, scientists and other researchers are much more cautious, i…
Authors: Fionn Murtagh, Michael Orlov, Boris Mirkin
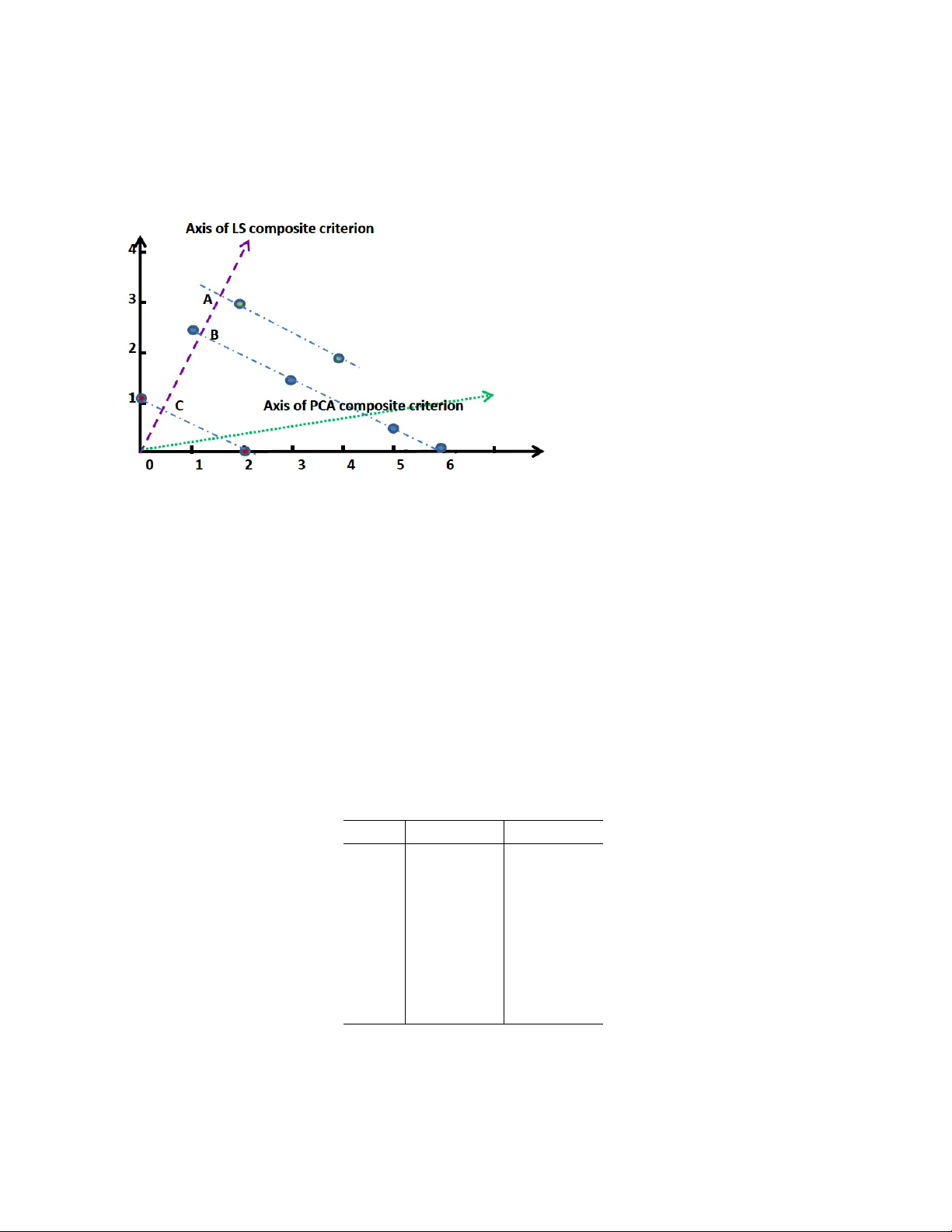
Qualitati v e Judgement of Research Impact: Domain T axonomy as a Fundamental Frame work for Judgement of the Quality of Research Fionn Murtagh (1), Michael Orlov (2), Boris Mirkin (2, 3) (1) School of Computing and Engineering, Uni versity of Huddersfield, UK (2) Department of Data Analysis and Machine Intelligence, National Research Uni versity Higher School of Economics, Mosco w , Russia (3) School of Computer Science and Information Systems, Birkbeck, Uni versity of London, UK Email: fmurtagh@acm.or g Abstract The appeal of metric e v aluation of research impact has attracted considerable interest in recent times. Although the public at large and administrati ve bodies are much interested in the idea, scientists and other researchers are much more cautious, insisting that metrics are but an auxiliary instrument to the qualitati ve peer-based judgement. The goal of this article is to propose a vailing of such a well positioned construct as domain taxonomy as a tool for directly assessing the scope and quality of research. W e first sho w how taxonomies can be used to analyse the scope and perspectiv es of a set of research projects or papers. Then we proceed to define a research team or researcher’ s rank by those nodes in the hierarchy that hav e been created or significantly transformed by the results of the researcher . An e xperimental test of the approach in the data analysis domain is described. Although the concept of taxonomy seems rather simplistic to describe all the richness of a research domain, its changes and use can be made transparent and subject to open discussions. K eywords: research impact, scientometrics, stratification, rank aggregation, multicriteria de- cision making, semantic analysis, taxonomy 1 Intr oduction: The Pr oblem and Backgr ound This article constructi vely supports the vie w expressed in the Leiden Manifesto (Hicks et al., 2015), as well as other recent documents such as DORA (Dora, 2013) and Metrics Tide Report (Metric T ide, 2016). All of these adv ance the principle that assessment of research impact should be made primarily according to qualitati ve judgment rather than by using citation and similar metrics. It may be maintained, due to the lack of comprehensive recording of process, that the traditional 1 org anisation of qualitati ve judgment via closed committees is prone to bias, mismanagement and corruption. In this work, it is proposed to use domain taxonomies for dev elopment of open, trans- parent and unbiased frame works for qualitativ e judgments. In this article, the usefulness of this principled approach is illustrated by , first, the issue of context based mapping and, second, the issue of assessment of quality of research. W e propose the direct ev aluation of the quality of research, and this principled approach is innov ati ve. W e also demonstrate how it can be deployed by using that part of the hierarchy of the popular A CM Classification of Computer Subjects (A CM, 2016) that relates to data analysis, machine learning and data mining. W e define a researcher’ s rank by those nodes in the hierarchy that hav e been created or significantly transformed by the results of the researcher . The approach is experimentally tested by using a sample of leading scientists in the data analysis domain. The approach is univ ersal and can be applied by research communities in other domains. In part 1 of this work, starting with section 3, there is the engendering and refining of taxonomy . W e express it thus to indicate the strong conte xtual basis, and how one faces and addresses, policy and related requirements. In part 2 of this work, staring with section 5, ranking is at issue that accounts fully for both quantitati ve and qualitati ve performance outcomes. 2 Re view of Resear ch Impact Measurement and Critiques The issue of measuring research impact is attracting intense attention of scientists because metrics of research impact are being widely used by various administrativ e bodies and by public at large as easy-to-get shortcuts for assessment of comparati ve strengths among scientists, research centres, and uni versities. This is further boosted by the wide a vailability of digitalized data and, as well, by the fact that research now adays becomes a widespread activity . The number of citations and such deri vati ves as Hirsch index are produced by a number of organizations including the in ventors, currently Thomson Reuters (Thomson Reuters, 2016), Scopus and Google. There is increasing pressure to use these or similar index es in ev aluation and management of research. There hav e been a number of proposals to amend the index es, say , by using less extensi ve characteristics, such as centrality index es in the inter-citation graphs or by following only citations in the work of “lead scientists” (Aragn ´ on, 2013). Other proposals deny the usefulness of bibliometrics altogether; some propose e ven such alternativ e measures as the “careful socialization and selection of scholars, supplemented by periodic self-e valuations and aw ards” (Osterloh and Fre y , 2014), that is, a social- and behavioural-based, administrati ve, exemplary model. Other , more practical systems, such as the UK Research Assessment Exercise (RAE), now the REF , Research Excellence Framew ork), intends to assess most significant contributions only , and in a most informal way , which seems a better option. Ho wev er , there have been criticisms of the RAE-like systems as well: first, in the absence of a citation index, the peer revie ws are not necessarily consistent in ev aluations (Eisen et al., 2013), and, second, in the long run, the system itself seems some what short-sighted; it has cut off e verything which is out of the mainstream (Lee et al., 2013). There hav e been a number of recent initiativ es undertaken by scientists themselves such as the San-Francisco Declaration 2 DORA (Dora, 2013), Leiden Manifesto (Hicks et al., 2015), The Metrics T ide Report (Metric T ide, 2016). DORA, for example, emphasizes that research impact should be scored ov er all scientific production elements including data sets, patents, and codes among others (Dora, 2013). Altogether , these declarations and manifestos claim that citation and other metrics should be used as an auxiliary instrument only; the assessment of research quality should be based on “qualitati ve judgement” of the research portfolio (Hicks et al., 2015). Y et there is no clarity on the practical implementation of these recommendations. This article is a further step in this direction. Any unbiased consideration of metrics as well as of other systems for assessment of research impact (Eisen et al., 2013; Lee et al., 2013) leads to conclusions that “qualitativ e judgment” should be a preferred option (Dora, 2013; Hicks et al., 2015; Metric Tide, 2016). This article points out to the concept of domain taxonomy which should be used as a main tool in actual organization of assessment of research impact in general and quality of research, specifically . The remainder of this article is organized as follo ws. W e begin by briefly re viewing direct and straightforward application of domain taxonomy , for supporting qualitativ e judgement. Relating to the policy-related work of a national research funding agency , and to the editorial work of a journal, these preliminary studies were pioneering. The third section explains how a domain taxonomy can be used for assessing the quality of research. The fourth section provides an experiment in testing the approach empirically . The fifth section compares the taxonomic ranking of our sample of scientists with rankings ov er citation and merit. 3 Qualitativ e, Content-Based Mapping, into which the Quan- titativ e Indicators are Mapped In this section and in the next section, we develop taxonomies using sets of ke ywords or selected actionable terms. It is sought to be, potentially , fully data-driv en. Le vels of resolution in our tax- onomy can be easily formed through term aggre gation. Mapping the taxonomy , as a tree endo wed with an ultrametric, to a metric space, when using lev els of aggreg ation, provides an approach to having focus (in a general sense, orientation and direction) in the analytics. Here we gi ve a first e xample, in which the taxonomies were generated with the goal to pro vide a tool for open and unbiased qualitati ve judgment in such contexts as research publishing and research funding. Concept hierarchies can be established by domain experts, and deployed in such contexts as research publishing and research funding. A short re vie w was carried out of thematic ev olution of The Computer Journal, relating to 377 papers published between January 2000 through to September 2007. The construction of a concept hierarchy , or ontology , was “bootstrapped” from the published articles. The top level terms, child nodes of the concept tree root, were “Systems – Physical”, “Data and Information”, and “Systems – Logical”. Noted was that the category of “bioinformatics” did not require further concept child nodes. A limited set of sub-categories was used for “software engineering”, these 3 −1.0 −0.5 0.0 0.5 −1.0 −0.5 0.0 0.5 1.0 Factor 1, 61% of inertia Factor 2, 39% of inertia Phys Inf Log 5 6 4 2 3 1 7 0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Display of 377 articles, 3 thematic areas, 7 years Figure 1: Principal factor plane of Correspondence Analysis of 377 published articles (positions sho wn with dots, not all in this central region), crossed by three primary thematic areas. These are: Information and Data (Inf), Systems–Physical (Phys), and Systems–Logical (Log). The years of publication sho wn (0 = 2000, 1 = 2001, etc.), used as supplementary elements in the analysis. being “Design”, “Education”, and “Programming languages”. Under the top le vel category of “Data and information”, one of the eight child nodes was “Machine learning”, and one of its child nodes was “Plagiarism”. This was justified by the appropriateness of the contents of published work relating to plagiarism. Once the concept hierarchy was set up, the 377 published articles from the sev en years under in vestigation were classified, with mostly two of the taxonomy terms being used for a giv en article. There was a maximum of four taxonomy terms, and a minimum of one. T able 1 displays the concept hierarchy that was used at that time. A Correspondence Analysis of this data, here with a focus on the top level themes, presents an interesting and rev ealing vie w . A triangle pattern is to be seen, in Figure 1, where Inf is coun- terposed on the first factor to the two other , more traditional Computer Science themes. Factor 2 counterposes the physical and the logical in the set of published research work. The information displayed in Figure 1 comprises all information, that is the inertia of the cloud of publications, and of the cloud of these top le vel themes. The year of publication, as a supplementary attribute of the publications, is inactiv e in the factor space definition, and each is projected into the factor space. W e see the movement from year to year , in terms of the top lev el themes. There is further general discussion in Murtagh (2008). 4 1. Systems -- Physical 1.1. Architecture, Hardware 1.1.1. Networks, Mobile 1.1.2. Memory 1.2. Distributed Systems 1.2.1. System Modelling 1.2.2. Networks, Mobile 1.2.3. Grid, P2P 1.2.4. DS Algorithms 1.2.5. Semantic Web 1.2.6. Sensor Networks 1.3. Networks, Mobile 1.3.1. Mobile Computing 1.3.2. Networks 1.3.3. Search, Retrieval 1.4. Information Delivery 1.4.1. Energy 1.4.1.1. Photonics-based 1.4.1.2. Nano-based 1.4.2. Displays 1.4.3. Bio-Engineering Applications 1.4.4. Miscellaneous Applications of Materials 2. Data and Information 2.1. Storage 2.1.1. Databases 2.1.2. Graphics 2.1.3. Imaging, Video 2.1.4. Memory Algorithms 2.1.5. Non-Memory Storage Algorithms 2.1.6. Network Storage Algorithms 2.2. Knowledge Engineering 2.2.1. Data Mining 2.2.2. Machine Learning 2.2.3. Search, Retrieval 2.3. Data Mining 2.3.1. Imaging, Video 2.3.2. Semantic Web 2.3.3. Complexity 2.4. Machine Learning 2.4.1. Databases 2.4.2. ML Algorithms 2.4.3. Reasoning 2.4.4. Representation 2.5. Quantum Processing 2.6. Algorithms 2.6.1. Coding, Compression, Graphs, Strings, Trees 2.7. Bioinformatics 2.8. Computation Modelling 3. Systems -- Logical 3.1. Information Security 3.1.1. Networks, Mobile 3.2. Software Engineering 3.2.1. Design 3.2.2. Education 3.2.3. Programming Languages 3.3. System Modelling 3.3.1. Software Engineering 3.3.2. Testing 3.3.3. Ubiquitous Computing 3.3.4. Workflow 3.3.5. Games 3.3.6. Human Factors 3.3.7. Virtual Materials Science T able 1: Concept hierarchy , incrementally constructed, representing a view of appropriate subject headings for articles published in the Computer Journal, 2000–2007. 5 The perspecti ve described, for archiv al, scholarly journal publishing, relates to the narrativ e or thematic e volution of research outcomes. 4 A pplication of Narrative Analysis to Science and Engineer - ing Policy This same perspecti ve as described in the previous section was prototyped for the narrativ e en- suing from national science research funding. The aim here was thematic balance and ev olution. Therefore it was complementary to the operational measures of performance – numbers of publi- cations, patents, PhDs, company start-ups, etc. In Murtagh (2010), the full set of large research centres (8 of these, with up to 20 million euro funding) and a class of less large research centres (12 of these, each with 7.5 million euro funding) were mapped into a Euclidean metric endowed, Correspondence Analysis, factor space. In this space there is displayed the centres, their themes, and, as a prototyping study , just one attribute of the research centres, their research budget. The first factor clearly counterposed centres for biosciences to centres for telecoms, computing and nanotechnology . The second factor clearly counterposed centres for computing and telecoms to nanotechnology . This is further elaborated in section 4.1. All in all, there is enormous scope for insight and understanding, that starts from subject matter and content. Quantitativ e indicators are well accommodated, with their additional or complemen- tary information. It may well be hoped that in the future, qualitativ e, content-based analytics, coupled with quantitati ve indicators, will be extended. For this purpose, it may well be very use- ful to consider not just published research, b ut all written, and subsequently submitted, research results and/or plans. Similarly for research funding, the content-based mapping and assessment of rejected work is rele v ant too, not least in order to contextualize the content of all domains and disciplines. The role of taxonomy is central to the information focusing that is under discussion in this section. Information focusing is carried out through mapping the ontology , or concept hierarchy , as a le vel of aggreg ation, corresponding therefore to non-terminal, i.e. non-singleton, nodes. Our interest in this data is to hav e implications of this for data mining with decision policy support in vie w . Consider a fairly typical funded research project, and its phases up to and beyond the funding decision. A narrati ve can alw ays be obtained, in one form or another , and is likely to be a require- ment. All stages of the proposal and successful project life cycle, including external e valuation and internal decision making, are highly document – and as a consequence narrati ve – based. As a first step, let us look at the very general role of narrati ve in national research de velop- ment. The following comprise our motiv ation: Ov erall view , i.e. overall synthesis of information; Orientation of strands of de velopment; Their tempo and rhythm. Through such an analysis of narrativ e, among the issues to be addressed are the following: Strategy and its implementation in terms of themes and subthemes represented; Thematic focus and cov erage; Organisational clustering; Ev aluation of outputs in a global conte xt; All the abov e 6 ov er time. The aim here is to view the “big picture”. It is also to incorporate contextual attributes. These may be the v aried performance measures of success that are applied, such as publications, patents, licences, numbers of PhDs completed, company start-ups, and so on. It is instead to appreciate the broader configuration and orientation, and to determine the most salient aspects underlying the data. 4.1 Assessing Cov erage and Completeness SFI Centres for Science, Engineering and T echnology (CSETs) are campus-industry partnerships typically funded at up to ¤ 20 million over 5 years. Strategic Research Clusters (SRCs) are also research consortia, with industrial partners and over 5 years are typically funded at up to ¤ 7.5 million. W e cross-tabulated 8 CSETs and 12 SRCs by a range of 65 terms deriv ed from title and summary information; together with b udget, numbers of PIs (Principal In vestigators), Co-Is (Co- In vestigators), and PhDs. W e can display any or all of this information on a common map, for visual con venience a planar display , using Correspondence Analysis. In mapping SFI CSETs and SRCs, we will now show how Correspondence Analysis is based on the upper (near root) part of an ontology or concept hierarchy . This we vie w as information focusing . Correspondence Analysis provides simultaneous representation of observ ations and at- tributes. Retrospectiv ely , we can project other observ ations or attributes into the factor space: these are supplementary observ ations or attrib utes. A 2-dimensional or planar vie w is likely to be a gross approximation of the full cloud of observ ations or of attributes. W e may accept such an approx- imation as rewarding and informati ve. Another way to address this same issue is as follows. W e define a small number of aggregates of either observations or attrib utes, and carry out the analysis on them. W e then project the full set of observ ations and attributes into the factor space. For map- ping of SFI CSETs and SRCs a simple algebra of themes as set out in the ne xt paragraph achiev es this goal. The upshot is that the 2-dimensional or planar vie w is a better fit to the full cloud of observ ations or of attributes. From CSET or SRC characterization as: Physical Systems (Phys), Logical Systems (Log), Body/Indi vidual, Health/Collectiv e, and Data & Information (Data), the following thematic areas were defined. 1. eSciences = Logical Systems, Data & Information 2. Biosciences = Body/Indi vidual, Health/Collectiv e 3. Medical = Body/Indi vidual, Health/Collectiv e, Physical Systems 4. ICT = Physical Systems, Logical Systems, Data & Information 5. eMedical = Body/Indi vidual, Health/Collectiv e, Logical Systems 7 −1.0 −0.5 0.0 0.5 1.0 −1.0 −0.5 0.0 0.5 1.0 CSETs and themes Factor 1, 64% of inertia Factor 2, 29% of inertia APC REMEDI BDI APC REMEDI DERI LERO CTVR CRANN DERI LERO NGL . . . . . . . . . . . APC REMEDI eSci Bio CSE Med ICT eMed eBio Figure 2: CSETs, labelled, with themes located on a planar display , which is nearly complete in terms of information content. 6. eBiosciences = Body/Indi vidual, Health/Collectiv e, Data & Information This categorization scheme can be viewed as the upper level of a concept hierarchy . It can be contrasted with the somewhat more detailed scheme that we used for analysis of articles in the Computer Journal, (Murtagh, 2008). CSETs labelled in the Figures are: APC, Alimentary Pharmabiotic Centre; BDI, Biomedical Diagnostics Institute; CRANN, Centre for Research on Adapti ve Nanostructures and Nanodevices; CTVR, Centre for T elecommunications V alue-Chain Research; DERI, Digital Enterprise Research Institute; LER O, Irish Software Engineering Research Centre; NGL, Centre for Next Generation Localization; and REMEDI, Regenerati ve Medicine Institute. In Figure 2 eight CSETs and major themes are sho wn. Factor 1 counterposes computer engi- neering (left) to biosciences (right). Factor 2 counterposes software on the positiv e end to hardware on the negati ve end. This 2-dimensional map encapsulates 64% (for factor 1) + 29% (for factor 2) = 93% of all information, i.e. inertia, in the dual clouds of points. CSETs are positioned relati ve to the thematic areas used. In Figure 3, sub-themes are additionally projected into the display . This is done by taking the sub-themes as supplementary elements following the analysis as such. From Figure 3 we might wish to label additionally factor 2 as a polarity of data and physics, associated with the extremes of softw are and hardware. 4.2 Change Over Time W e take another funding programme, the Research Frontiers Programme, to sho w ho w changes ov er time can be mapped. 8 −1.5 −1.0 −0.5 0.0 0.5 1.0 1.5 −1.0 −0.5 0.0 0.5 1.0 1.5 2.0 CSETs and themes Factor 1, 64% of inertia Factor 2, 29% of inertia APC REMEDI BDI APC REMEDI DERI LERO CTVR CRANN DERI LERO Local. . . . . . . . . . . . APC REMEDI eSci Bio CSE Med ICT eMed eBio phys log bdy hlth data Figure 3: As Figure 2 but with sub-themes projected into the display . Note that, through use of supplementary elements, the axes and scales are identical to those on Figure 2. Axes and scales are just displayed dif ferently in this figure so that sub-themes appear in our field of view . This programme follo ws an annual call, and includes all fields of science, mathematics and engineering. There are approximately 750 submissions annually . There was a 24% success rate (168 a wards) in 2007, and 19% (143 awards) in 2008. The a verage a ward w as ¤ 155k in 2007, and ¤ 161k in 2008. An a ward runs for three years of funding, and this is mo ving to four years in 2009 to accommodate a 4-year PhD duration. W e will look at the Computer Science panel results only , ov er 2005, 2006, 2007 and 2008. Grants awarded in these years, respectiv ely , were: 14, 11, 15, 17. The breakdown by insti- tutes concerned was: UCD – 13; TCD – 10; DCU – 14; UCC – 6; UL – 3; DIT – 3; NUIM – 3; WIT – 1. These institutes are as follows: UCD, Univ ersity College Dublin; DCU, Dublin City Uni versity; UCC, Univ ersity College Cork; UL, University of Limerick; NUIM, National Univ er- sity of Ireland, Maynooth; DIT , Dublin Institute of T echnology; and WIT , W aterford Institute of T echnology . One theme was used to characterize each proposal from among the follo wing: bioinformatics, imaging/video, software, networks, data processing & information retriev al, speech & language processing, virtual spaces, language & text, information security , and e-learning. Again this cat- egorization of computer science can be contrasted with one deriv ed for articles in recent years in the Computer Journal (Murtagh, 2008). Figures 4, 5 and 6 show dif ferent facets of the Computer Science outcomes. By keeping the displays separate, we focus on one aspect at a time. All displays howe ver are based on the same list of themes, and so allow mutual comparisons. Note that the principal plane sho wn accounts for just 9.5% + 8.9% of the inertia. Although accounting for 18.4% of the inertia, this plane, comprising 9 −2 −1 0 1 2 −2 −1 0 1 2 Factor 1, 9.5% of inertia Factor 2, 8.9% of inertia * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * Y05 Y06 Y07 Y08 RFP Computer Science evolution '05, '06, '07, '08 Figure 4: Research Frontiers Programme over four years. Successful proposals are shown as asterisks. The years are located as the av erage of successful projects. −2 −1 0 1 2 −2 −1 0 1 2 Factor 1, 9.5% of inertia Factor 2, 8.9% of inertia * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * UCD TCD DCU UL UCC DIT NUIM WIT NUIG RFP Computer Science institutes Figure 5: As Figure 4, displaying host institutes of the awardees. 10 −2 −1 0 1 2 −2 −1 0 1 2 Factor 1, 9.5% of inertia Factor 2, 8.9% of inertia * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * bioinf imagvid soft netw dataIR speech virtsp langtxt infsec elearn RFP Computer Science themes Figure 6: As Figures 4 and 5, displaying themes. factors, or principal axes, 1 and 2, accounts for the highest amount of inertia (among all possible planar projections). T en themes were used, and what the 18.4% information content tells us is that there is importance attached to most if not all of the ten. 4.3 Conclusion on the Policy Case Studies The aims and objecti ves in our use of the Correspondence Analysis and clustering platform is to dri ve strategy and its implementation in polic y . What we are targeting is to study highly multiv ariate, ev olving data flows. This is in terms of the semantics of the data – principally , complex webs of interrelationships and ev olution of relationships over time. This is the narrative of pr ocess that lies behind raw statistics and funding decisions. W e ha ve been concerned especially with information focusing in section 4.1, and this ov er time in section 4.2. 5 Domain T axonomy and Researcher’ s Rank f or Data Analysis Here we turn to a domain taxonomy , that is the Computing Classification System maintained and updated by the Association of Computing Machinery (A CM-CCS); the latest release, of 2012, is publicly av ailable at A CM (2012). Parts of A CM-CCS 2012 related to the loosely defined subject of “data analysis” including “Machine learning” and “Data mining”, up to a rather coarse granularity , are presented in T able 2. 11 T able 2: A CM CCS 2012 high rank items cov ering data analysis, machine learning and data mining Subject index Subject name 1. Theory of computation 1.1. Theory and algorithms for application domains 2. Mathematics of computing 2.1. Probability and statistics 3. Information systems 3.1. Data management systems 3.2. Information systems applications 3.3. W orld W ide W eb 3.4. Information retrie val 4. Human-centered computing 4.1. V isualization 5. Computing methodologies 5.1. Artificial intelligence 5.2. Machine learning It should be noted that a taxonomy is a hierarchical structure for shaping kno wledge. The hierarchy in volves just one relation “ A is part of B” so that it leaves aside many other aspects of knowledge including, for example, the dif ferences between theoretical interrelations, computa- tional issues and application matters of the same set of concepts. These, howe ver , may sneak in, e ven if unintentionally , in practice. For example, topics representing “Cluster analysis” occur in the following six branches within the A CM-CCS taxonomy: (i) Theory and algorithms for appli- cation domains, (ii) Probability and statistics, (iii) Machine learning, (iv) Design and analysis of algorithms, (v) Information systems applications, (vi) Information retrie val. Among them, (i) and (ii) refer to theoretical work, (i v) to algorithms, (v) and (vi) to applications. Item (iii), Machine learning, probably embraces all of them. Unlike in biology , the taxonomies of specific research domains cannot be specified exactly because of the changing structure of the domain and, therefore, are subject to much change. For example, if one compares the current A CM Computing Classification System 2012 (A CM, 2012) with its previous version, the A CM Classification of Computing Subjects 1998 which is av ailable at the same site, one cannot help but notice great differences in both the list of sub-domains and the structure of their mutual arrangement. W e consider the set of branches in T able 2 as a taxonomy of its o wn, referred to below as the Data Analysis T axonomy (D A T). An extended version of the taxonomy , along with three to four more layers of higher granularity , presented in Mirkin and Orlov (2015, pp. 241-249), will be used throughout for illustration of our approach. Out of v arious uses of a domain taxonomy , we pick up here its use for determining a scientist rank according to the rank of that node in the taxonomy which has been created or significantly transformed because of the results by the scientist (Mirkin, 2013). The concept of taxonomic rank is not uncommon in the sciences. It is quite popular , for exam- 12 ple, in biology: “ A T axonomic Rank is the lev el that an organism is placed within the hierarchical le vel arrangement of life forms” (see http://carm.org/dictionary-taxonomic-rank). As mentioned in Mirkin and Orlov (2015), Eucaryota is a domain (rank 1) containing Animals kingdom (rank 2). The latter contains Cor data phylum (rank 3) which contains Mammals class (rank 4) which contains Primates order (rank 5) which contains Hominidae family (rank 6) which contains Homo genus (rank 7) which contains, finally , Homo sapiens species (rank 8). Similarly , the rank of the scientist who created the “W orld wide web” (Berners-Lee, 2010), (the item 3.3 in T able 2) at layer 2 of the D A T taxonomy , is 2; and the rank of the scientist who dev eloped a sound theory for “Boosting” (Schapire, 1990), (the item 1.1.1.5 in D A T (Mirkin and Orlov , 2015)), is 4, whereas the rank of the scientists who proposed a sound approach to “T opic modeling” (Blei et al., 2003) (the item 5.2.1.2.4 in D A T (Mirkin and Orlov , 2015)) is 5. This specification of taxonomic rank, TR, is associated with qualitativ e innov ation, whereas the dominant current approach is to only re ward or take account of lo w rank, and particular , topic items. Using taxonomic ranks (TRs) based on domain taxonomies for ev aluating the quality of re- search dif fers from the other methods currently av ailable, through the following features: • The TR method directly measures the quality of results themselves rather than any related feature such as popularity; • The TR e v aluation is well subject-focused; a scientist with good results in optimization may get rather modest ev aluation in data analysis because a taxonomy for data analysis w ould not include high-le vel nodes on optimization; • The TR rank can get re versed if the taxonomy is modified so that the rank-gi ving taxon gets a less fa vourable location in the hierarchical tree; • The granularity of e valuation can be changed by increasing the granularity of the underlying taxonomy; • The TR ev aluations in different domains can be made comparable by using taxonomies of the same depth; • The maintenance of a domain taxonomy can be ef fectiv ely organized by a research commu- nity as a special acti vity subject to regular checking and scrutinising; • Assigning the TR to a scientist or their result(s) is derived from mapping them to a sub- domain that has been significantly af fected by them, and this is not a simple issue. The persons who do the mapping must be impartial and ha ve deep kno wledge of the domain and the results. The last two items in the list abo ve refer to the core of the proposal in this paper . They can be considered a clarification of the main claim ov er ev aluation of the research impact made by the scientists: qualitativ e considerations should prev ail ov er metrics (Dora, 2013; Hicks et al., 2015; 13 Metric T ide, 2016). Here the wide meaning of “qualitativ e” is reduced to two points: (a) de vel- oping and maintaining of a taxonomy , and (b) mapping results to the taxonomy . Both taxonomy de veloping any mapping decisions in volv e explicitly stated judgements which can be discussed openly and corrected if needed. This differs greatly from the currently employed procedures of peer-re vie wing which can be highly subjectiv e and dependent on various external considerations (Eisen et al., 2013; Engels et al., 2013; V an Raan, 2006). The activity of dev eloping and main- taining taxonomies can be left to the governmental agencies and funding bodies, or to scholarly academies, or to discipline and sub-discipline expert organisational bodies, whereas the mapping acti vity should be left, in a transparent way , to scientific discussions in v olving all relev ant indi- viduals. Of course, there is potential for further dev elopments of the formats: taxonomies could be extended to include v arious aspects characterizing research dev elopments, and mapping can be softened up to include spontaneous and uncertain judgements. 6 A Prototype of Empirical T esting W e focus on the field of Computer Science related to data analysis, machine learning, cluster analysis and data mining along with its taxonomy derived from the A CM Computing Classification System 2012 (A CM, 2012), as explained abov e. W e pick up a sample of 30 leading scientists in the field (about half from the USA, and other , mostly European, countries are represented by 2–3 representati ves), such that the information of their research results is publicly av ailable. Although we tried to predict the leaders, their Google-based citation index es are highly different, from a fe w thousand to a hundred thousand. W e picked up 4–6 most important papers by each of the sampled scientists and manually mapped each of the papers to taxons significantly affected by that. Since some of the relev ant subjects, such as “Consensus clustering” and “ Anomaly detection”, have not been presented in the A CM-CCS, we added them to D A T (Data Analysis T axonomy) as leaves, implying that a previous terminal node becomes a non-terminal node. The results of the mapping are presented in T able 3. The table also presents the deriv ed taxonomic ranks and the same ranks, 0–100 normalized. T o deri ve the taxonomic rank of a scientist, we first take the minimum of their ranks as the base rank. Then we subtract from it as many one tenths as there are subdomains of that rank in their list and as many one hundredths as there are subdomains of greater ranks in the list. For example, the list of S23 comprises ranks 4, 5, 4 leading to 4 as the base rank. Subtraction of two tenths and one hundredth from 4 giv es the deriv ed rank 3.79. The normalization is such that the minimum rank, 3.50, gets a 100 mark, and the maximum rank, 4.89, gets a 0. The last column, the stratum, is assigned according to the distance of the mark to either 70 or 30 or 0. 14 T able 3: Mapping main research results to the taxonomy; layers of the nodes af fected; Tr – taxo- nomic ranks deri ved from them; T rn – taxonomic ranks normalized to the range 0 to 100; and three strata obtained by k-means partitioning of the ranks. Scientist Mapping to taxonomy Layers T r T rn Stratum S1 4.1.2.7, 5.2.1.2.7, 5.2.3.7.7 4,5,5 3.88 73 1 S2 2.1.1.2, 2.1.1.2, 5.2.2.7, 5.2.3.5, 5.2.3.5 4,4,4,4,4 3.50 100 1 S3 3.2.1.4.2, 5.2.1.2.3, 5.2.1.2.7, 5.2.3.5.4 , 5.2.3.7.6 5,5,5,5,5 4.50 29 2 S4 1.1.1.4.3, 3.4.4.5, 5.2.1.1.1,5.2.1.2.7, 5.2.3.2.1,5.2.3.7.8 5,4,5,5,5,5 3.90 71 1 S5 3.2.1.4.4, 3.2.1.4.4, 3.2.1.4.5, 3.2.1.4.6, 3.2.1.11.1 5,5,5,5,5 4.50 29 2 S6 3.1.1.5.2, 3.1.2.1.1, 3.1.2.1.1 , 3.2.1.6., 3.2.1.7 5,5,5,4,4 3.77 81 1 S7 5.2.3.5.6, 5.2.3.5.7 5,5 4.80 7 3 S8 3.2.1.3.1, 3.2.1.4.1, 5.2.3.3.1, 5.1.3.2.1, 5.1.3.2.4 5,5,5,5,5 4.50 29 2 S9 5.2.1.2.3, 5.2.3.3.2, 5.2.3.5.1, 5.2.3.5.4, 5.2.3.6.2 5,5,5,5,5 4.50 29 2 S10 5.2.3.3.2, 5.2.3.13.1 5,5 4.80 7 3 S11 3.2.1.2, 3.2.1.2.1,3.2.1.3.3,3.2.1.4.1, 3.2.1.7.2 4,5,5,5,5 3.86 74 1 S12 3.2.1.9.1.1,3.2.1.10,3.2.1.11.2,5.1.1.7.1, 5.2.3.1.3,5.2.3.4.1 6,4,5,5,5,5 3.86 74 1 S13 1.1.1.3, 5.2.1.2.1,5.2.1.2.1,5.2.2.7.1, 5.2.3.7.1 4,5,5,5,5 3.86 74 1 S14 3.2.1.3.1 5 4.90 0 3 S15 5.2.4.3.1 5 4.90 0 3 S16 5.2.4.2.3 5 4.90 0 3 S17 2.1.3.7.1, 5.2.4.3.1, 5.2.3.7.5., 5.2.1.2.4, 5.2.3.2.4, 5.2.3.7.3.2, 5.2.3.5.4., 5.2.4.3.1 5,5,5,5,6,5,5 4.39 36 2 S18 3.2.1.9.1,3.2.1.9.2,5.2.3.3.3.1 5,5,6 4.79 8 3 S19 3.2.1.7.5,3.2.1.9.3,5.2.3.2.1.1,5.2.4.5.1 5,5,6,5 4.69 15 3 S20 3.2.1.4.3,5.2.3.7.7,5.2.3.7.8.1 5,5,6 4.79 8 3 S21 1.1.1.6,2.1.1.2,2.1.1.8.3,3.2.1.6, 3.4.1.6,5.1.2.4,5.2.1.1.3 4,4,5,4,4,4,5 3.57 95 1 S22 3.2.1.2.2,5.2.1.2.7.1,5.2.3.1.2,5.2.3.6.2.1 5,6,5,6 4.78 9 3 S23 3.2.1.3,3.2.1.3.1,3.4.4.1 4,5,4 3.79 79 1 S24 2.1.5.3.1 5 4.90 0 3 S25 5.2.3.3.3.2, 5.2.3.8.1 6,5 4.89 1 3 S26 3.2.1.11.1,3.2.1.11.1,3.3.1.6,5.2.2.7, 5.2.3.5.6 5,5,4,4,5 3.77 81 1 S27 3.2.1.3.2,3.2.1.4.1,5.2.1.2.1,5.2.3.1.1 5,5,5,5 4.60 21 2 S28 3.2.1.8 4 3.90 71 1 S29 5.2.3.3.2.1,5.2.3.3.3.3,5.2.3.3.4 6,6,5 4.88 1 3 S30 5.1.3.2.1.1,5.2.1.2.7.2,5.2.3.3.5 6,6,5 4.88 1 3 15 7 Comparing T axonomic Rank with Citation and Merit W e compared our taxonomic ranks with more con ventional criteria: (a) Citation and (b) Merit. The Citation criterion was deriv ed from Google-based index es of the total number of citations, the number of works receiving 10 or more citations, and Hirsch index h, the number of papers recei ving h citations or more. The merit criterion was computed from data on the following three indices: the number of successful PhDs (co)-supervised, the number of conferences co-organized, and the number of journals for which the researcher-scientist is a member of the Editorial Board. T o aggreg ate the indexes into a con ve x combination, that is, a weighted sum, automatically , a principled approach which works for correlated or inconsistent criteria has been dev eloped. Ac- cording to this approach, gi ven the number of strata (in our case 3), the aggregate criterion is to be found so that its direction in the index space is such that all the observations are projected into compact well-separated clusters along this direction (Mirkin and Orlov , 2013, 2015). T o be more specific, consider a data matrix scientist-to-criteria X = ( x i j ) where i = 1 , ..., N are indices of scientists, j = 1 , ..., M are indices of M criteria, and x i j is the score of j th criterion for the i th scientist. Let us consider a weight vector w = ( w 1 , w 2 , ..., w M ) such that w j ≥ 0 for e very j and ∑ j w j = 1, for the set of criteria. Then the combined criterion is f = ∑ M j = 1 w j x j where x j is j th column of matrix X . The problem is to find K disjoint subsets S = { S 1 , .. S k , ..., S K } , k = 1 , ..., K of the set of indices i , referred to as strata, according to values of the combined criterion f . Each stratum k is characterized by a v alue of the combined criterion c k , the stratum centre. Geometrically , strata are formed by layers between parallel planes in the space of criteria. At any stratum S k , we want the v alue of the combined criterion f i = ∑ M j = 1 w j x i j at any i ∈ S k to approximate the stratum centre c k . In other words, in the equations x i 1 w 1 + x i 2 w 2 + ... + x iM w M = c k + e i , e i are errors to be minimized ov er vector w . A least-squares formulation of the linear stratification (LS) problem: find a vector w , a set of centres { c } and a partition S to solve the problem in (1), as follo ws. min w , c , S K ∑ k = 1 ∑ i ∈ S k ( M ∑ j = 1 x i j w j − c k ) 2 such that M ∑ j = 1 w j = 1 w j ≥ 0 , j ∈ 1 ... M . (1) This problem can be tackled using the alternating minimzation approach, con ventional in clus- ter analysis. For any giv en weight vector w , the criterion in (1) is just the con ventional square-error clustering criterion of the K -means clustering algorithm ov er a single feature, the combined crite- rion f = ∑ M j = 1 w j x j . Finding an appropriate w at a giv en stratification S can be reached by using standard quadratic optimization software. T o illustrate the approach as it is and, also, its difference from the widely used Principal Com- ponent Analysis (PCA) approach to linearly combining criteria, let us consider the following ex- ample. In T able 4, scores of two criteria o ver 8 scientists are presented. 16 Figure 7: Eight scientists on the plane of criteria x and y . The LS and PCA combined criteria are represented with broken lines. T able 4: Scores of two criteria, x and y , over 8 scientists labelled, for con venience, by using an uppercase notation of the corresponding strata (see Figure 7). Label Criterion x Criterion y C1 2 0 C2 0 1 B1 6 0 B2 5 0.5 B3 3 1.5 B4 1 2.5 A1 4 2 A2 2 3 17 T able 5: Scores of two combined criteria, the LS based and PCA based. Label LS PCA C1 0.67 1.54 C2 0.67 0.23 B1 2.00 4.63 B2 2.00 3.97 B3 2.00 2.66 B4 2.00 1.34 A1 2.67 3.54 A2 2.67 2.23 Although usually criteria values are normalized into a 0–100% scale, we do not do that here to keep things simple. It appears, the data ideally , with zero error , fall into three strata, K = 3, as sho wn in Figure 7, according to combined criterion f = 1 3 x + 2 3 y . In contrast, the PCA based linear combination, z = 0 . 7712 x + 0 . 2288 y , admits a residual of 13.4% of the total data scatter , and leads to a somewhat dif ferent ordering, at which two top stratum scientists get lesser aggregate scores than two scientists of the B stratum. For con venience, the combined criteria scores are presented in T able 5. In the thus aggregated Citation criterion, the Hirsch index recei ved a zero coef ficient, while the other two were one half each. The zeroing of the Hirsch index weight is in line with the ov erwhelming critiques this index has been e xposed to in recent times, (Albert, 2013; Osterloh and Frey , 2014; Dora, 2013; V an Raan, 2006). A similarly aggregated Merit criterion is formed with weights 0.22 for the number of PhD students, 0.10 for the number of conferences, and 0.69 for the number of journals, which is consistent with the pre vailing practice of maintaining a hea vy and just submission re viewing process in leading journals. T o compare these scales, let us compute Pearson correlation coef ficients between them, see T able 6. T able 6: Pairwise correlations between criteria (only the part abo ve the diagonal is shown). Criterion Citation Merit TR -0.12 -0.04 Citation 0.31 As expected, the Citation and Merit criteria do not correlate with the T axonomic rank of the scientists. On the other hand, the traditional Citation and Merit criteria are somewhat positiv ely correlated, probably because they both relate to the popularity of a scientist. 18 8 Conclusions Assessments can be carried out at different le vels, a region, an org anization, a team or an individual researcher; within a domain or inter domains. What we can metaphorically express as wider horizons, are brought to our attention, through analysis of quality . Among the recommendations arising from this work, on the regional le vel, there are three on the particular subjects of our concern: • Set out a more structured and strategic process for proposing projects. • Conduct a systematic analysis of the existing infrastructure. • T ake a more systematic approach to e valuating the impact of operational projects. W ith these recommendations, we are emphasizing the importance of these underpinning themes. These themes, and their underpinnings, should be pursued assertiv ely for journals and other schol- arly publishing, and also for research funding programmes. W e both observe and demonstrate that e valuation of research, especially at the le vel of teams or individuals can be organized by , firstly , dev eloping and maintaining a taxonomy of the relev ant subdomains and, secondly , a system for mapping research results to those subdomains that hav e been created or significantly transformed because of these research results. This would bring a well-defined meaning to the widely-held opinion that research impact should be ev aluated, first of all, based on qualitativ e considerations. Further steps can be, and should be, undertaken in the directions of de veloping and maintaining a system for assessment of the quality of research across all areas of knowledge. Of course, dev eloping and/or incorporating systems for other elements of research impact, viz., kno wledge transfer , industrial applications, social interactions, etc., are to be taken into account also. In comprehensiv ely covering quality and quantitati ve research outcomes, there can be distinguished at least fi ve aspects of an indi vidual researcher’ s research impact: • Research and presentation of results (number , quality) • Research functioning (journal/v olume editing, running research meetings, revie wing) • T eaching (kno wledge transfer , knowledge disco very) • T echnology innov ations (programs, patents, consulting) • Societal interactions (popularization, getting feedback) Many , if not all, of the items in this list can be maintained by dev eloping and using corre- sponding taxonomies. The dev elopment of a system of taxonomies for the health system in the USA, IHTSDO SNOMED CT (SNOMED CT , 2016), extended now to many other countries, and languages, should be considered an instructi ve example of such a major undertaking. This suggests directions for future work. Among them are the follo wing. 19 In methods: (i) Enhancing the concept of taxonomy by including theoretical, computational, and industrial face ts, as well as dynamic aspects to it; (ii) De veloping methods for relating paper’ s texts, viz. content, and taxonomies; (iii) Dev eloping methods for taxonomy b uilding using such research paper texts, i.e. content; (i v) De veloping methods for mapping research results to taxon- omy units af fected by them; (v) Using our prototyping here, dev eloping comprehensiv e methods for ranking the impact of results to include expert-dri ven components; (vi) Also based on our prototyping here, de veloping accessible and widely used methods for aggregate rankings. In substance: (i) Dev eloping and maintaining a permanent system for assessment of the scope and quality of research at dif ferent le vels; (ii) Dev eloping a system of domains in research subjects and their taxonomies; (iii) Cataloguing researchers, research and funding bodies, and research results; (i v) Creating a platform and forums for discussing taxonomies, results and assessments. A spin-off of our very major motiv ation for qualitati ve analytics is to propose using a full po- tential of the research ef forts on a regional level. In our journal editorial roles, we realise very well that sometimes quite predictable rejection of article submissions can raise such questions as the follo wing: is there no qualitativ e interest at all in such work? Ho w can, or ho w should, improv e- ment be recommended? At least as important, and far more so in terms of wasteful energy and ef fort, is the qualitati ve analysis of rejected research funding proposals. (As is well known, a rela- ti vely small proportion of the research projects gets a “go ahead” nod. For e xample, The European Horizon 2020 FET -Open, Future Emerging T echnologies, September 2015 proposal submission resulted in less than a 2% success rate (FET , 2016): 13 successful research proposals out of 822 proposal submissions.) Giv en the workload at issue, on various le vels and from various vantage points, there is potential for data mining and knowledge discov ery in the vast numbers of rejected research funding proposals. Ultimately , and giv en the workload undertaken, it is both potentially of benefit, and justified, to carry out such analytics. Refer ences ABRAMO, G., CICER O, T ., ANGELO, C.A. (2013). “National peer-re vie w research assessment ex ercises for the hard sciences can be a complete waste of money: the Italian case”, Scientometrics , 95(1), 311–324. A CM (2012). The 2012 A CM Computing Classification System, http://www .acm.org/about/class/2012 (V iewed 2017-02-05). ALBER T , B. (2013). “Impact factor distortions”, Science , 340, no. 6134, 787. ARA GN ´ ON, A.M. (2013). “ A measure for the impact of research”, Scientific Reports 3, Article number: 1649. BERNERS-LEE, T . (2010). “Long liv e the W eb”, Scientific American . 303 (6). 80–85. BLEI, D.M., NG, A.Y ., JORD AN, M.I., LAFFER TY , J. (2003). “Latent Dirichlet allocation”, J ournal of Machine Learning Resear ch . 3: 993–1022. 20 CAN A V AN, J., GILLEN, A., SHA W , A. (2009). “Measuring research impact: de veloping practical and cost-ef fectiv e approaches”, Evidence and P olicy: A Journal of Resear ch, Debate and Practice , 5.2. 167–177. DORA (2013). San Francisco Declaration on Research Assessment (DORA), www .ascb .org/dora (vie wed 2017-02-05). EISEN, J.A., MA CCALLUM, C.J., NEYLON, C. (2013). “Expert failure: Re-ev aluating research assessment”. PLoS Biology , 11(10): e1001677. ENGELS, T .C., GOOS, P ., DEXTERS, N., SPR UYT , E.H. (2013). “Group size, h-index, and ef ficiency in publishing in top journals explain expert panel assessments of research group quality and producti vity”. Resear ch Evaluation , 22(4), 224–236. FET (2016), “FET -Open: 3 ne w proposals start preparation for Grant Agreements”, Futur e Emer g- ing T echnolo gies Newsletter , 21 March 2016. http://ec.europa.eu/ne wsroom/dae/itemdetail.cfm?item id=29587&newsletter=129 HICKS, D., WOUTERS, P ., W AL TMAN, L., DE RIJCKE, S., RAFULS, I. (2015). “The Leiden Manifesto for research metrics”. Natur e , 520, 429–431. SNOMED CT (2016). IHTSDO, International Health T erminology Standards Dev elopment Or- ganisation, SNOMED CT , Systematized Nomenclature of Medicine, Clinical T erms. http://www .ihtsdo.org/snomed-ct (vie wed 2017-02-05). LEE, F .S., PHAM, X., GU, G. (2013). “The UK research assessment ex ercise and the narro wing of UK economics”. Cambridge J ournal of Economics , 37(4), 693–717. METRIC TIDE (2016). “The Metric T ide: Report of the Independent Revie w of the Role of Met- rics in Research Assessment and Management”, http://www .hefce.ac.uk/pubs/rereports/Y ear/2015/metrictide/T itle,104463,en.html (vie wed 2017-02- 05). MIRKIN, B. (2013). “On the notion of research impact and its measurement”, Contr ol in Lar ge Systems, Special Issue: Scientometry and Experts in Managing Science . 44. 292–307, Institute of Control Problems, Mosco w (in Russian). MIRKIN, B., ORLO V , M. (2013). “Methods for Multicriteria Stratification and Experimental Comparison of Them”, Preprint WP7/2013/06, Higher School of Economics, Moscow , 31 pp. (in Russian). MIRKIN, B., ORLO V , M. (2015). “Three aspects of the research impact by a scientist: measure- ment methods and an empirical ev aluation”, in A. Migdalas, A. Karakitsiou, Eds., Optimization, Contr ol, and Applications in the Information Age , Springer Proceedings in Mathematics and Statis- tics. 130. 233–260. MUR T A GH, F . (2008). “Editorial”. The Computer Journal , 51(6), 612–614. MUR T A GH, F . (2010). “The Correspondence Analysis platform for uncov ering deep structure in data and information”. The Computer Journal , 53(3), 304–315. NG, W .L. (2007). “ A simple classifier for multiple criteria ABC analysis”. Eur opean Journal of Operational Resear ch . 177. 344–353. 21 ORLO V , M., MIRKIN, B. (2014). “ A concept of multicriteria stratification: A definition and solution”, Pr ocedia Computer Science , 31, 273–280. OSTERLOH, M., FREY , B.S. (2014). “Ranking games”. Evaluation r eview , Sage, pp. 1–28. RAMAN A THAN, R. (2006). “In ventory classification with multiple criteria using weighted linear optimization”, Computers and Oper ations Researc h . 33. 695–700. SCHAPIRE, R.E. (1990). “The strength of weak learnability”. Machine Learning . 5(2), 197–227. SIDIR OPOULOS, A., KA TSAR OS, D., MANOLOPOULOS, Y . (2014). “Identification of influ- ential scientists vs. mass producers by the perfectionism index”. Preprint, arXiv:1409.6099v1, 27 pp. SUN, Y ., HAN, J., ZHA O, P ., YIN, Z., CHENG, H., WU, T . (2009). “RankClus: integrating clustering with ranking for heterogeneous information network analysis”. EDBT ’09 Pr oceedings of the 12th International Confer ence on Extending Database T echnology: Advances in Database T echnolo gy , A CM, NY , 565–576. THOMSON REUTERS (2016). “Thomson Reuters intellectual property and science”. (Acqui- sition of the Thomson Reuters Intellectual Property and Science Business by Onex and Baring Asia Completed. Independent business becomes Clariv ate Analytics) http://ip.thomsonreuters.com (V iewed 2017-02-05). UNIVERSITY GUIDE (2016). “The Complete Univ ersity League Guide”. http://www .thecompleteuniv ersityguide.co.uk/league-tables/methodology. (V ie wed 2017-02-05) V AN RAAN, A.F . (2006). “Comparison of the Hirsch-index with standard bibliometric indicators and with peer judgment for 147 chemistry research groups”. Scientometrics , 67(3), 491–502. 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment