Generative adversarial network-based approach to signal reconstruction from magnitude spectrograms
In this paper, we address the problem of reconstructing a time-domain signal (or a phase spectrogram) solely from a magnitude spectrogram. Since magnitude spectrograms do not contain phase information, we must restore or infer phase information to re…
Authors: Keisuke Oyamada, Hirokazu Kameoka, Takuhiro Kaneko
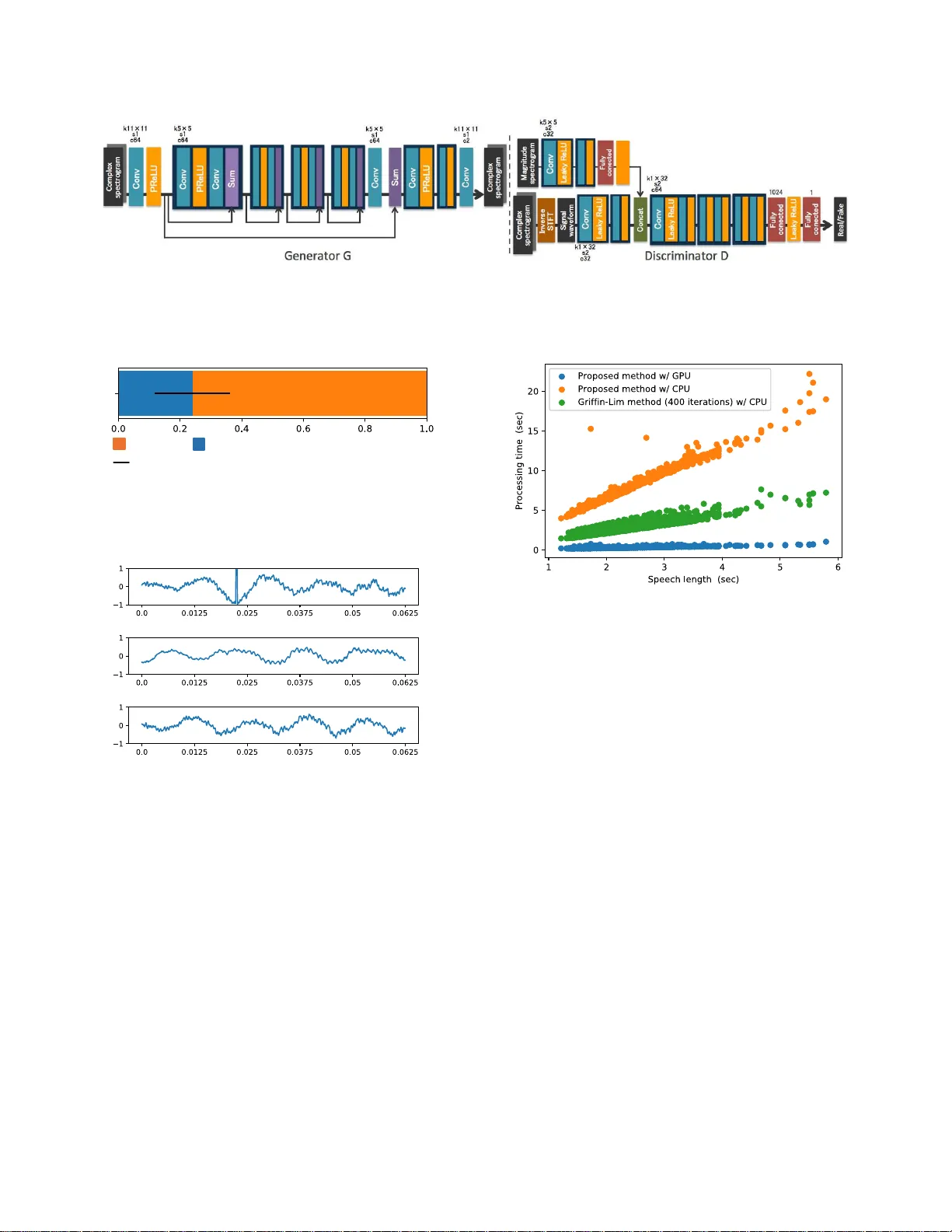
GENERA TIVE AD VERSARIAL NETWORK-B ASED APPR OA CH T O SIGNAL RECONSTR UCTION FROM MA GNITUDE SPECTR OGRAMS K eisuke Oyamada ⋆ , Hir okazu Kameoka † , T akuhir o Kaneko † , K ou T anaka † , Nobukatsu Hojo † , Hir oyasu Ando ⋆ ⋆ Univ ersity of Tsukuba, Japan † NTT Comm unication Science Laboratories, NTT Corporation, Japan ABSTRA CT In this paper, we address the proble m of recon structing a time- domain signal (or a ph ase sp ectrogram ) solely from a mag- nitude spectrogra m. Since magnitud e spectro grams do no t contain phase inf o rmation, we must r estore or inf er phase in- formation to reconstruct a time-dom a in signal. One widely used approac h fo r de a ling with the signal r econstruction prob- lem was p roposed b y Griffin and Lim. This metho d usually requires many iterations fo r the sign a l reconstruction proce ss and depend ing o n the in p uts, it does n ot always produ ce high- quality au dio sig n als. T o overcome these shortco mings, we apply a learn ing-based appro ach to the signal recon struction problem by modeling the signal recon struction process using a deep neur al n etwork and training it u sin g the idea o f a gene r- ativ e adversarial n etwork. Expe rimental ev alua tions rev e aled that ou r method was able to recon struct signals faster with higher q uality than the Griffin-Lim method . Index T erms — Phase reconstructio n, Deep n e ural net- works, Gener ativ e adversarial n etworks 1. INTR O DUCTION This paper addre sses the proble m of recon structing a time- domain sign al so le ly from a m agnitude spectrogr am. The magnitud e spectrog rams of real-world au dio signals tend to be high ly structu red in terms of both spectra l an d tem- poral regu la r ities. F o r examp le, pitch contou rs and forman t trajectories are clearly visible from a magnitude spectr ogram representatio n of speech com pared with a time-d omain sig- nal. Therefo re, th ere are many cases wher e pr ocessing mag- nitude spectrogram s ca n deal with pro blems mo re easily than directly pro c essing time-d omain signals. In fact, many meth - ods fo r mo n aural aud io source separation are applied to mag - nitude spectrog rams [ 1 – 3]. Fu r thermor e , a magn itu de sp e c- trogram representatio n was recently foun d to be reasonab le and e ffective fo r use w ith spe e ch synthesis systems [4, 5 ]. Since a m agnitude spectrog r am does n ot c o ntain phase informa tio n, we must restore o r infer p hase inform a tion to reconstruc t a time-do main signal. Th is p roblem is called the signal (o r phase) r econstructio n pr oblem. O n e widely used method for solving th e signal reconstru ction problem was propo sed b y Gr iffin and Lim [6] ( hereafter referred to as the Griffin-Lim meth od). On e of the drawbacks of th e Griffin- Lim method is that it usually requ ires many iteratio ns to obtain h igh-qu a lity audio signals. This makes it particularly difficult to apply it to r e a l-time system s. Furthermo re, there are some cases where high - quality aud io signals can never be o btained even tho ugh th e algo rithm is run fo r ma ny iter- ations. T o overcome the se shortco mings of the Griffin-Lim method, we apply a learning-b a sed a p proach to the signal reconstruc tion p roblem. Spec ifica lly , we prop ose mo deling the reconstruction pr ocess of a time-doma in sig n al f r om a magnitud e spectrogram using a deep n e ural n etwork (DNN) and propo se introd ucing th e idea of the ge nerative adversar ia l network ( GAN) [7] f o r training the signal generato r network. The rema inder of the paper is organized as fo llows. W e provide an overview of the phase recon stru ction pr oblem in Section 2, intr o duce the Griffin-Lim m ethod in Section 3, an d present ou r GAN- based app roach in Section 4. Experimen- tal evaluations, and supplemen ts for training our model are provided in Section 5. Finally , we offer o ur conclu sions in Section 6. 2. SIGNAL RECONSTR UCTION PROBLE M In this section, we provide an overview of the signal reco n- struction problem . W e use x = [ x (0) , . . . , x ( T − 1)] T ∈ R T to deno te a time dom ain signal a n d c f ,n ∈ C to den ote the time frequen cy comp onent of x where f and n indicate fre- quency and time indices, respectively . By d e fining w f ,n = [ w f ,n (0) , . . . , w f ,n ( T − 1)] T ∈ C T as a co mplex sinuso id of f requency ω f modulated by a window functio n centered at tim e t n , c f ,n is defin ed by the inner produ ct b etween x and w f ,n , namely c f ,n = w H f ,n x . W ith a sho rt-time Fourier transform (STFT), t n correspo n ds to the cente r time of fram e n and w f ,n is the mod u lated com p lex sinusoid padd e d with zeros over th e r ange outside th e fr ame. By u sing c ∈ C F N to denote a vecto r ob tained by stacking all the time-fr equency compon ents c f ,n , the r e lationship b etween c a n d x can be written as c = W x , (1) where W is a F N × T matrix wh ere each row is w H f ,n . Her e - after , we call c a complex spectrog ram. Since the total num- ber F N of tim e frequ ency po ints is usu a lly set at mor e than the nu mber T of samp le poin ts of the time dom ain signal, c is a redun dant representatio n of x . Na m ely , c b elongs to a T -dim e nsional linear subspace C spann ed by each co lumn vector o f W . W ith an STFT , all the elements of a com- plex spectr ogram must satisfy cer ta in cond itions to ensure that the waveforms within the overlapping segment of consec- utiv e fr ames ar e con sistent. By using a to den ote th e magni- tude spectro gram of c wh ere ea ch elem ent of a is given by the absolute value of the elemen t of c , the sig n al rec onstruction problem can b e cast as an op timization problem of e stimating x solely from a using the redu n dancy c onstraint a s a clu e. 3. GRIFFIN-LIM METHOD One widely used way of solving the p hase recon struction problem inv olves the Griffin-Lim method [6]. In this sectio n, we derive the iter a tive alg orithm o f the Griffin-Lim meth o d following the deriv atio n given in [8]. Whether o r no t a given c satisfies th e r e dundan cy co n- straint so that c is a complex spectrog ram associated with a time domain signa l can b e ev aluated by examining wh ether or n ot the o rthogo nal projection WW + c o f c to the subspace C matches c . Here , W + is a pseudo inv erse matrix of W satisfying W + c = a rgmin x k c − Wx k 2 2 = ( W H W ) − 1 W H c . (2) W ith an STFT , ( 2) cor respond s to an in verse STFT . Thus, WW + c is the STFT of the in verse STFT of c . Now , by using φ to d enote a vector where e a ch elem ent is the ph ase φ f ,n ≡ e θ f,n , the phase rec o nstruction pro blem for a giv e n a is form u lated as an optimization p roblem of estimating φ that minimizes J ( φ ) = k a ⊙ φ − W W + ( a ⊙ φ ) k 2 2 , (3) where ⊙ deno te s an elemen t-wise produ ct. Now , f rom (2), WW + ( a ⊙ φ ) is the poin t closest to a ⊙ φ in the subspace C . Th us, we ca n rewrite (3 ) as J ( φ ) = min ˜ c ∈C k a ⊙ φ − ˜ c k 2 2 . (4) According to the principle of the majorization -minimization algorithm [9], it can be shown that J + ( φ , ˜ c ) ≡ k a ⊙ φ − ˜ c k 2 2 is a majorizer o f J ( φ ) where ˜ c ∈ C is an au xiliary variable and a stationary po int of J ( φ ) can be f o und by iteratively perfor ming the following upd ates: ˜ c ← ar gmin ˜ c ∈C k a ⊙ φ − ˜ c k 2 2 = W W + ( a ⊙ φ ) , (5) φ ← argmin φ k a ⊙ φ − ˜ c k 2 2 = ∠ ˜ c . (6) Here ∠ · d enotes an op eration th a t divides eac h elem ent of a vector b y its ab solute value. W ith an STFT , Eq. (5) can b e in- terpreted as the in verse STFT of a ⊙ φ followed by th e STFT whereas Eq. (6) is a pro cedure for rep lacing the phase φ with the ph ase of ˜ c up dated via (5). T h is algorith m is p rocedur ally equiv alen t to the Griffin-Lim method [6]. The Griffin-Lim metho d usually requires many iterations to ob tain a high- quality audio sign al. This makes it partic- ularly difficult to apply to real-time systems. Furthermore, there ar e some cases where high-quality audio signals can never be ob tained even thoug h the algorithm is ru n fo r m any iterations, fo r example wh en a is an artificially created magni- tude spectrog ram. In the next section, we propose a learning - based appro ach to the p h ase recon stru ction pr oblem to over- come th ese shortcom ings of the Griffin-Lim me th od. 4. GAN-BASED SIGNAL RE C ONSTR U CTION 4.1. Modeling phase Reconstruction Process By using φ (0) to d enote the initial value of φ , and d efining h ( a , φ ) ≡ W W + a ⊙ φ and g ( c ) ≡ ∠ c , the iterative algo- rithm of the Gr iffin-Lim metho d can b e expressed a s a multi- layer co mposite func tio n ˆ c = h ( a , g ( · · · g ( h ( a , g ( h ( a , φ (0) )))) · · · )) . (7) Here, h is a linear p rojection whereas g is a nonlinear o p era- tion applied to the output of h . Hence , (7) can be viewed as a deep neural network (DN N ) where the weight parameter s and the activation function s are fixed. From this poin t of view , finding an alg orithm that converges mor e quick ly to a b et- ter solutio n than the Gr iffin-Lim algor ithm can be r egarded as learnin g the weigh t p arameters (an d the activ ation func- tions) o f the D NN . This idea is insp ir ed by the deep unfold ing framework [10], which uses a le a r ning strategy to o btain an improved version of a determin istic iterative inferenc e algo - rithm by unfo lding the itera tions an d treating them as lay ers in a DNN. Fortunately , an un lim ited numb er o f p a ir data of c and { a , φ } can be collected very easily by comp uting th e complex, magn itude and phase spectro grams of time do main signals. This is very ad vantageous fo r e fficiently tr a ining our DNN. In th e fo llowing, we consider a DNN that uses a and φ as inputs and g enerates c (or x ) as an o utput. W e call this DNN a generator G and express the relationship between the inp ut and o utput as ˆ c = G ( a , φ ) . 4.2. Learning Criterion For the ge n erator train ing, o ne natu ral cho ice for th e lear ning criterion would be a similarity metr ic (e.g., the ℓ 1 norm) be- tween the generato r output and a target complex spec trogram (or signal). Manually defin ing a similarity m etric amo u nts to assuming a specific form o f the probability distribution o f the target data (e.g., a Laplacian d istribution f or the ℓ 1 norm) . Howe ver, the d a ta distribution is u nknown. If we use a sim- ilarity metric defined in th e d ata space as the learning cr i- terion, the generato r will b e trained in such a way that the outputs that averagely fit the target d ata are co nsidered o p - timal. As a result, the gener ator will learn to genera te only oversmoothed signals. Th is is und esirable as the oversmooth- ing of rec o nstructed signals ca uses audio quality degrada tio n. T o av oid this, we p r opose using a similarity metr ic implic- itly learned u sin g a generativ e adversarial network (GAN) [7]. In addition to the g enerator network, we introdu ce a dis- criminator network D that learns to co rrectly discriminate the complex spectrogr ams ˆ c g enerated by the g enerator and the complex spectr o grams of real audio signals. Giv en a target complex spectrogr am c , the discrimin ator D is expected to find a featu re space where ˆ c an d c are as separate as possi- ble. T h us, we expect that minimizing the distance between ˆ c and c measured in a hidden layer of the discrimin ator would make ˆ c indistinguishab le fr om c in the data space. By using D ( · , a ) ∈ R to d enote the discriminato r ne twork D , we first consider the following criteria for the discrimin ator V ( D ) = 1 2 E ( c , a ) ∼ p c , a ( c , a ) ( D ( c , a ) − 1) 2 + 1 2 E a ∼ p a ( a ) , φ ∼ p φ ( φ ) D ( G ( a , φ ) , a ) 2 . (8) Here, th e target label cor r espondin g to real data is assumed to be 1 an d that corr espondin g to the data gen erated by the generato r G is 0. Thus, (8) me a ns tha t V ( D ) becomes 0 only if the discriminator D corr e ctly distinguishes the “fake” complex spectrograms generated by the gen e r ator G and th e “real” comp lex spectr ograms of re a l audio signals. The r efore, the goal of D is to minimize V ( D ) . As for th e ge n erator G , one of the g oals is to deceive the discriminato r D so as to make the “ fake” com plex spectrogr ams as indistinguisha ble as po ssible fro m the “real” co mplex spectrogram s. T his can be accomplished by minimizing the following criterion U ( G ) = 1 2 E a ∼ p a ( a ) , φ ∼ p φ ( φ ) ( D ( G ( a , φ ) , a ) − 1) 2 . (9 ) Another goal for G is to make ˆ c = G ( a , φ ) a s close as pos- sible to the target co mplex spectrog ram c . By using D l ( · ) to denote the o utput of the l -th layer of the discrimina to r D , we would also like G to minimize I ( G ) = L X l =0 w l k D l ( c ) − D l ( G ( a , φ )) k 2 2 , (10) where w l is a fixed weight, which weig h s the impo rtance of the l -th lay er feature space. Here, the 0 -th layer correspo nds to the input layer, n amely D 0 ( c ) = c . The learn ing objectives fo r D and G can thus be summa- rized as follows: D : V ( D ) → minimize , (11) G : U ( G ) + λI ( G ) → minimize , (12) where λ is a fixed weigh t. A gen eral fram ew or k f o r training a gen erator network in such a way that it ca n deceive a r e al/fake discrim inator net- work is called a gen erative adversarial network (GAN) [7]. The n ovelty of our prop osed a pproach is that we have suc- cessfully ad apted th e GAN fr amew o rk to the sign al r econ- struction proble m by incorpo rating an a dditional term (10). The GAN framework u sing (8) and ( 9) as the learn ing crite- ria is called th e least squares GAN (LSGAN) [11]. Note that GAN frameworks using other learnin g criteria such as [12] have also been p roposed . Thus, we can also use the learning criteria employed in [7 ], [12] or others instead of (8) and (9). 5. EXPERIMENT AL EV ALU A TION W e tested our method a nd the Griffin-Lim method using real speech sam ples. 5.1. Experimental Settings 5.1.1. D ataset W e used clean spee c h signals excerpted from [13] as the ex- perimental data. The speech data c onsisted o f u tter ances of 30 speakers. The uttera nces of 28 speakers were u sed as the training set an d the r emaining utterance s were used as th e ev aluation set. For the m ini-batch trainin g, we divided each training utterance into 1-secon d-long segments with an over - lap of 0. 5 seconds. All the speech d a ta were downsampled to 16 kHz . Magn itude spectro grams were o btained with an STFT using a Blackm an window th at was 64 ms long with a 32 ms overlap. 5.1.2. Network A r chitectur e Fig. 1 shows the n etwork architectures we co nstructed for this experiment. The left half sh ows the architectur e of the gen- erator G and the rig ht half shows that of the discrim inator D . The light blue b locks in dicate conv olutio nal layers, and k , s , and c on each co nvolutional layer r epresent hyper-param eters. The yellow blocks ind icate a c ti vation fun ctions. PReLU [14] was u sed for th e ge nerator G an d Leaky ReLU [15] was u sed for the discr im inator D . T he violet blocks indicate element- wise sums, and th e green blo ck indicates the co ncatenation of features along the channel axis. Th e red b locks in dicate f ully- connected layers. Blocks withou t symbols hav e the sam e hyper-parameter s a s the pr evious bloc k s. Note that we re- ferred to [1 6] when constructing these architectu res. The g en- erator G is fully co n volutional [17], thus allowing an input to have an arbitrar y len gth. The we ight constan t w l was set to 0 f or l = 0 an d 1 for l 6 = 0 . λ was set to 1 . RMSprop [18] was used as th e optimizatio n alg orithm and the learn ing rate was 5 × 10 − 5 C α = 0 . 5 . T he mini-b atch size was 10 and the number of epochs was 7 3 . Instead o f directly feedin g an input magnitu de spectro - gram an d a ran domly- generated phase spectr o gram into the generato r G , we used a com plex spectro gram r e constructed using the Gr iffin-Lim m ethod af ter 5 iter ations as th e G in - put. Both the inpu t an d output of th e gener ator G h av e 2 channels, o ne co rrespond ing to th e r eal par t a n d th e othe r cor- respond in g to the ima ginary part of the comp lex spectrogram . For pre- processing, we no r malized the comp lex spectr o grams of the training data to obtain zero-m ean and unit-variance at each freq u ency . At test time, the scale of the generator outp ut at ea ch frequen cy was restore d . W e added a block th a t ap plies an inv erse STFT to the gen - erator o utput befor e feeding it in to th e discrim inator D . W e found th is particularly imp ortant as the tr aining did not work well with out this block. 5.2. Data A ugmentation It is a well-kn own fact that the difference between signals is hardly per c eptible to h uman ear s when the m agnitude spec- trogram s and the inter-frame phase differences are the same. This im p lies that there is an arb itrariness in the in itial ph a ses of spec trograms that are perceived similarly . By utilizing this proper ty , we can augme nt the trainin g data fo r G and D by preparin g many d ifferent wa vefo rms that are the same except for the initial p hases. W e expect that this data aug mentation would allow the gen erator to con c entrate on learning a way of inferrin g app ropriate inte r-frame phase differences g iv en a magnitud e spectrogra m , thus facilitating efficient lea rning. 5.3. Dimensionality Reduction Note that the real an d imagina r y pa r ts of the Fourier transform of a real-valued signal b ecome even and od d fu nctions, re- spectiv ely . Ow in g to this symmetric structure, it is sufficient to re sto r e/infer spectr al com p onents within the f requency range fro m 0 up to the Nyq uist frequency . W e can therefo re restrict the sizes o f the inpu t and output of th e generato r to this f requency ran ge. 5.4. Subjective E valuation W e comp ared o u r proposed me th od with the Griffin-Lim method in terms of the perceptual qu a lity o f recon structed signals by condu cting an AB test, wher e “ A ” and “B” were reconstruc ted signals o btained respe c ti vely with the pro posed and baselin e method s. W ith this listening test, “ A ” and “B” were presented in ran d om order s to eliminate bias as regards the orde r o f stimuli. Five listene r s particip ated in our listenin g test. Each listener was p resented with { “ A ”,“B” } × 1 0 signals and asked to select “ A ”or “B” fo r ea c h pair . The Griffin-Lim method was run for 4 00 iteratio ns. The signals were 2 to 5 seconds lo ng. The prefe rence scores are shown in Fig. 2. As the re- sult shows, the reconstru cted signals ob tained with the p ro- posed metho d were p referred by the listeners fo r 76% of the 50 pairs. 5.5. Generalizatio n ability T o con firm the genera liza tio n ab ility of the pr oposed metho d , we tested it on mu sical au dio signals excerpted from [19]. Examples of the reconstruc ted sign als ar e shown in Fig. 3. W ith these examples, we can observe a d iscontinuou s p oint in the reconstruc ted signal obtained with the Griffin-Lim method. On the other hand , the prop osed method appear s to have worked successfully , even tho ugh the model was trained using sp eech data. 5.6. Comparison of Processing T imes W e fur ther compare d the p r oposed method with th e Griffin- Lim m ethod in terms of the pr ocessing times need ed to recon- struct time d o main signals. For compar iso n , we me a sured the processing times for various speech len gths. W e used speech data shorter th an 6 seco nds f or the ev a luation. Here, the net- work architectu r e of o ur pro posed method was the same as Fig. 1, and the Griffin-Lim method was ru n for 40 0 itera- tions. The CPU u sed in this exper im ent was “Intel Core i7- 6850K CPU @ 3 .60GHz”. The GPU was “NVI DIA GeForce GTX 1080”. W e implemented the Griffin-Lim meth o d us- ing the fast Fourier tran sform functio n in NumPy [2 0]. W e implemented our m odel with Chainer [21]. Fig. 4 shows the result. As the speech data becom e longe r, the pro cessing time increases linearly . When executing the prop osed metho d using the GPU, the time need ed to reco nstruct a sign a l was only ab out one-tenth th e leng th of tha t signal. On the other hand, th e Griffin-Lim me th od executed usin g the CPU to ok about th e same time as the leng th o f the signal. Th e refore, if we can use a GPU, the prop osed method can be run in rea l time. Howev e r , when using the CPU, the pro posed method took abou t th ree times lon ger than the length of th e signal. I f we want to execute the proposed method in real-time using a CPU, we would need to construct a mo re comp act arch itec- ture than that shown in Fig. 1. One simple way would be to replace th e conv olu tional layers with d ownsampling a nd up - sampling layers. 6. CONCLUSION This pa per pro posed a GAN-based appro ach to sign a l re- construction fro m m agnitude spectrogr ams. The idea was to model the signal reconstruction p rocess u sing a DNN a n d train it using a similarity metric imp licitly learn ed using a GAN discrimin ator . Thr o ugh subjective ev aluations, we showed that the prop osed method was able to recon struct higher quality time domain sign als than the Gr iffin-Lim method, wh ich was run for 400 iterations. Furthermo re, we showed that the pro posed method can be executed in real-time when using a GPU. Futur e work will inclu de the ! " # " $ %&' $ ( ! ! ) * + , $ * - * # %&' $ ( ) ! " # $% ! & '() * ! " # $% ! & '() * ! " # $% ! + ,- ! .//0//! 1/2 ! 345 ! .6062 ! 1/! 345 ! " # $% ! .606! 1/! 345 ! .//0//! 1/! 37 ! . ' - / 0 " 1 ( + / " , &$ ' 2 $ %- ! 3" %0 4 5 %6 " ! + 89 $: ;< = : % (> # ? - ! " # $% ! ) (: . @ 2'() * ! "# $3: A ! B : 9 $8A ,C (< 1 D (3A ? # 9 ? : - ! " # $% ! ) (: . @ 2'() * ! E ,;;@ < 3# $(3A (C ! ./0F7! 17! 3F7 ! .6062 ! 17! 3F7 ! ./0F7! 17! 345 ! /G75 ! / ! " # $% ! + ,- ! " # $% ! & '() * ! " # $% ! . ' - / 0 " 1 ( + / " , &$ ' 2 $ %- ! ) (: . @ 2'() * ! E ,;;@ < 3# $(3A (C ! ) (: . @ 2'() * ! E ,;;@ < 3# $(3A (C ! . ' - / 0 " 1 ( + / " , &$ ' 2 $ %- ! H$% (? 1(< + I E I ! )(:.@2'()*! Fig. 1 . Network architecture s of g enerator an d discriminator . Lig ht b lue blocks indicate conv o lu tional lay ers. In each conv olutio nal laye r, k , s , an d c r epresent kern el size, stride size, and number o f channels, respectively . He r e, k1 × ∗ indicates a one-dim ensional conv olutio nal laye r w h ose kernel size is ∗ . Red blocks ind icate f ully connecte d layer . I n each fully conn ected layer, the nu mbers r epresents size of o utput unit. !"#$#%&' ! (")**)+,-)./.&01#'/2344/)0&"50)#+%6 ! 789/:#+*)'&+:&/)+0&";5< ! Fig. 2 . Result o f the AB test. The orange area ind icates the rate of the A and B pa irs for which the listeners preferr e d A (propo sed). The black bar indicates the 95% confid e n ce interval. ! ! "#$ " !%"#$ " !%"#$ " &'())(*+,(-.-"/012.3455.(/"'6/(1*%7 " 8'191%"2.-"/012 " :6';"/.26/6 " Fig. 3 . W aveforms of reco nstructed mu sic data [19]. The first row shows the acoustic sign al rec onstructed with the Griffin- Lim method, the second shows th e prop o sed method , and the third is the target acou stic signal (rea l-world acoustic signal). in vestigation o f a network arch itecture appro priate for CPU implementatio ns. 7. REFERENCES [1] P . Sm a ragdis, C. F ´ evotte, G. J. My sore, N. M oham- madiha, and M. Hoffman, “Static an d dyna m ic source separation using nonn egati ve factor izations: A un ified view , ” IEEE Signal Pr ocessing Magazine , vol. 31, no. 3, pp. 66– 75, 201 4. [2] T . V irtan en, J. Flor ent Gemme ke, B. Raj, and P . Smaragdis, “Comp ositional m odels f or audio pro c ess- ing: Uncovering the structur e o f sound mixtures, ” IEEE Fig. 4 . The chan ge in pro cessing tim e with respect to th e change in spee c h le n gth. Blue points show the proc essing time with the p roposed metho d a GPU. Green poin ts show the time with the Griffin-Lim me thod with a CPU. Orange points show the time with the pr oposed m e thod w ith a CPU. Signal Pr o cessing Magazine , vol. 3 2, no. 2, pp. 125 – 144, 2015 [3] H. Kam eoka, “Non -negativ e matrix factorization and its variants f or aud io signal processing, ” in Applied Ma - trix and T en sor V ariate Da ta An alysis , T . Sak ata (E d .), Springer Jap an, 2016 . [4] S. T akaki, H. Kameoka, an d J. Y amagishi, “Direct mod- eling of freque n cy sp ectra and wav e f orm g eneration based on phase r ecovery fo r DNN-b a sed speech syn the- sis, ” in Pr oc. Interspeech , p p. 1128– 1132, 2017 . [5] Y . W ang, RJ. Skerry -Ryan, D. Stan ton, Y . W u , R.J. W eiss, et al., “T acotro n: A fully end -to- end text-to-speec h synthesis m odel, ” arXiv preprint arXiv:1703.101 35 , 2017. [6] D. W . Griffin and J. S. Lim , “Signal e stima tion from modified short-time Fourier transfo rm, ” IE EE T rans. ASSP , vol. 32 , no. 2, p p. 23 6–243 , 19 84. [7] I. Goo d fellow , J. Poug et-Abadie, M. Mir z a, B. Xu, D. W ar de-Farley , et al., “Generative ad versarial n ets, ” in Adv . NIPS , pp. 2672– 2680, 2014 . [8] J. Le Roux, H. Kameo ka, N. On o, S. Sagay ama, “Fast sign al r e c onstruction fro m mag nitude STFT spe c - trogram based o n spec trogram con sistency , ” in Pr oc. D AFx , p p. 397–4 03, 2010 . [9] D. R. Hunter and K. Lan ge, “Quantile regression via a n MM algorithm, ” Journal of Computational and Graphi- cal Statistics , vol. 9 , p p . 60 –77, 2000. [10] J. R. Hershey , J. Le Rou x, and F . W ening er , “Deep un- folding : Model-based inspir ation o f novel d eep ar chi- tectures, ” arXiv p reprint ar X iv:1409 .2574 . [11] X. Ma o, Q. Li, H. Xie, R.Y . La u , Z. W ang, et al., “Least squ ares generative adversarial networks, ” in Pr oc. ICCV , pp. 2 8 13–28 21, 20 17. [12] M. Arjovsky , S. Chin ta la , and L. Bottou, “W a sserstein GAN, ” arX iv pr e print ar Xi v:1701 .0787 5 , 2 0 17. [13] C. V alentin i-Botinhao, “Noisy speech datab ase f or train- ing speech enhancement algo rithms an d TTS models, [dataset], ” Un iv er sity of Edinburgh. Schoo l of In format- ics. CSTR, 2016 . http://d x.doi.o rg/1 0.7488/ds/1356 . [14] K. He , X. Zh a n g, S. Ren, and J. Sun, “Delving d e ep into rectifiers: Surp assing human- level perfor mance on imagenet classification, ” in Pr oc. ICC V , pp. 10 2 6–10 3 4, 2015. [15] A.L. Maas, A.Y . Hannun , an d A.Y . Ng, “Rectifier non- linearities impr ove neura l network acoustic models, ” in Pr oc. ICML , vol. 3 0, no. 1, pp. 3, 2013 . [16] C. Led ig, L. Thesis, F . Husz ´ ar , J. Caballero, A. Cun- ningham , et al., “Photo-realistic sing le image super- resolution using a generative ad versarial network, ” arXiv prep rint arXiv:1609 .04802 , 20 16. [17] J. Lo n g, E. Shelha mer , an d T . Darr ell, “Fully conv o - lutional networks for semantic segmentation , ” in Proc. CVPR, pp. 3431 –3440 , 2015 . [18] T . T ielem an a n d G. Hinto n, “Lecture 6 .5-rmsp r op: Di- vide the gradien t by a runnin g average o f its r e c ent mag- nitude, ” COURSERA: Neur al network s f or m achine learning, vol. 4 , n o. 2, pp . 26–31 , 2012. [19] CAF ´ E DEL CHILLIA, “In Th e Story Th at W e Say , ” https://www . jamendo. com/track/1 455877/in-the-story-that-we-say , 2017. [20] S. W alt, S.C. Colbert, an d G. V aroq uaux, “The NumPy array: a structur e for e fficient numerical compu tation, ” Computing in Science & Engineering, vol. 13, no. 2 , pp. 22-3 0, 201 1 . [21] S. T ok ui, K. O o no, S. Hido, and J. Clayto n, “Chainer: a next-genera tio n open source framework f o r deep learn- ing, ” in Proc. Learning Sys in the twenty-nin th ann ual confere n ce on NI PS, vol. 5, 20 15.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment