Improving Massive MIMO Belief Propagation Detector with Deep Neural Network
In this paper, deep neural network (DNN) is utilized to improve the belief propagation (BP) detection for massive multiple-input multiple-output (MIMO) systems. A neural network architecture suitable for detection task is firstly introduced by unfold…
Authors: Xiaosi Tan (1, 2, 3)
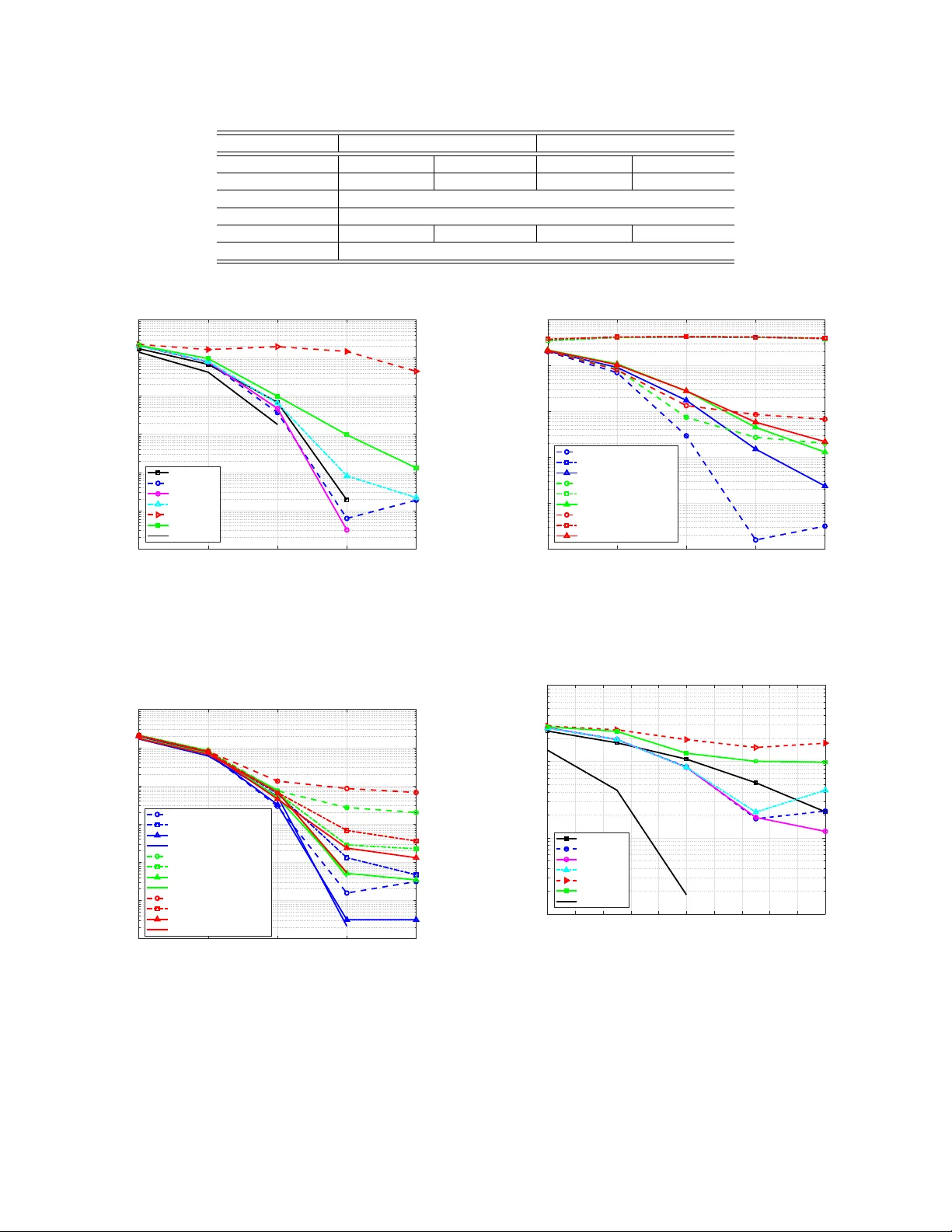
1 Impro ving Massi v e MIMO Belief Propag ation Detector with Deep Neural Network Xiaosi T an, W eihong Xu, Y air Be’ery , Senior Member , IEEE , Zaichen Zhang, Senior Member , IEEE , Xiaohu Y ou, F ellow , IEEE , and Chuan Zhang, Member , IEEE Abstract —In this paper , deep neural network (DNN) is utilized to impro ve the belief propagation (BP) detection f or massive multiple-input multiple-output (MIMO) systems. A neural net- work architecture suitable for detection task is firstly introduced by unf olding BP algorithms. DNN MIMO detectors are then pro- posed based on two modified BP detectors, damped BP and max- sum BP . The correction factors in these algorithms are optimized through deep learning techniques, aiming at improved detection performance. Numerical results are presented to demonstrate the performance of the DNN detectors in comparison with v arious BP modifications. The neural network is trained once and can be used for multiple online detections. The results show that, compared to other state-of-the-art detectors, the DNN detectors can achieve lower bit error rate (BER) with improv ed robustness against various antenna configurations and channel conditions at the same level of complexity . Index T erms —massive MIMO, deep lear ning, deep neural network, belief propagation (BP). I . I N T R O D U C T I O N W ITH the rapid traffic growth in telecommunications, systems using multiple-input multiple-output (MIMO) configurations with a large number of antennas hav e attracted a lot of attention in both academia and industry [1]. The massive MIMO system achiev es increased data rate, higher spectral efficienc y , enhanced link reliability and coverage over con ven- tional MIMO [2], which becomes one key technology for 5G wireless. Howe v er , its large scale brings unbearable pressure to signal detection in terms of computational complexity . In recent years, deep machine learning has led to a rev olution in many fields. W ith the deep learning techniques, computers can recognize relations between input and output data sets and further detect unknown objects from future inputs. The goal of this paper is to apply deep learning in the MIMO detection problem to propose a deep neural network-aided massiv e MIMO detector . A. Belief Pr opagation MIMO Detectors Many massi ve MIMO detection methods were presented, e.g., [3–6], among which the message passing approach, Xiaosi T an, W eihong Xu, and Chuan Zhang are with Lab of Efficient Architectures for Digital-communication and Signal-processing (LEADS), Southeast Univ ersity , Nanjing, China. Xiaosi T an, W eihong Xu, Zaichen Zhang, Xiaohu Y ou, and Chuan Zhang are with the National Mobile Commu- nications Research Laboratory , Southeast University , Nanjing, China. Xiaosi T an, W eihong Xu, Zaichen Zhang, and Chuan Zhang are with Quantum In- formation Center of Southeast Uni versity , Nanjing, China. E-mail: { tanxiaosi, wh.xu, zczhang, xhyu, chzhang } @seu.edu.cn. (Corr esponding author: Chuan Zhang.) Y air Be’ery is with the School of Electrical Engineering, T el-A viv Univ er- sity , T el-A viv , Israel. E-mail: ybeery@eng.tau.ac.il. belief propagation (BP), has been paid intensiv e attentions and broadly researched in recent years. BP detectors provides a superior performance in comparison to the aforementioned detection algorithms due to its lo wer -complexity , strong ro- bustness and also the so-called large-dimension beha vior , i.e., the detection performance is closer to optimal as the MIMO dimension increases [7, 8]. Ho we ver , it has some drawbacks when dealing with practical problems: 1) Loopy factor graph: The factor graphs defined by typ- ical MIMO channels are fully-connected, hence heav- ily loopy . The BER performance of BP suffers se vere degradation due to the loopiness, especially in practical channels which are spatially correlated fading. 2) Complexity: BP detectors are still of high complexity that implies lar ge delay and implementation difficulties, which are critical for some delay sensitive applications. Some modifications of BP have been proposed to handle these issues, among which we focus on the following methods: 1) Damped BP: BP with damping, or damped BP , is an efficient way to overcome the poor performance due to the cycles in factor graphs. It is a BP v ariant by averaging the two successive messages with a weighting factor (also called damping factor). It was observed in many works, e.g., [7 – 10], that the damping could improve the con ver gence of the BP algorithms. Indeed, damping is also applied in other message passing methods like approximate message passing (AMP) [11] to facilitate conv ergence [12]. • Challenges: The optimal damping factors are dif ficult to find. The av ailable method relies on the Monte Carlo sim- ulations which brings overwhelming computation burden. In [13], a heuristic automatic damping (HAD) method is proposed to automatically calculate the damping factor in each BP iteration, which improves the ef ficiency but still requires extra online calculation. 2) Max-Sum Algorithm: In [14], a max-sum (MS) algo- rithm is proposed to further reduce the computational com- plexity of BP with an approximation strategy . The normalized MS (NMS) and offset MS (OMS) are presented as an e xtension of MS in order to compensate for the performance degradation resulting from approximation operation. • Challenges: The normalized factor in NMS and of fset factor in OMS make a great influence to the performance improv ement, ho wev er, are hard to decide. [14] provides a method to update the factors based on the approximated prior probabilities and pre-computed errors, which also requires extra computation at each iteration. 2 Overall, the enhancements achiev ed by the modified BP algorithms mentioned above rely on the selection of the correction parameters including the damping, normalized and offset factors. Further improvements are demanded for: • A framework to optimize the correction factors efficiently with acceptable computational complexity; • Improv ed robustness against different channel conditions; • Outperming or le veling linear detectors under v arious antenna configurations and modulations. B. Deep Neural Network Deep learning (DL) has attracted worldwide attentions due to its po werful capabilities to solve complex tasks. W ith the advances in big data, optimization algorithms and stronger computing resources, such networks are currently state of the art in dif ferent problems including speech processing [15] and computer vision [16]. In recent years, deep learning methods have been purposed for communication problems. For instance, various channel decoders using deep learning techniques were proposed as in [17 – 19]. There were also man y works on learning to in vert linear channels and reconstruct signals [20 – 22]. [23] proposed to learn a channel auto-encoder via deep learning technologies. In the conte xt of massi ve MIMO detection, research has also been done. In [24], a deep learning network for MIMO detec- tion named DetNet is deri ved by unfolding a projected gradient descent method based on the linear detection algorithm. The work in [25] is based on virtual MIMO blind detection clustered WSN system and applies impro ved hopfield neural network (HNN) blind algorithm to this system. Also, deep learning techniques has been applied for symbol detection in MIMO-OFDM systems as introduced in [26, 27]. In particular , one promising approach to design deep archi- tectures is by unfolding an existing iterati ve algorithm [20]. Each iteration is considered a layer and the algorithm is called a network. The learning begins with the existing algorithm as an initial starting point and uses optimization methods to find optimal parameters and improv e the algorithm. From this point of vie w , the deep learning techniques provide a po werful tool to decide the optimal correction factors for the modified BP algorithms to achiev e improv ed performance. C. Contributions In this paper , to the best of the authors’ knowledge, a novel DNN MIMO detector based on the modified BP detectors is proposed for the first time. The main contributions are: • W e propose a formal framework to design a DNN MIMO detector by unfolding the BP iterations. T wo DNN MIMO detectors are introduced based on the damped BP and MS algorithms respecti vely . The deep learning techniques are utilized to decide the optimal correction factors. • Numerical results are presented to show the improv ed ro- bustness and adv anced performance of the DNN detectors compared with other BP variants and linear methods as the minimum mean-squared error (MMSE) approach. • W e show that the proposed framew ork is univ ersal for various channel conditions and antenna configurations. • The computational complexity of the DNN detectors is discussed. F or online detections, the DNN detectors achiev e improved performance at the same level of com- plexity as the other BP variants. • T raining methodology is discussed with details. W e sho w the ability of the proposed DNN detector to handle multiple channel conditions with one single training. D. P aper Outline The remainder of this paper is or ganized as below . Back- grounds of BP MIMO detectors are introduced in Section II, in which the modified BP methods including damped BP , MS, NMS and OMS are also introduced. In Section III, we present the corresponding deep neural network MIMO detector based on modified BP algorithms. Section IV shows details of the proposed deep neural network detector , its training procedure, and numerical results. Section V concludes this paper . E. Notations Throughout the paper , we use the following notations. Lowercase letters (e.g., x ) denote scalars, bold lo wercase letters (e.g., x ) denote column v ectors, and bold uppercase letters (e.g., X ) denote matrices. Also, the symbol I denotes the identity matrix; log( · ) denotes the natural logarithm; and C N ( x , σ 2 ) denotes the complex Gaussian function. I I . P R E L I M I N A RY A. MIMO System Model In this paper , we consider a MIMO system with M trans- mitting and N receiving antennas. Each user sends an inde- pendent data stream and the base station detects the spatially multiplex ed data through MIMO detection. The recei ved signal vector , y ∈ C N × 1 , reads y = Hx + n , (1) where x ∈ Θ M is the transmitted symbol vector , with the constellation Θ = { s 1 , s 2 , . . . , s K } , K is determined by modulation mode; n is the additive white Gaussian noise (A WGN) following C N (0 , σ 2 I M ) ; H denotes the channel matrix which can be described by the Kronecker model H = R 1 2 r H w R 1 2 t (2) according to [28], where R r and R t are the antenna correla- tion matrices at the receiv er and transmitter side respectiv ely , and H w is i.i.d. Rayleigh-fading channel matrix following independent Gaussian distribution. B. Belief Pr opagation Detector MIMO systems can be modeled by a factor graph as in Fig. 1 according to [29]. BP allows observation nodes to transfer belief information with symbol nodes back and forth to iterati vely improve the reliability for decision. The message updating at observation and symbol nodes at the l -th iteration is summarized in the following equations: 3 • Symbol nodes: α ( l ) ij ( s k ) = N X t =1 ,t 6 = j β ( l − 1) ti ( s k ) , (3) p ( l ) ij ( x i = s k ) = exp( α ( l ) ij ( s k )) P K m =1 exp( α ( l ) ij ( s m )) , (4) • Observation nodes: β ( l ) j i ( s k ) = log p ( l ) ( x i = s k | y j , H ) p ( l ) ( x i = s 1 | y j , H ) , (5) where α ij denotes the prior log-likelihood ratio (LLR), β j i denotes the posterior LLR and p ij is the prior probability of each symbol. The soft output after L iteration is given by γ i ( s k ) = N X t =1 β ( L ) ti ( s k ) , (6) and the s k that maximize γ i ( s k ) is chosen as the final decision of the receiv ed signal. More details of BP are given in [7]. x 1 x 2 . . . x M y 1 y 2 y 3 . . . y N a prior information a p osteriori information Sym b ol no des Observ ation nodes Fig. 1. Factor Graph of a large MIMO system. As the factor graph defined by the dense MIMO channel matrix is loopy as shown in Fig. 1, BP is not guaranteed to con ver ge to the MAP . The antenna correlation can even aggrav ate the looping effect due to the less randomness in the channel matrix which brings degradation in results [30]. Also, for each iteration, one division operation is needed to calculate the prior messages in Eq. (4), which brings difficulty to hardware implementation. From this viewpoint, two modifications of BP have been proposed to enhance the performance. C. Modified BP Detectors 1) Damped BP: Message damping is a judicious option to mitigate the problem of loopy BP without additional complex- ity . With damped BP , the messages p ( l ) ij at the l -th iteration in Eq. (4) can be smoothed as p ( l ) ij ⇐ (1 − δ ) p ( l ) ij + δ p ( l − 1) ij , (7) where the symbol ” ⇐ ” denotes the assignment, δ ∈ [0 , 1] is the damping factor to make a weighted average of the current calculated messages and the previous calculated messages. It was observed in aforementioned works like [7, 8] that the damping could improv e the con vergence of the BP algorithms. Howe ver , the optimal damping factor is difficult to find. The av ailable method relies on the bulk y Monte Carlo simulations. In [13], the HAD method is proposed to automatically calcu- late the damping factor in each BP iteration. Specifically , the con vergence of the messages can be measured by the closeness between the two successive messages, p ( l ) ij and p ( l − 1) ij , with the Kullback-Leibler div ergence: d ( l ) ij = K X k =1 p ( l ) ij ( s k ) log p ( l ) ij ( s k ) p ( l − 1) ij ( s k ) . (8) As we have M × N message vectors in total, the Kullback- Leibler diver gence of the two successiv e messages can be finally averaged as d ( l ) = 1 M N M X i =1 N X j =1 d ( l ) ij . (9) The heuristic damping factor in the l -th iteration is then defined as δ ( l ) = d ( l ) d ( l ) + c , (10) where c is a positiv e constant determined with d (1) of the first iteration. This method shows improved con vergence per- formance compared with BP , but requires online updates of the damping factor at each iteration, which leads to extra computational cost. More details can be found in [13]. 2) Max-Sum Algorithm: The max-sum (MS) algorithm is an approximation strategy of BP . The calculation of the prior probability at each iteration is simplified to eliminate the di vi- sion operation, which relieves the great dif ficulty of hardware implementation with some performance loss. Specifically , by taking logarithm for both sides of Eq. (4) and substitute the resulted summation P K m =1 exp( α ( l ) ij ( s m )) with the dominant term exp( max s m ∈ Ω { α ( l ) ij ( s m ) } ) , we get p ( l ) ij ( x i = s k ) = exp( α ( l ) ij ( s k ) − max s m ∈ Ω { α ( l ) ij ( s m ) } ) . (11) It is clearly seen that the elimination of the division in Eq. (11) reduces the hardware complexity greatly . Ho wev er , the prior probabilities are ov erestimated o wing to the approximation, which results in performance degradation. T o compensate the loss while keeping similar computational complexity , we can apply two modified approaches, the normalized MS (NMS) and the offset MS (OMS) algorithm. Let P 1 and P 2 denote the prior probability v alues calculated by Eq.s (4) and (11). As discussed above, P 2 will be slightly larger than P 1 . NMS aims at multiplying P 2 with a positive scale factor λ < 1 to get a better approximation, while OMS is dedicated to subtracting an offset factor ω < 1 from P 2 . Combining both modifications, the prior probability is computed as follows: f P 1 = λ · P 2 − ω , λ < 1 , ω < 1 . (12) T o accomplish performance enhancement, the values of λ and ω should be carefully selected. [14] proposed an 4 interpolation method to choose the optimal factors. Basically , P 1 and P 2 are pre-computed at sampled values of α ’ s, then the corresponding correction factors can be computed to minimize the error of f P 1 at each v alue of α . During the detection iterations, the correction factors are picked from the pre- computed list by nearest-neighbor interpolation of α . In [14], this method shows promising performance with QPSK. I I I . P R O P O S E D D N N M I M O D E T E C T O R In this section, we propose a deep neural network (DNN) MIMO detector based on the modified BP algorithms intro- duced in Section II-C. The neural network is constructed by unfolding BP algorithms, mapping each iteration as a layer in the network. The damping, normalized and offset factors are the parameters to be optimized, and will be ”learned” by the deep learning techniques. A. Deep Neural Network Deep neural network (DNN), also often called deep feedfor- ward neural network, is one of the quintessential deep learning models. A deep neural network model can be abstracted into a function f that maps the input x 0 ∈ R N 0 to the output y ∈ R N L , y = f ( x 0 ; θ ) , (13) where θ denotes the parameters that result in the best function approximation of mapping the input data to desirable outputs. In general, a DNN has a multi-layer structure, composing together many layers of function units (see Fig. 2). Between the input and output layers, there are multiple hidden layers. For an L -layer feed-forward neural network, the mapping function in the l -th layer with input x l − 1 from ( l − 1) -th layer and output x l propagated to the next layer can be defined as x l = f ( l ) ( x l − 1 ; θ l ) , (14) where θ l denotes the parameters of l -th layer, and f ( l ) ( x l − 1 ; θ l ) is the mapping function in l -th layer . . . . . . . . . . . . . Input lay er Hidden lay ers Output lay er Fig. 2. Architecture of a deep neural network. According to [20], a DNN can be designed by unfolding the BP algorithm, mapping each iteration to a layer in the network. This is resulted from the similarities between the BP factor graph and deep neural network, which are summarized in T able I. The BP algorithm is then improved by the deep learning optimization methods. Hence, a DNN-aided MIMO detector can be dev eloped by unfolding the BP detection algorithm, which is introduced in the following section. T ABLE I B P F G V S . D N N : T H E S I M I L A R I T I E S BP FG DNN Nodes Neurons T ransmitted signals x Input data x Receiv ed signals y Output data y l -th iteration l -th hidden layer Belief messages α ( l ) , β ( l ) , p ( l ) Hidden signals x l Message updating rules Eq. (3)-(5) Mapping function between layers Eq. (17) Correction factors δ , λ , ω Parameters θ B. Multiscale Corr ection F actors The purpose of the damping, normalized and offset factors are to ”correct” the iterated BP messages, hence we call them the correction factors. In damped BP , the damping factors are varying at each iteration. In the selection of the normalized/offset factors for MS, we further e xtend those factors to be different for each message p ( l ) ij . Actually , all the correction factors can be set distinct for each message at each iteration, and the calculation of the prior probability can be expressed in a more generalized way . Specifically , by extending the damping factors, Eq. (7) can be re-written as p ( l ) ij ⇐ (1 − δ ( l ) ij ) p ( l ) ij + δ ( l ) ij p ( l − 1) ij , (15) which forms a multi-scale damped BP . Meanwhile, damping can also be utilized in the MS algorithm to form a damped OMN/NMS. Combining Eq.s (7) and (12) we get p ( l ) ij ⇐ (1 − δ ( l ) ij ) λ ( l ) ij p ( l ) ij − ω ( l ) ij + δ ( l ) ij p ( l − 1) ij , (16) which is a multiple scaled damped MS approximation. These extensions aim at further improvement of the per- formance. Howe ver , they also result in a greater number of parameters to be optimized, especially when the number of antennas are large. This is a complex optimization problem for traditional approaches, but can be handled by the powerful tools in deep learning. C. The DNN Detector As described in Section II-B, at the l -th iteration in BP , with the messages α ( l − 1) = { α ( l − 1) ij } and p ( l − 1) = { p ( l − 1) ij } from the previous layer l − 1 , we update β ( l ) = { β ( l ) ij } at the observation nodes, and then α ( l ) = { α ( l ) ij } and p ( l ) = { p ( l ) ij } are updated at the symbol nodes. This process counts as a full iteration step in BP , which can be mapped to a hidden layer in a deep neural network. In this way the BP detector is unfolded to construct a DNN detector . Let ∆ denote the set of the parameters to be optimized, our DNN detector can be described as following, 5 T ABLE II S U M M A RY O F TH E PR O P O S E D D N N M I M O D E T E C T O R S : DN N - D B P AN D DN N - M S Method DNN-dBP DNN-MS The iterative algorithm Damped BP [7] Max-Sum BP [14] T raining parameters ∆ δ δ , λ , ω Inputs x , δ (0) , p (0) ij x , δ (0) , λ (0) , ω (0) , p (0) ij Mapping functions f ( l ) at the l -th iteration β ( l ) j i ( s k ) = log p ( l − 1) ( x i = s k | y j , H ) p ( l − 1) ( x i = s 1 | y j , H ) α ( l ) ij ( s k ) = P N t =1 ,t 6 = j β ( l ) ti ( s k ) p ( l ) ij ( x i = s k ) = exp( α ( l ) ij ( s k )) P K m =1 exp( α ( l ) ij ( s m )) p ( l ) ij ⇐ (1 − δ ( l ) ij ) p ( l ) ij + δ ( l ) ij p ( l − 1) ij β ( l ) j i ( s k ) = log p ( l − 1) ( x i = s k | y j , H ) p ( l − 1) ( x i = s 1 | y j , H ) α ( l ) ij ( s k ) = P N t =1 ,t 6 = j β ( l ) ti ( s k ) p ( l ) ij ( x i = s k ) = exp( α ( l ) ij ( s k ) − max s m ∈ Ω { α ( l ) ij ( s m ) } ) p ( l ) ij ⇐ (1 − δ ( l ) ij ) λ ( l ) ij p ( l ) ij − ω ( l ) ij + δ ( l ) ij p ( l − 1) ij Loss function L ( x , O ) = − 1 M M P i =1 K P k =1 x i ( s k ) log( O i ( s k )) { α ( l ) , β ( l ) , p ( l ) } = f ( l ) ( α ( l − 1) , β ( l − 1) , p ( l − 1) ; ∆ ( l ) ) , γ = o ( β ( L ) ) , O = σ ( γ ) , (17) where f ( l ) ( α ( l − 1) , β ( l − 1) , p ( l − 1) ; ∆ ( l ) ) summarizes the l -th iteration in modified BP algorithms with Eq.s (3), (5), and (15) or (16). γ is the soft output with o denotes Eq. (6), and O is the output of the DNN while σ denotes a sigmoid or a softmax function which rescales γ into range [0 , 1] . W ith the two modified BP algorithms in Section II-C, two different DNN detectors are proposed as in T able II: • DNN-dBP: When we deriv e the DNN based on damped BP , Eq. (15) is used and ∆ = { δ (1) , . . . , δ ( L ) } , where δ ( l ) = { δ ( l ) ij } are the damping factors at each layer . For simplicity , we denote this method as DNN-dBP . • DNN-MS: When the damped MS is applied, p ( l ) ’ s are computed by Eq. (16). In this case, ∆ = { δ (1) , . . . , δ ( L ) , λ (1) , . . . , λ ( L ) , ω (1) , . . . , ω ( L ) } , where δ ( l ) = { δ ( l ) ij } are the damping factors, λ ( l ) = { λ ( l ) ij } are the normalized factors and ω ( l ) = { ω ( l ) ij } are the offset factors at each iteration. This algorithm is called DNN-MS in the following context. An example of the structure of the proposed DNN detectors is sho wn in Fig. 3 with three BP iterations presented. Suppose the MIMO system considered includes M transmitting and N receiving antennas. In general, the input layer has M elements which are initialized with the prior information. For a detector with L BP iterations, the DNN will contain L hidden layers, each layer contains M blue neurons that corresponds to f in Eq. (17), which represents a full iteration in BP of updating the posterior then the prior messages. The choice of f depends on the different modified BP algorithms. Finally , the output layer contains the sigmoid/softmax neurons. T o increase the number of iterations in the DNN detector , we only need to concatenate a certain amount of identical hidden layers with blue neurons in Fig. 3 between the input and output layers. The cross entropy is adopted to e xpress the expected loss of the neural network output O and the transmitted symbol x , . . . . . . . . . . . . . . . R R R R Input lay er Hidden lay ers Output lay er One BP iteration step Fig. 3. The structure of the DNN detector with 2 BP iterations. which e valuates the performance of the detector as following: L ( x , O ) = − 1 M M X i =1 K X k =1 x i ( s k ) log ( O i ( s k )) . (18) The mini-batch stochastic gradient descent (SGD) method is used to minimize the loss function L and decide the optimal damping factors ( ∆) . With the aid of advanced DL libraries like T ensorflow [31], optimizations can be done efficiently . I V . N U M E R I C A L R E S U LT S For i.i.d. Rayleigh and correlated fading MIMO channels with different antenna configurations, numerical results of the proposed DNN detectors are giv en. DNN detector based on damped BP , the DNN-dBP , and DNN detector with MS, the DNN-MS, are both considered. MMSE results are set as benchmarks, and the performance of DNN is compared with the plain BP algorithm, the original MS algorithm and HAD. The BP algorithms in this paper are all based on the real domain single-edged BP as introduced in [7]. The modulation of 16 -QAM is used for all simulations. No channel coding is considered. 6 0 5 10 15 20 Average Received SNR(dB) 10 -6 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 BER L=5 L=6 L=7 L=8 L=9 Fig. 4. The BER performance of DNN-dBP with M = 8 , N = 32 with different number of hidden layers L . A. DNN Ar chitectur e and T raining Details T o numerically demonstrate the performance of the pro- posed DNN MIMO detector , the architecture of the neural network should be carefully selected. The settings of DNN- dBP and DNN-MS in our simulations are summarized in T able III, and details of these settings are discussed in this section. 1) Configurations and neur ons: As described in Section III-C, the number of neurons are selected simply according to the number of the transmitting antennas M . Define ρ = M / N as the system loading factor . T wo types of antenna config- urations are considered in our simulations: the symmetric configuration ( ρ = 1 ) with M = N = 16 and the asymmetric configuration ( ρ < 1 ) with M = 8 , N = 32 . 2) The depth of DNN: The depth of the DNN relates to the number of BP iterations, which is another vital factor for implementation. As mentioned in Section III-C, if the number of iterations is L , the depth of the network will also be L . T o properly select L , it’ s important to keep a good balance between the BER performance and the complexity . In our case, L is decided with a greedy search method as follo ws: (i) A searching range of possible values of L , [ l min , l max ] , is decided by the BER performance of the original BP . This is based on the observation in the previous researches that with the same number of iterations, damped BP should show better performance. (ii) Starting with the smallest value L = l min , we train the DNN detectors and test the trained network to obtain the BER performance, till it plateaus. (iii) For simplic- ity , this process is done once for each antenna configuration of DNN-dBP and DNN-MS in i.i.d. channels. For instance, in the asymmetric configuration case of DNN-dBP , we set [5 , 9] as the searching range, and the BER performance of the trained DNN-dBP is shown in Fig. 4. From which we pick L = 7 . 3) T raining details: The DNN is implemented on the advanced deep learning framework T ensorflow [31]. W e train the network using a variant of the SGD method for optimizing deep networks, named Adam Optimizer [32]. The signal-to- noise ratios (SNRs) are ranging from 0 dB to 20 dB (every 5 dB). W e used batch training with 100 random data samples ( 20 for each SNR step) at each iteration. For DNN-dBP , the network was trained for 5 , 000 iterations, and the DNN-MS case was trained for 10 , 000 iterations. Notice that only one offline training is performed for each antenna configuration in each case, and all the simulation results in different chan- nel conditions are calculated with this trained network. The training parameters are all initialized as 0 . 5 . B. Numerical Results 1) Asymmetric Antenna Configuration: In the simulations with asymmetric antenna configuration, M = 8 , N = 32 , and ρ = 0 . 25 . The depth of the DNN is set as L = 7 for DNN-dBP and L = 10 for DNN-MS. Fig. 5 shows the BER performance curve of DNN-dBP and DNN-MS in i.i.d. Rayleigh fading channels, and the results of MMSE, original BP , MS and HAD are also sho wn for comparison, together with BER performance in single-input single-output (SISO) channel with A WGN. The proposed DNN-dBP achie ves similar perfor- mance as the original BP , and shows improv ed stability and outperforms original BP and MMSE at higher SNRs. F or instance, at a BER of 10 − 3 , the performance gap between BP and DNN-dBP is negligible, while the HAD result has a degradation of 1 dB. Meanwhile, the MS detection shows very large performance degradation due to the prior approximation, but DNN-MS can achie ve a great improv ement. Ho we ver , the loss is still lar ge compared with BP , as at a BER of 10 − 3 , the degradation of DNN-MS already reaches 4 dB. The simulation results in correlated channels are shown in Fig.s 6 and 7, in which the correlation coefficient of transmitting (Tx) or receiving (Rx) antennas is set as 0.3. In Fig. 6, the proposed DNN-dBP is compared with original BP and HAD. W ith the correlations considered, all the algorithms except MMSE suf fer performance loss compared with the i.i.d. channels, among which Tx and Rx-Tx correlated channels show larger degradation. Howe ver , DNN-dBP outperforms the other methods greatly in all the correlation types, especially at higher SNRs. The results of the proposed DNN-MS are shown in Fig. 7 along with original BP and MS. In the correlated cases, the performance of MS shows an larger gap compared to BP , while DNN-MS achiev es improv ements. In the Rx correlated channels, the results from DNN-MS still shows a large degradation from BP . Ho we ver in the Tx and Rx-Tx correlated channels, the results of DNN-MS is close to BP , with some degradation at lower and medium SNR, but better performance at larger SNR. 2) Symmetric Antenna Configuration: In the symmetric antenna configuration, we consider M = 16 , N = 16 , and hence ρ = 1 . The depth of the network is set as L = 15 . In Fig. 8, the simulation results of MMSE, BP , HAD, MS and the DNN detectors in i.i.d. channels are giv en. The performance of BP , HAD and DNN-dBP and MMSE are similar in this case. MS results shows large degradation from BP . DNN- MS results achiev e some improvements, howe ver , are still far from satisfying. Fig. 9 sho ws the results of BP , HAD and DNN-dBP in correlated channels with correlation coefficients set as 0.3. In all different types of correlations, DNN-dBP outperforms BP while sho ws slightly better results compared 7 T ABLE III T H E S E T T I N G S O F DN N - D B P AN D D N N - M S D E T E C T O R S I N T H E N U M E R I C A L T E S T S . Method DNN-dBP DNN-MS Antenna configuration M = 8 , N = 32 M = 16 , N = 16 M = 8 , N = 32 M = 16 , N = 16 Hidden Layers L 7 15 15 15 SNRs for training { 0 , 5 , 10 , 15 , 20 , 25 } dB Mini-batch size 100 Size of training data 500 , 000 500 , 000 1 , 000 , 000 1 , 000 , 000 Optimization method Adam optimizer 0 5 10 15 20 Average Received SNR(dB) 10 -6 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 BER MMSE BP DNN-dBP HAD MS DNN-MS SISO, AWGN Fig. 5. Performance comparison of MMSE, BP , DNN-dBP , HAD, MS and DNN-MS in i.i.d. Rayleigh channels with asymmetric antenna configuration ( M = 8 , N = 32 ). 0 5 10 15 20 Average Received SNR(dB) 10 -6 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 BER Rx correlation, BP Rx correlation, HAD Rx correlation, DNN-dBP Rx correlation, MMSE Tx correlation, BP Tx correlation, HAD Tx correlation, DNN-dBP Tx correlation, MMSE Rx-Tx correlation, BP Rx-Tx correlation, HAD Rx-Tx correlation, DNN-dBP Rx-Tx correlation, MMSE Fig. 6. Performance comparison of MMSE, BP , DNN-dBP and HAD in different correlated channels with asymmetric antenna configuration ( M = 8 , N = 32 ). with HAD. Fig. 10 shows the results of BP , MS and DNN-MS in the correlated channels. Similar to the i.i.d. cases, DNN-MS curves show great improv ements compared with MS, but still hav e great degradation from BP results. 0 5 10 15 20 Average Received SNR(dB) 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 BER Rx correlation, BP Rx correlation, MS Rx correlation, DNN-MS Tx correlation, BP Tx correlation, MS Tx correlation, DNN-MS Rx-Tx correlation, BP Rx-Tx correlation, MS Rx-Tx correlation, DNN-MS Fig. 7. Performance comparison of MMSE, BP , MS and DNN-MS in dif ferent correlated channels with asymmetric antenna configuration ( M = 8 , N = 32 ). 0 2 4 6 8 10 12 14 16 18 20 Average Received SNR(dB) 10 -3 10 -2 10 -1 10 0 BER MMSE BP DNN-dBP HAD MS DNN-MS SISO, AWGN Fig. 8. Performance comparison of MMSE, BP , damped BP , HAD, DNN, MS and MS-DNN detectors in i.i.d. Rayleigh channels with symmetric antenna configuration ( M = 16 , N = 16 ). C. P erformance Evaluation of the Pr oposed DNN Detectors 1) DNN-dBP r educes BER in corr elated channels: As pre- sented in Fig.s 5 and 8, DNN-dBP sho ws similar performance as the original BP in i.i.d. channels. Howe ver , in Figs. 6 and 9, DNN-dBP achiev es great improvements in channels with different correlations. This is consistent with the purpose of 8 0 5 10 15 20 Average Received SNR(dB) 10 -2 10 -1 10 0 BER Rx correlation, BP Rx correlation, HAD Rx correlation, DNN-dBP Rx correlation, MMSE Tx correlation, BP Tx correlation, HAD Tx correlation, DNN-dBP Tx correlation, MMSE Rx-Tx correlation, BP Rx-Tx correlation, HAD Rx-Tx correlation, DNN-dBP Rx-Tx correlation, MMSE Fig. 9. Performance comparison of MMSE, BP , damped BP , DNN detectors in MIMO channels considering channel correlations with symmetric antenna configuration ( M = 16 , N = 16 ). 0 5 10 15 20 Average Received SNR(dB) 10 -2 10 -1 10 0 BER Rx correlation, BP Rx correlation, MS Rx correlation, DNN-MS Tx correlation, BP Tx correlation, MS Tx correlation, DNN-MS Rx-Tx correlation, BP Rx-Tx correlation, MS Rx-Tx correlation, DNN-MS Fig. 10. Performance comparison of MMSE, BP , MS and MS-DNN detectors in MIMO channels considering channel correlations with symmetric antenna configuration ( M = 16 , N = 16 ). damping: to mitigate the problem of loopy BP in spatially correlated channels. 2) DNN-MS ac hieves better performance compared to MS: The results of the original MS show large degradation due to the approximation of the priors. With DNN-MS, the BER curves are getting much closer to BP results, especially in the correlated channels according to Figs. 7 and 10. Howe ver , the detection performance of DNN-MS is still far from satisfying in the tests. 3) DNN detectors perform better with ρ < 1 : W ith the asymmetric antenna configuration, both DNN-dBP and DNN- MS achieve great performance improvements. DNN-BP out- performs BP and HAD as presented in Fig.s 5 and 6, while DNN-MS reaches comparable results with BP . Howe ver , when ρ = 1 , the gain of the DNN detectors is limited as shown in Fig.s 8 and 10. D. Complexity Analysis 1) Offline T raining: In our numerical tests, we train the network once for each antenna configuration with each DNN detector . The training requires a large amount of data ac- cording to T able III. The total computational cost of training depends on the amount of these inputs, S , hence is of high complexity as shown in T able IV. Ho wever , the training is done offline, and the complexity can be handled by powerful computational and storage de vices. The trained network can be stored for multiple online uses. Another inevitable issue of the DNN is that the ”optimized” network depends on the range of the training data. In practical problems, the training data should be generated with certain scenarios that we focus on to reach optimal performance. 2) Online Detection: The computational complexity of the proposed DNN detectors are compared with the other BP algorithms in T able IV. The BP modifications we consider are based on the real domain single-edged BP detector proposed in [8], which achiev es reduced complexity of order O ( M N ) at each iteration. All the presented methods, including original BP , HAD, MS and the proposed DNN-dBP and DNN-MS, share the same posterior message updating rule, which requires O ( M N ) complexity per iteration. In the calculation of prior probabilities, original BP , HAD and DNN-BP require O ( M ) division operations at each iteration, which are unnecessary in MS and DNN-MS. And in HAD, the computation for the adaptiv e damping factors brings extra complexity of order O ( M N ) at each iteration. Howe ver , the o verall complexity of all the methods is of the order O ( M N L ) . Hence, the proposed DNN-dBP achieves improv ed BER performance with the same computation complexity as the original BP . DNN-MS detection reduces the complexity by eliminating divisions that are difficult to implement, and it outperforms the MS algorithms significantly without extra computational cost. The recently proposed DNN based MIMO detector , DetNet[24], shows advantages in the sense that the kno wledge of the channel noise variance or SNR level is not required. It is based on a linear method which is not our focus and hence is fundamentally different from our work which requires channel estimation kno wledge. It achiev es great performance at a similar level of complexity for online detection of O ( M N L ) . Howe ver , a large number of hidden layers of DNN is needed to get satisfactory results, which also adds to the burden of the offline training cost. T ABLE IV C O M P L E X I T Y CO M PA R I S O N O F TH E D E T E C T I O N M E T H O D S Method Post.&Prior Factors T raining BP[7] O (( √ K − 1) M N L ) - - HAD[13] O (( √ K − 1) M N L ) O ( M N L ) - MS[14] O (( √ K − 1) M N L ) - - DNN-dBP O (( √ K − 1) M N L ) - O ( M N LS ) DNN-MS O (( √ K − 1) M N L ) - O ( M N LS ) 9 V . C O N C L U S I O N In this paper, we present a no vel framework of deep neural network MIMO detectors. The two proposed DNN detectors, DNN-dBP and DNN-MS, are designed by unfolding damped BP and MS BP algorithms, respecti vely . The architecture of the DNN detectors and the training strategies are discussed for implementation. Numerical results with different antenna configurations and v arious channel conditions are illustrated to show the adv anced performance of the proposed detection methods. The future work will be directed towards further op- timization of the DNN structure and ef ficient training methods. Also, this frame work can be applied to improve other iterative algorithms as AMP . A C K N O W L E D G E M E N T The authors would like to thank Alex Y ufit for useful discussion. R E F E R E N C E S [1] T . L. Marzetta, “Noncooperative cellular wireless with unlimited num- bers of base station antennas, ” IEEE T rans. W ir eless Commun. , vol. 9, no. 11, pp. 3590–3600, 2010. [2] F . Rusek, D. Persson, B. K. Lau, E. G. Larsson, T . L. Marzetta, O. Edfors, and F . Tufv esson, “Scaling up MIMO: Opportunities and challenges with very lar ge arrays, ” IEEE Signal Pr ocess. Mag. , v ol. 30, no. 1, pp. 40–60, 2013. [3] X. Y uan, L. Ping, C. Xu, and A. Kavcic, “ Achievable rates of MIMO systems with linear precoding and iterati ve LMMSE detection, ” IEEE T rans. Inf. Theory , vol. 60, no. 11, pp. 7073–7089, 2014. [4] A. K. Sah and A. Chaturvedi, “ An MMP-based approach for detection in large MIMO systems using sphere decoding, ” IEEE W ireless Commun. Mag. , vol. 6, no. 2, pp. 158–161, 2017. [5] P . Li and R. D. Murch, “Multiple output selection-LAS algorithm in large MIMO systems, ” IEEE Commun. Lett. , vol. 14, no. 5, 2010. [6] N. Srinidhi, S. K. Mohammed, A. Chockalingam, and B. S. Rajan, “Low-comple xity near -ML decoding of large non-orthogonal STBCs using reactiv e tabu search, ” in Proc. of IEEE International Symposium on Information Theory (ISIT) , 2009, pp. 1993–1997. [7] J. Y ang, C. Zhang, X. Liang, S. Xu, and X. Y ou, “Improved symbol- based belief propagation detection for large-scale MIMO, ” in Pr oc. of IEEE W orkshop on Signal Pr ocessing Systems (SiPS) , 2015, pp. 1–6. [8] J. Y ang, W . Song, S. Zhang, X. Y ou, and C. Zhang, “Low-comple xity belief propagation detection for correlated large-scale MIMO systems, ” Journal of Signal Pr ocessing Systems , pp. 1–15, 2017. [9] K. P . Murphy , Y . W eiss, and M. I. Jordan, “Loopy belief propagation for approximate inference: An empirical study , ” in Pr oc. of the 15th confer ence on uncertainty in artificial intelligence . Morgan Kaufmann Publishers Inc., 1999, pp. 467–475. [10] Q. Su and Y .-C. Wu, “On conv ergence conditions of gaussian belief propagation. ” IEEE T rans. Signal Pr ocess. , vol. 63, no. 5, pp. 1144– 1155, 2015. [11] C. Jeon, R. Ghods, A. Maleki, and C. Studer , “Optimality of large MIMO detection via approximate message passing, ” in Proc. of IEEE International Symposium on Information Theory (ISIT) , 2015, pp. 1227– 1231. [12] Mhlaliseni, Khumalo, W an-Ting, and Chao-Kai, “Fixed-point implemen- tation of approximate message passing (AMP) algorithm in massi ve MIMO systems, ” Digital Communications and Networks , vol. 2, no. 4, pp. 218–224, 2016. [13] Y . Gao, H. Niu, and T . Kaiser , “Massive MIMO detection based on belief propagation in spatially correlated channels, ” in Proc. of 11th International ITG Conference on Systems, Communications and Coding (SCC) , 2017, pp. 1–6. [14] Y . Zhang, L. Ge, X. Y ou, and C. Zhang, “Belief propagation detection based on max-sum algorithm for massi ve MIMO systems, ” in Pr oc. of 9th International Confer ence on W ireless Communications and Signal Pr ocessing (WCSP) , 10 2017, pp. 1–6. [15] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in Proc. of IEEE Conference on Computer V ision and P attern Recognition (CVPR) , 2016, pp. 770–778. [16] G. Hinton, L. Deng, D. Y u, G. E. Dahl, A.-r . Mohamed, N. Jaitly , A. Senior , V . V anhoucke, P . Nguyen, T . N. Sainath et al. , “Deep neural networks for acoustic modeling in speech recognition: The shared vie ws of four research groups, ” IEEE Signal Pr ocess. Mag. , vol. 29, no. 6, pp. 82–97, 2012. [17] E. Nachmani, Y . Be’ery , and D. Burshtein, “Learning to decode linear codes using deep learning, ” in Proc. of 54th Annual Allerton Confer ence on Communication, Contr ol, and Computing (Allerton) , 2016, pp. 341– 346. [18] W . Xu, Z. Wu, Y .-L. Ueng, X. Y ou, and C. Zhang, “Improved polar decoder based on deep learning, ” in Pr oc. of IEEE W orkshop on Signal Pr ocessing Systems (SiPS) , 2017, pp. 1–6. [19] L. Lugosch and W . J. Gross, “Neural offset min-sum decoding, ” in Proc. of IEEE International Symposium on Information Theory (ISIT) , 2017, pp. 1361–1365. [20] K. Gregor and Y . LeCun, “Learning fast approximations of sparse coding, ” in Proc. of the 27th International Conference on Machine Learning (ICML) , 2010, pp. 399–406. [21] M. Borgerding and P . Schniter, “Onsager-corrected deep learning for sparse linear inverse problems, ” in Proc. of IEEE Global Conference on Signal and Information Pr ocessing (GlobalSIP) , 2016, pp. 227–231. [22] A. Mousavi and R. G. Baraniuk, “Learning to inv ert: Signal recovery via deep con volutional networks, ” in Pr oc. of IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2017, pp. 2272– 2276. [23] T . J. O’Shea, K. Karra, and T . C. Clancy , “Learning to communicate: Channel auto-encoders, domain specific regularizers, and attention, ” in Pr oc. of IEEE International Symposium on Signal Pr ocessing and Information T echnology (ISSPIT) , 2016, pp. 223–228. [24] N. Samuel, T . Diskin, and A. Wiesel, “Deep MIMO detection, ” arXiv pr eprint arXiv:1706.01151 , 2017. [25] C. Jin, Y . Zhang, S. Y u, R. Hu, and C. Chen, “V irtual MIMO blind detection clustered wsn system, ” in Pr oc. of Asia-P acific Microwave Confer ence (APMC) , vol. 3, 2015, pp. 1–3. [26] S. Mosleh, L. Liu, C. Sahin, Y . R. Zheng, and Y . Y i, “Brain-inspired wireless communications: Where reservoir computing meets MIMO- OFDM, ” vol. PP , no. 99, pp. 1–15, 2017. [27] X. Y an, F . Long, J. W ang, N. Fu, W . Ou, and B. Liu, “Signal detection of MIMO-OFDM system based on auto encoder and extreme learning machine, ” in Pr oc. of International J oint Conference on Neural Networks (IJCNN) , 2017, pp. 1602–1606. [28] J. Proakis, Digital Communications , ser . Electrical engineering series. McGraw-Hill, 2001. [29] W . Fukuda, T . Abiko, T . Nishimura, T . Ohgane, Y . Oga wa, Y . Ohwatari, and Y . Kishiyama, “Low-complexity detection based on belief propa- gation in a massiv e MIMO system, ” in Pr oc. of IEEE 77th V ehicular T echnology Conference (VTC Spring) , 2013, pp. 1–5. [30] A. Chockalingam and B. S. Rajan, Larg e MIMO Systems . New Y ork, NY , USA: Cambridge University Press, 2014. [31] M. Abadi, A. Agarwal, P . Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin et al. , “T ensorflow: Large-scale machine learning on heterogeneous distrib uted systems, ” arXiv preprint arXiv:1603.04467 , 2016. [32] D. P . Kingma and J. Ba, “ Adam: A method for stochastic optimization, ” arXiv preprint arXiv:1412.6980 , 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment