Comparing the Max and Noisy-Or Pooling Functions in Multiple Instance Learning for Weakly Supervised Sequence Learning Tasks
Many sequence learning tasks require the localization of certain events in sequences. Because it can be expensive to obtain strong labeling that specifies the starting and ending times of the events, modern systems are often trained with weak labelin…
Authors: Yun Wang, Juncheng Li, Florian Metze
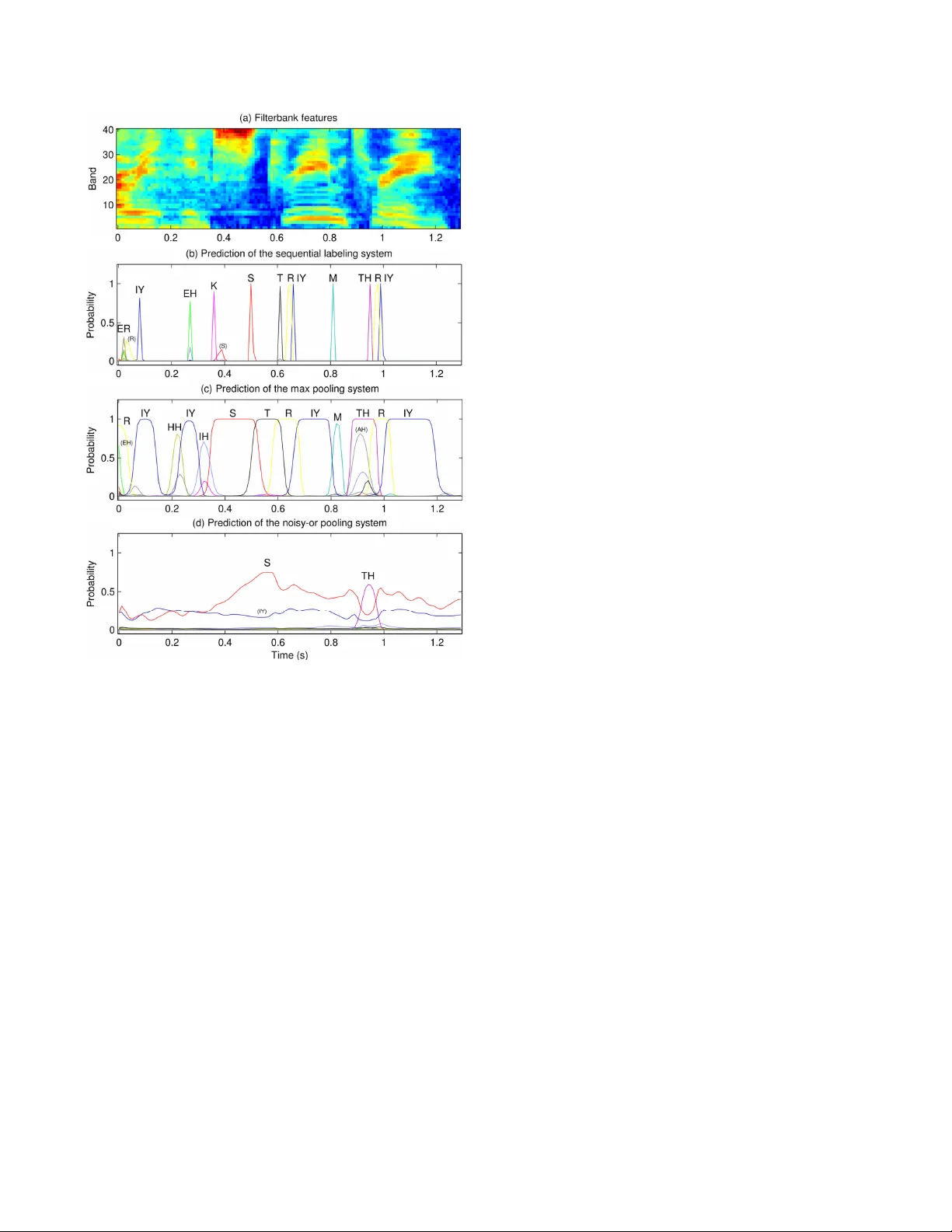
COMP ARING THE MAX AND NOISY -OR POOLING FUNCTIONS IN MUL TIPLE INST ANCE LEARNING FOR WEAKL Y SUPER VISED SEQUENCE LEARNING T ASKS Y un W ang † , J uncheng Li † , ‡ , Florian Metze † † Language T echnologies Institute, Carnegie Mellon Uni versity , Pittsb urgh, P A, U.S.A. ‡ Research and T echnology Center , Robert Bosch LLC, Pittsbur gh, P A, U.S.A. { yunwang, junchenl, fmetze } @cs.cmu.edu ABSTRA CT Many sequence learning tasks require the localization of certain ev ents in sequences. Because it can be expensi ve to obtain strong labeling that specifies the starting and ending times of the events, modern systems are often trained with weak labeling without explicit timing information. Multiple instance learning (MIL) is a popular framew ork for learning from weak labeling. In a common scenario of MIL, it is necessary to choose a pooling function to aggregate the predictions for the individual steps of the sequences. In this paper, we compare the “max” and “noisy-or” pooling functions on a speech recognition task and a sound event detection task. W e find that max pooling is able to localize phonemes and sound e vents, while noisy- or pooling f ails. W e provide a theoretical explanation of the dif ferent behavior of the tw o pooling functions on sequence learning tasks. Index T erms — Sequence learning, weak labeling, multiple instance learning (MIL), speech recognition, sound ev ent detection (SED) 1. INTR ODUCTION Many machine learning tasks take sequences as input. The se- quences may be either text ( e.g. machine translation), audio ( e.g. speech recognition), or in other forms. W e call such tasks sequence learning . Sequence learning tasks often ask for the localization of certain ev ents in the sequences. For example, in speech recognition, it is desirable for the system to output the timespan of each word or phoneme besides the transcription; in sound e vent detection (SED), it is often required to detect the onset and of fset times of each sound ev ent occurrence. Systems capable of localization are con ventionally trained with str ong labeling : the annotation of the training data specifies the timespan of each ev ent in the sequences. Howe ver , it is tedious to generate strong labeling for data by hand, which is a serious limitation when scaling up the systems. T o overcome this problem, researchers have turned to large data with weak labeling , in which the timespans of the ev ents are not explicitly giv en. The weakness of labels may still be classified into different le vels. For exam- ple, speech recognition systems trained with connectionist temporal classification (CTC) [2] take phoneme sequences as training labels. These labels do not specify the start and ending times of each phoneme, but do specify the order between phonemes; we call such labeling sequential labeling . Google Audio Set [3], a large corpus for SED released in early 2017, only labels which types of sound This work was supported in part by a gift a ward from Robert Bosch LLC and a faculty research award from Google. This work used the “bridges” cluster (at PSC) and the “comet” cluster (at SDSC) of the Extreme Science and Engineering Discovery Environment (XSEDE) [1], supported by NSF grant number A CI-1548562. Fig. 1 . Block diagram of a MIL system for sequence learning tasks. ev ents are present in each recording; we call such labeling pr esence/ absence labeling , and this is the focus of this paper . A popular solution for learning with presence/absence labeling is multiple instance learning (MIL) [4]. For example, MIL has been applied to SED in [5–8]. In a common scenario of MIL, it is important to choose a pooling function to aggregate instance-lev el predictions (see Fig. 1). In this paper , we compare two pooling functions: the “max” pooling function used in [5, 6, 8], and a “noisy- or” pooling function which has been applied to object detection in images [9–11]. W e ev aluate the two pooling functions on a speech recognition task and a sound ev ent detection task, both with pres- ence/absence labeling. W e measure their performance quantitativ ely as well as inspect their beha vior of localization. It turns out that max pooling learns to localize successfully , while noisy-or pooling fails. W e pro vide a theoretical analysis of this result, with special attention to the particularities of sequence learning tasks. 2. MUL TIPLE INST ANCE LEARNING Many weakly supervised tasks can be formulated as multiple in- stance learning (MIL) problems. In MIL, we do not hav e the ground truth label for each instance; instead, the instances are grouped into bags , and we only hav e labels for the bags. The relationship between the label of a bag and the (unkno wn) labels of the instances in it often follows the standar d multiple instance (SMI) assumption : a bag is positiv e if it contains at least one positiv e instance, and negati ve if it only contains negati ve instances. For a weakly supervised sequence learning problem, we can treat each sequence as a bag, and the steps ( e.g . audio frames) of the sequence as instances. For example, weakly supervised sound ev ent detection entails making frame-lev el predictions in order to localize the sound events, while only recording-lev el labels are giv en. The structure of a MIL system using the instance space paradigm [4] is shown in Fig. 1. The individual instances in a bag are first fed into an instance-level classifier . The classification does not hav e to be independent among the instances; for sequence learning, the instance-lev el classifier can be replaced by a con volutional or recur- rent neural network that propagates information from one instance to the next. The instance-lev el predictions are aggregated into a bag- lev el prediction using a pooling function. The loss function can be constructed by comparing the bag-lev el prediction with the label of the bag ( e.g. cross-entropy), and minimized with any optimization algorithm ( e.g . stochastic gradient descent). A number of pooling functions have been proposed. In this paper , we specifically study the “max” [5, 6, 8] and “noisy-or” [9–11] pooling functions. Let y i ∈ [0 , 1] be the prediction for the i -th instance in a bag, and y ∈ [0 , 1] be the bag-level prediction. The max pooling function simply tak es the maximum instance-lev el prediction as the bag-lev el prediction: y = max i y i , (1) while the noisy-or pooling function treats y i as the probability of the i -th instance being positi ve, and computes the probability of the bag being positiv e according to the SMI assumption: y = 1 − Y i (1 − y i ) . (2) In the general MIL frame work, the noisy-or pooling function appears more principled. Assuming that instances within a bag are mutually independent, it provides a probabilistic interpretation of the predictions. Also, from the perspectiv e of error back-propagation, all the instances in a bag can receive an error signal (as opposed to only the maximum instance when using the max pooling function). Howe ver , in the situation of sequence learning, these merits of the noisy-or pooling function may be questioned: the steps of a se- quence are often correlated with each other, and the conv olutional or recurrent neural network functioning as the instance-level classifier is able to propagate the gradient across time ev en though only a single step recei ves an error signal from higher layers. Whether these differences are significant enough to nullify the advantages of the noisy-or pooling function remains to be discov ered by experiment. 3. EXPERIMENT ON SPEECH RECOGNITION State-of-the-art speech recognition systems often employ a CTC output layer [2], which takes phoneme sequences as training labels (sequential labeling). W e take a step further and test out the “max” and “noisy-or” pooling functions using the even weaker presence/ absence labeling, i.e. we only tell the system which phonemes are present in each utterance. W e conducted the experiments on the TEDLIUM v1 corpus 1 . The corpus consists of 206 hours of training data, 1.7 hours of dev el- opment data, and 3.1 hours of testing data; we used 95% of the train- ing data for training, and 5% for validation. W e generated ground truth phoneme sequences for all utterances from the transcriptions and the dictionary; we only retained the 39 “real” phonemes and discarded all noise markers like “breath” and “cough”. The baseline system we compared against was a Theano [12] re- implementation of the example CTC system 2 in the EESEN toolkit 1 The corpus can be do wnloaded at http://www.openslr.org/resources/7/ . 2 https://github.com/srvk/eesen/tree/master/asr_egs/tedlium/v1 System Loss Hyperparameters PER averaged over Grad.clip Init.LR T rain V alid. Dev . T est CTC (baseline) Frames 10 − 4 3 4 . 8 15 . 4 13 . 9 14 . 9 Max pooling Utts., phonemes 0 . 01 0 . 3 40 . 5 43 . 0 39 . 7 40 . 7 Noisy-or pooling Frames, phonemes 10 − 8 3000 91 . 0 91 . 6 91 . 6 91 . 5 T able 1 . The details and performance of the CTC and weakly supervised speech recognition systems. [13]. This system took phoneme sequences as training labels. The network consisted of fiv e bidirectional LSTM layers, with 320 memory cells in each direction of each layer . The input layer had 40 neurons, which accepted 40-dimensional filterbank features 3 . The CTC output layer consisted of 40 neurons arranged in a softmax group, corresponding to the 39 phonemes plus a blank token. W e adapted the baseline system to build two systems with presence/absence labeling, using the “max” and “noisy-or” pooling functions, respectively . The input and hidden layers were identical to the baseline system. The output layer consisted of 39 neurons, without the one neuron dedicated to the blank token. These neurons used the sigmoid acti vation function. Even though phonemes cannot ov erlap in time, we did not want to enforce this restriction in the network. The frame-lev el predictions are then aggreg ated across time into an utterance-lev el prediction (a 39-dimensional vector). All the three systems were trained to minimize the cross-entropy loss function, averaged properly across different units (see T able 1). The optimization algorithm was stochastic gradient descent (SGD) with a Nesterov momentum of 0.9 [14]. Each minibatch contained 20,000 frames; an epoch consisted of about 2,000 minibatches. All the systems were trained for 24 epochs, with the learning rate staying constant in the first 12 epochs, and then halved in each of the next 12 epochs. W e found it essential to apply proper gradient clipping and a large initial learning rate, in order to ensure that the network could get through the initial stage of instability safely and progress with large enough steps after that. The gradient clipping limit and initial learning rate of each system are also listed in T able 1. W e decoded all the systems using simple best path decoding : choosing the most probable tok en (phoneme or blank) at each frame, collapsing consecutiv e duplicate tokens, and removing blanks. Since the output layer of the two weakly supervised systems did not have a neuron for the blank token, we set the prediction to blank if the probability of the most probable phoneme was smaller than 0 . 5 . T o av oid the extra complexity introduced by the le xicon and the language model, we e valuated all the systems using phone error rate (PER), as listed in T able 1. The baseline CTC system learnt fast and accurately , reaching a PER of 30% after the first epoch and con verging to 15%. The max pooling system reached a PER of 43%. Even though there was a gap between the max pooling system and the baseline, the learning can be regarded as successful considering that the max pooling system only saw presence/absence labeling during training. The noisy-or pooling system, ho wever , exhibited a PER above 90% even after 24 epochs, and its predictions were mostly blank. Fig. 2 shows the predictions of the three systems on an e xample utterance. The CTC system produces narrow peaks that align well with the actual position of the phonemes, but the peaks do not indicate the timespan of each phoneme. The max pooling system produces wide peaks that clearly indicate the onset and of fset time of each phoneme, which is exactly the desired behavior for localization. The noisy-or pooling system fails to predict anything meaningful, and only three phonemes receiv e non-negligible probabilities. 3 Unlike the EESEN system, we did not use delta and double delta features. Fig. 2 . The frame-level predictions of the various systems on an example utterance. The ground truth transcription is “very extreme terrain” (both the baseline and the max pooling systems mis-recognize “terrain” as “three”). Phonemes are differentiated by color . Peaks are annotated with their corresponding phonemes; phonemes in parentheses were not selected in the best path decoding. The results clearly indicate the ability of max pooling to perform localization. But why did noisy-or pooling fail, despite its proba- bilistic interpretation and easy propagation of error signal? Looking into the interaction between the loss and the pooling function, we found the noisy-or pooling system was excessiv ely harsh on false alarms and lenient on misses . Noisy-or pooling is harsh on false alarms precisely because it erroneously assumes that frames in a recording are independent. Because consecutiv e frames in a sequence are often correlated, when the system makes a false alarm, it normally generates a peak that spans several frames. This peak should be penalized only once, not for ev ery frame it spans. The noisy-or pooling function, howe ver , multiplies the 1 − y i of each frame, which makes the bag-lev el prediction y extremely close to 1 , and results in a large loss − log (1 − y ) . For example, in Fig. 2 (c), the max pooling system makes a false alarm of the phoneme TH . The frame-lev el prediction y i exceeds 0 . 999 for 7 frames; the maximum value is 1 − 2 × 10 − 7 . W ith the max pooling function, this incurs a loss of − log (2 × 10 − 7 ) ≈ 15 . 5 . If we used noisy-or pooling instead, this false alarm w ould incur a loss of at least − log(1 − 0 . 999) × 7 ≈ 48 . As a result, the noisy-or pooling system only dared to generate a small peak for the phoneme TH , as shown in Fig. 2 (d). Noisy-or pooling is lenient on misses because the system may believ e it has made the correct bag-level prediction for a positiv e bag, while all the instances-level predictions are negati ve. This also stems from the multiplication in the noisy-or pooling function. Let’ s look at the phoneme IH . Although hardly visible in Fig. 2 (d), its predicted probability is around 0 . 02 throughout the 130- frame utterance. The bag-lev el prediction calculated by the noisy-or pooling function is y ≈ 1 − (1 − 0 . 02) 130 ≈ 0 . 93 – the system believ es it has predicted the presence of IH correctly , and therefore will no longer make an effort to boost its frame-level probabilities. The phoneme IY illustrates a more extreme case: its predicted probability fluctuates around 0 . 2 , resulting in a bag-level prediction of y ≈ 1 − (1 − 0 . 2) 130 ≈ 1 − 2 . 5 × 10 − 13 . W ith the bag-level prediction so close to 1 , virtually no error signal will be passed do wn the network. This problem is inherent with the noisy-or pooling function, and limits its use to small bags. Sequence learning tasks, howe ver , often feature large bags with hundreds of instances. Max pooling, on the other hand, does not suffer from these fatal defects of noisy-or pooling. W ith an underlying RNN that can propagate information across time, it learns to perform sequence learning tasks relativ ely easily . 4. EXPERIMENTS ON SOUND EVENT DETECTION W e conducted experiments on T ask 4 of the DCASE 2017 challenge [15]. This task consists of two subtasks: T ask A is audio tagging, i.e. determining which ev ents are present in each recording, but without localizing the events; T ask B is sound event detection, i.e. T ask A plus localization. Both tasks consider 17 events related to vehicles and warning sounds. The data consists of a training set (51,172 recordings), a public test set (488 recordings), and a priv ate ev aluation set (1,103 record- ings). All the recordings come from Google Audio Set [3], and are 10-second excerpts from Y ouT ube videos. The test and ev aluation sets are strongly labeled so they can be ev aluated for both subtasks, but the training set only comes with presence/absence labeling. Also, the test and e valuation sets hav e balanced numbers of the events, but the training set is unbalanced. W e set aside 1,142 recordings from the training set to make a balanced validation set, and used the remaining recordings for training. W e did not do anything about the class imbalance in the training data. W e trained a con volutional and recurrent neural network (CRNN) using the Keras toolkit [16]. The structure of the network is shown in Fig. 3. The input is 40-dimensional filterbank features of the audio recording sampled at 160 frames per second, i.e. a matrix of size 1600 × 40 . The con volutional and pooling layers reduce the frame rate to 10 Hz, whose output is fed into a bidirectional GR U layer with 100 neurons in each direction. A fully connected layer with 17 neurons and the sigmoid activ ation function then predicts the probability of each sound event at each frame. These frame-le vel predictions can be used for SED; they are also aggre gated with either the max or the noisy-or pooling function to produce recording-level predictions for audio tagging. During training, the recording-level predictions are compared against the presence/absence labeling of the training data to compute the loss function. W e minimized the cross entropy av eraged ov er both recordings and e vents using the SGD algorithm with a batch size of 100 record- ings. The initial learning rate was 0 . 1 for the max pooling network and 0 . 3 for the noisy-or pooling network, both with a Nesterov momentum of 0 . 9 . Gradient clipping with a limit of 10 − 4 was found 800 * 20 * 32 1600 * 40 * 32 800 * 20 * 64 400 * 10 * 64 400 * 10 * 128 100 * 5 * 128 100 * 640 100 * 200 100 * 17 1600 * 40 1 * 17 conv 5*5 max pool 2*2 conv 5*5 max pool 2*2 conv 5*3 max pool 4*2 flatten BiGRU 100*2 fully connected max / noisy-or pooling across time Frame-level predictions Recording-level predictions Fig. 3 . The structure of the CRNN for audio tagging and sound event detection. All con volutional layers use the ReLU acti vation. T ask Metric V alid. T est Eval. T ask A (tagging) F1 53 . 3 50 . 1 50 . 7 T ask B (SED) Seg. ER 79 . 7 75 Seg. F1 39 . 4 46 . 9 T able 2 . The performance of the max pooling system on both the audio tagging and the SED subtasks of the DCASE 2017 challenge. to be necessary for noisy-or pooling, but no gradient clipping was needed for max pooling. For the max pooling network, we applied dropout with a rate of 0 . 1 , and decayed the learning rate with a factor of 0 . 8 when the validation loss did not reduce for 3 consecutive epochs, which contributed mar ginally to the performance. The frame-level and recording-level probabilities predicted by the network must be thresholded to generate output for ev aluation. Audio tagging was e valuated with the F 1 metric, while SED was ev aluated with both the error rate (ER) and the F 1 based on 1-second segments. All the metrics were micro-av eraged over all the 17 ev ent classes. W e found it critical to tune the threshold for each e vent class individually . W e devised an iterativ e procedure to tune the class-specific thresholds to optimize the micro-average F 1 : first, we tuned the threshold of each class to maximize the class-wise F 1 ; then, we repeatedly picked a random class and re-tuned its threshold to optimize the micro-average F 1 , until no improv ements could be made. After each epoch of training, we tuned the thresholds on the validation data to optimize the audio tagging F 1 ; the model with the highest F 1 was picked as the final model. The thresholds obtained on the v alidation data were applied to the test and ev aluation data for both audio tagging and SED. The performance of the max pooling system is shown in T able 2. This is comparable with most of the participates of the challenge in both subtasks. The noisy-or pooling system achiev ed a validation F 1 of 53.4% and a test F 1 of 49.6% for audio tagging. As first sight, this seems to indicate that noisy-or pooling performs as well as max pooling. Howe ver , we will show that this is only the case for audio tagging, and that noisy-or pooling is not suitable for SED. Fig. 4 illustrates the frame-level predictions of the max pooling and the noisy-or pooling systems on an example test recording. The recording contains the sound of a train sounding its horn intermittently . Fig. 4(c) indicates that the max pooling system is able to locate the interv als during which the horn is sounding and produce reasonable frame-level probabilities. Fig. 4(d), howe ver , indicates that the noisy-or pooling system suffers from the same problem observed in the speech recognition experiment: its frame-level predictions are too small, and will almost certainly be rejected even by class-specific thresholds. Even though these small frame-lev el predictions can make up reasonable recording-level probabilities through the multiplication in the noisy-or pooling function (Eq. 2), they are not intuiti ve as frame-le vel probabilities. Band (a) Filterbank features 20 40 (b) Ground truth (red means active) Train Train horn 0 0.5 1 Probability (c) Frame−level predictions of the max pooling system Train Train horn 0 1 2 3 4 5 6 7 8 9 10 0 0.5 1 Time (s) Probability (d) Frame−level predictions of the noisy−or pooling system Train Train horn Fig. 4 . The frame-lev el predictions of the max and noisy-or pooling systems on the e xample test recording “ 10i60V1RZkQ ”. In (c), the dotted lines indicate the thresholds for the two e vent classes. If we look closer at the frame-level predictions in Fig. 4(d), we can notice that they seem to follow the same trend as in Fig. 4(c), despite their small magnitude. W ould it be possible to perform SED with these small frame-level predictions, if we were able to set commensurate thresholds? W e used the same iterati ve procedure to optimize class-specific thresholds on the test set, and obtained a segment-based error rate of 83.5% and an F 1 of 40.9%. Note that these are the oracle performance of the noisy-or pooling system, yet they are barely comparable with the actual performance of the max pooling system (79.7% ER, 39.4% F 1 ). For reference, the oracle performance of the max pooling system is 75.7% ER and 45.8% F 1 . The analysis above indicates that the frame-lev el predictions of the noisy-or pooling system not only hav e improper magnitudes , but also lack the quality for good SED performance. The noisy-or pooling system is best treated as a black box for audio tagging. 5. CONCLUSION W e ev aluated the max and noisy-or pooling functions on two se- quence learning tasks with weak labeling: phone recognition on the TEDLIUM corpus, and audio tagging / sound ev ent detection in the DCASE 2017 challenge. W e found that systems using the two pooling functions achiev ed comparable performance in the audio tagging task, which did not require localization. Howev er , only the max pooling system succeeded in localizing the phonemes and sound ev ents; the noisy-or pooling system tended to produce excessi vely small frame-level probabilities despite the elegant theo- retical interpretation of the noisy-or pooling function. W e attribute the failure of the noisy-or pooling system to two factors: (1) the correlation between consecutive frames violates the assumption of independence, and (2) the multiplication in the noisy-or pooling function can lead the system to believ e a sequence is positive ev en though all its frames are negati ve. W e recommend using the max pooling function for weakly supervised sequence learning tasks that require localization. 6. REFERENCES [1] J. T owns, T . Cockerill, M. Dahan, I. Foster , K. Gaither, A. Grimshaw, V . Hazle wood, S. Lathrop, D. Lifka, G. D. Peterson, R. Roskies, J. R. Scott, and N. Wilkins-Diehr, “XSEDE: Accelerating scientific discov ery , ” Computing in Science & Engineering , vol. 16, no. 5, pp. 62–74, 2014. [2] A. Graves, S. Fern ´ andez, F . Gomez, and J. Schmidhu- ber , “Connectionist temporal classification: Labelling un- segmented sequence data with recurrent neural networks, ” in International Conference on Machine Learning (ICML) , A CM, 2006, pp. 369–376. [3] J. F . Gemmeke, D. P . W . Ellis, D. Freedman, A. Jansen, W . Lawrence, R. C. Moore, M. Plakal, and M. Ritter , “ Audio Set: An ontology and human-labeled dataset for audio ev ents, ” in International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , IEEE, 2017, pp. 776–780. [4] J. Amores, “Multiple instance classification: Revie w , taxon- omy and comparati ve study, ” Artificial Intelligence , vol. 201, pp. 81–105, 2013. [5] T .-W . Su, J.-Y . Liu, and Y .-H. Y ang, “Weakly-supervised audio event detection using ev ent-specific gaussian filters and fully con volutional networks, ” in International Confer- ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , IEEE, 2017, pp. 791–795. [6] A. Kumar and B. Raj, “ Audio event detection using weakly labeled data, ” in Multimedia Conference , ACM, 2016, pp. 1038–1047. [7] B. Raj and A. Kumar, “Audio e vent and scene recognition: A unified approach using strongly and weakly labeled data, ” in International Joint Conference on Neural Networks (IJCNN) , IEEE, 2017, pp. 3475–3482. [8] J. Salamon, B. McFee, and P . Li, “DCASE 2017 submis- sion: Multiple instance learning for sound ev ent detection, ” DCASE2017 Challenge, T ech. Rep., Sep. 2017. [9] O. Maron and T . Lozano-P ´ erez, “A framework for multiple- instance learning, ” in Advances in Neural Information Pro- cessing Systems (NIPS) , 1998, pp. 570–576. [10] C. Zhang, J. C. Platt, and P . A. V iola, “Multiple instance boosting for object detection, ” in Advances in Neural Infor- mation Pr ocessing Systems (NIPS) , 2006, pp. 1417–1424. [11] B. Babenko, P . Doll ´ ar, Z. T u, and S. Belongie, “Simultaneous learning and alignment: Multi-instance and multi-pose learn- ing, ” in W orkshop on F aces in Real-Life Images: Detection, Alignment, and Recognition , 2008. [12] Theano Dev elopment T eam, “Theano: A Python framework for fast computation of mathematical expressions, ” ArXiv e- prints , May 2016. [Online]. A vailable: http : / / arxiv . org/abs/1605.02688 . [13] Y . Miao, M. Gowayyed, and F . Metze, “EESEN: End-to- end speech recognition using deep RNN models and WFST- based decoding, ” in W orkshop on Automatic Speech Recog- nition and Understanding (ASR U) , IEEE, 2015, pp. 167–174. [14] Y . Nesterov , “A method of solving a conv ex programming problem with conv ergence rate O (1/sqr( k )), ” Soviet Mathe- matics Doklady , vol. 27, no. 2, pp. 372–376, 1983. [15] A. Mesaros, T . Heittola, A. Diment, B. Elizalde, A. Shah, E. V incent, B. Raj, and T . V irtanen, “DCASE 2017 challenge setup: Tasks, datasets and baseline system, ” in Proceedings of the Detection and Classification of Acoustic Scenes and Events 2017 W orkshop (DCASE2017) , 2017. [16] F . Chollet et al. , Keras , 2015. [Online]. A v ailable: https : //github.com/fchollet/keras .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment