Framework for evaluation of sound event detection in web videos
The largest source of sound events is web videos. Most videos lack sound event labels at segment level, however, a significant number of them do respond to text queries, from a match found using metadata by search engines. In this paper we explore th…
Authors: Rohan Badlani, Ankit Shah, Benjamin Elizalde
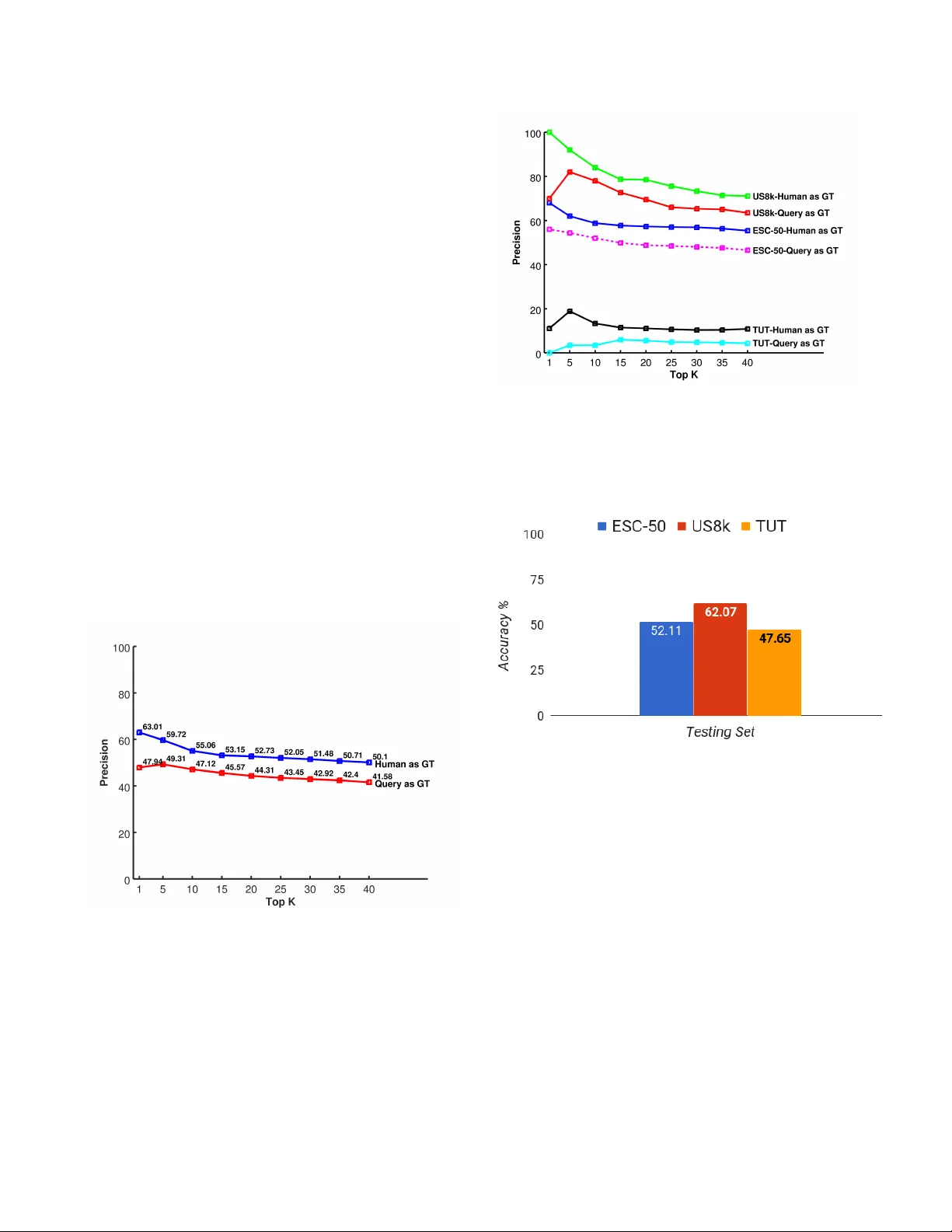
FRAMEWORK FOR EV ALU A TION OF SOUND EVENT DETECTION IN WEB VIDEOS Rohan Badlani ? ‡ Ankit Shah †‡ Benjamin Elizalde †§ Anura g K umar † Bhiksha Raj † † Language T echnologies Institute, Carne gie Mellon Uni versity , Pittsbur gh P A ? Department of Computer Science, BITS Pilani, India ABSTRA CT The largest source of sound e v ents is web videos. Most videos lack sound ev ent labels at segment level, howe ver , a signifi- cant number of them do respond to text queries , from a match found using metadata by search engines. In this paper we explore the extent to which a search query can be used as the true label for detection of sound ev ents in videos. W e present a framew ork for large-scale sound e vent recognition on web videos. The framework crawls videos using search queries corresponding to 78 sound ev ent labels drawn from three datasets. The datasets are used to train three classifiers, and we obtain a prediction on 3.7 million web video seg- ments. W e ev aluated performance using the search query as true label and compare it with human labeling. Both types of ground truth exhibited close performance, to within 10%, and similar performance trend with increasing number of ev alu- ated segments. Hence, our experiments sho w potential for using search query as a preliminary true label for sound e v ent recognition in web videos. Index T erms — Sound Event Detection, Con v olutional Neural Network, Lar ge-Scale audio ev ent detection, V ideo Content Analysis 1. INTR ODUCTION The Internet is being flooded with massive amount of mul- timedia data, mostly comprising of videos containing sound ev ents which are often critical to understand the video con- tent. Hence, it is necessary to automatically recognize sound ev ents within the audio, e.g . police sir en , dishwasher or bir ds singing . Sound e vent recognition has been applied to multiple forms, such as in conjunction with other modali- ties to retrie v e and inde x consumer -generated videos based on content [1, 2, 3, 4], video surveillance (e.g. detection of footsteps) [5], human-robot interaction (e.g. detection of chok e) [6, 7], wildlife monitoring (e.g. detection of an- imals) [8], and conte xt-aw are systems (e.g. outdoors or home) [9]. In recent years, the main sound recognition challenges: DCASE 2013 [10], 2016 [11] and 2017[12] hav e fostered re- search pro viding standard datasets, task guidelines, metrics ‡ First two authors contributed equally § Acknowledges CON ACYT for his doctoral fello wship, No.343964 and benchmark performances. Although necessary , the lit- erature tends to focus on DCASE-like datasets, which are audio-only recordings and smaller in scale. This leav es the primary source of sound events, the web, and its intrinsic problems less explored which makes it unclear ho w state of the art sound e vent recognition systems work on web videos. Although the Y ouTube based AudioSet [13] was recently re- leased containing weak labels for sound events, our work ex- plores mismatch conditions between existing audio-only re- search and datasets applied to Y ouT ube videos. Sound event recognition on large-scale web videos poses sev eral challenges, mainly the lack of annotated audio record- ings for sound e v ents to train and ev aluate systems. In order to exploit web recordings, unsupervised solutions have been explored, such as clustering [14] and sound diarization [15] or semi-supervised approaches [16, 17] or visual domain web video analysis [18, 19], which learn from a combination of labeled and unlabeled data sources. Another technique [20] relies on weak labels for learning where only the presence or absence of sounds in the recording is known. For web videos the primary idea is that associated metadata can be used to as- sign weak labels which can further be used for training classi- fication models [21, 22]. Howe ver , the metadata, such as title, keyw ords and description, are noisy and often related to the visual information rather than the audio content, hence it re- mains to be seen how reliably it can be used as a true label or ground truth to train and e v aluate sound recognition systems. This analysis forms the major contribution of the framew ork proposed in this paper . In this paper , we first do an e xploration to identify the e x- tent to which search query , which relates to the textual meta- data, can be used as a true label for sound ev ents at seg- ment level for Y ouT ube videos. This study , to the best of our knowledge is unav ailable in the literature. For our study , we dev eloped a framew ork for large-scale sound ev ent recogni- tion on web videos consisting of three modules, Crawl, Hear , F eedback . In Crawl , Y ouT ube videos were crawled using search queries corresponding to 78 sound ev ent labels and the k eyword sound ( < sound event label > sound) dra wn from three datasets. In Hear , the datasets are used to train three multi-class classifiers, which are used to obtain sound ev ent label prediction on 3.7 million video segments. W e ev al- uated performance using the search query as the true label and compare it on a subset against human labeling which was collected in the F eedback module. Both types of ground truth exhibit similar performance trend. Hence, we show that search query provides a reasonable ground truth for large- scale sound ev ent detection in web videos. 2. FRAMEWORK The purpose of the framework is to use our sound event la- bels as search queries to crawl videos, which lack true la- bels at segment level; train classifiers using labeled audio to recognize sound ev ents on the unlabeled crawled video seg- ments; and e v aluate the system performance using two types of ground truth, search query and human labeling collected through our website. The framework as described in follow- ing sections consists of three modules illustrated in Figure 1 Fig. 1 . Our framew ork consists of three modules: Cra wl, Hear and Feedback. 2.1. Crawl The Crawl module employs search queries to scrape audio from Y ouT ube videos using the Pafy API 1 . The queries are kept to use them later as true labels. 2.2. Hear Dataset Aggr e gator or ganizes dif ferent annotated sound ev ent datasets. The audio is then preprocessed and acoustic fea- tures are extracted in the F eatur e Extractor module. W e run a Sound Event Classifier , the features are used to train classi- fiers, on unlabeled segments of the crawled videos. The per- 1 https://pypi.python.or g/pypi/pafy formance is e valuated using the pre viously used search query and with the human inspection carried on the next module. 2.3. F eedback This module displays the classifier predictions along with cor- responding audio segments on our website nels.cs.cmu.edu . Using our website, human feedback is collected [assumed as true label for an experiment] to e v aluate classifier perfor - mance and compare the performance against search query as true label. 3. EXPERIMENTS AND EV ALU A TION In this section, we explain ho w we use our framework to study the relation between the search query and the presence of sound ev ents in video segments. T o achieve our objec- tiv e we trained sound ev ent classifiers using labeled record- ings sourced from three dif ferent audio-only datasets and run trained detectors on unlabeled crawled Y ouT ube video seg- ments. The performance was e v aluated using two types of true labels - with the search query used to retrie ve the videos and with the collected human inspection. 3.1. Crawl In contrast to audio-only recordings, collecting audio from videos poses se veral challenges. Y ouT ube contains massiv e amount of videos and a proper formulation of the search query is necessary to filter videos with higher chances of containing the desired sound ev ent. T yping a query composed by a noun such as air conditioner will not necessarily fetch a video con- taining such sound e v ent because the associated metadata of- ten corresponds to the visual content; contrary to audio-only websites such as fr eesounds.or g . Therefore, we modified the query to be a combination of ke ywords: “ < sound ev ent la- bel > sound”, for example,“air conditioner sound”. Although the results empirically improved, the sound e vent was not al- ways found to be occurring and ev en if it was present, some- times it was present within a short duration. W e discarded videos longer than ten minutes and shorter than three seconds because the y were either likely to contain unrelated sounds or were too short to be processed. The defined search query was used to crawl videos corre- sponding to 78 sound ev ent labels described in the follo wing Section 3.2.1. Around 260 hours of video was processed, equally distributed per audio ev ent, which corresponds to ov er 3.7 million video segments (90% o verlap) of 2.3 sec- onds each. The segments were con v erted to 16-bit encoding, mono-channel, and 44.1 kHz sampling rate W A V files. Note that, the acoustic content from these videos is unstructured and the target sound is often o verlapping by other audio, such as noise, speech or music. 3.2. Hear In this subsection, we explain how we used three labeled datasets to train our three sound ev ent classifiers and run them on the unlabeled crawled Y ouT ube video segments. 3.2.1. Dataset Aggr egator The 78 sound events come from 3 publicly av ailable anno- tated datasets - ESC50, US8k and TUT . W e partitioned each dataset into 60% training, 20% validation and 20% testing sets to avoid dealing with the costly process of cross-fold val- idation during testing of 3.7 million segments. ESC-50 or En vir onmental Sound Classification [23] has 50 classes from fi ve categories: animals, natural sound- scapes and water sounds, human non-speech sounds, inte- rior/domestic sounds and exterior sounds. ESC-50 consists of 2,000 audio segments with an a verage duration of 5 seconds. The US8K or UrbanSounds8K [24] has 10 classes: air conditioner , car horn, c hildr en playing, dog bark, str eet mu- sic, gun shot, drilling, engine idling, siren, jac khammer . Ur- banSounds8k consists of 8,732 audio segments with an a ver - age duration of 3.5 seconds. TUT 2016 [25] has 18 classes lik e car passing by , bir d singing, door banging from tw o major sound contexts namely home context and residential area. TUT dataset consists of 954 audio segments with an a verage duration of 5 seconds. 3.2.2. F eatur e Extr actor W e e xtracted features for all audio recordings in the datasets based on the work in [23] because they provided near to state- of-the-art performance at the time of de veloping our experi- mental results. Our pipeline is agnostic of the classifier used. The audio recordings were re-sampled into 16-bit encoding, mono channel at 44.1 kHz sampling rate as a standard format for all experiments. W e feed in two channels to our learn- ing model. The first channel comprises of log-scaled mel- spectrograms with 60 mel-bands with a windo w size of 1024 (23 ms) and hop size is 512 and the second channel comprises of delta coefficients for mel-spectrograms. 3.2.3. Sound Event Classifiers W e used multi-class classifiers using Conv olutional Neural Networks (CNNs) for each of the datasets based on the work in [23]. Thus, we trained 3 CNN models for classification of 50, 18 and 10 sound e vents from ESC-50, TUT and US8k re- spectiv ely . W e used different models for each dataset because using a single model for 78 audio events presented many chal- lenges like dealing with unbalanced classes, inconsistency in feature normalization and doing so resulted in low perfor- mance (15% lower accurac y). The CNN architecture consisted of the following layer parameters and optimizations done using the v alidation set. The input to the CNN is 60 × 101 × 2 . W e used 60 mel- filters, 101 number of frames (approximately 2.3 seconds of data) and 2 channels - mel-spectra and delta features for mel- spectrograms. The input window length of 101 frames is mov ed by 10 frames ( 90% overlap). Hence, we trained and predicted on audio se gments of approximately 2 . 3 secs. The first con volutional ReLU layer consisted of 80 filters of rect- angular shape (57x6 size, 1x1 stride) allowing for slight fre- quency in v ariance. Max pooling was applied with a pool shape of 4x3 an stride of 1x3. A second con volutional ReLU layer consisted of 80 filters (1x3 size, 1x1 stride) with max pooling (1x3 pool size, 1x3 pool slide). Further processing was applied through two fully connected hidden layers of 5000 neurons with ReLU non-linearity . The final output layer is a softmax layer . Training was performed using Keras im- plementation of mini batch stochastic gradient descent ev en with shuffled sequential batches (batch size 1000) and a ne- strov momentum of 0.9. W e used L2 weight decay of 0.001 for each layer and dropout probability of 0.5 for all layers. 3.3. Evaluation of Classifiers P erf ormance Y ouT ube videos at segment le vel lack of true labels for sound ev ents. Hence, we e v aluated the classification performance with two types of references or ground truth - the search query used to retrie ve the videos and the human inspection collected with the website described in the F eedback module. 3.3.1. Evaluation assuming Sear c h Query as Gr ound T ruth In this ev aluation process, all the segments of a retrie ved video using a gi ven search query , such as dog barking sound are labeled to contain do g barking , even if this might not nec- essarily be true. Motiv ation is that search query is a reflection of the accumulated metadata tags such as title, description and keyw ords and hence, we wanted to see to what degree the query relates to the acoustic content of the segments. 3.3.2. Evaluation using Human F eedbac k as Gr ound T ruth Human inspection is needed to provide the most reliable ground truth (true label). Hence, the 3.7 million predicted segments were sorted based on classifier confidence (prob- ability) and were ev aluated by a group of experts on tasks related to sound recognition. The top 40 segments for each of the 78 classes were distributed randomly among 5 human ev aluators and at least 3 people ev aluated each segment to reduce human bias and decide based on majority vote. The segments were displayed using a similar web interf ace as in the main page of nels.cs.cmu.edu, but the dif ference is that only the audio was displayed in lieu of video in order to a v oid rev ealing other cues, such as images or title. The ev aluators had to choose between two options, Correct or Incorrect , whether the e valuator claims that the system’ s predicted class was present within the segment or not. 4. RESUL TS AND DISCUSSION 4.1. Results on Crawled Y ouT ube V ideos This main takeaw ay of our study is the exhibited correla- tion between the presence of sound events in video segments and their corresponding search query (including the keyw ord sound), illustrated in Figures 3 and 2. Note that human in- spection is the most reliable ground truth while the search query is an assumption of true class because it is based on metadata, which may be based on visual content. Thus, the precision with human feedback was expected to be higher than the one with the query , b ut it was uncertain how big that gap could be. The query-based performance was better than we expected considering the uncertainty of the audio content in web videos. Moreover , the performance follows a similar trend to the one from human feedback with a relatively close precision of less than an absolute 10%, which shows potential for the search query (including the keyword sound) to be used as the class label in lieu of human annotations. The performance of the three classifiers on the video seg- ments e v aluated for both types of ground truth, search query and human feedback, are shown in both Figures 2 (com- bined weighted-average) and 3 (individual performance). The y-axis, has the performance in terms of Precision@K (a common retriev al metric), which is the precision of k high- confidence (probability) ranked segments. The x-axis has the T op K high-confidence segments yielded by our systems. In both figures, the results for K = 1-5 is unstable as the number of audio segments is small and could vary depending on the selected audio segments, howe ver performance stabilizes as K gro ws. W e stopped at T op 40 results because a Y ouT ube user , for example, tend to focus on the home page of results which translates to K equals to 10-20. Further , we e v aluated all the 3.7 million segments using search query as ground truth and obtained precision scores of 15.43% for ESC-50, 33.58% for US8k and 7.43% for TUT datasets. Future work in v olves using crowd-sourcing to collect more human feed- back to determine whether performance based on human inspection would remain within 10% precision. Fig. 2 . Performance for the combination (weighted a verage) of the three classifiers. (GT = ground truth) 4.2. Results on Datasets The classification accurac y of our three systems on their cor - responding testing sets is shown in order to establish their reliable performance in match conditions. Although the three datasets are well explored in the field, we split them in a different manner to av oid cross-fold experiments with 3.7 million segments. The classification accuracy for ESC-50 52.11%, US8k 62.07% and TUT 47.65% was considerably Fig. 3 . F or the three classifiers, the search query-based per - formance follo ws a similar and close trend to the one based on human feedback. (GT = ground truth) better than their corresponding random performance: 2%, 10%, 5.5% as shown in Figure 4. Fig. 4 . Classification accuracy for each of the three classi- fiers trained on the each of the three datasets showed reliable results on match conditions. 5. CONCLUSIONS W eb videos have no established true sound event labels at segment le vel. Thus, we studied the relation between search queries, based on sound event labels, and the presence of the corresponding sound e vent. W e dev eloped a frame work to crawl videos using search queries, trained classifiers with audio-only datasets on video segments and e v aluate perfor - mance with two types of ground truth - the search query and the collected human inspection. The y showed a correlation between the search query (including the ke yword sound) and the presence of sound e v ents in video segments. Our results encourage further exploration of the search query as a prelim- inary label of the true class to e valuate sound ev ent c lassifica- tion at a large-scale. 6. REFERENCES [1] Shoou-I Y u, Lu Jiang, Zexi Mao, Xiaojun Chang, Xingzhong Du, Chuang Gan, Zhenzhong Lan, Zhongwen Xu, Xuanchong Li, Y ang Cai, et al., “Informedia@ trecvid 2014 med and mer , ” in NIST TRECVID V ideo Retrieval Evaluation W ork- shop , 2014, vol. 24. [2] Y u-Gang Jiang, Xiaohong Zeng, Guangnan Y e, Dan Ellis, Shih-Fu Chang, Subhabrata Bhattacharya, and Mubarak Shah, “Columbia-ucf trecvid2010 multimedia e vent detection: Com- bining multiple modalities, contextual concepts, and temporal matching., ” in TRECVID , 2010, vol. 2, pp. 3–2. [3] Zhen-zhong Lan, Lei Bao, Shoou-I Y u, W ei Liu, and Alexan- der Hauptmann, “Double fusion for multimedia ev ent detec- tion, ” Advances in Multimedia Modeling , pp. 173–185, 2012. [4] Hui Cheng, Jingen Liu, Saad Ali, Omar Javed, Qian Y u, Amir T amrakar , Ajay Di v akaran, Harpreet S Sawhney , R Manmatha, James Allan, et al., “Sri-sarnoff aurora system at trecvid 2012: Multimedia e v ent detection and recounting, ” in Pr oceedings of TRECVID , 2012. [5] Pradeep K Atrey , Namunu C Maddage, and Mohan S Kankan- halli, “ Audio based ev ent detection for multimedia surveil- lance, ” in Acoustics, Speech and Signal Pr ocessing, 2006. ICASSP 2006 Pr oceedings. 2006 IEEE International Confer- ence on . IEEE, 2006, vol. 5. [6] Janvier Maxime, Xavier Alameda-Pineda, Laurent Girin, and Radu Horaud, “Sound representation and classification bench- mark for domestic robots, ” in 2014 IEEE International Con- fer ence on Robotics and Automation (ICRA) . IEEE, 2014, pp. 6285–6292. [7] Maxime Jan vier , Xavier Alameda-Pineda, Laurent Girinz, and Radu Horaud, “Sound-event recognition with a companion hu- manoid, ” in 2012 12th IEEE-RAS International Conference on Humanoid Robots (Humanoids 2012) . IEEE, 2012, pp. 104– 111. [8] Jose F Ruiz-Mu ˜ noz, Mauricio Orozco Alzate, and Germ ´ an Castellanos-Dom ´ ınguez, “Multiple instance learning-based birdsong classification using unsupervised recording segmen- tation, ” in 24th International Joint Confer ence on Artificial Intelligence , 2015. [9] Antti J Eronen, V esa T Peltonen, Juha T Tuomi, Anssi P Kla- puri, Seppo Fagerlund, T imo Sorsa, Ga ¨ etan Lorho, and Jyri Huopaniemi, “ Audio-based context recognition, ” IEEE T rans- actions on Audio, Speec h, and Language Pr ocessing , vol. 14, no. 1, pp. 321–329, 2006. [10] Tuomas V irtanen, Annamaria Mesaros, T oni Heittola, Mark D. Plumbley , Peter Foster , Emmanouil Benetos, and Math- ieu Lagrange, Pr oceedings of the Detection and Classification of Acoustic Scenes and Events 2016 W orkshop (DCASE2016) , T ampere Univ ersity of T echnology . Department of Signal Pro- cessing, 2016. [11] Dimitrios Giannoulis, Emmanouil Benetos, Dan Stowell, Mathias Rossignol, Mathieu Lagrange, and Mark D Plumbley , “Detection and classification of acoustic scenes and ev ents: an IEEE AASP challenge, ” in 2013 IEEE W ASP AA . IEEE, 2013, pp. 1–4. [12] A. Mesaros, T . Heittola, A. Diment, B. Elizalde, A. Shah, E. V incent, B. Raj, and T . V irtanen, “DCASE 2017 challenge setup: T asks, datasets and baseline system, ” in Pr oceedings of the Detection and Classification of Acoustic Scenes and Events 2017 W orkshop (DCASE2017) , Nov ember 2017, submitted. [13] Jort F . Gemmeke, Daniel P . W . Ellis, Dylan Freedman, Aren Jansen, W ade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter , “ Audio set: An ontology and human-labeled dataset for audio e vents, ” in Proc. IEEE ICASSP 2017 , New Orleans, LA, 2017. [14] Justin Salamon and Juan Pablo Bello, “Unsupervised fea- ture learning for urban sound classification, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2015 IEEE Interna- tional Confer ence on . IEEE, 2015. [15] Benjamin Elizalde, Gerald Friedland, Ho ward Lei, and Ajay Div akaran, “There is no data like less data: Percepts for video concept detection on consumer-produced media, ” in Pr o- ceedings of the 2012 A CM international workshop on A udio and multimedia methods for larg e-scale video analysis . ACM, 2012, pp. 27–32. [16] W enjing Han, Eduardo Coutinho, Huabin Ruan, Haifeng Li, Bj ¨ orn Schuller , Xiaojie Y u, and Xuan Zhu, “Semi-supervised activ e learning for sound classification in h ybrid learning en vi- ronments, ” PloS one , v ol. 11, no. 9, pp. e0162075, 2016. [17] Ankit Shah, Rohan Badlani, Anurag Kumar , Benjamin Elizalde, and Bhiksha Raj, “ An approach for self-training audio ev ent detectors using web data, ” arXiv pr eprint arXiv:1609.06026 , 2016. [18] C. Gan, T . Y ao, K. Y ang, Y . Y ang, and T . Mei, “Y ou lead, we e xceed: Labor-free video concept learning by jointly e x- ploiting web videos and images, ” in 2016 IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) , June 2016, pp. 923–932. [19] Chuang Gan, Chen Sun, Lixin Duan, and Boqing Gong, “W ebly-supervised video recognition by mutually voting for relev ant web images and web video frames, ” in Eur opean Con- fer ence on Computer V ision (ECCV) , 2016. [20] Anurag Kumar and Bhiksha Raj, “ Audio ev ent detection using weakly labeled data, ” in 24th ACM International Confer ence on Multimedia . A CM Multimedia, 2016. [21] Shawn Hershe y , Sourish Chaudhuri, Daniel PW Ellis, Jort F Gemmeke, Aren Jansen, R Channing Moore, Manoj Plakal, Devin Platt, Rif A Saurous, Bryan Se ybold, et al., “Cnn ar- chitectures for lar ge-scale audio classification, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE Interna- tional Confer ence on . IEEE, 2017, pp. 131–135. [22] Anurag Kumar and Bhiksha Raj, “Deep cnn frame work for audio e vent recognition using weakly labeled web data, ” arXiv pr eprint arXiv:1707.02530v2 , 2016. [23] Karol J Piczak, “En vironmental sound classification with con volutional neural networks, ” in 2015 IEEE 25th Interna- tional W orkshop on Mac hine Learning for Signal Pr ocessing (MLSP) . IEEE, 2015, pp. 1–6. [24] J. Salamon, C. Jacoby , and J. P . Bello, “ A dataset and tax- onomy for urban sound research, ” in 22st ACM International Confer ence on Multimedia (A CM-MM’14) , Orlando, FL, USA, Nov . 2014. [25] Annamaria Mesaros, T oni Heittola, and T uomas V irtanen, “TUT database for acoustic scene classification and sound ev ent detection, ” in 24th Eur opean Signal Pr ocessing Con- fer ence 2016 (EUSIPCO 2016) , Budapest, Hungary , 2016.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment