Emirati-Accented Speaker Identification in each of Neutral and Shouted Talking Environments
This work is devoted to capturing Emirati-accented speech database (Arabic United Arab Emirates database) in each of neutral and shouted talking environments in order to study and enhance text-independent Emirati-accented speaker identification perfo…
Authors: Ismail Shahin, Ali Bou Nassif, Mohammed Bahutair
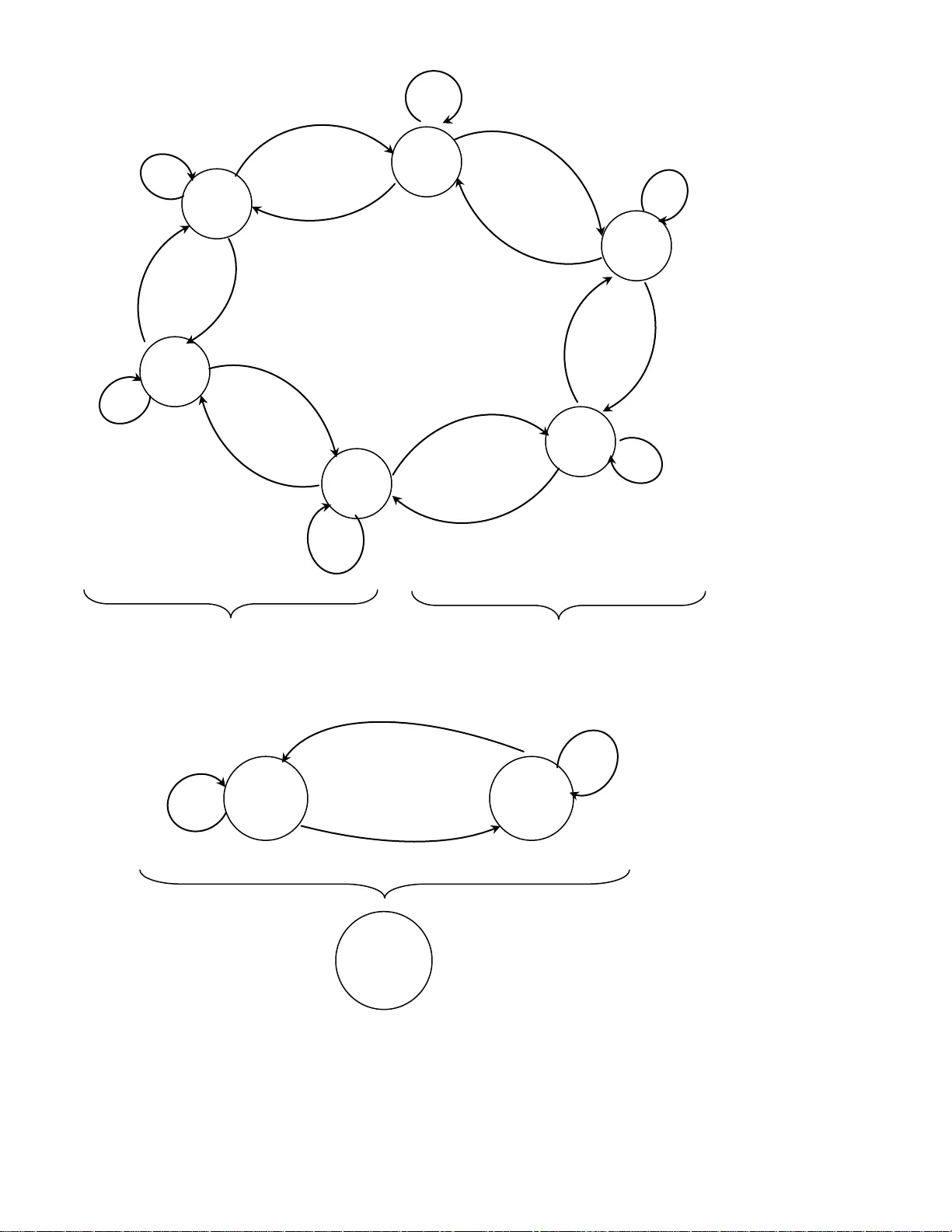
1 Emirati-Accented Speaker Identification in each of Neutral and Shouted Talking Environments Ismail Shahin 1,a , Ali Bou Nassif 2,b , Mohammed Bahutair 3,c 1, 2, 3 Department of Elec trical and Computer Engineering, University of Sharjah, Sharjah, UAE a ismail@sharjah.ac.ae , b anassif@sharjah.ac.ae, c mohammed.bahutair@hotmail.com Abstract This work is devoted t o capturing Emirati-accented spee ch database (Arabic United Arab Emirates database) in each of neutral and shouted talking environments in order to stud y and enhance text-independent Emirati-accented “ speaker identification performance in shouted environment ” based on each of “ First-Order Circular Suprasegmental Hidden Markov Models (CSPHMM1s), Second-Order Circular S uprasegmental Hid den Markov Models (CSPHMM2s), and Third-Order C ircular Suprasegmental Hidden Markov Models (CSPHMM3s) ” as classifiers. In this research, our database was collected from fifty Emirati native speakers (twent y five per gender) utte ring ei ght common Emirati sentences in each of neutral and shouted talking environments. The extracted features o f our collected database are called “ Mel-Frequenc y Cepstral Coefficients (MFCCs) ” . Our results show that average Emirati-accented speaker identification performance in neutral environment is 94.0%, 95.2%, and 95.9% based on CSPHMM1s, CSPHMM2s, and CSPHMM3s, respective ly. On the other hand, the average performance in shouted environment is 51.3%, 55.5%, and 59.3% ba sed, respectively, on “ CSPHMM1s, CSPHMM2s, and CSP HMM3s ” . Th e achieved “ average speake r identification performance in shouted environment based on CSPHMM3s ” is very simi lar to that obtained in “ subjective assessment by human listeners ” . 2 Keywords : Emirati-accented speech databa se; hidden Markov models ; “ neutral talking environment ” ; “ shouted talking environment ” ; speaker identification; suprasegmental hidden Markov models. 1. Introduction and Literature Review “ Speaker recognition ” is categorized into two different main ty pes : “ speaker identification and speaker verification (authentication) ” . “ Speaker identification ” is defined as the method of automatically finalizing who is speaking from a group of known speakers. “ Speaker verification ” is defined as the method of automatically acce pting or rejecting the identity of the claimed speaker. “ Speaker identification ” can be heavily utilized in investigating criminals to conclude the speculated suspects who produced a voice captured at the episode of a crime. On the other side, “ speaker verification ” is broadly utili zed i n security entry to services through a telephone such as: “ home shopping, home banking transactions using a telephone network, security control for restricted information areas, remote access to computers, and many other telecommunication services ” [ 1]. “ Speaker recog nition ” is grouped, based on the text to be spoken, into “ text- dependent and text-independent cases ” . I n the “ text-dependent case ” , “ speaker recognition ” necessitates the spea ker to utter speech for the same text in both training and testing phases, while in the “ text-independent case ” , “ speaker recognition ” is independe nt on the text being uttered. Arabs can communica te among themselves in the Ar ab count ries in on e of the four regional dialects of the Arabic language. These dialects are: Eg y ptian ( e.g. Egyptian), Leva ntine ( e.g. Palestinian), North African ( e.g. Algerian), and Gulf Arabic ( e.g. Emirati) [2]. 3 I n the areas of speaker recog nition and speech processing and recognition, most of the researc h work has been focus ed on speech spoken in English languag e [1], [3], [4], [5] while very limited number of studies focus on these areas on speech utt ered in Arabic language [ 6], [7], [ 8], [9] , [10]. One of the reasons of these few number of studies is the small number of accessible Arabic speech datasets in these are as [11], [12]. Al -Dahri et.al [6] studied word-depe ndent “ speake r identification systems ” encompassing 100 speake rs speaking Arabic isolated words based on “ Hidden Markov Models (HMMs) ” . “ Mel-Frequenc y Cepstral Coefficients (MFCCs) ” have been adopted as the extracted features of the utilized dataset. They reported 96.3% accuracy to recog nize the correct speaker [6]. Krobba et.al [7] investigated the effect of GSMEFR speech data on the performance of a “ text -independent speaker identification sy stem ” based on “ Gaussian Mixture Models (GMMs) ” as classifiers. The recognition assessment was also performed using original “ ARADI GI T sampled at 16 KHz and its 8 KHz down -sampled version ” . The “ ARADIGI T database ” is made up of 60 speakers generating the ten Arabic digits with a replicate of thre e times each. Various e xperiments were ac complished to calculate the deterioration caused by diverse aspects of the simulated codec [ 7]. Mahmood et.al [ 8] proposed and i mp lem ente d no vel f eatu res c all ed “Mu lt i-D irec tio nal Loc al F eat ure ( MDLF) ” for sp eake r reco gnit io n. In o rder to e xt ract MDLF, a wi ndo wed s pee ch si gnal h as b een pro cess ed b ased on “ Fas t Fo uri er T ra nsf orm (FFT) ” an d p ass ed th rough 24 M el -sc aled Fi lter Ban k, fol lo wed by a log com pre ssi on st age. M D LF ca rrie s the c harac teri st ics o f the s peak er in t ime s pect rum a nd yields a n im prov ed perfo rma nce. As a clas sif ier, G MM w it h a d iffe rent num ber o f mix tu res has been u sed in the ir wo rk . Th eir resu lts sho wed that th e pro pos ed MD LF gave hi gher reco gnit io n ac cu racy tha n t he tra dit io nal MFC C f eatu res. The MDLF o btai ns out sta ndi ng res ult s both in “ tex t- depe nde nt an d tex t -i nde pend ent speak er reco gnit io n ” usi ng Ara bic an d 4 Engl is h da tab ases [ 8] . S aeed and Nammous [ 9 ] studied a speech-and-spea ker (SAS) identification sy stem based on spoken Arabic digit recognition. The speech signals of the Arabic digits from zero to ten have been processed gra phically (the signal has been considered as a n object image for additional processing). The identification and classification stag es have been conducted with “ Burg' s estimation model ” and the algorithm of “ Toeplitz matrix minimal eigenvalues ” have been used as the major tools for signal -image description and feature extraction. I n the classification stage, both “ conventional and neur al-network-base d ” methods have been used. Their reported average overall success rate was 97. 5% to recog nize one utt ered word and recognizing its speaker, and 92.5% to recognize a three-digit password (three individual words) [9]. Tolba [ 10 ] used “ Continuous Hidden Markov Models (CHMMs) ” as a classifier to automatically identify Arabic speakers from their voices. MFCCs have been utili zed as the extracted features of speech signals. Ten Arabic speakers have been used to assess his proposed CHMM -based engine. His reported speake r identification performance is 100% and 80% for “ text-dependent and text-independent ” sy stems, respectively [10]. There are few number of publications that use Emirati-accented speech database [13], [14]. To the best of our knowledge, there are only two available studies in the area s of speech and speaker recog nition that use Emirati-accented database [13], [14]. Shahin and Ba-Hutair [13 ] studied in one of their work Emirati-accented “ speaker identification sy stems ” in a neutral ta lking environment based on each of “ Vector Quantization (VQ), GMMs, and HMMs ” as classifiers. The Emi rati database is made up of 25 men and 25 women Emirati native speakers. These speakers uttered 8 famous Emirati sentences that are broadly utilized in the “ United Arab Emirates society ” . The eight sentences were neutrally uttered (no stress or emotion) by each 5 speaker 9 times with a span of 1 – 3 seconds. They used MFCCs as the ex tracted feature s of their dataset. Their results showed that “ VQ ” is superior to each of “ GMMs and HMMs ” for both “ text-dependent and tex t-independent ” Emirati speaker identification. In another work by Shahin [14], he focused on evaluating a “ text-independent speaker verification ” using Emirati speech dataset collected in a neutral talking environment. The dataset was captured from 25 men and 25 women Emirati native speakers who uttered 8 commonly-used Emirati sentences. MFCCs have been utilized as the extracted features of speech signals. Three distinct classifiers have been employ ed in his work. These classifiers a re: “ First-Orde r Hidden Markov Models (HMM1s), Second-Order Hidden Markov Models (HMM2s), and Third -Order Hidden Markov Models (HMM3s) ” . His results show ed that HMM3s outperform each of HMM1s and HMM2s for a text-independent Emirati-accented speaker verification. This work aims at collecting Emirati-accented speech database (Arabic United Arab Emira tes database) uttered in each of “ neutral and shouted talking environments ” in order to study and enhance text-independent Emirati-accented “ speaker identification performance ” in a shouted environment based on each o f “ First-Order Circular Supraseg mental Hidden Markov Models (CSPHMM1s), Second-Order Circular Suprasegmental Hidden Markov Models (CSPHMM2s), and Third-Order C ircular Suprasegmental Hidden Markov Models (CSPHMM3s) ” as classifiers. These classifiers are novel for Emirati-accented speaker identification. In addition, seven experiments have been conducted to thoroughly study Emirati-accented “ speaker identification in each of neutral and shout ed talking environments ” . In this research, our speech database was captured from fifty Emirati native speakers (twenty five male and twenty five female) uttering eight common Emirati sentences in each of “ neutral and shouted environments ” . MFCCs have 6 been adopted as the ex tracted features of our collected dataset. This work is different from our two previous studies [13] , [14]. In [ 13], Shahin and Ba-Hutair studied Emirati-accented “ speaker identification sy stems in a neutral environment ” only based on each of “ VQ, GMMs, and HMMs ” as classifiers. In [ 14], Shahin focused on evaluating a tex t-independent speaker verification using Emirati-acce nted speech database captured in a neutral environment only based on three different classifiers: “ HMM1s, HMM2s, and HMM3s ” . The remaining structure of this paper is as follows: Brief overview of supraseg mental hidden Markov models is given in Section 2. The basics of “ CSP HMM1s, CSPHMM2s, and CSPHMM3s ” are given in Section 3. Section 4 gives the details of the captured speech database used in this work and the extracted features. “ Speaker identification algorithm in each of neutral and shouted environments based on CSPHMM1s, CSPHMM2s, and CSPHMM3s ” and the experiments are discussed in Section 5. Section 6 gives the results attained in the present work and their discussion. Finally , concluding remarks are given in Section 7. 2. Overview of Suprasegmental Hidden Markov Mode ls I n many of his studies, Shahin ex ploited and tested SPHMMs as classifiers. Such studies are: “ speaker identification in each of emotional and shouted environments ” [ 4], [15], [16] , speaker verification in emotional environments [17] , and emotion recognition [ 18], [19]. SPHMMs have proven to be superior models over HMMs in these studies since SPHMMs possess the capability to summarize some states of HMMs int o a new state named “ suprasegmenta l state ” . “ Supraseg mental state ” is able to look at the observation seque nce through a larger window. Such a state lets observations at rates that fit the case of modeling emotional and stressful 7 si gnals. Prosodic information cannot be recognized at a rate that is uti lized for acoustic modeling. The prosodic features of a unit of emotional and stressful signals are named “ supraseg mental fe atures ” be cause they affec t all the segments of the unit signa l. Prosodic events at the levels of “ phone, sy llable, word, and utterance ” are character ized using “ supraseg mental states ” , while “ acoustic events ” are patterned using “ conventional hidden Markov states ” . “ Prosodic information and acoustic information ” are merge d together withi n HMMs as [20], “ O P . O P . 1 O , P v Ψ l og α v λ l og α v Ψ v λ l og (1) where is a weig hting factor. W hen: m odel a coust ic of i mp ac t no a nd m odel p ros odi c t ow a rds c omp le t el y bi ased 1 α m odel a ny t ow ards bi ased not 0.5 α m odel p ros odi c of effe c t no a nd m ode l a coust ic t ow a rds c om p le t e l y bia s e d 0 α m odel p rosodic t owards bi ased 0.5 α 1 m odel a c ous t ic t ow a rds bi a s ed 0 α 0.5 (2) v is the v th acoustic model, v is the v th SPHMM model, O is the observation vector of a n utterance, O v λ P is the probability of the v th HMM model given the observation vector O , and O v P is the probability of the v th SPHMM model given the observation vector O ” . Further information about SPHMMs can be obtained from the referenc es [21], [22] . 8 3. Basics of CSPHMM1s, CSPHMM2s, and CSPHMM3s 3.1. “ First-order circular suprasegmental hidden Markov models ” “ CSPHMM1s ” have been derived from “ acoustic First -Order Circular Hidden Markov Models (CHMM1s) ” . Zheng and Yua n proposed and applied CHMM1s for “ speaker identification in neutral environment ” [ 23 ]. Shahin demonstrated tha t CHMM1s lead “ Left- to -Right First-Order Hidden Markov Models (LTRHMM1s) for sp eaker identification in shout ed environment ” [ 24]. More information about CHMM1s can be found in references [23], [24 ]. Fig. 1 illustrates an example of an essential topolog y of CSPHMM1s that has been formed from CHMM1s. As an example , this figure consists of six “ first-order acoustic hidden Markov states: q 1 , q 2 ,…, q 6 ” placed in a circular sh ape. p 1 is a “ first-order suprasegmental state ” that is made up of “ q 1 , q 2 , and q 3 ” . p 2 is a “ first-order supr asegmental state ” that is comprised of “ q 4 , q 5 , and q 6 ” . p 1 and p 2 are “ two su prasegmental states ” placed in a cir cular st yle. p 3 is a “ first-order suprasegmental state ” which consists of p 1 and p 2 . 3.2. “ Second-order circular suprasegmental hidden Markov models ” “ CSPHMM2s ” have been obtained from acoustic “ Second-Order Circular Hidden Markov Models (CHMM2s) ” [22] . Shahin proposed, used, and assessed CHMM2s for speaker recog nition in each of “ shouted and emotional environments ” [24]. Shahin showed in his studies that these models outperform each of “ LTRHMM1s, L TRHMM2s, and C HMM1s ” since CHMM2s hold the characteristics of both “ CHMMs and HMM2s ” [24 ]. Readers can get additional details about CHMM2s and CSPHMM2s from referenc e [ 24] and [22], respectively . 9 a 66 a 61 a 12 a 22 a 16 a 56 a 65 a 21 a 32 a 23 a 55 a 54 a 43 a 33 a 45 a 44 a 34 b 12 b 11 b 22 b 21 Figure 1. Basic structure of CSPHMM1s attained from CHMM1s q 5 q 4 q 3 q 2 q 1 q 6 a 11 P 2 P 1 P 3 10 As an example of CSPHMM2s, the six “ first-order acoustic circular hidden Markov states ” of Fig. 1 are replaced by six “second -order acoustic circular hidden Markov states ” ordered in the similar shape. p 1 and p 2 become “second -order suprasegmental states ” located in a circular form. p 3 is a “second -orde r suprasegmental state ” which is comprised of p 1 and p 2 . 3.3. “ Third-order circular suprasegmental hidden Markov models ” “ Third-Order Circular Suprasegmental Hidden Markov Models ” have been structured from acoustic “ Third-Order H idden Markov Models (HMM3s) ” . I n one of his studies, Shahin [ 25 ] employed, utiliz ed, and tested HMM3s to improv e low “ text -independent speaker identification performance in shouted environment ” . He showed that HMM3s are superior to each of “ HMM1s and HMM2s ” in such an environment [25 ]. I n HMM1s, the “ underly ing state sequence is a first -order Markov chain ” where the stochastic process is stated by a 2 -D matrix of a “ priori transition probabilities ” ( a ij ) between states s i and s j where a ij is given as [25] , ij t j t 1 i a Pr ob q s q s (3) I n HMM2s, the “ underly ing state sequence is a second-order Markov chain ” where the stochastic process is expressed by a 3-D matrix ( a ijk ). Hence, the “ transition probabilities in HMM2s ” are given as [25 ], ijk t k t 1 j t 2 i a Pr ob q s q s , q s (4) 11 I n HMM3s, the “ underly ing state sequence is a third-order Markov chain ” where the stochastic process is stated by a 4-D matrix ( a ijkw ). Accordingly , the “ transition probabilities in HMM3s ” are given as [25], ijk w t w t 1 k t 2 j t 3 i a Pr ob q s q s , q s , q s (5) The “ probability of the state sequence ” , , q ,..., q , q Δ Q T 2 1 is expressed as: 1 1 2 3 t 3 t 2 t 1 t T q q q q q q q q t4 Pr ob (Q ) a a (6) where “ i is the probability of a state s i at time t = 1, a ijk is the probability of the transition from a state s i to a state s k at time t = 3 ” . a ijk can be computed from equation ( 4). Thus, the initi al parameters of HMM3s can be obtained from the trained HMM2s. “ Prosodic and acoustic information ” within CHMM3s can be mingled into CSPHMM3s as [16], “ O Ψ P . α O λ P . α 1 O Ψ , λ P C S P HMM 3s C HMM 3s C S P HMM 3s C HMM 3s v v v v l og l og l og (7) where, v C H MM 3s λ is the acoustic third-order circular hidden Markov model of the v th speaker and v C SPHM M3s Ψ is the suprasegmenta l thi rd-order circular hidden Markov model of the v th speaker ” . To give an example of CSPHMM3s, the six “ first-order acoustic circular hidden Markov states ” of Fig. 1 are subst ituted by six “ third-order acoustic circular hidden Markov states ” structured in 12 the identical figure. p 1 and p 2 come to be third-order supra segmenta l states positioned in a circular structure. p 3 is a third-order suprasegmenta l state which is comprised of p 1 and p 2 . Shahin [ 16] showed that CSPHMM3s outperform each of CSPHMM1s and CSPHMM2s for speaker identification in a shout ed environment. This is because the characteristics of CSPHMM3s are composed of the chara cteristics of both “ Circular S uprasegmental Hidden Markov Models (CSPHMMs) ” and “ Third-Order Suprasegmental Hidden Markov Models (SPHMM3s) ” . 4. Emirati-Accented Speech Dataset and Extraction of Features 4.1. Collected Emirati-Accented Speech Dataset In this stud y, twenty fi ve male and twenty five female native Emirati speakers with ages spanning from 14 to 55 year old uttered the Emirati-accented speech database (Arabic database). Each speaker uttered 8 common Emirati sentences that are heavil y uti lized in the “ United Arab Emirates societ y ” . The eight sentences w ere po rtrayed by every speaker in ever y “ neutral and shouted environments ” (two isolated environments) 9 times with a span of 2 – 5 seconds. Th ese speakers were untrained to utter the Emirati sentences in advance to avoid any overstated expressions (to make this database spontaneous). The total collected number of utterances was “ 5400 ((50 spe akers × fir st 4 se ntences × 9 repetitions/sentence in ne utral environment fo r training session) + (50 speakers × last 4 sentences × 9 repetitions/sentence × 2 talking environments for testin g sessions )) ” . The sentences are tabulated in Tab le 1 (the ri ght column gives the sentences in Emi rati accent, the left column demonstrates the English version, and the 13 middle column shows the phonetic t ranscriptions of these sentences ). Thi s dataset was captured in two separate and distinct sessions: training session and testing ( identification) session. The recorded dataset was captured in an uncontaminated environment in the C ollege of Communication, “ Unive rsity of Sharjah, United Arab Emirates ” b y a group of professional engineering students. Th e database w as collected by a “ speech acquisiti on board usin g a 16-bit linear coding A/D converter and sampled at a sa mpling rate of 44.6 kHz ” . The signals were then down sampled to 12 k Hz. The samples o f si gnals were pre -emphasized and then segmented int o slices (frames) of 20 ms each with 31.25% intersection between successive slices. Table 1 Emirati speech database in its: English version, phonetic transcriptions, and Emirati acce nt No. English Version Phonetic Transcriptions Emirati Accent 1. We will meet with you in an hour. / bintl ɑ:ga wɪjɑ:k ʕugub sɑ:ʕah / 2. Go to my father he wants you. /si:r ʕɪ nd abu:jeh yib ɑ:k / 3. Bring my cell phone from the room. /ha:t til ɪ fu:ni: m ɪ n ɪ l ḥɪ jrah / 4. I am busy now I will talk to you later. / ma ʃɣɔ : ɫ (a) ʌḥ i:n barams ɪ k ʕʌ b s ɑ:ʕəh / 5. Every seller praises his market. / k ɪ l byai ʕ y ɪ mde ḥ su:gah / 6. A stranger is a wolf whose bite wounds won’t heal. / ɪlġari:b ði:b w ʕ a ẓ itah ma ṭ i:b / 7. Show respect around some people and show self-respect around other people. / na:æs ɪḥ ʃɪ mhom w na:s ɪḥ ʃɪ m nafsak ʕ anhom / 8. Don’t criticize what you can’t get and don’t swirl around something you can’t obtain. / illi magdart tiyibah l ɑ: tʕi:bah w illi mɑ:ṭ u:lah l ɑ: tḥ u:m ḥ u:lah / 14 4.2. Extraction of Features As features extracted from the Emirati-accented speech database, MFCCs have been uti lized in this study as the appropriate feature s that extract the phonetic content of Emirati-accented signals. These feature s have been large ly used in many area s of speech. Ex amples of such areas are speech and speaker recog nition. MFCCs have proven to outperform other coefficie nts in the two areas and they have shown to grant a high-level approximation of human auditory perception [17], [ 26], [27], [28] . I n this study, a 32-dimension feature analy sis of MFCCs (16 static MFCCs and 16 delta MFCCs) wa s utili zed to found the observation vectors in ea ch of “ CSPHMM1s, CSPHMM2s, and C SPHMM3s ” . I n each one of these models, a “ continuous mix ture observation density ” was chosen. In every suprasegmental model, the number of “ conventional states, N , is nine and the number of supraseg mental states is three ( every suprasegmental state is made up of three conventional states) ” . 5. “ Speaker Identification Algorithm in each of Neutral and Shouted Environments Based on CSPHMM1s, CSPHMM2s, and CSPHMM3s ” and the Experiments The “ training phase ” of each of “ CSPHMM1s, CSPHMM2s, and CSPHMM3s ” is very similar to the “ training phase ” of the “ conventional C HMM1s, CHMM2s, and CHMM3s ” , respectively . In the “ training phase ” of each of “ CSPHMM1s, CSPHMM2s, and CSPHMM3s ” (completely three isolated training phases), “ suprasegmental first-orde r circ ular models, suprasegmenta l second- order circular models, and suprasegmenta l third-order circular models ” are trained on top of “ acoustic first-order circular models, acoustic second-order circular models, and acoustic third- order circular models ” , respectively . In every “ training phase ” , the v th speaker model has been obtained utilizing the “ first four sentences ” of the Emirati-accented speech dataset with 9 15 replicates for every sentence spoken by the v th speaker in “ neutral environment ” . The entire number of utt erance s that have been utili zed to obtain the v th speaker model in every “ tr aining phase ” is 36 ( “ first 4 sentences × 9 repetitions/sentence ” ). In the “ test (identification) phase ” of each of “ CSPHMM1s, CSPHMM2s, and CSPHMM3s ” (entirely three separate “ test phases ” ), every one of the “ fifty speakers ” independently utters each sentence of the “ last four sentences ” of the dataset (text-independe nt) with 9 replicates per sentence in each of “ neutral and shouted environments ” . The overall number of utterances that have been uttered in every identification phase per talking environment is 1800 “ (50 speakers × last 4 sentences × 9 repetitions/sentence) ” . The probability of producing every utterance per speaker is independently calculated based on each of “ CSPHMM1s, CSPHMM2s, and CSPHMM3s ” . For every one of these three “ suprasegmental models ” , the model with the maximum probability is selected as the output of “ speaker identification ” as given in the coming formula for every talking environment: v mode l v mode l v , O P 1 50 m a x ar g * V (8) where “ O is the observation vector or sequence that corresponds to the unknown speaker, v m ode l is the acoustic hidden Markov model (this model c an be one of: CHMM1s, CHMM2s, or CHMM3s) of the v th speaker and v m ode l is the supraseg mental hidden Markov model (this model can be one of: CSPHMM1s, CSPHMM2s, or CSPHMM3s) of the v th speaker ” . 16 6. Results and Discussion The current research focuses on collecting Emirati-accented speech database uttered in each of neutral and shouted environments for the purpose of study ing and improving tex t-independent Emirati-accented “ speaker identification in shouted environment ” based on each of “ CSPHMM1s, CSPHMM2s, and CSPHMM3s ” as classifiers. These classifiers are novel for Emirati-accented speaker identification. In this research, the weighting factor has been selected to be equal to 0.5 to avoid biasing towards either “ acoustic or prosodic model ” in each of “ CSPHMM1s, CSPHMM2s, and CS PHMM3s ” . I n this work, our Emirati-acce nted speech databa se was collec ted in “ one of the studios that belong to the College of Communication at the University of Sharjah in the United Arab Emirates ” . Twenty five speakers per gender volunteered to utter eight common Emirati sentences with a replication of nine times each under each of neutra l and shouted environments. There were some difficulties that faced the team who captured this database: 1) The collected database is acted and unspontaneous. Therefore , the achieved results based on using such data are biased. The vast majority of studies usually use acted speech database since it is very difficult to collect spontaneous one. 2) There are some logistic problems in bringing old people to the university to collect their voices. 3) The speakers are volunteers and unprofessional ones. 17 Table 2 represents “ speaker identification performance in each of neutral and shouted environments ” using the Emirati-accented speech corpus based on each of the suprasegmenta l models: “ CSPHMM1s, CS PHMM2s, and CSPHMM3s ” as classifiers. This table clearly demonstrates that “ speake r identification performanc e ” is almost ideal in neutra l environmen t based on each one of these three classifiers. The reason is that each acoustic model ( “ CHMM1s, CHMM2s, and CHMM3s ” ) re sults in a high “ speaker identification performance ” in such an environment as given in T able 3. However, the performance has been steeply deteriorated in shouted environment since each corresponding acoustic model results in a poor “ speaker identification performance ” under this environment as shown in Table 3. I t is evident from Table 2 that “ CSPHMM3s ” outperform each of “ CSPHMM1s and CSPHMM2s ” in shouted environment by 15.6% and 6.8%, respec tively . Table 2 “ Speaker identification performance in each of neutral and shouted environments ” using Emirati- accented dataset based on each of the suprasegmental models: “ CSPHMM1s, CSPHMM2s, and CSPHMM3s ” Suprasegmental model Gender “ Speaker identification performance (%) ” “ Neutral environment ” “ Shouted environment ” CSPHMM1s Male 95.2 52.1 Female 92.8 50.5 Average 94.0 51.3 CSPHMM2s Male 96.0 56.7 Female 94.4 54.3 Average 95.2 55.5 CSPHMM3s Male 96.6 60.4 Female 95.2 58.2 Average 95.9 59.3 18 Table 3 “ Speaker identification performance in each of neutral and shouted environments ” using Emirati- accented dataset based on each of the acoustic models: “ CHMM1s, CHMM2s, and CHMM3s ” Acoustic model Gender “ Speaker identification performance (%) ” “ Neutral environment ” “ Shouted environment ” CHMM1s Male 91.4 38.0 Female 90.2 35.4 Average 90.8 36.7 CHMM2s Male 91.9 45.1 Female 90.7 42.7 Average 91.3 43.9 CHMM3s Male 92.8 50.2 Female 91.6 48.8 Average 92.2 49.5 “ Speaker identification performanc e based on the three acoustic models (CHMM1s, CHMM2s, and CHMM3s) ” has been significantly decreased in “shouted environment” compa red to that in “neutral environment” as shown in Table 3 . Acoustically, when speake rs shout, air pressure inside the speaker’ s vocal tract is increased significantly . This increase creates a big cavity that enlarge s vortices inside the vocal tract. Enlarg i ng the vortices results in an increase in the genera tion of sound that interse cts with the original sound [29]. He nce, the original speaker’s sound is contaminated with other sounds. Consequently , the mismatch that exists between the “training session in neutral environment” and the “testing session in shouted environment” is increased. This increase in the mismatch negatively affects “speaker identification performance in shouted environment based on each one of the acoustic models: CHMM1s, CHMM2s, and CHM M3s” . 19 To demonstrate whether “ speaker identification performance ” differe nces ( “ spea ker identification performance ” based on CSPHMM3s and that based on each of CSPHMM1s and CSPHMM2s in each of “ neutral and shouted environments ” ) are actual or just a ppear from statistical variations, a “ statistical significance test ” has been conducted. The “ statistical significance test ” has been performed based on the “Student’s t Distribution test ” as given by the following formula, p o o l ed 2 m o d el 1 m od el 2 m o d el 1, m od el SD x x t ( 9) wher e “ 1 m o d el x is the mean of the first sample (model 1) of size n , 2 m o d el x is the mean of the second sample (model 2) of the same size, and SD pooled is the pooled standard deviation of the two samples (models) ” given as, 2 SD SD SD 2 2 m o d el 2 1 m o d el p o o led (10) where “ SD model 1 is the standard deviation of the first sample (model 1) of size n and SD model 2 is the standard deviation of the second sample (model 2) of the same size ” . In this stud y, the “ calculated t values ” between “ CSPHMM3s ” and each of “ CSPHMM1s and CSPHMM2s ” in each of “ neutral and shouted environments ” using the Emirati-accented dataset are t abulated in Table 4. This table illustrates that each “ calculated t value in neutral environment ” is smaller than the “ tabulated critical value t 0.05 = 1.645 at 0.05 significant level ” . In contrast, each “ ca lculated t value in shouted environment ” is greater than the “ tabulated critical value t 0.05 = 1.645 ” . Therefore, “ CSPHMM3s ” significantly outperform each of 20 “ CSPHMM1s and CSPHMM2s in shouted environment ” . It is apparent that “ CSPHMM3s ” are superior models to each of “ CSPHMM1s and CSP HMM2s for speaker id entification ” since the “ characteristics of CSPHMM3s ” are comprised of the characteristics of b oth “ CSPHMM1s and CSPHMM2s ” . In CSPHMM3s, the “ state sequence is a third-order suprasegmental chain ” where the stochastic process is stated by a “ 4-D matrix ” since the “ state-transition probability at time t+1 depends on the states of the suprasegmental chain at times : t , t-1 , and t-2 ” . Accordingly, the stochastic process that is stated by a “ 4-D matrix ” yields greater “ s peaker id entification performance ” than that defined b y either a “ 2-D matrix (CSPHMM1s) or a 3- D matrix (CSPHMM2s) ” . The dominance of “ CSPHMM3s ” over each of the other tw o models becomes insignificant in “ neutral environment since the acoustic models: CHMM1s, CHMM2s, and CHMM3s ” function well in such an environment as shown in Table 3. Table 4 “ Calculated t values between CSPHMM3s and each of CSPHMM1s and CSPHMM2s in each of neutral and shouted environments ” using Emirati-accented corpus “ t model 1, model 2 ” Calculated t value “ Neutral environment ” “ Shouted environment ” “ t CSPHMM3s , CSPHMM1s ” 1.498 1.882 “ t CSPHMM3s , CSPHMM2s ” 1.523 1.801 Table 2 stat es also th at speaker i dentification performance for male Emirati speakers is greater than that for fe male Emirati speakers. Therefore, it can be concluded from this experiment that male Emirati speakers can be easil y identified compared to fe male Emirati speakers. This conclusion is in agreement with the UAE culture where the sp eech of the UAE female speakers is very close (female spe akers’ sp eech cannot be easily recognized); howe ver, the speech of the 21 UAE male speakers is different (male speakers’ speech can be easily reco gnized). Table 5 gives the “ calculated t values ” between m ale and fe male Emirati spe akers based on each of “ CSPHMM1s, C SPHMM2s, and CSP HMM3s in each of neutral and shouted environments ” using the Emirati-accented database. Table 5 “ Calculated t values ” between male and fe male Emirati speakers based on each of “ CSPHMM1s, CSPHMM2s, and CSPHMM3s in each of neutral and shouted environments ” using the Emirati- accented database t male , fe mal e “ Calculated t value ” “ Neutral environment ” “ Shouted environment ” CSPHMM1s 1.699 1.702 CSPHMM2s 1.717 1.793 CSPHMM3s 1.796 1.809 The “ calculated t values ” between each “ supraseg mental model ” and its belonging “ acoustic model in each of neutral and shouted environments ” using the Emirati-accented dataset are given in Table 6. This table clearly demonstrates that each “ suprasegmental model ” is superior to its corresponding “ acoustic model ” in each environment as each “ calculated t value ” in this table is higher than the “ tabulated critical value t 0.05 = 1.645 ” . Table 6 “ Calculated t values ” between each “ suprasegmental model ” and its corresponding “ acoustic model in each of neutral and shouted environments ” using Emirati-accented dataset “ t sup. model, acous tic model ” “ Calculated t value ” “ Neutral environment ” “ Sh outed environment ” “ t CSPHMM1s , CHMM1s ” 1.798 1.823 “ t CSPHMM2s , CHMM2s ” 1.806 1.861 “ t CSPHMM3s , CHMM3s ” 1.875 1.880 22 The obtained “ speaker identification performance in a neutral environment ” using Emirati- accented speech database (none of the previous studies have focused on “ speaker identification in shouted environment ” ) based on “ CSPHMM3s ” has been competed with that reported in some prior studies (non-Emirati Arabic database) in the same environment of: 1) Al -Dahri et.al [6] who studied word-dependent speaker identification sy stems containing 100 speakers utt ering Arabic isolated words based on HMMs as classifiers and MFCCs as the adopted extracted features of their used database. They achieved 96. 3% as a speaker identification performance [6] . Our achieved results based on C SPHMM3s are very close to their attained results. 2) Mahmood et.al [8] who proposed and applied novel feature s called MDLF for speaker identification. Based on MDL F as the extracted fe atures and GMM as the classifier, they obtained 98.9% as a speaker identification performance. Our reported results based on CSPHMM3s are very alike to their achieve d ones. 3) Tolba [10] who used CHMMs as classifiers to automatically identify Arabic speakers from their voice s and MFCCs as the extr acted feature s of speech sig nals. He obtained speaker identification performance of 80.0%. Our attained results in the current work outperform his results. Seven extra experiments have been separately executed in this study to ex tensively evaluate the attained “ speaker identification performance in each of neutral and shouted environments ” using Emirati-accented database based on “ CSPHMM3s ” . The seven experiments are: 23 1) Ex periment 1: “ Speaker identification performanc e ” using the Emirati-accented speech dataset based on “ CSPHMM3s ” has been competed with that based on four distinct “ state-of-the- art models and classifiers ” . The four classifiers and models are: “ Gaussian Mixture Models (GMMs) [ 30], [31] , Support Vector Machine (SVM) [ 32], [ 33], Genetic Algorithm (GA) [ 34], [35] , and Vector Quantization (VQ) ” [36] , [37] . Table 7 demonstrates speaker identification performance using the Emirati -accented dataset based on each of “ GMMs, SVM, GA, VQ, and CSP HMM3s ” . It is apparent from Table 2 and Table 7 that CSPHMM3s lead “GMMs, SVM, GA, and VQ” for Emirati-acce nted “ speaker identification in a neutral environment ” by 7.9%, 4.4%, 8.1%, and 6.6%, respectively . The two tables also show that “ CSPHMM3s ” a re super ior to “GMMs, SVM, GA, and VQ ” by 62.9%, 28.6%, 70.4%, and 83.6%, respec tively , for “ speaker identification in a shouted environment ” . Table 7 “ Speaker identification performance in each of neutral and shouted environments ” using Emirati- accented database based on each of “ GMMs, SVM, GA, VQ, and CSPHMM3s ” Models Gender “ Speaker identification performance (%) ” “ Neutral environment ” “ Shouted environment ” GMMs Male 91.1 54.6 Female 86.7 18.2 Average 88.9 36.4 SVM Male 92.2 56.7 Female 91.6 35.5 Average 91.9 46.1 GA Male 89.6 40.4 Female 87.8 29.2 Av erage 88.7 34.8 VQ Male 91.1 39.3 Female 88.9 25.3 Average 90.0 32.3 CSPHMM3s Male 96.6 60.4 Female 95.2 58.2 Average 95.9 59.3 24 2) Ex periment 2: The three classifiers and models : CSP HMM1s, CSP HMM2s, and CSPHMM3s have been evaluated on the same eight sentences of our collected database but are uttered in this experiment by speakers talking in a formal Arabic languag e (not biased towards any dialect). This database is called a formal-accented speech database. I n this experiment (tex t-independent), both the training and testing phases are comprised of the formal-accented database. The first four neutrally -uttered sentences of this formal- accented database are used in the training session, while the last four sentences of the formal-acc ented database are utilized in the identification session (one session for neutral environment and another separate session for shouted environment). Table 8 illust rates text-independent speaker identification performance based on each of CSPHMM1s, CSPHMM2s, and CSPHMM3s in each of neutral and shouted environments utiliz ing the formal-acc ented dataset. I t is evident from Table 9 that “ average speaker identification performance ” based on training and testin g our system using the Emirati -accented database is higher than that b ased on training and testing our sy stem using the formal- accented database in each of neutral and shouted environments . This is because the eight sentences of our da tabase fit better to native Arabic Emirati speakers rather than to nonnative Arabic Emirati speakers. These eight sentences are basically used in the daily communications among Emirati people only and they are not used among speakers talking in a for mal Ar abic language. Table 9 clearly shows that speaker identification improvement rate is more significant in shouted environment than in neutral environment. 25 Table 8 “ Speaker identification performance in each of neutral and shouted environments ” using formal- accented dataset based on each of “ CSPHMM1s, CSPHMM2s, and CSPHMM3s ” Models Gender “ Speaker identification performance (%) ” “ Neutral environment ” “ Shouted environment ” CSPHMM1s Male 91.1 47.4 Female 90.3 45.6 Average 90.7 46.5 CSPHMM2s Male 92.8 50.2 Female 91.2 48.6 Average 92.0 49.4 CSPHMM3s Male 92.9 55.0 Female 92.1 53.0 Average 92.5 54.0 Table 9 Speaker identification improvement rate of using Emirati-accented database over formal-accented database in each of “ neutral and shouted environments based on each of CSPHMM1s, CSPHMM2s, and CSPHMM3s ” Models “ Speaker identification improvement rate (%) ” “ Neutral environment ” “ Shouted environment ” CSPHMM1s 3.6 10.3 CSPHMM2s 3.5 12.3 CSPHMM3s 3.7 9.8 3) Ex periment 3: This experiment is the same as Experiment 2. However, the trai ning phase is made up from the formal-accented speech database and the test phase is composed of the Emirati-accented speech database (one test se ssion in neutral environment of the Emirati-accented database and another distinct test session in shouted environment of the same database). Therefore , in this experiment, we tra in our system with the formal- accented database and we test the system with the Emirati-accented database based on 26 each of CSPHMM1s, CSPHMM2s, and CSPHMM3s. Speaker identification performance based on each of CSPHMM1s, CSP HMM2s, and CSPHMM3s in each of neutral and shouted environments trained using the formal-accented database and tested using the Emirati-accented database is given in Table 10. Table 11 clearly exemplifies that training and testing our sy stem using the same Emi rati-acc ented database is superior to that training with the formal-accented database and testing with the Emi rati-accented database. This is because of the mismatch that exists between the training and testing phases. It is evident from this table that the sup eriority is significant in shouted environment while it is insignificant in neutral environment. Table 10 “ Speaker identification performance in each of neutral and shouted environments ” using formal-accented database in the training phase and Emirati-accented database in the testing phase based on each of “ CSPHMM1s, CSPHMM2s, and CSPHMM3s ” Models Gender “ Speaker identification performance (%) ” “ Neutral environment ” “ Shouted environment ” CSPHMM1s Male 89.3 45.2 Female 88.1 43.0 Average 88.7 44.1 CSPHMM2s Male 90.2 47.1 Female 90.0 45.3 Average 90.1 46.2 CSPHMM3s Male 91.7 51.9 Female 90.9 50.7 Average 91.3 51.3 Table 11 Speaker identification improvement rate of using the same Emira ti-accented database in both training and testing phases over that using formal-accented da tabase in the training phase and Emirati-accented in the testing phase in neutral and shouted environments based on each of “CSPHMM1s, CSPHMM2s, and CSPHMM3s ” 27 Models “ Speaker identification improvement rate (%) ” “ Ne utral environment ” “ Shouted environment ” CSPHMM1s 6.0 16.3 CSPHMM2s 5.7 20.1 CSPHMM3s 5.0 15.6 4) Ex periment 4: “ Speaker identification performance in neutral environment ” using the Emirati-accented database has been compared with one of our prior work [ 13]. I n one of our previous studies, we focused on Emirati speaker identification sy stems in neutral environment based on each of VQ , GMMs, and HMMs as classifiers. These sy stems have been tested on our collected Emirati speech database which is comprised of 25 male and 25 female Emirati speakers using MFCCs as features. The database in [13] is different from the database being used in the current research. In [ 13], our database was captured from 25 men and 25 women Emirati speakers with ag es between 14 and 27 y ears old. These speakers uttered 8 common Emirati sentences that are ex tensively utilized in the UAE society. Our results yield, for text-independent sy stems, avera ge speaker identification performance of 94.58%, 86.6%, and 74.8%, based on VQ, GMMs, and HMMs, respectively . These results are smaller than those achieved based on CSPHMM1s (94.0%), CSPHMM2s (95.2%), and CSPHMM3s (95.9%). 5) Ex periment 5: In this experiment, Emirati-accented speaker identification has been assessed for diverse values of based on CSPHMM3s. Fig. 2 clarifies averag e speaker identification performance in each of neutral and shouted environments using the Emirati-accented database based on CSPHMM3s for various values of (0.0, 0.1, 0.2, 28 …, 0.9, 1.0). I t is appare nt from thi s figure that as the value of grows in the range [0,0.5], “ speaker identification performance in shouted environment ” increases significantly , while the performance insi gnifica ntly increa ses when spans in the range [0.6,1.0]. This figure shows also that increasing the value of has an insignificant effect on improving speaker identification performance in neutral environment. The conclusion that can be drawn in this experiment states that “ suprasegmental hidden Markov models ” have more influence than “ acoustic models on speaker identifica tion performance in shouted environment ” of Emirati-accented database. Figure 2. “ Average speaker identification performance in each of neutral and shouted environments ” using the Emirati-accented dataset based on CSPHMM3s for various values of 6) Ex periment 6: In this experiment, “ a statistical c ross-validation technique ” has been performed to estimate the standard deviation of speaker identification performance in each of neutral and shouted environments using the Emirati -acce nted database based on each of CSPHMM1s, CSPHMM2s, and CSPHMM3s. Cross-validation tec hnique has 29 been independently carried out for each classifier as follows: the entire database (5400 utterances per classifier) has been random ly subdi vided int o five subsets per classifier. Each subset is made up of 1080 utterances (360 utterances have been used for training and the rest have been used for testing). The standard deviation has been calculated using these five subsets per classifier. The standard deviation values per classifier are given in Fig. 3. Based on this figure, cross-validation technique reveals that the computed standard deviation values are low. Low standard deviation values indi cate that the attained values of speaker identification performanc e are homogenous and not much difference among values. Therefor e, it is appa rent from this experiment that speaker identification performance in each of neutral and shouted environments using the Emirati-accented dataset based on each one of these classifiers and using the five subsets is very alike to that using the whole database without portioned it arbitrarily into five subsets per classifier (very minor variations). Figure 3. “ Calculated standard deviation values using statistical cross-validation technique in each of neutral and shouted environments ” of the Emirati -accented dataset based on each of “ CSPHMM1s, CSPHMM2s, and CSPHMM3s ” 30 7) Ex periment 7: An “ informal subjective assessment of CSPHMM3s ” using the Emirati- accented dataset has been conducted with ten “ nonprofessional listeners (human judges) ” . A total of 800 utterances (50 speakers × 8 sentences × 2 talking environments) have been utilized in this assessment. During the assessment, every listener was independently asked to recognize the unknown speaker in ea ch of neut ral and shouted environments (totally two distinct and separate environments) for eve ry test uttera nce. The “ average speaker identification performance in neutral and shouted environments ” based on the subjective assessment is 93.9% and 56.8%, respectively . These average s are very similar to the reported averages in the present study based on CSPHMM3s (95.9 % and 59.3% in neutral and shouted environments, respectively ). 7. Concluding Remar ks In this work, Emirati -accented speech database (Arabic United Arab Emirates database) was captured in e ach of neut ral and shouted environments in order to study, analyze, and improve text-independent Emirati-accented “ speaker ident ification performance in each of neutral and shouted environments ” ba sed on each of “ CSPHMM1s, CSPHMM2s, and CSPHMM3s ” as classifiers. These classifiers a re novel for suc h a database. In this stud y, seven extensive experiments have been carried out to thoroughly study and anal y z e this database for “ speaker identification in each of neutral and shouted environments ” . Some conclusions can be drawn in this work. Firstl y , as cla ssifiers, “ CSPHMM3s ” outperform each of “ GMMs, SVM, GA, VQ, CSPHMM1s, and CS PHMM2s ” for “ speaker identification in ea ch of neutral and shout ed environments ” . Secondly, in terms o f gender, male Emirati speakers can be easil y identified compared to fe male Emirati spea kers. Thirdly, supraseg mental models y ield higher speaker 31 identification performance than their corresponding acoustic mod els. Finally, speaker identification performan ce based on training an d testing speaker identification system using Emirati-accented da tabase is grea ter than that b ased on training and testing the s ystem usin g formal-accented Arabic database. Our work has some limitations. First, the collected dataset is limited to a total of fifty speakers . Second, the speakers are unprof essional ones. Third, there are some logistic problems in capturing speech signals from senior people. Finally, M FCCs have b een adopted in this work as the proper features that extract the phonetic content of Emirati-accented speech database. For future work, our plan is to make our captured Emirati-accented speech database a comprehensive one b y including more speakers. I n addition, we plan to include speakers from early ages (5 to 12 y ears old) and to include speakers from the seven emirates of the U AE ( Abu Dhabi, Dubai, Sharjah, Ajman, Umm al-Qaiwain, Ras al-Khaimah, and Fujairah). We also intend to determine the optimum extracted features that can be adopted as the appropriate fe atures to extract the phonetic content of Emirati-acc ented speech signals. Finally, we plan to use deep neural networks [38] as classifiers to enhance Emirati-accented “ speaker identification performance in a shouted environment ” . Acknowledgements The autho rs of this work wish to thank University of Sharjah for funding their work through the competitive research project entitled “Capturing, S tudying, and Anal yzing Arabic Emirati - Accented Speech Database in Stressful and Emotional Talking Environments for Dif ferent 32 Applications”, No. 1602 040349 - P. The authors wish also to thank engineers Merah Al Suwaidi, Deema Al Rais, and Hannah Saud for capturing the Emirati-accented speech database. “ Conflict of Interest : The authors declare that they have no competing int erests ” . “ Informed consent : This study does not involve any animal participants ” . References [1] S. Furui, “Speaker -dependent-feature- extraction, recognition and processing techniques,” Speech Communication, Vol. 10, March 1991, pp. 505-520. [2] K. Kirchhoff, J . Bilmes, S. Das, N. Duta, M. Egan, G. J i, , F. He, J. Henderson, D. Liu, M. Noamany, P. Schone, R. Schwartz, D. Vergyri, “ Novel approaches to Arabic speech recognition: Report from the 2002 Johns-Hopkins workshop,” I n: P roceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (I CASSP), V ol. 1, 2003, pp. 344 – 347. [3 ] K. R . Farr ell, R. J. Mammone and K. T. Assaleh, “Speaker recognition using neural networks and conventional classif iers,” IEEE Transactions on Speech a nd Audio Processing, Vol. 2 , January 1994, pp. 194-205. [4 ] I. Shahin, “Speaker identification in emotional talking environments based on CS PHMM2s,” Engineering Applica tions of Artificial I ntelli gence, Vol. 26, issue 7 , Aug ust 2013, pp. 1652- 1659. 33 [5] X. Zhao, Y. Shao and D. W ang, “CASA - based robust speaker identification,” IEEE Transactions on Audio, Speech and Language Pr ocessing J ournal, Vol. 20, No. 5 , J uly 2012, pp. 1608-1616. [6] S. S. Al-Dahri, Y. H. Al-Jassar, Y.A. Alotaibi, M.M. Alsulaiman, K. A. Abdullah- Al - Mamun, “A word - dependent automatic Arabic speaker identific ation s y stem” Signal Processing and Information Technology (ISSPIT 2008), pp. 198-202. [7 ] A. Krobba, M. Deb yeche, A. Amrouche, “Evaluation of speaker ident ification s ystem usin g GS MEFR speech data, Proc. 2010 International Conference on Design & Technolog y of Integrated Systems in Nanoscale Era, Hamma met, March 2010, pp. 1-5. [8] A. Mahmood, M. Alsulaiman, G. Muhammad, “ Automatic speaker recognition using multi directional local features (MDLF), ” Arabian Journal for Science and Engineering, Ma y 2014, Volume 39, Issue 5, pp. 3799 – 3811. [9] K. S aeed and M. K. Nammous, “A speech -and-speaker identification s ystem: Feature extraction, description, and classification of speech si gnal im age ,” IEEE Transactions on Industrial Electrons, Vol. 54, No. 2, April 2007, pp. 887 – 897. [10] H. Tolba, “A high - performance text -independent speaker identification of Arabic speakers using a CHMM-based approach ,” Alexandria engineering, Vol. 50, 2011, pp. 43-47. 34 [11] https://catalog.ldc.upenn.edu/LDC2002S02 (West Point Arabic Speech). [12] https://catalog.ldc.upenn.edu/LDC2006S43 (Gulf Arabic Conversational Telephone Speech) [13] I. Shahin and Mohammed Nasser Ba- H utair, “Emarati speaker identification,” 12 th International Conference on Signal Processing (ICSP 2014), HangZhou, China, October 2014, pp. 488-493. [14] I. Shahin, “Emirati speaker verification bas ed on HMM1s, HMM2s, and HMM3s,” 13th International Conf erence on Signal Pro cessing ( ICSP 2016), Chengdu, China, November 2016, pp. 562-567, DOI: 10.1109/ICSP.2016.7877896. [15] I. Shahin, “ I dentifying speakers using their emotion cues,” International Journal of Speech Technology, Vol. 14, No. 2, June 2011, pp. 89 – 98, DOI: 10.1007/s10772-011-9089-1. [16] I . Shahin, “Speaker identification in a shouted talking environme nt based on novel third- order circular suprasegmental hidden M arkov mo dels,” Circuits, S ystems and Signal Processing, DOI: 10.1007/s00034-015-0220-4, Vol. 35, issue 10, October 2016, pp. 3770-3792. [17] I. Shahin, “Emplo y ing emotion cues to verify speaker s in emotional t alking environments,” Journal of Intelligent S ystems, Special Issue on Intellige nt Healthcare S y stems, DOI: 10.1515/jisys-2014-0118, Vol. 25, issue 1, January 2016, pp. 3-17. 35 [18] I. Shahin and Mohammed Nasser Ba - Hutair, “Talking condition recognition in stressful and emotional talking environments based on CSPHMM2s,” International Journal of Speech Technology, Vol. 18, issue 1, March 2015, pp. 77-90, DOI: 10.1007/s10772-014-9251-7. [19] I. Shahin, “Studying and enhancing talking condition recognition in stressful and emotional talking environments based on HMMs, CHMM2s and S PHMMs,” J ournal on Multimodal User Interfaces, Vol. 6, issue 1, June 2012, pp. 59-71, DOI: 10.1007/s12193-011-0082-4. [20] T. S. Polzin and A. H. Waibel, “Detecting em otions in S peech,” Cooperative Multimodal Communication, Second International Conference 1998, CMC 1998. [21] I . Shahin, “Speaker identification in the shouted environment using suprasegmental hidden Markov models,” Signal Processing Journal, Vol. 88, iss ue 11, November 2008, pp. 2700-2708. [22 ] I . S hahin, “Employing second -order circular supras egmental hidden Markov models to enhance speaker identification performance in shouted talking environments,” EURASIP Journal on Audio, S peech, and Music Processing, Vol. 2010, Article ID 862138, 10 pa ges, 2010. doi:10.1155/2010/862138. [23 ] C. Zheng and B. Z. Yuan, “Text -dependent speaker identification using circular hidden Markov models”, IEEE International Conference on Acoustics, Spe ech and Signal Processing, S13.3, 1988, pp. 580-582. 36 [24 ] I . Shahin, “Enh ancing sp eaker identification performance und er the shout ed talking condition using second - order circular hidden Markov models” Speech Comm unication, Vol. 48, issue 8, August 2006, pp. 1047-1055. [2 5 ] I. Shah in, “Novel t hird -order hidden Markov models for spe aker identification in shouted talking environments,” Engineering Applications of Artificial Intelligence, Vol. 35, October 2014, pp. 316-323, DOI: 10.1016/j.engappai.2014.07.006. [26] I. Shahin, “Gender - dependent emotion recognition based on HMMs and SPHMMs,” International Journal of Spee ch Technology, Vo l. 16, issue 2, June 2013, pp. 133 -141, DOI: 10.1007/s10772-012-9170-4. [27 ] T. H. Falk and W . Y. Chan, “Modulation spectral features for robust far - fi eld speaker identification,” IEEE Transactions on Audio, Speech and Language Processing, Vol. 18, No. 1, January 2010, pp. 90-100. [28] D. T. Grozdić , S. T. Jovičić, and M. Subotić, "Whispered speech r ecognition u sing deep denoising autoencoder, " Engineering Applications of Artifici al Intelligence, Vol. 59, 2017, pp. 15-22. [29] I . Shahin and N. Botros, "Modelin g and anal yzing the vocal tra ct under normal and stressful talking conditions," IEEE SOUTHEASTCON 2001, Clemson, South Carolina, USA, March 2001, pp. 213-220. 37 [30] D. A. Rey nolds, "Speaker identification and verification using Gaussian mixture speaker models," Speech Communication, Vol. 17, issues 1-2, August 1995, pp. 91-108. [31] D. A. Reynolds and R. C. Rose, "Robust tex t -independent speaker identification using Gaussian mixture speaker models," IEEE Transactions on Speech and Audio Processing, Vol. 3, No. 1, January 1995, pp. 72-83. [32] W. M. Campbell, J . R. Campbell, D. A. Reynolds, E. Singer, and P. A. Torres -Carrasquillo, “Support vector machines for speaker and language recognition,” Comput er Speech and Language, 2006, Vol. 20, pp. 210 – 229. [33 ] P. Staroniewicz and W . Majewski, “SVM ba sed text -dependent speaker identification for large set o f voices," 12th European Signal Processing Conf erence, EUSIPCO 2004, Vienna, Austria, September 2004, pp. 333-336. [34 ] Q. Y. Hong and S . Kwong, “A genetic cl assification method for speaker reco gnition,” Engineering Applications of Artificial Intelligence, Vol. 18, 2005, pp. 13 – 19. [35 ] S. Casale, A. Russo, and S. Serano, “Multi sty le classification of speech under stress using feature subset selection based on ge netic algorithm s,” Speech Communication, Vol. 49, No. 10, August 2007, pp. 801 – 810. 38 [3 6 ] T. Kinnunen and H. L i, “An overview o f text -independent speaker rec ognition: From features to supervectors,” Speech Communication, Vol. 52, No. 1, January 2010, pp. 12 – 40. [3 7 ] T. Kinnunen, E. Karpov, and P. Franti, “Real - time speaker identification and verification,” IEEE Transactions on Audio, S peech and Language P rocessing, Vol. 14, No. 1, J anuary 2006, pp. 277 – 288. [3 8 ] M. Pavel, G. Ond rej, N. Ondrej, P. Oldrich, G. Franti sek, B. Lukas, and H. C. Jan, “Analysis of DNN approaches to speaker identification,” International Conference on Acoustics, Speech and Signal Processing 2016, pp. 5100-5104.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment