Detection under Privileged Information
For well over a quarter century, detection systems have been driven by models learned from input features collected from real or simulated environments. An artifact (e.g., network event, potential malware sample, suspicious email) is deemed malicious…
Authors: Z. Berkay Celik, Patrick McDaniel, Rauf Izmailov
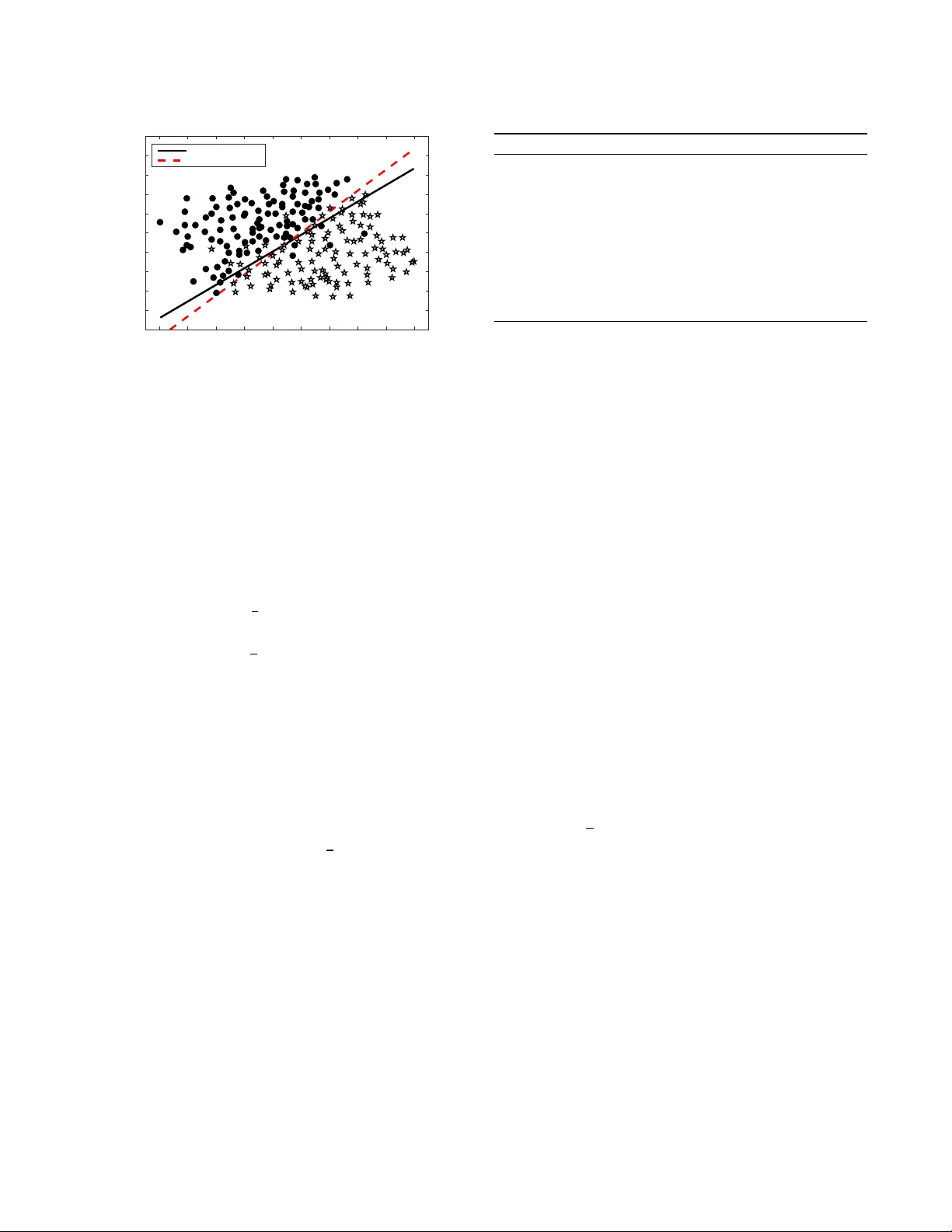
Detection under Privileged Information (Full Paper) ∗ Z. Berkay Celik Pennsylvania State University zbc102@cse.psu.edu Patrick McDaniel Pennsylvania State University mcdaniel@cse.psu.edu Rauf Izmailov V encore Labs rizmailov@appcomsci.com Nicolas Papernot, Ryan Sheatsley , Raquel Alvarez Pennsylvania State University {ngp5056, rms5643, rva5120}@cse.psu.edu Ananthram Swami Army Research Laboratory ananthram.swami.civ@mail.mil ABSTRA CT For well over a quarter century , detection systems have been driven by models learned from input features collected from r eal or sim- ulated environments. An artifact (e.g., network event, potential malware sample, suspicious email) is deemed malicious or non- malicious based on its similarity to the learned model at runtime. Howev er , the training of the models has been historically limited to only those features available at runtime. In this paper , we consider an alternate learning approach that trains models using “privileged” information–features available at training time but not at runtime– to improve the accuracy and resilience of detection systems. In particular , we adapt and extend recent advances in knowledge transfer , model inuence, and distillation to enable the use of foren- sic or other data unavailable at runtime in a range of security domains. An empirical evaluation shows that privileged informa- tion increases precision and recall over a system with no privileged information: we observe up to 7.7% r elative decrease in detection error for fast-ux bot detection, 8.6% for malware trac dete ction, 7.3% for malware classication, and 16.9% for face recognition. W e explore the limitations and applications of dierent privileged infor- mation techniques in detection systems. Such techniques provide a new means for detection systems to learn from data that w ould otherwise not be available at runtime. KEY W ORDS Detection systems; privileged information; machine learning A short version of this paper is accepted to A CM Asia Conference on Computer and Communications Security (ASIA CCS) 2018 1 IN TRODUCTION Detection systems based on machine learning ar e an essential to ol for system and enterprise defense [ 49 ]. Such systems provide predic- tions ab out the existence of an attack in a target domain using infor- mation collected in real-time. The detection system uses this infor- mation to compare the runtime envir onment against kno wn normal or anomalous states. In this way , the detection system “recognizes” when the environmental state becomes—at least probabilistically— dangerous. What constitutes dangerous is learned; detection al- gorithms construct models of attacks (or non-attacks) from past observations using a training algorithm. Thereafter , the detection systems use that model for detection at runtime. A limitation of this traditional approach is that it relies solely on the features (also referred to as inputs) that are available at runtime. In practice, many ∗ A short version of this paper appears in ACM Asia Conference on Computer and Communications Security (ASIA CCS) 2018. features are too expensive to collect in real-time or only available after the fact–and are thus ignored for the purposes of detection. Consider a r ecent event that occurred in the United States. In the Summer of 2017, the credit reporting agency Equifax fell victim to sophisticated cyber attacks that resulted in substantial exltration of p ersonal information and intellectual property [ 8 ]. W orking with the government sta and security analysts conducted a clandestine investigation. During that time, a vast amount of information was collected from networks and systems acr oss the agency , e .g., net- work ows, system logs les and user activity . An analysis of the collected data revealed the presence of previously undetected ad- vanced persistent threat (APT) actors on the agency’s network. Y et, the collected analysis is largely non-actionable by detection sys- tems post investigation; because the vast array of derived features would not be available at runtime, they cannot be used to train Equifax’s detection systems. In other conte xts, features may be available at runtime but infea- sible or undesirable to collect be cause of environmental or system constraints. For example, the collection of a large numbers of fea- tures in environments of mobile phones [ 6 ], Internet of Things (Io T) [ 45 ], sensor networks [ 23 ], embe dded contr ol systems [ 46 ], or ad-hoc netw orks [ 9 ] is often too slow or requires too many resources to be feasible in practice. These examples highlight a challenge for future intrusion de- tection: how can detection systems integrate intelligence relevant to an attack that is not available at runtime? Here, we turn to recent advances in machine learning that support models that learn on a superset of features use d at runtime [ 54 , 55 ]. The goal of the work described in this paper is to leverage these additional features, called privileged information (features available at training time, but not at runtime), to improve the accuracy of detection. Using this approach designers and operators of detection systems can leverage additional eort during system calibration to impro ve detection models without inducing additional runtime costs. Pioneered recently by V apnik, Izmailov , and others, learning under privilege d information eliminates the need for symmetric features in training and runtime–ther eby expanding the space of learning mo dels to include “ancillar y" and “non-runtime" infor- mation. Ho wever , to date, the application of these techniques in practical domains has been limite d, and within the context of se- curity non-existent. In this w ork, we explore ho w this new mode of learning can be leveraged in detection systems. This r equires an exploration of not only use of these new learning models but also their applicability to security domains and the r equirements of 1 those domains on feature engine ering. Our experience in this eort over the last two y ears has demonstrated that blind application of privileged application can lead to poor detection–yet judicious and careful use can substantially improv e detection quality . More concretely , in this paper , we explore an alternate appr oach to training intrusion detection systems that exploit privileged in- formation. W e design algorithms for three classes of privileged- augmented detection systems that use: (1) Knowledge transfer , a general technique of extracting knowledge fr om privileged informa- tion by estimation from available information, (2) Model inuence , a model-dependent approach of inuencing the model optimization with additional knowledge obtained from privileged information; and (3) Distillation , an approach of summarizing the additional knowledge about privileged samples as class probability vectors. W e further explore feature engineering in a privileged setting. T o this end, we measur e the potential impacts of privileged features on runtime models. Here, we use the degree to which a feature improves a model ( accuracy gain —a feature’s additiv e contribution to accuracy ) as a quality metric for selecting privileged features for a target model. W e develop an algorithm and system that se- lects features that maximize model accuracy in the presence of privileged information. Finally , we compar e the performance of privileged-augmented systems with systems without privilege d information. W e evaluate four recently proposed detection systems: (1) face authentication, (2) fast-ux bot detection, (3) malware trac detection, and (4) malware classication. Our contributions are: • W e augment several diverse detection systems using three classes of privileged information techniques and explore the strength and weaknesses of these techniques. • W e present the rst methods for feature engineering in privileged-augmented detection for security domains and identify inherent tensions between information utilization, detection accuracy , and model robustness. • W e provide an evaluation of techniques on a variety of ex- isting detection systems on real-w orld data. W e show that privileged information decreases the relative detection error of traditional detection systems up to 16.9% for face authen- tication, 7.7% for fast-ux bot dete ction, 8.6% for malware trac detection, and 7.3% for malware classication. • W e analyze dataset pr operties and algorithm parameters that maximize detection gain, and present guidelines and cautions for the use of privileged information in realistic deployment environments. After introducing the technical approach for detection in the next section, we consider several key questions: (1) How can the best features for a specic detection task b e identied? (Section 4) (2) How does privileged-base detection perform against tradi- tional systems? (Section 5) (3) How can we select the best privilege d algorithm for a given domain and detection task? (Section 6) (4) What are the practical concerns in using privileged informa- tion for detection? (Section 7) T raining Data Set Privileged Set Mo del T raini ng Model Detection ? Unknown sample x 1 ; : : : ; x n + Results x 1 ; : : : ; x n x 1 ; : : : ; x n + : : : : : : x ∗ 1 ; : : : ; x ∗ m x ∗ 1 ; : : : ; x ∗ m + : : : : : : T raining Data Set Mo del T raini ng Model x 1 ; : : : ; x n x 1 ; : : : ; x n + : : : : : : Detection ? Unknown sample x 1 ; : : : ; x n + Results Figure 1: Over view of a typical detection system (left) and proposed solution (right): Given training data including b oth malicious (+) and benign samples ( –), modern detection systems use training data to construct a mo del. T o predict the class of an unknown sample, the system examines its features using the model to predict the sample as b enign or malicious. In contrast, we construct a model both using training and privileged data, yet the model only requires the train- ing data features to dete ct unknown sample as benign or malicious. 2 PROBLEM ST A TEMEN T Detection systems use traditional learning algorithms such as sup- port vector machines or multilayer perceptrons (neural networks) to construct detection models . These models aim at learning patterns from historical data ( also r eferred to as training data) to estimate an underlying dependency , structure or behavior of a system, process or environment. This training data is a collection of samples that includes a vector of features (e.g., packets per second, port numb er) and class labels (e .g., anomalous or normal). Once trained, runtime events (e .g., network event) are compared to the learned mo del. Without loss of generality , the model outputs a label (or label con- dence) that most closely ts with those of the training data. The percentage of output labels that are correctly predicte d for a sample set is known as its accuracy . The quality of the detection system largely depends on featur es used to train models. In turn, the success of detection depends on explanatory variation behind the features that ar e used to separate an attack and benign sample. However , modern dete ction systems by construction assume that the features used to make predictions at runtime would be identical to those used for training (Se e Figure 1 (left)). This assumption restricts the model training to the features that are available at runtime to make predictions. As highlighted above, intelligence obtained from forensic investigations [ 56 ], data obtained through a human expert analysis [ 10 ], or features unable to be feasibly collecte d at runtime is simply not actionable. Juxtapose this with our goal of leveraging features in model training that are not available at runtime to improv e detection accuracy (See Figure 1 (right)). Note that we do not focus on a specic detection task or domain. W e begin in the following section by introducing the three approaches we use to integrate privileged information into detection models. 2 Learning algorithm Mapping function f : X s ! X ∗ Estimated v alues Standard features ( X s ) Privileged features ( X ∗ ) T raining data y Detection function f ( X s [ X ∗ ) for X ∗ (a) Knowledge transfer Detection space Correction space Model In fl uence slack v ariables( ξ ) Model in fl uence detection function T raditional detection function Correcting function Standard features ( X s ) Privileged features ( X ∗ ) T raining data (b) Model inuence Learning algorithm Learning algorithm f ( X s [ X ∗ ) soft lab els ( ^ y ) f ( X s ) Standard features ( X s ) Privileged features ( X ∗ ) T raining data y Detection function Distillation (c) Distillation Figure 2: Schematic overview of approaches. Instead of making a detection model solely rely on standard features of a dete ction system, we also integrate privileged features into detection algorithms. 3 PRI VILEGED INFORMA TION DETECTION This section introduces three approaches to integrate privileged features into dete ction algorithms: knowledge transfer , model inu- ence, and distillation. Figure 2 pr esents the schematic overview of approaches. Stated formally , we consider a conv entional detection algorithm as a function f : X → Y that aims at predicting targets y ∈ Y given some explanatory features x ∈ X . The models are built using a dataset containing pairs of features and targets, de- noted by D = { ( x i , y i )} n i = 1 . Following the denition of privileged information, we consider a detection setting where the features X used for detection are split into two sets to characterize their availability for dete ction at training time. The standard features X s = { x i , i = 1 , . . . , n , x i ∈ R d } includes the features that are reliably available both at training and runtime (as in conventional systems), while privileged features X ∗ = { x ∗ i , i = 1 , . . . , n , x ∗ i ∈ R m } have constraints that prev ent using them for detection at runtime. More formally , we assume that detection mo dels will be trained on some data {( x i , x ∗ i , y i )} n i = 1 , and they will make detection on some data { x j } n + m j = n + 1 . Therefore, our goal is creation of algorithms that eciently integrate privileged features { x ∗ i } n i = 1 into detection models, without requiring them at runtime. 3.1 Knowledge Transfer W e consider a general algorithm to transfer kno wledge from the space of privileged information to the space where the detection model is constructed [ 54 ]. The algorithm works by deriving a map- ping function to estimate each privileged feature from a subset of standard features. The algorithm use d to identify a mapping function f i is described in Algorithm 1. The estimation is straight- forward: the relationship between standard and privileged features is learned by dening each privileged feature x ∗ i as a target and stan- dard set as an input to a mapping function f i ∈ F (lines 1-3). The mapping functions can be dened in the form of any function such as regression or similarity-based (we giv e examples in Section 5.1). The use of the mapping function allows a system to apply the same model learne d from the complete set at training time with the union of standard and estimated privileged featur es on unknown samples (See Figure 2a). By using f i , detection systems are able to construct the complete features with the correct values of privileged features Algorithm 1: Knowledge Transfer Algorithm Input : Standard training set X s = ® x 1 , . . . , ® x L , ® x i ∈ R d Privileged training set X ∗ = ® x ∗ 1 , . . . , ® x ∗ L , ® x ∗ i ∈ R m f i ∈ F ← mapping function θ ← mapping function parameters 1 Find an optimal standard set b X ⊆ X s , for all x ∗ i ∈ X ∗ 2 Select set b X i for x ∗ i 3 Mapping function f evaluates ( b X i , x ∗ i ) as given x ∗ i = f i ( b X i , β | θ ) , f i ∈ F m 4 Output β for x ∗ i that minimizes f i 5 At runtime use f i to estimate x ∗ i at runtime–intuitively , each f i is used to generate a synthetic fea- ture that represents an estimate of a privileged feature (line 4). As a result, the accurate estimation of privileged features contributes to using complete and relevant features in a model training and, therefore, enhances the generalization of models compar ed to those trained solely on standard features. Note that the estimating power of f i is bounded by the size and completeness of the training data (with respect to the privilege d features), and thus the use of f i in the model should be calibrated based on measurements of estimation quality (See Section 5.4 for details). 3.2 Model Inuence Model inuence incorporates the useful information obtained from privileged features to the correction space of the detection model by dening additional constraints on the training err ors (See Fig- ure 2b) [ 54 , 55 ]. Intuitively , the algorithm learns how privileged information inuences outputs on training input feature vectors towards building a set of corrections for the space of inputs–in essence creating a correction function that takes as input runtime features and adjusts mo del outputs. Note that while w e adapt model inuence to support vector machines (SVM) herein, it is applica- ble to other ML techniques. More formally , consider a training datum that is generated from an unknown probability distribution p (X s , X ∗ , y ) . Our goal is to nd a model f : X s → Y such that the 3 -0.6 -0.5 -0.4 -0.3 -0.2 -0.1 0 0.1 0.2 0.3 x 1 -1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1 x 2 SVM linear kernel SVM+ linear kernel Figure 3: Model inuence: The SVM+ uses privileged information to correct the decision boundary of the model. expected loss is dened as: R ( θ ) = ∫ X s ∫ Y L (( x s , θ ) , y ) p ( x s , x ∗ , y ) d x s d y (1) Here the system is trained on standard and privileged features but only uses standard features at runtime. W e consider the optimiza- tion problem of SVM in its dual form as shown in Equation 2 (labeled as primary detection obje ctive) where α is Lagrange multiplier . L ( w , w ∗ , b , b ∗ , α , δ ) = main detection objective z }| { 1 2 | | w | | 2 + m Õ i = 1 α i − m Õ i = 1 α i y i f i + γ 2 | | w ∗ | | 2 + m Õ i = 1 ( α i + δ i − C ) f ∗ i | {z } inuence from privileged features (2) W e inuence the detection boundar y of a model trained on stan- dard features f i = w ⊺ x s i + b at x s i with the correction function dened by the privilege d features f ∗ i = w ∗ ⊺ x ∗ i + b ∗ at the same location (labeled as inuence from privileged features). In this man- ner , we use privileged features as a correction function of the slack variables ξ i dened in the objective of SVM. In turn, the useful information obtained from privileged features is incorporated as a measure of condence for each labeled standard sample . The formu- lation is named as SVM+ and requires O ( √ n ) samples to converge compared to O ( n ) samples for SVM which is useful for systems with a sparse data colle ction [ 12 , 54 ]. W e refer readers to Appendix A for a complete formulation and implementation. T o illustrate, consider the 2-dimensional synthetic dataset pre- sented in Figure 3, as well as the decision boundaries of two de- tection algorithms SVM (an unmodied Supp ort V ector Machines) and SVM+ (the same SVM augmented with model inuence correc- tion). The use of privileged information in model training separates the classes more accurately because privileged features accurately transfer information to standard space, and the resulting model becomes more robust to the outliers. This appr oach may provide even better class separation in datasets with higher dimensionality . T o summarize, as opposed to knowledge transfer , we eliminate the task of nding the mapping functions between standard and Algorithm 2: Distillation Algorithm Input : Standard training set X s = ® x 1 , . . . , ® x L , ® x i ∈ R d Privileged training set X ∗ = ® x ∗ 1 , . . . , ® x ∗ L , ® x ∗ i ∈ R m Training labels Y T ← T emperature parameter , T > 0 λ ← Imitation parameter , λ ∈ [0,1] 1 Learn a model f s using (X ∗ , y ) 2 Compute soft labels as s i = σ ( f s ( x ∗ i )/ T ) for all 1 ≤ i ≤ L 3 Learn detection model using Equation 3 with the given data as {(X s , Y ) , (X s , S ) } 4 Make detection using θ minimizing f t for standard features x s privileged features. Thus, we reduce the problem of model training to a single unied task. 3.3 Distillation Model compression or distillation are techniques to transfer knowl- edge from a complex Deep Neural Network (DNN) to a smaller one without loss of accuracy [ 24 ]. The motivation behind the idea suggested in [ 3 ] is closely related to knowledge transfer . The goal of the distillation is to use the class knowledge from both class labels (i.e., hard labels) and probability vectors of each (i.e., soft labels). The benet of using class pr obabilities in addition to the hard labels is intuitive because probabilities of each class dene a similarity metric over the classes apart from the samples’ cor- rect classes. Lopez-Paz et al. recently introduced an extension of model distillation used to compress models built on a set of features into models built on a dierent set of featur es [ 33 ]. W e adapt this technique to detection algorithms. W e address the problem of privileged information using distilla- tion as follows. First, we train a “privileged” mo del on the privileged set and labels whose output of the model is the v ector of soft labels S . Second, we train a distilled model (used at runtime) by minimiz- ing Equation 3, which learns a detection mo del by simultaneously imitating the privileged predictions of the privileged model and learning the targets of the standard set. The algorithm for learning such a model is presented in Algorithm 2 and outlined as follows: f t ( θ ) = argmin f ∈ F t 1 n n Õ i = 1 detection z }| { ( 1 − λ ) L ( y i , σ ( f ( x s i )) + imitate privileged set z }| { λ L ( s i , σ ( f ( x s i )) (3) W e learn a privilege d model f s ∈ F s by using the privileged samples available at training time (line 1). W e then compute the soft lab els by applying the softmax function (i.e., normalized ex- ponential) s i = σ ( f s ( x ∗ i )/ T ) (line 2). The output is a vector which assigns a probability to each class of the privileged samples. W e note that class probabilities obtained from privilege d model provide additional information for each class. Here , temperature parameter T controls the degree of class prediction smoothness. Higher T enables softer probabilities ov er classes and vice versa. A s a nal step, Equation 3 is sequentially minimized to distill the knowledge transferred from privileged featur es as a form of probability vectors (soft labels) into the standard sample classes (hard labels) (line 3). In Equation 3, the λ parameter controls the trade-o between priv- ileged and standard features. For λ ≈ 0 , the objective approaches 4 1 x 2 x ! ! Hard!examples! Easy!examples! X * X * X * X * X * X * Figure 4: Visualizing hard and easy benign ( -) and malicious (+) ex- amples. W e select privileged features that aims at increasing the de- tection of hard examples. the standard set objective, which amounts to dete ction solely on standard features. Ho wever , as λ → 1 , the objective transfers the knowledge acquired by the privileged model into the resulting detection mo del. Therefore, learning from the privilege d mo del does, in many cases, signicantly improve the learning process of a detection model. Distillation diers fr om model inuence and kno wledge transfer in at least two ways. First, while kno wledge transfer attempts to estimate the privileged features with a representation of a mapping function, distillation is a trade-o between the privileged sample probabilities and standard sample class labels. Second, in contrast to model inuence , distillation is independent of the machine learning algorithm (model-fr ee), and its objective function can b e minimized using a model of choice. 4 PRI VILEGED INFORMA TION SYSTEMS In this section, we explor e algorithms for feature engineering (se- lecting privilege d features for a detection task) and demonstrate their use in diverse experimental systems. 4.1 Selecting Privileged and Standard Features The rst challenge facing our mo del of detection is de ciding which features should be used as privileged information. Asked another way , given some potentially large univ erse of oine features, which are the most likely to improve detection? T o address this, w e develop an iterative algorithm that selects features that maximize model accuracy . Selection is made on the calculated accuracy gain of each feature–a measure of the additive value of the features concerning an existing feature set for detection accuracy . Our feature selection algorithm measures the potential impacts of privileged features that help detect the hard-to-classify examples. Generally speaking, easy examples fall in a distribution that can b e explained by some set of model parameters, and hard e xamples do not precisely t the model–and are either misclassied or near a decision boundar y (See Figure 4) [ 50 ]. As a consequence, accurate classication of hard examples is one of the main challenges of practical systems, as they ar e the main source of detection errors due to the incorrect or insucient information about normal or anomalous states of a system. Algorithm 3: Selecting privileged features Input : Standard feature set x s Related privileged feature set x ∗ SVM Detection model J evaluating accuracy of hard-to-classify examples 1 Start with the standard set Y 0 = x s 2 Select the next privileged feature x + = argmax x ∗ < Y k [ J ( Y k + x ∗ )] 3 Update Y k + 1 = Y k + x + ; k = k + 1 4 Go to 2 5 Output Y including standard and selecte d privileged features The rst step of feature engineering–as is true of any detection task–is identifying all of the available featur es that potentially may be used for detection. Spe cically , we collect the set of domain- specic features based on using domain knowledge and surveying the recent eorts in that domain. It is from that set that we will identify the privileged features to be used for training. Note that dening privileged features sometimes requires a level of domain ex- pertise. Howev er , trained security experts will nd most privileged features straightforward after dening the runtime constraints on features. Additionally , the initial privileged set may include irrele- vant featur es that carr y little or no useful information for the target detection task; thus we identify the privileged set using Algorithm 3. The algorithm starts with standard featur es of a detection system and sequentially adds one privileged feature from the set which maximizes correct classication of hard examples, i.e., the featur e whose addition to the existing set has the greatest positive impact on accuracy (measured accuracy gain). The accuracy gain of hard examples is found using SVM classier (model J in algorithm 3). This process is repeated until the potential feature set is empty , a maximum number of features is reached, or the accuracy gain is below a threshold for usefulness. Note that the quality of the selection process is a consequence of the training data use d to calculate accuracy gain. If the training data is not representativ e of the runtime input distribution, the algorithm could inadvertently over or under-estimate the accuracy gain of a feature and thereby weaken the detection system [ 15 ]. Additionally , the accuracy gain can be computed via dierent feature selection algorithms. For instance, a more brute force approach that evaluates the impact of all standard and privileged feature combination can be used. This drastically increases computation overhead with the high dimensional datasets used in our evaluation. Note that this limitation is not unique to feature selection in this context, but applies to all feature engineering in extant detection systems. 4.2 Experimental Systems In this section, we introduce four se curity-relevant systems for face authentication, fast-ux bot detection, malware trac detection, and malware classication. W e sele cted these experimental systems based on their appropriateness and diversity of their detection task. This diverse set of detection systems serves as a representative benchmark suite for our approaches. The following are the steps involved in constructing each system (discussed below ): (1) Extract standard features of e xisting detection systems 5 System Datasets and Standard features Incorporated privilege d features Detection time constraints on privileged features 1 [27, 30, 58] -Raw face images -Bounding boxes and cropped versions of facial images -Need of additional software for processing -Infeasible in energy and processing constrained sensors 2 [16, 25, 29, 42, 59] -Number of unique A and NS records in DNS packets -Edit distance, KL div ergence and Jaccard index (domain names) -Pr ocessing overhead of whitelist domains -Network, processing and document fetch delay - Time zone entropy of A and NS records in DNS packets -IP coordinate database processing overhead -Euclidean distance between server IP and NS address -Number of distinct Autonomous systems and networks - Time consuming WHOIS processing . . . . . . . . . 3 [17, 18, 36, 60] -Data bytes divided by the total number of packets -Source and destination port numbers -A dversary easily change them in subsequent malware versions - T otal number of RT T samples found -Byte frequency distribution in packet payload - The count of all packets with at least a byte payload - T otal connection time -Payload encryption in subsequent malware versions - The median of total IP packets - T otal number of packets with URG and P USH ag set . . . . . . . . . 4 [2, 19] -Frequency count of hexadecimal duos in binary les -Frequency count of distinct tokens in metadata log -Software-dependency of obtaining assembly source code -Computational overhead and error-prone feature acquisition T able 1: Description of detection systems: 1 Face A uthentication, 2 Fast-ux Bot Dete ction, 3 Malware Trac Dete ction, and 4 Malware Classication. Appendix B provides details on the standard and privileged features used throughout. Figure 5: Example of face authentication featur es. Original image for standard features (Left), croppe d (Middle), and funneled (Right) images used for privileged features. (2) Add new privileged featur es by identifying detection-time constraints on the features (3) Use the algorithm in preceding se ction to calibrate the de- tection system with standard and privileged features Through this process, we construct their privileged-augmented systems with application of approaches that is used for the valida- tion in the following section. T able 1 summarizes the e xperimental systems and the standard and privileged features selected. Addi- tional details about these systems and their featur es are presented in Appendix B. Experimental System: Face A uthentication - T o explore the eciency of approaches in image domains, we modeled a user authentication system based on recognition of facial images. Our goal is to recognize an image containing a face with an identier corresponding to the individual depicted in the image. W e use images from a public dataset that includes face images labeled with each person’s name [ 27 ]. W e build the features from 1348 facial images with at least 50 images per user . Privileged information. It is recently found that face recognition systems used for access control in particular energy and compu- tation constrained camera sensors can b e easily bypassed by an attacker [ 20 ]. In this, the lack of useful features or number of im- ages used to train the systems is the main reason of duping the systems into falsely authenticate/recognize users. W e use two types of privileged features for each image in addition to the original images in model training: cropped and funnele d versions of the images (Se e Figure 5) [ 30 , 58 ]. These images provide additional information for a users’ face by image aligning and lo calizing [ 26 ]. While it is technically possible these features can be obtained by an aid of software or human expert at runtime, the y are much more 00401000$56$8D$44$24$08$50$8B$F1$E8$1C$1B$00$00$C7$06$08$ 00401010$BB$42$00$8B$C6$5E$C2$04$00$CC$CC$CC$CC$CC$CC$CC$ 00401020$C7$01$08$BB$42$00$E9$26$1C$00$00$CC$CC$CC$CC$CC$ 00401030$56$8B$F1$C7$06$08$BB$42$00$E8$13$1C$00$00$F6$44$ 00401040$24$08$01$74$09$56$E8$6C$1E$00$00$83$C4$04$8B$C6$ ... $ mov$$$$$edi,$[esp+0Ch]$ jz$$$$$$short$loc_401506$ mov$$$$$esi,$[ecx+18h]$ lea$$$$$eax,$[ecx+4]$ cmp$$$$$esi,$10h$ mov$$$$$edx,$[eax]$ ...$ Figure 6: Excerpt from hexadecimal representations (right), and as- sembly view ( left) of an example malware. Selected byte bigrams and tokens for this malware is shown in boxes. likely to not be available in low energy and slow processing sensors (and thus we dene them as privileged). 1 Experimental System: Fast-ux Bot Dete ction - The Fast-ux bot detector is used to identify hosts that use fast-changing DNS entries to hide the existence of server hosts used for malicious activities. The raw data consists of 4GB DNS requests of benign and active fast-ux servers collected in early 2013 [ 16 ]. W e build a detection system by using the 19 features used in recently proposed botnet detectors [ 29 , 42 , 59 ]. This system relies on features obtained from domain names, DNS packets, packet timing intervals, WHOIS domain lookup and IP coordinate database. The resulting dataset includes many features to increase separation of Content Delivery Networks (CDNs) from fast-ux servers, as similarities between them are the main source of detection errors. Privileged information. In this system, ev en though the complete features are relevant for fast-ux detection, obtaining some featur es at runtime entails computational delays. For example , processing of WHOIS records, maintaining up-to-date IP coordinate database and whitelist of domain names takes several minutes/hours. Thus, we dene eleven featur es obtained from these sources as privileged to assure real-time detection. Experimental System: Malware T rac Detection - Next, we modeled a malware trac anomaly dete ction system based on net- work ow statistics use d in recent detection systems [ 17 , 22 , 36 ]. The system aggregates 20 ow featur es for detecting botnet com- mand and control (C&C) activity among benign applications. For instance, the ratio between maximum and minimum packet size from server to client and client to server nd out to be a distinctive observation b etween benign and malicious samples. W e add 173 bot- net trac of Zeus variants that is used for spam distribution, DDoS 1 W e interpret the accuracy gain as a defense for hardening misclassication of users. 6 System Approach Relative Gain over Traditional Dete ction Parameter Optimization? Detection time Overhead? Accuracy Precision Recall Fast-ux Bot Detection Knowledge Transfer 7.7% 5.3% 3.4% ✓ ✓ Malware Classication Model Inuence 7.3% 2.2% 3.7% ✓ ✗ Malware Trac Analysis Distillation 8.6% 2.2% 5% ✓ ✗ Face A uthentication Distillation 16.9% 9.3% 9.2% ✓ ✗ T able 2: Summary of accuracy , precision and recall gain via privileged information-augmented systems. The b est resulting approach for each detection system is illustrated. (See the next two sections for more details on approach comparison and runtime overhead of approaches.) attacks, and click fraud [ 21 , 48 ] to the 1553 benign applications (web browsing, chat, email, etc..) of Lawrence Berkeley National Laboratory (LBNL) [39] and University of T wente [5]. Privileged information. In this system, the authors eliminate the features that can b e readily alter ed by an attacker , as the model trained with tampered features allows an attacker to manipulate the detection results easily [ 35 , 60 ]. The impact of altering the featur es at run time on detection accuracy is recently studied [ 17 ]. For instance, consider that destination port numbers or packet interval time are used as a feature. An adversary may “easily" change them in subsequent malware versions to evade detection systems. Also, the authors do not use payload content to obtain features because the attacker can use encrypte d trac to prevent deep packet inspection. Thus, we de em such eight features as a privilege d, as inference do es not consider their tampered values at runtime. Experimental System: Malware Classication - The Micr osoft malware dataset [ 19 ] is an up-to-date publicly available corpus. The dataset includes nine malware classes inc luding hexadecimal repre- sentation of the malware ’s binar y content, and a class representing one of nine family names. The dataset used in our experiments includes 1746 malware samples extracted from 200GB malware les. W e build a real-time malware classication system by using the binary content le. Following a r ecent malware classication system [2], we construct features by counting frequencies of each hexadecimal duos (i.e., byte bigrams). These features found out to provide distinctive between dierent families because of exploiting the code dissimilarities among families. Privileged information. This dataset also includes a metadata man- ifest log le. The log le contains information such as memory allocation, function calls, strings, etc.. The logs along with the mal- ware les can be use d for classifying malware into their respective families. Thus, similar to the byte les, we obtain the fr equency count of distinct tokens from asm les such as mov() , cmp() in the text section (See Figure 6). These tokens allo w us to capture execu- tion dierences b etween dier ent families [ 2 ]. Howev er , in practice, obtaining features from log les introduces signicant overheads in the disassembly process. Further , various types or versions of a disassembler may output byte sequences dierently . Thus, this process may result in inaccurate and slow feature processing in real-time automated systems [ 37 ]. T o address these limitations, we include features from disassembler output as privileged for accurate and fast classication. 5 EV ALU A TION In this section, we explore the following questions: Knowledge Transfer Model Inuence Distillation Fast-ux Bot Detection Section 5.1 Section 5.4 Section 5.4 Malware Trac Detection Section 5.4 Section 5.2 Section 5.4 Face Authentication — — Section 5.3 Malware Classication Section 5.4 Section 5.4 Section 5.4 T able 3: Summary of validation experiments. (1) How much does privileged-augmente d detection improve p erfor- mance over systems with no privileged information? W e e valuate the accuracy , precision, and recall of approaches, and demon- strate the detection gain of including privileged features. (2) How well do the approaches perform for a given domain and detec- tion task? W e answer this question by comparing the results of approaches and present guidelines and cautions for appr opriate approach calibration to maximize the detection gain. (3) Do appr oaches introduce training and detection overhead? W e report model learning and runtime overhead of approaches for realistic environments. T able 2 shows the summary of the privileged information aug- mented systems, and T able 3 identies the validation experiments described throughout. As detailed throughout, we nd that the use of privilege d information can improve–often substantially– detection performance in the experimental systems. Overview of Experimental Setup . W e compare performance of privileged-augmented systems against two baseline (non-privileged) models: the standar d set model and the complete set model. The standard set mo del is a conventional detection system that does not include the privileged features for training or runtime, but uses all of the standard features. The complete set model is a conven- tional system that includes all the privileged and standards features for training or runtime. Note that the ideal privileged information approach would have similar performance as the complete set. T o learn standar d and complete set mo dels, we use classiers of Random Forest (RF) and Support V ector Machines (SVM) with a ra- dial basis function kernel. These classiers give better performance in the previously introduced systems and are also preferred by the system authors. The parameters of the models are optimized with exhaustive or randomized parameter sear ch based on the dataset size. All of our experiments are implemented in Python with the scikit-learn machine learning librar y or MA TLAB with the opti- mization toolbox and run on Intel i5 computer with 8 GB RAM. W e give the details of the implementation of privilege d-augmented systems while presenting the calibration of approaches in Section 6. 7 Fast-ux Bot Detection (FF) Model Accuracy Precision Recall Complete Set RF 99 ± 0.9 99.4 99.4 SVM 99.4 ± 0.3 99.3 100 Standard Set RF 96.5 ± 2.6 98.7 96.8 SVM 95 ± 2.3 94.4 95.5 Similarity (KT) RF 98.6 ± 1.3 99.3 98.7 SVM 96.7 ± 1.2 98.7 97.1 Regression (KT) RF 98.3 ± 1.4 99 98.7 SVM 96 ± 1.1 98.7 96.1 T able 4: Fast-ux Bot Detection knowledge transfer (KT) results. All numbers shown are percentages. The best result of the knowledge transfer options is highlighte d in boldface. W e show detection performance of complete and standard set models and compare their results with our approaches based on three metrics: accuracy , recall, and precision. W e also present the false positives and negatives when relevant. Accuracy is the sum of the true positive and true negativ es over a total number of samples. Recall is the numb er of true positives over the sum of false negatives and true positives, and precision is the number of true p ositives over the sum of false positives and true positives. Higher values of accuracy , precision, and recall indicates a higher quality of the detection output. 5.1 Knowledge Transfer Our rst set of experiments compares the performance of privileged- augmented detection system using knowledge transfer (KT) over standard and complete set models. In this experiment, we classify domain names into benign or malicious in fast-ux bot detection system (FF). T o realize KT , we implement two mapping functions to esti- mate the privileged features from a subset of standard features: regression-based and similarity-based . W e nd that both mapping functions learn the patterns of a training data and mostly suce for the derivation of the nearly precise estimated privileged features. First, a polynomial regression function is built to nd a coecient vector β ∈ R d such that there exists a x ∗ i = f i ( x s , β ) + b + ϵ for some bias term b and random residual error ϵ . The resulting func- tion is then used to estimate each privilege d feature at dete ction time given the standard features as an input. W e use polynomial regression that ts a nonlinear relationship to each privileged fea- ture and picks the one that minimizes the sum of squares error . T o evaluate the eectiveness of the regression, we implement a second mapping function named weighted-similarity . This function is used to estimate the privileged features from the most similar samples in the training set. W e rst nd the k most similar subset of standard samples that are selected by using the Euclidean distance between an unknown sample and training instances. Then, the privileged features are r eplaced by assigning weights that are inversely pro- portional to the similarities of their neighbors. W e note that other distance metrics gives worse accuracy than Euclidean distance for the studied datasets. T able 4 shows the accuracy of Random Forest Classier (RF) and Support V ector Machines (SVM) on standard, complete models, and KT in the form of multiple regression and weighted-similarity . Malware Trac Dete ction Model Accuracy Precision Recall Complete Set RF 98.7 ± 0.3 99.7 98.9 SVM 95.6 ± 1.2 98.8 94.6 Standard Set RF 92 ± 3 97.4 95.3 SVM 89.2 ± 0.6 94 94.6 Model Inuence SVM+ 94 ± 1.4 94.8 98.8 T able 5: Malware Trac Dete ction model inuence results. All num- bers shown are percentages. The average accuracy of ten independent runs of stratied cross- validation is given by measuring the dierence between training and validation p erformance with parameter optimization (e.g., k parameter in similarity). The complete model accuracy of both classiers is close to 99%. Note that baseline performance is obtained by always guessing the most probable class yields 68% accuracy . W e found that mapping functions are eective in nding a nearly precise relation between standard and privileged features. This decreases the expected misclassication rate on average b oth in false positives and negatives over benchmark detection with no privileged features. Both KT mapping options come close to the complete model accuracy on FF dataset (1% less accurate), and signicantly exceeds the standard set accuracy (2% more accurate). The results conrm that regression and similarity ar e more eective at estimating privileged features than solely using the standard features available at runtime. 5.2 Model Inuence Next, we evaluate the performance of model inuence-based priv- ileged information in detecting Zeus b otnet in real-w orld web (H T TP(S)) trac. Here, the system attempts to detect the mali- cious activity of a Zeus botnet that connects to C&C centers and lters private data. Note that the Zeus botnet uses H T TP mimicr y to avoid detection. As a consequence, the sole use of standard fea- tures makes detection of Zeus dicult, resulting in high detection error (wher e Zeus trac is mostly classie d as legitimate web traf- c). T o this end, we include privilege d features of packet ags, port numbers, and packet timing information from packet headers (See Appendix B for the complete list of features). W e observe that while these features can be spoofe d by adversaries under normal conditions, using them as privileged information may counteract spoong ( because inference do es not consider their runtime value). W e evaluate accuracy gain of mo del inuence over the standard model. W e use a p olynomial kernel in the objective function to perform a non-linear classication by implicitly mapping the fea- tures into a higher dimensional feature space. W e note that we avoid overtting by tuning of the regularization parameter . T a- ble 5 presents the impact of model inuence on accuracy , pr ecision, and recall and compares with standard and complete models. W e found that using the privileged features inherent to malicious and benign samples in model training systematically better separates the classes. This positive eect substantially impro ves both false negative and false positive rates. The accuracy of model inuence is close to the optimal accuracy and reduces the dete ction error on average 2% over RF trained on the standard set. This positive eect is more observable in SVM, and the accuracy gain yields 4.8%. 8 5.3 Distillation W e evaluate distillation on the e xperimental face authentication system. The standard features of a face authentication system con- sist of original images of users (i.e ., background included) with 3 RGB channels. W e obtain the privileged features of each image from funneled and downscaled bounding boxes of images. In this way , we better characterize each user’s face by specifying the face localization and eliminating the background noise. It is important to note that background of images may unrealistically increase the accuracy b ecause background regions may contribute to the distinc- tion between images. However , we verify by manual che cking that the images in our training set do not suer from this eect. In the following experiments, we construct both standard and privileged models using a deep neural network (DNN) with two hidden layers of 10 rectiers linear unit with a softmax layer for each class. This type of architecture is commonly applied in computer vision and provides superior results for image-specic applications. W e train the network with ten runs of 400 random training samples. Figure 7 plots the average distillation accuracy with various temperature and imitation parameters. W e show the accuracy of standard (dotted) and privileged set (dotted-dashed) models as a baseline. The resulting model achieves an average of 89.2% correct classication rate on the privileged set, which is b etter than the standard set with 66.5%. W e observe that distilling the privileged set features into our detection algorithm gives better accuracy than standard set accuracy with optimal T and λ parameters. The accuracy is maximized when T = 1 , the gain is on average 6.56%. The b est improvement is obtained when T = 1 and λ = 0 . 2 with 11.2% increase ov er the standard set mo del accuracy . However , increases in T negatively aect detection accuracy . This is because as T increases, the objective function puts more weight on learning from the standard features which upsets the trade-o between standard and privileged features. 5.4 Comparison of Approaches Next, we compare the relative performance of the approaches on three data sets. 2 Distillation is implemented using Deep Neural Networks (DNN), and regression and weighted similarity mapping functions are used for knowledge transfer . T able 6 presents the re- sults of kno wledge transfer (W e report similarity results as it yields better results than regression), model inuence and distillation and compares against complete and standard models. The accuracy , precision and recall gain of the best resulting approach for each detection system is summarized in T able 2. The accuracy of model inuence, distillation and knowledge transfer on the fast-ux detector and malwar e trac detection is stable. All approaches yield accuracy similar to the ideal accuracy of the complete set model, and often the increased accuracy is the result of the correct classication of true positives (intrusions). This results in on average up to 5% relative gain in r ecall with the model inuence and distillation over conventional models. In contrast, knowledge transfer often increases the number of samples detected by systems as b eing actually malicious (e.g., 99.3% precision in the fast-ux detector), meaning that the number of false alarms is 2 W e do not compare performance on face recognition b ecause processing the number of the input features (e.g., pixels) was intractable for se veral solutions. 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Imitation parameter ( 6 ) 0.35 0.4 0.45 0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95 1 Detection accuracy Standard set baseline Privileged set baseline T=1 T=2 T=5 T=10 Figure 7: Distillation impact on accuracy with privileged features in face authentication system. W e plot standard and privileged set ac- curacy as a baseline. T emperature ( T ) and imitation ( λ ) parameters are quantied on various values to show their impact on accuracy . reduced over conventional detection. The results conrm that the approaches are able to balance the conventional detection and its accuracy by using privileged features inherent to both benign and malicious samples: either reducing the false positives or negatives. W e note that these results ar e obtained after carefully tuning the model parameters. W e further discuss their parameter tuning in the following section and impact of results on systems in section 7. Distillation is easy to apply as its objective is independent of the machine learning algorithm (model-free) and often yields better results than other approaches. Its quality as a detection mechanism becomes more apparent when its objective function is implemented with deep neural networks (DNN) with a nonlinear objective [33]. This makes distillation give better results on average than other approaches. On the other hand, the design and calibration of model inuence detection requir e additional eort and care in tuning parameters–in the experiments, this additional eort yields strong detection (as 94.6% in malware classication). Note that when the dataset includes a large number of privileged features or samples, training of model inuence takes signicantly more time compared to other approaches (See next section). Finally , it is important to note that the while knowledge transfer accuracy gain for fast-ux detection and malware trac analysis is similar to other approaches, its malware classication results ar e inconsistent (i.e., 83.5% average accuracy with an 11.2% standard de- viation). Neither regression nor similarity mapping functions were able to predict the privileged features near precisely , in turn, they slightly degrade the accuracy (7-8%) on both RF and SVM standard set models. This observation conrms the need to nd and evalu- ate an appropriate mapping function for the transfer of knowledge discussed in Section 3.1. In this particular dataset, the mapping func- tions fail to nd a good relation between standard and privileged features. Regression suers from overtting to uncommon data points and similarity lacks tting data points that distinctly lie an abnormal distance from the range of standard features ( conrmed by an increase in the sum of square errors of estimated and true values for the privileged features). W e remark that derivation of more advanced mapping functions may solve this problem. Further , model inuence and distillation solv e this by eliminating the use of 9 Fast-ux Bot Detection Malware Trac Detection Malware Classication Model Acc. Pre. Rec. Acc. Pre. Rec. Acc. Pre. Rec. Complete Set RF 99 ± 0.9 99.4 99.4 98.7 ± 0.3 99.7 98.9 96.6 ± 1.2 99.3 95.2 SVM 99.4 ± 0.3 99.3 100 95.6 ± 1.2 98.8 94.6 95.7 ± 1 98.6 94.6 Standard Set RF 96.5 ± 2.6 98.7 96.8 92.9 ± 3 97.4 95.3 91.2 ± 1 91.3 94.4 SVM 95 ± 2.3 94.4 95.5 89.2 ± 0.6 94 94.6 91.8 ± 1.1 93.2 93.6 KT (Similarity) RF 98.6 ± 1.3 99.3 98.7 93.3 ± 2.1 94.4 98.4 90.1 ± 2.2 97.3 88 SVM 96.7 ± 1.2 98.7 97.1 92.6 ± 0.9 95.1 96 83.5 ± 11.2 88.3 85.6 Model Inuence SVM+ 97.3 ± 1.3 97 99.3 94 ± 1.4 94.8 98.8 94.6 ± 2.3 93.3 97.8 Distillation DNN 97.5 ± 0.3 97.4 99.3 95.7 ± 0.6 96.1 99.3 92.6 ± 0.7 92.6 95.3 T able 6: Summary of results: Accuracy (Acc.), Precision (Pre.) and Recall (Re c.) The best result for each detection system is highlighted in bold. mapping functions and including standard and privileged feature dependency into their objectives. Therefore, based on the above observations, the approaches are in nee d for a calibration based on the domain and task-specic properties to maximize the detection gain, as explored next. 6 LIMI T A TIONS In this section, we discuss the required dataset properties, algorithm parameters, training, and runtime overhead of using privileged in- formation for detection. W e also present guidelines and cautionary warnings for use of privileged information in realistic deployment environments. A summary of an approach selection criteria is pre- sented in T able 7. Model Dependency . Model selection is a task of picking an appro- priate model (e.g., classier) to construct a detection function from a set of potential models. Knowledge transfer can be applied to a model of choice, as privileged features are inferred with any accu- rately selected mapping function. Distillation requires a model with a softmax output layer for obtaining probability vectors. Howev er , we adapt model inuence to SVM’s objective function. Detection Overhead. The mapping functions used in knowledge transfer may introduce detection delays while estimating the priv- ileged features. For instance, weighted similarity introduced in Section 3.1 defers estimation until detection without learning a function at training time (i.e., lazy learner ). This may introduce a detection bottleneck if dataset includes a large number of samples. T o solve this problem, we apply stratied sampling to r educe the size of the dataset. Furthermore , constructing mapping functions at training time such as regression-based minimize the delay of estimating privileged features. For instance, in our experiments, weighted-similarity is used to estimate ten privileged features of 5K training samples in less than a second delay on 2.6GHz 2-cor e Intel i5 processor with 8GB RAM. Regression reduces this value to milliseconds. Therefore, if delay at runtime is the primary concern, we suggest using model inuence and distillation for learning the detection model, as they introduce no overhead at runtime. Model Optimization. T o obtain the best performance results, the parameters and hyperparameters of approaches ne ed to be care- fully tuned. For instance, ne-tuning of temperature and imitation parameters in distillation and kernel function hyperparameters in model inuence approaches may increase the detection perfor- mance. Similar to conventional dete ction, the numb er of parameters Model Detection time Mode l Training time Approach dependency overhead optimization overhead Knowledge Transfer ✗ ✓ Model Inuence ✓ ✗ Distillation ✗ ✗ Legend: ✓ yes ✗ no model dependent relatively higher T able 7: Guideline for approach sele ction. required to be optimized b oth for knowledge transfer and general- ized distillation can b e determined a priori base d on the selecte d model. However , model inuence has twice as many parameters as SVM—two kernel functions are used simultane ously to learn detection boundar y in standard and privileged feature spaces. W e apply grid search for small training sets and evolutionary search for large-scale datasets for parameter optimization. Training Overhead. Training set size aects the time required by model learning. The amount of additional time needed to run both knowledge transfer and generalized distillation is negligible, as they require similar models as existing systems apply . Howe ver , the objective function of model inuence may become infeasible or take a long time when the dimension of the feature space is very small, or dataset size is quite large. For instance , in our experi- ments, distillation and knowledge transfer train 1K samples with 50 standard and privileged features on the same machine used for one minute including optimal parameter sear ch. Model inuence takes on average 30 minutes on the same machine used for mea- suring detection overhead. Packages that are designed specically for solving the quadratic programming ( QP) problems (e.g., MA T - LAB quadprog() function) can be used instead of general solvers such as convex optimization package CVX to reduce the training time. Further , spe cialized spline kernels can be used to accelerate the computation [ 54 ]. W e give a specic implementation of mo del inuence in such packages in Appendix A. 7 DISCUSSION Our empirical results show that approaches reduce both false posi- tives and negatives over the systems solely built on their standard features. In a security setting, a false positive makes it extremely dif- cult for the analyst e xamining the reported incidents only to iden- tify the mistakenly triggered benign events correctly . It is not sur- prising, therefore, that recent resear ch focuses on p ost-processing of the alerts to produce a more qualitative alert set useful to the human analyst [ 51 ]. False negatives, on the other hand, have the 10 potential to cause catastrophic damage to both users and organiza- tions: ev en a single compromised system can cause serious security breaches. For instance, in malware trac and fast-ux bot dete ction, a false negative may cause a bot lter private data to a malicious server . In the case of malwar e classication and face authentication, it undermines the integrity of a system by misclassifying malware into another family or recognizing the wrong user . Thus, in no small way , impr ovement in false positives and negatives of these systems does matter in operational settings, improving reliable detection. 7.1 Uses of Privileged Information Privileged information is not restricted to the domains discussed above, but ar e readily adaptable problems and machine learning settings. For example, privileged information can be adapted to settings with unsupervised, regr ession, and metric learning [ 31 ]. With respect to detection, we consider several illustrativ e uses of privileged information below: Mobile Device Se curity - The growth of mobile malware requires robust malware detectors on mobile devices. Curr ent systems col- lect data for numerous type of attacks; however , exhaustive data collection at runtime can have high energy costs and induce notice- able interface lag. As a consequence, users may disable the detection mechanism [ 6 ]. W e note that high-cost features can be dened as privileged information to combat this problem. Enterprise Security - Enterprise systems use audit data gener- ated from a diverse set of devices and information sources for analysis [ 10 ]. For instance, SIEM products collect data from hosts, applications, and network devices in incredible volumes (e.g., 100K events per second yielding to 42 TB of compressed data). These massive datasets are mined for patterns identifying sophisticated threats and vulnerabilities. However , systems may be ov erwhelme d by feature collection and processing at runtime which makes their collection impractical for many settings. In such cases, features involving complex and expensive data collection can be dene d as privileged to balance the real-time costs and accuracy . Privacy Enhanced Detection - Many detection pr ocesses require the collection of privacy-relevant features, e.g., pattern and sub- stance of user network trac, use of the softwar e [ 11 , 13 ]. Hence, it is important to reduce the collection and e xposure of such data– legal and ethical issues may prevent continuously monitoring them in their original form. In these cases, a set of features can be dened as privileged to eliminate the requirement of obtaining and poten- tially retaining privacy-sensitive features at runtime from users and environments. 7.2 Privileged Information as a Defense W e also posit that privileged information can b e used as a defense mechanism in adversarial settings. More specically , the key at- tacks targeting machine learning are organized into two categories based on adversarial capabilities [ 28 ]: ( 1 ) causative (poisoning) at- tacks in which an attacker controls the training data by injecting well-crafted attack samples to control the prediction results, and ( 2 ) explanatory ( evasion) attacks in which attacker manipulates the malicious samples to e vade detection. For the former , privileged features adds an extra step for the attacker to pollute the training data because the attacker ne eds to dupe the data collection into including polluted privileged samples in addition to the standard samples–which for many systems including online learning would potentially be much more dicult. For the latter , privileged fea- tures may make detection systems more robust to the adversarial samples because privilege d features cannot be controlled by the adversary when producing malicious samples [ 32 ]. Moreover , be- cause the model is hidden from the adversary they cannot know the inuence of these features on the model [ 7 ]. As a proof of con- cept, recent works have used distillation of standar d features as a defense mechanism against adversarial p erturbations in DNNs [ 40 ]. In future work, we plan to further evaluate privileged information as a mechanism to harden machine learning systems. 8 RELA TED WORK Domain-specic feature engineering has been a key eort within the se curity communities. For example, researchers have previously used specic patterns to group malware samples into families [ 2 , 38 , 43 ], have explored using DNS information to understand and predict botnet domains [ 1 , 4 , 14 , 59 ], and have analyzed network and system level features to identify previously unknown malware trac [ 17 , 36 , 44 ]. Other w orks have focused on user authentication from facial images [ 41 , 52 ]. W e view our eorts in this pap er to be complementary to these and related works. Features in these works can b e easily enhanced with privileged information in dete ction algorithms to strike a balance between accuracy and the cost or availability constraints at runtime. The use of privileged information has recently attracted attention in a few others areas such as computer vision, image processing, and even nance . W ang et al. [ 57 ] and Sharmanska et al. [ 50 ] derived privileged features from images in the form of annotator rationales, object bounding b oxes, and textual descriptions. Ribeiro et al. use d annual turnover and global balance values as privileged featur es for enhancing the nancial decision-making [ 47 ]. Howev er , their approaches are not designed to model security-relevant data and do not consider feature engine ering but rather to determine if there is a possibility of application to a domain specic information. 9 CONCLUSIONS W e have presented a range of techniques to train detection systems with privileged information. All approaches use features available only at training time to enhance the accuracy of detection models. W e consider three approaches: (a) knowledge transfer to construct mapping functions to estimate the privileged features, ( b) model inuence to smooth the detection model with the useful informa- tion obtained from the privileged featur es, and (c) distillation using probability vector outputs obtained from the privileged features in the detection objective function. Our evaluation of several detection systems shows that we can we improve the accuracy , recall, and precision r egardless of their high detection performance using priv- ileged featur es. W e also presented guidelines for approach selection in realistic deployment environments. This work is the rst eort at developing detection under privi- leged information by exploring feature engine ering, algorithms, and environmental calibration. The capability aorded by this approach will allow us to integrate forensic and other auxiliary information that, to date , has not been actionable for detection. In the future, we 11 will explore various environments and evaluate its ability to pro- mote resilience to adversarial manipulation in detection systems. In this way , we will explore new models and systems using privileged features to promote lightweight, accurate and r obust detection. A CKNO WLEDGMEN TS Research was sponsored by the Army Research Laboratory and was accomplished under Cooperative Agreement Number W911NF- 13-2-0045 ( ARL Cyber Security CRA). The views and conclusions contained in this document ar e those of the authors and should not be interpreted as repr esenting the ocial policies, either ex- pressed or implied, of the Army Research Lab oratory or the U .S. Government. The U .S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation here on. REFERENCES [1] Manos A. et al . 2012. From throw-away trac to bots: dete cting the rise of DGA -based malware. In USENIX Security . [2] Mansour A. et al . 2015. Novel feature extraction, selection and fusion for eective malware family classication. arXiv preprint . [3] Jimmy B. and Rich C. 2014. Do deep nets really need to be deep?. In Advances in neural information processing systems . [4] Leyla B., E. Kirda, C. Kruegel, and Marco B. 2011. EXPOSURE: Finding malicious domains using passive DNS analysis. In NDSS . [5] R. Barbosa, R. Sadre, A. Pras, and R. Meent. 2010. University of Ttwente trac traces data repository . In University of Twente Tech Report . [6] J. Bickford et al . 2011. Security versus energy trade os in host-base d mobile malware detection. In Mobile systems, applications, and services . [7] B. Biggio, G. Fumera, and F. Roli. 2014. Pattern recognition systems under attack: Design issues and research challenges. International Journal of Pattern Recognition and A rticial Intelligence . [8] Equifax Data Breach. 2018. https://en.wikipedia.org/wiki/Equifax. (2018). [Online; accessed 15-January-2018]. [9] I. Butun et al . 2014. A survey of intrusion detection systems in wireless sensor networks. IEEE Communications Sur veys & Tutorials . [10] A. A. Cardenas, P. K. Manadhata, and S. P. Rajan. 2013. Big data analytics for security . IEEE System Security . [11] Z. B. Celik, H. Aksu, A. Acar , R. Sheatsley , A. S. Uluagac, and P . McDaniel. 2017. Curie: Policy-based Secure Data Exchange. [12] Z. B. Celik, R. Izmailov , and P. McDaniel. 2015. Proof and implementation of algorithmic realization of learning using privileged information (LUPI) paradigm: SVM+ . Technical Report NAS- TR-0187-2015. NSCR, CSE, PSU. [13] Z. Berkay Celik, David Lopez-Paz, and Patrick McDaniel. 2016. Patient-driven privacy control through generalized distillation. IEEE Symposium on Privacy- A ware Computing (PA C) . [14] Z. B. Celik, P. McDaniel, and T . Bowen. 2017. Malware modeling and experi- mentation through parameterized behavior . The Journal of Defense Modeling and Simulation . [15] Z. B. Celik, P. McDaniel, and R. Izmailov . 2017. Feature cultivation in privileged information-augmented detection. In ACM CODASPY International W orkshop on Security And Privacy A nalytics . [16] Z. B. Celik and S. Oktug. 2013. Detection of fast-ux networks using various DNS feature sets. In ISCC . [17] Z. B. Celik, J. Raghuram, G. Kesidis, and D . J. Miller . 2011. Salting public traces with attack trac to test ow classiers. In Usenix CSET . [18] Z. B. Celik, R. J. W alls, P. McDaniel, and A. Swami. 2015. Malware trac detection using tamper resistant features. In IEEE MILCOM . [19] Microsoft Malware Classication Challenge. 2017. https://www.kaggle .com/c/malware-classication/. (2017). [Online; ac- cessed 10-May-2017]. [20] N. M. Duc and B. Q. Minh. 2009. Y our face is not your password face authentication bypassing lenovo–asus–toshiba. Black Hat Briengs . [21] S. García, M. Grill, J. Stiborek, and A. Zunino. 2014. An empirical comparison of botnet detection methods. In Computers & Security . [22] G. Gu et al . 2008. BotMiner: Clustering Analysis of Network Trac for Protocol- and Structure-Independent Botnet Detection. In USENIX Security . [23] A. Hassanzadeh et al . 2013. PRIDE: Practical intrusion detection in resource con- strained wireless mesh networks. In Information and Communications Security . [24] G. Hinton, O. Vinyals, and J. Dean. 2015. Distilling the knowledge in a neural network. arXiv preprint . [25] C. Hsu, C. Huang, et al. 2010. Fast-ux b ot detection in real time. In RAID . [26] Gary Huang et al . 2012. Learning to align from scratch. In Advances in Neural Information Processing Systems . [27] G. B. Huang et al . 2014. Lab eled faces in the wild: Updates and new reporting procedures . Technical Report UM-CS-2014-003. UMASS. [28] L. Huang et al . 2011. Adversarial machine learning. In A CM security and articial intelligence workshop . [29] S. Huang et al . 2010. Fast-ux service network detection based on spatial snapshot mechanism for delay-free detection. In ASIACCS . [30] Vidit J. and E. Learne d-Miller . 2010. FDDB: A Benchmark for Face Detection in Unconstrained Settings . Technical Report UM-CS-2010-009. UMass. [31] Rico Jonschkowski, Sebastian Höfer, and Oliver Brock. 2015. Patterns for learning with side information. [32] P. Laskov et al . 2014. Practical evasion of a learning-based classier: A case study . In IEEE Security and Privacy . [33] D. Lopez-Paz, L. Bottou, B. Schölkopf, and V . V apnik. 2015. Unifying distillation and privileged information. arXiv preprint . [34] MA TLAB documentation of quadprog function. 2018. www.mathw orks.com/help/optim/ug/quadprog.html. [Online; accessed 15-March-2018]. [35] P. McDaniel, N. Papernot, and Z. B. Celik. 2016. Machine learning in adversarial settings. Security & Privacy Magazine . [36] D. J. Miller et al . 2012. Sequential anomaly dete ction in a batch with growing number of tests: Application to network intrusion detection. In MLSP . [37] L. Nataraj, V . Y egneswaran, P. Porras, and J. Zhang. 2011. A comparative as- sessment of malware classication using binary textur e analysis and dynamic analysis. In Security and Articial Intelligence W orkshop . A CM. [38] N. Nissim et al . 2014. No vel active learning methods for enhanced PC malware detection in windows OS. Expert Systems with Applications . [39] R. Pang, M. Allman, M. Bennett, J. Lee, V . Paxson, and B. Tierney . 2005. A rst look at modern enterprise trac. In Internet Measurement Conference . [40] N. Papernot et al . 2016. Distillation as a defense to adversarial p erturbations against deep neural networks. IEEE S&P . [41] O . M. Parkhi et al. 2015. Deep face recognition. British Machine Vision . [42] E. Passerini, R. Paleari, L. Martignoni, and D . Bruschi. 2008. F luxor: Detecting and monitoring fast-ux service networks. In DIMV A . [43] M. Z. Raque and J. Caballero. 2013. Firma: Malware clustering and network signature generation with mixed network behaviors. In RAID . [44] B. Rahbarinia et al . 2015. Segugio: Ecient behavior-based tracking of malware- control domains in large ISP networks. In IEEE DSN . [45] S. Raza, L. W allgren, and T . V oigt. 2013. SVELTE: Real-time intrusion detection in the Internet of Things. A d hoc networks . [46] J. Re eves, A. Ramaswamy , M. Locasto, S. Bratus, and S. Smith. 2011. Light- weight intrusion detection for resource-constrained embedded control systems. In Critical Infrastructure Protection . [47] Bernardete Ribeiro et al . 2012. Enhanced default risk models with SVM+. Expert Systems with Applications . [48] C. Rossow et al . 2013. Sok: P2p wned-modeling and evaluating the resilience of peer-to-peer b otnets. In IEEE Security and Privacy . [49] K. Scarfone and P. Mell. 2007. Guide to intrusion detection and prevention systems (IDPS). NIST special publication . [50] V . Sharmanska, N. Quadrianto, and C. H. Lampert. 2013. Learning to rank using privileged information. In International Conference on Computer Vision . [51] R. Shittu et al . 2015. Intrusion alert prioritisation and attack detection using post-correlation analysis. Computers & Security . [52] Y . Sun, D. Liang, X. W ang, and X. Tang. 2015. Deepid3: Face recognition with very DNNs. arXiv preprint . [53] B. A. T urlach and A W eingessel. 2007. quadprog: Functions to solv e quadratic programming problems. R package version . [54] V . V apnik and R. Izmailov . 2015. Learning using privileged information: Similarity control and knowledge transfer . Journal of Machine Learning Research . [55] V . V apnik and A. V ashist. 2009. A new learning paradigm: Learning using privileged information. Neural Networks . [56] R. J. W alls, E. G. Learned-Miller, and B. N. Levine. 2011. Forensic triage for mobile phones with DEC0DE. In USENIX Security . [57] Z. W ang and Q. Ji. 2015. Classier learning with hidden information. In IEEE Computer Vision and Pattern Recognition . [58] L. W olf, T . Hassner , and Y . T aigman. 2011. Eective unconstrained face recogni- tion by combining multiple descriptors and learned background statistics. Pattern A nalysis and Machine Intelligence . [59] S. Y adav et al . 2010. Detecting algorithmically generate d malicious domain names. In Internet Measurement Conference . [60] G. Zou, G. Kesidis, and D . J. Miller . 2011. A ow classier with tamper-resistant features and an evaluation of its portability to new domains. JSAC . 12 A MODEL INFLUENCE OPTIMIZA TION In this Appendix, we present the formulation of model inuence approach introduced in Section 3.2 (Section A.1) and its implemen- tation in MA TLAB (Section A.2) in order to realize the paradigm in detection systems. A.1 Model Inuence Formulation W e can formally divide the featur e space into tw o spaces at training time. Given L standard vectors ® x 1 , . . . , ® x L and L privileged vectors ® x ∗ 1 , . . . , ® x ∗ L with a target class y = { + 1 , − 1 } , where ® x i ∈ R N and ® x ∗ i ∈ R M for all i = 1 , . . . , L . The kernels K ( ® x i , ® x j ) and K ∗ ( ® x ∗ i , ® x ∗ j ) are selected along with positive parameters κ , and γ . Our goal is nding a detection mo del f → x s : y . The optimization problem is formulated as [54]: L Õ i = 1 α i − 1 2 L Õ i , j = 1 y i y j α i α j K ( ® x i , ® x j ) − γ 2 L Õ i , j = 1 y i y j ( α i − δ i )( α j − δ j ) K ∗ ( ® x ∗ i , ® x ∗ j ) → max L Õ i = 1 α i y i = 0 , L Õ i = 1 δ i y i = 0 0 ≤ α i ≤ κ C i , 0 ≤ δ i ≤ C i , i = 1 , . . . , L (1) The detection rule f for vector ® z is dened as: f ( ® z ) = sign L Õ i = 1 y i α i K ( ® x i , ® z ) + B ! (2) where to compute B , we rst derive the Lagrangian of (1): L ( ® α , ® β , ® ϕ , ® λ , ® µ , ® ν , ® ρ ) = L Õ i = 1 α i − 1 2 L Õ i , j = 1 y i y j α i α j K ( ® x i , ® x j ) − γ 2 L Õ i , j = 1 y i y j ( α i − δ i )( α j − δ j ) K ∗ ( ® x ∗ i , ® x ∗ j ) + ϕ 1 L Õ i = 1 α i y i + ϕ 2 L Õ i = 1 δ i y i + L Õ i = 1 λ i α i + L Õ i = 1 µ i ( κ C i − α i ) + L Õ i = 1 ν i δ i + L Õ i = 1 ρ i ( C i − δ i ) (3) with Karush-Kuhn- T ucker (KKT) conditions (for each i = 1 , . . . , L ), we rewrite ∂ L ∂ α i = − K ( ® x i , ® x i ) α i − γ K ∗ ( ® x ∗ i , ® x i ∗ ) α i + K ∗ ( ® x ∗ i , ® x ∗ i ) γ δ i − Õ k , i K ( ® x i , ® x k ) y i y k α k − γ Õ k , i K ∗ ( ® x ∗ i , ® x ∗ k ) y i y k ( α k − δ k ) + 1 + ϕ 1 y i + λ i − µ i = 0 ∂ L ∂ δ i = − K ∗ ( ® x ∗ i , ® x ∗ i ) γ δ i + K ∗ ( ® x ∗ i , ® x ∗ i ) γ α i + Õ k , i K ( ® x i , ® x k ) y i y k γ ( α k − δ k ) + ϕ 2 y i + ν i − ρ i = 0 (4) where λ i ≥ 0 , µ i ≥ 0 , ν i ≥ 0 , ρ i ≥ 0 , (5) λ i α i = 0 , µ i ( C i − α i ) = 0 , ν i δ i = 0 , ρ i ( C i − δ i ) = 0 , L Õ i = 1 α i y i = 0 , L Õ i = 1 δ i y i = 0 W e denote for i = 1 , . . . , L F i = L Õ k = 1 K ( ® x i , ® x k ) y k α k , (6) f i = L Õ k = 1 K ∗ ( ® x ∗ i , ® x ∗ k ) y k ( α k − δ k ) and rewrite (4) in the form ∂ L ∂ α i = − y i F i − γ y i f i + 1 + ϕ 1 y i + λ i − µ i = 0 ∂ L ∂ δ i = γ y i f i + ϕ 2 y y + ν i − ρ i = 0 λ i ≥ 0 , µ i ≥ 0 , ν i ≥ 0 , ρ i ≥ 0 , λ i α i = 0 , µ i ( C i − α i ) = 0 , ν i δ i = 0 , ρ i ( C i − δ i ) = 0 L Õ i = 1 α i y i = 0 , L Õ i = 1 δ i y i = 0 (7) The rst equation in (7) implies ϕ 1 = − y j ( 1 − y j F j − γ y j f j + λ j − µ j ) (8) for all j . If j is sele cted such that 0 < α j < κ C j and 0 < δ j < C j , then (7) implies λ j = µ j = ν j = ρ j = 0 and (8) has the following form ϕ 1 = − y j ( 1 − y j F j − γ y j f j ) ϕ 1 = − y j (( 1 − L Õ i = 1 y i y j K ( ® x i , ® x j )( α i ) − γ L Õ i = 1 y i y j K ∗ ( ® x ∗ i , ® x ∗ j )( α i − δ i )) 13 Therefore, B is computed as B = − ϕ 1 : B = y j ( 1 − L Õ i = 1 y i y j K ( ® x i , ® x j )( α i ) − γ L Õ i = 1 y i y j K ∗ ( ® x ∗ i , ® x ∗ j )( α i − δ i )) (9) where j is such that 0 < α j < κ C j and 0 < δ j < C j . A.2 Model Inuence Implementation W e present implementation of model inuence by solving its qua- dratic programming problem using MA TLAB quadprog function provided by the optimization toolbox. Other equivalent functions in R [53] or similar software can be easily adapted. MA TLAB function quadprog ( H , ® f , A , ® b , A e q , ® be q , ® l b , ® ub ) solves the quadratic programming problem in the form as follows: 1 2 ® z T H ® z + f T ® z → min A · ® z ≤ ® b A eq · ® z = ® be q ® l b ≤ ® z ≤ ® ub (10) Here, H , A , A e q are matrices, and ® f , ® b , ® be q , ® l b , ® ub are vectors. ® z is dened as ® z = ( α 1 , . . . , α L , δ 1 , . . . , δ L ) ∈ R 2 L . W e now rewrite (1) in the form of (10). 1 2 ® z T H ® z + f T ® z → min where f = (− 1 1 , − 1 2 , . . . , − 1 L , 0 L + 1 , . . . , 0 2 L ) and H i j = H 11 H 12 H 12 H 22 where, for each pair i , j = 1 , . . . , L , H 11 i j = K ( ® x i , ® x j ) y i y j + γ K ∗ ( ® x ∗ i , ® x ∗ j ) y i y j , H 12 i j = − γ K ∗ ( ® x ∗ i , ® x ∗ j ) y i y j , H 22 i j = + γ K ∗ ( ® x ∗ i , ® x ∗ j ) y i y j The second line of (10) is absent. The third line of (10) corresponds to the second line of (1) when written as A eq · ® z = ® be q where A eq = y 1 y 2 · · · y L 0 0 · · · 0 0 0 · · · 0 y 1 y 2 · · · y L , ® be q = 0 0 The fourth line of (10) corresponds to the third line of (1) when written as ® l b ≤ ® z ≤ ® ub where ® l b = ( 0 1 , 0 2 , . . . , 0 L , 0 L + 1 , . . . , 0 2 L ) , ® ub = ( κ C 1 , κ C 2 , . . . , κ C L , C 1 , C 2 , . . . , C L ) After all variables ( H , ® f , A , ® b , A e q , ® be q , ® l b , ® ub ) are dened, op- timization to olbox guide [ 34 ] can b e used to sele ct quadprog() function options such as an optimization algorithm and maximum number of iterations. Then, output of the function can be used in detection function f for a new sample ® z to make predictions as follows: f ( ® z ) = sign L Õ i = 1 y i α i K ( ® x i , ® z ) + B ! (11) B DET AILS OF DETECTION SYSTEMS In this Appendix, we detail the standard and privileged features of fast-ux bot and malware trac detection systems introduced in Section 4.2. T able 1 presents feature categories and denitions of fast-ux bot detector obtaine d from recent works [ 25 , 29 , 42 , 59 ], and T able 2 presents the features of malware trac dete ctor obtained from recent works [ 17 , 18 , 36 , 60 ]. The interested reader can refer to the references for the motivation of the feature selection. 14 Category Denition Featur e dependency Feature type DNS Answer Number of unique A records Number of NS records DNS packet analysis standard set Timing Network delay ( µ and σ ) Processing delay ( µ and σ ) Document fetch delay ( µ and σ ) H T TP requests standard set Domain name Edit distance Kullback-Leibler divergence (unigrams and bigrams) Jaccard similarity (unigrams and bigrams) Whitelist of benign domain names privileged set Spatial Time zone entropy of A records Time zone entropy of NS records Minimal service distances ( µ and σ ) IP coordinate database lookup (external source) privileged set Network Numb er of distinct autonomous systems Number of distinct networks WHOIS processing (external source) privileged set T able 1: Fast-ux b ot detection system standard and privileged feature descriptions ( µ is mean and σ is std. dev .). Abbreviation Denition Properties Feature type cnt-data-pkt The count of all the packets with at least a byte of TCP data payload - TCP length is observed -Client to server standard set min-data-size The minimum payload size observed - TCP length observed -Client to server -0 if there are no packets standard set avg-data-size Data bytes divided by the total number of pack- ets - TCP length observed -Packets with payload observed -Server to client -0 if there are no packets standard set init-win-bytes The total numb er of bytes sent in initial window -Retransmitted packets not counted -Client to server & server to client -0 if no A CK observed -Frame length calculated standard set RT T -samples The total number of RT T samples found -Client to server standard set IP-bytes- median Median of total IP packets -IP length calculated -Client to server standard set frame-bytes- var V ariance of bytes in Ethernet packets -Frame length calculated -Client to server standard set IP-ratio Ratio between the maximum packet size and minimum packet size -IP length calculated -Client to server & server to client -1 If a packet observed, and if no packets are observed 0 is reporte d standard set pushed-data- pkts The count of all the packets seen with the P USH set in TCP header -Client to server & server to client standard set goodput T otal number of frame bytes divided by the dierences between last packet time and rst packet time -Frame length calculated -Client to server -Retransmitted bytes not counted standard set duration T otal connection time Time dierence between the last packet and rst packet (SYN ag is seen from destination) privileged set min-IA T Minimum packet inter-arrival time for all pack- ets of the ow -Client to server & server to client privileged set urgent-data- pkts The total number of packets with the URG bit turned on in the TCP header -Client to server & server to client privileged set src-port Source port number -Undecoded privileged set dst-port Destination port number -Undecoded privileged set payload-info Byte frequency distributions -If not H T TPS at training time -If payloads are available -Client to server & server to client privileged set T able 2: Malware trac detection standard and privileged feature descriptions. 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment