Machine Speech Chain with One-shot Speaker Adaptation
In previous work, we developed a closed-loop speech chain model based on deep learning, in which the architecture enabled the automatic speech recognition (ASR) and text-to-speech synthesis (TTS) components to mutually improve their performance. This…
Authors: Andros Tj, ra, Sakriani Sakti
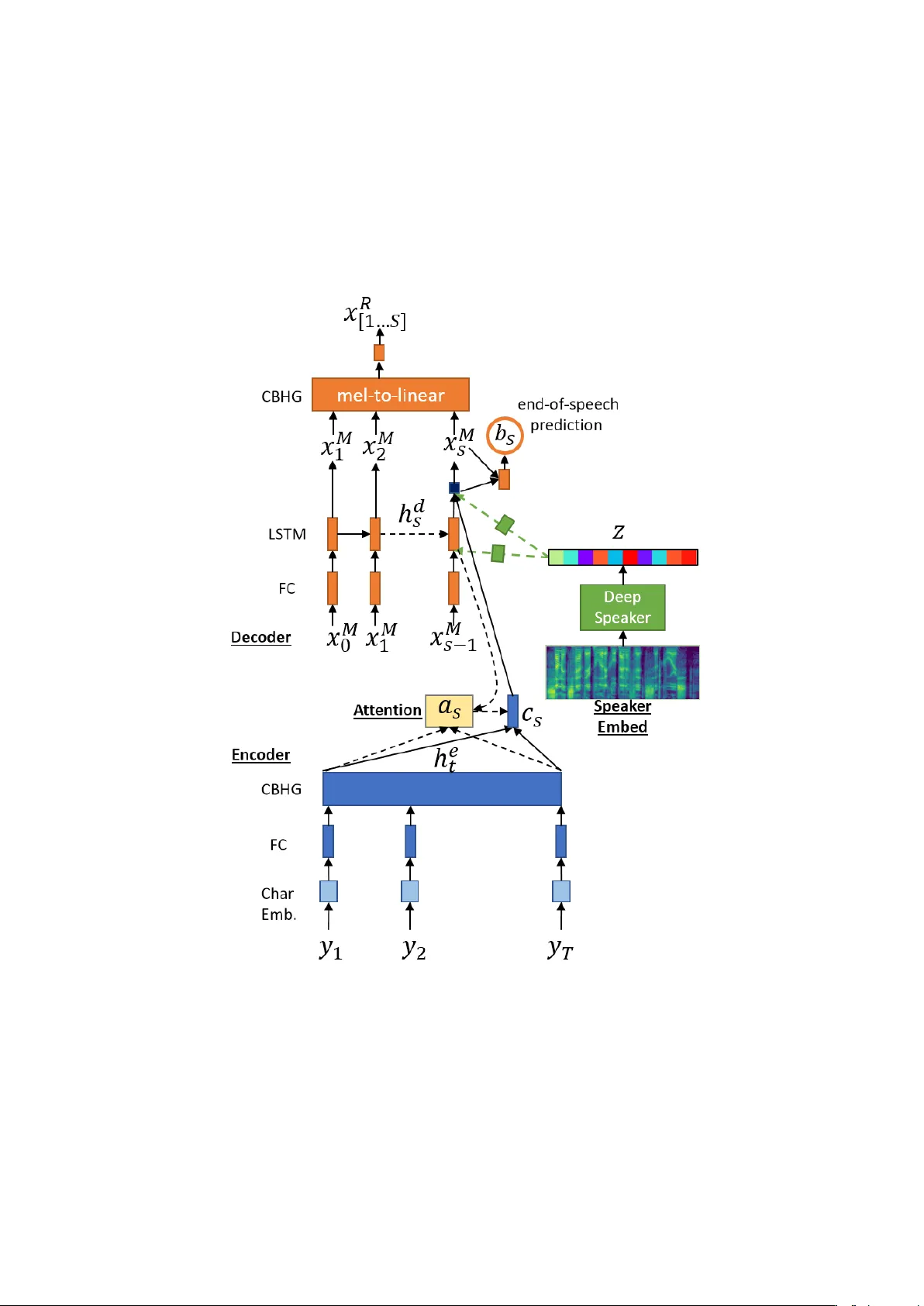
Mac hine Sp eec h Chain with One-shot Sp eak er Adaptation Andros Tjandra 1 , 2 , Sakriani Sakti 1 , 2 , Satoshi Nak am ura 1 , 2 1 Nara Institute of Science and T ec hnology Graduate Sc ho ol of Information Science, Japan 2 RIKEN, Cen ter for Adv anced In telligence Pro ject AIP , Japan { andros.tjandra.ai6,ssakti,s-nakamura } @is.naist.jp Marc h 29, 2018 Abstract In previous w ork, we dev eloped a closed-loop speech c hain mo del based on deep learning, in which the architecture enabled the automatic sp eec h recognition (ASR) and text-to-sp eec h syn thesis (TTS) components to m u- tually improv e their performance. This w as accomplished by the t w o parts teac hing eac h other using both labeled and unlab eled data. This approach could significan tly improv e mo del performance within a single-sp eaker sp eec h dataset, but only a sligh t increase could be gained in m ulti-sp eak er tasks. F urthermore, the mo del is still unable to handle unseen sp eak ers. In this pap er, we present a new sp eec h chain mechanism by integrating a sp eak er recognition mo del inside the lo op. W e also prop ose extending the capabilit y of TTS to handle unseen sp eakers by implementing one-shot sp eak er adaptation. This enables TTS to mimic v oice characteristics from one sp eak er to another with only a one-shot sp eak er sample, even from a text without any speaker information. In the sp eech chain lo op mec h- anism, ASR also b enefits from the ability to further learn an arbitrary sp eak ers c haracteristics from the generated sp eec h wa v eform, resulting in a significant improv ement in the recognition rate. Index T erms : sp eec h chain, sp eec h recognition, sp eech syn thesis, deep learn- ing, semi-sup ervised learning 1 In tro duction In human comm unication, a closed-lo op sp eec h chain mechanism has a critical auditory feedback mechanism from the sp eaker’s mouth to her ear [1]. In other w ords, the hearing pro cess is critical not only for the listener but also for the sp eak er. By simultaneously listening and speaking, the s peaker can monitor the v olume, articulation, and general comprehensibility of her speech. Inspired by suc h a mec hanism, we previously constructed a mac hine sp eec h c hain [2] based on deep learning. This architecture enabled ASR and TTS to mutually impro ve their p erformance by teac hing each other. 1 One of the adv antages of using a machine sp eec h chain is the ability to train a mo del based on the concatenation of both lab eled and unlabeled data. F or su- p ervised training with lab eled data (speech-text pair data), b oth ASR and TTS mo dels can b e trained indep enden tly by minimizing the loss of their predicted target sequence and the ground truth sequence. Ho wev er, for unsupervised training with unlab eled or unpaired data (sp eec h only or text only), the tw o mo dels need to supp ort each other through a connection. Our exp erimental results reveal that suc h a connection enabled ASR and TTS to further improv e their p erformance by using only unpaired data. Although this tec hnique could pro vide a significant impro vemen t in model p erformance within a single-sp eak er sp eec h dataset, only a sligh t increase could b e gained in m ulti-sp eak er tasks. Difficulties arise due to the fundamen tal differences in the ASR and TTS mec hanisms. The ASR task is to “extract” data from a large amount of in- formation and only retain the sp ok en conten t (many-to-one mapping). On the other hand, the TTS task aims to “generate” data from compact text informa- tion in to a generated speech w a veform with an arbitrary sp eak ers c haracteristics and sp eaking style (one-to-many mapping). The imbalanced amounts of infor- mation contained inside the text and sp eec h causes information loss inside the sp eec h-c hain and hinders us in p erfectly reconstructing the original speech. T o enable the TTS system to mimic the voices of different sp eakers, we previously only added sp eak er information via a sp eak er’s identit y by one-hot enco ding. Ho wev er, this is not a practical solution b ecause we are still unable to handle unseen sp eak ers. In this pap er, w e prop ose a new approach to handle voice characteristics from an unknown sp eaker and minimize the information loss betw een sp eec h and text inside the speech chain lo op. First, we integrate a sp eak er recognition system in to the sp eec h c hain lo op. Second, we extend the capability of TTS to handle the unseen sp eak er using one-shot sp eak er adaptation. This enables TTS to mimic v oice characteristics from one speaker to another with only a one-shot sp eak er sample, ev en from text without any sp eaker information. In the speech c hain lo op mec hanism, ASR also benefits from furthering learning an arbitrary sp eak ers characteristics from the generated sp eech w av eform. W e ev aluated our prop osed mo del with the well-kno wn W all Street Journal corpus, consisting of m ulti-sp eak er sp eec h utterances that are often used as an ASR b enc hmark test set. Our new sp eec h mechanism is able to handle unseen speakers and improv e the p erformance of b oth the ASR and TTS models. 2 Mac hine Sp eec h Chain F ramew ork Figure. 1 illustrates the new sp eec h c hain mec hanism. Similar to the earlier v ersion, it consists of a sequence-to-sequence ASR [3, 4], a sequence-to-sequence TTS [5], and a loop connection from ASR to TTS and from TTS to ASR. The k ey idea is to join tly train the ASR and TTS mo dels. The difference is that in this new version, we integrate a sp eaker recognition mo del inside the lo op illustrated in Fig. 1(a). As men tioned ab o ve, we can train our mo del on the concatenation of b oth lab eled (paired) and unlabeled (unpaired) data. In the follo wing, we describe the learning pro cess. 1. Paired sp eec h-text dataset (see Fig. 1(a)) Given the sp eec h utter- ances x and the corresp onding text transcription y from dataset D P , b oth 2 Figure 1: Overview of proposed machine speech c hain architecture with speaker recognition; (b) Unrolled process with only speech utterances and no text tran- scription (sp eec h → [ASR,SPKREC] → [text + sp eak er v ector] → TTS → sp eec h); (c) Unrolled pro cess with only text but no corresp onding sp eec h ut- terance ([text + sp eaker v ector by sampling SPKREC ] → TTS → sp eech → ASR → text). Note: gray ed b ox is the original sp eec h chain mechanism. ASR and TTS mo dels can b e trained indep enden tly . Here, w e can train ASR by calculating the ASR loss L P AS R directly with teacher-forcing. F or TTS training, w e generate a sp eak er embedding v ector z = SPKREC( x ), in tegrate z information with the TTS, and calculate the TTS loss L P T T S via teac her-forcing. 2. Unpaired sp eec h data only (see Fig. 1(b)) Given only the speech utterances x from unpaired dataset D U , ASR generates the text transcrip- tion ˆ y (with greedy or b eam-searc h decoding), and SPKREC provides a sp eak er-em b edding v ector z = SPKREC( x ). TTS then reconstructs the sp eec h wa veform ˆ x = T T S ( ˆ y , z ), and given the generated text ˆ y and the original sp eak er vector z via teacher forcing. After that, w e calculate the loss L U T T S b et w een x and ˆ x . 3. Unpaired text data only (see Fig. 1(c)) Given only the text tran- scription y from unpaired dataset D U , we need to sample speech from the av ailable dataset ˜ x ∼ ( D P ∪ D U ) and generate a sp eak er vector ˜ z = SPKREC( ˜ x ) from SPKREC. Then, the TTS generates the speech utterance ˆ x with greedy deco ding, while the ASR reconstructs the text ˆ y = AS R ( ˆ x ), given generated speech ˆ x via teacher forcing. After that, we calculate the loss L U AS R b et w een y and ˆ y . W e combine all loss together and up date b oth ASR and TTS mo del: L = α ∗ ( L P AS R + L P T T S ) + β ∗ ( L U AS R + L U T T S ) (1) θ AS R = O ptim ( θ AS R , ∇ θ AS R L ) (2) θ T T S = O ptim ( θ T T S , ∇ θ T T S L ) (3) where α, β are h yp er-parameters to scale the loss b et ween sup ervised (paired) and unsup ervised (unpaired) loss. 3 3 Sequence-to-Sequence ASR A sequence-to-sequence [6] architecture is a t yp e of neural net work that directly mo dels the conditional probability P ( y | x ) betw een t w o sequences x and y . F or an ASR mo del, w e assume the source sequence x = [ x 1 , .., x S ] is a sequence of sp eec h feature (e.g., Mel-sp ectrogram, MF CC) and the target sequence y = [ y 1 , .., y T ] is a sequence of grapheme or phoneme. The encoder reads source speech sequence x , forwards it through sev eral la yers (e.g., LSTM[7]/GR U[8], conv olution), and extracts high-lev el feature rep- resen tation h e = [ h e 1 , .., h e S ] for the deco der. The deco der is an autoregressiv e mo del that pro duces the curren t output conditioned on the previous output and the enco der states h e . T o bridge the information b et ween deco der states h d t and enco der states h e , we use an attention mechanism [9] to calculate the alignmen t probabilit y a t ( s ) = Alig n ( h e s , h d t ); ∀ s ∈ [1 ..S ] and then calculate the exp ected context v ector c t = P S s =1 a t ( s ) ∗ h e s . Finally , the decoder predicts the target sequence probabilit y p y t = P ( y t | c t , h d t , y
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment