Multiple Instance Deep Learning for Weakly Supervised Small-Footprint Audio Event Detection
State-of-the-art audio event detection (AED) systems rely on supervised learning using strongly labeled data. However, this dependence severely limits scalability to large-scale datasets where fine resolution annotations are too expensive to obtain. …
Authors: Shao-Yen Tseng, Juncheng Li, Yun Wang
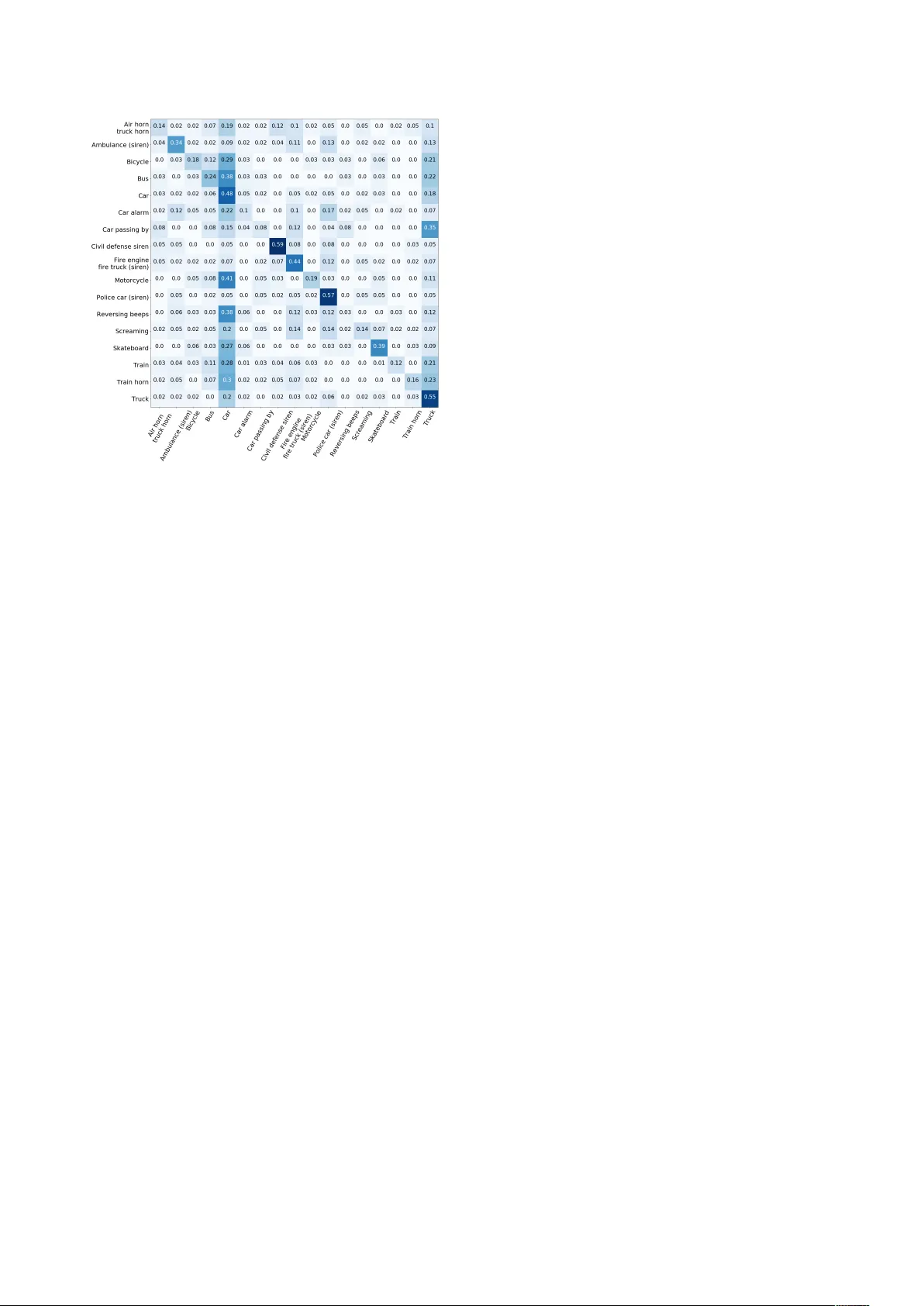
Multiple Instance Deep Learning f or W eakly Supervised Small-F ootprint A udio Event Detection Shao-Y en Tseng † , J uncheng Li ‡ γ , Y un W ang γ , Florian Metze γ , J oseph Szurle y ‡ , Samarjit Das ‡ ‡ Robert Bosch LLC, Research and T echnology Center , USA † Uni versity of Southern California, Department of Electrical Engineering, USA γ Carnegie Mellon Uni versity , Language T echnology Institute, USA shaoyent@usc.edu, { junchenl,yunwang,fmetze } @cs.cmu.edu, { joseph.szurley,samarjit.das } @us.bosch.com Abstract State-of-the-art audio e vent detection (AED) systems rely on supervised learning using strongly labeled data. Howe ver , this dependence se verely limits scalability to large-scale datasets where fine resolution annotations are too expensi ve to obtain. In this paper , we propose a small-footprint multiple instance learn- ing (MIL) framework for multi-class AED using weakly anno- tated labels. The proposed MIL framework uses audio embed- dings extracted from a pre-trained con volutional neural network as input features. W e show that by using audio embeddings the MIL framework can be implemented using a simple DNN with performance comparable to recurrent neural networks. W e ev aluate our approach by training an audio tagging sys- tem using a subset of AudioSet, which is a large collection of weakly labeled Y ouT ube video excerpts. Combined with a late- fusion approach, we improve the F1 score of a baseline audio tagging system by 17%. W e show that audio embeddings ex- tracted by the con volutional neural networks significantly boost the performance of all MIL models. This framework reduces the model complexity of the AED system and is suitable for applications where computational resources are limited. Index T erms : audio e vent detection, weakly-supervised learn- ing, multiple instance learning 1. Introduction Increasingly , de vices in v arious settings are equipped with au- ditory perception capabilities. The inclusion of acoustic signals as an extra modality brings robustness to a system and offers improv ed performance in many tasks. This benefit can be at- tributed to the omnidirectional nature of acoustic signals which provides a valuable cue for detecting events in various applica- tions. F or example, [1] analyzed audio signals to monitor the conditions of industrial tools, and in [2] a water leakage de- tection system using sound recordings of water pipes was pro- posed. Such systems are able to run in real-time and at a lo wer cost as capturing audio is much less expensi ve than distrib uting specialized physical sensors throughout the en vironment. In ad- dition, acoustic signals can provide informational cues that are hard to or cannot be captured by other modalities. A common example is the detection of alarms or sirens in a driving scenario with smart cars. V ery often, sources of these warning sounds may be visually occluded and these ev ents are only detectable using auditory perception [3][4]. Many of these applications also hav e a requirement of real-time operation using low com- putational resources. This is a major challenge si nce, unlike hu- man speech, en vironmental sounds are much more div erse and span a wider range of frequencies. Audio events that occur in these settings are also usually sporadic and corrupted by noise. Previous w orks on AED have relied on training models us- ing a supervised learning paradigm which requires strongly la- beled data [5][6]. Ho wever , giv en the difficulty and high re- source requirement of annotating large datasets there are only a few datasets that are publicly av ailable and are often of lim- ited size [7][8]. Moti vated by this, many recent works have explored the use of weakly labeled data for training AED sys- tems. One successful approach is to transform the audio into time-frequency representations and apply a con volutional re- current neural network to tag or classify the entire clip [9][10]. These methods, howe ver , are unsuitable for real-time applica- tions as the recurrent and subsequent pooling layers require the full clip to be parsed before a decision can be made. In addition, the complexity and computation time of these models are quite high. Another approach for learning with weak labels is to treat segments in an audio clip as a bag of instances and apply mul- tiple instance learning [11]. The MIL model assumes indepen- dent labels for each instance and accounts for the uncertainty of the weak labels by assigning a positiv e bag label only if there is at least one positiv e instance. Evidently , this paradigm is more suitable for portable applications as the classifier can be applied to individual instances which is ideal for real-time operation. In this work, we propose to enhance the framework for multi-class MIL using conv olutional audio embeddings. Differ- ent from prior works, our proposed architecture addresses the issue of b uilding low complexity models with a small footprint for real-time applications. W e propose the use of audio em- beddings as input features and show that by using pre-trained embeddings the MIL model can be implemented with a simple DNN architecture. The use of audio embeddings also signifi- cantly impro ves AED accuracy compared to random initializa- tion. Our proposed architecture removes the need for complex CNN structures or recurrent layers which drastically reduces model complexity and is suitable for portable applications with low computational resource and real-time requirements. 2. Multiple Instance Learning 2.1. MIL Framework The task of detecting audio e vents using weakly labeled training data can be formulated as a multiple instance learning problem [12]. In MIL, labels are assigned to bags of instances without explicitly specifying the relev ance of the label to indi vidual in- stances . All that is known is one or more instances within the bag contrib ute to the bag label. Applying this framew ork to our task, we view audio clip i as a bag of instances B i = { x ij } where each instance x ij is an audio se gment j of shorter dura- tion. W e then assign all the labels of the clip to the bag so that each bag has the label Y i = { y in } where y in = 1 indicates the presence of audio e vent n . The goal of the MIL problem is then to classify labels of unseen bags gi ven only the bag and label pairs ( B i , Y i ) as training data. In this we work we implement the MIL framew ork using neural networks. 2.2. MIL using Neural Networks In our implementation we generate instances by segmenting the audio clip into non-overlapping 1-second segments and taking the time-frequency representations. The segment size was cho- sen as a balance between number of total instances and coverage of audio e vents. W e use a frame size of 25ms with 10ms shift in the short-time Fourier transform and integrate the power spec- trogram into 64 mel-spaced frequency bins. A log-transform is then applied to the spectrogram. W e also use the first delta as an additional input channel. Since the spectrogram can be viewed as an image we em- ploy conv olutional layers for feature extraction. W e reference CNN architectures proven to have good performance in the field of computer vision. Specifically , we use the first three con v groups from VGG-16 [13] and add two fully-connected layers of size 3072 and 1024. Batch normalization is added after each con volutional layer . The ReLU activ ation function is used in all layers. As our goal is a multi-label system we apply a sigmoid activ ation function and view the outputs as independent poste- rior probability estimates for each class. W e use a reduced v er- sion of the full VGG model because (1) we are exploring com- pact models for portable applications and (2) the subset dataset does not contain enough samples to train lar ge models without ov erfitting. T o obtain a prediction for the entire bag we adopt a na ¨ ıve approach and assign the label of the maximum scoring instance to the bag. The moti vation behind this is in part due to the fact that since instances in a continuous audio clip are not i.i.d. many MIL algorithms are not applicable [11]. Howe ver this approach is still beneficial as it allo ws us to train an instance classifier which can be applied in a real-time scenario. Using this approach, the final bag label is obtained using a max pooling layer . That is b Y i = { ˆ y in } = { max j f n ( x ij ) } where f n ( x ij ) is the predicted probability of class n on instance x ij . The multi-class MIL loss can then be defined as simply the cross entropy loss summed ov er all the classes, which is J i = − X n ( y in log ˆ y in + (1 − y in ) log (1 − ˆ y in )) In order to address class imbalance we apply a weight to the MIL loss proportional to the in verse frequency of each class. During back-propagation only the gradient from the maximally scoring instance is calculated and used for updating weights. An interesting fact is that as each class has its o wn max pooling layer , errors originate from different instances between classes. Figure 1 shows the architecture of the proposed MIL framework using CNN. 2.3. MIL using A udio Embeddings Our model infers that for a certain class, the highest scoring instances are most important and contribute directly to the cor - responding bag label. The training of the neural network to … Conv Layers Sigmoid Fully Con. Max pooling Audio segmentation and feature extraction Clip label MAX instance back propagation Y ouTube Audio Clip Shared weights Figure 1: Ar chitectur e of MIL using CNN. Back-pr opagation is performed along the MAX instance for each class. identify these important instances is similar to an expectation maximization (EM) approach. Ho wev er there are two possi- ble issues which may result from this model. The first is that as with most EM methods, system performance highly depends on the initialization point. W ith a bad initialization point the model chooses the wrong instance as being indicative of the class label and optimizes on irrelev ant input. These types of er- rors would be hard to recover from if there is high v ariation for each individual audio ev ent. A second issue is that by using a max pooling layer over all instances back-propagation will only propagate through the maximum scoring instance. This may re- sult in some instances being ignored for most of the training. While this focus on relev ant instances only is the central idea of MIL, it greatly reduces rob ustness to noise which occurs inter- mittently in the audio. W e propose that the use of pre-trained audio embeddings can alleviate the abov e issues. By using au- dio embeddings as features we postulate that audio e vents as well as noise conditions can be better represented which can improv e the performance of the MIL framew ork. Similar to [14] we generate audio embeddings by training a CNN to give frame-wise predictions of the clip label. The in- put features are 128-bin log-mel spectrograms computed ov er 1-second segments of audio by short-time Fourier transform. W e use the clip label as tar gets for all 1-second segments in the audio clip. The outputs from the penultimate layer of the CNN are then extracted and used as input to the MIL framework. W e use the same CNN structure described in the previous section but add an additional fully-connected layer of size 512 to gen- erate the final audio embedding. Since frame-wise training of the instances results in badly labeled data, the final model selec- tion of the embedding CNN is crucial in generating meaningful embeddings. W e use the maximum of frame-wise predictions as the predicted clip label and select the CNN model with the best performance at the clip-lev el using held-out validation data. The final MIL system is similar in architecture to the MIL- CNN but uses audio embeddings as features for each instance. The con volutional layers are replaced with fully-connected lay- ers as we no longer deal with images. The best performing sys- tem has four hidden layers using a ReLU activation function with layer sizes of 512, 512, 256 and 128. The final architec- ture of the MIL framew ork is shown in Figure 2. … Sigmoid Fully Con. Max pooling Clip label Y ouTube Audio Clip Shared weights Embedding CNN Embedding CNN Embedding CNN Audio segmentation and feature extraction Figure 2: Arc hitecture of MIL using audio embeddings. 3. Dataset & Challenges 3.1. Dataset W e ev aluated our models using a subset of Google’ s AudioSet [15]. AudioSet is an extensi ve collection of 10-second Y ouT ube clips annotated over a large number of audio ev ents. This dataset contains 632 audio e vent classes and ov er 2 million sound clips, howev er as a proof of concept we refer to a sub- set released by the DCASE 2017 challenge [16]. The challenge subset contains 17 audio ev ent classes di- vided into two categories : W arning and V ehicle sounds. These audio e vents are highly focused on transportation scenarios and is primed tow ards ev aluating AED systems for self-driving cars, smart cities and related areas. The subset contains 51,172 sam- ples which is around 142 hours of audio. The class names and number of samples per class are shown in T able 1. Class Name Samp # Class Name Samp # W arning Sounds V ehicle Sounds Car alarm 273 Skateboard 1,617 Rev ersing beeps 337 Bicycle 2,020 Air/T ruck horn 407 T rain 2,301 T rain horn 441 Motorcycle 3,291 Ambulance siren 624 Car passing by 3,724 Screaming 744 Bus 3,745 Civil defense siren 1,506 T ruck 7,090 Police siren 2,399 Car 25,744 Fire engine siren 2,399 T able 1: Class labels and number of samples per class. 3.2. Challenges of the Dataset The main challenge of the dataset is the noisiness of Y ouT ube data. As clips are user submitted and mostly recorded using consumer devices in real life environments, audio ev ents are often far-field and corrupted with a variety of noise, including human speech, music, wind noise, etc. Another challenge is the variability of audio events. Ev en within class, the characteristic of an audio ev ent can v ary drastically . An example of this is the use of dif ferent types of sirens by different regions which would make it hard to differentiate between ambulance and fire truck sir ens . In short, it is possible that each label type encompasses all possible global variations of that cate gory . Finally , the number of samples per class is also highly im- balanced in the subset dataset. The imbalance ratio of the least occurring to most occurring class is 1:94. While this issue can be alle viated through machine learning techniques, the inherent shortage of information in minority classes may result in bad generalization of those classes. 4. Experimental Setup and Results In all experiments we used cross entropy as the loss function and the Adam optimizer [17] to perform weight updates. T o handle class imbalance the loss function was weighted inv ersely pro- portional to the number of samples for each class. For model selection of the embedding CNN we adopted a clip-level vali- dation scheme. The posterior class probabilities were averaged ov er all instances in a clip and the model with the best clip tag- ging accuracy was selected to generate audio embeddings. W e compared our MIL frame work to an MLP baseline from the DCASE challenge [16]. The best F1-score achiev ed by our MIL system using a CNN architecture on a two-fold cross-validation setup was 22.4%. Using audio embeddings as features and only a DNN as classifier the performance im- prov ed to 31.4% which is 20.5% absolute improv ement from the DCASE baseline. W e compared to an MIL frame work where the DNN classifier is replaced with a 3-layer Bi-LSTM RNN and found that results were comparable to DNNs. W e also applied late-fusion to models with different hyper-parameters using a weighted majority voting scheme which improv ed the F1-score further to 35.3%. The weights of the voting scheme were based on model v alidation accuracy . Finally , we sho w that the performance of our MIL frame work impro ves to 46.5% us- ing embeddings from AudioSet. These embeddings are part of AudioSet and trained with a CNN architecture from [14] using the Y ouT ube-8M dataset [18]. T able 2 shows the performance and parameter number of the different models. The confusion matrix for the proposed MIL system is shown in Figure 3. Although there is high confusability in the Car class, which may be due to the imbalance of labels, the system is still able to distinguish between classes with relativ e accuracy . Model Prec. Rec. F1 Param # Development set Baseline [16] 7.9 17.6 10.9 13K MIL-CNN 19.6 26.1 22.4 29M MIL-RNN-Embed 23.7 38.1 29.2 6.5M MIL-DNN-Embed 25.4 41.3 31.4 700K Ensemble 28.6 46.0 35.3 - MIL-DNN-AudioSet 41.9 52.2 46.5 700K Evaluation set Baseline [16] 15.0 23.1 18.2 13K Ensemble 31.6 39.7 35.2 - T able 2: Comparisons of pr ecision, recall, F1-scor e (%), and number of parameters for the various models. Figure 3: Confusion matrix for the pr oposed MIL system. 5. Discussion While our framework is not state-of-the-art [19], which achiev es a single-model F1-score of 54.2%, a more fair com- parison would be with models without recurrent layers, such as [20], which has an F1-score of 49.0%. Even so, a direct compar - ison is of limited value as our proposed method mainly aims to address two major issues in deploying AED to real-life scenar- ios: model complexity and real-time operation. Our proposed method reduces model complexity by removing the need of re- current layers and is suitable for applications where computa- tional resources are limited. Under similar performance condi- tions the MIL system using DNN reduces the number of param- eters by a factor of almost 10 compared to a 3-layer Bi-LSTM RNN. In terms of e valuation runtime, the DNN model is also up to 5 times faster than RNNs. The DNN model is able to handle 2,500 samples per second compared to 500 samples with RNN using an NVIDIA GTX-1080 GPU. In addition, by using independent instance classifiers our system is able to run in real-time and giv e running predictions of audio events. This property is crucial when applying AED in smart cars as e vents such as sirens and horns have to be detected as soon as they occur . With recurrent networks or e ven CNNs requiring full length inputs this mode of operation w ould not be possible. Finally , as shown by the gain in performance through the use of AudioSet embeddings, the MIL system can easily be improv ed through transfer learning of other sound events. An interesting observation from our experiments is that joint opti- mization of the pre-trained embedding CNN with the MIL loss did not impro ve performance much abov e random initializa- tion. This shows that audio embeddings already contain rich acoustic information and can be trained in a task-independent manner . The separation of embedding and classifier training means that we can take advantage of additional labels in large- scale weakly-supervised data and learn embeddings indepen- dently . Howe ver , we also observed that selection of the embed- ding model is pi votal in the final system performance and not all embeddings are as useful. 6. Conclusions In this work we proposed a small-footprint multiple instance learning framework using deep neural networks for audio ev ent detection which can be trained using large-scale weakly- supervised data. W e showed that by using pre-trained audio embeddings we can achie ve good performance with a simple DNN model in an MIL frame work. Audio embeddings were ex- tracted from a CNN trained to giv e frame-wise predictions for the weakly labeled data. While the performance of this CNN is poor, the embeddings generated by this model can be used as features to drastically improve the performance of an MIL framew ork. Further improvements were achie ved by using em- beddings from AudioSet which were trained with more data and additional labels. W e postulate that audio embeddings map data into an acoustically meaningful high-dimensional space which is more indicative of audio ev ents. Using these embeddings we can achiev e a good trade-off between model size and perfor- mance. In future work, we hope to apply our model to the entire AudioSet for a truly lar ge-scale weakly-supervised MIL frame- work. W ith the introduction of additional data as well as class labels we expect the audio embeddings to contain richer repre- sentations which can further improv e performance of AED in smart cars. 7. References [1] I. Ubhayaratne, M. Pereira, Y . Xiang, and B. Rolfe, “ Audio sig- nal analysis for tool wear monitoring in sheet metal stamping, ” Mechanical Syst. and Signal Pr ocess. , vol. 85, 2017. [2] S. Seyoum, L. Alfonso, S. J. van Andel, W . Koole, A. Groene we- gen, and N. v an de Giesen, “ A Shazam-like household water leak- age detection method, ” in Pr oc. of the XVIII Int. Conf. on W ater Distribution Syst. (WDSA) , v ol. 185, no. Supplement C, 2016. [3] F . Meucci, L. Pierucci, E. D. Re, L. Lastrucci, and P . Desii, “ A real-time siren detector to improve safety of guide in traffic en- vironment, ” in Proc. of the Eur opean Signal Process. Conf. (EU- SIPCO) , 2008. [4] J. Schr ¨ oder , S. Goetze, V . Gr ¨ utzmacher , and J. Anem ¨ uller , “ Auto- matic acoustic siren detection in traffic noise by part-based mod- els, ” in Pr oc. of the IEEE Int. Conf. on Acoustics, Speech and Signal Pr ocess. (ICASSP) , 2013. [5] J. Portelo, M. Bugalho, I. Trancoso, J. Neto, A. Abad, and A. Ser - ralheiro, “Non-speech audio e vent detection, ” in Pr oc. of the IEEE Int. Conf. on Acoustics, Speech and Signal Pr ocess. (ICASSP) , 2009. [6] O. Dikmen and A. Mesaros, “Sound ev ent detection using non- negati ve dictionaries learned from annotated overlapping e vents, ” in Pr oc. of the IEEE W orkshop on Applications of Signal Process. to Audio and Acoustics (W ASP AA) , 2013. [7] J. Salamon, C. Jacoby , and J. P . Bello, “ A dataset and taxonomy for urban sound research, ” in Pr oc. of the A CM Int. Conf . on Mul- timedia and Expo (ICME) , 2014. [8] A. Mesaros, T . Heittola, and T . V irtanen, “TUT database for acoustic scene classification and sound ev ent detection, ” in Proc. of the Eur opean Signal Process. Conf . (EUSIPCO) , 2016. [9] E. C ¸ akr , G. Parascandolo, T . Heittola, H. Huttunen, and T . V ir- tanen, “Conv olutional recurrent neural networks for polyphonic sound event detection, ” IEEE/ACM T rans. on Audio, Speech, and Language Pr ocess. , vol. 25, no. 6, 2017. [10] K. Choi, G. Fazekas, M. Sandler , and K. Cho, “Con volutional recurrent neural networks for music classification, ” in Proc. of the IEEE Int. Conf. on Acoustics, Speec h and Signal Pr ocess. (ICASSP) , 2017. [11] B. Babenko, “Multiple instance learning: algorithms and applica- tions, ” PubMed/NCBI Article , 2008. [12] A. Kumar and B. Raj, “ Audio event detection using weakly la- beled data, ” in Pr oc. of the ACM Conf. on Multimedia (MM) , 2016. [13] K. Simonyan and A. Zisserman, “V ery deep con volutional net- works for large-scale image recognition, ” arXiv pr eprint , vol. abs/1409.1556, 2014. [14] S. Hershey , S. Chaudhuri, D. P . W . Ellis, J. F . Gemmeke, A. Jansen, C. Moore, M. Plakal, D. Platt, R. A. Saurous, B. Sey- bold, M. Slaney , R. W eiss, and K. W ilson, “CNN Architectures for Large-Scale Audio Classification, ” in Pr oc. of the IEEE Int. Conf. on Acoustics, Speech and Signal Pr ocess. (ICASSP) , 2017. [15] J. F . Gemmeke, D. P . W . Ellis, D. Freedman, A. Jansen, W . Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “ Audio set: An ontology and human-labeled dataset for audio events, ” in Pr oc. of the IEEE Int. Conf. on Acoustics, Speech and Signal Process. (ICASSP) , 2017. [16] R. Badlani, A. Shah, and B. Elizalde, “DCASE 2017 challenge setup: T asks, datasets and baseline system, ” DCASE2017 Chal- lenge, T ech. Rep., 2017. [17] D. P . Kingma and J. Ba, “ Adam: A method for stochastic opti- mization, ” arXiv pr eprint , vol. abs/1412.6980, 2014. [18] S. Abu-El-Haija, N. Kothari, J. Lee, P . Natsev , G. T oderici, B. V aradarajan, and S. V ijayanarasimhan, “Y outube-8m: A large-scale video classification benchmark, ” arXiv preprint , vol. abs/1609.08675, 2016. [19] Y . Xu, Q. K ong, W . W ang, and M. D. Plumbley , “Large-scale weakly supervised audio classification using gated conv olutional neural network, ” arXiv pr eprint , vol. abs/1710.00343, 2017. [20] S.-Y . Chou, J.-S. Jang, and Y .-H. Y ang, “FrameCNN: A weakly- supervised learning framework for frame-wise acoustic event de- tection and classification, ” DCASE2017 Challenge, T ech. Rep., September 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment