Linear networks based speaker adaptation for speech synthesis
Speaker adaptation methods aim to create fair quality synthesis speech voice font for target speakers while only limited resources available. Recently, as deep neural networks based statistical parametric speech synthesis (SPSS) methods become dominant in SPSS TTS back-end modeling, speaker adaptation under the neural network based SPSS framework has also became an important task. In this paper, linear networks (LN) is inserted in multiple neural network layers and fine-tuned together with output layer for best speaker adaptation performance. When adaptation data is extremely small, the low-rank plus diagonal(LRPD) decomposition for LN is employed to make the adapted voice more stable. Speaker adaptation experiments are conducted under a range of adaptation utterances numbers. Moreover, speaker adaptation from 1) female to female, 2) male to female and 3) female to male are investigated. Objective measurement and subjective tests show that LN with LRPD decomposition performs most stable when adaptation data is extremely limited, and our best speaker adaptation (SA) model with only 200 adaptation utterances achieves comparable quality with speaker dependent (SD) model trained with 1000 utterances, in both naturalness and similarity to target speaker.
💡 Research Summary
This paper addresses the problem of speaker adaptation for neural network‑based statistical parametric speech synthesis (SPSS), focusing on scenarios where only a very limited amount of target‑speaker data is available. The authors build upon a multi‑task DNN‑BLSTM acoustic model that predicts mel‑cepstral coefficients, log‑F0, band‑aperiodicities and voiced/unvoiced flags from 753‑dimensional linguistic features. To adapt this model to a new speaker, they insert linear networks (LN) at multiple positions within the source network and fine‑tune these LNs together with the output linear layer. Three types of LN are considered—Linear Input Network (LIN), Linear Hidden Network (LHN) and Linear Output Network (LON)—but the final configuration that yields the best results places an LN before the last hidden BLSTM layer and another LN directly before the output layer.
A key challenge with full‑rank LN (Full‑LN) is the large number of speaker‑specific parameters (k² for a layer of size k), which leads to severe over‑fitting when adaptation data is scarce. To mitigate this, the authors propose a Low‑Rank Plus Diagonal (LRPD) decomposition of the LN transformation matrix:
Wₛ ≈ D + U·V,
where D is a fixed identity diagonal matrix, U ∈ ℝ^{k×r} and V ∈ ℝ^{r×k} with r ≪ k (r = 10 in the experiments). This reduces the parameter count to k·(2r + 1), roughly an 80 % reduction compared with Full‑LN, while preserving most of the expressive power needed for speaker characteristics. The LRPD‑LN is trained from random initialization; the authors also experimented with initializing from a decomposed Full‑LN but found no significant difference.
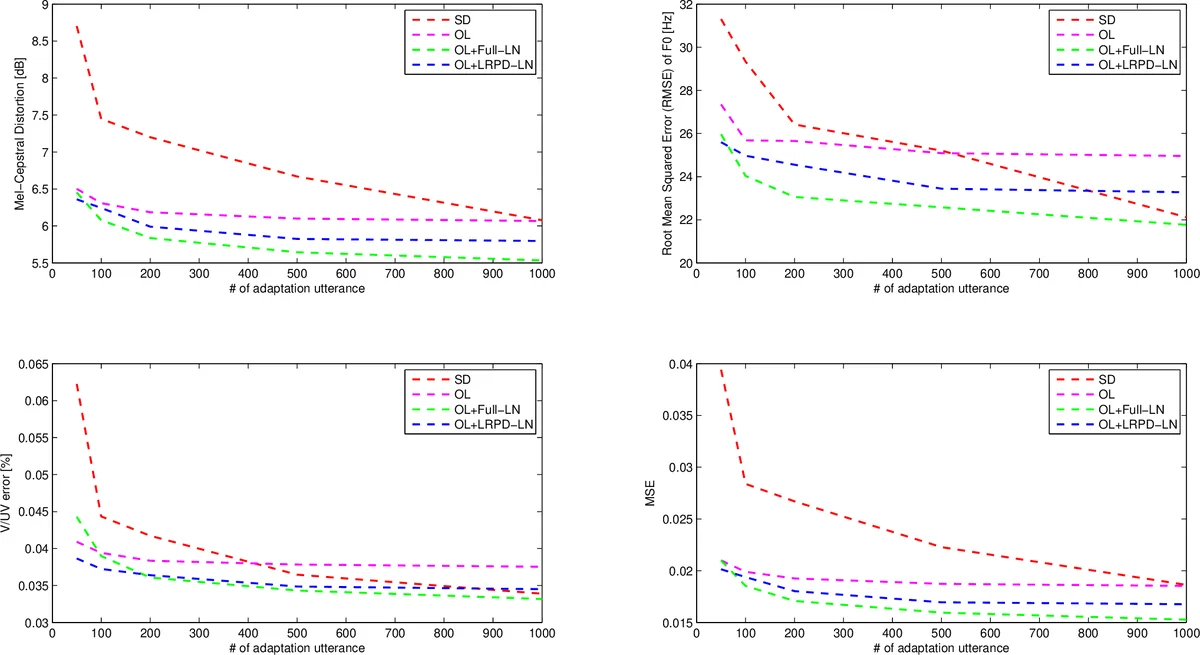
Experiments were conducted on a Mandarin corpus comprising three native speakers (male A, female B, female C), each with about 5 000 utterances. Adaptation scenarios covered: (1) female‑to‑female (similar speakers), (2) male‑to‑female, and (3) female‑to‑male (cross‑gender, more challenging). For each target speaker, adaptation data varied from 50 to 1 000 utterances; 200 utterances were held out for validation and 20 for listening tests. Baselines included a speaker‑dependent (SD) model trained on the same amount of target data, and a simple output‑layer fine‑tuning (OL) approach.
Objective metrics (Mel‑Cepstral Distortion, F0 RMSE, V/UV error, overall MSE) showed that all adaptation methods improve with more data, but LRPD‑LN consistently outperforms Full‑LN when the adaptation set is ≤ 100 utterances, avoiding the over‑fitting observed with Full‑LN. With ≥ 200 utterances, Full‑LN begins to catch up and surpasses LRPD‑LN at around 500 utterances, reflecting its higher capacity when sufficient data is present.
Subjective evaluations used Mean Opinion Score (MOS) for naturalness and similarity (5‑point scale). The findings mirror the objective results: (i) OL alone yields modest improvements; (ii) adding LN (both Full‑LN and LRPD‑LN) dramatically boosts both naturalness and similarity; (iii) LRPD‑LN is markedly more stable than Full‑LN in low‑resource conditions, delivering MOS scores comparable to the SD model trained on ten times more data (e.g., 200 adaptation utterances with LRPD‑LN ≈ SD with 1 000 utterances). In cross‑gender adaptation, the same trends hold, confirming the method’s robustness across speaker distance.
The paper concludes that (1) inserting linear networks at strategic layers and jointly fine‑tuning them with the output layer provides a powerful and efficient adaptation mechanism for neural TTS; (2) LRPD decomposition is essential for preventing over‑fitting when adaptation data is extremely limited, reducing the speaker‑specific parameter footprint without sacrificing quality; (3) the proposed approach enables high‑quality voice creation with as few as 200 utterances, a practical solution for commercial TTS services that need to add new voices quickly and cost‑effectively. Future work may explore dynamic rank selection, multi‑speaker joint training, or integration with other speaker‑embedding techniques (e.g., i‑vectors, speaker codes) to further enhance adaptation performance.
Comments & Academic Discussion
Loading comments...
Leave a Comment