Can we steal your vocal identity from the Internet?: Initial investigation of cloning Obamas voice using GAN, WaveNet and low-quality found data
Thanks to the growing availability of spoofing databases and rapid advances in using them, systems for detecting voice spoofing attacks are becoming more and more capable, and error rates close to zero are being reached for the ASVspoof2015 database.…
Authors: Jaime Lorenzo-Trueba, Fuming Fang, Xin Wang
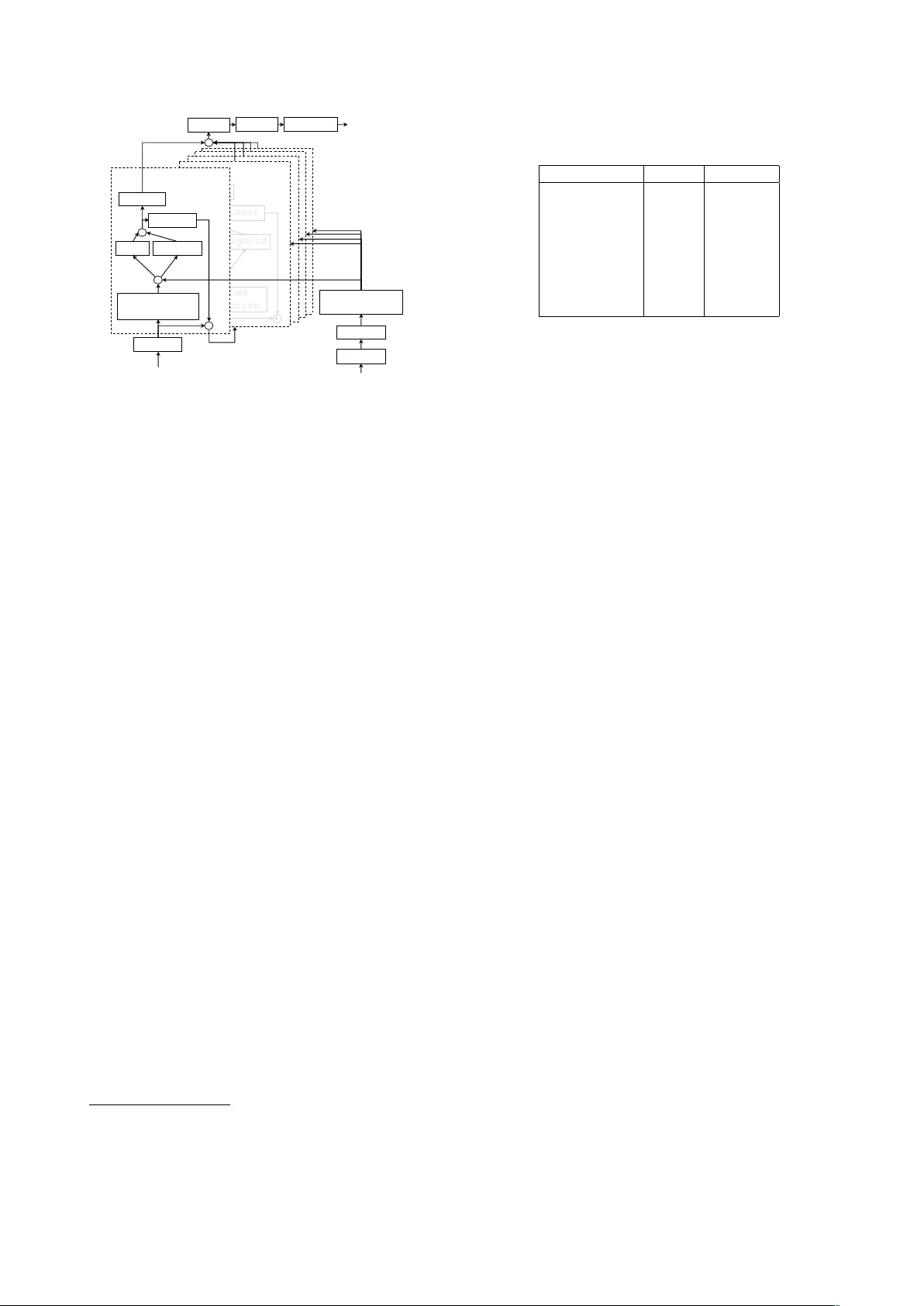
Can we steal y our vocal identity fr om the Inter net?: Initial in v estigation of cloning Obama’ s v oice using GAN, W a veNet and lo w-quality f ound data J aime Lor enzo-T rueba 1 , Fuming F ang 1 , Xin W ang 1 , Isao Echizen 1 , J unichi Y amagishi 1 , 2 , T omi Kinnunen 3 1 National Institute of Informatics, T okyo, Japan 2 Uni versity of Edinb urgh, Edinb ur gh, UK 3 Uni versity of Eastern Finland, Joensuu, Finland { jaime, fang, wangxin, iechizen, jyamagis } @nii.ac.jp, tkinnu@cs.uef.fi Abstract Thanks to the growing av ailability of spoofing databases and rapid advances in using them, systems for detecting voice spoofing attacks are becoming more and more capable, and error rates close to zero are being reached for the ASVspoof2015 database. Howe ver , speech synthesis and voice con version paradigms that are not considered in the ASVspoof2015 database are appearing. Such examples include direct wa veform modelling and generative adversarial networks. W e also need to inv estigate the feasibility of training spoofing systems using only low-quality found data. For that purpose, we dev eloped a generative adversarial network- based speech enhancement system that improv es the quality of speech data found in publicly av ailable sources. Using the enhanced data, we trained state-of-the-art text-to-speech and voice conv ersion models and evaluated them in terms of perceptual speech quality and speaker similarity . The results show that the enhancement models significantly improv ed the SNR of low-quality degraded data found in publicly av ailable sources and that they significantly improved the perceptual cleanliness of the source speech without significantly degrading the naturalness of the voice. Howe ver , the results also show limitations when generating speech with the low-quality found data. 1. Introduction ASVspoof2015 [1] is a commonly used database for de veloping and e valuating methods for preventing spoofing of automatic speaker verification (ASV) systems. Recent studies hav e shown very good spoofing detection rates for the ASVspoof2015 corpus with equal error rates (EERs) close to zero [2]. Howe ver , with recent adv ances in te xt-to-speech (TTS) and voice con version (VC) techniques in the speech synthesis field, it has become clear that the TTS and VC systems included in the corpus are out of date. Good examples of state-of-the-art speech synthesis techniques include direct wa veform modeling [3, 4, 5] and generativ e adversarial networks (GANs) [6]. In a recent study [7], speech synthesized using an end-to-end direct wa veform model was rated as natural as human speech. A preliminary study showed that direct wav eform models do not fool speaker recognition systems; ho wev er , Mel-spectra generated by a GAN hav e successfully fooled a speaker recognition system [8] 1 . 1 But the experiment was not f air as the attackers had knowledge of the features used in the recognition system and directly input generated features to the system, which are impractical assumptions. One drawback of the studies using the ASVspoof2015 corpus is that they used an unrealistic assumption: only studio-recorded speech was used for generating spoofing materials. If we think of more potential spoofing scenarios, it is reasonable to expect attacks using unwillingly obtained speech (i.e., recordings made in non-controlled environments). This motiv ated us to study the feasibility of training a speech enhancement system by obtaining publicly available data and then using tools to enhance the speech quality of the found data with the aim of creating reasonable state-of-the-art spoofing TTS or VC materials. In the case of using publicly a v ailable found data for generating spoofed speech, it is easy to understand that there are large amounts of speech data in publicly av ailable sources and that it is likely that data for almost anybody can be found one way or another . If we are talking about public personalities like President Barack Obama (a common target for identity theft research [9, 10]), the amount of data publicly av ailable is immense. Such data is commonly recorded in non-professional acoustic en vironments such as homes and offices. Moreov er , the recordings are often made using consumer devices such as smartphones, tablets, and laptops. Therefore, the speech portions of the recordings are typically of poor quality and contain a large amount of ambient noise and room rev erberation. Howe ver , applications de veloped for speaker adaptation of speech synthesis and for voice con version hav e been normally designed to work only on clean data with optimal acoustic quality and properties. Therefore, the quality of systems trained using data found in publicly av ailable sources is unknown. Our specific objectiv e was to answer two questions. First, how well can we train a speech enhancement system to enhance low-quality data found in publicly a vailable sources? Second, can we use such enhanced data to produce effecti ve spoofing materials using the best av ailable TTS and VC systems? 2. GAN-based speech enhancement Generativ e adversarial networks consist of two “adversarial” models: a generative model G that captures the data distribution and a discriminativ e model D that estimates the probability that a sample came from the training data rather than G . This GAN structure has been used to enhance speech [11, 12]. In the research reported here, we worked on improving the speech enhancement generati ve adversarial network (SEGAN) [11]. More specifically , we attempted to make the training process more robust and stable by introducing a modified training strategy for SEGAN’ s generator . 2.1. SEGAN-based speech enhancement SEGAN [11] exploits the generati ve adversarial structure in a particular fashion. The speech enhancement itself is carried out mainly by using model G , which follows an encoder-decoder structure that takes noisy speech as an input and produces enhanced speech as the output, similar to the U-net architecture used in the pix2pix framework [13]. The function of model D is to determine, during training, whether the enhanced speech is detected as fake (enhanced) or real (clean). If model D can be fooled by the enhanced speech, there is no gradients through model G . On the other hand, if model D cannot be fooled by the enhanced speech, the gradient is back-propagated through the model G and update it in order to fool the model D , thus biasing the structure tow ards producing enhanced speech closer to the clean speech. W e found that the SEGAN structure is sensiti ve to noise variations during training, making con vergence difficult. W e thus made two modifications to achie ve more robust training. For the first one, we created some pre-trained baseline speech enhancement models (which may be simpler signal processing methods or easier-to-train neural networks than GANs). They are used to enhance the speech, and then the content loss of the initial iterations of the generator model is computed on the basis of the baseline enhanced speech instead of on clean speech. For the second modification, a skip connection was added around the generator so that its task is not to generate enhanced speech from scratch b ut to generate a residual signal that refines the input noisy speech [6]. This should encourage the generator to learn the detailed differences between clean and enhanced speech wa veforms. 3. Speech Corpora W e used two types of speech corpora. The corpora used to train the speech enhancement module were constructed using publicly av ailable data so that the training process would be replicable. The corpus used as the source for the cloned voice was constructed using a number of President Barack Obama’ s public interventions obtained from v arious sources. 3.1. Corpora f or speech enhancement training For training the speech enhancement module, we used a subset (28 speakers; 14 male and 14 female; British accent; 400 utterances per speaker) of the Centre for Speech T echnology Research (CSTR) voice cloning toolkit (VCTK) corpus 2 [14] as the clean speech corpus. W e used different noisy iterations of this corpus to create four additional corpora for use in making the speech enhancement signal rob ust against noisy and/or reverberant en vironments (see table 3). These corrupted corpora were recorded as a collaboration between CSTR and the National Institute of Informatics of Japan and are publicly av ailable in the DataShare repository of the Uni versity of Edinbur gh. 3.1.1. Device-r ecorded VCTK corpus T o create the device-recorded (DR) VCTK corpus 3 [15] we re-recorded the high-quality speech signals in the original VCTK corpus by playing them back and recording them 2 http://datashare.is.ed.ac.uk/handle/10283/1942 3 https://datashare.is.ed.ac.uk/handle/10283/2959 T able 1: Corpora for speech enhancement training. Corpus Name Abbrev . #Files T otal Time VCTK clean 11572 8h54m56s Noisy VCTK n 11572 8h54m56s Rev erberant VCTK r 11572 8h54m56s Noisy Rev erberant VCTK nr 11572 8h54m56s Device Recorded VCTK DR 11572 8h54m56s T able 2: Characterization of the used Obama’ s found data. Sources Public speeches, interviews... T otal length (w . silence) 3h 7m 39s Minimum segment duration 0.54s Maximum segment duration 24.4s A verage segment duration 5.4s Estimated SNR mean 17.15 dB Estimated SNR variance 171.22 dB in of fice en vironments using relativ ely inexpensi ve consumer devices. This corpus enables our speech enhancement system to learn the nuanced relationships between high quality and device-recorded versions of the same audio. Eight different microphones were used simultaneously for the re-recording, which was carried out in a medium-sized office under two background noise conditions (i.e., windo ws either opened or closed). This resulted in 16 different conditions. 3.1.2. Noisy , Reverber ant, and Noisy and re verberant VCTK corpora W e used three other artificially corrupted v ariations of the CSTR VCTK corpus: Noisy VCTK 4 [16, 17], Rev erberant VCTK 5 [18], and Noisy and re verberant VCTK 6 [19]. This div erse portfolio of possible speech corruptions enables our speech enhancement system to learn how to target different possibilities, i.e., plain noisy , rev erberation compensation, and a mixture of both. As mentioned above, all the corpora are based on the CSTR VCTK corpus, so the speakers and utterances represented in the Edinburgh noisy speech dataset are similar to those of the DR-VCTK corpora. 3.2. Obama’ s found data Obama’ s data was found online, mainly in Y ouT ube videos with transcriptions as part of the description and from div erse sources such as intervie ws and political meetings. The recording conditions and environments were diverse, ranging from very noisy with lar ge amounts of re verberation to not so noisy or not so rev erberant, and nev er achie ving recording studio standards. The audio channel was split from the video channel, automatically segmented on long pauses, and down-sampled to 16 kHz. The transcription was copied over as a text file. T able 2 shows a brief characterization of the data. A histogram of the signal-to-noise ratio (SNR) in dB, estimated using the NIST SNR measurement tool 7 is shown in figure 1. It is evident that the vast majority of the speech signals had a very low SNR compared with con ventional speech generation corpus standards. For instance, the mean and variance of the SNRs estimated for the VCTK corpus were 4 https://datashare.is.ed.ac.uk/handle/10283/2791 5 https://datashare.is.ed.ac.uk/handle/10283/2031 6 https://datashare.is.ed.ac.uk/handle/10283/2826 7 https://www .nist.gov/information-technology- laboratory/iad/mig/nist-speech-signal-noise-ratio-measurements Estimated SNR of Obama' s found data Estimated SNR (dB) Frequency 0 10 20 30 40 50 60 0 200 400 600 Figure 1: SNR histogram of original Obama’ s found data. T able 3: Data sources used for training speech enhancement model. (See table 1 for the meanings of the abbreviations.) SOURCES #Files T otal Time DR 11572 8h54m56s n 11572 8h54m56s r 11572 8h54m56s nr 11572 8h54m56s DR+n 23144 17h49m52s DR+nr 23144 17h49m52s All (DR+n+r+nr) 46288 35h39m44s 30.19 and 23.73 dB, respecti vely , whereas those of the data used as the source for the cloned voice were 17.15 and 171.22 dB. 4. Enhancing Obama’ s found data As mentioned above, the aim of this research was to create reasonable state-of-the-art spoofing TTS or VC materials. More specifically , we aimed to train a waveform generation model that can replicate the target speak ers v oice, in this case, the very recognizable voice of President Barack Obama. Moreover , the training should be done using only easily av ailable low-quality resources, as explained in section 3.2. But that kind of data is generally too poor to ensure reasonably good training of speech synthesis systems. W e thus de veloped a generative adversarial network-based speech enhancement system for improving lo w- quality data to the point where it can be used to properly train TTS systems. 4.1. Design of the speech enhancement models As we had a large amount of free, publicly available resources for training our speech enhancement system, we did testing to determine the best training regime strategy . W e trained our speech enhancement system using se ven different sources with various amounts of data, as summarized in table 3. Our motiv ation for using three single-category sources and four combinations was our expectation that training using each single-category source would work well for the corresponding type of disturbance (i.e., training using source “n” should be good for cleaning noise, “r” should be good for cleaning rev erberation, and “DR” should be good for compensating for low-quality recording de vices). Since most of the data found will come from noisy poor -quality sources, it made sense to combine “DR” with the dif ferent noisy corpora. Moreov er , since having as much v aried data as possible helps neural networks generalize better , the combination of all the corpora should also be effecti ve. T able 4: A verage SNR in dB estimated with NIST tool for the results of the different speech enhancement models. SOURCES av erage SNR (dB) Obama source 17.2 n 49.8 r 22.7 nr 43.1 DR 28.24 DR+n 40.1 DR+nr 41.37 all (DR+n+r+nr) 37.89 4.2. T raining of the speech enhancement models Similar to the original SEGAN training strategy , we extracted chunks of wav eforms by using a sliding window of 2 14 samples at ev ery 2 13 samples (i.e., 50% overlap). At testing time, we concatenated the results at the end of the stream without ov erlapping. For the last chunk, instead of zero padding, we pre-padded it with the pre vious samples. For batch optimization, RMSprop with a 0.0002 learning rate and a batch size of 100 was used. The modified SEGAN model conv erged at 120 epochs. For selecting the pre-enhancement method, we conducted preliminary experiments, using the Postfish [20] and the HRNR [21]. Their sequential use enhanced the quality of the samples, so we used this compound method to generate the baseline models described in section 2.1. The source code and extended documentation for the SEGAN implementation are av ailable online 8 . 4.3. Objective e valuation of the speech enhancement After the speech enhancement models were trained, they were applied to the noisy data. The effect of the enhancement process was evaluated by estimating the SNR once again using the NIST tool. Although SNR is most likely not the best measure of enhancement, the lack of a clean reference limited the av ailability of tools. The SNR estimation results (table 4) show a clear picture: the enhancement process, regardless of which training data were used, improv ed the average SNR of the original Obama voice data. In particular , training using noisy data (i.e., “n”, “nr”, and their mixtures) was considerably more effecti ve than training using the other two possibilities (i.e., “r” and “DR”). This is attributed to the fact that their use reduces the noise lev els in the signal, which is what the SNR measure targets. Their use may not actually improv e the perceptual quality of the voice signals. Histograms showing the improvement in SNR when “n” and when all the v ariants were used are shown in figures 2 and 3 respectiv ely . 4.4. Per ceptual evaluation of the speech enhancement As mentioned in the previous section, SNR is most likely not the best measure of enhancement. Since the ultimate objective of our research is to produce high quality synthetic speech, be it through speech synthesis or through voice con version, it makes sense to ev aluate perceptual quality from the viewpoint of human users. W e thus carried out a cro wdsourced perceptual ev aluation with Japanese native listeners. W e presented the listeners with a set of 16 screens, each corresponding to one of the eight evaluated conditions (original plus seven enhanced versions) for one of two utterances. The ev aluators were given 8 https://github .com/ssarfjoo/improvedse gan Estimated SNR of Obama' s found data enhanced with the n corpus Estimated SNR (dB) Frequency 0 20 40 60 80 0 100 300 500 Figure 2: SNR histogram of original Obama v oice data after enhancement using noisy VCTK. Estimated SNR of Obama' s found data enhanced with all the corpora Estimated SNR (dB) Frequency 0 20 40 60 80 0 100 200 300 400 Figure 3: SNR histogram of original Obama v oice data after enhancement using all VCTK variants. two tasks: 1) rate the percei ved quality of each speech sample on a MOS scale and 2) rate the cleanliness of each speech sample (i.e., free from noise, re verberation, and artifacts), also on a MOS scale (with 1 being very noisy speech and 5 being clean speech). The participants were able to listen to each speech sample as many times as they wanted, b ut they could not proceed to the next sample until they completed both tasks. They were not allowed to return to previous samples. The samples were selected on the basis of their length, ev aluating in the all the utterances (i.e., 530 utterances) between 5.0 and 5.9 seconds long. In total this meant that 265 sets for ev aluating all the ev aluation utterances, which was done 3 times for a total of 795 sets. The participants were allowed to repeat the ev aluation up to 8 times, thereby ensuring that there were at least 100 different listeners. A total of 129 listeners took part in the e valuation (72 male, 57 female). 4.4.1. Results The results of the perceptual e valuation (table 5) also show a clear picture. For the original Obama voice data, there was a clear perception of noisiness and related factors (MOS score of 2.42 for cleanliness) e ven though the percei ved quality was reasonably high (3.58). Studio recorded clean speech is normally rated 4.5 on a verage [22], whereas the original Obama voice data was rated 3.5, that is, one point less, most likely due to the poor conditions on which these sources were recorded. Use of the enhanced versions, improved the cleanliness of the source data, with different degrees of improv ement depending on the source data used. Most noteworthy is the T able 5: Results of the perceptual evaluation (MOS score). Non-statistically significant differences are mark ed with *. SOURCES Quality Cleanliness Obama source 3.58* 2.42 n 2.73 3.35 r 3.55* 3.17 nr 3.11 3.42* DR 3.51 3.31 n+DR 3.26 3.02 nr+DR 3.30 3.34 all (n+r+nr+DR) 3.41 3.40* cleanliness result for “noisy-rev erberant” (3.42), which had the largest impro vement. This is attributed to the original data being recorded mostly in noisy en vironments with reverberation, so a speech enhancement system targeting this condition giv es the best improvement in that field. The cleanliness result for “all” was similarly high, which we attribute to the training being done for all possible situations. On the other hand, there was a cost to applying these speech enhancements: a consistent degradation in the percei ved speech quality . This implies that speech enhancement focused on cleanliness can greatly reduce the naturalness of the speech. This means that the approaches providing the biggest improv ements in SNR, such as the “noisy” condition with a quality score of 2.73 or the “noisy-reverberant” condition with a quality score of 3.11, may not be the best way to produce clean speech for further speech processing. In short, there seems to be a trade-off between quality degradation and cleanliness improvement, which is not encouraging. But, if we look at the results for the ”all” condition, combining all possible data sources, we see that it provided one of the best cleanliness scores (3.40) with one of the smallest quality degradations (0.17 degradation). This strongly suggests that having trained our speech enhancement system in a variety of degradation conditions ga ve the system enough generalization capability and enough kno wledge of human speech to reduce noisiness while maintaining as much as possible voice naturalness. 5. Generation of the synthetic samples W e used two approaches to generate spoofed speech wa veforms: CycleGAN [23] for VC (section 5.1) and an autoregressi ve (AR) neural network for TTS acoustic modeling (section 5.2). While both approaches generate mel- spectrograms, CycleGAN con verts the mel-spectrogram from a source speaker into a mel-spectrogram that retains the speech contents and overlays the voice characteristics of the target speaker . In contrast, the AR approach con verts the linguistic features extracted from text into the mel-spectrogram of the target speaker . Gi ven the generated mel-spectrogram for the target speaker , the W aveNet neural network generates the speech wav eforms (section 5.3). The process for generating spoofed speech is illustrated in figure 4. The decision to use the mel-spectrogram as the acoustic feature was based on the expected limitations of traditional features (e.g., F0, Mel-generalized cepstrum, and aperiodicity bands) as the estimation of F0 is problematic in both the original noisy speech signals and the enhanced signals when considering the noisy data we found. W e also used an increased number of mel bands compared to other approaches [7] (80 vs. 60) with the expectation that it would help the wav eform model better Uni - LSTM Bi - LSTM FF Tanh FF Tanh Linguistic features Linear FF Tanh FF Tanh + + linear Mel - spectro gram Random dropout Time delay 1 time step CycleGAN AutoRegressive acoustic model Mel - spectrogram Of source speaker Linguistic features from text WaveNet Mel - spectrogram Speech waveform Figure 4: Process for generating spoofed speech. Dilated convolution + Tanh Sigmoid * e t 1 linear e t 2 l t h t g t y 0 t y 00 t + s (1) t r (1) t linear FF 4 layers T/F? D Y FF 4 layers T/F? D X G F X b Y Y FF 4 layers b X FF 4 layers OR OR Forward Backward Figure 5: Diagram of CycleGAN. G and F are generators; D X and D Y are discriminators. X and Y are real distrib utions, and ˆ Y and ˆ X represent the corresponding generated distributions. ‘FF’ means feed-forward neural network. cope with corrupted or noisy segments. 5.1. VC based on CycleGAN CycleGAN was originally dev eloped for unpaired image-to- image translation, which consists of two generators ( G and F ) and two discriminators ( D X and D Y ), as shown in figure 5. Generator G serves as a mapping function from distribution X to distrib ution Y , and generator F serves as a mapping function from Y to X . The discriminators aim to estimate the probability that a sample came from real data x ∈ X (or y ∈ Y ) rather than from the generated sample ˆ x = F ( y ) (or ˆ y = G ( x ) ). As shown in the same figure, CycleGAN has two translation directions: forwar d ( X → ˆ Y → ˆ X ) and backwar d ( Y → ˆ X → ˆ Y ). This means that X to Y translation and Y to X translation can be learned simultaneously . Furthermore, an input is carried back to its original form through each translation direction and thereby minimizing consistency loss: L cyc ( G, F ) = E x ∼ p data ( x ) [ k F ( G ( x )) − x k 1 ] + E y ∼ p data ( y ) [ k G ( F ( y )) − y k 1 ] , (1) where E is the expectation and k · k 1 is the L1 norm. W ith this structure, it is possible to keep part of the information unchanged when an input is translated by G or F . When applying this model to VC, X and Y can be thought of as the feature distribution of the source speaker and that of the target speaker, respectiv ely . By reconstructing the input data, linguistic information may be retained during translation. Additionally , speaker individuality can be changed by adversarial learning using an adversarial loss [24]. By integrating consistenc y loss and adversarial loss, we can learn a mapping function for VC using a non-parallel database [25]. T o train a CycleGAN-based VC system, we used a female speaker (Japanese-English bilingual) as the source speaker . Her speech was recorded in a studio. The target speaker Uni - LSTM Bi - LSTM FF Tanh FF Tanh Linguistic features Linear FF Tanh FF Tanh + + linear Mel - spectro gram Random dropout Time delay Figure 6: AR neural network for TTS acoustic modeling. FF T anh and Linear denote feedforward layers with T anh and identity activ ation function, respectively . Bi-LSTM and Uni- LSTM denote bi-directional and uni-directional LSTM layers. The “T ime delay” block keeps the Mel-spectrogram for frame n and sends it to the Uni-LSTM at frame n + 1 . was President Barack Obama 9 . Both his original voice data and the enhanced data with SNR > 30 dB (9240 utterances) were used. In accordance with the source speaker’ s data sets, we implemented three VC systems: one using 611 Japanese utterances, one using 611 English utterances, and one using a mixture of Japanese and English utterances. The generator and discriminator of the CycleGAN were a fully connected neural network with six layers. A 240-dimension vector consisting of a 80-dimension mel-spectrogram and the first and second deriv atives were input into the CycleGAN. There were 256, 512, 512, and 256 units in the hidden layers. A sigmoid was used as the activ ation function. Batch normalization [26] was conducted for each hidden layer of the generators. The batch size and learning rate for the generators and discriminators were randomly selected 128 and 4096 frames and 0.001 and 0.0001, respectiv ely . 5.2. TTS acoustic modeling based on AR neural network An acoustic model for TTS conv erts the linguistic features extracted from a text into acoustic features such as a mel- spectrogram. Specifically for this work, giv en a sequence of linguistic feature l 1: N = { l 1 , · · · , l N } of N frames, an acoustic model needs to generate a sequence of acoustic features a 1: N = { a 1 , · · · , a N } with the same number of frames. Here, l n and a n denote the linguistic features and the mel-spectrogram for the n -th frame. The AR neural network illustrated in figure 6 was used to con vert l 1: N into a 1: N . This network has two feedforward layers and a bi-directional long-short-term-memory (LSTM) unit recurrent layer near the input side. Following these three layers, it uses another uni-directional LSTM layer . Different from the first LSTM layer , this one not only takes the output of the previous layer but also the pre vious output of the whole network as input. For example, it takes a n − 1 as input when it generates a n for the n -th frame. This type of data feedback is widely used in neural text generation and machine translation [27, 28], and a network with this type of feedback loop is referred to as an autoregressiv e model. Note that, while the natural a n − 1 from the training set is fed back during training, the generated b a n − 1 is fed back during generation. Also note that a simple trick is used here that impro ves network performance: it is to randomly drop out the feedback data in both the training and generation stages [29]. The linguistic features used for both training and synthesis 9 Audio samples are available at https://fangfm.github. io/crosslingualvc.html Dilated convolution + Tanh Sigmoid * Linear + Linear WaveNet block Dilated convolution + Tanh Sigmoid * Linear + Linear Linear … + Linear softmax Linear waveform Waveform (delayed by 1 step) Bi - LSTM CNN Mel - spectrogram Up - sampling to 16kHz Figure 7: Structure of W aveNet vocoder . Each W av eNet block is surrounded by dotted line. Details of first W aveNet block are shown. were extracted using Flite [30]. The dimension of these feature vectors was 389. The alignment information was obtained using forced alignment with a hidden-semi Markov model trained using HTS [31] on the mel-spectrograms. In addition to the linguistic features, a numeric variable characterizing the enhancement condition was used as input. T ogether with the input features, the network was trained using the mel-spectrograms obtained with the enhanced speech method explained in section 4. The dropout rate was set to 25%. 5.3. W av eNet vococder Building a state-of-the-art data-driven v ocoder such as W aveNet represents a big challenge when trying to use the types of data we found: it is not easy to gather sufficient data that are good enough for the process. This is where the advantage of having used another data-driv en speech enhancement system comes into play . As hinted at in the introduction to section 4, we can take advantage of our GAN-based speech enhancement system to generate multiple enhanced versions of the noisy speech data, effecti vely multiplying the amount of training data av ailable for training our system. For this research, we trained our W aveNet vocoder on the enhanced version of the original Obama voice data. The network structure is illustrated in figure 7. The vocoder works at a sampling rate of 16 kHz. The µ -law compressed wav eform is quantized into ten bits per sample. Similar to that in a pre vious study [5], the network consists of a linear projection input layer , 40 W aveNet blocks for dilated conv olution, and a post- processing block. The k -th dilation block has a dilation size of 2 mod( k , 10) , where mod( · ) is modulo operation. In addition, a bi-directional LSTM and a 1D con volution layer are used to process the input acoustic features. The acoustic features fed to every W aveNet block contain the 80-dimensional mel- spectrogram plus an additional component specifying which of the different speech-enhancing models produced that speech wa veform 10 . 10 The tools for the TTS and W aveNet implementation are based on a modified CURRENNT toolkit [32] and can be found online http://tonywangx.github .io T able 6: Results of second perceptual ev aluation (MOS score). Non-statistically significant differences are marked with superscripts. Sources Quality Similarity Natural 4.40 4.70 Copy-synthesis 2.45 1 2.99 VC1 2.66 2 1.56 3 VC2 2.67 2 1.55 3 VC3 2.83 1.56 3 TT1 2.49 1 1.43 4 TT2 2.51 1 1.40 4 TT3 2.63 2 1.45 4 6. Per ceptual evaluation of the generated speech T o ev aluate the generation capabilities of the proposed system, we carried out a second crowd-sourced perceptual evaluation with Japanese nativ e listeners. The ev aluation was conducted in the same way as the one described in section 4.4. Only the tasks were dif ferent: 1) rate the quality of the voice in each speech sample, ignoring the effects of background noise and 2) rate the similarity of the voice to that of the spoofed speaker (i.e., Obama), ignoring speech quality and cleanliness. T o compare with the target speaker, we presented the participants two additional samples (one generated by the ev aluated system and one with natural speech), both containing the same linguistic content but dif ferent than the one used for rating speech quality . The participants were asked to rate on a MOS scale the similarity of the two speakers. 6.1. Systems evaluated W e ev aluated six systems plus natural speech and copy synthesis of the mel-spectrograms of the natural speech with the trained W aveNet v ocoder: • V oice con version system 1 (VC1): Japanese-to-English bilingual VC • V oice conv ersion system 2 (VC2): English-to-English monolingual VC • V oice con version system 3 (VC3): Japanese and English mixed utterances multilingual VC • T ext to speech system 1 (TT1): text to speech from estimated mel-spectrogram for noisy condition • T ext to speech system 2 (TT2): text to speech from estimated mel-spectrogram for enhanced-all condition • T ext to speech system 3 (TT3): Speech generated with TT2 with a small added amount of rev erberation W ith the three different v oice con version systems, we aimed to ev aluate the effect of noise and to inv estigate whether CycleGAN can be used for cross-lingual VC systems. With the three TTS systems, we aimed to analyze the ef fect of generating spectrograms on the basis of different conditions for speech enhancement and to determine the importance of mimicking the en vironmental conditions of the reference natural speech when considering human perception. 6.2. Results The results for the second perceptual ev aluation are summarized in table 6. There was a total of 103 unique participants (52 male and 51 female). The results for natural speech indicate that the participants were able to identify the actual Obama voice regardless of the en vironmental conditions (MOS score of 4.70 for similarity). They also indicate that they were able to distinguish the naturalness and frequency of the speech regardless of the background noise and/or reverberation (MOS score of 4.40 for quality). The results for copy synthesis using the trained W aveNet vocoder were quite different (MOS score of 2.45 for quality). The W av eNet system and scripts had pre viously been successful at generating speech when clean speech was used for training [33], suggesting that the difference was due to the nature of the data used for training. One possibility is that using mixture density networks for generating output wa veforms is problematic for modeling the variance of noisy data. Looking at the TTS system results, we see that the quality of the generated speech did not change significantly with the generation condition (MOS score of 2.5) and was similar to that for copy synthesis. Adding a small amount of reverberation improv ed the perceived speech quality so that it was ev en higher than with copy synthesis (2.63 versus 2.45). This means that re verberation can mask part of the noise generated by the W aveNet vocoder . The significant drop in the similarity score means that we cannot say whether the ev aluators were capable of identifying Obama’ s voice. Looking at the VC system results, we see a similar pattern. In terms of quality , the VC systems were slightly b ut significantly better than both TTS and copy synthesis. This is probably because the VC systems were trained on selected data (i.e., only data with estimated SNR > 30 dB), and clean data was used for the source speaker . In terms of similarity , they were slightly but significantly better than TTS but far worse than copy synthesis. Comparing VC1 (Japanese-to-English bilingual VC) with VC2 (English-to-English mono-lingual VC), we see that they achiev ed similar MOS scores for both speech quality and speaker similarity . This suggests that CycleGAN can be used to train a bilingual VC model. When Japanese and English utterances were mixed (VC3), the speech quality was slightly higher for the other VC systems. This is probably because twice the amount of source speaker training data was used. 7. Evaluation based on anti-spoofing countermeasures W e have also ev aluated the b uilt TTS and VC systems based on anti-spoofing countermeasures. The countermeasure used is a common Gaussian mixture models (GMMs) back-end classifier with constant Q cepstral coefficient (CQCC) features [34]. T raining of the countermeasure is speaker -independent and we hav e used two alternati ve training sets to train the two GMMs (one for natural or bona fide speech; another one for synthetic or con verted v oices). The first one contains the training portion of the ASVspoof2015 data consisting of 5 (now outdated) spoofing attacks, and the second one consists of the con verted audio samples submitted by the 2016 V oice Conversion Challenge (VCC2016) participants [35]. The latter contains 18 diverse stronger VC attacks 11 . T able 7 shows the ev aluation results for the CQCC-GMM countermeasure when scored on the found data of Obama (that is, the same data used for the listening tests in a previous section). The results are presented in terms of equal error rate (EER, %) of the spoofing countermeasure. The higher the EER, 11 http://dx.doi.org/10.7488/ds/1575 T able 7: Evaluation results based on anti-spoofing countermeasures (EER in percentages). 32-mix CQCC-GMMs were trained on ASVspoof2015 or VCC2016 sets. Sources ASVspoof2015 VCC2016 Copy-synthesis 4.63 8.46 VC1 2.32 1.08 VC2 2.16 0.00 VC3 2.25 1.01 TT1 1.60 0.00 TT2 2.01 0.00 TT3 0.79 0.00 the more confused the countermeasure will be in telling apart our generated voices from natural human speech. As we can see from a table 7, although the VC and TTS systems in this paper are more advanced methods than ones included in the current ASVspoof 2015, the countermeasure models can still detect both the proposed VC and TTS samples using the found data easily . This is because not only the VC and TTS process but also the additional speech enhancement process caused noticeable artifacts. 8. Conclusions and future w ork W e have introduced a number of publicly av ailable and kno wn datasets that prov ed to be extremely useful for training speech enhancement models. Application of these models to a corpus of low-quality considerably degraded data found in publicly av ailable sources significantly improved the SNR of the data. A perceptual ev aluation rev ealed that the models can also significantly improve the perceptual cleanliness of the source speech without significantly degrading the naturalness of the voice as is common when speech enhancement techniques are applied. Speech enhancement was most effectiv e when the system w as trained using the largest amount of data av ailable as doing so covered a wide variety of en vironmental and recording conditions, thereby impro ving the generalization capabilities of the system. A second perceptual ev aluation re vealed that, while generating synthetic speech from noisy publicly available data is starting to become possible, there are still obvious perceptual problems in both text-to-speech and voice con version systems that must be solv ed to achiev e the naturalness of systems trained using very high quality data. Therefore, we cannot recommend yet that next-generation ASVspoof data be generated using publicly av ailable data even if adding this new paradigm of speech generation systems is a must. Acknowledgements: This work was partially supported by MEXT KAKENHI Grant Numbers (15H01686, 16H06302, 17H04687). 9. References [1] Z. W u, J. Y amagishi, T . Kinnunen, C. Hanili, M. Sahidullah, A. Sizov , N. Evans, M. T odisco, and H. Delgado, “ Asvspoof: The automatic speaker verification spoofing and countermeasures challenge, ” IEEE Journal of Selected T opics in Signal Pr ocessing , vol. 11, no. 4, pp. 588–604, June 2017. [2] H. Muckenhirn, M. Magimai-Doss, and S. Marcel, “End-to-end con volutional neural network-based v oice presentation attack detection, ” in Pr oc. IJCB 2017 , 2017. [3] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. V inyals, A. Grav es, N. Kalchbrenner, A. Senior, and K. Ka vukcuoglu, “W avenet: A generativ e model for raw audio, ” arXiv pr eprint arXiv:1609.03499 , 2016. [4] Y . W ang, R. Sk erry-Ryan, D. Stanton, Y . W u, R. J. W eiss, N. Jaitly , Z. Y ang, Y . Xiao, Z. Chen, S. Bengio, Q. Le, Y . Agiomyr giannakis, R. Clark, and R. A. Saurous, “T acotron: T o wards end-to-end speech synthesis, ” in Pr oc. Interspeech , 2017, pp. 4006–4010. [5] A. T amamori, T . Hayashi, K. K obayashi, K. T akeda, and T . T oda, “Speaker-dependent W aveNet vocoder , ” in Pr oc. Interspeech 2017 , 2017, pp. 1118–1122. [6] T . Kaneko, H. Kameoka, N. Hojo, Y . Ijima, K. Hiramatsu, and K. Kashino, “Generati ve adversarial network-based postfilter for statistical parametric speech synthesis, ” in Pr oc. ICASSP 2017 , 2017, pp. 4910–4914. [7] J. Shen, M. Schuster , N. Jaitly , R. Skerry-Ryan, R. A. Saurous, R. J. W eiss, R. Pang, Y . Agiomyrgiannakis, Y . W u, Y . Zhang, Y . W ang, Z. Chen, and Z. Y ang, “Natural TTS synthesis by conditioning wav enet on mel spectrogram predictions, ” in Pr oc. ICASSP 2018 , 2018. [8] W . Cai, A. Doshi, and R. V alle, “ Attacking speaker recognition with deep generative models, ” arXiv pr eprint arXiv:1801.02384 , 2018. [9] R. Kumar , J. Sotelo, K. Kumar , A. de Brebisson, and Y . Bengio, “Obamanet: Photo-realistic lip-sync from text, ” in NIPS 2017 W orkshop on Machine Learning for Cr eativity and Design , 2017. [10] S. Suwajanakorn, S. M. Seitz, and I. K emelmacher- Shlizerman, “Synthesizing Obama: learning lip sync from audio, ” A CM T ransactions on Graphics (TOG) , vol. 36, no. 4, pp. 95:1–95:13, 2017. [11] S. Pascual, A. Bonafonte, and J. Serr, “SEGAN: Speech enhancement generativ e adversarial network, ” in Pr oc. Interspeech 2017 , 2017, pp. 3642–3646. [12] C. Donahue, B. Li, and R. Prabha valkar , “Exploring speech enhancement with generati ve adv ersarial netw orks for rob ust speech recognition, ” Pr oc. ICASSP 2018 , 2018. [13] P . Isola, J.-Y . Zhu, T . Zhou, and A. A. Efros, “Image-to- image translation with conditional adversarial networks, ” in Pr oc. CVPR 2017 , 2017. [14] C. V eaux, J. Y amagishi, and S. King, “The voice bank corpus: Design, collection and data analysis of a large regional accent speech database, ” in Pr oc. Oriental COCOSD A 2013 , 2013, pp. 1–4. [15] S. S. Sarfjoo and J. Y amagishi, Device Recorded VCTK (Small subset version) , Uni versity of Edinb urgh, 2017. [16] C. V alentini-Botinhao, X. W ang, S. T akaki, and J. Y amagishi, “Speech enhancement for a noise-robust text-to-speech synthesis system using deep recurrent neural networks, ” in Interspeech 2016 , 2016, pp. 352–356. [17] ——, “In vestigating RNN-based speech enhancement methods for noise-robust text-to-speech, ” in 9th ISCA Speech Synthesis W orkshop , 2016, pp. 146–152. [18] C. V alentini-Botinhao, “Rev erberant speech database for training speech derev erberation algorithms and tts models, ” Univ ersity of Edinbur gh, 2016. [19] ——, “Noisy rev erberant speech database for training speech enhancement algorithms and tts models, ” Univ ersity of Edinbur gh, 2017. [20] M. Montgomery . (2005) Postfish by Xiph.org, A vailable: https://svn.xiph.org/trunk/postfish/README. [21] C. Plapous, C. Marro, and P . Scalart, “Improved signal-to-noise ratio estimation for speech enhancement, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 14, no. 6, pp. 2098–2108, 2006. [22] S. King, L. Wihlbor g, and W . Guo, “The Blizzard Challenge 2017, ” in The Blizzar d Challenge workshop 2017 , August 2017. [23] J. Zhu, T . Park, P . Isola, and A. Efros, “Unpaired image- to-image translation using cycle-consistent adversarial networks, ” in Proc. ICCV 2017 , 2017. [24] X. Mao, Q. Li, H. Xie, R. Y . Lau, Z. W ang, and S. P . Smolley , “Least squares generati ve adversarial networks, ” in Pr oc. ICCV 2017 . IEEE, 2017, pp. 2813–2821. [25] F . F ang, J. Y amagishi, I. Echizen, and J. Lorenzo- T rueba, “High-quality nonparallel v oice con version based oncycle-consistent adv ersarial network, ” in Pr oc. ICASSP 2018 , 2018. [26] S. Ioffe and C. Szegedy , “Batch normalization: Accelerating deep network training by reducing internal cov ariate shift, ” in International confer ence on machine learning , 2015, pp. 448–456. [27] I. Sutske ver , O. V inyals, and Q. V . Le, “Sequence to sequence learning with neural networks, ” in Proc. NIPS , 2014, pp. 3104–3112. [28] S. Bengio, O. V inyals, N. Jaitly , and N. Shazeer , “Scheduled sampling for sequence prediction with recurrent neural networks, ” in Pr oc. NIPS , 2015, pp. 1171–1179. [29] X. W ang, S. T akaki, and J. Y amagishi, “ An RNN-based quantized F0 model with multi-tier feedback links for text-to-speech synthesis, ” in Proc. Interspeech , 2017, pp. 1059–1063. [30] HTS W orking Group, “The English TTS system Flite+HTS engine, ” 2014. [Online]. A vailable: http: //hts- engine.sourceforge.net/ [31] H. Zen, T . T oda, M. Nakamura, and K. T okuda, “Details of Nitech HMM-based speech synthesis system for the Blizzard Challenge 2005, ” IEICE T rans. Inf. & Syst. , vol. E90-D, no. 1, pp. 325–333, Jan. 2007. [32] F . W eninger, J. Bergmann, and B. Schuller , “Introducing CURRENNT–the Munich open-source CUD A recurrent neural network toolkit, ” Journal of Machine Learning Resear ch , v ol. 16, no. 3, pp. 547–551, 2015. [33] X. W ang, J. Lorenzo-Trueba, S. T akaki, L. Juvela, and J. Y amagishi, “ A comparison of recent wav eform generation and acoustic modelingmethods for neural- network-based speech synthesis, ” in Pr oc. ICASSP 2018 , April 2018. [34] M. T odisco, H. Delgado, and N. Evans, “ A new feature for automatic speak er verification anti-spoofing: Constant q cepstral coef ficients, ” in Odysse y 2016 , 2016, pp. 283– 290. [35] T . T oda, L.-H. Chen, D. Saito, F . V illavicencio, M. W ester , Z. W u, and J. Y amagishi, “The voice con version challenge 2016, ” in Interspeech 2016 , 2016, pp. 1632–1636.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment