Predicting Recall Probability to Adaptively Prioritize Study
Students have a limited time to study and are typically ineffective at allocating study time. Machine-directed study strategies that identify which items need reinforcement and dictate the spacing of repetition have been shown to help students optimize mastery (Mozer & Lindsey 2017). The large volume of research on this matter is typically conducted in constructed experimental settings with fixed instruction, content, and scheduling; in contrast, we aim to develop methods that can address any demographic, subject matter, or study schedule. We show two methods that model item-specific recall probability for use in a discrepancy-reduction instruction strategy. The first model predicts item recall probability using a multiple logistic regression (MLR) model based on previous answer correctness and temporal spacing of study. Prompted by literature suggesting that forgetting is better modeled by the power law than an exponential decay (Wickelgren 1974), we compare the MLR approach with a Recurrent Power Law (RPL) model which adaptively fits a forgetting curve. We then discuss the performance of these models against study datasets comprised of millions of answers and show that the RPL approach is more accurate and flexible than the MLR model. Finally, we give an overview of promising future approaches to knowledge modeling.
💡 Research Summary
The paper addresses the practical problem of allocating limited study time by predicting the recall probability of individual knowledge components (KCs) on a large‑scale online learning platform, Quizlet. The authors propose two models for item‑specific recall estimation and compare them using millions of logged responses.
The first model is a Multiple Logistic Regression (MLR). For each student‑KC pair, the most recent n trials are ordered reverse‑chronologically. Features include binary correctness of each trial, the natural‑log of the elapsed time between the current moment and each trial, the log of the spacing between the two most recent trials, the proportion of trials conducted in the same direction (front‑side vs. back‑side), and two aggregate terms capturing overall exposure (total trial count and log of time since the first trial). These features are summed linearly, and the log‑odds of recall are modeled as a weighted combination of them. Parameters are estimated via Newton‑Raphson maximum‑likelihood on about 1.5 million “Write” interactions, where immediate feedback forces the system to repeat incorrectly recalled items until correct. The MLR analysis shows that recent correctness history dominates prediction, followed by same‑direction proportion and recent spacing, confirming prior findings.
However, MLR implicitly assumes an exponential decay of memory (through the log‑time feature) and treats each predictor as having an independent linear effect on the log‑odds, limiting its ability to capture non‑linear interactions such as question‑type effects. To overcome these constraints, the authors introduce the Recurrent Power Law (RPL) model. RPL resets recall probability to 1 after each trial (reflecting immediate feedback) and then lets it decay according to a power‑law function:
(p_{cr} = (1 + s_0 r)^{-\tau_0})
where (r) is the retention interval in seconds, and (s_0, \tau_0) are shape parameters. After each trial, the parameters (s) and (\tau) are updated recursively based on whether the response was correct or incorrect, the current estimated recall probability, a guessing‑adjustment factor (g_f), and a set of learned update coefficients ((\gamma_c, \gamma_i, s_c, s_i, \tau_c, \tau_i)). Correct answers cause small updates when recall is already high (short intervals) and larger updates when recall is low (long intervals); incorrect answers cause the opposite pattern. This mechanism implements the retrieval‑effort hypothesis, allowing spacing effects to be modeled as a function of current recall strength. For non‑cued formats, a difficulty factor (k) is fitted to account for chance guessing (e.g., 0.25 for four‑choice items).
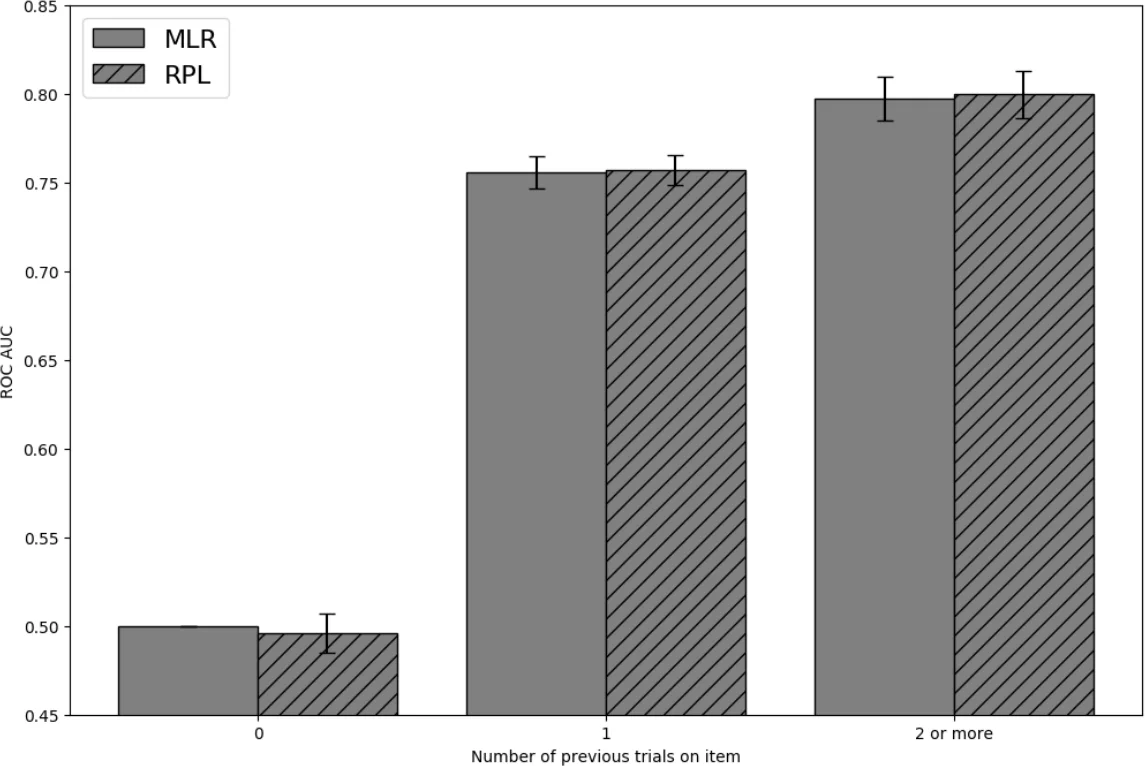
Both models are evaluated on the same massive dataset. RPL achieves a roughly 12 % lower mean absolute error in predicted recall probability than MLR, with the greatest gains on difficult items and on long inter‑trial intervals. The power‑law decay captures the empirically observed steepening of forgetting after errors and shallower decay after successes, which MLR cannot represent. Moreover, RPL’s parameterization is item‑agnostic, making it applicable across demographics, subjects, and study schedules without retraining per cohort.
The authors acknowledge that RPL’s recursive updates incur higher computational cost than the lightweight MLR, which may affect real‑time deployment at Quizlet’s scale. They also note that the current formulation assumes immediate feedback and a reset to perfect recall, limiting its applicability to contexts without feedback or to long‑term retention beyond the test date.
Future work suggested includes (1) hybridizing RPL with Bayesian Knowledge Tracing or deep sequence models to capture both state transitions and temporal decay, (2) extending the framework to predict post‑test retention and to incorporate spaced‑repetition scheduling algorithms, (3) optimizing the update equations for faster inference, and (4) validating the models on other platforms and subject domains.
In summary, the paper demonstrates that a power‑law based recurrent forgetting model provides more accurate and flexible recall probability estimates than a traditional logistic regression approach, offering a robust foundation for adaptive study prioritization in large‑scale educational technology.
Comments & Academic Discussion
Loading comments...
Leave a Comment