Joint Task Assignment and Wireless Resource Allocation for Cooperative Mobile-Edge Computing
This paper studies a multi-user cooperative mobile-edge computing (MEC) system, in which a local mobile user can offload intensive computation tasks to multiple nearby edge devices serving as helpers for remote execution. We focus on the scenario whe…
Authors: Hong Xing, Liang Liu, Jie Xu
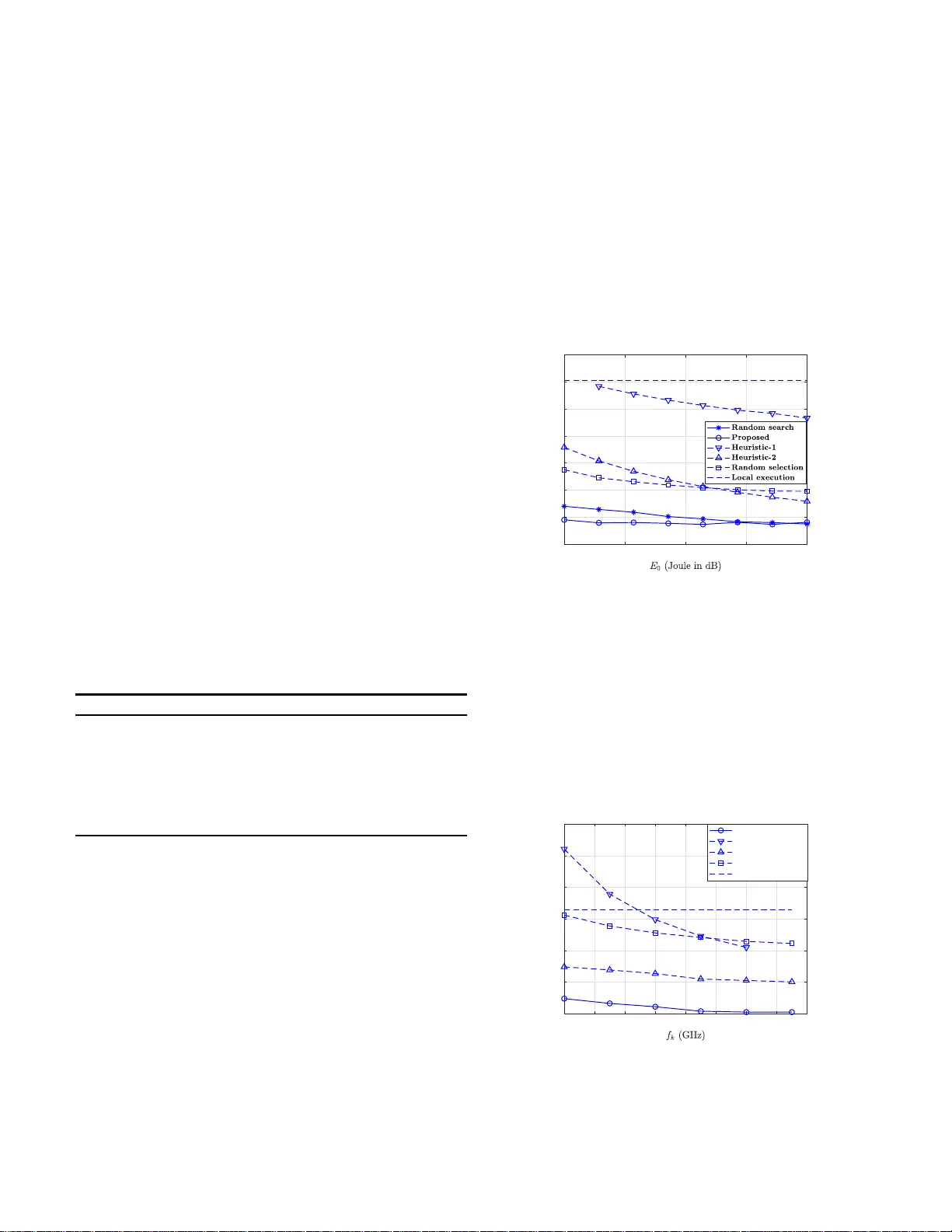
Joint T ask Assignment and W ireless Resource Allocation for Cooperati ve Mobile-Edge Computing Hong Xing † , Liang Liu ‡ , Jie Xu § , and Arumugam Nallanathan † † School of EECS, Quee n Mary University of London, Londo n, U.K. ‡ Departmen t of ECE, Uni versity of T oronto, T oron to, Canada § School of In formatio n Engineering, Guangdong Univ ersity of T echn ology , Guangzh ou, Chin a E-mails: h.xing @qmul.ac.u k, lianguot.liu@uto ronto.c a , jiexu@gdut.ed u.cn, a.nallanath an@qmul.a c . uk Abstract —This paper studies a multi-user cooperativ e mobile- edge computing (MEC) system, in which a local mobil e user can offload intensive computation tasks to multiple n earby edge devices serving as h elpers for remote execution. W e focus on the scenario where the local user has a number of indep en dent tasks that can be executed in parallel but ca nnot be further partitioned. W e consid er a time division multiple access (TDMA) communi- cation protocol, in wh ich the local user can offload computation tasks to the helpers and download results from them over pr e- scheduled time slots. Under this setup, we minimize the local user’ s computation latency by optimizing the task assignment jointly with the time and power allocations, sub j ect to ind ividual energy constraint s at the local user and the helpers. Howev er , the joint task assignment and wireless res ource allocation problem is a mixed-integer non-linear program (MINL P ) th at is hard to solve optimally . T o tackle this challenge, we first relax it in to a con vex problem, and then propose an efficient suboptimal solution based on the opti mal solution to the relaxed conv ex problem. Fin ally , numerical results show that our proposed joint design significantly reduces the local user’s computation latency , as compared against other benchmark schemes that d esign the task assignment separately from the offloadin g/downloading resour ce allocations and local execution. I . I N T RO D U C T I O N It is envisioned that by th e year of 2020, ar ound 5 0 billio n s of interconnected In ternet o f Things (IoT) de vices will surge in wireless networks, featurin g new app lications such as v ideo stream analysis, augm ented reality , and autonom ous driving. The u npreced ented growth o f such applications dem ands in- tensiv e an d latency-cr itical computation at these IoT de vices, which, howe ver , is h ardly affordable by c onv entiona l mobile computin g systems. T o address such new challenges, mobile- edge compu ting (MEC) ha s been ide n tified a s a promising solution b y provid ing c loud-like comp uting function s at the network edge [1–5 ]. MEC has received growing researc h interests in both academia and industry . T o maxima lly reap the ben efit o f MEC, it is c r itical to jointly manage the radio and comp utation resources for perform a nce optimizatio n [6]. F or instance, [7] in vestigated an MEC system with orthogonal frequ e n cy divi- sion multiple access (OFDMA)- based comp utation offloading , in which the sub c arrier allocatio n fo r offloading and the users’ central pro cessing un it (CPU) f requen c ies for local c o mputing were jointly optimized to minim ize the energy co n sumption at mobile devices. [8] conside r ed multi-user MEC systems with both time division multip le access (TDMA) and OFDMA- based offloading, in which th e optimal resou rce allocation policies were de veloped by taking into account bo th wireless channel conditions and users’ local co mputatio n capabilities. Furthermo re, a n ew multi-user MEC system w as studied in [9] by exploiting multi-antenna non-or th ogon al multiple access (NOM A)-based com putation offloading. In ad dition, a wireless powered multi-u ser MEC system was d eveloped f or IoT systems in [10], where th e users conducted computation offloading relyin g o n the harvested e n ergy fro m a multi- antenna access po int (AP) integrated with MEC servers. I n these prio r work s, the MEC servers are usu ally assumed to be of rich co m putation an d e n ergy resou rces, such that the computatio n time an d/or the results downloading time are assumed negligible. T his, however , may no t be true in pr a ctice [11, 12], especially for scenar io s where multip le lightweigh t edge d evices such as cloudlets and smartph ones are employed for coop erative mob ile-edge computing . On anoth er f ront, in distributed co mputing systems, task assignment and task sched u ling have been extensively studied to impr ove the computation quality o f service (see, e . g., [ 1 3] and the refer ences ther ein). For examp le, [1 4 ] studied the task assignment am ongst m ultiple servers for par allel co mputation and [12] in vestigated the sche d uling of sequential tasks with proper order . Howe ver, this line of r e search of ten assum ed static cha nnel and co m putation cond itions b ut ig nored th eir dy- namics an d heterog eneity , th us mak ing it d ifficult to be d irectly applied to M EC. Recently , there are f ew w ork s consider in g joint task scheduling and co mmunica tions resourc e manage- ment. For in stance, [1 2 ] jointly o ptimized the task schedu ling and wireless power allocation in a single-user single-cor e MEC system, in which multiple indepen dent computation tasks a t the lo cal u ser r equire to b e seq uentially executed at the MEC server . In this paper, we study a multi-user co operative MEC system, in wh ich a lo cal m obile user ca n offload a num ber of ind e p enden t computation tasks to mu ltiple near b y edge devices serving as he lpers (such as smar tphones, tablets, W iFi APs, and cellular base stations (BSs)) f o r remote execution. Assuming that the tasks can be executed in p arallel but can n ot be furth e r partitioned, we co nsider a TDMA co mmun ica tion protoco l, in which the local u ser offloads tasks an d downloads computatio n results over pr e-schedu led time slots. Th e contri- butions of this pap er are summa rized as fo llows. 1) W e for- mulate the laten cy-minimization problem that jointly optim izes computatio n tasks assignment and time/power allocation s for both tasks offloading and results downloading, subject to individual energy con straints at all th e user and helpe r s. 2) Since the f o rmulated p roblem is a mixed - integer non-lin ear progr am (MIN L P) th at is hard to solve optimally in ge n eral, we propose an ef ficient algorithm to obtain a subo p timal solution based on the optimal solution to a relaxed (con vex) problem . 3 ) Simulation r esults show striking perfo rmance gain achieved by the p roposed design in co m parison with o ther benchm a rk schem es that design the task assignmen t separately from the offloading/downloadin g resou rce alloc ations and lo- cal execution. The remaind er of this paper is organized as follows. The system model is presen ted in Section II. Th e jo int compu tation task assign ment and time allocation s proble m is f ormulated in Section I I I. In Sec tion IV , an effecti ve joint optimization algorithm is prop osed. Simu la tio n results are provided in Section V, with conclusion dr awn in Section VI. I I . S Y S T E M M O D E L W e conside r a multi-u ser coop erative MEC system that consists of o n e local mobile user, an d K nearb y wireless edge de vices serving as helper-nodes, deno ted b y th e set K = { 1 , . . . , K } , all equ ipped with single antenna. For conv enience , we define the local user as the ( K + 1) -th node. Suppose that the loca l user has L in d epend e n t tasks to be executed, denoted by the set L = { 1 , . . . , L } , and the inp ut (outpu t) d a ta leng th of each task l ∈ L is denoted b y T l ( R l ) in bits. In the considered MEC system, each task can be either com puted locally , or of floaded to o n e of the K helpers for remote execution. Let Π ∈ R L × ( K +1) denote the task a ssignment matrix , wh ose ( l , k ) -th entry , denoted by π ( l , k ) ∈ { 0 , 1 } , l ∈ L , k ∈ K ∪ { K + 1 } , is g iv en by π ( l , k ) = ( 1 , if the l th task is assigned to the k th user, 0 , otherwise. Also, d efine L ( k ) = { l ∈ L : π ( l , k ) = 1 } as the set of tasks that are a ssign ed to node k , k ∈ K ∪ { K + 1 } . At last, denote by C l,k (in cycles per bit) the numbe r of CPU cycles req uired for computing on e inp ut bit of the l th task at the k th node, l ∈ L , k ∈ K ∪ { K + 1 } . Also denote the CPU frequency a t the k th n ode as f k (in cycles per second), k ∈ K ∪ { K + 1 } . A. Lo c a l Computing The tasks in the set L ( K +1) are executed locally . Hence, the local compu tation time is given by t c 0 = L X l =1 π ( l , K + 1) C l, 0 T l / f 0 . (1) hƐĞƌ ϭ hƐĞƌ < hƐĞƌ Ϯ o ff K t d l K t c t c t K d l t d l t KĨĨůŽĂĚŝŶŐ ŽǁŶůŽĂĚŝŶŐ ŽŵƉƵƚĂƚŝŽŶ c K t dŽƚĂůůĂ ƚĞŶĐLJ o ff t of f t I Fig. 1. The TDMA-based frame for the proposed protocol. The corre sp onding compu tation energy co nsumed by the lo cal user is given by [2] E c 0 = κ 0 L X l =1 π ( l , K + 1) C l, 0 T l f 2 0 , (2) where κ 0 is a con stant denotin g the effecti ve cap acitance coefficient that is d e cided b y the ch ip a r chitecture of th e lo cal user . B. Re mote Computing at Help ers On the o th er hand, the tasks in the set of L ( k ) requires to be offloaded to the k th n ode, k ∈ K , for remo te execution. In this p a per, we consider a three-phase TDMA communication protoco l. As shown in Fig. 1, the local u ser fir st offloads the tasks in the set L ( k ) to the k th nod e , k ∈ K , via TDMA. No te that at each TDMA time slo t, the local user merely o ffloads tasks to o ne helper . Then the helpers co mpute their assigned tasks an d send the compu tatio n results back to the local user via TDMA. Similarly , at each time slot, there is m erely one helper tr ansmitting th e r e su lts. In the following, we introduce the three-ph ase p rotocol in detail. 1) Phase I: T ask Offloading: First, the tasks are o ffloaded to th e helpers via T D M A. For simp licity , in th is paper we assume that the lo c a l user offloads the tasks to the helpers with a fixed order of 1 , 2 , · · · , K , as shown in Fig. 1. Let ¯ h k denote the ch annel power g ain fr om the local user to the k th n ode for o ffloading, k ∈ K . The achie vable ra te from the local user to the k th n o de is given by (in b its/second) r of f k = B log 2 1 + p of f k ¯ h k σ 2 k ! , (3) where B in Hz denotes the a vailable tran smission band width, p of f k is the tran smitting power at the lo cal u ser for offloading tasks to the k th nod e, and σ 2 k is the power of additive wh ite Gaussian n oise (A WGN) at the k th node. Then, the task offloading time for the k th no d e is gi ven by 1 t of f k = P L l =1 π ( l , k ) T l r of f k . (4) 1 If no task is of floaded to node k , i.e., π ( l, k ) = 0 , ∀ l , then the offloadi ng rate r of f k = 0 , and we define t of f k = 0 and p of f k = 0 in this case. According to (3 ) a n d (4), p of f k is expressed as p of f k = 1 h k f P L l =1 π ( l , k ) T l t of f k ! , (5) where h k = ¯ h k /σ 2 k is the nor malized channel power g ain from the local user to the k th node , an d f ( x ) , 2 x B − 1 . Th e total energy consu med b y the local user fo r o ffloading all the tasks to the help ers is then expressed as: E of f 0 = K X k =1 1 h k f P L l =1 π ( l , k ) T l t of f k ! t of f k . (6) 2) Phase II: T ask Execution: After receiving the assigned tasks in L ( k ) , the k th nod e proc e e ds with co mputing . Similar to (1) , th e computation time of the k th node is given by t c k = L X l =1 π ( l , k ) C l,k T l / f k . (7) Its corre sp onding co mputation al energy is thus gi ven by E c k = κ k L X l =1 π ( l , k ) C l,k T l f 2 k , (8) where κ k is the cor respond ing capacitan ce constant of the k th node. 3) Phase III: T ask Result Downlo ading : After computin g all the assigned tasks, the helpers begin tran smitting compu- tation results back to the lo cal user v ia TDMA. Similar to the task o ffloading, we assume that the helpers transmit their respective co mputation r esults in the order of 1 , · · · , K . Let ¯ g k denote the channel power gain fro m nod e k to th e lo cal user for downloading. The achiev able r ate of downloading results from the k th node is then given by r dl k = B log 2 1 + p dl k ¯ g k σ 2 0 , (9) where p dl k denotes the tran smitting power of the k th node, and σ 2 0 denotes the power of A WGN at the lo cal user . The downloading time of the loc a l user from the k th nod e is thus giv en by t dl k = P L l =1 π ( l , k ) R l r dl k . (10) According ly , th e tra nsmitting power of th e k th nod e is ex- pressed as p dl k = 1 g k f P L l =1 π ( l , k ) R l t dl k ! , (11) where g k = ¯ g k /σ 2 0 denotes the n o rmalized channel power gain from the k th node to the local user . The commu nication energy of th e k th node for deli vering its re su lts to the local user is thus given by E dl k = 1 g k f P L l =1 π ( l , k ) R l t dl k ! t dl k . (12) Since TDMA is used in both Ph ase I and Phase III, each helper has to wait until it is scheduled. Specifically , the first scheduled helper, i.e., n ode 1 , can tra nsmit its co mputation result to th e local user only when the following two conditions are satisfied: first, its co mputation has b een com pleted; and second, task o ffloading from the lo cal user to all the K helpers are completed suc h that th e wireless channels begin av ailable for data downloading, as shown in Fig. 1 . As a result, no de 1 starts tra nsmitting its results after a period o f waiting time giv en by I 1 = max { t of f 1 + t c 1 , K X k =1 t of f k } , (13) where t c 1 is the task e xecution time at no de 1 (c.f. (7)). Moreover , for e ach of the oth er K − 1 h elpers, it can transmit the computatio n r esults to the local user only when: first, its co mputatio n has been comp leted; second, the ( k − 1 ) th node sch eduled precedin g to it h as finished transmitting . Consequently , den oting the waiting time for node k ( k ≥ 2 ) to start transmission as I k , I k expressed as I k = max { k X j =1 t of f j + t c k , I k − 1 + t dl k − 1 } . (1 4) According ly , the completio n time for all the results to fin ish being downloaded is expressed as T = I K + t dl K . (15) T o su m marize, taking both local com p uting and rem ote execution in to accou nt, the total latency for all of the L tasks to be executed is given as T total = max { t c 0 , T } . (16) I I I . P RO B L E M F O R M U L AT I O N In this paper, we aim at min imizing the total latency , i.e., T total , b y optim izing the task assignment strategy , i.e., π ( l , k ) ’ s, the tra n smission time for task of floadin g and result downloading, i.e., t of f k ’ s and t dl k ’ s ( e quiv alent to transmitting power a s sh own in (5) and (11 )), subject to the individual energy constraints for both the local user and the K helpers as well as th e task assignme nt constraints. Specifically , we are interested in the f ollowing pr oblem: (P1) : Minimize Π , { t of f k ,t dl k } T total Subjec t to E c 0 + E of f 0 ≤ E 0 , (17a) E c k + E dl k ≤ E k , ∀ k ∈ K , (17b) K + 1 X k =1 π ( l , k ) = 1 , ∀ l ∈ L , (17c) π ( l , k ) ∈ { 0 , 1 } , ∀ l ∈ L , k ∈ K ∪ { K + 1 } , (17d) t of f k ≥ 0 , t dl k ≥ 0 ∀ k ∈ K . (17e) The constraints given by (17a) and (17 b) r e present the total energy constra in ts for the local user an d th e k th node, respec- ti vely; (1 7 c) guaran tees that each task m ust b e assigned to one node; and finally ( 17d) ensures that each task ca nnot be partitioned . I V . P RO P O S E D J O I N T T A S K A S S I G N M E N T A N D T I M E A L L O C AT I O N S The challenge s in solving p roblem (P1) lie in two folds. First, the objectiv e functio n ( c.f. (15 )) is a co mplicated func- tion inv olving multiple max function s due to recur sive feature of I k (c.f. (14)), for k ≥ 2 . Second, th e task ass ignm ent variables are constra in ed to be bin ary (c.f.( 17d) ). Hence, in this section we first simp lify the objective fu nction lev eragin g the structure of the op timal solu tio n. Th en f or the equivalently transform ed p roblem, we propo se a suboptima l solution to deal with the bin a r y constraints. A. Pr oblem Refo rmulation First, the following lemma is r equired to simplify the objective function of (P1 ). Lemma 4.1: The functio n h ( y , t ) = f y t t monoto nically decreases over t > 0 . Pr oof: T h e m onoton icity of the above fu nction can be obtained by e valuating the first-order partial deri vati ve of h ( x, t ) with respect to (w .r .t.) t , and using th e fact that (1 − x ) e x − 1 < 0 , for x > 0 . Then prob le m (P1) can be recast into an equiv alent p roblem as stated in the f o llowing pro position. Pr oposition 4.1 : Problem (P1 ) is equivalent to th e following problem : (P1 - Eqv) : Minimi ze Π , { t of f k ,t dl k } ,I 1 I 1 + K X k =1 t dl k Subjec t to K X k =1 t of f k ≤ I 1 , (18a) t of f 1 + P L l =1 π ( l, 1) C l, 1 T l f c 1 ≤ I 1 , (18b) P L l =1 π ( l,K +1) C l, 0 T l f 0 ≤ I 1 + K X k =1 t dl k , (18c) P L l =1 π ( l,k ) C l,k T l f c k ≤ I 1 + k − 1 X j =1 t dl j − k X j =1 t of f j , ∀ k ∈ K \ { 1 } , (18d) (17a) − (17e ) , (18e) where the constraints giv en by (18a) and (18b) determine the waiting time o f node 1 (c.f . (13 )); (1 8c) f ollows by substituting (1) for t c 0 (c.f. (26)); and (18 d ) are obtaine d by rep lacing t c k ’ s, k ≥ 2 , with ( 7) (c.f. (22)). Pr oof: There are tw o possible cases f or the o p timal I k ’ s giv en by (1 4): case 1) P k j =1 t of f j + t c k > I k − 1 + t dl k − 1 ; and case 2) P k j =1 t of f j + t c k ≤ I k − 1 + t dl k − 1 . In line with Lemma 4. 1 , the total transmitting en ergy of the k th node, i. e ., E dl k ’ s (c.f. (12)), monoto nically decreases over t dl k ’ s. Hen ce, if the first case occurs, node k − 1 ( k ≥ 2 ) can slow d own its downloadin g, e.g., extending t dl k − 1 , un til I k − 1 + t dl k − 1 = P k j =1 t of f j + t c k , such that I k remains u nchang ed but the transmittin g energy of nod e k − 1 gets reduced. As suc h , witho ut loss of optimality , the two cases can be merged into one as I k = I k − 1 + t dl k − 1 , ∀ k ∈ K \ { 1 } , (19) subject to the co mputation deadline con straints given by t c k ≤ I k − 1 + t dl k − 1 − k X j =1 t of f j , ∀ k ∈ K \ { 1 } . (20) Since it fo llows from (19 ) th at I k = I 1 + k − 1 X j =1 t dl j , (21) (20) reduces to t c k ≤ I 1 + k − 1 X j =1 t dl j − k X j =1 t of f j , ∀ k ∈ K \ { 1 } . (22) Furthermo re, sub stituting (21) for I K in (15 ), T is simplified as T = I 1 + K X k =1 t dl k . (23) Then, plugg in g (23 ) into (16), the total laten cy gi ven by (16) turns out to be T total = max { t c 0 , I 1 + K X k =1 t dl k } . (24) On the othe r h and, it can b e similarly verified that when the optimal T total giv en by (24) y ields t c 0 > I 1 + P K k =1 t dl k , it is always possible for o n e of the K helpers to slow down its transmission with its com m unication energy sa ved suc h that I 1 + P K k =1 t dl k = t c 0 . Th erefore , without loss of o p timality , T total can be fu rther reduced to T total = I 1 + K X k =1 t dl k , (25) which is the ob je c tive function of Pro blem (P1-Eq v), and subject to t c 0 ≤ I 1 + K X k =1 t dl k . (26) It is also worth y o f n oting th at to gua rantee the feasi- bility of p roblem (P1) o r (P1-Eqv), it is sufficient to have E 0 > P L l =1 ( κ 0 C l, 0 T l f 2 0 + ln 2 P K k =1 1 h k T l B ) a nd E k > P L l =1 ( κ k C l,k T l f 2 k + ln 2 g k R l B ) , ∀ k ∈ K , wh ich are assum ed to be true through o ut the paper, and thus we only focus on the feasible cases. B. S uboptima l Solutio n to (P1) Problem ( P1-Eqv ) is an MINLP and is in gener al NP- hard. Note tha t un der given Π , (P1- Eqv) proves to be convex, since it is shown that E of f 0 (c.f. (6)) and E dl k ’ s (c . f. (12)) ar e conv ex fun ctions over t of f k ’ s an d t dl k ’ s, respectively . Howev er, although th e optimal solution to (P1 -Eqv) can be obtained by exhaustiv e search , it is computationally to o expensi ve (as many as ( K + 1) L times of sear ch) to implement in practice. Therefo re, in this sub section we pro p ose a subop timal so lution to ( P1-Eqv ) (or (P1)) by jo intly optimizing the task assignment and the transmission time /power . W e first replace the b inary constraints gi ven b y (17 d) with the con tinuous o nes given by π ( l , k ) ∈ [0 , 1] , ∀ l ∈ L , ∀ k ∈ K ∪ { K + 1 } , (27) which resu lts in a relaxed prob lem denoted b y (P1- E qv-R). Since (P1-Eqv -R) pr oves to be jo intly co n vex w .r .t. Π , { t of f k , t dl k } , and I 1 , it c a n be efficiently solved b y some off-the-she lf conv ex optimiz a tio n tools such as CVX [ 1 5]. Next, den oting the o p timal task assignm ent matrix Π to (P1-Eqv -R) as Π ∗ , we propo se to ro u nd off π ∗ l,k ’ s to ˆ π l,k ’ s as follows such th at (17 c ) and ( 1 7d) for (P1- Eqv) are satisfied. ˆ π ( l , k ) = ( 1 , if k = ˆ k l , 0 , otherwise, , ∀ l ∈ L , (28) where ˆ k l = arg max k ∈K∪{ K +1 } π ∗ l,k , ∀ l ∈ L . As shown earlier, given ˆ π l,k ’ s as (28), (P1-Eqv ) turns out to be join tly con vex w .r .t. { t of f k , t dl k } and I 1 , and thus can again b e efficiently solved by conve x optimiza tio n too ls to obtain optimal transmission time/power under g iv en task assignment. The pr oposed algo - rithm for solv in g (P1) is summ arized in Algorithm 1. Algorithm 1 Proposed Algorith m f or Solving (P1) 1) Solve (P1-Eqv- R) using CVX; 2) Obtain the optimal task a ssign ment matrix Π ∗ ; 3) Round off π ∗ l,k ’ s in accordance w ith (28) yielding ˆ Π ; 4) Solve (P1-Eqv) given ˆ Π to obtain { ˆ t of f k , ˆ t dl k } and ˆ I 1 . Output the suboptima l solu tion to (P1 ) as ˆ Π , { ˆ t of f k , ˆ t dl k } , an d ˆ I 1 . V . S I M U L A T I O N R E S U LT S In th is sectio n, we verify the effecti veness o f the pro- posed joint task assignm ent and TDM A resource allocation against other baseline sche m es. First, we p rovide two heuristic schemes: 1) ‘h euristic- 1 ’ assigns each task as per the ch annel gains only , i.e., k = arg min k ∈K { max { 1/ h k , 1/ g k }} , ∀ l ∈ L ; and 2) ‘h euristic- 2 ’ assign s each task as per the co mputation al time fo r executing this task, i.e . , k l = arg min k ∈K C ( l , k ) T l / f k , ∀ l ∈ L . In addition , ‘random selection’ solves (P1-Eq v) by random ly cho osing a feasible Π . Mo reover , since the theoret- ically optimal task a ssign ment m ust be found by exhau sti ve search, we provide a near-optimal ‘rando m sear ch’ scheme that runs ‘rand om selection’ for 100 0 times and selects the b e st solution. At last, in ‘local execution’, the local user executes all the comp utation tasks locally . The inpu t d ata length T l is assumed to be un iformly distributed betwee n 0 and 10 4 , deno ted b y T l ∼ U [0 , 10 4 ] , ∀ l ∈ L . Similarly , we set R l ∼ U [0 , 10 3 ] and C l,k ∼ U [0 , 10 3 ] , ∀ l ∈ L , k ∈ K . The K helpers are located within a radius uni- formly d istributed within 0 . 5 km away fro m the local user . The wireless channel model consists of both large-scale path lo ss, and small-scale Rayleigh fading with an av erag e chann el power g ain of 1 . The other parameter s are set as follows unless o therwise spec ified: B = 312 . 5 KHz, σ 2 = − 14 4 dB, κ = 10 − 28 [8, 10], K = 5 , L = 10 , f 0 = 1 GHz, f k = 2 GHz, and E k = E 0 = − 20 dB, ∀ k ∈ K . -20 -15 -10 -5 0 5 10 15 20 25 30 35 40 Latency of the MEC system (ms) Fig. 2. T otal latency versus the energy constraint s with E k = E 0 , ∀ k ∈ K . Fig. 2 shows the total latency versus the energy constrain ts. It is o b served that our pro posed joint task assignment and time allocations ou tperform s all other schemes in most cases and keeps a negligible gap with the near-optimal ‘ r andom searc h ’ under large energy co nstraints. I t is also seen that ‘h euristic-2’ only ou tperfor ms ‘ r andom selection’ when E 0 is larger than − 8 . 5 dB, since in the low-energy case, assign ing tasks as p er only co mputation al resou rces may oc c u r too much en ergy fo r computatio n and th us less for co mmun ic a tio ns. 0.8 1 1.2 1.4 1.6 1.8 2 2.2 2.4 5 10 15 20 25 30 35 Latency of the MEC system (ms) Proposed Heuristic-1 Heuristic-2 Random selection Local execution Fig. 3. T otal latenc y versus the helpers’ CPU frequenc y wit h f 0 = 1 GHz and L = 6 . Fig. 3 compares the system latency versus the he lpers’ CPU frequency . It is seen that th e total laten cy red uces with the h elpers’ frequency , which is intuiti ve. Moreover, both ‘heuristic-2 ’ and the propo sed scheme tend to b e lower - bound ed wh e n f k ’ s co ntinues incr easing, since un der the same energy co nstraint, large f k ’ s lead s to sign ificant computatio n energy expen diture, and thus the latency of the system is even- tually bottlenec ked by com municatio ns time. Furthe r more, as ‘heuristic-1 ’ only selects the helper with the best chann el condition , all the tasks ar e then p erform e d on this single helper, whose f requen cy thus needs to be sufficiently larger than the local freq uency f 0 to sur pass ‘local execution’. I t is also worth noting that the per forman ce of ‘heuristic-1’ is not ev aluated further when f k ’ s is larger than 2 GHz, simply because op e r ating with such high freque n cy violates its energy constraint. 5 10 15 20 25 30 35 40 0 50 100 150 200 250 Latency of the MEC system (ms) Proposed Heuristic-1 Heuristic-2 Random selection Local execution Fig. 4. T otal latenc y versus the number of computation tasks with K = 4 and E k = E 0 = − 10 dB, ∀ k ∈ K . The impa ct of the total nu mber of comp utation tasks on the latency is shown in Fig. 4. W ith th e numb er of tasks increasing, longer de lay is expected for all schemes with the propo sed design achieving th e best perf ormanc e , esp e c ially when L beco mes large. Unlike in Fig. 3, ’heuristic-1 ’ always outperf orms ’local execution’ , sin c e th e commun ication-aware task assign m ent selects the helper with poten tially sho rt com - munication s time to offload the tasks, while exploiting its high CPU freq uency . V I . C O N C L U S I O N In this p aper, we invest igated joint task assign ment as we ll as time and/or power allocations for a mu lti- user cooper ativ e MEC system employing TDMA - based commu nications. W e considered a pra c tica l task m odel whe re the local user has multiple independen t computatio n tasks that can be e xecuted in parallel. Under this setup, we aimed at min im izing the computatio n latency subject to individual energy constraints at the local user and th e h elpers. Th e laten cy minimization problem was f o rmulated a s an MINLP , which is difficult to be solved optimally . W e p r oposed a low-comp lexity sub optimal scheme by fir st relaxing the integer variables (f or task assign- ment) as c o ntinuo u s o nes, then solving th e relaxed problem, and finally constructing a subo p timal solution to the origin a l problem based on the o ptimal solution to the relaxed p r oblem. Finally , th e effecti veness of the pr oposed sch e me was verified by nume r ical r e sults. R E F E R E N C E S [1] H. Z hang, Y . Qiu, X. Chu, K. L ong, and V . C. M. Leung, “Fog radio access networks: Mobility management, interfere nce m itigat ion, and resource optimizati on, ” IEEE W ire less Commun. , vol. 24, no. 6, pp. 120– 127, Dec. 2017. [2] Y . Mao, C. Y ou, J. Zhang, K. Huang, and K. B. Letaief, “ A surve y on mobile edge computing: T he communicatio n perspecti ve, ” IEE E Commun. Surve ys T uts. , vol. 19, no. 4, pp. 2322–2358, Fourthqu arter 2017. [3] K. Kumar , J. Liu, Y .-H. Lu, and B. Bharga va, “ A surve y of computation of floading for mobile systems, ” Mobile Netw . and Appl. , vol. 18, no. 1, pp. 129–140, Feb . 2013. [4] E TSI, “Executi v e briefing-mobile edg e computin g (MEC) initiati v e (White Paper), ” 2014. [5] CISCO, “Fog computi ng and the internet of things: Extend the cloud to where the things are (W hite Paper) , ” 2015. [6] S. Barbarossa, S. Sardellit ti, and P . D. Lorenzo, “Communicat ing while computing : Distrib uted mobile cloud computing over 5G heterogene ous netw orks, ” IEE E Signal Proce ss. Mag. , vol. 31, no. 6, pp. 45–55, Nov . 2014. [7] Y . Y u, J. Zhang, and K. B. L etaief, “Joint subcarri er and cpu time alloca - tion for mobile edge computing, ” in Pr oc. IEEE Global Communicati ons Confer ence (GLOBECOM) , W ashingt on, DC, USA, Dec. 2016. [8] C. Y ou, K. Huang, H. Chae, and B. H. Kim, “Energy -effic ient resource alloc ation for m obile-e dge computation offloading, ” IEEE Tr ans. W ir e- less Commun. , vol. 16, no. 3, pp. 1397–1411, Mar . 2017. [9] F . W ang, J. Xu, and Z . Ding, “Optimized multiuser computatio n of fload- ing with multi-antenn a NOMA, ” in Proc. IEE E Global Communicat ions Confer ence (GLOBECOM) W orkshop , Singapore, Dec. 2017. [10] F . W ang, J. Xu, X. W ang, and S. Cui, “Joint offloa ding and computing optimiza tion in wireless powered mobile-edge computing systems, ” to appear in IE E E T rans. W ir eless Commun. , 2018. [11] A. Al-Shuwaili and O. Simeone, “Energ y-effic ient resourc e allocation for mobile edge computi ng-based augmente d real ity appli cations, ” IEEE W ir eless Commun. Lett. , vol. 6, no. 3, pp. 398–401, Jun. 2017. [12] Y . Mao, J . Zhang, and K. B. Letaief , “Joint task offloadi ng scheduling and transmit power allocat ion for mobile-edge computing systems, ” in P r oc. IEEE W ire less Communicat ions and Networking Confer ence (WCNC) , San Francisco, CA, USA, Mar . 2017. [13] W . Alsalih, S. Akl, and H. Hassancin, “Energ y-awa re task schedul- ing: to wards enabling mobile computi ng o ver m anets, ” in Pr oc. IE EE Internati onal P arall el and Distribu ted Pr ocessing Symposium (PDPS) , Den ve r , Colorado, USA, Apr . 2005. [14] X. Chen, L. Pu, L . Gao, W . W u, and D. Wu, “Exploitin g massiv e D2D collaborat ion for ener gy-ef ficient mobile edge computing, ” IEEE W ir eless Commun. , vol. 24, no. 4, pp. 64–71, Aug. 2017. [15] M. Grant an d S. Boyd, “CVX: Matlab softw are for disciplined con ve x programming, version 2.1, ” Mar . 2014. [Online]. A v ailable : http:/ /cvxr .com/c vx
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment