Selecting Microarchitecture Configuration of Processors for Internet of Things
The Internet of Things (IoT) makes use of ubiquitous internet connectivity to form a network of everyday physical objects for purposes of automation, remote data sensing and centralized management/control. IoT objects need to be embedded with process…
Authors: Prasanna Kansakar, Arslan Munir
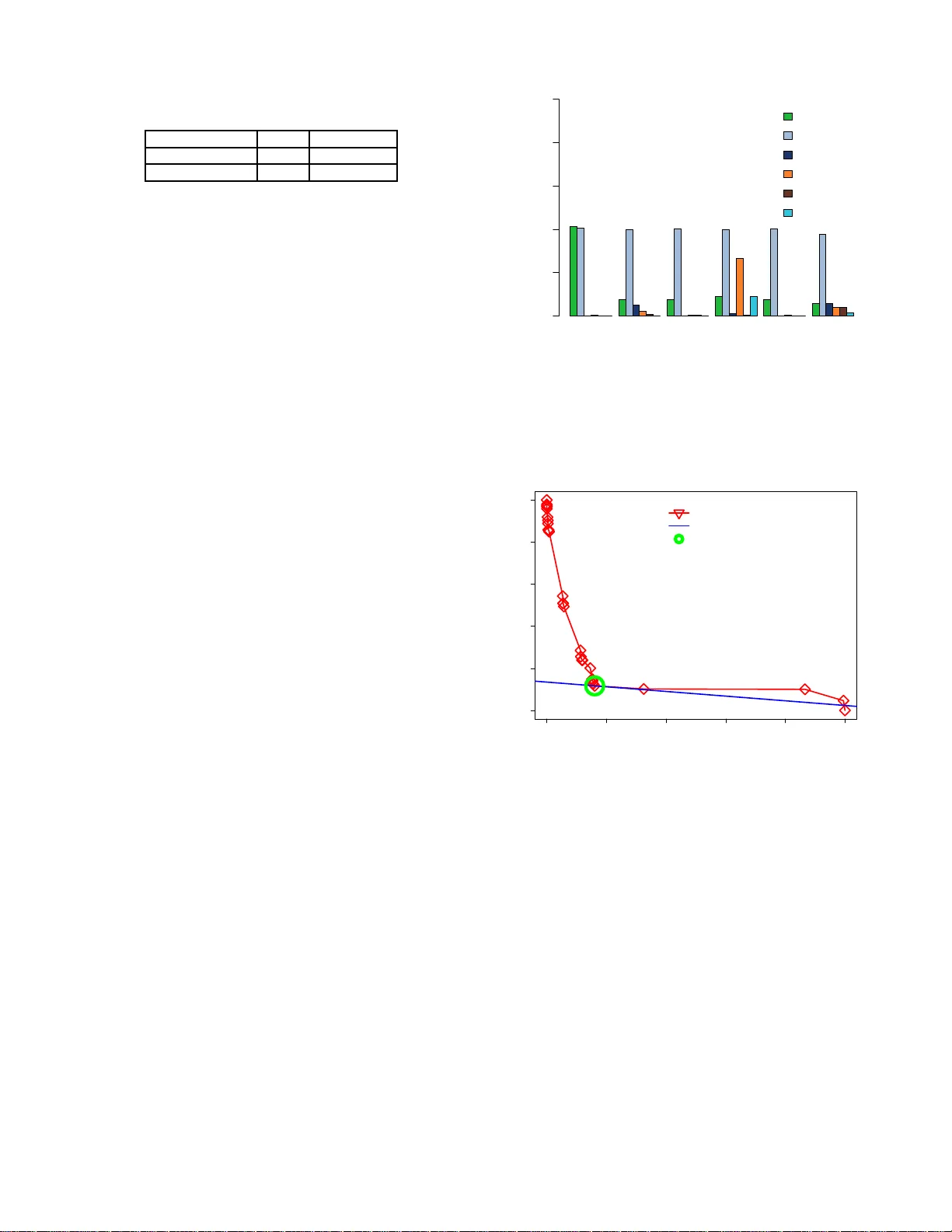
1 Selecti ng Microarc hitecture Configuration of Processors for Internet of Things Prasanna Kansak a r , Student Member , IEEE and Arslan Munir , Senior Membe r , IEEE Abstract —The Internet of T hings (IoT) makes use of ubiqui tous internet connectivity to form a network of everyday physical objects for purposes of automation, remote data sensi ng and centralized management/control. IoT objects need to be embedded wi t h processing capabilities to fulfill th ese services. The design of proc essing units for IoT objects is constrained by various stringent requirem ents, such as perfo rmance, power , thermal dissip ation etc. In order to meet th ese dive rse requirements, a multitude of processor design parameters need to be tuned accordingly . In this paper , we propose a temporally effi cient design space exploration methodology which determines p ower and performance optimized microa rchitecture configurations. W e also d i scuss the possible combinations of these microa rchitecture configurations to f orm an effective two-tiered heterogeneous processor fo r IoT applications. W e ev aluate our design space exploration methodology u sing a cycle-accurate simulator (ESESC) and a standard set of P ARSEC and SPLAS H2 benchmarks. The results show that our methodology determines microa rchitecture confi gurations which are within 2.23%– 3.69% of the configurations obtained from f u lly exhaustive exploration while on l y exploring 3%–5% of th e design sp ace. Our methodology achiev es on av erage 24.16 × speedup in design space exploration as compared to fu lly exhaustive exploration in findin g power and performance optimized micr oarchitecture configurations for processors. Index T erms —Internet of Things (IoT), d esign space exploration, micro architecture, tunable processor p arameters, cycle-accurate simulator (ESESC), P ARSEC and SPLAS H2 benchmarks I . I N T R O D U C T I O N A N D M OT I V A T I O N T HE internet h as g r own rap idly in both enterprise and consume r markets. This has given rise to th e Internet of Thing s (IoT) wherein e veryday physical o bjects are interconnected through a commu nication network for purpo ses of automa tio n, remote data sensing and cen tralized managem ent/control. The Io T creates an intelligent, invisible network fabric that can b e sensed, controlled and pro g rammed which allows objects in IoT ec o system to co mmunicate, directly o r indirectly , with each other or th e In ternet [1]. The “thin gs”, in the scop e of IoT , are IoT enable d objects co ntaining sensing and actuating elements along with embedd e d ha rdware and sof tware componen ts wh ich facilitate data aggregation , network con nectivity and security . Each IoT enabled object is d esigned to perform an application specific task using data gath e r ed by itself or using inform ation made av a ilab le to it throug h o ther objects in the network. There has been widespr ead deploymen t of Io T o bjects in recent years in various application s like h ealthcare, industry , tran sportation The authors are with the Department of Computer Science, Kansas State Uni versi ty , Manhatta n, KS e-mail: { pkansakar @ksu.edu, amunir@ksu.edu } etc. It is estimated that 6. 4 billion connected end -devices ar e in use in th e year 2016 [2], with the nu mber expe cted to rise to 26 billion b y the year 2 0 20 [1]. The massive d eployment of IoT objects r esults in generatio n of large volumes of data. Data com munication , p rocessing, real-time analy sis and security of such large volumes o f data are imp ortant issues that need to be resolved fo r efficient growth of the Io T ecosystem in th e years to come. In the current IoT m odel, IoT end - devices are designed to b e as simple a nd as cost effecti ve as possible. Thus, they ar e designed with limited processing capab ilities, just enough to securely conn ect and offload data to the c lo ud. Almost all complex data man agement function alities suc h as data filtering and analysis are delegated to cloud datacen ters, the core units of the IoT model. W ith th e g rowth in d ata volume in the IoT ecosy stem , there r ises se veral significan t ch allenges which r e nders this mo del infe a sib le. W e list her e three such challenges. • Network Overload - Core network bandwidth is a vital resource in the IoT eco system wh ich must b e used efficiently . With ever increasing num b er of IoT o bjects, relaying data over the co re ne twork to the cloud, the network is sev erely overloaded. Ne twork overloads introdu c e latency in critical data processing oper ations which impac t most IoT applica tio ns such as hea lthcare and transportatio n that require real time data pro cessing. • Data security - D a ta commun ic a tion in the IoT ecosystem mostly occurs over th e public network infrastru cture. In order to en su re secu re data com munication , several complex security proto cols m ust be a p plied to th e data. The volume of d ata requirin g secur ity increases as th e number of Io T o bjects deployed in the IoT ecosystem increases. Ap plying com plex security protocols to large volumes of data r e quires extensiv e computing ope rations which cann ot be m atched by th e energy budget of I o T objects. • Upgradability - As the IoT lan dscape continu es to ev olve, it beco mes necessary to upgrade Io T deploymen ts in frequen t period s. IoT objects must be designed to suppo r t hassle fr ee additio n of new f eatures via remote access. In an ideal IoT model, IoT objects must b e able to up grade to new , more complex featu res witho ut deployment of ne w Io T objects and without any d irect hu man in volvement. W ith limited processing ability , ad dition of new featu res to existing Io T objects m a y be challenging or even infeasible. The ch allenges posed by the cu r rent IoT model can b e overcome by adding pro cessing capab ilities inside or lo cal 2 to I oT objec ts [3]. With the add ed pro cessing units, data managem ent oper ations suc h a s filtering and analysis can be carrie d out within the local n e twork. IoT ob jects can thus, co m municate summaries of info rmation, obtained fro m filtering the aggregated data, to the clou d. This contributes significantly to freeing up the core ne twork b andwidth. The reduction in data volume also redu ces the energy expend iture on data secur ity as less data requ ires lesser number of computin g oper ations to secu re. Ha ving more processing ability also makes Io T deployments m ore flexible to upgrad es as newer featur e s can be added witho u t significantly burdening the system. Processing units interfaced with IoT o b jects require an optimal balan ce b etween power and perf o rmance [4]. Since many IoT objects are battery powered, it is desirable that these objects operate for th e ir en tire lifetime with the batter y they are deployed with (e.g. medical sensors implan ted in to a patient’ s body via in v asi ve surgical pr o cess). A lth ough gr eat p rogress has been made in batter y technology , batteries are still not able to keep p ace with the demands of modern electronics [5]. So , power optimization mu st be co nsidered in p arallel with per formanc e o ptimization. T IER 1 T IER 2 I NTERCONNECT H OST P ROCESSOR HIGH PERFORMANCE OPTIMIZED I NTERF ACE P ROCESSOR S ENSING E LEMENTS A CTUA TION C ONTROL LOW POWER OPTIMIZED I NTERF ACE P ROCESSOR S ENSING E LEMENTS A CTUA TION C ONTROL LOW POWER OPTIMIZED I NTERF ACE P ROCESSOR S ENSING E LEMENTS A CTUA TION C ONTROL LOW POWER OPTIMIZED Fig. 1. T wo-tiere d hete rogeneou s processor archit ecture model for IoT For incorporatin g higher lev els of power op timized perfor mance in IoT deploym ents, a two-tiered heterogene o us processor arch itecture is suitable [3] [6]. This tw o-tiered architecture , shown in Figure 1, consists of a host pro cessor , optimized f o r high pe rforman ce, interfaced with a n umber of interface pr ocessors, optimize d for low power o peration. The interface pr ocessors collect data fro m data- sensing elem ents and control actuating elements. These processors are a lways operated in active mo de beca use their lo w p ower o peration does no t se verely impact battery life . Higher end function , such as filtering and an alysis of data, and, imp lementation of complex security pr otocols are perfo rmed by the ho st processor . Since these o perations are in frequen t, th e power hungr y h ost p rocessor is m ostly op erated in sleep state and only activ ated intermittently for limited duration s. Designing efficient embedde d processors with p ower - optimized perfor mance, for use in IoT objects, is a tedious pr ocess. Prev enting high per forman c e processors from v iolating th e power budget requ irements dictated b y the mar ket is an enor mous design c h allenge [7]. The oppor tunities fo r optimizing a processor design for power are the g reatest at the architecture lev el [7]. Thu s, power and perfo rmance optimizatio ns sho uld b e perfo rmed while defining the micro architecture con figuration of proc essors. Th e microarch itecture configur ation consists o f se veral processor design para m eters each o f which has to be tuned based o n the im pact it has on the overall power and p erforma n ce of the processor . Selecting a microar chitecture c onfiguratio n in volves rigorous design space explor a tion over a search space consisting of all p ossible setting s for tu nable processor d esign parameters. Th ere are two main challenges that need to be addressed in th is process. Firstly , the design space exploration metho dology , employed to select micro architecture configuratio ns of processor s f o r IoT objects, m u st be tem porally efficient. Lon g pro cessor design time leads to long time to market wh ich results in lo wered profits [8] [ 9] and sho rter prod uct life cycle [ 9]. The Io T market also lacks accepted industry standards so, tho se who get to the market first have th e greatest op portun ity to influence those standard s [9]. Secondly , the design space exploration m ethodolo gy must balance p r ocessor power consum ption with p erform a n ce, which a re conflicting design metrics [10]. It is not p ossible to h av e optimal solutions f o r optimiz a tion pro blems with conflicting design metrics. Th e optimization prob le m shou ld instead be mod eled as an Optimal Production Frontier p r oblem also k n own as Pareto Efficiency [11] pr o blem. Multiple solutions are obtained for such p roblems wh ere each so lu tion fa vors one of th e co n flicting metrics. Th e design sp a c e exploration method ology must intelligently choo se the best trade-off solution based on applica tio n sp e cific requ ir ements. In this p aper , we propose a tem porally efficient desig n space exploration m ethodolo g y f or determinin g power and perfor mance optimized m icroarchitectu re co nfiguratio n s of embedd e d processor s used in IoT objects. W e use a combinatio n o f exh austi ve, greedy a nd one-sho t sear ch methods to perfor m design space exploration. W e verify the effecti veness of o ur methodo logy b y testing it on a cycle accurate simulator using a large set of standard benc h marks with varying workloads. The main co ntributions of our paper are: • W e propo se a temp orally effi cient design space exploration methodo logy to fin d microar chitecture configur ations for low-power and high-per f ormance optimized embed ded p r ocessors used in Io T objects. • W e inclu de a thr eshold parame te r in the design space exploration metho dology which ca n be manipu lated by the system d esigner to control design time based on tim e to market constrain ts. • W e propose exhaustive, greedy and one-shot search algorithm s which y ield microarc h itecture co nfiguration s which are 2.2 3%-3.69 % of the m icroarchitectu re configur ations obtain ed from fully exhaustive search. • W e distinguish between d ifferent micro architecture configur ations based on th e size and type of bench m ark used, and, relate them with po tential u se cases in IoT . The remaind er of the paper is organized as follows. In Section I I, we present a revie w of related work. W e de scr ibe our design space exploration metho dology in Section III and 3 elaborate on its different ph ases in Section IV. In Section V we describe the cycle-accur a te simula to r and bench m arks used to test our methodo logy . W e discuss the results in Section VI and p resent o u r conclusions and future research dir ections in Section VII. I I . R E L A T E D W O R K Sev eral SoC design com panies hav e released articles on technique s of in creasing p rocessing cap abilities in IoT objects. Some articles g uide the selection of pr ocessors for IoT objects while o thers describe low p ower optimized processor architecture s for Io T deploymen ts. ARM propo sed a processor a rchitecture consisting of multiple homoge n eous pr ocessors in a s ingle IoT object each serving a different pu r pose [6]. They defined a sy stem with three Cortex-M p rocessors, one to handle network connectivity , one to manag e interface with sensors and actuators an d one as a host p rocessor co ntrolling the oth e r two. They stated that mu ltiple processors are b etter for lowering power co n sumption in IoT o b jects since o nly the p rocessor serving the current task would be in a cti ve mode while the rest would be in sleep mode. ARM also pr oposed a guide to selecting micro controller s for IoT objects [12]. In this guide, th ey argued that high -end microco ntrollers were suitable for Io T d eployments for tw o rea so ns. Firstly , high- end micro controllers com plete p rocessing tasks soon er an d can en ter sleep mode to conserve power and secondly , larger flash and RAM sizes av a ilab le with hig h-end micr ocontro llers facilitate implementatio n of c o mplex n etworking p rotocols without addition o f any new processor s in the sy stem . T h ese articles clearly demo nstrate the n eed for having m ore p ower - optimized perf o rmance in IoT deploym ents. Synopsys also propo sed the use of mu ltiple proc essors in IoT deploymen ts [13]. They described the use o f two- tiered processor architecture in IoT ob jects – u ltra low power embedd e d pro c e ssors used to interface with sensing elem e nts to collect, filter an d pr ocess data and host processor u sed to m anage embedd ed processors. Their pr ocessor arch itecture lowered power co nsumption by keeping power hun gry host processor mostly in sleep mode, similar to the concept used by ARM. Synop sys also discussed optimiza tio n of pr ocessors using configura b le har dware extensions fo r sensor applications [13]. They stated th at ad d ing custom hardware extension s for executing typical sensor fun c tions redu ces the pr ocessor cycle count requir ed to execute sensor application s. The red uction in cycle count lowers energy co nsumption either by lowering the cloc k freque n cy and keeping the same execution time, or having the same power but sh o rter execution time. Apart from research carried out by SoC de sig n com panies, processor design has also been extensi vely stud ied in academia [14] [15]. T h ere a re many resear c h works in literature in volving optimized p rocessor design. Most works employ design space explora tion [1 6] [1 7] techniques utilizing searc h meth ods like exh austi ve and greed y search and optimizing algor ithms like gene tic and e volutionary algorithm s. Givar gis et al. [18] developed an e xploration methodo logy n amed PLA TUNE (PLA Tform TUNE r) that carried out e xhaustive searche s in two stages: first, over clusters of strongly in te r connected param eters to obtain Pareto-optimal configu rations local to each clu ster , an d second, over all the clusters to o b tain a glo bal Pareto- optimal solutio n. Th e appr oach could explo re design spaces as large as 10 14 configur ations, but it took an ord er of 1- 3 days to complete. Palesi et al. [19] argued that the high exploration time for PLA TUNE was du e to the fo rmation of large partial search spaces in the clustering p rocess. Palesi et al. improved the PLA TUNE explo ration metho dology b y introdu c ing a ne w thresho ld value that distinguished between clusters based o n th e size of their partial search-space. Exhaustive search method was used for clusters with partial search-spaces smaller than the thresh o ld value and a genetic exploration algorithm was used for larger spaces. Thr ough this im provement, th ey were a ble to achieve 80 % reduc tion in simulatio n time while still remain ing within 1% of th e results o btained from exhau sti ve search . Genetic algorithms were also used in the system MUL TI CUBE, by Silvano et al. [20]. Th e MUL TICUBE system define d an autom atic design space exploration a lgorithm that co uld quickly determine an approx imate Pareto fron t fo r a given design requirements. Munir et al. [ 21] pro posed an other alternative to overcome the overhead of exhau sti ve search in their work on dyn amic optimization of w ir eless sensor netw orks. Their approach was d ivided into two phases. In the first phase, a one-sho t search algorith m selected initial p arameter settings an d further ordered th e pa r ameters based on their significance tow ards the application req u irements. In the second ph ase, a g reedy algorithm was u sed to search the d e sign spac e . Their appro ach yielded a design con figuration th at was within 8% o f the optimal configur ation while only exploring 1% of the design space. In this paper, we improve on the work carried out by Munir et al. [21]. W e le verage a similar ap p roach to design space exploration but add two new p hases: a set-partition in g ph ase and an exhau sti ve search phase. T he ad dition of th e exhau stive search phase aim s at inc r easing the degree of closeness to the optimal solution by explorin g a larger portion of the design space, a s argued by Silvano et al. [20]. T he limit on the number of con fig urations c o nsidered in th e exhaustiv e search is determined by the set-partition ing phase that uses a threshold value [19]. I I I . M E T H O D O L O G Y Our design space exploratio n m ethodolo gy for determining optimal microarch itecture configuration of embedd ed processors fo r I oT is shown in Figure 2. Our methodo logy is implem ented in four phases – initial o n e-shot search configur ation tuning and parameter significance, set- partitioning , exhaustive search configu ration tun ing and greedy search co nfiguration tuning . The initial one-shot search c onfiguratio n tuning and parameter significance phase is carried out by the initial one-sho t search config uration tuning module and the parameter significance ordering module. The m icroarchitec tu re configur ation parameter settings set, which consists of all the po ssible settings for each tun able m icroarchitectu re parameter, is provided as in put to the initial one-sho t search 4 Microarchitecure con fi guration parameter settings set Initial one-shot con fi guration tuning module Cycle - accurate simulator Test benchmarks Parameter signi fi cance ordering module Set partitioning Separated exhaustive search set Separated greedy search set Exhaustive search con fi guration tuning module Greedy search con fi guration tuning module Best settings of parameters in exhaustive search set Optimized microarchitecture con fi gurations for processor for IoT Weights for design metrics Exploration threshold Signi fi cance ordered parameter set INPUT OUTPUT INPUT INPUT INPUT Fig. 2. Design space explor ation methodology for determi ning optimal microarch itect ure configurat ion of embedded processor for IoT configur ation tuning module b y the system designer . This module u ses the p a rameter settings set to g enerate initial test configur ations. Each initial co nfiguration is passed to a cycle- accurate simulator . Th e test bench marks fo r ev aluating the microarch itecture co nfiguratio n s ar e provid ed as inpu t to the simulator by the system de signer . The simula to r executes each initial test con figuration sepa r ately fo r each test b enchmark specified. The test bench marks p r ovide varying workload s for testing the initial test configuration s. The sy stem designer also provides the weigh ts for balancin g d esign metrics as input to the simulato r . These weig hts are u sed to spec if y the p referred tradeoff b etween conflicting design metrics. The simulator mo dule ev aluates the initial test configur ations sup plied by the initial one-sho t search configur ation tuning modu le to determine the b est initial setting f or each tunable mic r oarchitectur e pa r ameter . The simulation r esults are forwarded to the parame ter significance orderin g module wh ere the tunab le micro a r chitecture parameters are or d ered based on their sign ificance to the design metrics co nsidered. The ordered set of significance values is comm unicated to the set-pa rtitioning modu le which separates the pa rameters into two search sets – exhaustive a nd greed y . The par a meters are sep arated based o n an exploration threshold value provid e d by the system design er . The exploration thr eshold value is used to contr ol search space for the exhau sti ve search phase of our design space exploration m ethodolo gy . T he exh a u sti ve search phase is the longest phase in the design space exp lo ration methodo logy and pro cessor d esign time c a n be sign ificantly altered by varying this exploratio n thresho ld value. The microarchitectur e parameters separated out in th e exhaustiv e search set are communicate d to th e exhaustive search con figuration tuning mod ule. This m odule generates test co nfiguration s using all possible combin ations of tuna ble processor d e sign para meters. Th e parameters which are not in th e exhaustiv e search set retain their best setting s fr om the initial one- shot sear c h configura tion tunin g pr ocess. These test configur ations are evaluated o n the cycle-accu rate simulator to determine a test configuration p ossessing the best tradeoff between the conflicting design metrics consider e d. The best settings f or the micr o architecture p arameters in the exhaustiv e search set are then commu nicated to the greedy searc h configur ation tun ing module. The greed y search config uration tun ing modu le gen e r ates test configuration s u sing the p rocessor d esign parameters separated out in the gr e edy search set. A greedy search algorithm (r efer Section IV -D ) is used to generate these test configuration s. The microarch itecture param eters in th e exhaustiv e search set retain the ir best setting ob ta in ed fro m the exhaustiv e sear ch simulation p rocess. Th e parameters wh ic h are in neither of th e two search sets, retain their b est settings from the initial one-sh ot search co nfiguratio n tuning p rocess. The best c onfiguratio n ob tained at the end of the g r eedy search co nfiguratio n tun ing proce ss is communicated bac k to the pro cessor d esigner as the optimal microar chitecture o f the processor with the preferr ed tradeoff betwee n the conflicting design metrics. A. De fining the Design Space Consider n num ber of tunable p a rameters are av ailable to describe the microar chitecture configuration of an emb edded processor for IoT . Let P be the list of these tu nable pa rameters defined as the f ollowing set: P = { P 1 , P 2 , P 3 , · · · , P n } (1) Each tunab le parameter P i [where i ∈ { 1 , 2 · · · n } ] in the list P is the set of po ssible settings for i th parameter . Let L be the set containing the size of th e set of possible settings f o r each param eter in list P . L = { L 1 , L 2 , L 3 , · · · , L n } (2) such that, L i = | P i | ∀ i ∈ 1 , 2 , · · · , n (3) where | P i | is the cardinal value o f set P i . So, each parameter setting set P i in th e list P is d efined as follows: P i = { P i 1 , P i 2 , P i 3 , · · · , P iL i } ∀ i ∈ { 1 , 2 , · · · , n } (4) The values in the set P i are arrang ed in ascending order . The state space for design space explo ration is the collec tio n of all the possible configur ations that can be obtain ed using the n pa r ameters. S = P 1 × P 2 × P 3 × · · · × P n (5) 5 Here, × represents the C artesian produ ct of lists in P . Throu g hout this paper, we use the term S to denote the state space com p osed o f all n tun able parameter s. T o main tain generality , when refe r ring to a state space com posed o f a tunable parameter s where a < n , we attach a subscript to the term S . S a = P 1 × P 2 × P 3 × · · · × P a ∀ a < n (6) W e note th at the state space of a tunab le parameters d oes not constitute a complete d e sig n co nfiguration and is only used as an intermed iate when defining o u r m ethodolo gy . W e also reserve the u se of × op erator in the following manner: S a = S a × P i ∀ i ∈ { 1 , 2 , · · · , n } (7) This represents the extension of th e state space S a to include one new set of parameter settings P i from the list P . T h is operation increases the numb er of tunable parameters in state space a by one. When ref erring to a d esign configur ation that belongs to the state space S , we use the term s . W e attach sub scripts to s to refer to specific design co nfiguratio n s. For example, a state s f that consists of the first setting of each tunable par ameter can be written as: s f = ( P 11 , P 21 , P 31 , · · · , P n 1 ) (8) Similarly , to denote an incomp lete/partial design configuration of a tu n able param eters we use the term δ s a . B. B enchmarks Each o f the co nfiguration s, selec te d from the state space S by our m ethodolo g y , is tested o n m numb er of test ben chmarks. The design metrics f o r each simulated configur ation is co llected separately f o r each ben chmark. C. Objective Functio n In our metho dology , d esign c o nfiguratio n s are comp ared with each other based on their objective f unctions. The objective fu n ction of a design co nfiguration is the weigh ted sum of the nor malized desig n m etrics obtained after simulating that d esign con figuration. Let o be the n u mber of design metrics and V be the set o f norm alized values of d esign metrics which are obtained from the simulation. V k s = { V k s 1 , V k s 2 , V k s 3 , · · · , V k so } ∀ k = 1 , 2 , · · · , m (9) Let w b e the set o f weights for the d e sig n metrics based o n the r equiremen ts o f the targeted ap plication. These weights are set by the system design er . w = { w 1 , w 2 , w 3 , · · · , w o } (10) such that, 0 ≤ w l ≤ 1 ∀ l = 1 , 2 , · · · , o (11) and, X w l = 1 ∀ l = 1 , 2 , · · · , o (12) T ABL E I L I S T O F S Y M B O L S Symbol Description n Number of tuna ble microarc hitec ture parameters P List of tunable microa rchite cture parameters P i Set of possibl e sett ings for i th tunable microarchite cture paramete r L Size of set of possible setting s for each tuna ble microarch itect ure paramete r L i Cardina l va lue of set P i S State space for design space explorat ion S a Parti al/Inc omplete state space s tag State in state space S with ‘tag’ identifier δs a State in partial state space S a m Number of test bench marks o Number of design metrics V k s Set of normalize d value s obtained for design metric s from simulatio n of state s for k th benchmark w Set of weights for design metrics w l W eight for l th design metric F k s Objecti ve functio n obtained from simulating state s for k th benchmark The ob jectiv e function F of a design config u ration s fo r a test benchm a rk k is defined as follows: F k s = X w l V k sl ∀ l = 1 , 2 , · · · , o (13) The optimization problem , consider ed in this paper, is to minimize the value of th e objec tive fun ction F . The d esign metrics are chosen such that the m inimization of their values is the fav orable design ch oice. For example, when considerin g the perfor m ance m etric, the design go al is to maximize performan ce. T o mo del this into the ob jectiv e function which w e use execution time to measure p erform a nce. Minimizing execution time would fit with minimizin g the objective function while still mod eling th e design goa l of maximizing performan ce. The optimization pr oblem for each test bench mark k is defined as follows: min. F k s s.t. s ∈ S (14) T able I pr esents the sy m bols established in this sectio n in list form. I V . P H A S E S O F M E T H O D O L O G Y Our proposed d e sign space explora tio n method ology consists of fo u r distinct phases. In this section, we e lab orate on the steps in volved in each phase using th e notatio n set up in Section III. A. P hase I : I n itial One-S hot Sear ch Config uration T un ing and P arameter S ignifican c e In this phase of ou r m ethodolo g y , best initial setting for each tunable microarch itecture p arameter in set P is deter mined by u sing a one-sho t search con figuration tunin g process. The one-sho t search pro cess is based o n single factor analy sis which is an effecti ve heuristic appro a c h used in design space exploration [ 22]. Unlike sin g le factor analysis wherein parameters can have on ly tw o settings, a ze r o value and a non-ze r o v alue setting, o ne-shot search works on parameters 6 with m o re than two no n-zero value settings. In on e - shot search process, p arameters are evaluated on a on e by one basis. T wo test con figurations are genera ted f or each pa rameter, one with the first setting a nd one with the last setting s f rom the list of settings for th e curren t parameter . The remaining par a m eters are arb itrarily set to th e ir fir st setting fr o m their corresp o nding list of settin g s. Algorithm 1 : Initial One-Sh ot Search Con fig uration T u n ing and Parameter Significance Input: P - List of T unable Parameters Output: B - Set o f Best Setting s; D - Significance of Parameters with respect to Objecti ve Function 1 for i ← 1 to n do 2 s f = { P i 1 } 3 s l = { P iL [ i ] } 4 for j ← 1 to n do 5 if i 6 = j t hen 6 s f = s f ∪ { P j 1 } 7 s l = s l ∪ { P j 1 } 8 end 9 end 10 for k ← 1 to m do 11 Explore k th benchm a rk using configuration s f 12 Calculate F k s f 13 Explore k th benchm a rk using configuration s l 14 Calculate F k s l 15 D k i = F k l − F k f 16 if D k i > 0 then 17 B k i = P i 1 18 else 19 B k i = P iL [ i ] 20 end 21 end 22 end The steps in volved in initial one-shot search configuratio n tuning and d e termining parameter significance are deta iled in Algorithm 1. Th e first and last te st configu rations gener ated for e valuating a tunable microarchitec ture p arameter, P i in set P , are d enoted by s f and s l , respectively . These co nfiguration s are tested o n the cycle-accu rate simu lator . From the results of the simulation , ob jecti ve functions, F s f and F s l correspo n ding to s f and s l , respectively , ar e dete r mined. T he o bjectiv e function values are used to determine best initial setting as well as significance of each micr oarchitectur e parameter . The magnitud e of the difference b e tween F s f and F s l , which is stored in param eter significance set D (line 15), is u sed as parameter sign ificance. Th e hig her the magnitud e o f a difference D k i , i ∈ { 1 , 2 , 3 , . . . , n } for a bench m ark k , k ∈ { 1 , 2 , 3 , . . . , m } , the highe r is the significance of parameter P i to the work load characterized by benchm a rk k . Th e sign o f the difference between F s f and F s l is used to pick th e best initial setting for parameter P i . If the difference is p ositi ve, then the first setting of p arameter P i is chosen as the best setting, o therwise the last setting is chosen. Th e best settings for the parameter s are stored in th e set of best settin g s B k i (lines 17 and 19). B. P hase II : Set-P artitionin g Algorithm 2: Set-Partitionin g Input: D - Sig nificance of Parameters towards Objec tive Function; I - Index Set; T - Exhaustive Search Threshold Factor Output: E - Set of Parameters for Ex haustiv e Search; G - Set o f Parameters for Greed y Sea r ch 1 E = ∅ and G = ∅ 2 for k ← 1 to m do 3 sortDescending ( | D k | )- s.t. ind ex information of the sorted values is pre served in I k 4 sort( P k ) and sort( L k ) w .r .t. in dex informatio n in I k 5 num E = 1 and i = 1 6 while num E ≤ T do 7 num E = num E × L k i 8 if num E ≤ T t hen 9 E k = E k ∪ { P i } 10 i = i + 1 11 else 12 break 13 end 14 end 15 num G = ceil (( | P k | − |E k | ) / 2 ) 16 while num G > 0 do 17 G k = G k ∪ { P k i } 18 num G = num G − 1 19 i = i + 1 20 end 21 end The set-p a r titioning phase, presen ted in Alg orithm 2, shows how the parameter significan c e values d etermined in the first ph ase of our meth odolog y are u sed to separ ate the list o f tunab le microar c hitecture parameters into exhaustiv e and greed y search sets. First, the parameter significance set | D k | for each benchmark k, k ∈ { 1 , 2 , 3 , . . . , m } , is sor ted in descendin g o rder of magnitu d e using the sortDescending ( | D k | ) function . The ind ex inf ormation of the sorted values is preserved in a set o f ind exes I k (line 3). For example, if the fifth entry D k 5 has the greatest value, D k 5 will becom e th e first entry in the set D k and first entry in the set of indexes I k will be 5, th at is, I k 1 = 5 . The set of indexes, I k , is u sed to sort the list of tunable m icroarchitectu re parameters, P k , and list of set sizes, L k . After sor tin g, the parameters with higher significance lie to wards the start o f the set and the pa r ameters with lower significance lie tow ards the end of the set. The list of param eters is then divided into three subsets, exhaustive search , gre edy search and on e-shot search sets. The exhaustive search set gets p arameters with the highest significance. T he number o f parameters separated into the exhaustive search set depends on the explor ation threshold value, T , provide d by the system designe r . The thr eshold value 7 T limits the size of the p artial sear ch space of the exhaustive search set, nu m E (line 6). After separating out exhaustive search set, the param eters remaining in the parameter list are separa te d in to greedy search and on e-shot search sets. The list o f re maining parameter is divided into two halves (lin e 15) and the upper half ceil (( | P | − |E k | ) / 2) is separ ated as th e greedy search set and the lower ha lf is separated as on e-shot search set. W e observe emp irically that dividing the list of remaining p arameters into halves provid es efficient d esign space exploration withou t significantly compro mising the solution qu ality . The parame ter s separated as o n e-shot search set ar e n ot explore d f urther an d are left at the best settings determined fo r the m in Algo rithm 1. C. Phase III : E xhaustive Sea rc h Configuration T u ning Algorithm 3: Exhau sti ve Search Input: P - List of T unable Parameters; B - Set of Best Settings fo r One-shot Search; E - List of Parameters for Exh austiv e Search Output: B - List o f Best Settings for One-sho t and Exhaustive Search 1 s E = ∅ 2 δ s E = ∅ and δ s E ′ = ∅ 3 for k ← 1 to m do 4 F k s b = ∞ 5 for i ← 1 to n do 6 if P i / ∈ E k then 7 δ s k E ′ = δ s k E ′ ∪ { B k i } 8 end 9 end 10 for i ← 1 to n do 11 if P i ∈ E k then 12 S k E = S k E × P i 13 end 14 end 15 for j ← 1 to | S k E | do 16 δ useds k E j is a pa r tial configura tio n in state space S k E 17 s k E = δ s k E j ∪ δ s k E ′ 18 Explore k th benchm a rk using configuration s k E 19 Calculate F k E 20 if F k s E < F k s b then 21 F k s b = F k s E 22 B k = s k E 23 end 24 end 25 end Algorithm 3 details the steps in volved in the exhau sti ve search process. The exhau sti ve search process determ ines the best setting s for the par a m eters in the exhaustive search set E . First, the settings for the param e te r s that are no t in the exhaustiv e search set E are assign e d ( line 7). These parameters are assign ed th eir b est setting s fro m th e set of best settings B k i as de te r mined in the initial one-shot search configur ation tuning pro cess describ ed in Algorithm 1 . These settings make up the partial test design configuration δ s E ′ . Next, a partial state spac e S E is fo rmed for the parameters in the exhausti ve search set E (line 12). Every possible partial test design con figuration, δ s E j (line 1 6), in the par tial state space S E , is co mbined with the partial test design configur ation δ s E ′ to form comple te simulatable test design configur ations. Each comp le te test design configu ration is ev a lu ated on the simulator . An objective function value, F s E , is obtained for each comp lete test design configur ation, s E , from the simu lato r . The algorithm keeps track of the smallest objective fun ction value encoun te r ed in the search pro c e ss in F s b which re p resents the best ob jecti ve function value. When a d esign c onfiguratio n results in an objective f unction that has a value less than F s b (line 20), then F s b is chang e d to the new minimum value and the set of best setting s B is updated with the co rrespond ing design con figuration . D. Ph ase IV : Greedy Sear ch Con figuration T un ing In the final phase of our methodo logy , describ ed in Algorithm 4, the best settings for the parameters in greedy search set G are determin ed. For each par a meter in the set G , the sign of the param eter significanc e is ch ecked to d etermine whether the first setting or last setting was chosen as the best setting in the first phase o f our methodo logy . I f the sign of parameter sig n ificance is po siti ve, then it indicates that first setting fo r th at param eter yields a smaller objective fun ction as com pared to the la st. If the sign is negative then it indicates that the last setting for that p arameter yields a smaller objective function as comp ared to the first. W e assume that the setting that yields th e smallest objectiv e fun ction lies closer tow ards the setting that yields the smallest objectiv e function in the initial o ne-shot sear ch c onfiguratio n tu n ing pr ocess. T o ensure that th e search pr ocess starts fro m the setting that yielde d the smallest objective fu nction in the in itial o ne-shot search configur ation tun in g pr ocess, we sort the set of parameter settings P i in descending ord er ( f or last setting as best setting) or left u nchange d in de fault ascending order ( for first setting as best setting ) (line 8). In th e greed y search process, the par ameters in the g reedy search set are co nsidered on e a t a time. First, a partial test design con figuration δ s G P ′ is fo rmed using the exhaustive search set, the one - shot search set and the n o n-curr ent parameters in greed y search set. The parameters in the exhaustiv e sear c h set, E , are assigned their best values as determined in the exhaustive search configuration tuning process. The parameters in the one-sho t search set retain the best settings dete r mined in the initial o ne-shot configuratio n tuning process. The non-cur r ent parameters in the g reedy search set, G , are assigned be st settings in one of two ways. If the non -curren t param eter has alrea dy b e en processed by the greedy search optimization process, then the parameter is assigned the b est setting ob tained f rom that p r ocess. If the non-cu rrent par a meter has not b een processed yet, then the parameter is assigned the b e st setting obtained f rom the initial one-sho t search co nfiguration tuning pro cess. 8 Algorithm 4: Greedy Search Input: P - List of T unable Parameters, D - Significan ce of Parameters towards Objec tive Function, B - Set of Best Settings for On e-shot and Exh austi ve Search, E - Set of Parameters for E x haustive Search, G - Set of Parameters for Gree d y Search Output: B - Comp le te set of Best Settings 1 s G = ∅ 2 δ s G ′ = ∅ 3 G P = ∅ 4 for k = 1 to m do 5 F k s b = ∞ 6 for i ← 1 to n do 7 if P i ∈ G k then 8 if D k i < 0 then 9 G P = sortDescen ding ( P i ) 10 end 11 for j ← 1 to n do 12 if P j 6 = G P then 13 δ s k G ′ P = δ s k G ′ P ∪ { B k j } 14 end 15 end 16 for l ← 1 to L i do 17 s k G = δ s k G P ′ ∪ { G P l } 18 Explore k th benchm a rk using configur ation s k G 19 Calculate F k s G 20 if F k s G < F k s b then 21 F k s b = F k s G 22 B k i = G P j 23 else 24 break 25 end 26 end 27 end 28 end 29 end The par tial test design config uration δ s G P ′ is th en comb ined with the settings f or the cur rent p a r ameter b eing processed to fo rm the comp lete simulatable test d e sign configu r ation s G (line 17). Th is configuratio n is evaluated on th e cycle- accurate simulator . The re su lting ob jectiv e function , F s G , is compare d with the be st objec ti ve fun ction F s b , which holds the smallest value ob jectiv e function encou ntered thus far in the search pr ocess. Similar to th e exhaustive search proce ss, when a design co n figuration r e sults in an objective function that has a value less than F s b (line 20), the n F s b is chan ged to the new minimum value and the set of best setting s B k i is updated with the correspo nding design con fig uration. However , wh en the search p r ocess en counters a design configuratio n that results in an objectiv e function that h as a value greater th an F s b , then the search p r ocess for the curren t par ameter is terminated and the next parameter in the parameter list G is explored. V . E X P E R I M E N TA L S E T U P W e used the ESESC [23] (En hanced Sup er ESca lar ) simulator to simulate all the test micr o architectur e configur ations genera te d by our meth o dology . The ESESC simulator is a fast cycle-accurate chip multipro cessor simulator . It mode ls an out-o f-order RISC (Red u ced Instruction Set Comp uting) p rocessor ru nning ARM instruction set. W e used benchm arks f rom the P ARSEC and SPLASH2 [24], [2 5] ben c hmark suite to test our methodolo gy . T he P ARSEC an d SPLASH2 ben chmark suite is a co llec tion of standardized benchm arks which pr ovides a diverse range of workloads for ev aluation of pro cessors. W e used the following bench marks from the P ARSEC and SPLASH2 suite to test our meth o dology . P ARSEC Benchmarks : Black scholes, Canneal, Facesim, Fluidanimate, Freqm in e, x 264 SPLASH2 Benchmarks : Cholesky , FFT , LU cb, LU ncb, Ocean cp, Ocean ncp , Radiosity , Radix, Raytrace The method ology phases were imp lemented using PERL [26]. Th e resu lts from th e simu lation pr o cesses were collected in MS Exc e l using Excel-Writer-XLSX [27] tool for PE RL. W e tested ou r d esign spa ce exploration metho dology separately for lo w-power and high-p erforma n ce p rocessor design. W e combined th e microarchitecture configuratio ns obtained f rom th ese tests to form a two-tiered heterogen eous processor architectur e. Th e microarchitec tu re configur ation obtained fr om the low-power processor design tests wer e used to imp lement the low-power op timized interface processors, the lower tier of the two-tiered architecture. The micro a rchitecture configura tio n obta in ed from the hig h- perfor mance processor design tests wer e u sed to implemen t the high -perfo rmance optim ized host pro cessor , the upp er tier of the two-tiered arch itecture. T ABL E II M I R C OA R C H I T E C T U R E C O N F I G U R A T I O N PA R A M E T E R S E T T I N G S S E T Parame ter Name Set of Settings Low-P ower High-Perf ormance Cores 1, 2, 4 2, 4, 8 Frequenc y (MHz) 75, 100, 125, 150 1700, 2200, 2800, 3200 L1-I Cache Size (kB) 8, 16, 32, 64 8, 16, 32, 64, 128 L1-D Cache Size (kB) 8, 16, 32, 64 8, 16, 32, 64, 128 L2 Cache Size (kB) 256, 512, 1024 256, 512, 1024 L3 Cache Size (kB) 2048, 4096 2048, 4096, 8192 The list of microarchitec ture parameter s considere d for testing our methodo logy along with the set of possible settin g s for each param eter is listed in T able II. W e used d ifferent ra nge of settings f or low-power and high -perfo r mance pro cessor design. The range of settings listed in T ab le II under low- power d esign were used for the design of low-po wer o ptimized interface p rocessors. The design space cardinality for low- power processor design was 1,1 52 config u rations. The range of setting s listed in T able II under high-p erforman ce design were used fo r the d e sign of high-p e rforman ce o ptimized host processor . T he design space cardinality fo r high-p erforman ce processor design was 2 , 700 configur ations. 9 T ABL E III W E I G H T S F O R D E S I G N M E T R I C S Configuration Powe r Perf ormance Low-Po wer 0.9 0.1 High-Performa nce 0.1 0.9 W e u sed power and per formanc e as design metrics to ev a lu ate the microarch itecture co n figuration s for both low- power and high-p erforman ce op timized processors. W e u sed normalized value of total dynamic power an d leakage power [28] across all th e cores in the pro cessor as th e power metric and the normalized value of total ex ecution time as the perfor mance metric. W e used the weights presented in T able III to specify the p reference for the conflicting design m etrics of power and perfor mance. The linear objective functio n u sed for the e valuation of the test m icroarchitectu re config urations was: F = w P · P + w E · E (15) where, P = D y namic P owe r + Leak e d P ower E = T otal E xecution T im e (16) V I . R E S U LT S In this section, we pr esent the r esults ob tained while testing our metho dology . This section is d i vided into two sub sections. In the first sub section, we present results to validate our design space explo ration me th odolog y and in the second subsection, we discuss some of the ap plicability of som e of th e microarch itecture co n figuration s to importan t Io T use cases. A. E valuation of design space explor ation methodo logy For evaluating our meth odolog y , w e co mpared our microarch itecture configu ration re su lts with tho se obtained from a fully exhausti ve search of the d esign space. W e tested our method ology with an exploration thr eshold of T = 1 50. This threshold value is an upper b ound which lim its the par tial state space f or th e exhau sti ve search p hase of o ur m ethodolo gy . 1) P arameter significan ce: Figure 3 shows the normalized values of p arameter significance for different P ARSEC benchm a rks. The nor malization is carried out using the maximum values fo r total p ower and total execution time obtained in th e initial on e-shot searc h con figuration tu n ing process. The p arameter significan ce values are calculated in the first phase o f our m ethodolo gy , initial one-shot search configur ation tun in g. W e obser ve th a t the significance of each o f the tunable processor design parameter s varies b a sed on the type o f work lo ad offered by the test benchmark s. For each of the test b enchmark s, there are at most th ree significant processor d esign para m eters. W e n ote that the operating frequen cy is the processor design par ameter with the highest sign ificance for most of the test b enchmark s followed by core cou nt, which is the secon d most significant d esign parameter . For c e rtain test benchm a r ks, the size of the L1-I cache and L1-D cache are also h ighly significant to ov erall design. The large significanc e in cache sizes is a result o f large work in g sets with fine data-par allel granu larity offered by those test benchma r ks. Blackscholes Canneal F acesim Fluidanimate Freqmine x264 Cores Frequency L1−I Cache L1−D Cache L2 Cache L3 Cache P arameter Significance |D| 0.0 0.2 0.4 0.6 0.8 1.0 Fig. 3. Significance of microarc hitect ure configuration paramet ers for P ARSEC benc hmarks for high-perfor mance optimize d processor for IoT 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.2 0.4 0.6 0.8 1.0 T otal P ower Ex ecution Time x264 pareto front Objective function line P oint of intersection Fig. 4. L inear objec ti ve function plotted with Pareto front for x264 (P ARSEC) benchmark for high-performance optimi zed processor for IoT 2) Selecting a favorable tradeoff solution : Figu re 4 shows the Pareto front ob tained for x26 4 ( P ARSEC) benchma rk for high -perfo rmance optim iza tion requir ement. Th e Pareto front is generated using th e nor malized values of total power and execution time design metrics. Th e front represen ts the conflicting interdepen dency be twe e n power and perfor mance in a pro c essor . It sho ws th at inc r easing the perform a nce of a processor degrades its power efficiency whereas increasing power efficiency d egrades performan ce. It is thus impossible to deter mine a micro architecture co nfiguration which results in b oth these m etrics having optim al values. The go al of the de sig n space exploration method ology is to determin e a balance between these co nflicting d esign metr ics. A suitable tradeoff between these metrics is selected by u sing th e preferen ce specified using the weigh ts assigned to each metric. In our experimen ts, we specified w P and w E as the weights for p ower and perform a nce metrics respectiv ely to d e fine a linear o bjectiv e fun ction (Equ ation 1 5). Figure 4 shows th e objective function plotted along with th e Pareto f ront. W e note that the objective fun ction fo r ms a straight line in the power - 10 T ABL E IV C O M PA R I S O N O F M I R C OA R C H I T E C T U R E C O N FI G U R A T I O N S O B TA I N E D F O R X 2 6 4 ( PA R S E C ) B E N C H M A R K F O R H I G H - P E R F O R M AN C E O P T I M I Z E D P R O C E S S O R F O R I O T Parame ter Name Micr oarc hitectur e Configuration Proposed Fully Exhausti ve Methodol ogy Search Cores 2 2 Frequenc y (MHz) 3200 3200 L1-I Cache Size (kB) 64 128 L1-D Cache Size (kB) 64 128 L2 Cache Size (kB) 1024 256 L3 Cache Size (kB) 2048 8192 T otal Power (W) 1.597 1.600 Executio n Time (ms) 35.142 34.152 perfor mance gr aph with the slope − w P /w E . W e ob serve that the objectiv e func tion is tangent to the Pareto fro nt at the p ower -perform ance value p air of th e micr oarchitectur e configur ation ob tained as solution b y our method ology . 3) Comparison with fully exhaustive sea r ch: W e verified the micr oarchitectur e configu ration obtained a s solution from our m e th odolog y by c o mparing it against the solution ob tained by runn ing a fully exhaustive search of the d esign space . W e presen t a comparison of the x264 (P ARSEC) benchm ark as an exam ple in T able IV. T h e table shows a side-by-side compariso n of the micro architecture co nfiguratio n s obtained from ou r p roposed methodolo gy with the same o btained from fully exhaustiv e search. Compar ing th e se values, we see that significant param eters like op erating frequen cy and core-c ount match exactly while other parame ter s only dif fer slightly . The table also con ta in s the v alues of the total power and execution time obtain ed for both con fig urations. Com paring the values of these d esign m etrics, we see that the to tal power and execution time values ob tained from our method ology are within - 0.18% and 2.89% respectiv ely of the to tal power an d execution time values ob tained from fu lly exhau sti ve exploratio n. Using o ur method ology , o n average we ach ie ve microarch itecture con figuration s w ith total p ower values within 2.2 3% for low-power optim ized processor and execution time with in 3.69% fo r h igh-per f ormance optimized processors as compared to fully exhaustive search. T hese configur ations are obtain e d by exploring on ly 3%–5% of th e processor design sp a ce which results in our meth odolog y having an average sp e edup of 24. 1 6 × as co mpared to fully exhaustiv e explo ration o f the design space . B. A pplication scopes in IoT Based on the ty pe and size of workload offered b y the test benchm arks, we separate them into four different categories each of which r elates to an Io T application or process. T a ble V shows the c ategorization o f some o f the key test ben c hmarks. Th e Cho lesky and Radix ben c h marks from the SPLASH2 b enchmar k suite are categor ized un der data sensing and aggregation. The Cholesky be n chmark is a sparse matrix factorization kern e l and the Radix benchm ark is an integer sor t kernel [29]. Th e Cho lesky benchmark is representative of data sen sin g in IoT application s, where data is acquired from m ultiple sensor sou rces and transformed in to T ABL E V C AT E G O R I Z AT I O N O F T E S T B E N C H M A R K S AC C O R D I N G T O I O T A P P L I C A T I O N IoT A pplicati on Benchmar ks Data sensing and aggre gation Cholesk y , Radix Data analysis and Data mining Blacksc holes, Freqmine Graphics Face sim, Fluidanimate Signal processing and Communicat ion FFT T ABL E VI M I R C OA R C H I T E C T U R E C O N F I G U R A T I O N S F O R L O W - P OW E R O P T I M I Z E D P R O C E S S O R S F O R I O T Parame ter Name Micr oarc hitectur e Configuration Cholesky Radix Cores 1 1 Frequenc y (MHz) 75 75 L1-I Cache Size (kB) 8 8 L1-D Cache Size (kB) 32 64 L2 Cache Size (kB) 256 2 56 L3 Cache Size (kB) 20 48 4096 T otal Power (W) 0.0934 0.0935 Executio n Time (ms) 327.958 332.535 a more useful format. The Radix benchm ark is repr esentativ e of data aggregation, wher e indexing, sorting and sto ring operation s are c a rried out on sensed data. These benchmar k s are usefu l in deter mining the micro architecture configura tio ns of lo w-power optimized interface processors for the two-tiered heteroge n eous processor architecture. The rem aining categories all mode l more com plex applications requ ir ing hig h lev el of proc e ssing capa bilities. The Blackscholes and Freqmine be nchmark s fr om the P ARSEC ben chmark suite are listed under d a ta an a ly sis and data mining. The Blackscholes ben chmark is a financial analysis benc h mark that analytically solves large sets of partial differential equatio ns [24]. The Freqmin e bench mark is a data mining kernel which impleme n ts Freq uent Itemset Minin g [24]. These b enchmar ks are representative of data an alysis and filtering oper ations that need to be carried out o n large volumes of sensor data in an IoT network. The Facesim and Fluidan imate bench marks fr om the P ARSEC benchmark suite are listed u n der graph ics. Th e Facesim bench mark gene r ates a visua lly realistic mo del o f a human face an d the Fluidan imate ben c hmark simulates an incompr essible fluid for inter a cti ve anim ation pu rposes [24]. Graphical applications are impo rtant in I oT objects which need to interact with users via grap hical u ser interfaces. The FFT bench mark from the SPLASH2 benc hmark suite is listed under signal proce ssing an d c o mmunicatio n. The FFT benchm a rk is an impleme n tation of Fast Fourier Transform algorithm which is optimized to minim ize in terprocess commun ication [2 9]. Signal processing and c o mmunicatio n is one of the mo st com mon ap plications in an IoT network. FFT is an important Digital Sig nal Processing (DSP) algorithm which is re q uired in co mmunicatio n of data over Software Defined Radios (SDR) [14]. These ben chmarks, which req uire higher p rocessing capabilities, are useful in determining the mic r oarchitectur e configur ations of high- perfor m ance optimize d host pro c essor for the two-tiered heterogeneo us processor architectur e. 11 T ABL E VII M I R C OA R C H I T E C T U R E C O N F I G U R A T I O N F O R H I G H - P E R F O R M A N C E O P T I M I Z E D P R O C E S S O R S F O R I O T Parame ter Name Micr oarc hitectur e Configuration Blackschol es F reqm ine Face sim Fluidanimate FF T Cores 8 2 2 2 4 Frequenc y (MHz) 3200 32 00 3200 3200 3200 L1-I Cache Size (kB) 64 32 8 8 128 L1-D Cache Size (kB) 1 28 12 8 64 64 32 L2 Cache Size (kB) 256 1024 1024 1024 512 L3 Cache Size (kB) 8192 20 48 8192 4096 2048 T otal Power (W) 4. 549 1.565 1.546 1.546 2.563 Executio n Time (ms) 28.1239 67.319 60.072 55.605 29.986 1) Micr oarc hitectur e config u rations for low-po wer optimized pr ocessors fo r IoT : T able VI shows the microarch itecture con figurations o btained for Cholesky and Rad ix b enchmar ks from the SPLASH2 benchmar k suite. In these con figuration s, we note that for low-power optimized processor, the lo west operating f r equency and core count are selected. This r esult can b e interp r eted in tuitiv ely , b e cause high o perating frequ e n cy an d high nu mber of c o res in the processor inc r eases the p ower consum ption of the processor . W e also note that these co n figuration s h av e large L1-D cach e sizes. Th is is because of the large workload offered by the test ben chmarks. This is rep resentativ e of the growing IoT ecosystem in which large volumes of d a ta are g athered fro m a large num ber o f sensing elements. The values of total power and execution times for micro architecture configu r ations are also shown in T able VI . W e observe that the power values are in the rang e of a hun dred m illiwatts and the execution time is in the ra nge of a fe w hun dred m illiseconds. These values are within the operatio nal r equiremen ts in most IoT d eployments. These config u rations imp lement the inter face proc e ssors in the two-tiered heter ogeneou s pro cessor architecture. W ith low-po wer requirem ents, these p r ocessors can alw ays be operated in active mode, with out impacting th e p ower budget of IoT d eployments 2) Micr oarc hitectur e confi guration for h igh-performan ce optimized pr ocessors for Io T : T able VII sho ws the microarch itecture configu rations ob tained fo r Blacksch oles, Freqmine, Facesim and Fluidanimate benc hmarks f r om the P ARSEC ben chmark suite and the FFT b e n chmark from the SPLASH2 b enchmar k suite. W e analyze th e m ic r oarchitectur e configur ations obtained for these test b enchmark s according to the categorization discu ssed in sub section VI -B. W e observe th a t fo r data an alysis an d data m in ing ap plications, represented by the Black scholes and Fr e qmine benc hmarks, higher performan ce is achieved primarily b y th e increase in o perating frequ e ncy . W e no te that the size of th e L1-D cache for these application s is also high, which is because both are h ighly data-p arallel benchmar ks. The size of the L2 cache, for Black scholes, and, L3 cache, for Fr eqmine, is also high which is also a resu lt of data-p a rallelism in these benchm arks. For graph ics applications, rep resented by Facesim and Fluida n imate ben chmarks, higher pe r forman c e can again be attributed to incr ease in operating frequ ency . These benchmark s a r e also highly data-parallel w h ich exp lain s the large L 1-D cach e, L2 c a c he and L3 cach e in th e re su lting microarch itecture configu rations. In signal processing and commun ication applications, represented by FFT b enchmar k, perfor mance improvement, similar to other applicatio ns, is attained b y incr ease in operating fr equency . Howe ver , FFT requires a larger instruction cac he as compar e d to larger data caches for other app lications. Higher L1-I cache could be a result of the FFT bench mark bein g optimized for lo w interpro c ess comm unication. The total power and execution time o f each microarch itecture configuration is also listed in T able VII. These configuratio ns hav e h igh total power values in the range of one to a few watts but significantly low execution time values in the r ange of f ew tens o f milliseconds. Th ese configur ations implement the host proc e ssor in the two-tiered heteroge n eous processor architec ture. Due to th e ir high-p ower requirem ent, these processors are mostly kept in sleep mode and are activated intermittently for shor t durations to save energy and prolon g battery life. Because these processors have shorter execution times, they can execute th eir tasks quickly and g o to sleep thus, decr easing the du r ation that they are active. V I I . C O N C L U S I O N A N D F U T U R E W O R K In this pap er , we proposed a tem porally e ffi cient design space exploration methodolo gy for selecting micr oarchitectur e configur ations o f processors f or IoT . Our exploration methodo logy con sisted of four ph ases. In the first p h ase, we determined best initial settings for tu nable pro cessor design parameters using initial on e-shot search m ethod. W e also calculated the significance of each desig n parameter o n the overall design in this ph ase. T he results of this p h ase we re used in the second phase to separate th e processor design parameters into distinct search sets using an exploration threshold value supp lied b y the system designer . The third and the fo urth phase of the metho d ology implemented exhaustiv e and greedy search methods to prune these search sets to determine the best microarchitectur e configu ration o f the processor . W e tested our method ology over two design spaces, one for deter mining low-power op timized and the other for determinin g high-p erforma nce optimized p rocessors for I oT . W e v alidated the results obtain ed from o ur meth odolog y by co mparing with solutions obtained from fully exhau sti ve exploration of th e design spaces. Our results revealed that our methodo logy obtained microarch itecture config u rations close to within 2 .23%–3. 69% of the con figurations obtaine d from 12 fully exhaustiv e search. Our methodo lo gy only explored 3%– 5% of the overall design space to determine these h igh qu ality solutions. T his resulted in 24.16 × average speedup o n design space explor a tion as c o mpared to th e time requ ir ed for fully exhaustiv e explo ration. W e also described a two-tiered h eterogen eous proce ssor architecture for inco rporating power-optimized p erforma nce in IoT o b jects. W e u sed the results o btained from the ev a luation of our design space explo ration metho dology to describe the two-tiered arc hitecture. W e categorized the test benchm arks into four different categories, relating them with possible IoT use cases and analyze microar chitecture configur a tions determined fo r these benchm arks to make o ur assertions on processors for I oT objects. W e determined that f or low-power optimization , microar chitecture co nfiguration s with lower core count and lower ope rating freq uency are more suitable. For high-p erforman ce optimization , improvement in per formanc e primarily results f rom incr ease in op e r ating frequency . W e also analyzed th e cache hier archy for dif ferent micro architecture configur ations an d relate d them with th e type and size of workloads offered b y the test benchmark s. In the future, we plan to investigate microar c hitecture configur ations of ultra-low power processor s for I oT . W e also intend to test our d esign space explo ration methodo logy using stan dard I oT be nchmark s. W e also aim to imp rove o ur methodo logy by in corpor a tin g better optim iz a tion techniques like g enetic an d evolutionary algo rithms and machine - learning. W e also plan to study the practical applicability of th e two- tiered h e terogeneo us p rocessor m odel fo r pro cessors for IoT objects, and , com pare the model with pro cessor architecture models curr ently in use in the IoT market. R E F E R E N C E S [1] J . Chase, “The evol ution of the internet of things - from connected things to livin g in the data, preparing for challeng es and IoT readiness, ” T exas Instruments, T ech. Rep., Sep 2013. [2] (2015, Nov) Gartner says 6.4 billion connected ”thi ngs” will be in use in 2016, up 30 perce nt from 2015. [Online]. A vail able: http:/ /www .gartner .com/ne wsroom/id/3165317 [3] S . Bath. (2016, Aug) Dev elop ing solutions for the internet of things. [Online]. A vail able: https: //goo.gl/ECy cve [4] “Dev eloping soluti ons for the internet of things, ” Intel, T ech. Rep., 2014. [5] S . Matalo n, R. Klein , and C. W alls, “Embedded system power consumption : A softwa re or hardwa re issue?” Mentor Graphics, T ech. Rep., Jun 2011. [6] “Intelligent flexib le IoT nodes, ” ARM, T ech. Rep., Oct 2015. [7] Y . V eller and S. Matal on, “Why you should optimize power at the elect ronic system lev el, ” Mentor Graphic s, T ech. Rep., Aug 2010. [8] C. Rommel, “ Architect ing s uccess with heterogeno us systems, ” VDC Researc h, Mentor Graphics, T ech. Rep., 2016. [9] “IoT opportunity demands new approach to mcu-based embedde d designs - rapidly moving m ark et requires inte grated silicon/sof tware platform, ” Renesas and Synerg y , T ech. Rep., Oct 2015. [10] J. Brank e, K. Deb, K. Mietti nen, and R. Slo w inski, Multiobj ectiv e Optimizati on - Interactiv e and Evolution ary A ppr oaches . V erlag Berlin Heidelb erg: Springe r , 2008. [11] S. Boyd and L. V andenbe rghe, Con vex Optimization . Ne w Y ork, NY , USA: Cambridge Univ ersity Press, 2004. [12] K. Char , “Interne t of things system design with integrate d wireless MCUs, ” Silicon Labs, ARM, T ech. Rep., Oct 2015. [13] J. Geuzebroek and A. V aassen, “Buil ding an ef ficient , tight ly coupled embedded system using an exte nsible processor , ” Synopsys, T ech. Rep., Jun 2014. [14] T . Ade gbija, A. Rogacs, C. Pat el, and A. Gordon-Ross, “Enabling right- provi sioned microprocessor archit ecture s for the intern et of things, ” in ASME Pr oceed ings of Internati onal Mec hanical Engineerin g Congr ess and Exposition , Houston, T exas, USA, Nov 2015. [15] J. Michanan, R. Dewri, and M. J. Rutherford, “Understandi ng the po wer- performanc e tradeof f through pareto analysis of liv e performan ce data, ” in Pr oceedi ngs of Internati onal Gr een Computing Conferen ce (IGCC) , Dallas, T exas, USA, Nov 2014. [16] Q. Guo, T . Chen, Y . Chen, Z.-H. Zhou, W . Hu, and Z. Xu, “Effe cti ve and ef ficient microproc essor design space explorat ion using unlabeled design configur ations, ” ACM T ransaction s on Intellig ent Systems and T echnolo gy , vol. 5, no. 1, pp. 20:1–20 :18, Jan 2014. [17] M. Monchi ero, R. Canal, and A. Gonzalez , “Powe r/performanc e/the rmal design-spac e explorati on for multicore architec tures, ” IEEE T ransactions on P arallel and Distributed Systems , vol. 19, no. 5, pp. 666–681, May 2008. [18] T . Giv arg is and F . V ahid, “Pla tune: A tuning frame work for system- on-a-chi p plat forms, ” IE EE T ransactio ns on Computer-Aided Design of Inte grated Circ uits and Systems , vol. 21, no. 11, pp. 1317–1327, Nov 2002. [19] M. Pale si and T . Giv argis, “Mult i-objec ti ve design s pace exploratio n using genetic algorithms, ” in Pro ceedin gs of the 10th International Symposium on Hardwar e/Softwar e Codesign (CODES) , Estes Park, CO, USA, May 2002. [20] C. Sil v ano, W . Fornaciari , G. Pal ermo, V . Zaccaria, F . Castro, M. Martinez, S. Bocchio, R. Zafalo n, P . A va sare, G. V anmeerbee ck, C. Ykman-Couvr eur , M. W outers, C. Kavk a, L. Onesti, A. T urco, U. Bondi, G. Mariani, H. Posadas, E . V illar , C. Wu, F . Dongrui, Z. Hao, and T . Shibin, “MUL TICUBE: Multi-obje cti ve design space explor ation of multi-core archit ectures, ” in Pro ceedin gs of IEEE Computer Societ y Annual Symposium on VLSI (ISVLSI) , Lixouri, Kefal onia, Jul 2010. [21] A. Munir , A. Gordon-R oss, S. L ysecky , and R. L ysecky , “ A lightwe ight dynamic optimiza tion methodo logy and appli catio n metrics estimati on model for wireless sensor netw orks, ” Sustainable Computing: Informatic s and Systems , vol. 3, no. 2, pp. 94 – 108, Jun 2013. [22] D. Sheldon, “Design s pace explora tion of parameteriz ed s ystems using design of expe riments, ” Ph.D. dissertation, Department of Computer Science , Dec 2011. [23] E . K. Ardestani and J. Renau, “ESE S C: A fast multicore simulator using time-ba sed sampling, ” in Pro ceedin gs of IEE E 19th Internati onal Symposium on High P erformanc e Computer A r chit ectur e (HP CA ) , W ashington, DC, USA, Feb 2013. [24] C. Bienia, “Bench marking modern multiprocessors, ” Ph.D. dissertation, Departmen t of Computer Science, Jan 2011. [25] Y . Bao, C. Bienia, and K. Li, The P ARSE C Benchmark Suite T utorial - P A RSEC 3.0 , San Jose, CA, USA, Jun 2011. [26] (2015) Perl reference . [Online]. A vaila ble: http://p erlmav en.com/ [27] J. McNamara. (2015, Apr) Excel-writer -XLSX. [Online]. A va ilabl e: http:/ /search.c pan.org/ dist/Excel- W riter-XL SX/ [28] A. F . Lorenzon, M. C. Cera, and A. C. S. Beck, “On the influence of stati c power consumption in multico re embedded systems, ” in 2015 IEEE International Symposium on Cir cuits and Sytems (ISCAS) , Lisbon, Portugal , May 2015. [29] S. C. W oo, M. Ohara, E. T orrie, J. P . Singh, and A. G upta, “The SPLASH-2 progra ms: Characteri zatio n and methodolog ical considera tions, ” in Pr ocee dings of 22nd Annual Inte rnational Symposium on Compute r Arc hitec tur e (ISCA) , Santa Marg herita Ligure, Italy , Jun 1995. Prasanna Kansakar is a PhD student in the Departmen t of Computer Science (CS) at Kansas State Univ ersit y (K-Stat e), Manhat tan, KS. His research intere sts include Internet of Things, embedded and cyber-ph ysical systems, computer archit ecture , multicore, secure and trustworthy systems, and hardware-base d securi ty . Kansakar has an MS de gree in computer s cienc e and engineeri ng from the Unive rsity of Ne v ada, Reno (UNR). He is a student m ember of the IEEE . 13 Arslan Munir is currently an Assistant Professor in the Department of Computer Scienc e (CS) at Kansas State Univ ersity (K-State). He holds a Michelle Munson-Serban Simu Ke ystone Researc h Faculty Scholarshi p from the College of Engineering. He was a postdoctoral research associa te in the E lect rical and Computer Engineering (ECE) departme nt at Rice Unive rsity , Houston, T e xas, USA from May 2012 to J une 2014. He recei ved his M.A.Sc. in E CE from the Uni ve rsity of British Columbia (UBC), V ancouver , Canada, in 2007 and his Ph.D. in ECE from the Uni ve rsity of Florida (UF), Gainesvi lle, Florida, USA, in 2012. From 2007 to 2008, he worked as a software dev elopmen t enginee r at Mentor Graphics in the Embedded Systems Di vision. Munir’ s current researc h interests include embedded and cybe r- physical systems, secure and trustwort hy systems, hardware-b ased security , computer architec ture, multicore, parallel computing , distrib uted computing, reconfigura ble computing, artificial intell igence (AI) safety and security , data analyt ics, and fault toleranc e. Munir recei ved m any acade mic awa rds includi ng the doctoral fellowshi p from Natural Sciences and Engineering Research Council (NSERC) of Canada. He earned gold medals for best performance in elect rical engineeri ng, gold medals and acade mic roll of honor for securin g rank one in pre-engineeri ng prov incial examin ations (out of approxi mately 300,000 candidat es). He is a Senior Member of IEEE.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment