Bayesian anti-sparse coding
Sparse representations have proven their efficiency in solving a wide class of inverse problems encountered in signal and image processing. Conversely, enforcing the information to be spread uniformly over representation coefficients exhibits relevan…
Authors: Clement Elvira, Pierre Chainais, Nicolas Dobigeon
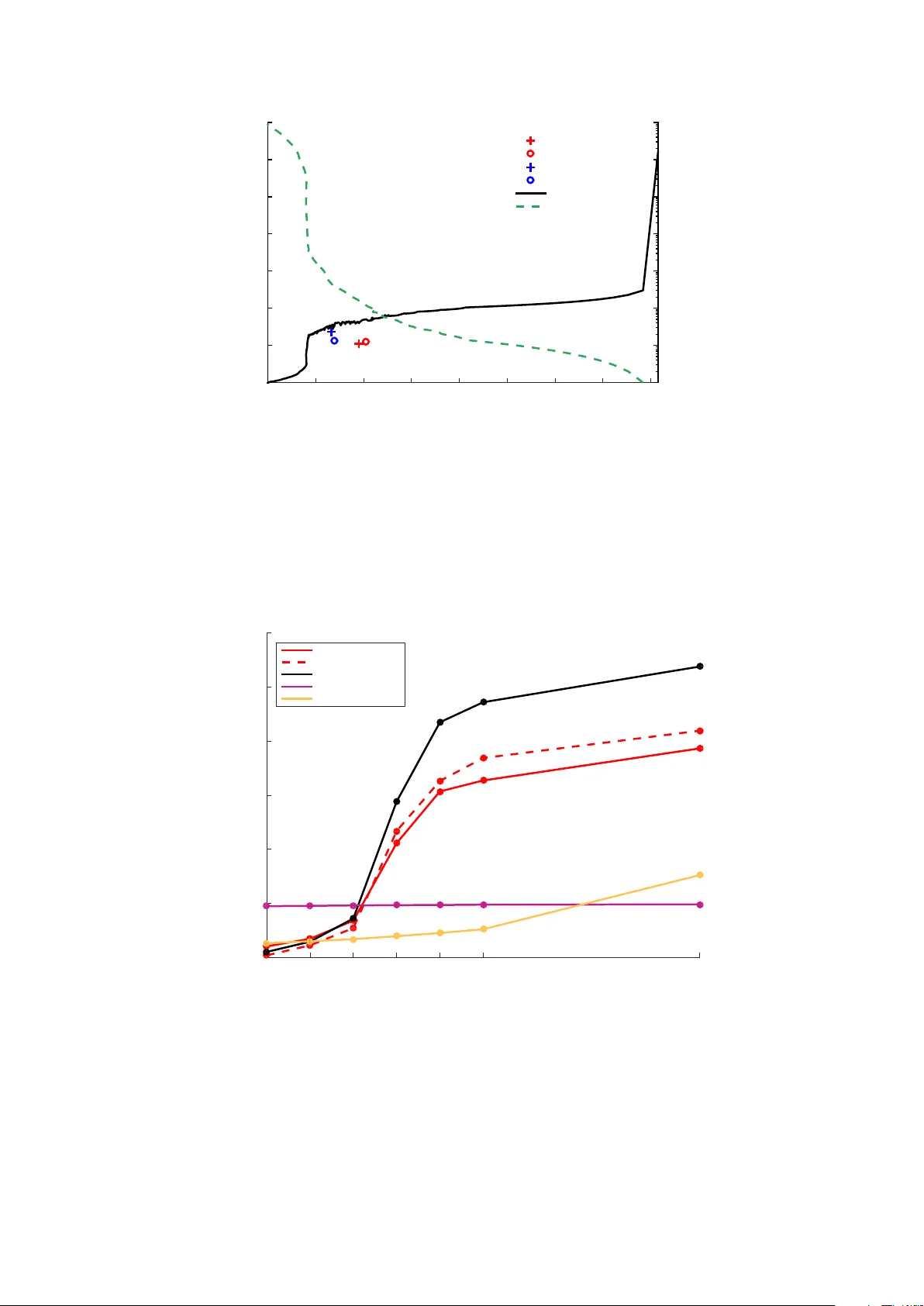
1 Bayesian anti-sparse coding Cl ´ ement Elvira, Student Member , IEEE , Pierre Chainais, Member , IEEE and Nicolas Dobigeon, Senior Member , IEEE Abstract Sparse representations hav e prov en their efficienc y in solving a wide class of in verse problems encountered in signal and image processing. Con versely , enforcing the information to be spread uniformly ov er representation coefficients e xhibits relev ant properties in v arious applications such as digital communications. Anti-sparse re gularization can be naturally expressed through an ` ∞ -norm penalty . This paper derives a probabilistic formulation of such representations. A new probability distribution, referred to as the democratic prior, is first introduced. Its main properties as well as three random v ariate generators for this distribution are derived. Then this probability distribution is used as a prior to promote anti-sparsity in a Gaussian linear inv erse problem, yielding a fully Bayesian formulation of anti-sparse coding. T wo Markov chain Monte Carlo (MCMC) algorithms are proposed to generate samples according to the posterior distribution. The first one is a standard Gibbs sampler . The second one uses Metropolis-Hastings moves that exploit the proximity mapping of the log-posterior distribution. These samples are used to approximate maximum a posteriori and minimum mean square error estimators of both parameters and hyperparameters. Simulations on synthetic data illustrate the performances of the two proposed samplers, for both complete and ov er-complete dictionaries. All results are compared to the recent deterministic variational FITRA algorithm. Index T erms democratic distribution, anti-sparse representation, proximal operator , in verse problem. Cl ´ ement Elvira and Pierre Chainais are with Univ . Lille, CNRS, Centrale Lille, UMR 9189 - CRIStAL - Cen- tre de Recherche en Informatique Signal et Automatique de Lille, F-59000 Lille, France (e-mail: { Clement.Elvira, Pierre.Chainais } @ec-lille.fr ). Nicolas Dobigeon is with the Univ ersity of T oulouse, IRIT/INP-ENSEEIHT , CNRS, 2 rue Charles Camichel, BP 7122, 31071 T oulouse cedex 7, France (e-mail: Nicolas.Dobigeon@enseeiht.fr). Part of this work has been funded thanks to the BNPSI ANR project no. ANR-13-BS-03-0006-01. August 27, 2018 DRAFT 2 I . I N T RO D U C T I O N Sparse representations have been widely advocated for as an efficient tool to address various problems encountered in signal and image processing. As an archetypal example, they were the core concept underlying most of the lossy data compression schemes, exploiting compressibility properties of natural signals and images over appropriate bases. Sparse approximations, generally resulting from a transform coding process, lead for instance to the famous image, audio and video compression standards JPEG, MP3 and MPEG [1], [2]. More recently and partly motiv ated by the advent of both the compressi ve sensing and dictionary learning paradigms, sparsity has been intensi vely exploited to regularize (e.g., linear) ill-posed in verse problems. The ` 0 -norm and the ` 1 - norm as its con ve x relaxation are among the most popular sparsity promoting penalties. Follo wing the ambi valent interpretation of penalized regression optimization [3], Bayesian inference naturally of fers an alternative and fle xible framework to deri v e estimators associated with sparse coding problems. For instance, it is well known that a straightforward Bayesian counterpart of the LASSO shrinkage operator [4] can be obtained by adopting a Laplace prior [5]. Designing other sparsity inducing priors has motiv ated numerous research works. They generally rely on hierarchical mixture models [6]–[9], heavy tail distributions [10]–[12] or Bernoulli-compound processes [13]–[15]. In contrast, the use of the ` ∞ -norm within an objectiv e criterion has remained somehow confidential in the signal processing literature. One may cite the minimax or Chebyshev approximation principle, whose practical implementation has been made possible thanks to the Remez exchange algorithm [16] and leads to a popular design method of finite impulse response digital filters [17], [18]. Besides, when combined with a set of linear equality constraints, minimizing a ` ∞ -norm is referred to as the minimum-ef fort control problem in the optimal control framework [19], [20]. Much more recently , a similar problem has been addressed by L yubarskii et al. in [21] where the Kashin’s r epr esentation of a giv en vector over a tight frame is introduced as the expansion coefficients with the smallest possible dynamic range. Spreading the information over representation coefficients in the most uniform way is a desirable feature in various applicativ e contexts, e.g., to design robust analog-to-digital con version schemes [22], [23] or to reduce the peak-to-a verage power ratio (P APR) in multi-carrier transmis- sions [24], [25]. Resorting to an uncertainty pri nciple (UP), L yubarskii et al. hav e also introduced se veral examples of frames yielding computable Kashin’ s representations, such as random orthogonal matrices, random subsampled discrete Fourier transform (DFT) matrices, and random sub-Gaussian matrices [21]. The properties of the alternate optimization problem, which consists of minimizing the maximum magnitude of the representation coefficients for an upper-bounded ` 2 -reconstruction error , hav e been deeply in vestigated in [26], [27]. In these latest contributions, the optimal expansion is called the democratic r epr esentation and some bounds associated with archetypal matrices ensuring August 27, 2018 DRAFT 3 the UP are deri v ed. In [28], the constrained signal representation problems considered in [21] and [27] is con v erted into their penalized counterpart. More precisely , the so-called spread or anti-sparse r epr esentations result from a variational optimization problem where the admissible range of the coef ficients has been penalized through a ` ∞ -norm min x ∈ R N 1 2 σ 2 k y − Hx k 2 2 + λ k x k ∞ . (1) In (1), H defines the M × N representation matrix and σ 2 stands for the variance of the residual resulting from the approximation. Again, the anti-sparse property brought by the ` ∞ -norm penalization enforces the information brought by the measurement vector y to be ev enly spread ov er the repre- sentation coef ficients in x with respect to the dictionary H . It is worth noting that recent applications hav e capitalized on these latest theoretical and algorithmic advances, including approximate nearest neighbor search [29] and P APR reduction [30]. Surprisingly , up to our knowledge, no probabilistic formulation of these democratic representations has been proposed in the literature. The present paper precisely attempts to fill this gap by deriving a Bayesian formulation of the anti-sparse coding problem (1) considered in [28]. Note that this objecti ve dif fers from the contrib ution in [31] where a Bayesian estimator associated with an ` ∞ - norm loss function has been introduced. Instead, we merely introduce a Bayesian counterpart of the v ariational problem (1). The main motiv ations for deriving the proposed Bayesian strate gy for anti-sparse coding are threefold. Firstly , Bayesian inference is a flexible methodology that may allow other parameters and hyperparameters (e.g., residual variance σ 2 , regularization parameters λ ) to be jointly estimated with the parameter of interest x . Secondly , through the choice of the considered Bayes risk, it permits to define a wide class of estimators, beyond the traditional penalized maximum likelihood estimator resulting from the solution of (1). Finally , within this framework, Markov chain Monte Carlo algorithms can be con veniently designed to generate samples according to the posterior distribution. Contrary to deterministic optimization algorithms which provide only one point estimate, these samples can be subsequently used to b uild a comprehensiv e statistical description of the solution. T o this purpose, a new probability distribution as well as its main properties are introduced in Section II. In particular , we sho w that p ( x ) ∝ exp ( − λ k x k ∞ ) properly defines a probability density function (pdf). In Section III, this so-called democratic distribution is used as a prior distribution in a linear Gaussian in verse problem, which provides a straightforward equi valent of the problem (1) under the maximum a posteriori paradigm. Moreover , exploiting rele vant properties of the democratic distribution, this section describes two Markov chain Monte Carlo (MCMC) algorithms as alternativ es to the deterministic solvers proposed in [27], [28]. The first one is a standard Gibbs sampler which sequentially generates samples according to the conditional distrib utions associated with the joint posterior distribution. The second MCMC algorithm relies on a proximal Monte Carlo step recently August 27, 2018 DRAFT 4 introduced in [32]. This step exploits the proximal operator associated to the logarithm of the target distribution to sample random vectors asymptotically distributed according to this non-smooth density . Section IV illustrates the performances of the proposed algorithms on numerical experiments. Concluding remarks are reported in Section V. T ABLE I L I S T O F S Y M B O L S . Symbol Description N , n Dimension, index of representation vector M , m Dimension, index of observed vector x , x n Representation vector , its n th component y , y m Observation vector , its m th component H Coding matrix e Additiv e noise vector λ Parameter of the democratic distribution µ Re-parametrization of λ such that λ = N µ D N ( λ ) Democratic distribution of parameter λ over R N C N ( λ ) Normalizing constant of the distribution D N ( λ ) K J A J -element subset { i 1 . . . i J } of { 1 , . . . , N } U , G , I G Uniform, gamma and inv erse gamma distributions d G Double-sided gamma distribution N I T runcated Gaussian distribution over I C n Double con vex cones partitioning R N c n , I n W eights and intervals defining the conditional distribution p x n | x \ n g , g 1 , g 2 Negati ve log-distribution ( g = g 1 + g 2 ) δ Parameter of the proximity operator ε j , d j , φ δ ( x ) Family of distinct values of | x | , their respective multiplicity and family of local maxima of prox δ λ k·k ∞ q ( ·|· ) Proposal distribution ω in , µ in , s 2 n , I in W eights, parameters and intervals defining the conditional distribution p x n | x \ n , µ, σ 2 , y I I . D E M O C R AT I C D I S T R I B U T I O N This section introduces the democratic distribution and the main properties related to its marginal and conditional distributions. Finally , two random v ariate generators are proposed. Note that, for sake August 27, 2018 DRAFT 5 of conciseness, the proofs associated with the following results are reported in the companion report [33]. A. Pr obability density function Lemma 1. Let x ∈ R N and λ ∈ R + . The inte gr al of the function exp ( − λ k x k ∞ ) over R N is pr operly defined and the following equality holds Z R N exp ( − λ k x k ∞ ) d x = N ! 2 λ N . Pr oof: See Appendix [33, App. A]. As a corollary of Lemma 1, the democratic distribution can be defined as follows. Definition 1. A N -r eal-valued r andom vector x ∈ R N is said to be distrib uted accor ding to the democratic distribution D N ( λ ) , namely x ∼ D N ( λ ) , when the corr esponding pdf is p ( x ) = 1 C N ( λ ) exp ( − λ k x k ∞ ) (2) with C N ( λ ) , N ! 2 λ N . Fig. 1. The democratic pdf D N ( λ ) for N = 2 and λ = 3 . As an illustration, the pdf of the bidimensional democratic pdf for λ = 3 is depicted in Fig. 1. Remark 1. It is interesting to note that the democratic distribution belongs to the exponential family . Indeed, its pdf can be factorized as p ( x ) = a ( x ) b ( λ ) exp ( η ( λ ) T ( x )) (3) wher e a ( x ) = 1 , b ( λ ) = 1 /C N ( λ ) , η ( λ ) = − λ and T ( x ) = k x k ∞ defines sufficient statistics. August 27, 2018 DRAFT 6 B. Moments The two first moments of the democratic distribution are a vailable through the follo wing property . Property 1. Let x = [ x 1 , . . . , x N ] T be a random vector obeying the democratic distribution D N ( λ ) . The mean and the covariance matrix ar e given by: E [ x n ] = 0 ∀ n ∈ { 1 , . . . , N } (4) v ar [ x n ] = ( N + 1)( N + 2) 3 λ 2 ∀ n ∈ { 1 , . . . , N } (5) co v [ x i , x j ] = 0 ∀ i 6 = j . (6) Pr oof: See Appendix [33, App. B]. C. Mar ginal distributions The marginal distributions of any democratically distributed vector x are giv en by the following Lemma. Lemma 2. Let x = [ x 1 , . . . , x N ] T be a random vector obeying the democratic distribution D N ( λ ) . F or any positive inte ger J < N , let K J denote a J -element subset of { 1 , . . . , N } and x \K J the sub-vector of x whose J elements indexed by K J have been r emoved. Then the mar ginal pdf of the sub-vector x \K J ∈ R N − J is given by p x \K J = 2 J C N ( λ ) J X j =0 J j ( J − j )! λ J − j x \K J j ∞ × exp − λ x \K J ∞ . (7) Pr oof: [33, App. C] In particular , as a straightforward corollary of this lemma, two specific marginal distributions of D N ( λ ) are giv en by the following property . Property 2. Let x = [ x 1 , . . . , x N ] T be a random vector obeying the democratic distribution D N ( λ ) . The components x n ( n = 1 , . . . , N ) of x ar e identically and mar ginally distributed according to the following N -component mixtur e of double-sided Gamma distributions 1 x n ∼ 1 N N X j =1 d G ( j , λ ) . (8) 1 The double-sided Gamma distribution d G ( a, b ) is defined as a generalization over R of the standard Gamma distribution G ( a, b ) with the pdf p ( x ) = b a 2Γ( b ) | x | a − 1 exp ( − b | x | ) . August 27, 2018 DRAFT 7 Mor eover , the pdf of the sub-vector x \ n of x whose n th element has been r emoved is : p x \ n = 1 + λ x \ n ∞ N C N − 1 ( λ ) exp − λ x \ n ∞ . (9) Pr oof: [33, App. C] These two specific marginal distributions p x \ n and p ( x n ) are depicted in Fig. 2 (top and bottom, right). −2 −1 0 1 2 0 0.1 0.2 0.3 0.4 0.5 x −20 −10 0 10 20 0 0.005 0.01 0.015 0.02 0.025 0.03 x Fig. 2. T op: marginal distribution of x \ n when x ∼ D N ( λ ) for N = 3 and λ = 3 . Bottom: marginal distribution of x n when x ∼ D N ( λ ) for N = 3 (left) or N = 50 (right) and λ = 3 . Remark 2. It is worth noting that the distribution in (8) can be re written as p ( x n ) = λ 2 N N − 1 X j =0 λ j j ! | x n | j exp ( − λ | x n | ) which behaves as p ( x n ) ≈ λ 2 N when N → + ∞ . This means that the components of x tend to be mar ginally distributed accor ding to uniform distributions over R in high dimension. This behavior is depicted in F ig. 2 bottom-right. D. Conditional distributions Before introducing conditional distrib utions associated with any democratically distrib uted random vector , let partition R N into a set of N non-ov erlapping double-con ve x cones C n ⊂ R N ( n = 1 , . . . , N ) defined by C n , x = [ x 1 , . . . , x N ] T ∈ R N : ∀ j 6 = n, | x n | > | x j | . (10) August 27, 2018 DRAFT 8 These sets are directly related to the index of the so-called dominant component of a giv en demo- cratically distributed vector x . More precisely , if k x k ∞ = | x n | , then x ∈ C n and the n th component x n of x is said to be the dominant component. An example is giv en in Fig. 3 where C 1 ⊂ R 2 is depicted. These double-cones partition R N into N equiprobable sets with respect to (w .r .t.) the democratic distribution, as stated in the follo wing property . x 2 = x 1 x 2 = − x 1 x 1 x 2 Fig. 3. The double-cone C 1 of R 2 appears as the light red area while the complementary double-cone C 2 is the uncolored area. Property 3. Let x = [ x 1 , . . . , x N ] T be a random vector obeying the democratic distribution D N ( λ ) . Then the pr obability that this vector belongs to a given double-cone is P [ x ∈ C n ] = 1 N . (11) Pr oof: See Appendix [33, App. D] paragraph D-A. Remark 3. This pr operty simply exhibits intuitive intrinsic symmetries of the democratic distribution: the dominant component of a democratically distributed vector is located with equal pr obabilities in any of the cones C n . Moreov er , the following lemma yields some results on conditional distributions related to these sets. Lemma 3. Let x = [ x 1 , . . . , x N ] T be a random vector obeying the democratic distribution D N ( λ ) . Then the following r esults hold x n | x ∈ C n ∼ d G ( N , λ ) (12) x \ n | x ∈ C n ∼ D N − 1 ( λ ) (13) x j | x n , x ∈ C n ∼ U ( − | x n | , | x n | ) ( j 6 = n ) (14) August 27, 2018 DRAFT 9 and P x ∈ C n | x \ n = 1 1 + λ x \ n ∞ (15) p x \ n | x 6∈ C n = λ N − 1 x \ n ∞ C N − 1 ( λ ) e − λ k x \ n k ∞ . (16) Pr oof: See Appendix [33, App. D] paragraph D-B. Remark 4. Accor ding to (12) , the marginal distrib ution of the dominant component is a double- sided Gamma distribution. Con versely , accor ding to (13) , the vector of the non-dominant components is mar ginally distributed accor ding to a democratic distrib ution. Conditionally upon the dominant component, these non-dominant components ar e independently and uniformly distributed on the admissible set, as shown in (14) . The pr obability in (15) shows that the pr obability that the n th component dominates incr eases when the other components ar e of low amplitude. Finally , based on Lemma 3, the following property related to the conditional distributions of D N ( λ ) can be stated. Property 4. Let x = [ x 1 , . . . , x N ] T be a random vector obeying the democratic distribution D N ( λ ) . The pdf of the conditional distribution of a given component x n given x \ n is p x n | x \ n = (1 − c n ) 1 2 x \ n ∞ 1 I n ( x n ) + c n λ 2 e − λ ( | x n | + k x \ n k ∞ ) 1 R \I n ( x n ) (17) with I n , − x \ n ∞ , x \ n ∞ and where c n = P x ∈ C n | x \ n is defined by (15) . Pr oof: See Appendix [33, App. D] paragraph D-C. Remark 5. The pdf in (17) defines a mixture of one uniform distribution and two shifted exponential distributions with pr obabilities 1 − c n and c n / 2 , r espectively . An example of this pdf is depicted in F ig 4. This pr operty opens the door to a natural random variate gener ator accor ding to the democratic distribution thr ough the use of a standar d Gibbs sampler . This random generation strate gy is detailed in paragraph II-F2. E. Pr oximity operator of the ne gative log-pdf The pdf of the democratic distribution D N ( λ ) can be written as p ( x ) ∝ exp ( − g 1 ( x )) with g 1 ( x ) = λ k x k ∞ . (18) August 27, 2018 DRAFT 10 −10 −5 0 5 10 0 0.02 0.04 0.06 0.08 0.1 x −5 0 5 0 0.1 0.2 0.3 0.4 x Fig. 4. Conditional distribution of x n | x \ n when x ∼ D N ( λ ) for N = 2 , λ = 3 and x \ n ∞ = 1 (left) or x \ n ∞ = 10 (right). This paragraph introduces the proximity mapping operator associated with the negati ve log-distrib ution g 1 ( x ) (defined up to a multiplicati ve constant). This proximal operator will be subsequently resorted to implement Monte Carlo algorithms to draw samples from the democratic distribution D N ( λ ) (see paragraph II-F) as well as posterior distrib utions deri ved from a democratic prior (see paragraph III-B3b). In this context, it is conv enient to define the proximity operator of g 1 ( · ) as [34] prox δ g 1 ( x ) = argmin u ∈ R N λ k u k ∞ + 1 2 δ k x − u k 2 2 (19) Up to the authors’ kno wledge, no closed-form expression is av ailable for (19). Ho wev er , this operator can be explicitly computed follo wing the algorithmic scheme detailed in Algo. 1, based on the follo wing property . Property 5. Let x ∈ R N and δ ∈ R + . W e denote ε 1 , . . . , ε J the J distinct values among {| x n |} N n =1 and d 1 , . . . , d J their respective multiplicity order s with P J j =1 d j = N . Then the n -th component of ρ , pr ox δ g 1 ( x ) , denoted as ρ n , is given by ρ n = sign( x n ) φ δ ( x ) if | x n | ≥ φ δ ( x ) x n otherwise (20) wher e φ δ ( x ) = max 0 , φ 1 δ ( x ) , . . . , φ J δ ( x ) (21) and, for j = 1 , . . . , J , φ j δ ( x ) = 1 P j k =1 d k j X k =1 d k ε k − λδ ! . (22) August 27, 2018 DRAFT 11 Algorithm 1: Algorithm to compute prox δ g 1 ( x ) Input : x , δ 1 Identify ε 1 . . . ε J as the J dif ferent values of | x n | ’ s, and d 1 . . . d J their respective multiplicity order ; 2 for j ← 1 to J do 3 Compute φ j δ ( x ) following (22) ; 4 end 5 Compute φ δ ( x ) = max 0 , φ 1 δ ( x ) , . . . , φ J δ ( x ) ; 6 for n ← 1 to N do 7 if | x n | ≥ φ δ ( x ) then 8 ρ n = sign( x n ) φ δ ( x ) ; 9 else 10 ρ n = x n ; 11 end 12 end 13 Set ρ = [ ρ 1 , . . . , ρ N ] T ; Output : ρ = prox δ g 1 ( x ) Pr oof: See Appendix [33, App. E] From Property 5, under this proximity mapping, all components greater than a threshold are reduced to a common value, while all the others remain unchanged. Remark 6. As stated earlier , this pr oximity operator will be r esorted while designing Monte Carlo algorithms able to generate random samples according to distributions derived fr om g 1 ( · ) . In this specific context, almost surely , the multiplicity or ders d j ( j = 1 , . . . , J ) ar e all equal to one, i.e., J = N and ε n = | x n | ( n = 1 , . . . , N ). F . Random variate generation This paragraph introduces three distinct random variate generators that allow to draw samples according to the democratic distribution. August 27, 2018 DRAFT 12 1) Exact r andom variate generator: Property 3 combined with Lemma 3 permits to rewrite the joint distribution of a democratically distributed vector according to the following chain rule p ( x ) = N X n =1 p x \ n | x n , x ∈ C n p ( x n | x ∈ C n ) P [ x ∈ C n ] = N X n =1 Y j 6 = n p ( x j | x n , x ∈ C n ) p ( x n | x ∈ C n ) P [ x ∈ C n ] where P [ x ∈ C n ] , p ( x n | x ∈ C n ) and p ( x j | x n , x ∈ C n ) are gi ven in (11), (12) and (14), respectiv ely . This finding can be fully exploited to design an ef ficient and exact random variate generator for the democratic distribution, see Algo. 2. Algorithm 2: Democratic random v ariate generator using an exact sampling scheme. Input : Parameter λ , dimension N 1 % Drawing the cone of the dominant component 2 Sample n dom uniformly on the set { 1 . . . N } ; 3 % Drawing the dominant component 4 Sample x n dom according to (12); 5 % Drawing the non-dominant components 6 for j ← 1 to N ( j 6 = n dom ) do 7 Sample x j according to (14); 8 end Output : x = [ x 1 , . . . , x N ] T ∼ D N ( λ ) 2) Gibbs sampler -based random gener ator: Property 4 can be e xploited to design a democratic random v ariate generator through the use of a Gibbs sampling scheme. It consists of successively drawing the components x n according to the conditional distributions (17), defined as the mixtures of uniform and truncated Laplacian distributions. After a given number T bi of b urn-in iterations, this generator, described in Algo. 3, provides samples asymptotically distrib uted according to the democratic distribution D N ( λ ) . 3) P-MALA-based random generator: An alternati ve to draw samples according to the democratic distribution is the proximal Metropolis-adjusted Langevin algorithm (P-MALA) introduced in [32]. P-MALA builds a Markov chain x ( t ) T MC t =1 whose stationary distribution is of the form p ( x ) ∝ exp( − g ( x )) August 27, 2018 DRAFT 13 Algorithm 3: Democratic random v ariate generator using a Gibbs sampling scheme. Input : Parameter λ , dimension N , number of burn-in iterations T bi , total number of iterations T MC , initialization x (1 , 0) = h x (1 , 0) 1 , . . . , x (1 , 0) N i T MC 1 for t ← 1 to T MC do 2 f or n ← 1 to N do 3 Set x ( t,n − 1) \ n = h x ( t,n ) 1 , . . . , x ( t,n ) n − 1 , x ( t,n − 1) n +1 , . . . , x ( t,n − 1) N i T ; 4 Draw x ( t,n ) n according to (17); 5 Set x ( t,n ) = h x ( t,n ) 1 , . . . , x ( t,n ) n − 1 , x ( t,n ) n , x ( t,n − 1) n +1 , . . . , x ( t − 1 ,n − 1) N i T ; 6 end 7 Set x ( t +1 , 0) = x ( t,N ) ; 8 end Output : x ( t, 0) ∼ D N ( λ ) (for t > T bi ) where g is a positiv e con vex function with lim k x k→∞ g ( x ) = + ∞ . It relies on successi ve Metropolis Hastings moves with Gaussian proposal distributions whose mean has been chosen as the proximal operator of g ( · ) ev aluated at the current state of the chain. In the particular case of the democratic distribution, P-MALA can be implemented by e xploiting the deriv ations in paragraph II-E, where g ( · ) = g 1 ( · ) has been defined in (18). More precisely , at iteration t of the sampler , a candidate x ∗ is proposed as x ∗ | x ( t − 1) ∼ N prox δ / 2 g 1 x ( t − 1) , δ I N . (23) Then this candidate is accepted as the new state x ( t ) with probability α = min 1 , p ( x ∗ | λ ) p x ( t − 1) | λ q x ( t − 1) | x ∗ q x ∗ | x ( t − 1) ! (24) where q x ∗ | x ( t − 1) is the pdf of the Gaussian distribution given by (23). The algorithmic parameter δ is empirically chosen such that the acceptance rate of the sampler lies between 0 . 4 and 0 . 6 . The full algorithmic scheme is av ailable in Algo. 4. 4) Random gener ator performance comparison: Figure 5 compares the first 15 lags of the empirical autocorrelation function (A CF), computed with 500 samples drawn from the democratic distribution D N (3) for N = 2 (left) and N = 50 (right) using the exact (top), Gibbs sampler -based (middle) and P-MALA (bottom) variate generators. In lower dimensional cases, the chain generated with exact sampling has remarkably lower autocorrelation. Computational times required to generate 1000 samples from the democratic distribution for various dimensions are reported in T able II. These results show that the Gibbs sampler-based method has a August 27, 2018 DRAFT 14 Algorithm 4: Democratic random v ariate generator using P-MALA. Input : Parameter λ , dimension N , number of burn-in iterations T bi , total number of iterations T MC , algorithmic parameter δ , initialization x (0) 1 for t ← 1 to T MC do 2 Draw x ∗ | x ( t − 1) ∼ N prox δ / 2 g 1 x ( t − 1) , δ I N ; 3 Compute α following (24) ; 4 Draw w ∼ U (0 , 1) ; 5 if w < α then 6 Set x ( t ) = x ∗ ; 7 else 8 Set x ( t ) = x ( t − 1) ; 9 end 10 end Output : x ( t ) ∼ D N ( λ ) (for t > T bi ) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 2 · 10 − 2 4 · 10 − 2 6 · 10 − 2 8 · 10 − 2 0 . 1 0 . 12 0 . 14 Empirical Autocorrelation 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 2 · 10 − 2 4 · 10 − 2 6 · 10 − 2 8 · 10 − 2 0 . 1 0 . 12 0 . 14 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 2 · 10 − 2 4 · 10 − 2 6 · 10 − 2 8 · 10 − 2 0 . 1 0 . 12 0 . 14 Empirical Autocorrelation 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 2 · 10 − 2 4 · 10 − 2 6 · 10 − 2 8 · 10 − 2 0 . 1 0 . 12 0 . 14 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 Lag Empirical Autocorrelation 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 Lag Fig. 5. First 15 lags of the empirical autocorrelation function when generating 500 samples drawn from D N ( λ ) using the exact (top), Gibbs sampler-based (middle) and P-MALA (bottom) variate generators with λ = 3 for N = 2 (left) and N = 50 (right). August 27, 2018 DRAFT 15 T ABLE II C U M U L A T I V E T I M E S T O D R AW 500 S A M P L E S AC C O R D I N G T H E D E M O C R A T I C D I S T R I B U T I O N D N ( λ ) W I T H λ = 3 F O R V A R I O U S N . N Exact (ms) Gibbs (ms) P-MALA (ms) 2 2 . 06 × 10 − 1 2 . 05 × 10 3 1 . 11 × 10 2 5 3 . 30 × 10 − 1 2 . 66 × 10 3 1 . 12 × 10 2 10 3 . 46 × 10 − 1 3 . 60 × 10 3 1 . 14 × 10 2 50 9 . 24 × 10 − 1 1 . 01 × 10 4 1 . 27 × 10 2 100 1 . 71 × 10 0 1 . 85 × 10 4 1 . 46 × 10 2 significantly higher cost when compared with the exact random generator . Whereas the exact sampler easily scales in higher dimension, the Gibbs based sampler needs approximately 10 4 more time. This is explained by its intrinsic algorithmic structure: the Gibbs sampler-based method requires to draw a multinomial variable for each component, followed by either exponential or uniform distrib uted v ariables. Con versely , exact random generator only needs to generate one gamma distributed variable and ( N − 1) uniform samples. From these findings, the Gibbs sampler-based and P-MALA strategies might seem out of interest since significantly outperformed by the exact random generator in terms of time computation and mix- ing performance. Howe ver , both exhibit interesting properties that can be exploited in a more general scheme. First, the Gibbs sampler -based generator sho ws that each component of a democratically distributed vector can be easily generated conditionally on the others. Then, P-MALA exploits the algorithmic deriv ation of the proximity operator associated with g 1 ( · ) to draw vectors asymptotically distributed according to the democratic distribution. This opens the door to extended schemes for sampling according to a posterior distrib ution resulting from a democratic prior when possibly no exact sampler is av ailable. This will be discussed in Section III. I I I . D E M O C R AT I C P R I O R I N A L I N E A R I N V E R S E P RO B L E M This section aims to provide a Bayesian formulation of the model underlying the problem described by (1). From a Bayesian perspectiv e, the solution of (1) can be straightforwardly interpreted as the MAP estimator associated with a linear observ ation model characterized by an additiv e Gaussian residual and complemented by a democratic prior assumption. Assuming a Gaussian residual results in a quadratic discrepancy measure and, as a consequence, in a quadratic data fidelity term as in (1). Setting the anti-sparse coding problem into a fully Bayesian framew ork pa ves the way to a comprehensi ve statistical description of the solution. Moreover , it permits to implement other algorithmic strategies beyond MAP estimation, namely Markov chain Monte Carlo techniques. August 27, 2018 DRAFT 16 A. Hierar chical Bayesian model Let y = [ y 1 . . . y M ] T denote an observed measurement vector . These observ ations are assumed to be related to an unkno wn description vector x = [ x 1 . . . x N ] T through a kno wn coding matrix H according to the linear model y = Hx + e . (25) The residual vector e = [ e 1 . . . e N ] T is assumed to be distributed according to a centered multiv ariate Gaussian distrib ution N ( 0 M , σ 2 I M ) . The Bayesian model is introduced in what follows. It relies on the definition of the likelihood function associated with the observation vector y and on the choice of prior distributions for the unknown parameters, i.e., the representation vector x and the residual v ariance σ 2 , assumed to be a priori independent. 1) Likelihood function: The Gaussian property of the additiv e residual term yields the following likelihood function f ( y | x , σ 2 ) = 1 2 π σ 2 M 2 exp − 1 2 σ 2 k y − Hx k 2 2 . (26) 2) Residual variance prior: A noninformativ e Jeffre ys prior distribution is chosen for the residual v ariance σ 2 f σ 2 ∝ 1 σ 2 . (27) 3) Description vector prior: As motiv ated earlier, the democratic distribution introduced in Section II is assigned as the prior distribution of the N -dimensional unknown vector x x | λ ∼ D N ( λ ) . (28) In the follo wing, the hyperparameter λ is set as λ = N µ , where µ is assumed to be unknown. Enforcing the parameter of the democratic distribution to depend on the problem dimension allows the prior to be scaled with this dimension. Indeed, as stated in (12), the absolute value of the dominant component is distributed according to the Gamma distribution G ( N , λ ) , whose mean and variance are N /λ and N /λ 2 , respectiv ely . W ith the proposed scalability , the prior mean is constant with the dimension E [ | x n | | x ∈ C n , µ ] = 1 /µ (29) and the variance tends to zero v ar [ | x n | | x ∈ C n , µ ] = 1 / ( N µ 2 ) . (30) August 27, 2018 DRAFT 17 4) Hyperparameter prior: The prior modeling introduced in the pre vious paragraph is comple- mented by assigning prior distribution to the unknown hyperparameter µ , introducing a second lev el in the Bayesian hierarchy . More precisely , a conjugate Gamma distribution is chosen as a prior for µ µ ∼ G ( a, b ) . (31) since the conjugacy property allows the posterior distribution to be easily deriv ed. The values of a and b will be chosen to obtain a flat prior . 5) P osterior distrib ution: The posterior distribution of the unknown parameter vector θ = { x , σ 2 , µ } can be computed from the following hierarchical structure: f ( θ | y ) ∝ f ( y | x , σ 2 ) f ( x , σ 2 | µ ) f ( µ ) (32) where f ( x , σ 2 | µ ) = f ( σ 2 ) f ( x | µ ) (33) and f ( y | x , σ 2 ) , f ( σ 2 ) , f ( x | µ ) and f ( µ ) hav e been defined in Eq. (26) to (31), respectiv ely . Thus, this posterior distribution can be written as f ( x , σ 2 , µ | y ) ∝ exp − 1 2 σ 2 k y − Hx k 2 2 × 1 C N ( µN ) exp ( − µN k x k ∞ ) × 1 σ 2 M 2 +1 1 R + ( σ 2 ) × b a Γ( b ) µ a − 1 exp ( − bµ ) . (34) As e xpected, for given values of the residual variance σ 2 and the democratic parameter λ = µN , maximizing the posterior (34) can be formulated as the optimization problem in (1), for which some algorithmic strategies have been for instance introduced in [27] and [28]. In this paper , a different route has been taken by deriving inference schemes relying on MCMC algorithms. This choice permits to include the nuisance parameters σ 2 and µ into the model and to estimate them jointly with the representation v ector x . Moreover , since the proposed MCMC algorithms generate a collection x ( t ) , µ ( t ) , σ 2( t ) N MC t =1 asymptotically distrib uted according to the posterior of interest (32), the y provide a good knowledge of the statistical distribution of the solutions. B. MCMC algorithm This section introduces two MCMC algorithms to generate samples according to the posterior (34). They are two specific instances of Gibbs samplers which generate samples according to the conditional distributions associated with the posterior (34), follo wing Algo. 5. As shown below , the steps for sampling according to the conditional distributions of the residual variance f ( σ 2 | y , x ) August 27, 2018 DRAFT 18 and the democratic parameter f ( µ | x ) are straightforward. In addition, generating samples for the representation vector f ( x | µ, y ) can be achie ved component-by-component using N Gibbs mo ves, follo wing the strategy in paragraph II-F2. Howe ver , for high dimensional problems, such a crude strategy may suffer from poor mixing properties, leading to slow con ver gence of the algorithm. T o alle viate this issue, an alternati ve approach consists of sampling the full vector x | µ, y using a P- MALA step [32], similar to the one proposed in paragraph II-F3. These two strategies are detailed in the following paragraphs. Algorithm 5: Gibbs sampler Input : Observation vector y , coding matrix H , hyperparameters a and b , number of burn-in iterations T bi , total number of iterations T MC , algorithmic parameter δ , initialization x (0) 1 for t ← 1 to T MC do 2 % Drawing the residual variance 3 Sample σ 2( t ) according to (35). ; 4 % Drawing the democratic parameter 5 Sample µ ( t ) according to (37). ; 6 % Drawing the repr esentation vector 7 Sample x ( t ) using, either (see paragraph III-B3) • Gibbs steps, i.e., following (38) ; • P-MALA step, i.e., following (41) and (42); 8 end Output : A collection of samples µ ( t ) , σ 2( t ) , x ( t ) T MC t = T bi +1 asymptotically distributed according to (34). 1) Sampling the residual variance: Sampling according to the conditional distribution of the residual variance can be conducted according to the following in verse-gamma distribution σ 2 | y , x ∼ I G M 2 , 1 2 k y − Hx k 2 2 (35) 2) Sampling the democratic hyperparameter: Looking carefully at (34), the conditional posterior distribution of the democratic parameter µ is f ( µ | x ) ∝ µ N exp ( − µ k x k ∞ ) µ a − 1 exp ( − bµ ) . (36) Therefore, sampling according to f ( µ | x ) is achiev ed as follows µ | x ∼ G ( a + N , b + N k x k ∞ ) (37) August 27, 2018 DRAFT 19 3) Sampling the description vector: Follo wing the technical dev elopments of paragraph II-F, two strategies can be considered to generate samples according to the conditional posterior distrib ution of the representation vector f ( x | µ, σ 2 , y ) . They are detailed below . a) Component-wise Gibbs sampling: A first possibility to draw a v ector x according to f ( x | µ, σ 2 , y ) is to successiv ely sample according to the conditional distribution of each component given the others, namely , f ( x n | x \ n , µ, σ 2 , y ) , as in algorithm of paragraph II-F2. More precisely , straightforward computations yield the following 3 -mixture of truncated Gaussian distributions for this conditional x n | x \ n , µ, σ 2 , y ∼ 3 X i =1 ω in N I in µ in , s 2 n (38) where N I ( · , · ) denotes the Gaussian distribution truncated on the I and the truncation sets are defined as I 1 n = −∞ , − x \ n ∞ I 2 n = − x \ n ∞ , x \ n ∞ I 3 n = x \ n ∞ , + ∞ . The probabilities ω in ( i = 1 , 2 , 3 ) as well as the (hidden) means µ in ( i = 1 , 2 , 3 ) and variance s 2 n of these truncated Gaussian distributions are gi ven in Appendix. This specific nature of the conditional distribution is intrinsically related to the nature of the conditional prior distribution stated in Property 4, which has already exhibited a 3 -component mixture: one uniform distrib ution and tw o (shifted) exponential distributions defined over I 2 n , I 1 n and I 3 n , respectiv ely (see Remark 5). Note that sampling according to truncated distributions can be achiev ed using the strategy proposed in [35]. b) P-MALA: Similarly to the strategy dev eloped in paragraph II-F3 to sample according to the prior distrib ution, sampling according to the conditional distribution f ( x | µ, σ 2 , y ) can be achie ved using a P-MALA step [32]. In this case, the distribution of interest can be written as f ( x | µ, σ 2 , y ) ∝ exp ( g ( x )) where g ( x ) deri ves from the Gaussian (ne gati ve log-) likelihood function and the (neg ativ e log-) distribution of the democratic prior so that g ( x ) = 1 2 σ 2 k y − Hx k 2 2 + λ k x k ∞ (39) with λ = µN . Howe ver , up to the authors’ kno wledge, the proximal operator associated with g ( · ) in (39) has no close form solution. T o alleviate this problem, a first order approximation is considered 2 , 2 Note that a similar step is inv olved in the fast iterative truncation algorithm (FITRA) [30], a deterministic counterpart of the proposed algorithm and considered in the next section for comparison. August 27, 2018 DRAFT 20 as recommended in [32] prox δ / 2 g ( x ) ≈ prox δ / 2 g 1 x + δ ∇ 1 2 σ 2 k y − Hx k 2 2 (40) where g 1 ( · ) = λ k·k ∞ has been defined in paragraph II-F3 and the corresponding proximity mapping is av ailable through Algo. 1. Finally , at iteration t of the main algorithm, sampling according to the conditional distribution f ( x | µ, σ 2 , y ) consists of drawing a candidate x ∗ | x ( t − 1) ∼ N prox δ / 2 g x ( t − 1) , δ I N (41) and to accept this candidate as the new state x ( t ) with probability α = min 1 , f x ∗ | µ, σ 2 , y f x ( t − 1) | µ, σ 2 , y q x ( t − 1) | x ∗ q x ∗ | x ( t − 1) ! . (42) C. Infer ence The sequences x ( t ) , σ 2( t ) , µ ( t ) T MC t =1 generated by the MCMC algorithms proposed in paragraph III-B are used to approximate Bayesian estimators. After a b urn-in period of N bi iterations, the set of generated samples X = x ( t ) T MC t = T bi +1 is asymptotically distrib uted according to the mar ginal posterior distribution f ( x | y ) , resulting from the marginalization of the joint posterior distrib ution f x , σ 2 , µ | y in (34) over the nuisance parameters σ 2 and µ f ( x | y ) = Z f x , σ 2 , µ | y dσ 2 dµ (43) ∝ k y − Hx k − M 2 2 ( b + N k x k ∞ ) − ( a + N ) . (44) As a consequence, while the minimum mean square error (MMSE) estimator of the representation vector x can be approximated as an empirical av erage over the set X ˆ x MMSE = E [ x | y ] (45) ' 1 T r T MC X t =1 x ( t ) . (46) with T r = T MC − T bi , the marginal maximum a posteriori (mMAP) estimator can be approximated as ˆ x mMAP = argmax x ∈ R N f ( x | y ) (47) ' argmax x ( t ) ∈X f x ( t ) | y . (48) August 27, 2018 DRAFT 21 I V . E X P E R I M E N T S This section reports several simulation results to illustrate the performance of the Bayesian anti- sparse coding algorithms introduced in Section III. In paragraph IV -A, the v alidity of the samplers deri ved in paragraph III-B has been assessed following the experimental scheme in [36], exploiting some properties of the democratic distributions enounced in Section II. Paragraph IV -B e valuates the performances of the two versions of the samplers (i.e., using Gibbs or P-MALA steps) on a toy example, by considering measurements resulting from a representation vector whose coefficients are all equal up to a sign. Finally , paragraph IV -C compares the performances of the proposed algorithm and its deterministic counterpart introduced in [30]. For all experiments, the coding matrices H have been chosen as randomly subsampled columnwise DCT matrices since the y ha ve shown to yield democratic representations with small ` ∞ -norm and good democracy bounds [27]. Howe ver , note that a deep in vestigation of these bounds is out of the scope of the present paper . A. Assessment of the Bayesian anti-sparse coding algorithms W e first consider a first experiment to assess the validity of the Monte Carlo algorithms introduced in paragraph III-B and, in particular , the two methods proposed to sample according to the conditional distribution of the representation vector f x | y , σ 2 , µ , see step 7 in Algo. 5. T o this aim, the so- called successive conditional sampling strategy proposed by Ge weke in [36] is followed for fix ed nuisance parameters σ 2 and µ . This procedure does not fully assert the correctness of the sampler but it may help to detect errors, e.g., as in [37]. More precisely , it consists of dra wing a sequence x ( t ) , y ( t ) T MC t =1 asymptotically distributed according to the joint distribution f x , y | σ 2 , µ using the Gibbs sampler described in Algo. 6. Algorithm 6: Successiv e conditional sampling Input : Residual variance σ 2 , democratic parameter µ , coding matrix H . 1 Sample x (0) according to D N ( µN ) ; 2 for t ← 1 to T MC do 3 Sample y ( t ) | x ( t − 1) , σ 2 ∼ N ( H x ( t ) , σ 2 ) ; 4 Sample x ( t ) | y ( t ) , µ, σ 2 using, either • Gibbs steps, i.e., following (38) ; • P-MALA step, i.e., following (41) and (42); 5 end Output : A collection of samples y ( t ) , x ( t ) T MC t = T bi +1 asymptotically distributed according to f y , x | σ 2 , µ August 27, 2018 DRAFT 22 One can notice that this algorithm boils do wn to successiv ely sample according to the Gaussian likelihood distribution f y | x , σ 2 , µ and the conditional posterior of interest f x | y , σ 2 , µ . This later step is achiev ed using either the component-wise Gibbs sampler or P-MALA technique described in paragraph III-B3. Within this framew ork, the generated samples x ( t ) should be asymptotically distributed according to the prior democratic distribution f ( x | µ ) . Thus they can be exploited to specifically assess the validity of this step, by resorting to the properties of this distrib ution, see Section II. In this experiment, we propose to focus on one of these properties: the absolute value of the dominant component f | x n | µ, x n ∈ C n follo ws the gamma distribution G ( N , λ ) with λ = N µ , see (12). Figure 6 (left) compares the theoretical pdf of this gamma distribution with the empirical pdfs computed from T MC = 2 × 10 4 samples generated by the Geweke’ s scheme with the Gibbs (top) and P-MALA (bottom) samplers, where M = N = 3 , µ = 2 and σ 2 = 0 . 25 . Figure 6 (right) sho ws the corresponding quantile-quantile (Q-Q) plots which tends to ascertain the validity of the two versions of the MCMC algorithm. B. P erformance analysis on a toy example This paragraph focuses on a toy example to illustrate the con ver gence of the two versions of the proposed algorithm, i.e., based on Gibbs or P-MALA steps detailed in paragraphs III-B3a and III-B3b, respecti vely . T o this end, a simple experimental set-up with M = N = 16 has been considered where anti-sparse vectors x hav e been generated with coefficients randomly chosen among {− N − 1 , + N − 1 } . Observ ation vectors are then obtained following the free-noise forward model y = Hx . The proposed MCMC algorithms are used to generate samples ( x ( t ) , σ ( t ) , µ ( t ) ) T MC t = T bi asymptotically distributed according to the joint posterior distribution (34) with T MC = 3000 iterations including T bi = 2000 burn-in iterations. The MMSE and mMAP estimators of representation vector have been approximated from these samples follo wing the strategy described in paragraph III-C. T wo criteria hav e been used to ev aluate the performance of these estimators SNR x = 10 log 10 k x k 2 2 k x − ˆ x k 2 2 (49) P APR = N k ˆ x k 2 ∞ k ˆ x k 2 2 (50) where ˆ x refers to the MMSE or mMAP estimator of x . The signal-to-noise ratio SNR x measures the quality of the estimation with respect to the unkno wn (democratic) signal x . Con versely , the peak-to-av erage power ratio P APR quantifies anti-sparsity by measuring the ratio between the crest of the estimated signal and its av erage value. Note that the proposed algorithms do not aim at directly minimizing the P APR: the use of a democratic distribution prior should promote anti-sparsity and therefore estimates with low P APR. August 27, 2018 DRAFT 23 ||x|| ∞ 0 1 2 3 4 5 f(||x|| ∞ ) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Gamma distribution quantiles 0 1 2 3 4 5 Empirical distribution quantiles 0 1 2 3 4 5 ||x|| ∞ 0 1 2 3 4 5 f(||x|| ∞ ) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Gamma distribution quantiles 0 1 2 3 4 5 Empirical distribution quantiles 0 1 2 3 4 5 Fig. 6. Left: theoretical Gamma pdf of the dominant component absolute value (red) and empirical pdf (blue) resulting from 2 × 10 4 samples generated by successiv e conditional sampling (Algo. 6) with the Gibbs sampler (top) and P-MALA (bottom). Right: corresponding Q-Q plots. Figure 7 shows the ev olution of both criteria through iterations for both versions of the algorithm. Note that, according to (46) and (48), the mMAP estimators are approximated from all the generated samples while the MMSE estimates are only computed from samples generated after the burn-in period, located with a vertical line. The plots associated with the mMAP estimates show that, after less than 200 iterations, the Gibbs sampler generates vectors with P APR lo wer that 1 . 05 and SNR x higher than 75 dB. The MMSE estimator computed from these samples quickly con ver ges to similar results (after the burn-in period). Conv ersely , the estimators approximated from the samples generated using the P-MALA steps need 10 times more iterations to con verge to wards solutions with P APR around 1 . 2 and SNR x close to 40 dB. Howe ver , considering the computational time with a personal computer equipped with a 2 . 8 Ghz Intel i5 processor , the simulation of 3000 samples requires 20 seconds using Gibbs sampling and only 2 seconds using P-MALA steps. These observations highlight the fact that the algorithm based on P-MALA steps is much faster ev en though it needs more samples August 27, 2018 DRAFT 24 0 500 1000 1500 2000 2500 3000 0 50 100 150 200 Iteration number SNR x burn−in P−MALA MMSE P−MALA mMAP Gibbs MMSE Gibbs mMAP 0 500 1000 1500 2000 2500 3000 1 1.5 2 2.5 3 Iteration number PAPR burn−in Fig. 7. As functions of the iteration number , SNR x (top) and P APR (bottom) associated with mMAP (dashed lines) and MMSE (continuous lines) estimates computed using the proposed algorithm based on Gibbs steps (blue) and P-MALA steps (red). The end of the burn-in period is localized with a vertical black dotted line. than the full Gibbs sampler to build robust estimators. T o alleviate this limitation, the strategy adopted in the next experiments performs 20 Metropolis-Hastings moves (42) within a single iteration of the MCMC algorithm (as recommended in [32]). C. P erformance comparison 1) Experimental set-up: In this experiment, the observ ation vector y is composed of coefficients independently and identically distrib uted according to a Gaussian distrib ution, as in [27]. The proposed MCMC algorithm is applied to infer the anti-sparse representation x of this measurement vector y with respect to the M × N coding matrix H for two distinct scenarios. Scenario 1 considers a small dimension problem with M = 50 and N = 70 . In Scenario 2, a higher dimension problem has been addressed, i.e., with M = 128 and N ranging from 128 to 256 , which permits to ev aluate the performance of the algorithm as a function of the ratio N / M . In Scenario 1 (resp., Scenario 2), the proposed mMAP and MMSE estimators are computed from a total of T MC = 12 × 10 3 (resp., T MC = 55 × 10 3 ) iterations, including T bi = 10 × 10 3 (resp., T bi = 50 × 10 3 ) b urn-in iterations. For this latest scenario, the algorithm based on Gibbs steps, see paragraph III-B3a, has not been considered because of its computational burden, which experimentally justifies the interest of the proximal MCMC-based approach for large scale problems. August 27, 2018 DRAFT 25 Algorithm performances have been e valuated over 20 Monte Carlo simulations thanks to two figures-of-merit. The anti-sparse level of the recov ered representation v ector ˆ x has been measured using the P APR defined in (50). Since the actual representation vector x is not av ailable anymore (as in the previous experiment), the reconstruction error denoted SNR y and defined by SNR y = 10 log 10 k y k 2 2 k y − H ˆ x k 2 2 . (51) is the second figure-of-merit. The proposed algorithm is compared with a recent P APR reduction technique, detailed in [30]. This fast iterativ e truncation algorithm (FITRA) is a deterministic counterpart of the proposed MCMC algorithm and solves the ` ∞ -penalized least-squares problem (1). Similarly to various v ariational techniques, FITRA needs the prior kno wledge of the hyperparameters λ (anti-sparsity lev el) and σ 2 (residual variance) or , equiv alently , of the regularization parameter β defined (up to a constant) as the product of the two hyperparameters, i.e., β , 2 λσ 2 . As a consequence, in the following experiments, this parameter β has been chosen according to 3 distinct rules. The first one, denoted FITRA-mmse, consists of applying FITRA with β = 2 ˆ λ MMSE ˆ σ 2 MMSE , where ˆ λ MMSE and ˆ σ 2 MMSE are the MMSE estimates obtained with the proposed P-MALA based algorithm. In the second and third configurations, the regularization parameter β has been tuned to reach two solutions corresponding to either a target reconstruction error SNR y = 20 dB (and free P APR) or a tar get anti-sparsity lev el P APR = 1 . 5 (and free SNR y ), denoted FITRA-snr and FITRA-papr, respectiv ely . For all these configurations, FITRA has been run with a maximum of 500 iterations. Moreo ver , to illustrate the regularizing ef fect of the democratic prior (or , similarly , the ` ∞ -penalization), the proposed algorithm and the 3 configurations of FITRA hav e been finally compared with the least-squares (LS) solution as well as the MMSE and mMAP estimates resulting from a Bayesian model based on a Gaussian prior (or, similarly , an ` 2 -penalization). 2) Results: T able III sho ws the results in Scenario 1 ( M = 50 and N = 70 ) for all considered algorithms in terms of SNR y and P APR. For this scenario, the full Gibbs method needs approximately 6 minutes while P-MALA needs 8 seconds only . The mMAP and the MMSE estimates pro vided by P-MALA reach reconstruction errors of SNR y = 23 . 7 dB and SNR y = 22 . 4 dB, respectively . The mMAP estimate obtained using the full Gibbs sampler performs quite similarly while numerous estimates from the Gibbs MMSE ha ve con ver ged to solutions that do not ensure correct reconstruction, which explains worse SNR y results. This is the signature of an unstable behavior of the Gibbs MMSE estimate. When using FITRA-mmse, solutions with similar SNR y but lo wer P APR are recovered. Both MCMC and FITRA algorithms hav e provided anti-sparse representations with lower P APR than LS or ` 2 -penalized solutions, which confirms the interest of the democratic prior or , equiv alently , the ` ∞ -penalization. August 27, 2018 DRAFT 26 T ABLE III S C E N A R I O 1 : R E S U LT S I N T E R M S O F S N R y A N D PA P R F O R V A R I O U S A L G O R I T H M S . SNR y P APR P-MALA MMSE 22.4 3.69 P-MALA mMAP 23.7 2.82 Gibbs MMSE 9.6 3.69 Gibbs mMAP 12.7 2.82 FITRA-mmse 21.8 1.53 FITRA-snr 19.9 1.86 FITRA-papr 9.3 1.5 LS 306.4 7.27 Gaussian prior MMSE 81.4 7.04 Gaussian prior mMAP 154.6 6.92 Fig. 8 displays the results for a gi ven realization of the measurement v ector y where the SNR y is plotted as a function of P APR. T o provide a whole characterization of FITRA and illustrate the trade-of f between the expected reconstruction error and anti-sparsity le vel, the solutions provided by FITRA corresponding to a wide range of regularization parameter β are sho wn. The mMAP and MMSE solutions recovered by the two versions of the proposed algorithm are also reported in this SNR y vs. P APR plot. They are located close to the critical region between solutions with lo w P APR and SNR y and solutions with high P APR and SNR y : the proposed method recovers relev ant solutions in an unsupervised way . While Gibbs estimates seem to reach a better compromise than P-MALA ones, we emphasize that the Gibbs sampler is in f act relati vely unstable and therefore less robust. Moreov er , the Gibbs sampler does not scale to high dimensions due to its prohibitiv e computational cost. Scenario 2 permits to ev aluate the performances of the algorithm as a function of the ratio N / M . For measurement vectors of fixed dimension M = 128 , the anti-sparse coding algorithms aim at recov ering representation vectors of increasing dimensions N = 128 , . . . , 256 . As a consequence, for a gi ven P APR level of anti-sparsity , the SNR y is expected to be an increasing function of N/ M . Fig. 9 confirms this intuition since the performance of FITRA-papr in terms of SNR y (slightly) increases when N / M increases. Con versely , for a giv en level SNR y of reconstruction error , the P APR is expected to be a decreasing function of this ratio. Fig. 10 sho ws that the P APR of FITRA- snrdecreases when N / M increases. Moreover , Fig. 9 shows that, in term of SNR y , the behavior of the P-MALA mMAP and MMSE estimates is similar to FITRA-mmse’ s. Howe ver , they are able to August 27, 2018 DRAFT 27 PAPR 1 2 3 4 5 6 7 8 9 SNR y 0 50 100 150 200 250 300 350 β 10 -5 10 -4 10 -3 10 -2 10 -1 10 0 10 1 10 2 P-MALA MMSE P-MALA mMAP Gibbs MMSE Gibbs mMAP FITRA β Fig. 8. Scenario 1: SNR y as a function of P APR. The path for the FITRA regularization parameter β is depicted as green dashed line with the scale in the left y -axis. achie ve lo wer P APR once the ratio N / M is greater than 1 . 3 and 1 . 4 , respecti vely , as illustrated in Fig. 10. Ratio N/M 1 1.1 1.2 1.3 1.4 1.5 2 SNR y 0 20 40 60 80 100 120 P-MALA MMSE P-MALA mMAP FITRA-mmse FITRA-snr FITRA-papr Fig. 9. Scenario 2: SNR y as a function of the ratio N / M . V . C O N C L U S I O N This paper introduced a fully Bayesian framew ork for anti-sparse coding of a giv en measurement vector on a known and potentially over -complete dictionary . T o deri ve a Bayesian formulation of the August 27, 2018 DRAFT 28 Ratio N/M 1 1.1 1.2 1.3 1.4 1.5 2 PAPR 1 1.5 2 2.5 3 3.5 4 4.5 5 5.5 P-MALA MMSE P-MALA mMAP FITRA-mmse FITRA-snr FITRA-papr Fig. 10. Scenario 2: P APR as a function of the ratio N / M . problem, a new probability distrib ution was introduced. V arious properties of this so-called democratic distribution were exhibited, which permitted to design an exact random variate generator as well as two MCMC-based methods. This distribution was used as a prior for the representation vector in a linear Gaussian in verse problem, a probabilistic version of the anti-sparse coding problem. The residual variance as well as the anti-sparsity level were included in a fully Bayesian model, to be estimated jointly with the anti-sparse code. A Gibbs sampler was deriv ed to generate samples distributed according to the joint posterior distribution of the coef ficients of representation, the residual v ariance and the anti-sparse lev el. A second sampler was also proposed to scale to higher dimensions. T o this purpose, the proximity mapping of the ` ∞ -norm was considered to design a P-MALA within Gibbs algorithm. The generated samples were used to approximate two Bayesian estimators of the representation vector , namely the MMSE and mMAP estimators. The validity of the proposed algorithms was first assessed following the successive conditional sampling scheme proposed in [36]. Then, they were ev aluated through various experiments, and compared with FITRA a variational counterpart of the proposed MCMC algorithms. While fully unsupervised, they produced solutions comparable to FITRA in terms of reconstruction error and P APR, with the noticeable advantage to be fully unsupervised. In all experiments, as expected, the democratic prior distrib ution, was able to promote anti-sparse solutions of the coding problem. For that specific task, the mMAP estimator generally provided more relev ant solutions than the MMSE estimator . Moreover , the P-MALA-based algorithm seemed to be more robust than the full August 27, 2018 DRAFT 29 Gibbs sampler and had the ability to scale to high dimension problems, both in term of computational times and performances. Future works include the unsupervised estimation of the coding matrix jointly with the sparse code. This would open the door to the design of encoding matrices that would ensure equal spreading of the information ov er their atoms. Furthermore, since the P-MALA based sampler showed promising results, it w ould be rele vant to inv estigate the geometric ergodicity of the sampler . Unlike most of the illustrati ve examples considered in [32], this property can not be easily stated for the democratic distribution since it is not C 1 but only C 0 . A C K N O W L E D G M E N T S The authors would like to thank Dr . V incent Mazet, Univ ersit ´ e de Strasbourg, France, for providing the code to draw according to truncated Gaussian distributions following [35]. A P P E N D I X P O S T E R I O R D I S T R I B U T I O N O F T H E R E P R E S E N TA T I O N C O E FFI C I E N T S The (hidden) mean and variances of the truncated Gaussian distributions inv olved in the mixture distribution (38) are giv en by µ 1 n = 1 k h n k 2 h T n e n + σ 2 λ µ 2 n = 1 k h n k 2 h T n e n µ 3 n = 1 k h n k 2 h T n e n − σ 2 λ and s 2 n = σ 2 k h n k 2 2 where h i denotes the i th column of H and e n = y − P i 6 = n x i h i . Moreov er , the weights associated with each mixture component are ω in = u in P 3 j =1 u j n (52) with u 1 n = exp µ 2 1 n 2 s 2 n + λ x \ n ∞ φ µ 1 n ,s 2 n − x \ n ∞ u 2 n = exp µ 2 2 n 2 s 2 n × h φ µ 2 n ,s 2 n x \ n ∞ − φ µ 2 n ,s 2 n − x \ n ∞ i u 3 n = exp µ 2 3 n 2 s 2 n + λ x \ n ∞ × 1 − φ µ 3 n ,s 2 n x \ n ∞ August 27, 2018 DRAFT 30 where φ µ,s 2 ( · ) is the cumulated distribution function of the normal distribution N ( µ, s 2 ) . R E F E R E N C E S [1] E. J. Cand ` es and M. B. W akin, “ An introduction to compressiv e sampling, ” IEEE Signal Pr ocess. Mag. , vol. 25, no. 2, pp. 21–30, March 2008. [2] M. A. Davenport, M. F . Duarte, Y . C. Eldar , and G. Kutyniok, “Introduction to compressed sensing, ” in Compressed Sensing: Theory and Applications , Y . C. Eldar and G. Kutyniok, Eds. Cambridge, UK: Cambridge Univ ersity Press, 2012, ch. 1, pp. 1–64. [3] R. Gribonv al, “Should penalized least squares regression be interpreted as maximum a posteriori estimation?” IEEE T rans. Signal Pr ocess. , vol. 59, no. 5, pp. 2405–2410, May 2011. [4] R. Tibshirani, “Regression shrinkage and selection via the LASSO, ” J. Roy . Stat. Soc. Ser . B , vol. 58, no. 1, pp. 267–288, 1996. [5] S. D. Babacan, R. Molina, and A. K. Katsaggelos, “Bayesian compressiv e sensing using Laplace priors, ” IEEE T rans. Image Process. , vol. 19, no. 1, pp. 53–63, Jan. 2010. [6] F . Caron and A. Doucet, “Sparse Bayesian nonparametric regression, ” in Proc. Int. Conf. Machine Learning (ICML) , Helsinki, Finland, July 2008. [7] M. E. Tipping, “Sparse Bayesian learning and the relev ance vector machine, ” J. Mach. Learning Resear ch , vol. 1, pp. 211–244, 2001. [8] A. Lee, F . Caron, A. Doucet, and C. Holmes, “ A hierarchical Bayesian framew ork for constructing sparsity-inducing priors, ” arXiv .or g , Sept. 2010. [9] K. E. Themelis, A. A. Rontogiannis, and K. D. K outroumbas, “ A novel hierarchical Bayesian approach for sparse semisupervised hyperspectral unmixing, ” IEEE T rans. Signal Pr ocess. , vol. 60, no. 2, pp. 585–599, Feb. 2012. [10] S. Ji, Y . Xue, and L. Carin, “Bayesian compressiv e sensing, ” IEEE T rans. Signal Pr ocess. , vol. 56, no. 6, pp. 2346– 2356, June 2008. [11] D. Tzikas, A. Likas, and N. Galatsanos, “V ariational Bayesian sparse kernel-based blind image deconv olution with Student’ s-t priors, ” IEEE T rans. Image Pr ocess. , vol. 18, no. 4, pp. 753–764, April 2009. [12] C. F ´ evotte and S. J. Godsill, “ A Bayesian approach for blind separation of sparse sources, ” IEEE T rans. Audio, Speech, Language Process. , vol. 14, no. 6, pp. 2174–2188, Nov . 2006. [13] N. Dobigeon, A. O. Hero, and J.-Y . T ourneret, “Hierarchical Bayesian sparse image reconstruction with application to MRFM, ” IEEE T rans. Image Process. , vol. 18, no. 9, pp. 2059–2070, Sept. 2009. [14] C. Soussen, J. Idier, D. Brie, and J. Duan, “From Bernoulli-Gaussian decon volution to sparse signal restoration, ” IEEE T rans. Signal Pr ocess. , vol. 29, no. 10, pp. 4572–4584, Oct. 2011. [15] L. Chaari, H. Batatia, N. Dobigeon, and J.-Y . T ourneret, “ A hierarchical sparsity-smoothness Bayesian model for ` 0 − ` 1 − ` 2 regularization, ” in Pr oc. IEEE Int. Conf. Acoust., Speech, and Signal Processing (ICASSP) , Florence, Italy , May 2014, pp. 1901–1905. [16] E. Remes, “Sur une propri ´ et ´ e extr ´ emale des polyn ˆ omes de Tchebychef, ” Communications de l’Institut des Sciences Math ´ ematiques et M ´ ecaniques de l’Universit ´ e de Kharkoff et de la Soci ´ et ´ e Math ´ ematique de Kharkoff , vol. 13, no. 1, pp. 93–95, 1936. [17] T . W . Parks and J. H. McClellan, “Chebyshev approximation for nonrecursive digital filters with linear phase, ” IEEE T rans. Cir c. Theory , vol. 19, no. 2, pp. 189–194, March 1972. [18] J. H. McClellan and T . W . Parks, “ A personal history of the Parks-McClellan algorithm, ” IEEE Signal Process. Mag. , vol. 22, no. 2, pp. 82–86, March 2005. [19] L. W . Neustadt, “Minimum effort control systems, ” J. SIAM Control , vol. 1, no. 1, pp. 16–31, 1962. August 27, 2018 DRAFT 31 [20] J. A. Cadzow , “ Algorithm for the minimum-effort problem, ” IEEE T rans. Autom. Contr . , vol. 16, no. 1, pp. 60–63, 1971. [21] Y . L yubarskii and R. V ershynin, “Uncertainty principles and vector quantization, ” IEEE T rans. Inf. Theory , vol. 56, no. 7, pp. 3491–3501, July 2010. [22] Z. Cvetkovi ´ c, “Resilience properties of redundant expansions under additiv e noise and quantization, ” IEEE T rans. Inf. Theory , vol. 29, no. 3, pp. 644–656, March 2003. [23] A. R. Calderbank and I. Daubechies, “The pros and cons of democracy , ” IEEE T rans. Inf. Theory , vol. 48, no. 6, pp. 1721–1725, June 2002. [24] B. Farrell and P . Jung, “ A Kashin approach to the capacity of the discrete amplitude constrained Gaussian channel, ” in Pr oc. Int. Conf. Sampling Theory and Applications (SAMPT A) , Marseille, France, May 2009. [25] J. Ilic and T . Strohmer, “P APR reduction in OFDM using Kashin’ s representation, ” in Pr oc. IEEE Int. W orkshop Signal Pr ocess. Adv . W ireless Comm. , Perugia, Italy , 2009, pp. 444–448. [26] C. Studer , Y . W otao, and R. G. Baraniuk, “Signal representations with minimum ` ∞ -norm, ” in Pr oc. Ann. Allerton Conf. Comm. Contr ol Comput. (Allerton) , 2012, pp. 1270–1277. [27] C. Studer , T . Goldstein, W . Y in, and R. G. Baraniuk, “Democratic representations, ” IEEE T rans. Inf. Theory , submitted. [Online]. A vailable: http://arxiv .org/abs/1401.3420/ [28] J.-J. Fuchs, “Spread representations, ” in Proc. IEEE Asilomar Conf. Signals, Systems, Computers , 2011. [29] H. Jegou, T . Furon, and J.-J. Fuchs, “ Anti-sparse coding for approximate nearest neighbor search, ” in Proc. IEEE Int. Conf. Acoust., Speech, and Signal Pr ocessing (ICASSP) , 2012, pp. 2029–2032. [30] C. Studer and E. G. Larsson, “P AR-aware large-scale multi-user MIMO-OFDM downlink, ” IEEE J. Sel. Ar eas Comm. , vol. 31, no. 2, pp. 303–313, Feb . 2013. [31] J. T an, D. Baron, and L. Dai, “Wiener filters in Gaussian mixture signal estimation with ` ∞ -norm error , ” IEEE T rans. Inf. Theory , vol. 60, no. 10, pp. 6626–6635, Oct. 2014. [32] M. Pereyra, “Proximal Markov chain Monte Carlo algorithms, ” Stat. Comput. , May 2015. [33] C. Elvira, P . Chainais, and N. Dobigeon, “Bayesian anti-sparse coding – Complementary results and supporting materials, ” University of T oulouse, IRIT/INP-ENSEEIHT , and Ecole Centrale Lille, LA GIS UMR CNRS, France, T ech. Rep., Dec. 2015. [Online]. A vailable: http://www .enseeiht.fr/ ∼ dobigeon/papers/Elvira T echReport 2015.pdf [34] J.-J. Moreau, “Fonctions con vex es duales et points proximaux dans un espace hilbertien, ” CR Acad. Sci. P aris S ´ er . A Math , vol. 255, pp. 2897–2899, 1962. [35] N. Chopin, “Fast simulation of truncated gaussian distributions, ” vol. 21, pp. 275–288, 2011. [36] J. Gewek e, “Getting it right: Joint distribution tests of posterior simulators, ” J. Amer . Stat. Assoc. , vol. 99, pp. 799–804, Sept. 2004. [37] D. Knowles and Z. Ghahramani, “Nonparametric bayesian sparse factor models with application to gene expression modeling, ” Ann. Appl. Stat. , vol. 5, no. 2B, pp. 1534–1552, 06 2011. August 27, 2018 DRAFT
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment