Item-Item Music Recommendations With Side Information
Online music services have tens of millions of tracks. The content itself is broad and covers various musical genres as well as non-musical audio content such as radio plays and podcasts. The sheer scale and diversity of content makes it difficult for a user to find relevant tracks. Relevant recommendations are therefore crucial for a good user experience. Here we present a method to compute track-track similarities using collaborative filtering signals with side information. On a data set from music streaming service SoundCloud, the method here outperforms the widely adopted implicit matrix factorization technique. The implementation of our method is open sourced and can be applied to related item-item recommendation tasks with side information.
💡 Research Summary
The paper addresses the challenge of providing relevant music recommendations in large‑scale streaming services where the catalog contains tens of millions of tracks spanning diverse genres, podcasts, and other audio content. Traditional content‑based approaches (using raw audio) can only distinguish coarse‑grained genres, while metadata‑based methods suffer from sparsity and noise. Collaborative filtering (CF) is the most widely adopted technique, but it struggles with the cold‑start problem for tracks that receive few user interactions. To overcome these limitations, the authors propose a non‑personalized item‑item similarity model that combines strong positive user signals with side information (e.g., track creator) within a factorization‑machine framework.
User Interaction Modeling
All implicit and explicit actions (plays, shares, likes, playlist additions, etc.) are merged into a single “positive” event if they indicate strong engagement. Single listens and skips are discarded because they are noisy; skips were empirically found to correlate with positive interactions. Users with fewer than five distinct interacted tracks and tracks with fewer than five unique users are filtered out. To keep training tractable, popular tracks are randomly down‑sampled to 10 k interactions.
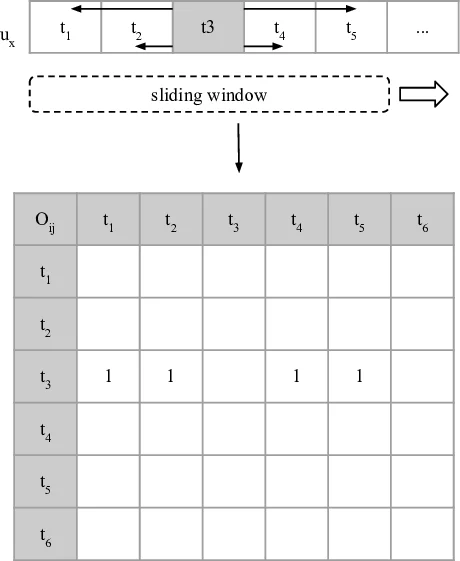
Sliding‑Window Co‑occurrence Construction
Positive interactions are ordered by timestamp for each user. A sliding window of size w = 10 (five items to the left and right of a central track) moves along the sequence, generating ordered track‑track pairs. Each pair increments a co‑occurrence matrix O, where Oᵢⱼ counts how often track i appears in the context of track j. Pairs farther from the center receive lower weight. This yields a dense item‑item matrix O⁺ that is far less sparse than the original user‑item matrix.
Factorization Machine (FM) Model
The authors employ FM to learn latent vectors for tracks, context tracks, and any additional side features. Each training instance is represented by a binary feature vector ~x composed of three parts: (1) one‑hot encoding of the target track, (2) one‑hot encoding of the context track, and (3) one‑hot encodings of side attributes such as track length, age, popularity, creator ID, and audio descriptors (MFCC, spectral contrast, chroma). The prediction function is
ŷ( ~x ) = Σᵢ wᵢ xᵢ + Σᵢ Σⱼ>i ⟨ ~vᵢ, ~vⱼ ⟩ xᵢ xⱼ
where wᵢ are bias terms and ~vᵢ are latent vectors of dimensionality k. This formulation allows arbitrary numbers of feature interactions, unlike classic matrix factorization which only models a single user‑item interaction per example.
Training Objective
A logistic loss is used to push observed positive pairs (y = +1) close together and sampled negative pairs (y = –1) far apart:
L(ŷ, y) = log(1 + exp(–ŷ·y)).
Negative samples are drawn from the entire catalog according to a smoothed track‑co‑occurrence distribution, ensuring that most sampled pairs are truly dissimilar. The overall objective includes L2 regularization on biases and latent vectors and is minimized via stochastic gradient descent with AdaGrad learning‑rate adaptation (a single learning rate is applied to all dimensions for efficiency).
Experimental Setup
The method was evaluated on a proprietary SoundCloud dataset containing ~1.5 billion interactions from ~40 M users and ~1 B tracks. Data were split chronologically: interactions before a cutoff timestamp formed the training set, while later interactions formed the test set (5 M users, 25 M interactions). Tracks present in the training set were removed from the test set to avoid leakage. Three models were compared:
- IMPL – the implicit matrix factorization model of Hu, Koren, and Volinsky (2008).
- ITEM – the proposed FM‑based item‑item model without side information.
- ITEMc – ITEM augmented with the track creator as side information.
All models used 150 latent factors, and hyper‑parameters (α for IMPL, λ regularization) were tuned on a validation split. Evaluation employed Mean Percentile Rank (MPR), computed per track and aggregated across bins defined by the number of training occurrences (e.g., 5–10, 10–20, …, >150 k). Lower MPR indicates that true co‑occurring tracks are ranked higher.
Results
Across all bins, ITEM outperformed IMPL, achieving substantially lower MPR values. Adding creator information (ITEMc) yielded further gains, especially in the long‑tail bins where tracks have few interactions. For tracks appearing only five times in the training data, ITEMc achieved an MPR close to 0.5, meaning the model ranks true co‑occurring tracks far better than random guessing. The improvements demonstrate that (a) the sliding‑window co‑occurrence matrix provides a richer signal than the sparse user‑item matrix, and (b) side information, even if noisy, helps disambiguate sparse items.
Conclusions and Implications
The study shows that a non‑personalized item‑item similarity model built on a dense co‑occurrence matrix and trained with factorization machines can surpass traditional implicit matrix factorization, particularly for rare items. Side information such as creator IDs further boosts performance in the long tail. Because the model produces item embeddings, it can be easily turned into personalized recommendations by matching a user’s previously listened tracks to their nearest neighbors, enabling explainable suggestions (“Because you liked X, you may also like Y”). The authors have open‑sourced their implementation, facilitating adoption in other domains (e.g., movies, news articles) where item‑item recommendation with side information is needed.
Comments & Academic Discussion
Loading comments...
Leave a Comment