Towards Deep Modeling of Music Semantics using EEG Regularizers
Modeling of music audio semantics has been previously tackled through learning of mappings from audio data to high-level tags or latent unsupervised spaces. The resulting semantic spaces are theoretically limited, either because the chosen high-level tags do not cover all of music semantics or because audio data itself is not enough to determine music semantics. In this paper, we propose a generic framework for semantics modeling that focuses on the perception of the listener, through EEG data, in addition to audio data. We implement this framework using a novel end-to-end 2-view Neural Network (NN) architecture and a Deep Canonical Correlation Analysis (DCCA) loss function that forces the semantic embedding spaces of both views to be maximally correlated. We also detail how the EEG dataset was collected and use it to train our proposed model. We evaluate the learned semantic space in a transfer learning context, by using it as an audio feature extractor in an independent dataset and proxy task: music audio-lyrics cross-modal retrieval. We show that our embedding model outperforms Spotify features and performs comparably to a state-of-the-art embedding model that was trained on 700 times more data. We further discuss improvements to the model that are likely to improve its performance.
💡 Research Summary
The paper introduces a novel framework for learning music semantic embeddings that explicitly incorporates listeners’ brain activity, captured via electroencephalography (EEG), alongside the audio signal. Traditional music‑semantic models rely on external annotations such as tags, artist labels, or emotion dimensions, which are either coarse, costly to obtain, or insufficient to capture the full subjective experience of music. By using EEG as a regularizer during training, the authors aim to model semantics directly from the neural correlates of perception, thereby bypassing the “tyranny of words” and the need for exhaustive labeling.
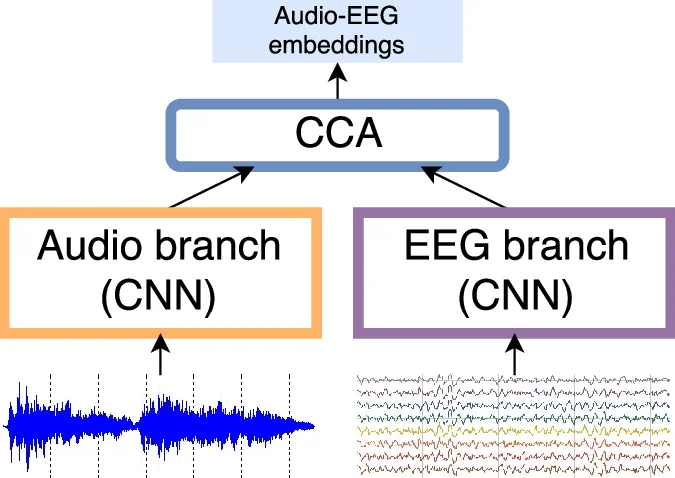
The technical core consists of a two‑view deep neural network (NN) architecture: one branch processes 1.5‑second audio chunks sampled at 22 050 Hz, the other processes 16‑channel EEG recordings sampled at 250 Hz. Both branches employ stacks of 1‑D convolutional layers with ReLU activations, batch normalization, and max‑pooling, culminating in 128‑dimensional latent vectors. To align the two modalities, the authors adopt Deep Canonical Correlation Analysis (DCCA) as the loss function. DCCA extends classical CCA by learning nonlinear mappings (the two NN branches) and then maximizing the linear correlation of the projected features. The loss is implemented by back‑propagating through the eigen‑decomposition of regularized covariance matrices, ensuring that the learned embeddings from audio and EEG are maximally correlated. After training, a linear CCA is fitted on the learned representations to obtain the final semantic space.
For data collection, 18 participants each listened to 60 music excerpts (average length ≈15 s) and two baseline segments (noise and silence) in a randomized order, followed by two self‑selected full songs (one liked, one disliked but from the same album). EEG was recorded using an OpenBCI 32‑bit board with the Daisy module, providing 16 channels placed according to the extended 10‑20 system (frontal, central, parietal regions). Pre‑processing involved a >0.5 Hz high‑pass filter, a 50 Hz notch filter, wavelet‑based artifact removal (WAR), and Wavelet Semblance Denoising (WSD). Because electrode‑scalp contact varies across subjects and trials, each channel‑stimulus pair was individually scaled to the range
Comments & Academic Discussion
Loading comments...
Leave a Comment