New Fairness Metrics for Recommendation that Embrace Differences
We study fairness in collaborative-filtering recommender systems, which are sensitive to discrimination that exists in historical data. Biased data can lead collaborative filtering methods to make unfair predictions against minority groups of users. We identify the insufficiency of existing fairness metrics and propose four new metrics that address different forms of unfairness. These fairness metrics can be optimized by adding fairness terms to the learning objective. Experiments on synthetic and real data show that our new metrics can better measure fairness than the baseline, and that the fairness objectives effectively help reduce unfairness.
💡 Research Summary
The paper addresses fairness concerns in collaborative‑filtering recommender systems, arguing that conventional fairness metrics—most notably demographic parity—are insufficient because they assume user preferences are independent of sensitive attributes such as gender or race. In many real‑world domains, however, these attributes strongly influence preferences, leading to systematic bias when historical data are used uncritically.
To capture a broader spectrum of unfairness, the authors propose four novel metrics:
-
Value Unfairness measures the signed difference between average predicted scores and true ratings for disadvantaged versus advantaged groups. A consistent sign difference indicates that one group is systematically over‑ or under‑estimated.
-
Absolute Unfairness takes the absolute value of the same difference, focusing on the magnitude of error regardless of direction, thus reflecting overall prediction quality disparity between groups.
-
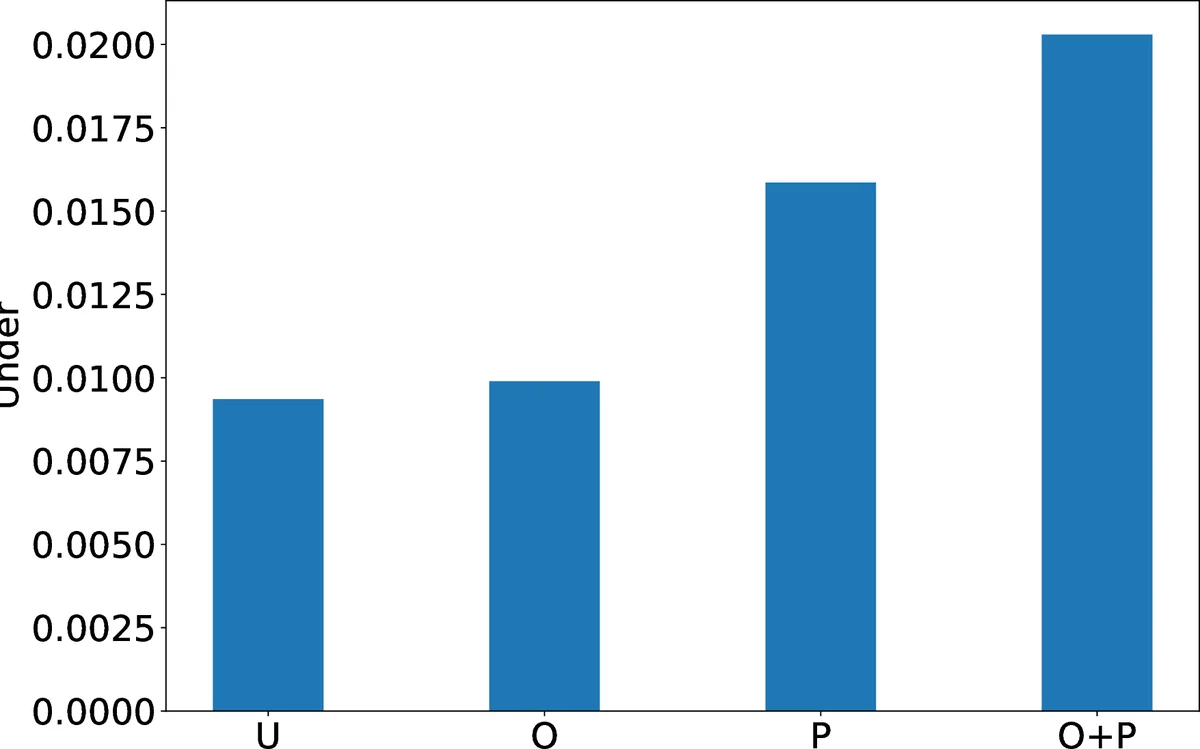
Underestimation Unfairness applies a hinge function to capture only cases where predictions fall short of true preferences. This is crucial in settings where missing recommendations (e.g., STEM courses for women) have higher stakes than extra recommendations.
-
Overestimation Unfairness mirrors the previous metric but for cases where predictions exceed true preferences, helping to avoid recommending items that users are unlikely to enjoy.
The authors also reinterpret the previously used “non‑parity” measure as a regularization term that penalizes the absolute difference between overall average ratings of the two groups.
All metrics are incorporated into the matrix‑factorization objective as additional penalty terms:
\
Comments & Academic Discussion
Loading comments...
Leave a Comment