Exploring compression techniques for ROOT IO
ROOT provides an flexible format used throughout the HEP community. The number of use cases - from an archival data format to end-stage analysis - has required a number of tradeoffs to be exposed to the user. For example, a high “compression level” in the traditional DEFLATE algorithm will result in a smaller file (saving disk space) at the cost of slower decompression (costing CPU time when read). At the scale of the LHC experiment, poor design choices can result in terabytes of wasted space or wasted CPU time. We explore and attempt to quantify some of these tradeoffs. Specifically, we explore: the use of alternate compressing algorithms to optimize for read performance; an alternate method of compressing individual events to allow efficient random access; and a new approach to whole-file compression. Quantitative results are given, as well as guidance on how to make compression decisions for different use cases.
💡 Research Summary
The paper investigates compression strategies for ROOT I/O, the de‑facto data format used throughout high‑energy physics (HEP). ROOT stores event data in TTrees, which are split into branches (TBranch) and further into baskets (TBasket). By default each basket is compressed as a whole using ZLIB’s DEFLATE algorithm. The authors evaluate three dimensions of compression: (1) alternative compression libraries, (2) a fine‑grained “Random Access Compression” (RAC) that compresses each event individually, and (3) external, file‑system‑level compression using SquashFS.
1. Comparison of compression libraries
The study uses a 6.4 GB CMS file containing 6 500 events and runs on a 4‑core virtual machine. Three libraries are tested: ZLIB (levels 1‑9), LZMA (levels 1‑9), and LZ4/LZ4HC (high‑compression mode). Results (Table 1) show clear trade‑offs. LZMA‑9 achieves the highest compression ratio (5.29×) but requires ~5 000 s to compress and ~212 s to decompress, making it unsuitable for frequent read/write cycles. ZLIB‑1 compresses quickly (86 s) but yields a modest ratio (1.79×) and a relatively long decompression time (21 s). LZ4HC‑5 provides a ratio comparable to ZLIB‑1 (1.75×) while cutting decompression time to 2.8 s (≈13 % of ZLIB‑1). LZ4 (no‑HC) is the fastest to compress (11 s) and decompress (2.97 s) but its ratio (2.17×) is lower than ZLIB‑5. The authors conclude that for workloads where CPU time dominates (e.g., interactive analysis), LZ4HC‑5 or ZLIB‑1 are preferable, whereas archival storage may justify LZMA‑9 despite its cost.
2. Random Access Compression (RAC)
Standard ROOT compresses an entire basket (≈64 KB) at once, which forces a full basket decompression even when only a single event is needed. RAC modifies this by compressing each event separately and storing an offset table inside the basket. Three synthetic event types are used: TFloat (39 B), TSmall (4 KB), and TLarge (4 MB). Compression ratios drop dramatically for tiny events (TFloat: 5.09 → 1.77) because inter‑event redundancy is lost and per‑event metadata adds overhead. For TSmall the ratio declines only slightly; for TLarge it is unchanged because each basket already holds a single event.
Read‑performance tests distinguish “cold cache” (disk reads) and “hot cache” (memory reads). In cold‑cache random reads, RAC reduces CPU time for TFloat and TSmall to ~21 % of ZLIB’s cost, since only the needed fragment is decompressed. For TLarge, RAC is slower because of the extra offset handling. Sequential reads show a modest gain for TSmall (overall real time drops from 12.07 s to 11.99 s) and a large reduction in CPU time (4.88 s vs. 11.34 s), indicating the bottleneck shifts from CPU‑bound to I/O‑bound. The authors note that RAC is most beneficial when events are small and random access is frequent; otherwise the overhead may outweigh the gains.
3. External compression with SquashFS
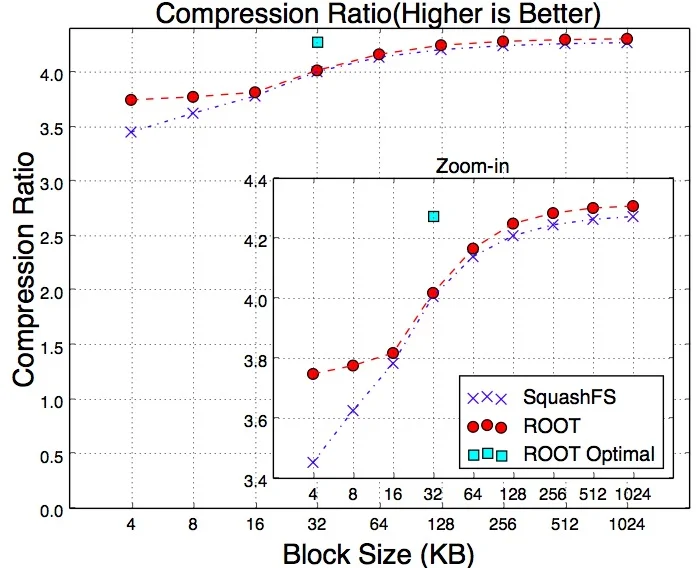
The authors also evaluate compressing a ROOT file outside the framework using SquashFS, which stores the file as a compressed read‑only filesystem. They vary the SquashFS block size from 4 KB to 1 MB. Compression ratios improve with larger blocks; for block sizes ≤16 KB ROOT’s native compression is superior, while for larger blocks the two approaches converge.
Three read workloads are examined: (a) full sequential read, (b) reading every 10 % of events, and (c) reading every 1 % of events. In cold‑cache scenarios SquashFS must sometimes load multiple blocks to retrieve a single event that straddles a block boundary, leading to higher I/O overhead compared with ROOT, which knows the exact basket layout. In hot‑cache scenarios, SquashFS decompresses in kernel space, so block size has little impact on read time, whereas ROOT’s user‑space decompression time grows with larger baskets.
Conclusions and recommendations
The paper demonstrates that no single compression scheme dominates across all use cases. High‑ratio algorithms (LZMA) are appropriate for long‑term archival where write‑once‑read‑rarely is acceptable. For analysis pipelines where CPU time is at a premium, LZ4HC (especially level 5) or low‑level ZLIB (level 1) provide a good balance. RAC can dramatically accelerate random reads of small events but incurs a penalty in compression ratio and for large events. External compression via SquashFS offers a transparent alternative without substantial loss of compression efficiency, though it does not outperform ROOT for random‑access workloads.
Future work includes integrating newer, possibly hardware‑accelerated compressors into ROOT, refining RAC to reduce metadata overhead, and exploring hybrid schemes that combine ROOT’s basket awareness with external filesystem features. Users are encouraged to profile their specific workloads and select the compressor and configuration that best matches their storage, CPU, and access‑pattern constraints.
Comments & Academic Discussion
Loading comments...
Leave a Comment