Speaker identification from the sound of the human breath
This paper examines the speaker identification potential of breath sounds in continuous speech. Speech is largely produced during exhalation. In order to replenish air in the lungs, speakers must periodically inhale. When inhalation occurs in the mid…
Authors: Wenbo Zhao, Yang Gao, Rita Singh
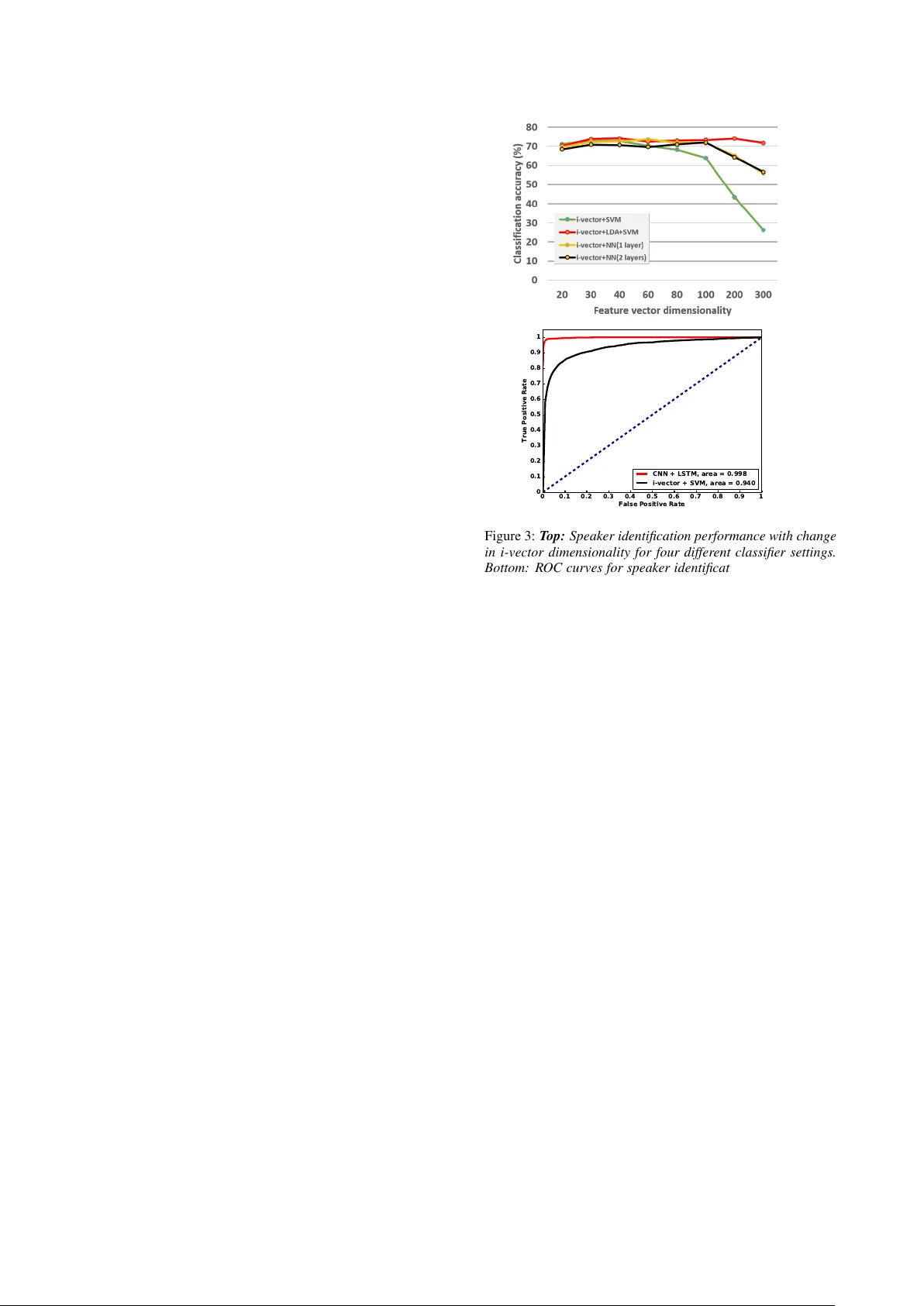
Speaker identification fr om the sound of the human br eath W enbo Zhao, Y ang Gao, Rita Singh Carnegie Mellon Uni v ersity , Pittsb ur gh, USA { wzhao1,yanggao,rsingh } @cs.cmu.edu Abstract This paper examines the speaker identification potential of breath sounds in continuous speech. Speech is largely pro- duced during exhalation. In order to replenish air in the lungs, speakers must periodically inhale. When inhalation occurs in the midst of continuous speech, it is generally through the mouth. Intra-speech breathing behavior has been the subject of much study , including the patterns, cadence, and v ariations in energy levels. Howe ver , an often ignored characteristic is the sound produced during the inhalation phase of this cycle. Intra-speech inhalation is rapid and ener getic, performed with open mouth and glottis, effecti vely exposing the entire vocal tract to enable maximum intake of air . This results in vocal tract resonances ev oked by turbulence that are characteristic of the speaker’ s speech-producing apparatus. Consequently , the sounds of inhalation are expected to carry information about the speaker’ s identity . Moreover , unlike other spoken sounds which are subject to acti ve control, inhalation sounds are gen- erally more natural and less affected by voluntary influences. The goal of this paper is to demonstrate that breath sounds are indeed bio-signatures that can be used to identify speakers. W e show that these sounds by themselves can yield remarkably ac- curate speaker recognition with appropriate feature representa- tions and classification framew orks. Index T erms : V oice biometrics, human breath, speaker identi- fication, constant-Q spectra, con volutional neural networks 1. Introduction Intervocalic breath sounds are fundamentally different from re- laxed breath sounds that occur outside of speech. This is be- cause breath plays an important role in controlling the dynam- ics of speech. Natural speech is produced as a person exhales. It is almost impossible to pr oduce sustained speech during in- halation [1]. As a person speaks, a specific volume of air is pushed out through the lungs and trachea into the vocal cham- bers, gated through the vocal folds in the glottis. Intervocalic breath sounds happen when the speaker e xhausts the volume of air pre viously inhaled during continuous speech, and needs to inhale again. This inhalation is generally sharp and rapid, and volumetrically anticipatory of the next burst of speech. The v ol- ume of air inhaled also depends on the air-intake capacity of the speaker’ s nasal and oral passageways, trachea and inner struc- tures leading to the lungs, and further varies with myriads of other factors that relate to the speaker’ s lung capacity , energy lev els, muscular agility , etc. Since exhalation is volumetrically linked to inhalation, by association the quality of the speech produced during exhalation also varies with all of these f actors. Furthermore, when a person inhales, the v ocal tract is usually lax, and is in its natural shape. The lips are not protruded, nor do the articulators obstruct the vocal tract in any way . In lax con- figurations, dif ferences between speakers are expected to show up prominently as differences in resonant frequencies (due to differences in facial skeletal proportions and dimensions of the vocal chambers), differences in relati ve sound intensities (due to different lung capacities and dif ferent states of health), etc. For all these reasons, we e xpect that man y parameters of the speaker’ s persona have their effects, and possibly measurable signatures, embedded in intervocalic breath sounds. Our goal in this paper is to experimentally show that these person-specific signatures within human breath (inhalation) sounds can indeed be used for speaker identification. This can be useful in many real-life scenarios, especially those of forensic importance. For example, we hav e sho wn in an earlier study [2], that breath is in v ariant under disguise and impersonation. Its resonance patterns are normally not under voluntary control of the speaker , and in general are extremely difficult to modify in a consistent manner for mechanical or cognitiv e reasons. Fig. 1 shows the spectrograms of the breath sounds of a child and four adult speakers, three of who were attempting to impersonate the fourth speaker . This example is in fact extracted from the public performances of voice artists who were attempting to impersonate the US presidential candi- date in the 2016 elections in USA – Mr . Donald T rump. W e see the qualitative differences in the breath sounds and durations clearly in these examples. Even though in reality the imper- sonators of Mr . Trump sound very similar, their breath sounds show v ery distinctiv e speaker-specific patterns. (a) (b) Figure 1: (a) Spectro gram of breath sounds of a 4-year old child during continuous speech. The formants F1, F2 and F3 corr e- spond to the r esonance of br eath sounds, and ar e clearly visi- ble. (b) Breath sounds of Mr . Donald T rump (label 3), and of his impersonators (Labels 1, 2 and 4). All signals wer e energy- normalized and ar e displayed on exactly the same scale. 1.1. Prior work Speaker identification from speech signals is a widely applied and well researched area, with decades of work supporting it. T echnology from this area has been the mainstay of forensic analysis of voice as well, an area that has been largely centered around the topics of speaker identification [3, 4, 5, 6], verifica- tion [7, 8], detection of media tampering, enhancement of spo- ken content, and profiling [9, 10]. All of these areas have used articulometric considerations to advantage. Ho wever , there are no reported studies that use or suggest the use of breath sounds strongly in any of these forensic contexts. The closest appli- cation – and one that takes a stretch of imagination to relate to forensics – in fact comes from the medical field, where the sound of the patient’ s breath is sometimes used very subjec- tiv ely by the clinician to deduce the patient’ s medical condition (such as lung function, respiratory diseases, response to their treatment, etc.) [11, 12, 13]. The rest of this paper is organized as follo ws. In Section 2 we present a very brief revie w of two feature formulations that we deri ve from breath sounds for our experiments. In section 3, we describe a problem formulation and solution framework for speaker identification based on conv olutional neural networks (CNN) with Long-Short T erm Memory (LSTM). In section 4, we present our experiments, and in Section 5 we present our conclusions. 2. Brief re view of feature f ormulations Breath is a turbulent sound. Since the spectral distributions of turbulent sounds are well represented by Gaussians, we hypoth- esize that the standard speaker identification techniques based on supervectors and i-v ectors [14] would work with breath sounds as well. In this section we describe two feature formulations that we selected for representing breath sounds. The two formulations we chose are i-vectors, the currently accepted best features used in commercially deployed state-of-art speaker identification and verification systems [14], and a set of novel CNN-RNN based features deri ved from constant-Q representations of the speech signal. W e describe these briefly in the subsections belo w . 2.1. I-V ectors as features f or breath sounds Identity-vector (i-v ector) based feature representations are ubiq- uitously used in state-of-art speaker identification and verifica- tions systems. In order to obtain i-vectors for any speech recording, the distribution of Mel-frequenc y Cepstral Coefficient (MFCC) vectors derived from it is modeled as a Gaussian mixture. The parameters of this Gaussian mixture models (GMM) are in turn obtained through maximum a posteriori adaptation of a Uni- versal Backgr ound Model that represents the distribution of all speech [15, 16]. The mean vectors of the Gaussian in the adapted GMM are concatenated into an e xtended v ector , kno wn as a GMM Supervector , which represents the distribution of the MFCC vectors in the recording [17]. I-vectors are obtained through factor analysis of GMM su- pervectors. Follo wing the factor analysis model, each GMM supervector M is modeled as M = m + Tw M , where m is a global mean, T is a triangular loading matrix comprising bases representing a total variability space , and w M is the i-vector corresponding to M . The loading matrix T and mean m are learned from training data through the Expectation Maximiza- tion (EM) algorithm [18]. Subsequently , giv en any recording M , its i-vector can also be deri ved using EM. 2.2. Constant-Q spectr ographic features For our purposes, a constant-Q spectrogram of a speech signal may be derived by computing the constant-Q spectra of consec- utiv e frames of the signal, which are then displayed in temporal succession on the spectrogram. As in general spectrographic representation used for speech signals, the frames span dura- tions of 20 ∼ 30 ms and overlap by 50%-75%. For each frame s [ t ] , we compute its constant-Q transform x cq t [19]. In the case of digital recordings, specifically , the constant-Q transform of each frame s [ t ] of the signal is giv en by x cq [ k ] = 1 N k X n
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment