Stream Attention for far-field multi-microphone ASR
A stream attention framework has been applied to the posterior probabilities of the deep neural network (DNN) to improve the far-field automatic speech recognition (ASR) performance in the multi-microphone configuration. The stream attention scheme h…
Authors: Xiaofei Wang, Yonghong Yan, Hynek Hermansky
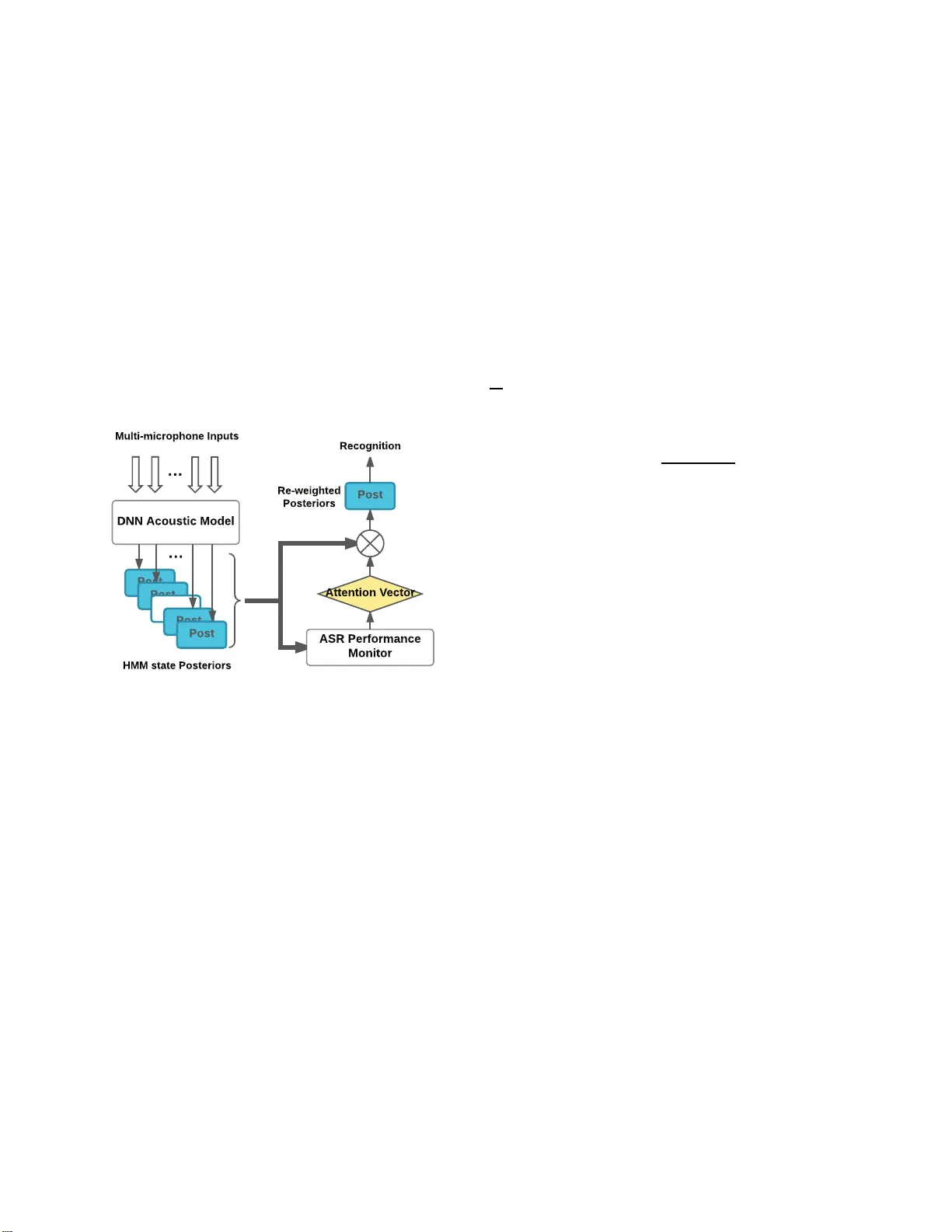
STREAM A TTENTION FOR F AR-FIELD MUL TI-MICR OPHONE ASR Xiaofei W ang † ,⋆ Y onghong Y an ⋆ and Hynek Hermansky † † Center for Language and S peech Processing, Johns Hopkins Unive rsit y 3400 North Charles Street, B altim ore, MD 21218, US A ⋆ Institute of Acoustics, Chinese Ac ademy of Sciences No.21 North 4th Ring W est Road, Beijing 10 0190, China ABSTRA CT A stream atten tion framework has been applied to the p oste- rior probab ilities of the deep neural network (DNN) to im- prove th e far -field auto matic sp eech recognition (ASR) per- forman ce in the m ulti-microp hone configuratio n . The stream attention scheme has been re a lize d throug h an attention vec- tor , which is derived by predictin g th e ASR perf ormance from the ph oneme posterio r distribution of in dividual microphone stream, focusing the reco gnizer’ s attentio n to mo re reliable microph ones. Investi g a tio n on the various ASR p erforma nce measures has been carried out using the real recorded dataset. Experime nts results sh ow that th e pro p osed f ramew or k has yielded sub stantial improvemen ts in word error rate (WER). Index T erms — Far -field m ulti-microp hone ASR, ASR perfor mance measure, Stream attention 1. INTRODUCTION In far-field ASR scen ario, it is feasible to use many parallel recogn itio n streams. A situa tio n need s to b e so lved wh ere a number of micro phone s, which fo r m acou stic stream s, are distributed in space to acquire spee ch to be rec ognized. De- pending on the roo m situation an d micro phone status, some streams (microphone s closer to the speaker , less noise and reverberation) ma y deliver better recogn itio n results than the others. Automatically selecting the be st m ic r ophon e for ASR, and furth er ach ieving a potential better ASR per - forman ce th rough combining th e m icropho nes is desirable. Con vention al solutions such as selecting the acoustic stream with the highest energy are vulnerable to strong noises. There are several ways to enhan ce the ASR per formanc e utilizing the mu lti-microph one co nfiguration . One possible strategy is to align the time delay between the m icropho nes and use spatial inf ormation to carry out b eamform in g [1][2]. Howe ver , in the distributed setup, time de la y s are difficult to estimate. Further, as a fron t- end pro cessing modu le, the ob - jectiv e fun ctions are no t optimal for ASR [3 ]. An o ther way This work is supported by the National Natural Scienc e Founda- tion of China (No. 61601453) and the China Scholarship Council (No. 2016049100 07) of ap proachin g this problem is to find th e highest likeliho o d combinatio n o f best path s thr ough multiple r ecognition lat- tices, formed from all in dividual streams [4][5]. T his requires carrying ou t full searches in each micropho ne stream , which is typically done over the whole len gth of e a c h utterance . And the computing comp lexity of the multiple decoding opera- tions is the bottlene c k. Most ASR sy stems require fe ature vectors, which repre- sent inform ation about underlyin g speech sound at regular time interv als. Such feature vectors c an be derived from pos- terior p robabilities o f the sounds, estima te d by DNN classi- fiers. DNN posterior s are able to tolerate the misalignment between the classifier inputs and corre sp onding labels [6]. W e propo se to construct at ev ery time instant the best feature vec- tor from a com b ination of the most r eliable sound p osteriors from different available streams, wh ich is a stream attention scheme. I n this way , only on e deco ding op eration for ASR is needed, which is more ef fective tha n mu ltip le oper ations. Attention schem e c an be ac hiev ed by gen e rating an atten- tion vector for multiple inputs [7][8], among which the a t- tention vector plays an impor tant ro le in addressing the cr u- cial p art of the inputs based on specific attention criter ion. Giv en the feature vectors ( DNN posteriors), the ke y prob lem of stream attention that to deal with is to fin d an ap propr ia te measure of the goodn ess of f eature vecto r s in the individual streams. This goo dness measure could th en be used in de- riving p r oper attention vector for the construction of the best feature vector . In th is study , we propo se a strea m attention frame work to deal with the far-field multi-microph one ASR proble m , in which th e sounds f rom m ic r ophon es ar e no t forced aligned. For b e tter und e rstanding th e framework, we inv estigate sev- eral mea su res th at built the relationship b etween the good - ness o f DNN posterior vectors and the ASR per formanc e [9][10][11][12][13][14], and test the framew or k using v ari- ous attention vectors on a real recorded dataset. Specifically , attention vectors are estimated based on the discriminative judgmen t a mong the microphon e streams. The r emainder of this p a per is organized as follows: Section 2 describes the proposed stream attention frame- work of the m u lti-microph one system. In section 3, different ASR perfor mance measures are comp ared in far-field m ulti- microph one ASR experiments using re a l recording s. Section 4 co n cludes the paper . 2. PROPOSED FRAMEW ORK In this section, we d escribe the stream atten tion framework applied on the po sterior p robabilities of Hid d en Markov Model (HMM) state to fo rce the r ecognizer auto matically fo- cusing on the reliable micr ophon es in th e multi-micro phone configur ation. A b rief diagra m in Fig.1 demon strates th e attention schem e and attentio n vector estimation using the multiple posteriors, with each cor r esponding to the Softm a x output o f a typical DNN-HMM class ifier . Fig. 1 . Stream attention framew or k for ASR using the p oste- rior pro babilities form D NN classifier . 2.1. Formulation of the S tream Attentio n Scheme As suggested in Fig.1, let P t = [ P 1 t , P 2 t , ..., P M t ] T de- note the po sterior p robability sequences of HMM states O at time t , where T is the transpo se o peration and P i t = p ( O | X i t ) , i = 1 , ..., M is the i th p osterior prob a bility se- quence giv en the feature sequence X i t extracted fr om the signal of micr ophon e i . M is th e total stream number, wh ich is eq ual to the number of micro phones (or ar rays). Specif- ically , X i t = [ X i t − τ , ..., X i t , ..., X i t + τ ] T is context based , including 2 τ + 1 adjacent frames ce n tered at time t . Assuming that we have the stream attention vector w t = [ w 1 t , w 2 t , ..., w M t ] T , which is a M- element vector with summ a- tion equal to 1 at time t , w e are able to achiev e the re-weigh ted posterior pro b ability sequen ce ˆ P t as f ollows, ˆ P t = w t P t (1) After the re-weighted comb ination, ˆ P t is u sed for decod ing. 2.2. Attention V ector Estimation The attention vector can be estimated v ia ev aluating the rel- ativ e ASR perf o rmance betwe e n the microph one stream s in unsuper v ised ways. Specifically , ASR per f ormance measures are integrate d to realize this purpose, stated as follows. 2.2.1. Based on ana lysis of phoneme posterior gram Researchers propo sed to distingu ish ASR perf ormance th rough observing the relation ship between recognitio n accuracy and representatio n o f phoneme posteriorgra m . Posterior distri- bution at a particular time point would con verge to non- informa tive, as the signals were increasin g ly corru pted by noise or reverberation. Therefo r e, in verse entropy 1 /H i of P i t is a measure to determine the p erforma nce o f micro phone stream i [9][1 0], so that the attention vector of each fr ame is giv en by w i t = 1 /H i P M i =1 1 /H i (2) By conside r ing the temporal prop erties of phon eme pos- terior probab ility , mean tim e distance (M-measure) [11] and delta M-measure [13] accumulate the divergences of pro ba- bility estimates spaced over several time-span s. M-measu r e accumulates ho w similar or different every two probability vectors P i t − ∆ t and P i t are, by calcu lating their sym metric Kullback-Leibler divergence (KLD) D ( P i t − ∆ t , P i t ) . If the speech were corrupted b y stationary or slowly varying dis- tortions, these distortions start dom inating the signal and the phon eme posterior s becom e m o re similar , r esulting in a lower average value of M-measure. Delta M-measure f urther takes phon eme dep endence into account. B oth M-measure and delta M-measur e rely o n lon g-term windows over h un- dreds of milliseco nds. Stream with better ASR perfo rmance would hav e a larger value than the other streams in th is win - dow . Thus, a time-in variant attention vector h aving bin ary elements across the window is derived, wh ich is given by w i t == 1 , if M i (∆ t ) > M j (∆ t ) , wh ere i 6 = j , t belongs to all th e fram e time in the wind ow . 2.2.2. Based on unsup ervised learning It’ s well-known that multi-layer neural network is g ood at modeling the complex data distributions. In th e unsu pervised learning appr oach, we use the auto encoder as an ASR per- forman ce m onitor to m odel the ou tput acti vations of DNN acoustic m odel [14]. In the train ing phase, an au toencode r is train ed on the phone m e p osterior sequences with Lo git (to make the fea tures more Gau ssian) and principal comp onent analysis (PCA) transform ation (tr ansformatio n basis o f PCA is ev alua ted from the training d ata). The data for tr aining the autoencod er is the same as that fo r training the DNN classifier . Mean square err o r (MSE) criterion is u sed . In th e test ph ase, the re construction error o f test d ata is used as a m easure of stream confiden c e , which means that a vector similar to the distribution of training data will y ield a low recon struction error co mpared to vectors dr awn from a dif feren t d istribution. The lo wer the reconstruction error is, the better test an d training da ta are matched , resulting in a bet- ter re c o gnition a c curacy . Different from M-measure and delta M-measure, autoenco der b ased ASR performan c e monitor is a frame-wise techn ique. The elemen t of attention vector w i n is g iven as follows, w i t = 1 / || e i || 2 P M i =1 1 / || e i || 2 (3) where || e n || is the l 2 norm o f reco n struction error v ector s. The tempo ral transition of phonemes is a speech-sp e cific proper ty , which is widely applied to the spe ech-related tech- niques. In this study , we use context-b a sed p honeme posterior features centered by the c u rrent frame as the inp ut, and cur- rent frame at time t as the trainin g target. T o further relaxing the strict alignm ent of inpu t features and correspon ding tar- gets and significantly r e ducing the input size [15], we exploit the TDNN structure with splices in the hidden lay ers to train the au to encoder . 3. EXPERIMENT AND DISCUSSION 3.1. Dataset and Baseline The propo sed framework was e valuated o n a subset of M ixer- 6 dataset [1 6]. During the recording, US English speakers were required to read fr om a list of sentence s. In details, the recordin gs were conducted on -site a t LDC in tw o distinct of- fice rooms (de n oted by ”LDC” and ”HRM” room) e quipped with multi-c h annel recordin g platfo rms. Each ro om was set up with a matching set o f 13 distinct micr ophon es, placed at equiv alent lo cations rela tive to th e spe a ker . T h erefore, this distributed setup mee ts our needs. The tra nscribed dataset was separated into training part and testing part for ASR experiments. For each utterance, we had synchro nous ( not time-aligned due to the pro pagation of the sound wave) 13 rec ordings simu ltan eously . W e used the recordin gs fro m micro phone 2 (head-mo unted micr ophon e , best acou stic chann el) as the training data, an d the r emain- ders for testing. T raining data was 24 6.5 hou rs fro m mor e than 1350 speakers. And the test data consisted of two pa r ts, one having 1 031 utteranc e s from 4 distincti ve speakers in the ”LDC” room and the o th er one having 898 utterances fr o m another 4 speakers in th e ”HRM” room, respectively . W e tested all the 13 microphon e streams on the ty p i- cal DNN-HMM system train ed o n MFCC featur es, with 11 frames stacking (+5-5) . T o examine the imp rovement of the proposed sch e me ap plied on the a coustic posterior s, the languag e model used for decoding was weak but equally for all the recog nition experiments below . T able 1 shows the ba selin e WER fo r each m icropho ne stream. Except fo r microph one 2, whose acoustic scene was matched with the training, we der i ved two test sets fo r the stream attention task. For the ”LDC” set, we had twelve stream s working in normal status. For the ”HRM” set, ten streams worked well for A SR, howe ver , the other two f ailed (Mic 3& 11). This ph enomeno n happen s q u ite often in the real en viro nments, as microph ones might be o ut of ch a rge sudden ly or affected b y strong noise and reverberation. The system sho u ld be robust in case o f such m icropho n e failures. T able 1 . WERs(%) of m icropho ne streams (Mic X) on the two test sets. Recognizer was train e d using th e reco r dings from Mic 2 (Mic 2 was no t used for testing). Stream Index LDC room HRM room Mic 1 23.8 27.0 Mic 2(M atched) 10.2 10.8 Mic 3 26.7 97.6 Mic 4 10.9 8.2 Mic 5 12.9 12.9 Mic 6 10.1 8.7 Mic 7 15.1 15.3 Mic 8 14.0 12.6 Mic 9 22.7 18.3 Mic 10 11.3 13.4 Mic 11 10.6 75.9 Mic 12 14.6 12.7 Mic 13 19.9 21.9 3.2. Description of the compara tive methods W e compar ed the WER results between the p roposed stream attention schem e using M-measur e and delta M-measure [11][13] and the c o mbination of lattices, generated by differ- ent stream s by doing a union of the lattices [4]. Both of them were p r ocessed sentence- by-sentenc e . W e also to ok e qual weig hts [17], in verse entr o py [10] and autoencoder (AE ) [1 4] for perform ance compar iso n since they were based o n the frame-wise re-weighting of the HMM state po steriors in the prop osed stream attention fr amew ork . What’ s more, as f o r the autoenco der h ierarchy , we in vesti- gated th e effect of using different tempo ral context sizes on WER. Th e autoenco der was train ed with 6 layers ( a 24-u nit bottleneck layer in the middle), an d each layer co n sisted of 512 Relu units. Th e temporal context was introdu ced via a TDNN architectur e with different tem poral resolution at each layer . 3.3. Results T able.2 shows the WER results usin g various compar ati ve technique s. As shown in Group A, we p ick ou t the matched case (Mic 2) and best micr ophon e (oracle) a s the baselin e s T able 2 . WERs(%) co mparison of v ario us micro- phone stream r e-weighting method s on the Mixer-6 multi- microph one dataset. Group System&Method LDC HRM A Matched (Mic 2) 10.1 10.8 Best micr ophon e (Orac le) 10.1 8.2 Lattice com bination 11.7 19.3 B M-measure 10.3 9.1 Delta M-m e a sure 10.2 8.8 C Equal weigh ts 9.8 30.5 In verse entr opy re-weight 7.8 7.9 AE re- w e ight w/o co ntext 8.7 7.1 D AE re- w e ight w context [-8, 5] 8.5 7.1 AE re- w e ight w context [-13,10] 8.4 7.1 AE re- w e ight w context [-16,12] 8.2 6.9 AE re- w e ight w context [-20,14] 8.6 6.9 E In verse entr opy Max 17.6 19.4 AE Max w con text [-16,12 ] 20.8 18.2 based on T able 1. W e can see th at lattice comb ination p er- forms worse than the baselines, especially on the ”HRM” test set. Using the sentence-by-senten ce strategy , o u r schem e carried ou t o n the DNN po steriors show the supe r ior perfo r- mance to lattice lev el p rocessing, wh ic h is delivered by Group ”B”. M-measure is able to make the system pay mo re atten- tion to the best stream at the sentence level, b ut also can no t outperf orm th e b est microphone stream. Delta M-measure slightly imp roves the selection accu racy . In some a p plica- tions, the acoustic si tua tio n may change dy namically and so- lutions, which require such lon ger signal spans f o r making th e stream selection , may not be ap propria te. Group ”C” g ives the r esults of fra m e-wise re-weigh ting using different kinds o f attention vector s. When apply ing equal weights to the twelve microph one stre ams, a better WER (9 .77%) is ach iev ed o n the ”LDC” test set, which is superior to the best indi vidu al m icropho n e. Howe ver , per- forman ce on ”HRM” test set with two o f the streams in bad condition gets m uch worse (30 . 45%). In con trast, inverse entropy achieves a substantial improvement compared to the best microph one, showi n g a 22 .8% an d 3. 7 % r elati ve im- provement for ”LDC” and ”HRM” set in WER, resp e cti vely . But th e WER impr ovement o f ”HRM” set is n o t as much as that of ”LDC” set. This phen omenon does no t o ccur when the autoen coder based attentio n vector was applied . W e find that the im provements are consistent in both test sets. Fur- thermor e , a trend can be observed by enlarging the con text window , indicated by Group ”D”. Th e g ain increases as we used m o re TDNN network context until [-16,1 2] (r elativ e improvements f or ”LD C” set and ”HRM” set are 1 8.8% and 15.9%, r e spectiv ely) then the WER goes up wh en we apply a larger context [-20, 14] on the ”LDC” set. While results on th e ”HRM” set seem stab le where only a little improvement has 0 2 4 6 8 10 12 Number of microphones for re-weighting 5 10 15 20 25 WER% LDC test set HRM test set Fig. 2 . WERs(%) with r e sp ect to the num ber of microp hone streams for the re-we ig hting scheme. Attention vector is cal- culated using the ”AE re-weight with context [-16,12] ”. been achiev ed u sing more co ntext info rmation. According to the results, the entropy b ased system yields the best result on the ”LDC” set, which does not include extremely corrup ted microph one streams. The two extrem e ly corrup ted streams in the ”H RM” set appear to b e better d ealt with using the autoenco der b ased system. T o fur th er gain insight into c hoosing the n umber of m icro- phone streams in the frame-level re-we ig hting task, we ex- plore the trend of WER v ia re-weighting the n-best ( n = 1 , ..., 12 ) streams. Group ”E” shows an extreme case that only one microphone stre a m is locked given a frame (The ”Max” m e ans ”Winner T akes All” for the total 12 stream s). The results show a se vere perf ormance d egradation fo r both the method s. Ho wever , if we focu s on the trend in Fig. 2, we can find that the WERs decrea se d ramatically using only sev- eral micropho ne stream s, and conv erge to steady with more streams. One interesting observation is th at the ”HRM” test set con verges faster than the ”LDC” set, which is in accor d with the fact that fewer micr ophon e stream s have excellent WER resu lts in the ”HRM” set. 4. CONCLUSION In this stud y , we aim ed at imp roving the multi-chan nel far- field ASR perfo rmance by stressing the collabor ation o f microph one stre a ms. A stre a m attention architecture was designed to give a more reasonab le f rame-wise fusion of HMM state posterior p robabilities for the recognizer , r egar d - less of the time misalignment of microphones. Accord in g to the ASR results o n the Mixer-6 dataset, we fo und that our pro posed framework showed a substantial capability to improve the p erforman ce with mu ltiple inp uts. The approach is highly p arallel and, esp ecially in the case of the entropy- based sy stem , r elati vely compu tationally affordable. While the au to encoder system showed a m ore r obust perform ance in case of micr o phone perturb ation. In futu r e works, we would like to te st the framework in the situation that the target speaker moves around and figure out th e traces of active micropho ne streams. W e are also in- terested in merging the posterio rs using n onlinear networks. 5. REFERENCES [1] Cha Zha n g, Dinei Flor ˆ encio, Demba E Ba, and Zhengy ou Zhan g, “Maximum likelihood soun d sou rce localization and beam forming fo r directional micro- phone array s in distributed meetings, ” IEEE T ransac- tions on Multimedia , v ol. 10, no. 3 , pp. 538– 548, 2008. [2] Shmulik Ma r kovich-Golan, Alexand er Bertrand, Marc Moonen , and Sharon Gan not, “Optimal distributed minimum- variance beamfor ming app roaches for speech enhancem ent in wireless acoustic sensor n e tworks, ” Sig- nal Pr ocessing , v ol. 1 07, pp . 4–20, 2015 . [3] Zhong Meng, Sh inji W atanabe, John R Hershey , an d Hakan Erdoga n , “Deep long short-term memo ry adap- ti ve beamfo rming networks fo r m ultichannel ro bust speech reco g nition, ” in Acoustics, Speech an d Signa l Pr o cessing (ICASSP), 2017 IEEE International C on fer - ence on . IEEE, 2017, p p. 271 – 275. [4] Jonathan G Fiscus, “ A post-pr ocessing system to yield reduced word error rates: Recognize r output voting er- ror reduction (rover), ” in Automatic Speech Recog- nition an d Understanding, 19 97. Pr o ceedings., 1997 IEEE W orksho p on . IEEE, 1997, pp. 347–354. [5] Haihua Xu, Daniel Povey , Lid ia M angu, and Jie Zh u , “ An improved con sensus-like method fo r m inimum bayes risk decoding and lattice com bination, ” in Acous- tics Spee ch and Sign al P r oce ssing (ICASSP), 2010 IEEE Internation al Conference on . IEEE, 201 0, p p. 4938 – 4941. [6] Alex W aibel, T oshiyuki Han azawa, Geoffrey Hinton, Kiyohiro Shikano, and K evin J Lang, “Phonem e recog- nition u sing time-delay ne ural networks, ” IEE E trans- actions on acoustics, speech, and signal pr ocessing , vol. 37, no. 3, pp . 328–33 9, 1 9 89. [7] Dzmitry Bahdanau , Kyunghyun Cho, a nd Y oshua Ben - gio, “Neural machine tran slation by jointly learning to align an d translate, ” arXiv pr eprint arXiv:14 09.04 73 , 2014. [8] Suyoun Kim an d Ian Lane , “Recurrent models for auditory attention in multi-micr o phone distance speech recogn itio n, ” in INTERSP EECH , 2016, pp . 383 8–384 2. [9] Shigeki Okaw a, En rico Bocch ieri, and Alexandros Potamianos, “Multi-ban d sp e ech recogn ition in noisy en vir o nments, ” in Acoustics, Speech an d Signa l Pr o- cessing, 199 8. P r oc eedings of the 1 998 IEEE In terna- tional Confer en ce on . IEEE, 1 998, vol. 2 , pp. 641– 644. [10] Hem ant Misra, Herv ´ e B ou rlard, and V ivek T yag i, “Entropy-b ased multi-stream combin ation, ” T ech. Rep., IDIAP , 2 002. [11] Hynek Hermansky , E hsan V ariani, and V ijay aditya Ped- dinti, “ M ean temporal distance: Predicting asr error from temporal p roperties of sp eech signal, ” in A cous- tics, Spe ech an d Sig nal Pr ocessing (ICAS SP), 2013 IEEE Internatio nal Confer en ce o n . IEEE, 2013, pp. 7423– 7426. [12] Bernd T Meyer, Sri Ha r ish Mallidi, Angel Ma r io Castro Mart´ ınez, Guillermo P ay ´ a-V ay ´ a, Hendrik Kayser, and Hynek Herman sky , “Perf ormance monitor in g for auto- matic speech recognition in noisy m ulti-chann el envi- ronmen ts, ” in Spo ken Langu age T e chnology W orksho p (SLT), 2016 IEEE . IE EE, 2016 , pp. 50 –56. [13] Sri Har ish Mallidi, T e tsu ji Ogawa, and Hynek Herman- sky , “Un certainty estimation of d nn classifiers, ” in Auto- matic Sp eech Recogn ition and Und erstanding (ASRU), 2015 IEEE W orkshop on . IEEE, 2015, pp. 2 83–28 8. [14] Sri Harish Reddy Mallidi, T etsuji Ogawa, Karel V esel ` y, Phani S Nidad av olu, and Hynek Herm ansky , “ Autoen - coder based multi-stream com bination for no ise robust speech recogn itio n., ” in INTERSPEECH , 201 5, pp. 3551– 3555. [15] V ijayadity a Pedd inti, Daniel Povey , an d Sanjeev Khu- danpu r, “ A time d elay neu ral network architecture fo r efficient mo deling of lon g tempor al contexts, ” in Six - teenth Ann ual Confer en ce of the I nternationa l Speech Communicatio n Association , 201 5. [16] L Bra n dschain, D Gr aff, C Cieri, K W alker , C Caruso, and A Neely , “ The m ixer 6 corpus: Resources for cross- channel and text in depend e nt speaker r e cognition, ” in Pr o c. of LREC , 20 10. [17] Josef Kittler, Mohamad Hatef , Rober t PW Duin, an d Jiri Matas, “On combin ing classifiers, ” IE EE transactions on p attern a nalysis a nd ma chine intelligence , v ol. 20, no. 3, pp. 22 6 –239, 1998 .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment