Filtering Variational Objectives
When used as a surrogate objective for maximum likelihood estimation in latent variable models, the evidence lower bound (ELBO) produces state-of-the-art results. Inspired by this, we consider the extension of the ELBO to a family of lower bounds defined by a particle filter’s estimator of the marginal likelihood, the filtering variational objectives (FIVOs). FIVOs take the same arguments as the ELBO, but can exploit a model’s sequential structure to form tighter bounds. We present results that relate the tightness of FIVO’s bound to the variance of the particle filter’s estimator by considering the generic case of bounds defined as log-transformed likelihood estimators. Experimentally, we show that training with FIVO results in substantial improvements over training the same model architecture with the ELBO on sequential data.
💡 Research Summary
This paper introduces Filtering Variational Objectives (FIVOs), a new family of variational lower bounds for maximum‑likelihood estimation in latent variable models with sequential structure. The key idea is to treat the log of an unbiased particle‑filter estimator of the marginal likelihood as an objective function. By viewing such objectives as Monte Carlo Objectives (MCOs), the authors prove that the tightness of the bound is directly linked to the relative variance of the underlying estimator: lower variance yields a tighter bound. Particle filters, unlike naïve importance sampling, maintain a set of weighted particles and perform resampling, which reduces variance growth from exponential to linear (or better) in the sequence length. Consequently, FIVOs can be substantially tighter than the Importance‑Weighted Auto‑Encoder (IWAE) bound.
Algorithm 1 details the FIVO computation: given observations (x_{1:T}), a model (p), a variational posterior (q) factorised over time, and a particle count (N), the filter sequentially proposes latent extensions, updates incremental importance weights, and optionally resamples based on an effective‑sample‑size criterion. The log of the product of incremental estimates provides an unbiased estimator (\hat p_N(x_{1:T})); its expectation defines the FIVO bound.
Optimization proceeds via stochastic gradient ascent. When (q) is re‑parameterisable, the gradient of (\log \hat p_N) with respect to model and inference parameters can be estimated by back‑propagation through the particle‑filter forward pass. Although the full gradient includes additional terms from the stochastic resampling decisions, the authors find that ignoring these terms (i.e., using only (\nabla_{\theta,\phi}\log \hat p_N)) yields lower variance and works well in practice.
Theoretical analysis shows that, under a mild independence condition (future observations independent of past latents given past observations), the optimal variational posterior (q^*) makes the FIVO bound equal to the true log‑marginal likelihood—a property termed “sharpness.” Moreover, if the log‑estimator is uniformly integrable, the bound converges to the exact log‑likelihood as the number of particles (N) grows.
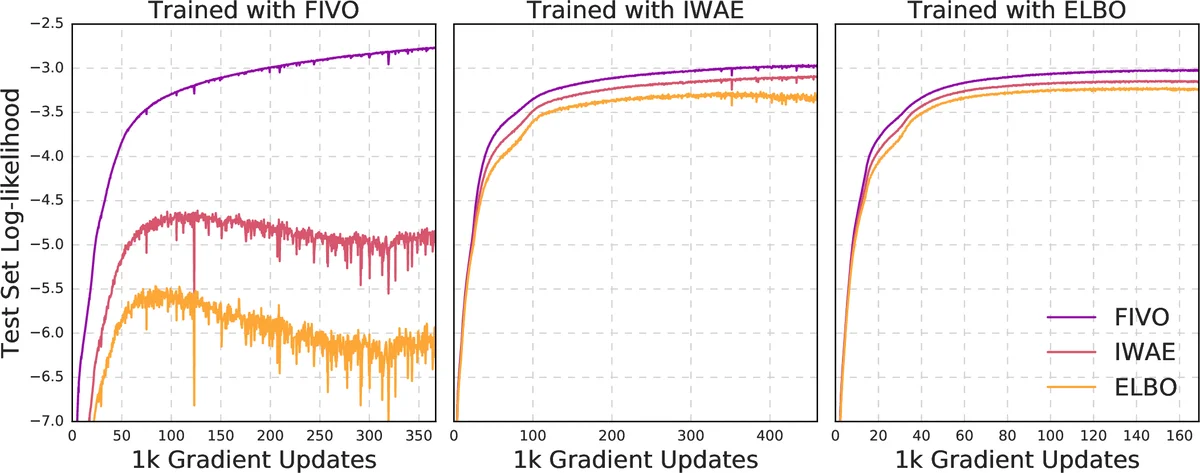
Empirical studies on sequential data (speech and language modeling) compare ELBO, IWAE, and FIVO using identical neural architectures. Results demonstrate that FIVO achieves faster convergence during training and higher final test log‑likelihoods than both ELBO and IWAE. Increasing the particle count further tightens the bound, confirming the theoretical predictions.
In summary, the paper establishes that particle‑filter‑based variational objectives provide a principled and practically effective way to exploit sequential structure, delivering tighter bounds and improved performance over existing variational methods. This work opens the door to more efficient learning in a wide range of time‑dependent latent variable models.
Comments & Academic Discussion
Loading comments...
Leave a Comment