Computationally Efficient Target Classification in Multispectral Image Data with Deep Neural Networks
Detecting and classifying targets in video streams from surveillance cameras is a cumbersome, error-prone and expensive task. Often, the incurred costs are prohibitive for real-time monitoring. This leads to data being stored locally or transmitted t…
Authors: Lukas Cavigelli, Dominic Bernath, Michele Magno
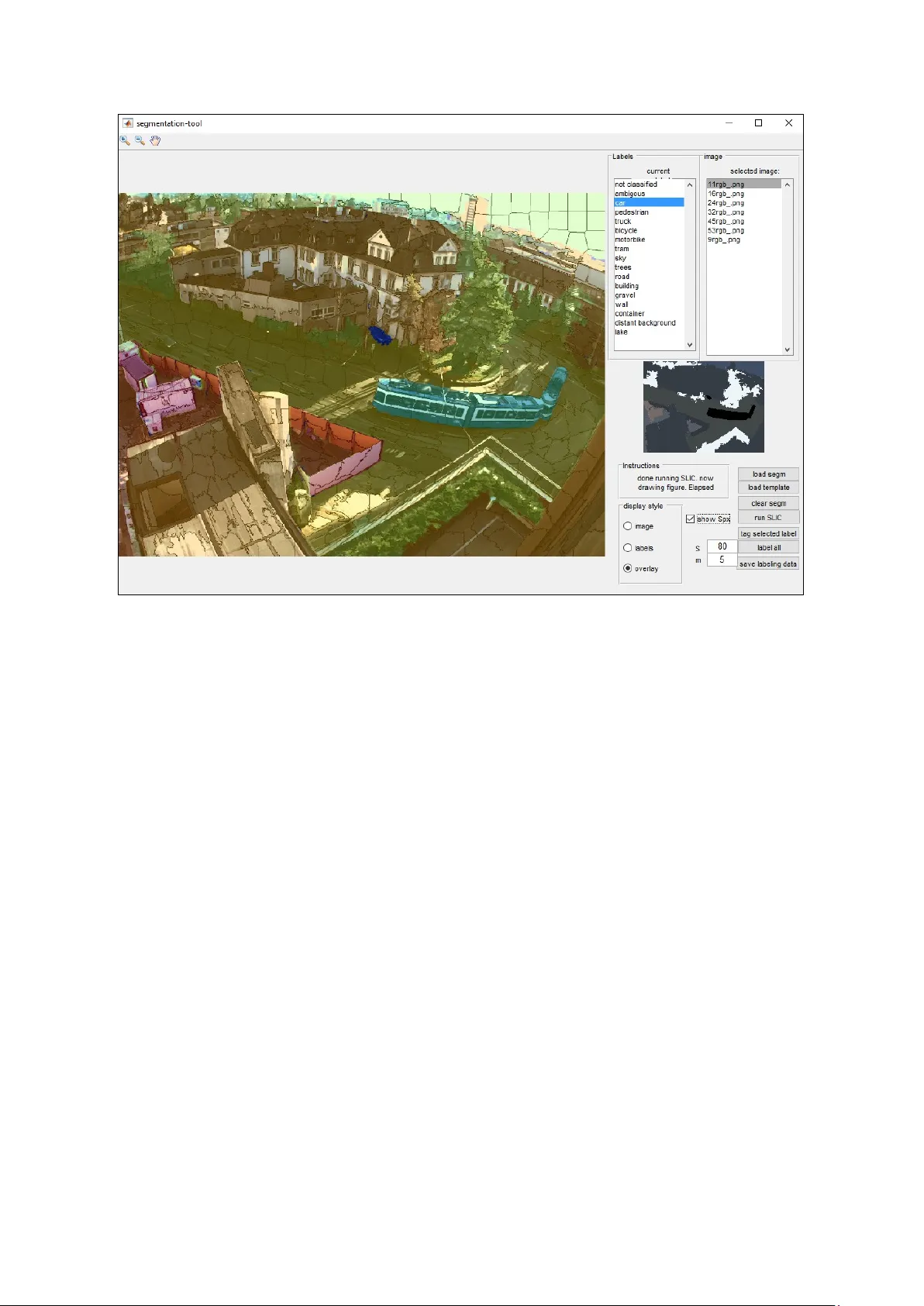
Computationally Efficient Target Classification in Multispectral I mage Data w ith Deep Neural Netw orks Lukas Cavigelli a, * , Dominic Bernath a , Michele Magno a,b , Luca Benini a,b a ETH Zurich, Integrated S ystems Laboratory, Gloriastr. 3 5, CH-809 2 Zurich, Switzerland b University of Bologna, DEI, Viale Risorgi mento 2, I-40126 Bolo gna, Italy ABSTRACT Detecting and classifying targets in video strea ms from surveillance cameras is a cumberso me, error -prone and expensive task. Often, the inc urred costs are prohibitive for real-time m o nitoring. This leads to data being stored locally or tran s mitted to a central stor age site for post-incident examination. T he required co mmunication links and archiving of the video data are still expensive and this setup excludes pree mptive actions to respond to imminent threats. An effective wa y to overco me these li mitations is to build a smart ca mera that analyz es the data on-site, close to the sensor, and transmi ts alerts when relevant video seque nces are detected . Deep neural networks (DNNs) have come to outperform humans in visual classification s tasks and are also p erforming exceptionally well on other c omputer vision tasks. The concept o f DNNs and Convolutional Net works (ConvNets) can easily be extended to make us e of higher-di mensional input d ata such as multispectral data. We explore this op portunity in terms of achievable acc uracy and required co mputational effort. To analyze the precision o f DNNs for sce ne labelin g in an urb an surveillance scenario we hav e cr eated a dataset with 8 classes obtained in a f ield experi ment. We combine an RGB camera with a 25-channel VIS-NIR snapshot sensor to ass e ss the potential o f multispectral image d ata for targe t classificatio n. We evaluate several n e w DNNs, s howing th a t the sp ectral information fu sed toget her with the RGB frames can be used to improve the accurac y of t he syste m or to achieve similar accuracy with a 3x smaller computation effort. We achieve a very high per-pixel accurac y of 99. 1%. Even for scarcely occurring, but particularly i nteresting classes, suc h as cars, 75 % of the pixels ar e labeled correctly with er rors occurring only aro und the bord er of the objects. This high accurac y was ob tained with a training set of only 30 labeled imag es, paving the way for fast adaptation to various application sce narios. Keywords: Multispectral imaging, convolut ional neural networks, scene labeling , semanti c segmentation, smart ca mera , hyperspectral imaging, urban surveillance, deep learning . 1. INTRODUCT IO N Video analysis is widely used for enhanced s urveillance and inspection ap plications in m any co mmercial and i ndustrial products. Vid eo analysis is based on algorithm s that pro cess the i mages acquired by a camera to extract features and meaning to auto matically dete ct significant eve nts . Durin g the last 20 years many algorith ms have been proposed to achieve the b est per formance i n video anal ysis usin g seve ral approac hes (e.g . Suppo rt Vector Machines, Hidden Markov Model s among others). Today, no vel algorith ms based o n deep neural networks (DNN s) are overcoming the per formance o f the previous algorithms and coming close to or exceeding t he accuracy of hu mans. Moreover, DNNs are not only achievi ng * Corresponding author. E-mail : cavigelli @iis.ee.ethz.ch high p erformance in whole image classi fication but al so in parts of them, i.e . in ob ject detection and i n general object/scene semantic segmentation. Multispectral i mages are w idel y used i n remote s e nsing, geoph ysical monitoring, astronomy , industrial pro cess monitorin g and target detection 1 – 6 b ecause of their ability to cap ture more inf o rmation about the material properties, facilitating the analysis of the i mage data 7 by seeing m o re than nor mal RGB ca meras or the human ey e. However, such ca meras with more than just a few channel s are still relatively rar e, and a large share of the m is likely used for defense applications in a stationary setup or mounted on vehicles due to their size, weight, and pro curement cost. Over the last two years, a new type of fully-integrated multispec tral CMOS sensor has become available, shrinking the device size and weight to the one of normal RGB ca meras while at the sa me time making the m much more affordable. T he application o f DNN -based embedded visual analytics to multispectral images is a scar cely explored area, w i th significant potential for i mproved robustness and accurac y. DNNs are also known to be computational ly e xpensive. A pop ular way to provide this co mputation power needed to process images and video, is t o us e a large number of ex p ensive servers in a datacenter, which ar e connected to the camera via E thernet or other fast co mmunication interfaces . T his is, for example , the approach used by Go ogle a nd Facebook to process i mages and video from users dis tributed in the world . Ho wev er , the constantl y increasing number o f t he ca meras sending data to servers and supercomputers, is posing the problem of the huge amount of data being transferred and the computational po wer needed. Moreover, this app roach significantly increases t he time required to get a meaning from the processing data, li miting the possibility to have real -time processing. In contra st with th is approach, an emerging solution is to p rocess the data close to the sensors with embedded processors . This brings several benefits, such as reduci ng the amount of data need ed to be transferred, i mproving the response time to detect dangerous situation s a nd not requiring any fast external con nectivity or h u ge storage capacit y to w o rk prop erly. Due to these properties, ca meras that embed computational resources o n b oard, w e ll -known as s mart ca meras, are beco ming more an d m ore popular and ar e used in emerging surv eillance applications . A lt hough to day e mbedded processors have very high com p utational power , pushed up by ad vances in mobile phone s and portable co mputers, they a re still o rders of magnitude less po werful than superco mputers and workstations. For this reason, video processing in embed ded processors rem ains a very challen ging task, especially when th e y impleme nt highly accurate DNN s . T o run these algorith ms on an embedded platform, a co mbination o f optimized DNNs a nd a highly efficient i mplementation is needed 8 – 15 . In this paper , w e analyze the potential use o f multispectral sensors and e mbeddable DNN s for automated analysis o f video surveillance d ata in a “smart multi spectral ca mera” syste m. We create a dataset using a 2k RGB camera co mbined with a multispectral imagi ng device providing 25 equall y-spaced sp ectral bands in the range of 600 to 9 75 nm from a n urban surveillance perspective. With th e obtained data we eval uate the accurac y ac hievable w ith sev er al different DNNs analyzing the data automatically, labeling each pi xel with one o f 8 classes. The rest o f the paper is organized as f o llows : In Sectio n 2 we list some r elated w o rk before ex p laining h ow the dataset was collected in Section 3. We present three di fferent t ype of D NNs in Section 4, which w e then e valuate and test in Sectio n 5. Section 6 concludes t he paper. 2. RELATED WORK The ground-breaking performance of deep learning and convolutional neural networks ( ConvNets) in partic ular is undisputable nowadays . ConvNets have been sho wn to outperform trad itional co mputer vision appr oaches by a large margin in ma ny app lications areas and they have eve n proven t heir beyond-human performance on visual ta sk s such as image clas sification. I n t his p aper, we are focusing on sce ne labeling, so metimes r eferred to as semantic segmentation, for which ConvNets are showing si milarly outstanding results 8,16 – 18 . Hyper- a nd multispectral data and images obtained with very specific spectral filters have b een success fully used for industrial computer vision (q uality co ntrol, …) and remote sensing for so me ti me. Ho wever, multispectral sensors have been very expensive, bulky, an d often required a non -trivial s ynchronization system. With th e recent appearance of single - chip multispectral snapshot s ensor, these ha ve beco me much more comparable with i ndustrial RGB i mage sensors. Alongside this, new anal ysis to ols have become available , some of them freel y like Scyven 19 . Existing w o rk usin g ConvNets to anal yze multispectral i mage data is limited to different ap plication areas and often ve ry few spectral cha nnels. In one w o rk 20 , the authors co mbine RGB im a ges with a single thermal LWIR cha nnel to detect (but not segment) pedestrians from a car’s perspective, co llecting a dataset and using traditional HOG features. T he authors of two o ther w or ks 21,22 report on using ConvNets to classi fy aer ial scen es from the UCMerced Lan d -use dataset 23 (32 classes , 100 images with 256x25 6 pixel each), the RS19 d ataset (1005 images from Google Earth with 600x600 pixel w ith 1 9 classes) and the Brazilian Coffee Scenes dataset 24 (2 classes, SPOT satellite images, 36577 images with 64x64 pixels each), of which the last incl udes multispectral i mages with 3 channels: red , green and NIR. Scene labeli ng has al ways be en a computationall y expen sive ta sk, req uiring p owerful G PUs to be able to process just a few lo w-resolution images eac h seco nd using ConvNet s 8,25,26 and often several min utes per fr ame with traditio nal co mputer vision methods 27 – 30 to obtain d ecent qualit y results. This a lready assumes the use of o ptimized software implementatio ns, and currently only specialized hardware implementations using FPGAs or even ASICs can provide reasonable throughput and accuracy within the po w er li mits of an embedded platform 8,9,31,32 . 3. DATASE T COLLECTION There is only li mited related work usin g many -channel multispectral information to perfor m scene lab eling, and no ne for urban sur veillance scenario s. Furthermore, the types of sen sors used in related work strongly focused on using beam splitters and ded icated imaging sensor s for each channel i nstead of a multis p ectral mosaic sensor 20 . Before being ab le to perform any evaluatio ns toward s answering the questio n of whether multispectr al data can i mprove scene labeling results or si mplify the pr ocessing pipeline to obtain good results , we need to create a dataset. We combine a lower reso lution multispectral 2 5-channel mosaic VISNI R sensor with a hi gh resolution RGB ca mera, which could be integrated with an embedded processor such as the Tegra K1 to build a s mart camera able to pro cess data on - site . In this section, we e xplain how we collected this dataset. We identify t he specific cameras used, explain how the data of the t w o sensors has been merged, and how the gro und truth labeling has bee n created. 3.1 Image sensors We have collected a dataset using two sensors , a high-re solution RGB sensor to capture shapes acc urately a nd a lower resolution multispectral sensor to obtain additional informa tion about the materials. For the RGB images we have use d high-resolution ca mera from Point Grey, the Flea3 FL3- U3 -32S2C- CS , built around the Sony IMX036 1/2 .8" CMOS sensor providing pixel ima ges a t 6 0 frame/s o ver U SB 3 . W e eq uipped this ca mera with a Fujinon YV2.8x2.8SA -2 lens with a var iable focal length of 2.8 -8 mm . The multispectral i mages have b een acquired using the Xim ea xiSpec MQ022HG- IM -SM5X5-NIR ca mera, which feature s a 2/3 ” CMOS snapshot mosaic sensor by IMEC. T his sensor is b ased on a monoc hrome CMOSIS C MV2000 d evice with pixels with an ad ditional int erference filter -based mosaic to obtain different spectral channels. It provides 25 equal ly -spaced s p ectral bands with center freq uencies in the ra nge of 600 - 975 nm and can stream multispectral cubes at up to 170 frame/s over USB 3 . We used the Tamron 22HA lens with a focal length of 6.5 mm for this devic e, combined with a Sc hneider FIL LP565 long-pass filter to suppress light with half the wavelength of the individual resonance fil ters cr eating t he mosaic on the se nsor . T he selection of the se lense s was strongly influenced b y t he desire to capture a surveillance ca mera view o f the scenery 33 . The RGB camera meas ures 3/3 /4.5 cm with a weight of 35 g and the lens is 5 c m long, has a diameter o f 5.5 cm and weights 50 g. T he multispectr al camera weighs 32 g a nd fits i nto a 2.7/2.7/3 cm ho using. T he lens add s another 60 g, is 3.7 cm long and has a 3.7 cm diameter. The t wo devices use 3 W and 1.6 W, respectively. 3.2 Image alignment To cr eate a rectified setup, we have fixed both cameras on a mounting plate and ad justed the RGB camera le ns’ focal length to best match the field- of -view size of the multispectral ca mera. In a first step the mosaic m u ltispec tral i mage is con verted fr om its 2D data layout to a multispectral cube of pixels and 25 channels . When overla ying the images so me distortio n differences beco me visible . T o correct this, we infer a geometric transformation usi ng the local weighted mean transfor m (LWMT) with the 12 closest points used to deduce a 2 nd degree polynomial transformation for each control p oint pair b ased on a total of 33 correspo ndence pairs scattered all across the i mage. We use this transfor m to warp the multispectral image c ube to the RGB im age using bicubic interp olation , aligning t he pixels of the two i mage sources , such that they ca n be stacked to a 2 8 channel image . Finally, the resulting image cube is crop ped to pixel, such that onl y area s where data from both sources is available remain as illustrated in Fig ure 2. Figure 1. The two cameras fixed on a mounting plate (left) and a sample image of the dataset and cut-outs of 6 from the total of 25 chan nels of multispectral data (right) . Figure 2. A typical ground-truth labeled RGB image with an overlay showing the area covered by the warped multispectral image and with the cropped area used for our dataset. With the above mentioned procedure, we do not perform any deb ayering/demosaicking , for which a large variety of algorithms exist to make the visual perce ption of RGB images as pleasing as p ossible. Many of them ca nnot easil y be adapted to non-RGB data, and the most straight- forward one w o uld be to use bilinear interpolation for this as well. We have d ecided not to do so, b ecause suc h an interp olation step can also be represented in the f irst convolution layer of a ConvNet, such that doing this explicitly be fore would primarily add to the overall computational effort without much benefit. The first co nvolution la yer can also compensate for var ying sensitivity of the individual spec tral bands. 3.3 Data labeling We have collected 40 images from the same street surveilla nce perspective. Based on the RGB image, we have labeled each pixel with o ne of 8 classes: car/truck, sky, building, road/gravel, tree/shru bbery, tram, water, distan t background. For the evaluatio n, we have rando mly partitioned the data set into 30 tr aining images and 10 test images. So me sample images are sho wn in Figure 3 . In order to facilitate the cr eation of the ground truth , we ha ve developed a program to assi st in labeling the dataset shown in Figure 5 . I nstead of assigning a c lass to each pixel indi vidually, we segme nt the image into superpixels usin g the SLIC algorithm 34 and lab el these. SLIC clusters the pixels based on a combination of the photo distance and the L2 distance in the image plane to create an oversegmentation of the i mage. The label is then assigned to each pixel within the superpixel. It has p roven useful to start with large s uperpixels and fu r ther i mprove wit h a finer-grained segmentation. The manual labeling process w as further sped u p by making use of t he static background, taking the la beling of o ne image as a starting point for the next one. Figure 3. Sample images from the acquired dataset. Figure 4. Class distrib ution of the training and tes t dataset. The manual labelling of a dataset is not straight-for ward. We have assigned the above labels as accurately as possible, but did n o t include a hard - to -classify , unclassified , or amb iguous class . T his means t hat if there ar e ped estrians (a non-existing class) which co ver only a few pixels, they h ave been classified like their surroundings pixels. Als o the distinction between distant ba ckground and buildings , trees is based on being clearly able to distinguish them at the give n resolution, which might vary based on personal p erception. Furthermore, the dataset contains trees in front of buildings an d th e roa d, leaving some g ap s through which the background is v isible. We have labeled th e entire area covered by the foreground object with its class, only labeling gaps t hrough which the bac kgrou nd is visible, if they cover se veral pixels. The class distribu tion is very uneven, such t hat what might be the most interesting classes, ca r/truck and tram , mak e up o nly a s mall share o f the total number of lab eled pixels in the data set (cf. Figure 4). 4. NEURAL NETWORK ARCHITECTUR ES In this sect ion, we present three ty pes of neural networks, starting with a p er -pixel classification w i th a n o rmal multi-layer neural network to explore w hat is possib le with a relat ively simple classifier. We t hen move on to present our o wn pro posed ConvNets, exploring the impro vement t hat can be o btained based on the shape and textur e of o bjects in the ima ge. We approach this by ad apting a kno wn scene labelin g Co nvNet targeted at a different, R GB-onl y dataset and further explo re the use of ConvNets b ased on the concepts of the c urrent state- of -th e-art in im age recognition and adap t them to our application. 4.1 Per-pixel classificat ion Spectral inf o rmation has lon g and successfully been used for m a terial classification. This type of analysis is done on a per- pixel basis, independent o f neighborin g values. We per form such a material -based classification using a 5-la yer neural Figure 5. The scene labeling tool with the labeling overlaid on the RGB image and sup erpixel boundaries in shown in black . network evaluated for each pixel individuall y to analyze whether the ad ditional multispectral channels can improve segmentation results i n this setting. This should provide a data point in the co rner of fast and very energ y-efficient analysis at lower accuracy than t he more complex ConvNet s . We class i fy each pixel individually by its 3 or 28 channels fo r the RGB-only and multispect ral + RGB image, respectively. We train a 5-layer n e ural network w it h 32, 128, 512, 64, and 10 output ch an nels f or each la yer. As a non-linearity between the la yers we use the ReLU activatio n function, prec eded by batc h nor malization to aid with speedy training 35,36 . As will be explained in the next sectio ns, the other neural net works include two pooling layers, each with a subsampling factor of 2 in bo th dir ections. In order to b e able to compare these networks better, we s ubsample the input i mage befor e ap plying pixel-wise classi fication. 4.2 Convolutional net work targeting the Sta nford backgrounds dataset Looking onl y at individual p ixels of an image is not optimal, if we desire to o btain a high-quali ty sem antic segmentation of the sce ne. Based on this input only, it would also be tremendousl y difficult for humans to solve such a tas k. A key ingredient to a high-q uality segmentation is the reco gnition of the shape o f objects, their texture, and their contextua l relation. With a per -pixel analysis there i s only a little information abou t the texture, o nly the pixel’s color, and very little contextual infor mation given by the dataset acquisition setu p and its class distrib ution. By using a Con vNet we can i mprove by always taking a spatially local neighbo rhood into consideration , buildi ng a hierarchy of increas ingly abstract r epresentations to capt ure this infor mation, such as that a ca r has wheels with dark tires and occurs on a road . This is done by the typical stacking o f sequences of a convolutional, an activation and a pooling layer. To get a performance b aseline, w e used the struct ure of the network prese nted in 8 , which was optimized for the Stanford Backgrounds dataset. This dataset contains 715 im a ges o f str eet view scenes with 8 class e s and a resolution o f . The used ConvNet is shown in Fi gure 7, using max-pooling and ReLU acti vations . This Con vNet co mes in t wo flavors: single -scale and multi-scale. A pplying a feature ex tractor, such as a ConvNet, o n scaled versions o f the image to build a limited invariance of the features to the size of objects is a wide-spread concept in computer visio n. In ord er to be able to train the ConvNet end - to -e nd, the feature extraction part is applied to the images scaled do wn b y a factor of 1, 2, and 4. T he resulting feature map is bilinearly inte rpolated such t hat all 3 feature maps ar e of the same size, befor e the y ar e stack on top of each other and per -pixel classification is applied. T he three feature Figure 6. The pixel-wise classification neural network. Figure 7. The scene labeling ConvNet based on 8 used to obtain a perf or mance baseline. extraction branche s for the different scales share the sa me par ameters (weights, biases) and t he gradients during backpropagation are applied to all the branches. Differently fro m the o riginal imple mentation, we ap ply the convolutional la yers with zero -padding of t heir input in order to not loose pixels at the borders of the image when ap plying the convolutions also i n th e single -scale configuration . In this way, we obtain a bo rderless res ult, si nce the multi -scale configuration would ot her wise imply very wide bo rders and a full o utput labeling map is d esirable in any case. In ord er to reduce the evaluatio n time a nd memor y requirements , we are training the ConvNet with a scaled -down inp ut image of pixel. W ith this net work, the output resolutio n is smaller b y a factor of 4 in eac h direction due to the max -pooling layers. In ord er to pr ocess not only the RGB d ata, but also the multispectral informa tion, we simply increase the number of input la yers o f the first convolutional layer to 28 . Contrary to the original network, it h as proven to be more effective n o t to include any prep rocessing steps such a s contrast normalization. 4.3 ResNet-inspired conv olutiona l networks The network presented in the previous section has been optimized for a differe nt dataset and ne wer types of net works which are showing better accuracy in image recognition tas ks have beco me available . Dee p residual networks (Re sNets) are the current sta te- of -th e -art method, having a sequence of very small filters ( ) and ever y few layers a b ypass path to be able to train deeper lay er s of the network as well 18 . We take this concept to build our own C o nvNet s and to optimize them for our applicatio n. We have co nstruct ed several ConvNets of varying depth and di fferent numbers of feature maps , and analyze t he effect of mul ti-scale features and the multispectral data. We have kept t he two m o st interest ing results which are at the Par eto-optimal front i n terms of error rate and computational effort. 4.4 Training the convolutio nal netw orks We use the T orch framework for training the ConvNets. Optimization of the trained para meters is d one using the ADAM algorithm 37 a nd with batch normalization layers i n front of the activation functions and no drop out 36 . We app ly an equal - weight multi-class margin loss functio n , with the the target class index and x the output of the ConvNet. This optimizes the parameters o f the networ k to maximize the distance of the training sa mples in the Figure 8. On the top, the ResNet module is shown which serve s as a basis for the tw o ResNet-inspired ConvNets. The max- pooling operations are on ly a p plied if me n tion ed and the con volution m odu le in the l o wer p ath is only inserted if the number of feature maps differs betw e en the input and the output. The two networks evaluated are shown in the center and at t h e bottom o f the image. The pixel-wise classification is the same as shown in Figure 7 . output space of the ConvNet , si milar to the linear SVM obj ective 38 . All of the networks used here have an output with lower resolution due to the pooling lay er s. We train the network with an acco rdingly down -sampled ground truth labeli ng. 5. RESULT S & DISCUSSION We have evaluated the afore mentioned neural networks to d etermine the per-pi xel error rate as well as the computatio nal effort, the t wo most important criteria for a smart camera. Per forming per-pixel classification (Net work A ) using the RGB and the multispectral d ata, we obtained an erro r r ate of 9.4% on the te st set. For comparison, the ConvNet described in Section 4.2 (Network B) yielded an error rate of 0 .9% and the two ResNet-like ConvNets achieved err or rates of 1.3% an d 1.1% for the d eeper and the shallo wer o ne (Ne twork C1 and C2) , respectively. Se veral additional neural networks based on the co ncepts sho wn in Sect ion 4 have b een evaluated, but we report only those on the P areto -optimal front in ter ms of error rate and computation e ffort. One o f the major goals in o ur e xperiments was to f i nd w het her a multispectral camera w ould ad d r elevant ne w infor mation to i mprove the classification accuracy. W e have thus trai ned the best perfor ming Net work B only o n RGB data as well, suffering a noticeab le degradatio n with an increase of 0.4% in the error rate. This clearly shows that the additio nally gathered information aids i n impro ving the quality of the re sults. It also more generally sh ows that it is indeed possible to train a ConvNet for this tas k using a relatively s mall dataset. The variations bet ween the analyzed neural networks in ter ms of er ror might seem sma ll and a slightly less accurate network acceptable (cf. Figure 9). However, with a d ataset as unbalanced as th e one o btained for our application scenario, this can have a strongly lever aged i mpact on the error rate of unco mmon classes. The confusion m atr ices in Figure 10 visualize this . The d ifference of 0 .4% on the per -pixel erro r rate results in a drop of 18% in the clas sificati on of car/truck pixels. Ho wever, an error rate of e.g. 1 0% i n case of the tram does not mean t hat ob jects are missed, but rather that the classification around the ir borders is somewhat fuzzy. It is im po rtant to note, that every c ar, truck or tram in the te st se t has always been par tially recognized. On an embedded platform with hard power constraints, the c omputation effort can li mit the choice of neural net works deployable. T hus, i t can be come acceptable to have some a ccuracy losses and use t he networks C1 o r C2. The Net work C1 has the same erro r rate as the RGB -only Network A with a 3x s maller computational burd en , that makes it interest ing to add such a multispectral sensor to save power on a s ystem level . T he Nvidia Tegra K1 p latform with a two -core AR M processor and a sm all GPU is specifically tar geting such embedd ed computer vision applications and is ab le to perform about 96 GOp /s, consuming 10 Watts 8 . This means that we can either p rocess about 1 fra me/s with Network A or 3 frame/s with Network C1, achievi ng the same accurac y as Network A if it was evaluated without the multispectral d ata. Figure 9 . Pixel-wise error rate o f the evaluated networks on the test set an d their computation effort (left) and scene labelin g output of a test image processe d by Network A. 6. CONCLUSIONS In this work we evaluated t he benefits of combining an R GB cam er a with a multispectral camera in an e mbedded sm art camera. We have collected a dataset for scene labeling from an urban s urveillance per spective i ncluding a multispectral camera. W e ha ve pr esented novel ConvNets for scene lab eling usi ng this additio nal data. We s howed that even with a very limited amount of labeled d ata, highly accurate convolutio nal networks can be trained , making them an interest ing option even for rapid deployment in new surroundings. W e have further report how multi spectral data can be used to i mprove th e accuracy or, alternatively, to r educe the co mputational effort by 3x effectively increasi ng the overall energ y efficienc y and pushing real-ti me processing closer the ran ge of what is possib le on embedded p rocessing platforms. ACKNOWLEDG EMENTS This work was funded by armasuisse Science & Technology. REFERENC ES [1] Gross W., Boehler J., Schilling, H., Middel mann W., We yermann J ., Wellig P., Oechslin R C., Kneubuehler M., “ Assessment of target detectio n limits in h yperspectral data, ” Pro c. SPIE Secur. + Def. 9653 (201 5). [2] Bioucas-dias, J . M., Plaza, A., Camps-valls, G., Sche unders, P., Nasrab adi, N. M.., Chanussot, J., “ Hy per spectral Remote Sensing Data Analysis and Future Challen ges, ” IEE E Geosci. Remote Sens. Ma g.(June), 6 – 3 6 (2013). [3] Güneralp, I., Filippi, A. M. ., Randall, J. , “ Estimation of floo dplain aboveground biomass using multispectral remote sensing and nonpara metric modeling, ” Int. J. Appl. Ear th Obs. Geoinf. 33 (1), 119 – 12 6 (2014). [4] Qin, J., Chao, K., Kim, M. S., Lu, R.., B urks, T. F., “ Hyperspectral and m ultispectral imaging for evalua ting food safety and quality, ” J . Food Eng. 118 (2), 157 – 171, Elsevier Ltd (2013 ). [5] Dissing, B . S., P apadopoulou, O. S., T assou, C., Ersboll, B. K., Carstensen, J. M., P anagou, E. Z.., Nychas, G. J., “ Using Multi spectral I maging for Spoilage Dete ction o f Pork Meat, ” Foo d Bio process Technol. 6 (9) , 2268 – 2279 (2013). [6] van der Meer, F. D., van der W erff, H. M. A., van Ruitenbeek, F. J. A., Hec ker, C. A., Bakker, W. H., Noo men, M. F., van d er Meijd e, M., Carranza, E . J. M., de Smeth, J. B., et al., “ Multi- and hyperspec tral geologic re mote sensing: A review, ” Int. J. Appl. E arth Obs. Geoinf. 14 (1 ), 112 – 128, Elsevier B.V. (2012). [7] Quesada-Barriuso, P., Argüel lo, F.., Heras, D. B., “ Efficient segmentation of hy perspectral i mages on commodity GPUs, ” Front. Artif. Intel l. Appl. 243 , 2130 – 2139 (2012). [8] Cavigelli, L., Magno, M.., Benini, L., “ Accelerati ng Real-T ime Embed ded Scene Labeling with Con volutional Networks, ” Pro c. ACM/IEEE Des. Autom. Conf. (20 15). [9] Andri, R., Cavigelli, L., Rossi, D.., Benini, L., “ YodaNN: An Ultra- Low P ower Convolutional Neural Network Accelerator Based o n Binary Weights, ” arXiv:1606.0 5487 (2016). Network A, RGB-o nly. Pixel-wise erro r rate: 1.3% Network A. Pixel- wise error rate: 0.9% Figure 10 . Confusion m atrices of Network A using the RG B data so lely (left) and combining it with the m ultispectral data (rig ht). [10] Rastegari, M., Ordonez, V., Redmon, J.., Farhadi, A., “ XNOR -Net: ImageNet Classi fication Using Binary Convolutional Neural Net works, ” arXi v:1603.0527 9 (2016). [11] Paszke, A., Chaurasia, A., Kim, S.., Culurciello, E ., “ ENet: A Dee p Neural Net work Architect ure for Real -Ti me Semantic Segmentation, ” arXic:16 09.02147 (2016). [12] Ovtcharov, K., R uwase, O., Kim, J ., Fowers, J ., Strauss, K.., Chung, E. S., “ Accelerating Deep Convolutional Neural Networks Usin g Specialized Har dware ” ( 2015). [13] Chen, T ., Du, Z., Sun, N., Wang, J., W u, C., Chen, Y.. , Temam, O., “ DianNao: A Small- Footprint High- Throughput Accelerator for U biquitous Mac hine -Learning, ” Proc. ACM Int. Conf. Archit. Suppo rt P rogram. La ng. Oper. Syst., 269 – 284 (2014). [14] Farabet, C., Martini, B., C o rda, B., A kselrod, P ., Culurciello, E .., LeCun, Y., “ NeuFlow: A R untime Reconfigurable Dataflo w Pro cessor for Vision, ” Proc. IEEE Conf. Co mput. Vis. Pattern Recognit. Work., 109 – 116 (2011). [15] Conti, F.., Benini, L., “ A Ultra -Low-Energy Convolution Engine for Fast Brain -Inspired Vision in Mu lticore Clusters, ” Proc. IEEE Des. Autom. Test E ur. Conf. (20 15). [16] Farabet, C., Couprie, C., Najman, L.., LeCun, Y., “ Sce ne Parsing with M ultiscale Feature Learning, P urity Trees, and Optimal Covers, ” ar Xiv:1202. 2160 (2012). [17] Long, J ., Shelhamer, E.., Dar rell, T., “ Fully Convolutional Networks for Semantic Segmentation, ” Pro c. IEEE Conf. Comput. Vis. Patter n Recognit. (201 5). [18] He, K., Zhang, X., Ren, S.., Sun, J., “ Deep Resid ual Learning for I mage Recognition, ” ar Xiv:1512.0 3385 (2015). [19] Habili, N.., Oorloff, J., “ Scyllarus: Fro m Research to Commercial Software, ” Proc. 24th Australa s. Softw. E ng. Conf. (2015). [20] Hwang, S., Park, J., Kim, N., Ch oi, Y.., Kweon, I. S., “ Multispectral pedestrian detectio n: Benchmark dataset and baseline, ” Proc. IEEE Comput. Soc. Conf. Comput. Vi s. Pattern Recognit., 1 037 – 1045 (2015). [21] Nogueira, K., Miranda, W. O.., Santos, J. A . Dos., “ Improving Spatial Feature Representatio n f rom Aerial Scenes by U sing Convolutio nal Networks, ” Brazilian Symp. Co mput. Gr aph. Image Pro cess. 2015 -Octob , 2 89 – 296 (2015). [22] Nogueira, K., P enatti, O. A. B. ., Santos, J. A. dos., “ Towards Better Explo iting Convolutional Neural Net works for Remote Sensing Sce ne Classification, ” arXiv:1602.0 1517 (2016). [23] Yang, Y.., Ne wsam, S., “ Bag- of -visual-words and spatial extensions for land- use classifica tion, ” P roc. 1 8th SIGSPATIAL Int. Con f. Adv. Geogr. Inf. Syst. - GIS ’ 10, 270 (2010). [24] Penatti, A. B., Nogueira, K.., Santos, J. A., “ Do Deep Fea tures Generalize fro m E veryda y Ob jects to Remote Sensing and Aerial Sce nes Domains ?, ” 44 – 51 (2015) . [25] Farabet, C., Couprie, C., Najman, L.., LeCun, Y., “ Learning H ierarchical Features for Scene Labeling, ” IEEE Trans. Patter n Anal. Mach. Intell. (2013). [26] Farabet, C., “ T owards Real -Time Image Understandin g with Co nvolutional Networks, ” Un i versité Paris-Est (2014). [27] Seyedhosseini, M.., Tasdizen, T., “ Scene L ab eling with Contextual Hierar chical Models, ” arXiv:1402.0 595 (2014). [28] Kumar, M.., Koller, D., “ Ef ficiently selecting regions for scene understanding, ” Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 32 17 – 3224 (20 10). [29] Ayvaci, A., Raptis, M.. , Soatto, S., “ Occlusion Detectio n a nd Motion Esti mation with Convex Op timization, ” Adv. Neural Inf. Proce ss. Syst . 2 , 100 – 108 (2010). [30] Tighe, J.., Lazebnik, S., “ Supe rparsing: scalable nonpar ametric image parsing with superpi xels, ” Proc. E ur. Conf. Comput. Vis. (201 0). [31] Cavigelli, L., Gschwe nd, D., Mayer, C., W illi, S., Muheim, B.., Benini, L., “ Origa mi: A Convolutio nal Network Accelerator, ” P roc. ACM Gt. Lakes Symp. VLSI, 19 9 – 204, ACM Press (201 5). [32] Cavigelli, L.., Benini, L., “ Origami: A 803 GOp/s/W Convolutional Network Accelerator , ” IEEE T rans. Circuits Syst. Video T echnol. (2016). [33] Kruegle, H., CCTV Surveillance: Video Practices and Technology, B utterworth -Heinemann, Woburn, MA, USA (1995). [34] Achanta, R., Shaj i, A .. , Smith, K., “ S LIC Superpixels C o mpared to State- of -the-Art Superpixel Methods, ” Pattern Anal. … 34 (11), 2274 – 2281 (2012). [35] Nair, V.. , Hinton, G. E., “ Rectified Linear U nits Improve Restricted Boltz mann Machines, ” Proc. 27th Int. Conf. Mach. Learn.(3), 8 07 – 814 (2010) . [36] Ioffe, S.., Szegedy, C., “ Batch Normalization: Accelerating Deep Net work T raining b y Reducing I nternal Covariate Shift, ” P roc. Int. Conf. Mach. Learn., 44 8 – 456 (2015). [37] Kingma, D.., Ba, J ., “ Adam: A Method for Stochastic Optimizatio n, ” Proc. Int. Conf. Lear n. Represent. (2015). [38] Rosasco, L., De Vito, E., Caponnetto, A ., Piana, M.., Verri, A., “ Are loss f u nctions all the sa me?, ” Neural Comput. 16 (5), 1063 – 1076 (2004).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment