Improving Neural Machine Translation through Phrase-based Forced Decoding
Compared to traditional statistical machine translation (SMT), neural machine translation (NMT) often sacrifices adequacy for the sake of fluency. We propose a method to combine the advantages of traditional SMT and NMT by exploiting an existing phrase-based SMT model to compute the phrase-based decoding cost for an NMT output and then using this cost to rerank the n-best NMT outputs. The main challenge in implementing this approach is that NMT outputs may not be in the search space of the standard phrase-based decoding algorithm, because the search space of phrase-based SMT is limited by the phrase-based translation rule table. We propose a soft forced decoding algorithm, which can always successfully find a decoding path for any NMT output. We show that using the forced decoding cost to rerank the NMT outputs can successfully improve translation quality on four different language pairs.
💡 Research Summary
The paper addresses the well‑known trade‑off between fluency and adequacy in neural machine translation (NMT). While NMT produces highly fluent output, it often suffers from over‑translation, under‑translation, or completely unrelated lexical choices. To mitigate these problems, the authors propose a hybrid approach that leverages an existing phrase‑based statistical machine translation (PBMT) model to compute a “forced decoding” cost for each NMT hypothesis and then uses this cost to rerank an n‑best list of NMT outputs.
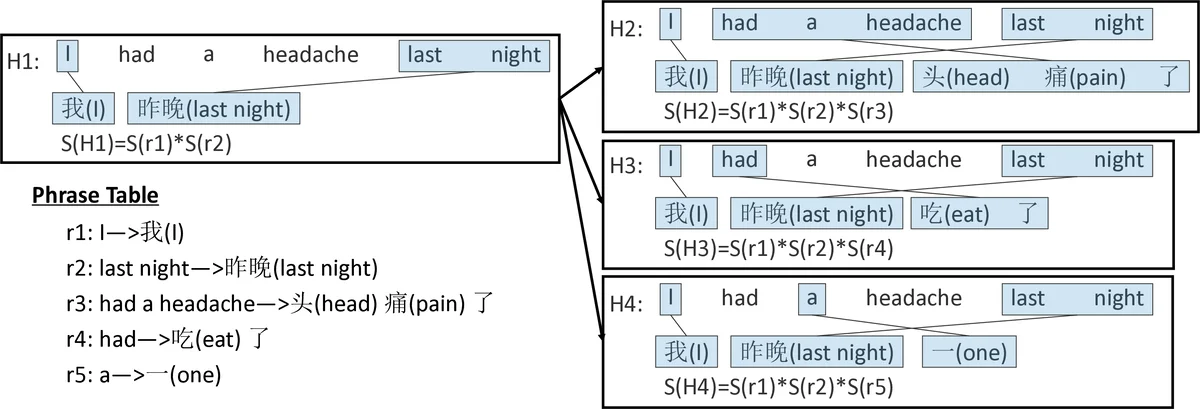
The central technical contribution is a soft forced decoding algorithm. Standard PBMT decoding can only generate translations that are covered by its phrase table; consequently, many NMT outputs lie outside this search space and cannot be evaluated directly. The authors introduce two special rule types: (1) source‑word‑to‑null rules that allow deletion of source words, and (2) null‑to‑target‑word rules that permit insertion of target words. The scores of these rules are derived from the frequency of unaligned words in the training corpus, giving higher penalties to content words and lower penalties to function words. By augmenting the phrase table with these rules, the decoder can always construct a decoding path that exactly reproduces any NMT output, albeit possibly with insertions or deletions. The score of the best such path, S_d, is combined with the original NMT log‑probability P_n in a linear model (w1·log P_n + w2·log S_d) whose weights are tuned on a development set.
Because beam search n‑best lists from NMT are typically low‑diversity, the authors also devise a sampling scheme to enrich the candidate set. At each decoding step they randomly choose between the two most probable tokens according to the NMT distribution, repeating this process 1,000 times and adding the 1‑best beam output, yielding a 1,001‑item list for reranking.
Experiments are conducted on four language pairs: English‑Chinese, English‑Japanese, English‑German, and English‑French. Baselines include a strong attentional NMT system, a PBMT system, and an NMT system augmented with lexical translation probabilities (Arthur et al., 2016). The proposed reranking method consistently outperforms all baselines, achieving BLEU improvements of roughly 1.5–3.5 points over the strong NMT baseline. Qualitative analysis shows that the forced decoding score heavily penalizes hypotheses with over‑translation or missing content, effectively correcting many adequacy errors while preserving fluency.
In summary, the paper demonstrates that a soft forced decoding framework, which bridges the gap between phrase‑based SMT and modern NMT, can be used to compute a complementary adequacy‑focused score. When combined with NMT probabilities and applied to a diverse n‑best list, this score yields significant translation quality gains across multiple language pairs, offering a practical and language‑agnostic way to enhance NMT adequacy without sacrificing its fluency advantages.
Comments & Academic Discussion
Loading comments...
Leave a Comment