DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset
We develop a high-quality multi-turn dialog dataset, DailyDialog, which is intriguing in several aspects. The language is human-written and less noisy. The dialogues in the dataset reflect our daily communication way and cover various topics about our daily life. We also manually label the developed dataset with communication intention and emotion information. Then, we evaluate existing approaches on DailyDialog dataset and hope it benefit the research field of dialog systems.
💡 Research Summary
The paper introduces DailyDialog, a high‑quality, manually annotated multi‑turn English dialogue dataset designed to address the shortcomings of existing conversational corpora. DailyDialog consists of 13,118 dialogues collected from English‑learning websites where native speakers have written realistic, everyday conversations. After de‑duplication and automatic spell‑checking, each dialogue averages 7.9 turns and 14.6 tokens per utterance, providing a compact yet rich source of data compared with long, noisy corpora such as Switchboard or OpenSubtitles.
Two layers of annotation are provided. First, each utterance is labeled with one of four dialog‑act categories—Inform, Question, Directive, and Commissive—following ISO 24617‑2 and the scheme of Amanova et al. (2016). These categories capture information‑exchange acts (Inform, Question) and action‑oriented acts (Directive, Commissive). Second, each utterance receives an emotion label based on Ekman’s “Big Six” theory (Anger, Disgust, Fear, Happiness, Sadness, Surprise) plus an “Other” class for emotions not covered by the six basic categories. Three trained annotators achieved an inter‑annotator agreement of 78.9 % and resolved disagreements by majority voting.
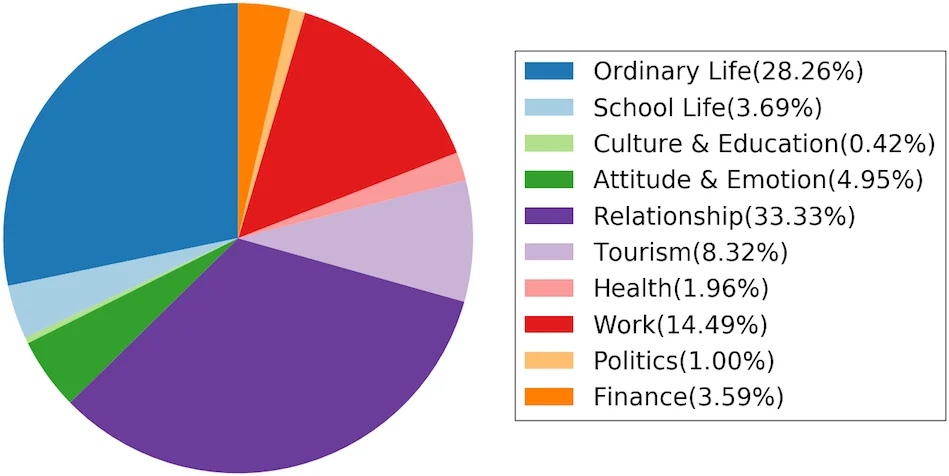
Statistical analysis shows that dialogues cover ten topical domains, with the largest being Relationship (33.33 %), Ordinary Life (28.26 %), and Work (14.49 %). The distribution of dialog acts is skewed toward Inform (45.2 %) and Question (28.6 %), but the dataset also contains substantial numbers of Directive (16.8 %) and Commissive (9.4 %) acts. Importantly, the authors identify natural bi‑turn flows such as Question‑Inform and Directive‑Commissive, as well as two more complex multi‑turn patterns: (1) a speaker often answers a question and then poses a new one (found in 18.3 % of dialogues), and (2) a sequence of proposals followed by a commitment (observed in 9.2 % of dialogues). These patterns are rarely present in single‑turn or task‑oriented corpora.
Emotion statistics reveal a strong positivity bias: Happiness accounts for 74 % of all utterances, and 28 % of dialogues end on a happy note. Only a small fraction (0.8 %) of conversations shift from an initial negative emotion to a positive conclusion, highlighting the potential for research on emotion regulation in dialogue agents.
To demonstrate the dataset’s utility, the authors evaluate five families of models on a standard split (11,118 training, 1,000 validation, 1,000 test dialogues). The baseline retrieval methods include embedding‑based cosine similarity and feature‑based similarity; enhanced retrieval incorporates dialog‑act and emotion reranking. Generation baselines consist of Seq2Seq with GRU encoders/decoders, and a conditional generation model that takes the annotated intent and emotion as additional inputs. All models use a 25 k vocabulary, 300‑dimensional Word2Vec embeddings pretrained on Google News, and are trained with Adam (learning rate 0.0002).
Results indicate that models leveraging the manual annotations outperform plain retrieval or vanilla generation in both relevance (BLEU, ROUGE) and emotional consistency (emotion‑aware metrics). In particular, the conditional generation model produces responses that better align with the intended dialog act and expressed emotion, confirming that the fine‑grained labels are valuable for controlled response generation.
In summary, DailyDialog provides a well‑curated, richly annotated resource that captures realistic daily conversational flows, a diverse set of topics, and explicit emotional content. It fills a gap between small, domain‑specific task‑oriented datasets and large, noisy open‑domain corpora, making it an ideal benchmark for research on dialog act classification, emotion detection, response retrieval, and controlled response generation. The authors anticipate that DailyDialog will spur advances in emotion‑aware conversational agents, multi‑turn dialogue management, and future extensions such as multimodal or cross‑lingual dialogue modeling.
Comments & Academic Discussion
Loading comments...
Leave a Comment