Python Non-Uniform Fast Fourier Transform (PyNUFFT): multi-dimensional non-Cartesian image reconstruction package for heterogeneous platforms and applications to MRI
This paper reports the development of a Python Non-Uniform Fast Fourier Transform (PyNUFFT) package, which accelerates non-Cartesian image reconstruction on heterogeneous platforms. Scientific computing with Python encompasses a mature and integrated…
Authors: Jyh-Miin Lin
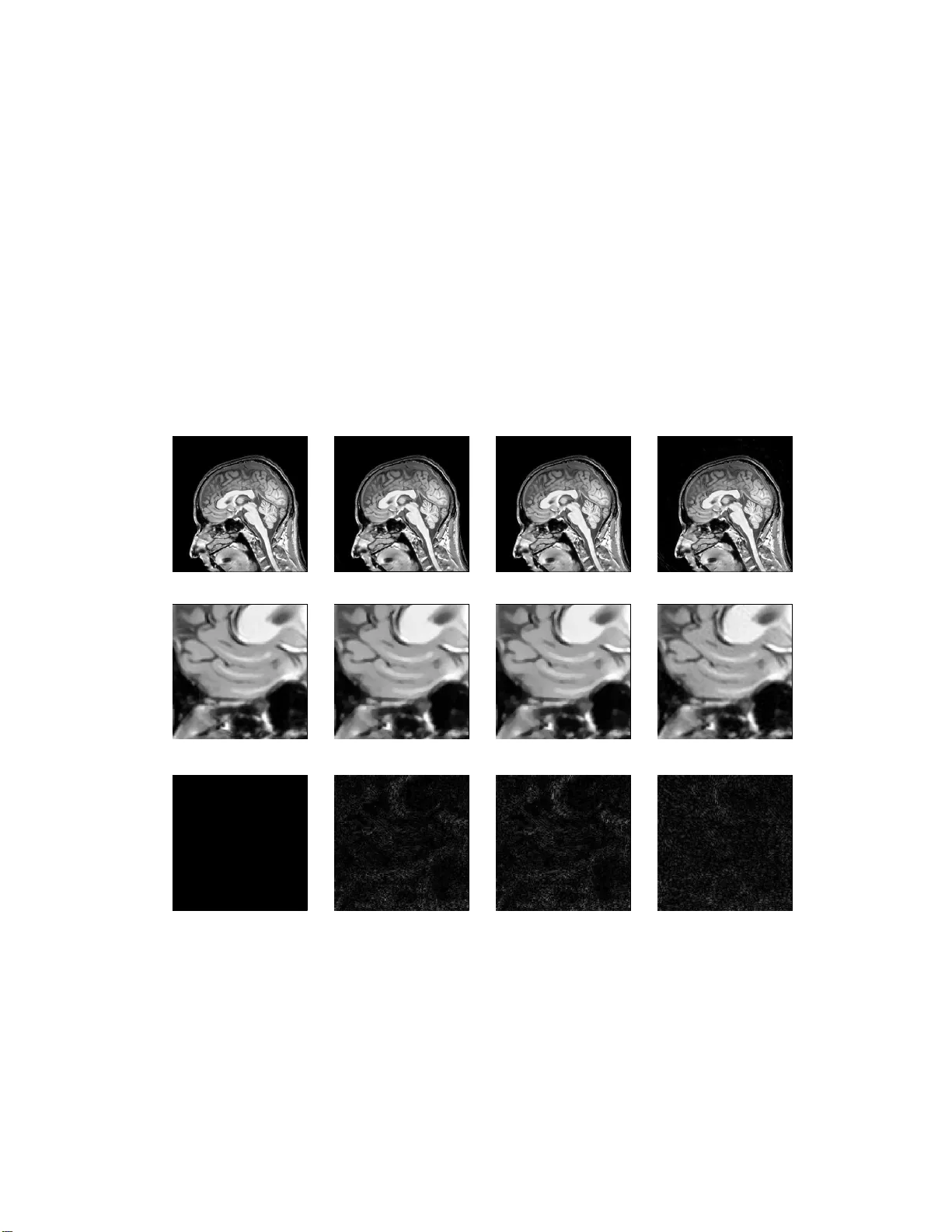
Python Non-Uniform F ast F ourier T ransform (PyNUFFT): m ulti-dimensional non-Cartesian imag e reconstruction pac k age for heterogeneous platfo rms and applications to MRI Jyh-Miin Lin a,b a Dep artment of R adiolo gy, Universi ty of Cambrid ge, Cambridge CB2 0QQ , UK jml86@c am.ac.uk b Gr aduate Institute of Biome dic al Ele ctr onics and Bioinforma tics, National T aiw an University, T aip ei, T aiwa n Abstract This pap er rep o rts the dev elopmen t of a Python Non-Uniform F a st F ourier T r ansform (PyNUFFT) pac k age, whic h accelerates non- Cartesian image re- construction on heterogeneous platfo rms. Scientific computing with Python encompasses a mature and in tegrated environme nt. The NUFFT algor ithm has b een extensiv ely used for non-Cartesian image reconstruction but previ- ously there w as no nativ e Python NUFFT library . The curren t PyNUFFT soft w are enables m ulti-dimensional NUFFT on heterogeneous platforms. The PyNUFFT als o pro vides sev eral solv ers, including the conjugate gradient metho d, ℓ 1 total-v ariation regularized ordinary least square (L1TV-OLS) and ℓ 1 total-v ariation regularized least absolute deviation (L1TV-LAD). Metapro- gramming libraries were emplo y ed to accelerate PyNUFFT. The PyNUFFT pac k ag e has b een tested on m ulti-core CPU and GPU, with acceleration fac- tors of 6.3 - 9.5 × on a 32 thread CPU platf o rm and 5.4 - 13 × o n the GPU. Keywor ds: Heterogeneous system architecture (HSA), graphic pro cessing unit (G PU), m ulti-core system, metaprogramming, ℓ 1 total v ar ia tion regularized reconstruction Pr eprint submitte d to J. Par al lel Distrib. Co mput. Octob er 10, 2017 Highligh ts • A Python no n- uniform fast F ourier transform (PyNUFFT) pack age w as dev elop ed. • Computations are accelerated on heterogeneous systems, including m ulti- core CPU and G PU. • It pro vides the accelerated nonlinear conjugate gra dien t metho d, ℓ 1 total-v ariation regularized ordinar y least square and ℓ 1 total-v ariation regularized least absolute deviation. • Pre-indexing enables m ulti-dimensional NUFFT and fast image g radi- en ts on heterogeneous platforms. • The single-precision version is dual-licensed under MIT a nd LG PL-3.0. • Applications to magnetic resonance imaging reconstruction are pre- sen ted. 2 1. Introduction F ast F ourier t r ansform ( FFT) is an exact fast algor ithm to compute dis- crete F ourier transform when data are acquired on an equispaced grid. In cer- tain image pro cessing fields, ho w ev er, t he frequency lo cations are ir regularly distributed, whic h obstructs the use of FFT. The alternative Non-Uniform F ast F ourier T ransform (NUFFT) algor ithm is a fast mapping for comput- ing non-equispace d frequency comp onen ts. Sev eral previous non-Cartesian image reconstructions are summarized in the discussion section (Section 4.1). Python is a fully-fledged and w ell-supp orted progr a mming language in data science. The imp ort a nce of Python language is manifested in the recen t surge of in terest in mac hine learning. Dev elop ers hav e increasingly relied on Python to build soft w are, taking adv an tage of its abundan t libra ries and activ e comm unity . Y et the standard Python n umerical environme nts lack a nativ e implemen tation of NUFF T pack ages, and the dev elopmen t o f an effi- cien t Python NUFFT ma y fill a g ap in the image pro cessin g field. How ev er, Python has been notorious fo r its slo w execu tion sp eed, whic h hamp ers the implemen tation of a n efficien t Python NUFFT. During the past decade, the sp eed of Python has b een greatly impro v ed b y n umerical libraries with r apid array ma nipulat io ns and v endor-prov ided p erformance libra ries. How ev er, parallel computing using multi-threading mo del cannot b e easily implemen ted in Python. This problem is mostly due to the Global In terpreter Lock (GIL) of Python in terpreter, whic h only allo w ed one core to b e used a t the same time, while the m ulti-threading capabilities of mo dern Symmetric m ultipro cessing (SMP) pro cessors cannot b e exploited. Recen tly , general purp ose graphic pro cessing unit (GPGPU) computing has enabled enormous acceleration b y offloading computat io ns to h undreds to sev eral thousands of parallel pro cessing units on GPUs. This emerging programming mo dels ma y enable one to dev elop an efficien t Python NUFFT pac k ag e, by circum v en ting the limitations of GIL. Tw o G PGPU arc hitectures are commonly used, i.e. the proprietary Compute Unified Device Architec - ture (CUDA, NVIDIA, Santa Clara, CA, USA) a nd Op en Computing Lan- guage (Op enCL, Khronos Group, Bea v erton, OR,USA). The se tw o similar arc hitectures can b e p orted to each other, or could b e dynamically generated from Python co des [1]. Th us, we ha v e dev elop ed the Python NUFFT ( PyNUFFT) pack age, whic h w as optimized f or hete rog eneous systems, including m ulti-core CPU a nd 3 GPU. The design of PyNUFFT aims to reduce the run-t ime while main- taining the readabilit y of Python program. Python NUFFT (PyNUFFT) con tains the following features: (1) algorithms written and tested for hetero- geneous platforms (including m ulti-core CPU and GPU); ( 2) pre-indexing to handle m ulti-dimensional NUFFT a nd imag e gradien t; (3) providing sev eral nonlinear solvers . 2. Material and metho ds PyNUFFT soft w are was dev elop ed o n a 64-bit Lin ux system with a quad- core CPU (Intel i7-6700HQ Pro cessor, 6M Cac he, up to 3.50 GHz) and a GPU (NVIDIA Geforce GTX 965m, 102 4 CUDA Cores at 944+ Bo ostBase Clo c k(MHz), 2G B GD DR5 memory at 25 00 MHz Memory Clo c k). The cur- ren t v ersion w as modified from the previous v ersion whic h was accelerated with CUD A [2]. The new v ersion is built on Py Op enCL, PyCUD A [1] a nd Reikna [3] licensed under dual MIT and GNU Lesser General Public License v3.0 (LGPL-3 .0) [4]. Th us, PyNUFFT may b e used in a v ariet y o f pro jects. 2.1. PyNUFFT: an NUFFT impleme ntation in Python The execution of PyNUFFT pro ceeds through three ma jor stag es: (1) scaling, (2) o v ersampled FFT, and (3) in terp olation. The three s tages can b e form ulated as t he com bination of linear op erations: A = VFS (1) where A is the NUFFT, S is the scaling, F is the FF T, and V is the inte rp o- lation. The defa ult k ernel f unction in PyNUFFT is the min-max kernel [5], whereas other k ernel functions can b e used. The design of the three-stage NUFFT algorit hm is illustrated in Figure 1 ( A). Ba tc h-mo de NUFFT can b e p erformed with serial pro cessing or parallel pro cessing. 2.1.1. Sc aling Scaling w as p erformed b y in-place m ultiplication cMultiplyV ecIn place. The complex m ulti-dimensional arra y w as offloaded to the device. 2.1.2. Oversample d FFT This stage is comp osed of tw o steps: (1) zero-padding which copies the small arra y to a larger arra y , and (2) FFT. The first step recomputed the arra y indexes on-the-flight with logical op erations, a ste p w hic h is not well 4 FFT x xx k_Kd k_Kd Sparse Matrix-V ector Multiplication Scaling y zero- padding Three-stage forward NUFFT PyNUFFT methods CPU systems S : self.x2xx() F : self.xx2k() V : self.k2y() Heterogeneous Systems S : self._x2xx(): cMultiplyV ecInplace() synchronize() F : self._xx2k(): cMultiplyScalar() cSelect() fft() synchronize() V : self._k2y(): cSparseMatV ec() synchronize() k (A) (B) S F V Figure 1: (A) A 2D example of the forward PyNUFFT (B) The methods provided in PyNUFFT. F orward NUFFT can be deco mp o sed in to three stages: scaling, FFT, a nd int erp o la tion. supp orted on GPUs. Here, a g eneralized pre-indexin g procedure w a s imple - men ted to a v oid matrix reshaping on the fligh t, a nd the cSelect subroutine copies the arra y1 to array 2 a ccording to t he pre-indexes order1 and order2. This pre-indexing av oids m ulti-dimensional matrix res haping on the flig ht, th us greatly simplifying the algorithm on G PU platforms. In addition, pre- indexing can b e generalized t o m ulti-dimensional arrays (with size N in , N out ). Once the indexes (inlist, outlist) w ere obta ined, the input array can b e rapidly copied to a larger array . No matrix reshaping will b e needed during iterations. The in v erse FFT is a lso based on t he same subroutines of the o v ersampled FFT, but it rev erses the order of computations. Th us, an IFFT is follo w ed b y ar ra y cop ying. 5 2.1.3. Interp olation While the curren t PyNUFFT includes the min- ma x interpolato r [5], ot her k ernels could also b e used. The scaling factor o f the min-max in terp olator w as designed to minimize the error of off - grid samples [5]. The inte rp olation k ernel w as stored as the Compressed Sparse Ro w matrix (CSR) format for C- order (ro w-ma jor ) array . Th us, the indexing w as accommo dated fo r C-order and the cSparseMatV ec subroutine could quick ly compute the in terp ola tion without matrix reshaping. cSparseMatV ec had b een optimized to exploit the data coalescenc e and parallel threads on the heterogeneous platforms. The w arp in CUD A (or wa v efron t in Op enCL) con trol the size of w o r kgroups in the cSparseMatV ec k ernel. Note that the indexing o f the C-ordered arr ay is differen t from the fortra n array (F- order) implemen ted in MA TLAB. Gridding is the conj ug a te tr a nsp ose of the in terp olation, whic h also uses the same cSparseMatV ec subroutine. 2.1.4. A djoin t PyNUFFT Adjoin t NUFFT reve rses the order of the forward NUFFT. Eac h stage is the conjugat e transp ose (Hermitian transp ose) of the forward NUFFT: A H = S H F H V H (2) whic h is also illustrated in F igure 2. 2.1.5. Self-adjoint NUFFT (T o eplitz) In iterative algorithms, the cost function is used to represen t data con- sistency: cost f unction : ar g min x k A x − y k 2 (3) (4) in whic h the normal equation is comp osed of in terp o la tion ( A ) a nd gridding ( A H ): nor mal eq uation : A H A x = A H y (5) Th us, precomputing the A H A can improv e the run-time efficiency[6]. See Figure 3 6 inverse FFT x xx k_Kd k_Kd Sparse Matrix-V ector Multiplication Scaling y crop Image Three-stage adjoint NUFFT PyNUFFT methods CPU systems V H : self.y2k() F H : self.k2xx() S H : self.xx2x() Heterogeneous Systems V H : self._y2k(): cSparseMatV ec() synchronize() F H : self._xx2k(): cMultiplyScalar() fft() cSelect() synchronize() S H : self._xx2x(): cMultiplyV ecInplace() synchronize() k (A) (B) S H F H V H Figure 2: (A) The adjoint PyNUFFT (B) The metho ds provided in P yNUFFT. Adjoint NUFFT can b e decomp o sed into three stages: gridding, IFFT, and r escaling. 2.2. Solver The NUFFT prov ided solv ers to restore m ulti-dimensional imag es (or 1D signals in the time-domain) from t he non-equispaced frequency samples. A great n um b er of reconstruction metho ds exist for non-Cartesian image reconstruction. These metho ds are usually categorized in to three families: (1) density comp ensation and gridding, (2) least square r egression in k - space, and (3) iterative NUFFT. 2.2.1. Density c omp ensation and gridding The sampling den sity comp ensation method generated a tap ering func- tion w (sampling densit y compensation function), whic h can b e represen ted 7 x xx k_Kd k_Kd Sparse Matrix-V ector Multiplication y Selfadjoint (T oepli tz) NUFFT PyNUFFT methods CPU systems S : self.x2xx() F : self.xx2k() V H V : self.k2y2k() F H : self.k2xx() S H : self.xx2x() Heterogeneous Systems S : self._x2xx(): cMultiplyV ecInplace() synchronize() F : self._xx2k(): cMultiplyScalar() cSelect() fft() synchronize() V H V : self._k2y2k(): cSparseMatV ec() synchronize() F H : self._xx2k(): cMultiplyScalar() fft() cSelect() synchronize() S H : self._xx2x(): cMultiplyV ecInplace() synchronize() k (A) (B) S H F H V H V S F Figure 3: (A) The self-adjoin t PyNUFFT (T o eplitz) (B) The methods are provided in PyNUFFT. The T o eplitz metho d precomputes the in terp o la tion-gridding matr ix ( V H V ), which can be accelerated on CPU and GPU. See T able 1 for measured accele ration factors . as the following stable iteratio ns [7]: w i +1 = w i AA H w i (6) Once w is prepared, the samplin g densit y comp ensation will be calculated b y: x = A H ( y · w ) (7) 2.2.2. L e ast sq uar e r e gr ession Least square regression is a solution to the inv erse problem of imag e reconstruction. Consider the fo llo wing problem: x = ar g min x k y − A x k 2 (8) 8 • Conjugate gradien t metho d (cg) : A solution to Equation (8) is the t w o-step solution: k = min k k y − V k k 2 (9) The most exp ensiv e step is to find k in Equation (9). Once k ha s b een solv ed, the in ve rse of FS can b e computed by the in v erse FF T and then divided by the scaling fa ctor: x = S − 1 F − 1 k (10) The conjugate gradien t metho d is an iterativ e solution when the sparse matrix is a symmetric Hermitian matrix: V H y = V H V k , solv e k (11) Then eac h iteration generates the residue, whic h is used to compute the next v alue. The conjugate gradien t metho d is also prov ided for heterogeneous systems. • Other iterative least square solv ers : Scip y [8] provides a v ariet y of least square solv ers, including lsmr, lsqr, bicg, bicgstab, gmres, lgmres. These solv ers w ere in tegrated in t o the CPU v ersion of PyNUFFT. 2.2.3. Iter ative NUFF T Iterativ e NUFFT r econstruction solv es the inv erse problem with v arious forms of image regula rization. Due to the larg e size of the interpola tion and FFT, iterative NUFFT is computationally exp ensiv e. Here, PyNUFFT is also optimized for iterative NUFFT reconstructions on heterogeneous sys- tems. • Pre-indexing for fast image gradien t : T otal-v ar ia tion is a basic image regularizat io n whic h has been extensiv ely used in image denos- ing a nd imag e reconstruction. Image gradien t computes the difference b et w een adjacen t pixels, whic h is represen ted as follo ws: ∇ i x = x ( ..., a i + 1 , ... ) − x ( ..., a i , ... ) (12) 9 where a i is the indexes of the i -th axis. Computing the image gra - dien t requires image rolling, follow ed b y subtracting the t w o images. Ho w ev er, multi-dimensional image rolling on heterogene ous is expen- siv e and PyNUFFT adopts the pre-indexing to sav e the run-time. This pre-indexing pro cedure generates the indexes for the rolled image, and the indexes are offloaded to heterogeneous platforms b efor e iterativ e algorithms b egin. Th us, computing the image rolling is not needed during the iterations. The adv antage of this pre-indexing pro cedure is demonstrated in Figure 4, in which preindexing mak es image gradien t run fa ster on CPU and GPU. • ℓ 1 total-v ariation regularized ordinary least square (L1TV- OLS) : The ℓ 1 to t a l-v a riation regularized reconstruction includes the piece-wise smo othing into the reconstruction mo del. x = ar g min x ( µ k y − Ax k 2 + λT V ( x )) (13) where T V ( x ) is the total-v ariation of the image: T V ( x ) = Σ |∇ x x | + |∇ y x | (14) Here, the ∇ x and ∇ y are directional gradien t op erators applied to the image domain along the x and y axes. Equation (14) is solv ed by the v ariable- splitting metho d and has previously b een dev eloped[9 , 10, 1 1]: K = µ A H A + λ ∇ T x ∇ x + λ ∇ T y ∇ y (15) The inner iterations are as follows : r hs k = µ ( A H y k ) + λ ∇ T x ( d k x − b k x ) + λ ∇ T y ( d k y − b k y ) (16) x k +1 = K − 1 r hs k (17) d k +1 x = shr ink ( ∇ x x k +1 + b k x , 1 /λ ) (18) d k +1 y = shr ink ( ∇ y x k +1 + b k y , 1 /λ ) (19) b k +1 x = b k x + ( ∇ x x k +1 − d k +1 x ) (20) b k +1 y = b k y + ( ∇ y x k +1 − d k +1 y ) (21) The outer iteration is: A H y k +1 = A H y k + A H y − A H A x k +1 (22) 10 CP U GP U P r e i n d e x i n g ( CP U) P r e i n d e x i n g ( GP U) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 E x e c u t i o n t i m e s ( m s) Figure 4: Preindexing fo r fast image gr adient ( ∇ and ∇ T ). Image gradie nt ca n b e slow if the indexes ar e to b e calculated with ea ch iteration. Pr eindexing can sav e the time needed for r e calculation and image gr adient dur ing itera tions. • ℓ 1 total-v ariation regularized least absolute deviation (L1TV- LAD) : Least a bsolute deviation (LAD) is a statistical regression mo del whic h is robust to non-stationar y noise distribution [1 2]. It is p o ssible to solv e the ℓ 1 total-v ariation regularized problem with the LAD cost 11 function [1 3]: x = ar g min x ( µ k y − Ax k 1 + λT V ( x )) (23) where T V ( x ) is the total-v ariation of the image. Note that LAD is the ℓ 1 norm of the data consistency . Here, a v ariable- splitting metho d is describ ed. K = µ A H A + λ ∇ T x ∇ x + λ ∇ T y ∇ y (24) The inner iterations of ℓ 1-LAD are as follows: r hs k = µ ( A H y k + d k f − b k f ) + λ ∇ T x ( d k x − b k x ) + λ ∇ T y ( d k y − b k y ) (25) x k +1 = K − 1 r hs k (26) d k +1 x = shr ink ( ∇ x x k +1 + b k x , 1 /λ ) (27) d k +1 y = shr ink ( ∇ y x k +1 + b k y , 1 /λ ) (28) d k +1 f = shr ink ( A H A x k +1 − A H y + b k y , 1 /µ ) (29) b k +1 x = b k x + ( ∇ x x k +1 − d k +1 x ) (30) b k +1 y = b k y + ( ∇ y x k +1 − d k +1 y ) (31) b k +1 f = b k f + ( A H A x k +1 − A H y − d k +1 f ) (32) The outer iteration is: A H y k +1 = A H y k + A H y − A H A x k +1 (33) Note that Equation (29) is a shrink age function, whic h is quic kly solv ed on CPU as w ell as on heterogeneous sy stems. • Multi-coil regularized image reconstruction : In m ulti-coil regu- larized image reconstruction, t he selfadjoin t NUFFT in Equation (5) is extended to m ulti-c hannel data: A H multi A multi x = N c X i A H i A i x (34) = N c X i conj ( c i ) · A H A · c i · x (35) where coil-sensitivities ( c i ) of m ultiple c hannels multiply each channel b efore the NUFFT ( A ) a nd after the a dj oin t NUFF T ( A H ). 12 2.3. Applic a tions to br ain MRI A 3T brain MRI template [14] w as used t o sim ulate the non-Cartesian MRI acquisition. The image was resized to 51 2 × 512 and the non-Cartesian k -space [15] was used to simu late t he data. 2.4. Benchmarks PyNUFFT w as tes ted on a multi-core CPU cluster and a GPU instance of the cloud-based Lin ux w eb services. All the computations w ere completed with single float (FP32) complex n um b ers. The configuration of CPU a nd GPU systems w ere as f o llo ws. • Multi-core CPU : The CPU instance (m4.16xlarge, Amazon W eb Ser- vices) is equipp ed with 64 vCPUs (In tel E5 2 686 v4) and 61 G B of memory . The num b er of vCPUs can b e dynamically con t r olled b y the CPU hotplug functionalit y of the Linux system, a nd computations are offloaded to the In tel O p enCL CPU device with 1 to 64 threads. PyNUFFT w as executed on the m ulti- core CPU instance with 1 - 64 threads. The PyNUFFT transforms w ere offloaded to the Op enCL CPU device and w ere execu ted 20 time s. The times required for the transforms a re compared with the run times on the single thr ead CPU. Iterativ e reconstructions we re also teste d on the m ulti-core CPU. W e measured the execution times o f the conjugate gradient metho d, ℓ 1 total-v ariation regularized reconstruction and the ℓ 1 total- v ar ia tion reg- ularized LAD on the multi-core system. • GPU : The GPU instance (p2.xlarge, Amazon W eb Services) is equipp ed with 4 vCPUs (Intel E5 2686 v4) and one T esla K80 (NVIDIA, Santa Clara, CA, USA) with tw o G K210 GPUs. Each GPU is comp osed of 2496 parallel pro cessing cores and 12 G B of m emory . Computations are compiled and offlo a ded to one GPU b y CUDA and Op enCL APIs. T r ansformations w ere rep eated 20 times to measure the a v eraged run times. Iterativ e reconstructions w ere a lso tested on the K80 GPU, and the execution t imes of conjugate gra dient metho d, ℓ 1 total- v aria tion regularized reconstruction and ℓ 1 total-v ariation regularized LAD on the multi-core system w ere compared with iterativ e solv ers on the CPU with one thread. 13 3. Results 3.1. Applic a tions to br ain MRI This w ork fo cuses on accelerating the PyNUFFT pac k age on heteroge- neous platfo r ms, and the complete image qualit y assessmen t w a s not carried out in this pap er. Some v isual results of MRI reconstructions can b e seen in Figure 5. Iterativ e NUFFT using L1TV-OLS and L1 TV-LAD result in few er ripples in the brain structure tha n the sampling densit y comp ensation metho d. Tr u e Image L1 TV- LA D L1TV -OLS Sam p l i n g d e n si t y c o m p e n s a t i o n Figure 5: Simulated r esults of brain MRI. The brain template w as reconstructed with t wo iterative NUFFT alg orithms (L1TV-OLS and L1TV-L AD) and the sampling densit y comp ensation m etho d. Compared with sampling density comp ensation method, fewer ripples ca n b e seen in L1TV-OLS and L1TV-LAD. 14 T able 1: Run time (a nd a cceleration) o f subroutines and solvers Op erations 1 vCPU 32 vCPUs PyOp enCL K8 0 PyCUD A K80 Scaling( S ) 709 µ s 557 µ s (1.3 × ) 133 µ s (5.3 × ) 300 µ s (2.4 × ) FFT( F ) 12.6ms 2.03 ms (6.2 × ) 0.78 ms (16.2 × ) 1.12 ms (11.3 × ) In terp olation( V ) 25 ms 2 ms (12 × ) 4 ms(6 × ) 4 ms (6 × ) Gridding( V H ) 24 ms 2 ms (12 × ) 5 ms (4.8 × ) 4.5 ms (5.4 × ) IFFT( F H ) 16 ms 3.1 ms (5.16 × ) 4.0 ms (4 × ) 3.5 (4.6 × ) Rescaling ( S H ) 566 µ s 595 µ s (0.95 × ) 122 µ s (4.64 × ) 283 µ s (2 × ) V H V 4.79 ms 2.62 ms (1.83 × ) 0.18 ms (26 × ) 0.15 ms (31 × ) F orw ard ( A ) 39 ms 5 ms (7.8 × ) 6 ms (6.5 × ) 6 ms ( 6 .5 × ) Adjoin t ( A H ) 38 ms 6 ms (6.3 × ) 7 ms (5.4 × ) 6 ms ( 6 .3 × ) Selfadjoin t ( A H A ) 34.7 ms 11 ms (3.15 × ) 9 ms (3.86 × ) 8 ms (4.34 × ) Solv ers 1 vCPU 32 vCPUs PyOp enCL K80 PyCUD A K80 Conjugate gradient 11.8 s 2.9 7 s (4 × ) 1.32 s (8.9 × ) 1.89 s (6.3 × ) L1TV-OLS 14.7 s 3.26 s (4.5 × ) 1.79 s (8.2 × ) 1.68 s (8.7 × ) L1TV-LAD 15.1 s 3.6 2 s (4.2 × ) 1.93 s (7.8 × ) 1.78 s (8.5 × ) 3.2. Benchmarks • Multi-core CPU : T able 1 listed the detailed run-times of the differ- en t stages of for ward NUFFT, adjoint NUFFT, and selfadjoin t NUFFT (T oeplitz). The o v erall execution sp eed of PyNUFFT w as faster on the m ulti-core CPU platform than single thread CPU. Y et the accelera- tion factors of eac h stage v aried from 0.95 ( no acceleration) to 15.6. Compared w ith computations on single thread, 32 threads accelerate in terp olation and gridding b y a factor of 12, and the FFT and IFFT w ere accelerated by a factor of 6.2 - 15.6. The b enefits of 32 threads are limited fo r certain computations, in- cluding scaling, rescaling and interpolation- gridding ( V H V )). In t hese computations, the acceleration factors of 32 threads r a nge from 0.95 to 1.85. This limited p erfo rmance gain is due to the high efficiency of sin- gle thread CPU, whic h is already fast enough and lea ve s limited r o om for impro v emen t. In particular, the in t egr a ted in terp olation- g ridding ( V H V ) is already 10 times f a ster than the sep ara t e in terp ola t ion a nd regridding sequence . On a single-thread CPU, V H V requires only 4.79 ms, whereas the separate interpola t io n ( V ) and gridding ( V H ) require 49 ms. In this case, 32 threads deliv er only an extra 83% of p erformance 15 to V H V . Figure 6 illustrates the acceleration on the multi-core CPU a gainst the single thread CPU. The p erformance of PyNUFFT improv ed by a factor o f 5 - 10 when the n um b er of threads increases fro m 1 to 20, and the softw are ac hiev es p eak performance with 30 - 32 threads (equiv alen t to 15 - 16 phys ical CPU cores). More t ha n 32 threads bring no substan tial b enefits in p erfor mance. F orw ard NUFFT, adjoin t NUFFT and selfadjoin t NUFFT (T o eplitz) are accelerated on 32 threads with an acc eleration f actor of 7.8 - 9.5. The acceleration fa ctors of iterative solv ers (conjugate gradien t metho d, ℓ 1 total-v a r iation regularized least square (L1TV-OLS) and ℓ 1 total- v ariat io n regularized least a bsolute deviation (L1TV-LAD)) a re fro m 4.2 - 5. • GPU : T a ble 1 sho ws that GPU deliv ers a generally faster PyNUFFT trans- form, with the a cceleration factors ranging from 2 to 31. Scaling and rescaling ha v e led to a mo derate degree of acceleration. The most significant acceleration occurs in the in terp ola tion-gridding ( V H V ) in whic h G PU is 26 - 31 times faster than single-thread CP U. This significan t acceleration is faster than the acceleration factors for separate interpolatio n ( V , with 6 × acceleration) and gridding ( V H with 4 - 4.6 × acceleration). F orw ard NUFFT, adjoin t NUFFT and selfadjoin t NUFFT (T o eplitz) are accelerated on K8 0 GPU b y 5.4 - 13. Iterativ e solv ers on GPU are 6.3 - 8.9 f aster t ha n single-thread, and ab out 2 × faster than 32 threads. 4. Discussion 4.1. R elate d w ork Differen t k ernel functions (in terp o la tors) a re a v ailable in previous NUFFT implemen tations, including: (1)the min-max in terp oalto r [5], (2) the fast ra- dial basis functions [16, 17], (3)least square in terp olator [18], (4)least mean- square error in terp olato [19], (5) fast Gaussian summation [20], (6) Kaiser- Bessel function [21], (7) linear system transfer function or in v erse reconstruc- tion [22, 23]. 16 The NUFFTs ha v e b een implemen ted in differen t programming languages: (1) Matlab (Math w orks Inc, MA, USA)[5, 19, 2 1, 24]; (2) C++ [25]; (3) CUD A [21, 25]; (4) F ortran [20]; (5) O p enA CC using PGI compiler (PGI Compilers & T oo ls) [26 ]. NUFFT has b een accelerated on single and m ultiple GPUs. F ast itera- tiv e NUFFT using the Ka iser-Bessel function w a s accelerated on G PU with total-v ariation regularization [25] and generalized tota l- v ar ia tion regulariza- tion [21]. A real-time inv erse r econstruction is dev elop ed in Sebastinan et al. [27] and Murphy et al. [28], but this inv erse reconstruction do es not p erform the full interpolatio n a nd gridding during iteratio ns. The paten t of Nadar et al.[29] describ es a custom m ulti-GPU buffer to improv e the mem- ory access for image reconstruction with no n-uniform k -space. An mripy pac k ag e applies the Numb a compiler in its NUFFT with Gaussian k ernel (h ttps://github.c om/p eng-cao/mrip y). Other than NUFFT, iterative discrete F ourier transform (DF T) is slo w er than NUFFT, and GPUs can bring enormous acceleration factors to iterativ e reconstruction [30, 31 ]. Still, iterativ e DF Ts on GPUs ma y be slo w er than iterativ e NUFFTs o n GPUs. 4.2. Discussions of PyNUFFT The NUFF T tra nsforms (forw ard, adjoin t, and T o eplitz) ha v e b een ac- celerated on m ulti-core CPU and G PU. In particular, the b enefits of fast iterativ e solv ers (including least square a nd iterative NUFF T) hav e b een sho wn in the results of b enc hmarks. The image reconstruction times (with 100 iterations) for one 256 × 256 image are less than 4 seconds on a 3 2 thread CPU platform and less than 2 seconds on the GPU platfor m. The curren t PyNUFFT has b een tested with computat ions using the single-precision float ing num b ers (FP32). Ho w ev er, the num ber o f FP64 units on GPU is only a fraction of the n um b er o f FP32 units, which will re duce the performance with FP64 and slo w down the p erformance of PyNUFFT (with 1/ 3 of the FP32 p erformance). 4.3. Conclusion An op en-source PyNUFFT pack age can accelerate non-Cartesian imag e reconstruction on multi-core CPU and GPU pla t f orms. The acceleration factors are 6.3 - 9.5 × on a 3 2 thread CPU platfor m and 5.4 - 1 3 × on a T es la K80 GPU. The iterativ e solv ers with 100 iterations can b e completed within 4 seconds on the 32 thread CPU platform and 2 seconds on the GPU. 17 5. Ackno wledgemen ts The w ork w as supported by the Ministry of Science and T ec hnology (MOST) T aiw an, partly b y the Camb ridge Common w ealth, Europ ean and In ternational T rust (Cam bridge, UK), as w ell as the Ministry of Education, T a iw an. The b enc hmarks w ere carr ied out on Amazon W eb Services provided b y A WS Educate credit. J.-M. Lin declares no conflict o f inte rest. 6. References References [1] A. Kl¨ oc kner, N. Pin to, Y. Lee, B. Cata nzaro, P . Iv ano v, A. F asih, Py - CUD A and PyOp enCL: A scripting-ba sed approac h to GPU run- t ime co de generation, Parallel Computing 38 (3) (20 12) 15 7–174. [2] J.-M. Lin, H.-W. Ch ung, PyNUFFT: p ython non-uniform fast F ourier transform for MRI, in: Building Bridges in Medical Sciences 2017, St John’s College, Camb ridge CB2 1TP , UK, 2017. [3] B. Opanc h uk, Reikna, a pure Python GPGPU library , h ttp://reikna.publicfields.net/, Acce ssed: 2017-10 - 09. URL http://reikna.public fields.net/ [4] F ree Softw are F oundation, GNU General Public License. URL http://www.gnu.org/l icenses/gpl.html [5] J. F essler, B. P . Sutton, Nonuniform fast F ourier transforms using min- max inte rp olation, IEEE T ra nsactions on Signal Pro cessing 51 (2) (2 003) 560–574. [6] J. F essler, S. Lee, V. T. Olaf sson, H. R. Shi, D . C. Noll, T o eplitz-based iterativ e image reconstruction for MRI with correction fo r magnetic field inhomogeneit y , IEEE T r a nsactions on Signal Pro cessing 53 (9) (2005) 3393–340 2. [7] J. G. Pip e, P . Menon, Sampling densit y comp ensation in MRI: Ratio nale and a n iterative n umerical solution, Magnetic Resonance in Medicine 41 (1) (19 99) 179–18 6. 18 [8] E. Jones, T. Oliphan t, P . P eterson, et al., SciPy: Op en source scien tific to ols for Python (2001– ). URL http://www.scipy.org / [9] J.-M. Lin, A. J. P atterson, H.-C. Chang, T.-C. Ch uang, H.- W. Ch ung, M. J. Gr av es, Whitening o f colored no ise in PR OPELLER using iterative regularized PICO reconstruction, in: Pro ceedings of the 23rd Ann ual Meeting of In ternational So ciet y for Magnetic Res onance in Medicine, T o ron to, Canada, 2015, p. 3738 . [10] J.-M. Lin, A. J. P atterson, C.-W. Lee, Y.-F. Chen, T. Das, D. Scoff- ings, H.-W. Ch ung, J. Gillard, M. Gra v es, Impro v ed iden tification and clinical utilit y of pseudo-in v erse with constrain ts (PICO) reconstruction for PR OPELLER MRI, in: Pro ceedings of the 24t h Ann ual Meeting of In ternational So ciet y for Magnetic Res onance in Medicine, Singap ore, 2016, p. 177 3. [11] J.-M. Lin, S.- Y. Tsai, H.-C. Chang, H.-W. Ch ung, H. C. Chen, Y.-H. Lin, C.-W. Lee, Y.- F . Chen, D . Scoffings, T. Das, J. H. Gillard, A. J. P atterson, M. J. Grav es, Pseudo-in v erse constrained (PICO) reconstruc- tion reduces colored noise of PR OPELLER and impro v es the gr ay-white matter differen t iation, in: Pro ceedings of the 25th Ann ual Meeting of In ternational So ciety for Magnetic Resonance in Medicine, Honolulu, HI, USA, 2017, p. 1524. [12] L. W ang , The p enalized LAD estimator for high dimensional linear regression, Journal of Multiv ar ia te Analysis 120 (2013 ) 135 – 15 1. doi:http:// doi.org/10.1016/j.jmva.2013.04.001 . [13] J.-M. Lin, H.-C. Chang, T.-C. Chao, S.- Y. Tsai, A. P atterson, H.- W. Ch ung, J. Gillard, M. G ra v es, L1-L AD: Iterative MRI reconstruc- tion using L1 constrained le ast a bsolute deviation, in: Europ ean So ci- et y for Magnetic Resonance in Medicine a nd Biolo gy (ESMRMB) 2017 Congress, 20 17. [14] F. Lalys, C. Haegelen, J.- C. F erre, O. El-Ga na oui, P . Jannin, Construc- tion and asses smen t of a 3-T MRI brain template, Neuroimage 49 (1) (2010) 345–354. 19 [15] J.-M. Lin, A. J. P atterson, H.-C. Chang, J. H. Gillard, M. J. Grav es, An iterativ e reduced field-of-view reconstruction for perio dically rotated o v erlapping parallel lines with enhanced reconstruction PROPE LLER MRI, Medical Ph ysics 42 (10) (2 015) 5 757–576 7 . [16] D. P otts, G . Steidl, F ast summation a t nonequispaced knots b y NFFTs., SIAM Jo urnal on Science Computing 24 (20 04) 2013–2 037. [17] J. Keiner, S. Kunis, D . P otts, Using NF FT 3 — a softw are library f or v arious nonequispaced fast Fourier transforms, A CM T ransactions on Mathematical Soft ware ( TOMS) 36 (4) (2009) 19. [18] J. Song, Y. Liu, S. L. Gewalt, G. Cofer, G. A. Johnson, Q. H. Liu, Least-square NUFFT metho ds applied t o 2-D and 3- D radially enco ded MR image reconstruction, IEEE T ransactions on Biomedic al Engineer- ing 5 6 (4) (2009) 1134–11 42. [19] Z. Y ang, M. Jacob, Mean square optimal NUF F T appro ximation for effi- cien t non-Cartesian MRI reconstruction, Journal of Magnetic Resonance 242 (20 14) 12 6–135. [20] L. G r eengard, J.-Y. Lee, Accelerating the non uniform fast Fourier trans- form, SIAM review 46 (3) (2 0 04) 443–4 5 4. [21] F. Knoll, A. Sc hw arzl, C. S. D . Diwoky , gpuNUFFT An op en-source GPU library for 3D gridding with direct Matlab Interface., in: Pro c ISMRM, 2 014, p. 4297. [22] C. Liu, M. Moseley , R. Bammer, F ast SENSE reconstruction using linear system transfer function., in: Pro ceedings of the In ternational So ciet y of Magnetic Resonance in Medicine, 2 0 05, p. 689. [23] M. Uec k er, S. Z hang, J. F rahm, Nonlinear inv erse reconstruction for real-time MRI of the hum an heart using undersampled radial FLASH, Magnetic Resonance in Medicine 63 (6 ) (201 0 ) 1456 –1462. [24] M. F errara, Implemen ts 1D-3D NUFFTs via fast Gaussian gridding., matlab Cen tral, h ttp://www.math w orks.com/matlab cen tral/fileexchange/25135-n ufft– nfft–usfft ( 2 009). 20 [25] K. Bredies, F . Knoll, M. F reib erger, H. Sc harfetter, R. Stollb erger, The agile library for biome dical imag e recons truction using GPU a ccelera- tion, Computing in Science and Engineering 15 (2013 ) 34–44 . [26] A. Cerjanic, J. L. Ho ltrop, G. C. Ngo, B. Leback , G. Arnold, M. V. Mo er, G. L a Belle, J. A. F essler, B. P . Sutton, Po w erGrid: A open source libr a ry for accelerated iterativ e mag netic resonance image reconstruction, in: Pro c ISMRM, 2016, p. 525. [27] S. Schaetz , D. V oit, J. F rahm, M. Uec k er, Acce lerated computing in magnetic r esonance imaging: Real-time imaging using non-linear inv erse reconstruction, CoRR. URL http://arxiv.org/abs /1701.08361 [28] M. Murph y , M. Alley , J. Demmel, K. Keutzer, S. V asana w ala, M. Lustig, F ast-SPIRiT compressed sensing pa rallel imaging MRI: Scalable parallel implemen tation and clinically feasible run time, IEEE T ransactions on Medical Imag ing 31 (6) (2012) 125 0 –1262. [29] M. S. Na da r, S. Martin, A. Lefeb vre, J. Liu, Multi-GPU FIST A imple- men tation for MR reconstruction with non- unifo rm k-space sampling, uS Paten t App. 14/031 ,3 74 (2013). [30] S. S. Stone, J. P . Haldar, S. C. Tsao, W.-m. W. Hwu, Z.-P . Liang, B. P . Sutton, Accelerating a dv anced MRI reconstructions on G PUs, in: Pro ceedings of the 5th Conference on Computing F ron- tiers, CF ’08, AC M, New Y ork, NY, USA, 20 0 8, pp. 261–272. doi:10.1145 /1366230.1366276 . URL http://doi.acm.org/1 0.1145/1366230.1366276 [31] J. Gai, N. Ob eid, J. L. Holtrop, X.-L. W u, F. Lam, M. F u, J. P . Hal- dar, W. H. W en-mei, Z.-P . Liang, B. P . Sutton, More IMP A TIENT: A gridding- accelerated To eplitz-based strategy for non-Cartesian high- resolution 3D MRI o n GPUs, Journal of Parallel and Distributed Com- puting 7 3 (5) (2013) 686–697 . 21 0 2 4 6 N u m b e r o f v CP U s ( 2 x Cor e s) 2 4 6 8 Ac c e l e r a t i o n f a c t o r F o r w a r d N UFF T 0 2 0 4 0 6 0 Nu m b e r o f v CP Us ( 2 x Co r e s ) 2 4 6 8 1 0 Ac c e l e r a t i o n f a c t o r Ad j o i n t N UFF T 0 2 0 4 0 6 0 Nu m b e r o f v CP Us ( 2 x Co r e s ) 2 4 6 8 1 0 Ac c e l e r a t i o n f a c t o r S e l f a d j o i n t NU F FT( To e p l i t z) 0 2 0 4 0 6 0 Nu m b e r o f v CP Us ( 2 x Co r e s ) 1 2 3 4 Ac c e l e r a t i o n f a c t o r Co n j u g a t e g r a d i e n t m e t h o d 0 2 0 4 0 6 0 Nu m b e r o f v CP Us ( 2 x Co r e s ) 1 2 3 4 Ac c e l e r a t i o n f a c t o r L1 t o t a l v a r i a t i o n 0 2 0 4 0 6 0 Nu m b e r o f v CP Us ( 2 x Co r e s ) 1 2 3 4 Ac c e l e r a t i o n f a c t o r L1 t o t a l v a r i a t i o n LA D Figure 6: Acceleratio n factors aga inst the num b er of threa ds (vCPUs for Amazo n W eb Services). The optimal pe rformance o ccurs ar ound 30 - 32 threads. There is no substantial bene fits for more than 32 threa ds. 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment