Learning a Predictive Model for Music Using PULSE
Predictive models for music are studied by researchers of algorithmic composition, the cognitive sciences and machine learning. They serve as base models for composition, can simulate human prediction and provide a multidisciplinary application domai…
Authors: Jonas Langhabel
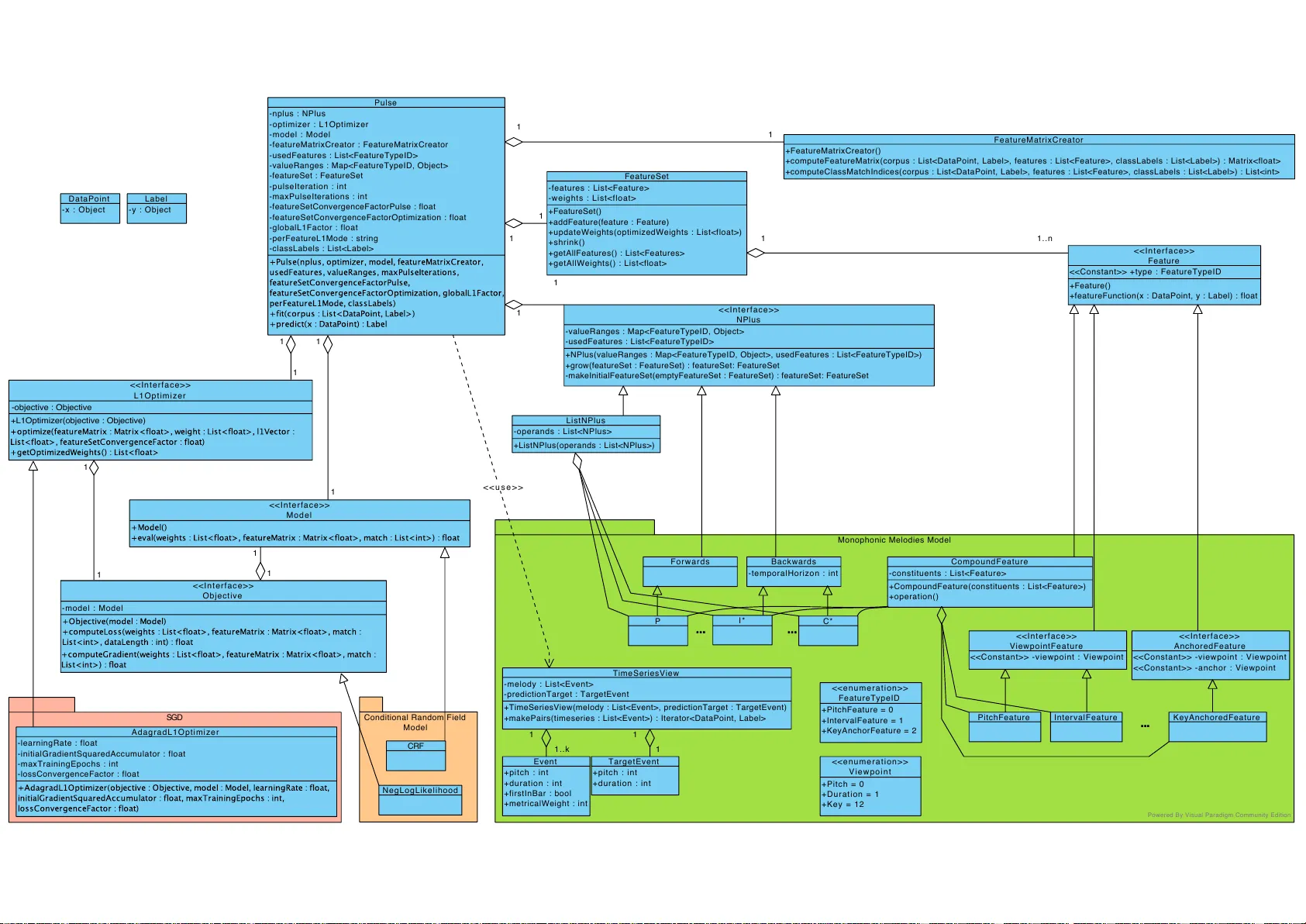
Learning a Predictive Model for Music Using P ULSE Master Thesis in Computer Science by Jonas Langhabel September 2017 supervised by Robert Lieck Machine Learning and Robotics Lab, University of Stuttgart Systematic Musicology and Music Cognition, TU Dresden Prof. Dr . Klaus-Robert Müller Machine Learning Group, TU Berlin reviewed by Prof. Dr . Klaus-Robert Müller Machine Learning Group, TU Berlin Prof. Dr . Marc T oussaint Machine Learning and Robotics Lab, University of Stuttgart Statement in Lieu of an Oath I hereby confirm that I have written this thesis on my own without illegitimate help and that I have not used any other media or materials than the ones r eferred to in this thesis. Eidesstattliche Erklärung Hiermit erkläre ich, dass ich die vorliegende Arbeit selbstständig und eigenhändig sowie ohne unerlaubte fremde Hilfe und ausschließlich unter V erwendung der aufgeführten Quellen und Hilfsmittel angefertigt habe. Berlin, (Date/Datum) (Signature/Unterschrift) Acknowledgements First and foremost, I would like to express my gratitude to Robert Lieck who provided me with this intriguing topic, put an extraor dinary amount of time in my supervision, and was a gr eat teacher to me. I would further like to thank Pr of. Dr . Klaus-Robert Müller and Prof. Dr . Marc T oussaint for their supervision and support of this thesis. Special thanks go to Prof. Dr . Martin Rohrmeier for his musicological mentoring, for the invitations to his chair for Systematic Musicology and Music Cognition at TU Dresden, and for his patr onage of our research paper about my work. I am grateful to my reviewers Deborah Fletcher , Christian Gerhorst, Jannik W olff, and Malte Schwarzer for their valuable comments. Finally , I would like to thank my wife for her support that allowed me to put all my focus on this thesis, and my daughter for making my breaks worthwhile. Abstract Predictive models for music ar e studied by resear chers of algorithmic composition, the cognitive sciences and machine learning. They serve as base models for compo- sition, can simulate human pr ediction and provide a multidisciplinary application domain for learning algorithms. A particularly well established and constantly advanced subtask is the prediction of monophonic melodies. As melodies typically involve non-Markovian dependencies their prediction r equires a capable learning algorithm. In this thesis, I apply the recent feature discovery and learning method P ULSE to the realm of symbolic music modeling. P ULSE is comprised of a feature generating operation and L 1 -regularized optimization. These ar e used to iteratively expand and cull the featur e set, ef fectively exploring featur e spaces that ar e too lar ge for common feature selection appr oaches. I design a general Python framework for P ULSE , pro- pose task-optimized feature generating operations and various music-theor etically motivated features that ar e evaluated on a standard corpus of monophonic folk and chorale melodies. The pr oposed method significantly outperforms comparable state- of-the-art models. I further discuss the free parameters of the learning algorithm and analyze the feature composition of the learned models. The models learned by P ULSE afford an easy inspection and ar e musicologically interpr eted for the first time. Zusammenfassung Prädiktive Modelle für Musik sind Gegenstand der Forschung in den Feldern der algorithmischen Komposition, der Kognitionswissenschaft und des maschinellen Lernens. Die Modelle liefern eine Basis zum Komponieren, sie können menschli- ches V er halten vor hersagen und sie bieten eine interdisziplinäre Anwendung für Lernalgorithmen. Ein aussergewöhnlich beliebter und ständig vorangetriebener T eil- bereich des prädiktiven Modellier ens ist die V orhersage von monophonen Melodien. Da Melodien typischerweise nicht-Markovsche Abhängigkeiten mit sich bringen, erfordert ihr e Prädiktion besonders leistungsfähige Lernalgorithmen. In dieser Thesis wende ich die kürzlich entwickelte P ULSE Methode an, um symbolische Musik zu modellieren. P ULSE ist eine Methode zum Aufspüren und Lernen der geeignetsten Merkmale. Dazu werden abwechselnd neue Merkmale generiert und die global Besten mithilfe von L 1 -regularisierter Optimierung aus- gewählt. Dadurch können Merkmalsräume durchsucht werden, die zu groß für gängige Merkmal-Auswahlverfahren sind. Ich entwerfe ein Python Framework für die P ULSE Methode und geeignete generier ende Operationen für die Erzeugung von Merkmalen für Melodien sowie zahlr eiche musiktheoretisch motivierte Merkmals- typen. Die erlernten Modelle werden auf einem etablierten Korpus monophoner V olksmusik und monophoner Choräle evaluiert; die vorgestellte Methode übertrifft deutlich die besten vergleichbar en Modelle. W eiter hin diskutier e ich die fr eien Pa- rameter des Lernalgorithmus und analysier e die Merkmal-Zusammensetzung der gelernten Modelle. Die mit P ULSE gelernten Modelle sind einfach inspizierbar und werden zum ersten Mal musikwissenschaftlich interpr etiert. Contents 1 Introduction 10 1.1 About Music Modeling . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 1.2 Approach . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 1.3 Contribution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 1.4 Thesis Structur e . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 2 Background and Related W ork 14 2.1 Predictive Models for Music . . . . . . . . . . . . . . . . . . . . . . . . 14 2.1.1 Long-T erm and Short-T erm Models . . . . . . . . . . . . . . . 14 2.1.2 Ensemble Methods . . . . . . . . . . . . . . . . . . . . . . . . . 15 2.1.3 n -gram Models . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 2.1.4 Connectionist Approaches . . . . . . . . . . . . . . . . . . . . . 20 2.2 P ULSE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22 2.2.1 The Conditional Random Field Model . . . . . . . . . . . . . . 23 2.2.2 The Objective . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24 2.2.3 The N + Operation . . . . . . . . . . . . . . . . . . . . . . . . . 24 2.3 Stochastic Gradient Descent . . . . . . . . . . . . . . . . . . . . . . . . 25 2.3.1 AdaGrad . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 2.3.2 AdaDelta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 2.3.3 L 1 Regularization in SGD T raining . . . . . . . . . . . . . . . . 26 3 PyPulse : A Python Framework for P ULSE 29 3.1 Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 3.1.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 3.1.2 Module Descriptions . . . . . . . . . . . . . . . . . . . . . . . . 30 6 Contents 7 3.2 Implementation Details . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 3.2.1 Implementing L 1 -Regularized Optimization . . . . . . . . . . 31 3.2.2 V ectorizing Cumulative Penalty L 1 Regularization . . . . . . 32 3.2.3 Adding a Learning Rate to AdaDelta . . . . . . . . . . . . . . 33 3.2.4 Hot-Starting the Optimizer . . . . . . . . . . . . . . . . . . . . 33 3.2.5 Convergence Criteria . . . . . . . . . . . . . . . . . . . . . . . . 33 3.2.6 The Feature Matrix . . . . . . . . . . . . . . . . . . . . . . . . . 35 3.2.7 Computation of the CRF . . . . . . . . . . . . . . . . . . . . . . 35 3.2.8 N + Postprocessing . . . . . . . . . . . . . . . . . . . . . . . . . 36 4 PyPulse for Music 37 4.1 T ime Series Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37 4.2 T emporally Extended Featur es . . . . . . . . . . . . . . . . . . . . . . 38 4.2.1 V iewpoint Features . . . . . . . . . . . . . . . . . . . . . . . . . 39 4.2.2 Anchored Featur es . . . . . . . . . . . . . . . . . . . . . . . . . 41 4.2.3 Linked Features . . . . . . . . . . . . . . . . . . . . . . . . . . . 43 4.3 N + Operations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43 4.3.1 Long-T erm Model . . . . . . . . . . . . . . . . . . . . . . . . . 45 4.3.2 Short-T erm Model . . . . . . . . . . . . . . . . . . . . . . . . . 46 4.4 Regularization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47 4.5 Inference . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49 5 Model Selection 50 5.1 Methodology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50 5.1.1 Corpus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50 5.1.2 Evaluation Measures . . . . . . . . . . . . . . . . . . . . . . . . 52 5.1.3 Gaussian Process Based Optimization . . . . . . . . . . . . . . 53 5.1.4 Cross-V alidation . . . . . . . . . . . . . . . . . . . . . . . . . . 54 5.2 Reducing Computational Expenses . . . . . . . . . . . . . . . . . . . . 55 5.2.1 T uning and Comparing AdaGrad and AdaDelta . . . . . . . . 55 5.2.2 Detecting Convergence . . . . . . . . . . . . . . . . . . . . . . 58 5.2.3 Hot-Starting AdaGrad . . . . . . . . . . . . . . . . . . . . . . . 59 5.3 Reducing Overfitting . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61 Contents 8 5.3.1 L TM Regularization T erms . . . . . . . . . . . . . . . . . . . . 62 5.3.2 STM Regularization T erms . . . . . . . . . . . . . . . . . . . . 63 5.4 Comparing N + Operators and Feature Combinations . . . . . . . . . 66 5.4.1 L TM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67 5.4.2 STM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69 5.5 Comparison of Hybrid Models . . . . . . . . . . . . . . . . . . . . . . 71 5.5.1 L TM+STM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72 5.5.2 L TM+L TM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73 6 Evaluation 75 6.1 Literature Comparison . . . . . . . . . . . . . . . . . . . . . . . . . . . 75 6.1.1 Comparison with State-of-the-Art Methods . . . . . . . . . . . 75 6.1.2 Comparison with n -gram MVS . . . . . . . . . . . . . . . . . . 77 6.1.3 Comparison with Psychological Data . . . . . . . . . . . . . . 78 6.2 Analysis of the Learned Models . . . . . . . . . . . . . . . . . . . . . . 80 6.2.1 Musicological Analysis . . . . . . . . . . . . . . . . . . . . . . 81 6.2.2 T emporal Model Analysis . . . . . . . . . . . . . . . . . . . . . 85 6.2.3 Sequence Generation . . . . . . . . . . . . . . . . . . . . . . . . 89 7 Conclusion 91 7.1 Thesis Review . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91 7.2 Future Resear ch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92 Bibliography 95 A UML Class Diagram 103 B SGD Hyperparameter 105 B.1 AdaGrad . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105 B.2 AdaDelta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 106 C Generated Melodies 107 C.1 Generated Bach Chorales . . . . . . . . . . . . . . . . . . . . . . . . . . 107 C.2 Generated Chinese Folk Melodies . . . . . . . . . . . . . . . . . . . . . 108 Acronyms & Abbreviations BWV Bach-W erke-V erzeichnis CRF Conditional random field CSR Compressed sparse r ow matrix format CV Cross-validation EFSC Essen Folksong Collection EMA Exponential moving average FNN Feed-forward neural network GEMM Fast general matrix multiplication GP Gaussian process IDyOM Information Dynamics of Music L-BFGS Limited-memory Broyden-Fletcher -Goldfarb-Shanno algorithm L TM Long-term model MIDI Musical Instrument Digital Interface MIR Music information r etrieval MVS Multiple viewpoint systems NLP Natural language processing NPMM Neural probabilistic melody model OWL-QN Orthant-wise limited-memory quasi-Newton optimization PPM Prediction by partial matching PULSE Periodical uncovering of local structur e extensions PyPulse Python framework for PULSE RBM Restricted Boltzmann machine RNN Recurrent neural networks R TDRBM Recurr ent temporal discriminative RBM SGD Stochastic gradient descent STM Short-term model TEF T emporally extended featur es UML Unified Modeling Language 9 Chapter 1 Introduction In a world that is growing ever more interconnected, for ging links between cultures becomes an increasingly meaningful endeavor . Of all cultural contrivances, music is one that has the power to go beyond the barriers that divide us and bring people together in a unique way . Thus, musical cognition and particularly the understand- ing of similarities and differences in styles is not only relevant for musicians, but for everyone. 1.1 About Music Modeling While the study of music is typically pursued in the fields of arts and humanities as well as historic and systematic musicology , music has always exerted a certain pull on resear chers of machine learning. Computational modeling of music and algorithmic composition have been well established since the 1990s and constitute two appealing realms for the application of learning methods (Papadopoulos and W iggins 1999). Music provides multifaceted data with several layers of temporal structur e such as r hythm, melody and harmony (Lerdahl and Jackendoff 1985; Narmour 1992). This sparked the search for a grammar as in natural language processing (Rohrmeier 2007; Steedman 1984). Machine learning models adopt the techniques of humans who acquire their understanding of music by culturally influenced statistical learning (Huron 2006; Rohrmeier and Rebuschat 2012; Saffran, Johnson et al. 1999). This stands in contrast to prior computational rule-based approaches of finding a grammar or model of music (Lerdahl and Jackendof f 1985; Narmour 1992; Schellenber g 1997). For music and statistical language modeling, n -gram models enjoy great popularity today . However , long ranging dependencies that may encompass the entir e length of a piece, cannot be captur ed by traditional Markovian approaches (Rohrmeier 2011). For example, the first and last note ar e 10 Introduction 11 often identical and motifs are repeated during the piece. Thus, it is indicated to apply non-Markovian methods, which were recently shown to outperform state-of- the-art melody models (Cherla, T ran, Garcez et al. 2015). Many statistical models of music have been learned for songs fr om dif ferent cultur es and styles: European, Canadian and Chinese folk music (Pearce and W iggins 2004), T urkish folk music (Sertan and Chordia 2011), northern Indian raags (Srinivasamurthy and Chordia 2012) and Greek folk music (Conklin and Anagnostopoulou 2011), to name just a few . This highlights the cross-cultural interest in music modeling of local as well as foreign pieces. Music is consider ed to be a well suited domain for the study of human cognition. Pearce and Rohrmeier (2012) reason that music is a fundamental and ubiquitous human trait that has played a vital role in evolution, shaping culture and human interaction. Accor ding to Pearce and Rohrmeier , musical complexity and variety constitute a scientifically interesting cognitive system. Computational models of music have been used to analyze expectation behaviorally (Pearce and W iggins 2006, 2012) and neuroscientifically (Rohrmeier and Koelsch 2012), as well as to study human memory (Agres et al. 2017). By learning predictive models of music, this thesis is tightly linked to the study of expectation. In psychology , the expectations in future-dir ected information pr ocessing (that is the expected likelihood of future events) are r eferr ed to as predictive uncertainty (Hansen and Pear ce 2014). Expectation in music was reported to evoke emotion (Huron 2006; Meyer 1956) and tension (Lehne et al. 2013). Being deceived in ones expectations of a melody’s continuation may not have as far -reaching implications as a similar mistake in traffic. Nonetheless, such a deception was shown to make the listener ’s heart rate drop (Huron 2006), which underlines the significance of expectation in music. Similarly , unexpected harmonies were detectable by skin conductance measur ements (Stein- beis et al. 2006). In consequence, the right prediction of future events in music is essential for computational cognitive models as well as models of music generation. An event-based predictive model for symbolic music computes the conditional probability distribution over all possible futur e events given the past events. For- mally , the conditional pr obability distribution p ( s t | s 0: t − 1 ) is computed over all possible events s t ∈ X at time t in the song, given the context s 0: t − 1 of events that have already occurr ed, wher e X is the sequence’s alphabet or symbol space. Note that this problem is analogous to the prediction of the next letter or wor d of a text in statistical language models. Figure 1.1 visualizes the output of a predictive melody model for Bach chorale Erstanden ist der heil’ge Christ (BWV 306). The probability distributions for the prediction of chr omatic pitch events were generated by a model learned with P ULSE . The dots in grayscale repr esent the probabilities for each pitch Introduction 12 value at time t , given the past t − 1 pitches that occurr ed in the data. The red markers visualize the actual pitches. Figure 1.1: Piano keyboard visualization of the output of a predictive model for music. The pr edictive pitch distributions for J. S. Bach’s chorale Erstanden ist der heil’ge Christ (BWV 306) were generated by a model learned with P ULSE . The red markers represent the actual pitch values. Each column represents the model’s probability distribution for the next note, given all pr evious true notes. 1.2 Approach In this thesis, the recent P ULSE method (Lieck and T oussaint 2016) is, for the first time, applied outside the realm of r einfor cement learning to the task of sequential melody prediction. P ULSE is an evolutionary algorithm that was shown to be successful in the domain of r einforcement learning and in the discovery of non-Markovian temporal causalities. In addition to learning a predictive model, P ULSE also discovers and selects the best features for this model. T o find a set of features, P ULSE iteratively expands and culls the featur e set until conver gence, by using a feature generating operation and L 1 -regularized optimization alternately . This allows P ULSE to explore feature spaces that are too large to be explicitly listed in common featur e selection approaches. At the same time, the feature generating operation and r egularization factor allow the injection of top-down knowledge into the learner . The underlying conditional random field model affords an easy inspection and interpretation of the converged featur e set. I design a general Python framework for supervised learning with P ULSE called PyPulse as well as a specialization of PyPulse for monophonic melody prediction. Subsequently , I explore the hyperparameter space of the method to find the best models and feature sets. The best models are compared to state-of-the-art models, analyzed, and musicologically interpreted. The pr oposed framework operates Introduction 13 on sequences of musical events represented by digitized musical scores in the MusicXML, **kern , MIDI or abc format. 1.3 Contribution This is the first application of the recently published P ULSE feature discovery and learning algorithm to music. My focus lies on computational modeling of music cognition and musical styles (in contrast to algorithmic composition). I contribute to the P ULSE method and machine learning community by (1) confirming P ULSE ’s capabilities through a successful application in a new domain, (2) designing and developing a P ULSE Python framework, and (3) evaluating it in combination with L 1 -regularized stochastic gradient descent. Further , I contribute to the field of com- putational modeling of music by (1) introducing a new appr oach which outperforms the current state-of-the-art algorithms significantly while (2) at the same time pro- viding insights into the learned models, which I show to be music-theoretically interpretable. T o the field of cognitive sciences I contribute by introducing a new computational surr ogate model of human pitch expectation. Last but not least, I contribute to algorithmic composition by providing new state-of-the-art models of musical styles which I show to be suf ficient for the generation of new melodies of the respective styles. 1.4 Thesis Structure Chapter 2 is concerned with summarizing the line of resear ch on music modeling that I will carry on, and with intr oducing P ULSE and other algorithms that I will use subsequently . Chapters 3 and 4 introduce and describe the new PyPulse framework and its application to music. The best PyPulse models for music ar e determined in chapter 5. Chapter 6 evaluates the learned models in depth by comparing them with prior work and analyzing the discovered featur e sets. Parts of this thesis were presented in (Langhabel, Lieck et al. 2017) but a large share of my work will remain exclusive to this thesis. This includes, but is not limited to, an in-depth discussion of the PyPulse framework (chapters 3 and 4), an examination of all fr ee variables of the learner (chapter 5), the intr oduction of a lar ger number of musical featur es (§4.2 and §5.4), a comparison of a model’s predictions with psychological data (§6.1.3), the musicological analysis of metrical-weight-based features (§6.2.1), an analysis of the discovered featur e sets’ temporal extents (§6.2.2), and sequence generation from the learned models (§4.5 and §6.2.3). Chapter 2 Background and Related W ork 2.1 Predictive Models for Music In this section, I review the most relevant literatur e for this thesis about music, specifically melody pr ediction. Firstly , I describe the concepts of long- and short- term models as well as multiple viewpoint systems to shed light on the underlying learning setting. Secondly , I introduce notable melody pr ediction models that are used to bring these concepts to life. The focus lies on the well-established n -gram models, as well as on recent better -performing connectionist approaches. 2.1.1 Long-T erm and Short-T erm Models The terms long-term model (L TM) and short-term model (STM) are borrowed fr om the respective memory models in cognitive psychology . In the context of music prediction, they refer to the offline trained (the default setting when training any model or classifier) L TM and an online trained (during prediction time) STM that is discarded after every test song. Note however that Rohrmeier and Koelsch (2012) call the neuroscientific flavor to the STM’s naming misleading. They remark that the model’s concept neither matches the biological auditory sensory memory with an only second-long buffer , nor the working memory . The concept to distinguish between an offline and online model for melody prediction was pioneer ed by Conklin (1990). Since then, the ensemble of both models was shown to outperform pure L TMs (Cherla, T ran, W eyde et al. 2015; Conklin and W itten 1995; Pearce 2005; Pearce and W iggins 2004; Whorley et al. 2013). For example, T eahan and Cleary (1996) used the same idea to improve the compression performance of English texts by training a model on a corpus of similar texts first. In music, the L TM captures style-specific characteristics and motives while 14 Backg round and Related Work 15 the STM captures piece-specific characteristics and motives. For each prediction of s t , the STM is trained on the context s 0 , . . . , s t − 1 within the current piece. Figure 2.1 invites the reader to intuitively compare the concept of L TM and STM based on music examples. (a) Beethoven’s Ode to Joy (b) German nursery rhyme (dataset 6, song 2) Figure 2.1: The beginning of two melodies. W ell known (a) can be continued after sufficient exposure to classical music using our mind’s L TM. Less known (b) can be carried on by memorizing motives in line with the STM concept without prior exposure. Pearce and W iggins (2004) also investigated a hybrid called L TM+ that is pre- trained offline and continuously improved online with every new test datum that it encounters. Such models are not investigated in this thesis. 2.1.2 Ensemble Methods Basically , L TM and STM are single models that can be combined to a mixture-of- experts. In multiple viewpoint systems however , L TM and STM may already be mixture-of-experts themselves. Such ensembles of classifiers typically boost the performance compared to each standalone classifier . Multiple V iewpoint Systems Multiple viewpoint systems (MVS) ar e ensembles of music models that each have differ ent points of view – viewpoints – on the musical surface. They were first intr o- duced by Conklin (1990) and Conklin and W itten (1995) and have since then been applied to a range of tasks such as modeling of melody (Conklin and W itten 1995; Pearce 2005; Whorley et al. 2013), harmony (Hedges and W iggins 2016; Rohrmeier and Graepel 2012; Whorley and Conklin 2016; Whorley , W iggins et al. 2013), and classification (Conklin 2013; Hillewaere et al. 2009). Figure 2.2 outlines the concept of MVS. The final hybrid model is a combination of the L TM and STM predictions, whereas the L TM and STM can be a combination of several viewpoint models themselves. The probability distributions are combined on a per prediction basis. Backg round and Related Work 16 L TM ST M Hybrid F ina l P r edictio n com bine V iewpoint P r edictio ns com bine com bine V iewpoint P r edictio ns Figure 2.2: The multiple viewpoint system (MVS) architectur e (r eproduced based on figure 3, Conklin and W itten (1995)). Several predictions of long-term model (L TM) and short-term model (STM) viewpoints are combined separately in a first step, and merged into a final L TM+STM hybrid pr ediction in a second step. In an MVS, the sequence events for each viewpoint ar e of different types . For a type τ , the partial function Ψ τ defines a mapping from the sequence events to [ τ ] , the set of all values τ might take. A viewpoint for τ consists of Ψ τ and a model of sequence prediction over [ τ ] . Conklin and W itten (1995) define the following viewpoint categories: • Basic viewpoints are taken directly fr om the data. The function Ψ τ is total. Examples are ‘chr omatic pitch’ or ‘note duration’ viewpoints. • Derived viewpoints are inferred from one or several basic viewpoints. The function Ψ τ may be partial. Examples for this viewpoint are the ‘sequen- tial melodic interval’ ( seqint ), the ‘interval fr om a r efer ent’ ( intfref ) or the ‘sequential differ ence in note onset’ ( gis221 ). • Linked viewpoints operate on the Cartesian product of their constituents and introduce the capability to model correlations between viewpoints. The linked viewpoint of intfref and seqint is written as intfref ⊗ seqint . • T est viewpoints map to { 0, 1 } and are used to mark locations in the sequence. An example of which is the ‘first event in bar ’ ( fib ) viewpoint. • Threaded viewpoints ar e only defined on locations as described by a test viewpoint. Their alphabet is the Cartesian product of a test and another viewpoint. An example is the ‘ seqint between first events in bars’ ( thrbar ). Backg round and Related Work 17 The challenge is to find the best performing set of viewpoints. Using the viewpoints intfref ⊗ seqint , seqint ⊗ gis221 , pitch and intfref ⊗ fib , Conklin and W itten (1995) r eported their best result of 1.87 bits of cr oss-entropy (see section 5.1.2 for a description of this measure) on a dataset of 100 Bach chorales. However , this performance was computed on a single hold-out set and thus does not generalize well. Pearce (2005) used the same set of viewpoints on a dataset of 185 chorales (see dataset 1 in section 5.1.1) using 10-fold cross-validation and reported 2.045 bits. In addition to that, Pearce employed a selection algorithm to find the best set of viewpoints and achieved a performance of 1.953 bits (smaller values are better). T o train the MVS, the authors cited above used n -gram models of sequence prediction (see section 2.1.3). Combination Rules Ensembles of classifiers, mixture-of-experts and hybrid models all r efer to the same concept: The predictions of several models ar e combined into one. T wo combination rules have been applied to melody pr ediction models in the past, and will be considered here: Conklin (1990) was the first to apply a technique based on a weighted arithmetic mean (the sum rule ), which was then complemented by Pearce, Conklin et al. (2004) with a geometrical mean version (the product rule ). Pearce, Conklin et al. showed that the pr oduct rule performs better than the sum rule for combinations of viewpoints within the L TM or STM. In combinations of the L TM and STM (the use case of combination r ules in this work), both rules wer e shown to perform similarly , however , the sum rule was shown to perform better than the product r ule if the combined L TMs and STMs operate on the same viewpoints. Outside the realm of music, Alexandre et al. (2001) and Kittler et al. (1998) who combine classifiers using above techniques found the sum rule to be mor e r obust against erroneously high or low probability estimates than the product rule. They observed a better performance of the sum rule in the tested scenarios. Conklin (1990) also proposed weighting approaches for the source distributions that work on a per-distribution basis and pr oved to incr ease the performance. For a set of models M with model m ∈ M , let p m ( s t | s 0: t − 1 ) be the predictive distribution for s t as computed by m . The weighted arithmetic mean is then defined as p ( s t | s 0: t − 1 ) = ∑ m ∈ M w m p m ( s t | s 0: t − 1 ) ∑ m ∈ M w m , (2.1) Backg round and Related Work 18 and the geometrical mean with normalization constant Z is defined as p ( s t | s 0: t − 1 ) = 1 Z h ∏ m ∈ M p m ( s t | s 0: t − 1 ) w m i 1 ∑ m ∈ M w m . (2.2) The weighting strategy is shared by both methods and follows the idea that pr e- dictive distributions with lower entr opy should entail a higher weight. Parameter b ≥ 0 tunes the bias attributed to the lower-entr opy distribution. The divisor log | X | normalizes the weights to be in [ 0, 1 ] , with X being the sequence’s alphabet. The weighting factor w m for model m is then computed by w m = − ∑ s ∈ X log p m ( s | s 0: t − 1 ) log | X | − b . (2.3) 2.1.3 n -gram Models L TM, STM and MVS are general concepts that need a sequence model – such as n -gram models – to put them to life. n -grams are especially popular as language models in machine translation, spell checking, and speech r ecognition. In the r ealm of music, they have first been used by Brooks et al. (1957), Hiller and Isaacson (1959) and Pinkerton (1956), and since then gained gr eat popularity , too (Rohrmeier and Koelsch 2012). n -grams are used for almost all MVS implementations, and they ar e also used independently in, for example, Ogihara and Li (2008) and Rohrmeier and Cross (2008). In a sequence, n -grams are contiguous subsequences of length n . n -gram models use n -grams for statistical learning by counting occurr ences of each subsequence in the training data. They are ( n − 1 ) th-order Markov models, as the prediction of the next event s t depends on the last n − 1 events only . Using maximum likelihood estimation the prediction is computed with p ( s t | s t − n : t − 1 ) = c ( s t | s t − n : t − 1 ) ∑ s ∈ X c ( s | s t − n : t − 1 ) (2.4) where c ( s t | s t − n : t − 1 ) describes the occurrence count of the n -gram s t − n : t . The choice of the right n is important as a too large n leads to overfitting on the training data whereas a too small n results in insufficient exploitation of the data structur e. Unbounded n-grams are variable-or der Markov models that make the choice of n superfluous: they try to compute the predictions p based on the lowest-order context s t − n : t − 1 that matches the data and unambiguously implies s t to occur next in any training sequence s t − n : t . If such a context does not exist, the highest order context that still matches the data is chosen. A disadvantage for n -grams of Backg round and Related Work 19 long contexts is that they suffer from the curse of dimensionality: the number of model parameters grows exponentially with n . Smoothing and Escaping Methods In addition to overfitting for lar ge n , the vanilla n -gram approach explained above has another flaw called the zero-fr equency problem. If a subsequence did not occur in the training data but is encounter ed during pr ediction time, it is assigned likelihood zero. Pearce and W iggins (2004) make an in-depth empirical comparison of escaping and smoothing techniques that mitigate overfitting and the zero-fr equency pr oblem. They use the prediction by partial matching (PPM) algorithm (Cleary and W itten 1984) which is prominent in data compression based on n -gram models. Cleary and W itten’s original version implements backoff smoothing : In case the context of length n − 1 does not occur in the data, the algorithm backs off to the next shorter context length to compute the prediction. Another variant examined by Pearce and W iggins is interpolated smoothing , which always computes a weighted average of contexts of all length. Thus, it simultaneously reduces overfitting caused by an inappropriately chosen n and the zero-frequency pr oblem. Escaping strategies aim at solving the zer o-frequency pr oblem by assigning non- zero counts to newly encountered subsequences during prediction time. Pearce and W iggins (2004) tested several such strategies, amongst which, for example, the most basic one simply assigns count one to all unseen n -grams. Pearce and W iggins (2004) reported unbounded n -grams using their escaping strategy (C) and interpolated smoothing to be the best performing L TM configura- tion. They achieved 2.878 bits on a benchmarking corpus of monophonic chorale and folk melodies 1 . The corresponding STM, L TM+, and hybrid of both achieved 3.147, 2.614 and 2.479 bits, r espectively . n -grams held the pr evious state-of-the-art for STMs. IDyOM The Information Dynamics Of Music (IDyOM) framework 2 is a cognitive model for pr edictive modeling of music using MVS and unbounded n -grams (Pear ce 2005). IDyOM extends the work of Pear ce and W iggins (2004) with a larger range of viewpoints. It supports manual as well as automatic viewpoint selection. The 1 In the remainder of this thesis I will refer to this corpus as the Pearce corpus (also see section 5.1.1). 2 https://code.soundsoftware.ac.uk/projects/idyom- project Backg round and Related Work 20 system produces state-of-the-art r esults for n -gram models on the task of melody prediction. Since its introduction, the IDyOM framework was used several times in r esearch of the cognitive sciences. For example, Hansen and Pear ce (2014), Pear ce, Müllen- siefen et al. (2010) and Pear ce and W iggins (2012) discuss IDyOM’s suitability as a model for auditory expectation. 2.1.4 Connectionist Approaches The comparison to connectionist appr oaches is of particular importance, as an approach based on recurr ent neural networks (RNN) held the previous state-of- the-art for non-ensemble methods in monophonic melody pr ediction. While there have been many connectionist approaches in the past (Bosley et al. 2010; Mozer 1991; Spiliopoulou and Storkey 2011), I will go into detail on only the most recent approaches that use the same benchmarking corpus and measur e. RBM Cherla, W eyde, Garcez and Pear ce (2013) use a restricted Boltzmann machine (RBM) for the task of melody modeling. RBMs ar e a type of neural network in that, as a restriction compar ed to Boltzmann machines, the hidden units within one layer are not connected. Their approach outperforms n -gram L TMs on the Pearce corpus, especially for larger context sizes n . Furthermore, the RBM scales linearly with n and | X | in contrast to an exponential scaling of n -grams. The authors also proposed a unified model that uses note durations additionally to pitches, as well as an arithmetic mixture model of a pitch and duration model. They report that the unified pitch and duration model performed worse than the pitch-only model, but that the ensemble performed better . The RBM pitch-only model was later r eported to achieve 2.799 bits on the Pear ce corpus (Cherla, T ran, Garcez et al. 2015). FNN Feed-forward neural networks (FNN) were applied to single and multiple viewpoint melody prediction in prior work. Cherla, W eyde and Garcez (2014) examined two differ ent ar chitectur es: (1) A FNN with a single sigmoidal hidden layer , a variable number of hidden units and input layer vectors of differ ent length, and (2) an extension to the FNN (1) named neural pr obabilistic melody model (NPMM) which Backg round and Related Work 21 modifies the neural probabilistic language model and accepts several vectors as input. Each vector repr esents the fixed-length context of a musical viewpoint, for example, the past n pitches. The viewpoints ar e one-hot encoded. In the NPMM several such binary input vectors ar e transformed to real-valued vectors of lower dimensionality within an additional embedding layer; the r espective embeddings are learned from the data. The real-valued vectors then form the input to FNNs of architecture (1), all hidden units use hyperbolic-tangent activations. Thus, the prediction of an NPMM can be based on several viewpoints. The softmax output layer then returns the desir ed pr obability vector over the prediction classes 3 . Cherla, W eyde and Garcez evaluated their models on the Pearce corpus and per - formed better than n -gram models but worse than the RBM on the single viewpoint task with 2.830 bits. In addition to that, they compared the performance of a single model with three input viewpoints and a mixture of single-input models of the same viewpoints on one dataset of the Pear ce corpus. Both performed better than the single-viewpoint model, although the ensemble of several NPMM performed slightly better than the multiple-input NPMM. R TDRBM The recurr ent temporal discriminative RBM (R TDRBM) was introduced by Cherla, T ran, Gar cez et al. (2015) as a non-Markovian appr oach for L TMs, and used in STM and L TM+STM hybrid settings by Cherla, T ran, W eyde et al. (2015). Cherla et al. combined the discriminative approach for RBMs (Larochelle and Bengio 2008) with the structure of the r ecurr ent temporal RBM (Sutskever et al. 2009), to achieve discriminative learning while capturing long-term dependencies in time series data: the conditional pr obabilities p ( s t | s 0: t − 1 ) are learned directly while they explicitly depend solely on s t − 1 . The R TDRBM held the pr evious state-of-the-art on L TM melody prediction for a single input type, with 2.712 bits on the Pear ce corpus. It performs worse than n -gram models in the STM setting with 3.363 bits, but held the pr evious r ecord in the combined L TM and STM (using n -gram STMs) with 2.421 bits. In this section I have intr oduced the most relevant melody modeling literature for this thesis. While this work operates on symbolic data, much resear ch has also been done on the prediction of raw audio data. For example, ‘A.I. Duett’ of the 3 According to Gal (2016) and Gal and Ghahramani (2016) the softmax output does not model the probability distribution over the pr ediction classes pr operly . They give examples that have high softmax outputs despite having a low model certainty . Gal and Ghahramani propose the Monte Carlo dropout method to compute the pr obabilities. Backg round and Related Work 22 https://magenta.tensorflow.org/ project, Thickstun et al. (2016), and Oor d et al. (2016), to name a few recent works. 2.2 P ULSE In the domain of reinfor cement learning, delayed causalities pose special challenges to the learner . For example, a household r obot leaving the fridge door open and discovering bad food the day after has to be able to conclude that this is not the cause of some directly preceding action, but of a delayed one. Therefor e, such pr oblems can only be solved with non-Markovian approaches. Lieck and T oussaint (2016) introduced periodical uncovering of local structure extensions ( P ULSE ), a feature discovery and learning method, that can find features for arbitrarily delayed or non- Markovian causal relationships. P ULSE pulsatingly gr ows and shrinks the featur e set by r epeated generation of new featur es and selection of the fittest. It operates like an evolutionary algorithm with the exception that the fitness measure is not applied to each feature separately , but to the entire population at once. Featur es can be arbitrary functions that describe certain aspects of the data (see section 2.2.1). P ULSE was analyzed in both, a model-free and a model-based setting, and outperformed its competitors in the latter in a partially observable maze envir onment with delayed rewar ds. Algorithm 1 describes P ULSE in pseudo-code. In P ULSE , a featur e construction kit named N + is called repeatedly to incrementally build the featur e set F (line 3). This stands in contrast to typical feature selection methods where a large universal feature set is reduced to the features that ar e relevant for the data. Let θ = { θ f | f ∈ F } be the respective set of feature weights. The optimization of an L 1 -regularized objective O on feature set F and training data D assigns non-zero weight θ f to meaningful features f ∈ F . L 1 regularization is used to both select features and reduce overfitting. In line 5, using S H R I N K , all features with zero weight are removed from the feature set. Note that features are always added with weight zero (line 11) so that the objective value r emains the same befor e and after a call to G R O W . If greedily optimized, the objective value will monotonically decr ease. For a time series prediction setting where dependencies reach back n events, the authors proved that P ULSE will converge to a globally optimal featur e set within n iterations, if : (1) N + uses conjunctions to expand every feature with all basis features, (2) the basis features ar e indicator featur es and describe all r elevant past events, (3) the objective O is a strictly monotonic function of the model’s goodness, and (4) the optimization of O involves every feature f ∈ F and leads to a model that performs Backg round and Related Work 23 Algorithm 1 P ULSE (repr oduced, based on algorithm 1 Lieck and T oussaint (2016)) Input: N + , O , D Output: F , θ 1: F ← ∅ , θ ← ∅ 2: while F not converged do 3: G R O W ( F , θ , N + ) 4: θ ← ar gmin θ O ( F , θ , D ) 5: S H R I N K ( F , θ ) 6: return F , θ 7: function G R O W ( F , θ , N + ) 8: for f ∈ N + ( F ) do 9: if f / ∈ F then 10: F ← F ∪ { f } 11: θ f ← 0 12: function S H R I N K ( F , θ ) 13: for f ∈ F do 14: if θ f = 0 then 15: F ← F \ { f } equally to an optimal pr edictor (see section 3.3 in Lieck and T oussaint (2016) for details). The ‘no free lunch’ theorem states that ther e is no universal learning framework that performs well in all scenarios (W olpert and Macready 1997; W olpert, Macready et al. 1995). Prior knowledge about the domain of deployment has to be included into the framework to achieve a good performance. In P ULSE , prior knowledge can be included in two ways: (1) By the definition of the N + operator and features, and (2) by the choice of the regularization term in the objective. The N + operator and objective as well as the underlying model are explained her einafter . 2.2.1 The Conditional Random Field Model The model-based P ULSE approach uses conditional random field (CRF) models. CRFs (Laf ferty et al. 2001) are a class of powerful discriminative classifiers for supervised learning. They were demonstrated to be successful in many applications (Peng et al. 2004; Sutton and McCallum 2006), including music (Durand and Essid 2016; Lavrenko and Pickens 2003). In CRF , the data is described b y feature functions f which are arbitrary mappings f : ( x , y ) 7 → R , where x ∈ X is the input data or context and y ∈ Y is the class label or outcome. Backg round and Related Work 24 A CRF computes the conditional probability p ( x | y ) using the log-linear model p ( x | y ) = 1 Z ( y ) exp ∑ f ∈F θ f f ( x , y ) Z ( y ) = ∑ x 0 ∈ X exp ∑ f ∈F θ f f ( x 0 , y ) . (2.5) Factor Z is called the partition function and normalizes the probabilities to sum up to unity . In log-linear models (also known as maximum entropy models), the linear combination of feature functions is computed in the logarithmic space which af for ds positive results even for negative feature values. The partition function can become a computational bottleneck, as it requir es the summation over the whole space Y . 2.2.2 The Objective As no closed form solution exists for equation 2.5, numerical optimization is used to find the best weight values θ . Lieck and T oussaint used L-BFGS optimization for this task. T ypically , maximum likelihood estimation, or equivalently minimization of the negative log-likelihood , is used as optimization objective. Operating in logarithmic space has the advantage that floating point underflows (for very small likelihoods) are avoided and that the derivatives ar e computed over a sum instead of a product. For likelihood L , with L = ∏ ( x , y ) ∈ D p ( x | y ) , the objective ` ( θ ; D ) is computed as the sum of the negative log-likelihood and a convex r egularization term R ( θ ) with regularization str ength λ : ` ( θ ; D ) = − ∑ ( x , y ) ∈ D log p ( x | y ) + λ R ( θ ) (2.6) As both summands are convex, ` is convex as well, and any local optimum will be a global optimum. T o facilitate feature selection, P ULSE requires R ( θ ) to include terms that drive the weights of non-expressive featur es to zer o. The authors relied on L 1 regularization, whereas more sophisticated R ( θ ) could have been used to incorporate prior knowledge into the model (e.g. assuming a Gaussian prior over the weights with L 2 regularization). 2.2.3 The N + Operation The antagonist of the L 1 -regularized optimization is the N + operation. The regular- ization compacts the feature set ( S H R I N K ) and the N + operation expands it with new candidates ( G R O W ). The interplay of S H R I N K and G R O W is depicted in figure 2.3. In the figure, cir cles describe features. The feature set is a subset of the whole possible Backg round and Related Work 25 features space. Filled circles have non-zer o weight, while empty cir cles have zer o weight. Feature spaces can be too lar ge to be searched exhaustively or even to be listed explicitly . The N + operation serves as a task-specific heuristic to generate new candidate features and add them on probation to the feature set. N + bases its decisions on the active featur es (those with a non-zero weight) in the shrunken featur e set that have already pr oven beneficial. The authors describe the generation of new candidates by creating liaisons between the active features and all elements from a set of basis features using conjunctions. Any other operation that synthesizes finite sets of features based on the active feature set is suitable, too. Such an operation may be the recombination of features using logical operands or the mutation of featur es by dr opping out terms. r emove if w =0 af ter optimization added by N + F eatur e Set Figure 2.3: Interplay of the G R O W and S H R I N K operators that expand (using N + ) and cull (using L 1 -regularized optimization) the featur e set. Full circles are featur es with non-zero, empty cir cles with zer o weight. 2.3 Stochastic Gradient Descent Stochastic gradient descent (SGD) is a first-order online optimization algorithm. In batch gradient descent, the objective to be minimized (or maximized) is computed on the entire training dataset. In SGD, the gradient of the true objective is stochastically approximated using one datum (vanilla SGD) or a small subset of the training data (mini-batch SGD). Its main advantages show on very large datasets that are too big to fit in memory and cause expensive overheads in the computation or approximation of the Hessian matrix. In practice, optimizations on lar ge datasets often conver ge faster using SGD compared to batch methods. The main disadvantage in using vanilla SGD is that finding a good learning rate and annealing schedule is har d. This shortcoming has been tar geted by several automatic learning rate tuning methods such as AdaGrad and AdaDelta, which I use in this work. Backg round and Related Work 26 2.3.1 AdaGrad Duchi, Hazan et al. (2011) introduced AdaGrad, a method to automatically decay the learning rate individually per dimension of the weight vector . For each dimension and update, the L 2 norm of all past gradient s g is accumulated. Subsequently , the initial learning rate η is divided by these accumulators that increase monotonically . The underlying idea is that a history of larger gradients decr eases the learning rate more than a history of smaller gradients. Thus, for dimensions with infr equently observed features or weaker gradients, the learning rate r emains r elatively higher . Let e be a small constant to prevent divisions by zero. For iteration t + 1, the weight update for weight vector w is w t + 1 = w t + ∆ w t (2.7) ∆ w t = − η q ∑ t τ = 1 g 2 τ + e g t . (2.8) The main problem inher ent in this method is that the learning will stall in case of elongated training durations that cause the rate to become infinitesimally small. 2.3.2 AdaDelta AdaDelta was developed to solve the problem of diminishing gradients in AdaGrad. Furthermore, while SGD and AdaGrad r equir e a meticulous tuning of the learning rate, AdaDelta was shown to perform similarly well without the need to tune any learning rate parameter (Zeiler 2012). The history of past gradients is represented by the exponential moving average (EMA) of the squar ed gradients E [ g 2 ] , with decay rate ρ . This replaces the global accumulation and prevents infinitesimally small updates. The numerator normalizes the weight updates to the same scale as the previous updates, using EMAs as well. Again, let e be a small constant, then ∆ w t = − p E [ ∆ w ] t − 1 + e p E [ g 2 ] t + e g t . (2.9) 2.3.3 L 1 Regularization in SGD T raining The ef fect of L 1 regularization is best described by T ibshirani (1996)’s explanation of the lasso : “It shrinks some coefficients and sets others to zero, and hence tries to retain the good featur es of both subset selection and ridge r egr ession.” Its feature selecting properties stem from the diamond-like shape of the L 1 ball, whose corners lie on the coordinate axes wher e all but one coef ficient is zero. The contour lines of Backg round and Related Work 27 the stochastic gradients are more likely to touch the corners than the sides of the diamond, and thus, many coefficients become zer o. Sparse models ar e advantageous when feature values are expensive to acquire, to increase the prediction speed in practice, and to reduce memory usage. The regularizing properties are advantageous whenever training data is not ample and maximum likelihood learning causes overfitting. T suruoka et al. (2009) state that it is dif ficult to have L 1 regularization in SGD for two reasons: (1) The L 1 norm is discontinuous at the orthant boundaries and thus not differ entiable everywhere, and (2) the stochastic gradients are very noisy which makes the local decision whether to globally set a weight to zer o or not dif ficult. Following the appr oach to add the L 1 term to the objective – as it is done in batch methods – is not suf ficient; it is highly unlikely that the weight updates precisely sum up to zero after optimization and thus the r esulting model would not be sparse. The following approaches seek to produce sparse models with L 1 in SGD: Xiao (2010) maintains running averages of past gradients and solves smaller optimization problems in each iteration to cir cumvent selecting features based on local decisions. Carpenter (2008), Duchi and Singer (2009), Langford et al. (2009) and Shalev-Shwartz and T ewari (2011) all follow a two-step local approach. They first compute the updated weight without considering the regularization term, and then apply the regularization penalties under the constraint that the weights are clipped whenever they cross zer o. T suruoka et al. (2009) point out shortcomings in the weight clipping methods and propose their cumulative penalty approach. They compared their method to OWL-QN BFGS (Andrew and Gao 2007) using CRF models, and found it to be similar in accuracy but faster on all benchmarked NLP tasks. In their approach, the total penalty u that could have been applied to any weight is accumulated globally , as well as on a per -dimension basis the penalties q that actually wer e applied. The resulting L 1 penalty term is based on the dif fer ence of the total and actual penalty accumulators, and applied after the r egular weight update. As a consequence, the gradients are smoothened out and a regularization accor ding to the unknown r eal gradients is simulated. Let N be the size of the training dataset, λ 1 be the r egularization str ength for L 1 , and η be the global learning rate. Let further w i repr esent one dimension of the weight vector and let q i be the respective actual penalty accumulator . Then, the Backg round and Related Work 28 weight update for optimization iteration t + 1 is computed with w i t + 1 2 = w i t + ∆ w i t (2.10) w i t + 1 = max ( 0, w i t + 1 2 − ( u t + q i t − 1 ) w i t + 1 2 > 0 min ( 0, w i t + 1 2 + ( u t − q i t − 1 ) ) w i t + 1 2 < 0 (2.11) where the total penalty accumulator u and the received penalty accumulator q i are defined as u t = λ 1 N t ∑ k = 1 η k (2.12) q i t = t ∑ k = 1 ( w i k + 1 − w i k + 1 2 ) . (2.13) Chapter 3 PyPulse : A Python Framework for P ULSE In this chapter , I discuss the design and implementation of P ULSE , a Python frame- work for P ULSE . The framework was designed with generality in mind and supports feature discovery and learning for any kind of labeled data. The implementation boasts SGD in combination with L 1 regularization to gear for large datasets, and uses Cython modules to maximize speed. Currently , the PyPulse framework is still under development and parts of it are solely realized for music-specific time series. The code will be published on https://github.com/langhabel . 3.1 Design The module design is specified as a UML class diagram (Rumbaugh et al. 2004). The main modules are sketched in the following whereas the full diagram, including the specializations for music fr om chapter 4, is pr ovided in appendix A. Note that in the implementation for efficiency reasons the conceptual modules were melted together in several instances. 3.1.1 Overview A minimalist version of the class diagram is presented in figure 3.1 and gives a structural overview of the architectur e. The central Pulse module executes the algorithm while making use of the other modules. 29 PyPulse : A Python F ramew ork for P ULSE 30 P u l s e F e a t u r e S e t F e a t u r e M a t r i x C r e a t o r L 1 O p t i m i z e r M o d e l F e a t u r e N P l u s O b j e c t i v e 1 1 . . n Figure 3.1: A UML sketch of the PyPulse framework’s main modules. 3.1.2 Module Descriptions In the following, the main modules and their chief functionalities are explained briefly: • Pulse : The main module has the public methods fit() and predict() for supervised training and prediction. fit() accepts a list of labeled data points, predict() accepts a data point and r eturns a label. Pulse is initialized to use a given NPlus , L1Optimizer and Model . During training, the learning algorithm alternatingly uses NPlus and L1Optimizer to discover the best feature set. • FeatureSet : The FeatureSet is the container of the features and their respec- tive weights. Its method shrink() removes all featur es with zero weight from the feature set. • NPlus : The NPlus module has the method grow() which takes a FeatureSet object and returns an expanded instance of it. If pr eviously empty , FeatureSet is initialized based on a given list of feature types. T o be able to expand a feature, the implementation of NPlus has to have knowledge of the featur e’s structur e. • Feature : In CRFs, features are functions f : ( x , y ) 7 → R . In the implementation, a feature function takes a data point and label pair and r eturns a float value. The implementation has to maintain all relevant constants and states for the feature function’s computation. • FeatureMatrixCreator : The job of the FeatureMatrixCreator is to prior to optimization compute the values of the feature function for each data point, feature in the feature set, and occurring class label. All values are stor ed in a three-dimensional featur e matrix (see section 3.2.6). PyPulse : A Python F ramew ork for P ULSE 31 • Model : This module provides the function eval() that, given the feature weights, the feature matrix, and for every data point a refer ence to the matching class label, evaluates the model. • L1Optimizer : The function optimize() computes the best model weights using L 1 -regularized optimization. As input optimize() takes a feature matrix, weight vector , regularization, and convergence parameters. Its actions are guided by the optimization Objective . • Objective : This module declares the public functions computeLoss() and computeGradient() that compute the loss value to be minimized during opti- mization and the gradient, r espectively . Their computation r equir es the featur e weights, the feature matrix, the number of training data points, and for every data point a refer ence to the matching class label. 3.2 Implementation Details The core of the algorithm is best depicted as two nested loops (see figur e 3.2). For every outer loop iteration for feature discovery ther e are several inner loop iterations to select the best features using L 1 -regularized optimization. In every iteration, the outer loop executes the sequence of function calls grow() – optimize() – shrink() . optimization loop featu r e discove ry loop Figure 3.2: Interplay of P ULSE ’s main loops. The outer loop expands the feature set, the inner loop selects and learns the best features. For every outer loop iteration there ar e many inner loop iterations. 3.2.1 Implementing L 1 -Regularized Optimization It is pertinent to ask whether SGD or L-BFG S optimization is preferable to implement the L1Optimizer module. Bottou (2010), Lavergne et al. (2010) and V ishwanathan et PyPulse : A Python F ramew ork for P ULSE 32 al. (2006) show that SGD with cumulative penalty L 1 regularization (see section 2.3.3) is preferable over the Quasi-Newton L-BFGS method for lar ge CRF models. Based upon these findings, I choose SGD over L-BFGS. In prior attempts, I tested the L 1 -regularized SGD optimizer AdaGrad-Dual A veraging (Duchi, Hazan et al. 2011), as implemented in the T ensorFlow machine learning framework (Abadi et al. 2015). However , the observed convergence rates proved to be unsatisfying. Resorting to Theano (Ber gstra et al. 2010), I implement L 1 -regularized versions of the optimizers AdaGrad and AdaDelta by adapting them to T suruoka et al. (2009)’s cumulative penalty approach (see section 3.2.2), which leads to good results. 3.2.2 V ectorizing Cumulative Penalty L 1 Regularization In the following, I describe my adjustments to the cumulative penalty appr oach of T suruoka et al. (2009) to make it work with adaptive stochastic gradient methods. The resulting optimizers learn L 1 -regularized models with automatic per-featur e learning rate annealing. Regularization serves as a means to reduce overfitting and to pr omote better generalization performance. In the context of P ULSE , it additionally provides a means of injecting prior knowledge into the model (see section 4.4 for more details). T o inject prior knowledge, per -feature regularization is mor e pr ecise than a global regularization rate that treats all features equal. This is especially the case when features describe varied pr operties or ar e of a heterogeneous expr essiveness. AdaGrad and AdaDelta maintain accumulator vectors to compute per -featur e learning rates and weight updates. The cumulative penalty method maintains per- feature accumulators q for the received weight penalties. Originally , it is designed to be used with a global learning rate and global L 1 regularization factors only (see section 2.3.3). I extend the algorithm by vectorizing the total penalty accumulator u . The resulting method offers per -feature learning rates and regularization factors while conserving the algorithm’s essence. Let u i t repr esent the total penalty accumulator value for dimension w i of the weight vector and iteration t . Let further λ i 1 be the L 1 regularization strength for feature i , N be the size of the training data, and η i = ∆ w i / g i be the r espective adaptive per-featur e learning rate of AdaGrad or AdaDelta. The vectorized version of equation 2.12 is then defined as u i t = λ i 1 N t ∑ k = 1 η i k . (3.1) PyPulse : A Python F ramew ork for P ULSE 33 3.2.3 Adding a Learning Rate to AdaDelta T o accelerate the learning in AdaDelta, I intr oduce an initial learning rate parameter η to equation 2.9. Using the notation from section 2.3.2, the extended weight update formula is ∆ w t = − η p E [ ∆ w ] t − 1 + e p E [ g 2 ] t + e g t . (3.2) 3.2.4 Hot-Starting the Optimizer Figure 3.2 visualizes that for each feature discovery loop, a new optimization is started, for a modified featur e set. In every new outer loop iteration, features that graduated from the candidate to the active state are initialized with their pr evious non-zero weight, and the new candidates are initialized with weight zero. However , all AdaGrad/AdaDelta and cumulative penalty accumulators ar e reset by default. W ith the intent to accelerate learning, I add a hot-starting option to the optimizers that carries over the accumulator values (total penalty accumulator , received penalties accumulator and squared gradient accumulator vectors) of the selected featur es to subsequent iterations. 3.2.5 Convergence Criteria Convergence criteria aim at detecting an optimization algorithm’s arrival at the optimum. The criteria that I implemented for the feature discovery and optimization loop, as shown in figure 3.2, ar e outlined in the following. Inner Loop Convergence Criteria For the optimization loop, I implement two criteria. The first one is based on the convergence of the active featur e set (i.e. the features with non-zero weight), and the second one is based on the conver gence of the loss value (i.e. the value of the negative log-likelihood objective). The two criteria arise from differ ent intents: The first one takes effect when the active featur e set stops changing, and can be used in all but the last outer loop iteration wher e a convergence of the loss value is required. This motivates the second criterion that is meant to kick in later and meant to ensur e a thorough training of the final feature set. Note that prior to the last outer loop iteration, we are only inter ested in the selected featur es, not their weights. Let i be the current training epoch, τ inner , loss and τ inner , active the decay rates of the exponential moving averages (EMA), ` i the accumulated negative log-likelihood PyPulse : A Python F ramew ork for P ULSE 34 (see section 2.2.2) over epoch i , and F active i the active feature set at epoch i . Let factors γ inner , loss and γ inner , active be the convergence thr esholds for the loss-based and active-feature-set-based criterion, r espectively . The convergence criteria ar e defined as abs EMA ( ` i , τ inner , loss ) − EMA ( ` i − 1 , τ inner , loss ) < γ inner , loss (3.3) EMA ( | ( F active i ∪ F active i − 1 ) \ ( F active i ∩ F active i − 1 ) | , τ inner , active ) < γ inner , active . (3.4) Outer Loop Convergence Criteria For a well chosen L 1 regularization factor , the P ULSE feature discovery loop will ar- rive at an equilibrium between S H R I N K and G R O W , and the feature set will converge. T o detect such an equilibrium, three convergence criteria wer e implemented. W ith j being the current outer loop iteration, F j the feature set at iteration j , τ outer the decay rate of the EMA, and γ outer the convergence tolerance, they ar e: (a) The relative conver gence of the number of changing features in the feature set | ( F j ∪ F j − 1 ) \ ( F j ∩ F j − 1 ) | < γ outer · | F j | . (3.5) The symmetric differ ence of featur e sets F j and F j − 1 between two consecutive iterations dir ectly describes the fluctuation of features in the pr evious iteration. The count of changed features is compar ed to the threshold, which is r elative to the current featur e set count. (b) The relative conver gence of the differ ence in featur e set size abs ( | F j | − | F j − 1 | ) < γ outer · | F j | . (3.6) The absolute differ ence in feature set size between two consecutive iterations is a heuristic strategy for criterion (a). This criterion is simpler to compute than (a) but oblivious to the actual number of fluctuating features. Arrival at a constant feature set size is a necessary but not suf ficient condition for featur e set convergence. (c) The convergence of the EMA of the validation err or H abs EMA ( H j , τ outer ) − EMA ( H j − 1 , τ outer ) < γ outer . (3.7) T o stop learning after convergence of the validation error is a standard machine learning approach. However , in P ULSE , the validation error does not always decrease monotonically . T o smoothen the values, I consider the EMA of the PyPulse : A Python F ramew ork for P ULSE 35 validation error instead. Once the absolute difference of consecutive values falls below the threshold, learning is stopped. 3.2.6 The Feature Matrix The three-dimensional featur e matrix F ∈ ( D × F × X ) quickly becomes very large (recall D to be the data, F the featur e set and X the space of all class labels or prediction alphabet). For example, | D | = 10, 000, | F | = 10, 000 and | X | = 20 already leads to a size of 8 GB for a matrix with 32 bit float values. However , if indicator features f ( x , y ) ∈ { 0, 1 } are used, then F will typically be very sparse. The sparsity permits the storage of F as a compressed sparse r ow (CSR) matrix which in the observed cases reduces the memory consumption by more than thr ee or ders of magnitude. 3.2.7 Computation of the CRF I use a CRF-based appr oach to implement the module Model as described in 2.2.1. This approach was already shown to be effective by Lieck and T oussaint (2016). The computation of the model’s gradient in the objective, specifically the matrix multiplication F [ data idx ] · θ for every data point, is the computational bottleneck of the optimization. I decided to use single-threaded sparse matrix multiplication, as provided by Theano. Below , the investigations leading to this implementation options are described. Space limitations enfor ce F to be stor ed as a sparse matrix; nonetheless, single slices F [ data idx ] can still be reverted to the dense representation for the computation of the model or objective. That raises the question whether a dense or sparse matrix multiplication runs faster . One inhibiting factor regar ding the sparse alternative is that Theano (version 0.9.0b1) does not implement parallel sparse matrix operations on neither GPU nor CPU. Still, tests showed that single threaded sparse matrix multiplication performs faster than a parallelized dense multiplication. Furthermore, runtime pr ofiling reported the sparse multiplication to take only 20% (Python dot product) of the total computation time compared to 80% (GEMM) for the parallel version (without considering the time needed to make the matrix dense). Using a GPU to run dense multiplication failed for two reasons: (a) If a slice F [ data idx ] is copied to the GPU memory for every mini-batch, the Host-to-GPU transfer time outweighs any benefits, and (b) if instead the whole dense feature matrix is copied to the GPU once, the size of the featur e matrix is r estricted by the size of the GPU memory . An approach that was not tested is to compute F [ data idx ] · θ by looping PyPulse : A Python F ramew ork for P ULSE 36 over the feature set while only updating weights for featur es used in the current datum. 3.2.8 N + Postprocessing During expansion, the N + operator can introduce a significant number of irrelevant features. Such features slow down the optimization without providing any benefits. Thus, a postprocessing of the feature set after expansion is generally desirable. Obviously irrelevant ar e featur es with value zero for all data points and class labels, as they don’t change the value of typical models (e.g. linear/log-linear models). These features are r emoved fr om the featur e set after expansion and befor e optimization. In practice, this allows to implement and use N + operations that would have otherwise introduced too many irrelevant features and would have render ed optimization interminable. Chapter 4 PyPulse for Music In this chapter , I describe two specializations of PyPulse : Its adaptation to time series data and to music. The latter includes the conception of music-specific features, N + operators and regularization functions. The result is the highly versatile and potent PyPulse for music framework for the prediction of musical attributes. In line with prior resear ch, this work uses event-based, in contrast to quantized time-based, time series data. Each event is described as a multidimensional vector of musical attributes, most importantly MIDI pitches on a chromatic scale. Indicator functions, as they are fr equently used in NLP , are employed as features. Using the N + operator , such features can be expanded with logical operations. This work looks at differ ent expansions with logical conjunctions. As a result, each feature can be a conjunction of other features itself. Feature selection is facilitated with a range of per-featur e r egularization factors, which depend on each featur e’s temporal extent. For the choice of the N + operator and r egularization factors, the L TM and STM are consider ed separately . 4.1 T ime Series Data This work uses event-based sequences of symbolic music data. In contrast, PyPulse is a supervised learning framework that learns data-label pairs ( x , y ) in its CRF model. Though, the representation of a time series pr ediction or tagging task as a supervised learning problem is straightforward: The data points x are the musical contexts s 0: t − 1 , for all possible time indices t . Based upon these contexts, the labels y that repr esent the next time series event s t are to be predicted. Alternatively , any other label such as a sequence of tags could be predicted. As a typical piece of music 37 PyPulse for Music 38 contains more than one musical facet and possibly several voices, the time series events are multidimensional vectors of musical attributes. Besides the L1Optimizer module, the FeatureMatrixCreator poses a compu- tational bottleneck for the learner . Thus, the FeatureMatrixCreator module was optimized for time series data, parallelized, and implemented in Cython (Behnel et al. 2011). 4.2 T emporally Extended Features What should the musical featur es look like? As mentioned pr eviously , the N + op- erator r equires knowledge about the featur es’ str ucture to be able to r ead and manipulate them. I build on the concept of temporally extended features (TEF), proposed and r ealized by Lieck and T oussaint (2016) in the context of reinfor cement learning. A TEF for time series is a function f : X ∗ × X 7 → { 0, 1 } , where X is the possibly multidimensional alphabet of the series (e.g. homophonic or polyphonic melodies) and X ∗ is the respective set of all possible sequences. PyPulse for music uses two kinds of TEF: Compound featur es and basis featur es . Each basis feature f σ , ν has the properties time σ ∈ N and value ν ∈ X and is computed by f σ , ν ( s 0: t − 1 , s t ) = I ( v , s t − σ ) (4.1) where the indicator function I ( · , · ) returns one if both arguments ar e equal and zero otherwise. Basis feature f σ , ν thus considers the event that lies σ steps in the past. T ime σ = 0 looks at the current event, which is to be predicted. Compound features are conjunctions of featur es f i from a set Γ of arbitrary basis features f ( s 0: t − 1 , s t ) = ^ f i ∈ Γ f i σ , ν ( s 0: t − 1 , s t ) . (4.2) Basis features do not exist on their own but only as constituents of compound features. Note that each compound feature is requir ed to contain a basis feature f 0, ν , as only features with σ = 0 make a statement about the event s t to be predicted. A feature that operates entir ely in the past has no predictive esteem. One that operates solely in the future ( σ = 0) models the occurrence fr equencies of value ν . Three extensions of basis features are formalized in the following, having se- quences of musical events in mind. PyPulse for Music 39 4.2.1 V iewpoint Features V iewpoint features increase the expr essiveness of TEF basis featur es by operating on differ ent views on the data. They alter the definition of f σ , ν by ahead of evaluation applying a mapping Ψ from the input sequence to the viewpoint value range V , where value ν ∈ V (compare section 2.1.2). While the definition of f σ , ν in equation 4.1 requir es s 0: t − 1 and s t to be of same dimensionality , this r equirement is relaxed in viewpoint featur es: Let U ⊇ X be the by viewpoints extended time series alphabet and U ∗ be the universal set of all sequences in the viewpoint domain. Let f : U ∗ × X 7→ { 0, 1 } be the updated feature function and Ψ : U ∗ × X 7→ V be the viewpoint mapping, then f σ , ν ( s 0: t − 1 , s t ) = I v , Ψ ( s 0: t − 1 , s t ) t − σ . (4.3) V iewpoint features can be derived from one or several viewpoints themselves, as Ψ can be chosen arbitrarily within its input/output value ranges. A feature may also choose to operate independently from either (or even both) of its properties σ and ν . In (Langhabel, Lieck et al. 2017) we used the term generalized n-gram features to describe compound features of one or several viewpoints. They encompass a superset of n-gram features , that describe all temporally contiguous sequences of basis features, by additionally including all sequences that skip one or mor e time step. Generalized n -grams can best be compr ehended by imagining n -grams that may have holes. Hence, they can depend on distinguished events in the past. While the space of all generalized n -grams has size ( | X | + 1 ) n , in P ULSE , typically only a tiny fraction of features has to be consider ed explicitly . An overview of all implemented viewpoint feature types is given in the upper part of table 4.1. They are described in the following. Pitch (P) Pitch features describe the chromatic pitches of note events. They affor d learning of the pitches’ occurr ence frequencies as well as transposition-sensitive motifs. The feature values equal the MIDI pitch values at the r espective times. The value range P ⊂ N encompasses all occurring pitch values. For a generic application, the equivalent of pitch featur es is a dir ect learning of the time series events, meaning the mapping Ψ for P is the identity . PyPulse for Music 40 Interval (I) The distance in semitones between two pitch values at times t and t 0 6 = t is defined as the melodic interval. In interval features , the interval is defined to be sequential. That means the sour ce pitch values stem fr om subsequent time indices t and t 0 = t + 1. Due to a lack of a reference pitch at time zero, they are undefined for s 0 . Interval features ar e the tool of choice to describe transposition-invariant motifs. They take values of I ⊂ Z , where I is the set of all occurring intervals. Octave Invariant Interval (O) Octave invariant intervals are an octave-invariant subcategory of interval features. They are computed by taking the interval feature value modulo 12, which is the number of semitones in one octave. As they ar e unsigned, they are less suited to describe motives. Instead, they forge links with the harmonic (vertical) intervals that make up chords. The intent behind these features is to learn broken chords which frequently make up parts of melodies. Contour (C) Contour features describe melodies as either rising, falling or static. They are gear ed to model melodic movements on a higher level of abstraction than interval features. Their values are computed by taking the sign of the melodic interval and lie in the range { − 1, 0, 1 } . Extended Contour (X) Extended contours refine contour features by differ entiating between large (more than five semitones) and small intervals. The distinction is motivated by Narmour (1992), who writes that lar ge intervals pr ompt a change of the registral direction whereas small intervals suggest its continuation. Metrical W eight (M) The concept of the metrical weight (Lerdahl and Jackendof f 1985) is best understood by looking at the example in figur e 4.1. Several layers of incr ementally finer grids are placed over the counts of each bar . The finest grid spacing is determined by the shortest note duration. In this example, the differ ent grids are of one, two, four and eight grid points. For each grid, a note’s weight is incremented if it lies on one of the PyPulse for Music 41 Figure 4.1: The metrical structur e of a melody excerpt. The stars indicate the metrical weight; more stars corr espond to a higher weight. grid points. The value range M ⊂ N , here M = { 1, 2, 3, 4 } , is determined by the depth of the metrical structur e. The metrical weight poses a special case among the presented features as it depends on several input dimensions, namely: The offset of the first bar and the note durations. It is worth noting that the metrical weight is defined for σ = 0, irrespective of the tar get alphabet X , as it is derived solely fr om the context. Negated V iewpoints (N P , N I , N C ) The negated viewpoints N P , N I and N C are copies of the respective pitch, interval and contour viewpoints, with the only dif fer ence that the output of the indicator function is negated. The motivation in negated features lies in the efficient representation of causalities such as: “If the last interval was a fifth, then the curr ent one is not a fifth”. Negated viewpoint features br eak the sparsity of the featur e matrix, as they are typically true almost everywhere. Because of immense memory r equir ements they were not evaluated. 4.2.2 Anchored Features Anchored featur es are a subclass of viewpoint features. The differ ence is of a semanti- cal kind: Anchored featur es compute a relationship between two viewpoints Ψ anchor and Ψ target . The viewpoint Ψ anchor is the anchor or r eferent, in relation to which the viewpoint Ψ target is considered. The anchor function A ( Ψ anchor , Ψ target ) computes a kind of relation or distance measure. I use anchored features such that Ψ anchor and Ψ target map to pitch values, and the distance measur e A computes the interval between them. The benefit in computing such relative viewpoints is that it enables the learning of regularities on dif ferent scopes, for example for pieces, phrases or bars. Let value ν ∈ V A , then f σ , ν ( s 0: t − 1 , s t ) = I v , A ( Ψ anchor , Ψ target ) t − σ . (4.4) PyPulse for Music 42 The implemented anchor ed features ar e shown in the middle part of table 4.1 and described in the following. Key (K) Key featur es ar e octave invariant intervals between the current pitch and the tonic per mode. I use the Krumhansl-Schmuckler key finding algorithm (Krumhansl 1990) with key pr ofiles fr om (T emperley 1999) for the computation of the key and tonic. Key profiles are weight vectors of dimension 12 (as many as ther e are choices for the tonic) for both major and minor scales. The Krumhansl-Schmuckler algorithm com- putes correlations between (optionally duration-weighted) note fr equency counts and the key pr ofiles. For that, the key profiles ar e transposed to 12 dif ferent tonics. The highest correlated key profile and its transposition determine the tonic and mode. Having features anchored to the key has the advantage of learning regularities that are individual for each song depending on its key . Here, the regularities are motifs and pitch frequencies relative to the computed key . For each mode, the value range are the 12 degr ees of the chr omatic scale { Major , minor } × { 0, . . . , 11 } . T onic (T) T onic features are computed like key featur es, but ignor e the mode and instead only use the tonic as anchor . Their value range is { 0, . . . , 11 } . This has the advantage that the learned regularities can be generalized over both major and minor keys. Additionally , ignoring the mode might abstract away fr om certain mistakes in the output of the Krumhansl-Schmuckler algorithm. Fr equent confusions of the algorithm are the identification of the r elative mode, subdominant or dominant as tonic. First-in-Piece (F) Frequently , the first or one of the first pitches equals the tonic of the song. First- in-piece features simply use these pitches as estimate for the tonic. F i for i ∈ N + computes the interval between the current and the i -th tone in the piece. The value range is a subset of all occurring intervals I in the dataset. In contrast to key and tonic features, I decided to use dir ection-sensitive intervals her e, hoping to achieve a surplus in accuracy . This was not possible for key and tonic features, as the respective r efer ence tonics were octave invariant alr eady . PyPulse for Music 43 4.2.3 Linked Features Compound features that do not include a basis feature for the target viewpoint at time σ = 0 will compute the same value for all outcomes s t . As they do not contribute to the model, I call them non-pr edictive . T o become predictive , such features have to occur in compounds that contain predictive basis featur es. According to above definition, metrical weight (M) featur es ar e non-pr edictive. However , M features can be transformed to adopt a predictive nature. For example, the N + operator could be designed to generate compounds of M features and predictive features. P ULSE would select the best compounds after optimization. However , M features on their own, due to their non-predictivity , would not survive the very first round of feature selection. A linked feature is a construct to utilize non-predictive featur es that bypasses the dependency on N + , by initializing non- predictive featur es in predictive compounds. In their simplest form, linked features are length-two compounds of a non-predictive and a predictive feature. More complex compounds are possible, but will not be investigated in this thesis. The bottom part of table 4.1 lists the implemented linked features. In all cases, the value range is the cross pr oduct of the sour ce types. Metrical W eight with Pitch (M P ) M P features ar e compounds of metrical weight and pitch featur es. As M P features model the pitch frequencies per metrical weight, they link pitch values indirectly with their position in the bar . Metrical W eight with Key/T onic (M K /M T ) Similarly to above, M K and M T model the key and tonic in r elation to the metrical weights. These features afford the learning of a chromatic scale degree distribu- tion dependent on the position in the bar . The tonic version provides a higher generalization; the key version a higher precision. 4.3 N + Operations The function of N + in P ULSE is to grow the feature set in every outer loop iteration (see section 3.2). Given the past feature sets, N + has the pivotal role of guiding the search through the feature space. In many cases, its operation is distributed on several sub-N + operators that each ar e active only for specific feature types or PyPulse for Music 44 Abbr . Name V alue Range V Description V I E W P O I N T F E AT U R E S P Pitch P ∈ N chromatic MIDI pitch I Interval I ∈ Z sequential pitch interval O Octave invariant int. { 0, . . . , 11 } intervals modulo 12 semitones C Contour {− 1, 0, 1 } registral dir ection, sign of interval X eXtended contour {− 2, − 1, 0, 1, 2 } as contour but − 2 /2 if interval > 5 M Metrical weight M ∈ N weight within metrical structure N P , N I , N C Negated Pitch, etc. X , I , { − 1, 0, 1 } negated versions of P , I and C A N C H O R E D F E AT U R E S T T onic { 0, . . . , 11 } octave invariant intervals fr om tonic K Key { M, m } × { 0, . . . , 11 } octave invariant intervals from key F 1 First-in-piece I ∈ Z intervals fr om first-in-piece F 1,2,3 First-three-in-piece I ∈ Z intervals from first-thr ee-in-piece L I N K E D F E AT . M P Metrical weight, Pitch M × V P combined metrical weight and pitch M K Metrical weight, Key M × V K combined metrical weight and key M T Metrical weight, T onic M × V T combined metrical weight and tonic T able 4.1: Overview of the implemented feature types. P is the set of all occurring pitches, I the set of all occurring intervals and M the set of all occurring metrical weights in the data. combinations ther eof. Thr ee techniques for growing the temporal extent of com- pound features named forwards , continuous and backwards expansion ar e introduced in this section. It is notable that the N + operator satisfies Pearce and W iggins (2012)’s claim that good models for music should select their own viewpoints. In P ULSE , the algorithm freely constructs the most suitable featur es from a pr edefined construction kit. The responsibilities of N + include the initialization and expansion of the feature set. Let B be an arbitrary basis feature type: • Initialization: The initialization determines which feature types are used. N + B is shorthand notation for the operator that adds type B features with σ = 0 for all ν ∈ V B to the feature set. • Expansion: The ∗ operator is used to indicate expansion of the given types. The operator N + B ∗ initializes the featur e set equally to N + B , and additionally expands features of type B with features f σ , ν of the same type for all ν ∈ V B and σ dependent on the chosen strategy (see sections 4.3.1 and 4.3.2). The notation N + ( B 1 B 2 ) ∗ denotes that B 1 and B 2 features are initialized, and that featur es which contain either type ar e expanded with f σ , ν for all ν ∈ V B 1 and all ν ∈ V B 2 . Such an expansion is also called intermingled expansion . In the remainder of this thesis, feature type names will be used to describe the corresponding N + operators. For example B 1 B 2 B 3 is shorthand notation for the application of the N + operators N + B 1 , N + B 2 and N + B 3 . PyPulse for Music 45 A grammar for music would be the ideal heuristic to construct complex features while keeping the search space at a minimum. However , grammars can to date only be generated for single pieces (Sidorov et al. 2014) with the general solution for entire styles r emaining an open r esearch question (Ler dahl and Jackendoff 1985, 2006; Rohrmeier 2007, 2011). The techniques introduced in this work expand features in all possible dir ections in contrast to a grammar -restricted set of directions. The specific expansion methods are explained in the following, separately for the L TM and STM. 4.3.1 Long-T erm Model In the L TM, training works by repeatedly running iterations of the outer loop on a training dataset until the feature set conver ges. Hence, N + can learn from pr evious iterations by considering the current feature set, and even from the acceptance rates of its proposed candidate featur es. Backwards Expansion Lieck and T oussaint (2016) suggested a feature expansion method that expands features backwar ds in time and constr ucts generalized n -gram features. Lieck and T oussaint aimed at describing delayed causalities in reinforcement learning. This intention still holds in the context of melody pr ediction, as each note may depend on an arbitrary selection of preceding notes. I pick up on a variation of Lieck and T oussaint’s approach called ‘gradual tem- poral extension’ that expands featur es stepwise into the past, and for which con- vergence has been proven. Let F B ⊂ F denote the set of all compound features of viewpoint B after optimization and shrinking. The expansion in iteration i is then defined by N + B ∗ ( F ; i ) = g ∃ f ∈ F B , ν ∈ V B : g = f ∧ f i + 1, ν . (4.5) A global time index i is incremented every outer loop iteration, and determines the time of the newly added features f σ , ν to be σ = i + 1. Features f i + 1, ν are added to each compound f for all allowed values ν in V B . That means there are | V B | many new features per compound of type B . After n expansions, if no features wer e removed, the feature set would encompass the set of all contiguous and generalized n -grams. Remember that time index i describes the previous time steps, consequently all expansions according to equation 4.5 ar e done back in time. PyPulse for Music 46 The N + operator is based on assumptions and knowledge about the structur e of the underlying data, to effectively serve as a sear ch heuristic through the featur e space. These assumptions are that (1) expansions of short relevant featur es are likely to be relevant as well, and (2) that a once irr elevant feature will not r egain r elevance, irrespective of the expansion. Features ar e assumed to be r elevant if they survive L 1 regularization, and irrelevant otherwise. T ranslated to music, this means that N + aims at expanding r elevant motifs or patterns of musical attributes, wher eas it expects that non-relevant motifs or patterns will only get less probable, if expanded. 4.3.2 Short-T erm Model The STM distinguishes fr om the L TM in that the training dataset grows over time and is generally much smaller . P ULSE could be applied to the STM scenario without any alterations by fitting a new P ULSE instance on every time index of the song. However , this would require a huge number of outer loop iterations per song and is rather inefficient, considering that only one datum is added to the training set per call. Thus, for the STM, the outer loop is reduced to a single iteration per fit and the N + expansion is modified to take only the newest datum into account. This trade comes at the cost of giving up on having holes in the rendered n -gram features, but enables an ef ficient incremental learning of the STM. On the implementation side, PyPulse is adapted to carry over the model’s state between subsequent fittings of the learner . The for the STM specialized N + operators are described in the following. Continuous Expansion The essence of continuous expansion matches that of backwards expansion, with the exception that it does not r equire a global iteration counter . Instead, time index i is computed fr om the maximum temporal extent of the curr ent compound featur e by incrementing it by one: N + B ∗ ( F ) = g ∃ f ∈ F B , ν ∈ V B , i = max-depth ( f ) : g = f ∧ f i + 1, ν (4.6) While this method af for ds learning of features without r equiring any time or counter input, it prevents the occurr ence of holes: the features learned are contiguous n -grams. Note that for every new datum s t the features are only expanded by one time step. That means that the full set of n -gram features for datum s t will only be reached, if no features were to be removed, after n − 1 more features wer e added at time t + n − 1. This is wasteful information processing, considering that the data in the PyPulse for Music 47 STM was rar e in the first place. However , it is yet to be seen that motifs and patterns that have just occurred ar e more r elevant for the prediction of the next note, than those that lie further back in a piece. Forwards Expansion Forwards expansion addr esses the shortcomings of continuous expansion by gener- ating the set of all t -grams at song index t , if no features were to be r emoved. This is achieved by adding featur es to the fr ont of the context, rather than to the tail. For this, the time indices of all featur es in the compound are first shifted back by one time step (operator f − 1 ), and then new featur es are added for time σ = 0 and all values ν ∈ V B . Forwards expansion is formalized as N + B ∗ ( F ) = g ∃ f ∈ F B , ν ∈ V B : g = f − 1 ∧ f 0, ν . (4.7) In forwards expansion, the algorithm is given full control over the decision whether the most recent motifs and patterns, or those that lie further back, are more r elevant. Thus, it constitutes the principally more capable extension method for the STM. 4.4 Regularization Regularization pr ovides – in addition to the choice of the featur es and N + operator – another means of injecting prior knowledge into the model. Equally important, regularization also provides a means to curb overfitting. This section discusses these aspects of regularization, with r espect to their r ealization in PyPulse for music . T o inject prior knowledge, we can on the one hand add new regularization terms to the objective, and on the other hand change the regularization strength or factor . These modifications influence which features are removed from the set by L 1 regularization and affect the weights of the features that are kept. The N + expansions in subsequent outer loop iterations directly depend on the selected feature sets and thus on the regularization. In consequence, the final featur e set is shaped through an interplay of the N + operator and regularization. Regularization curbs overfitting by penalizing the feature weights with an extra term in the objective 1 . The goal is to find a balance between an overly precise fit (overfit) and a too loose fit on the data. Different regularization terms show differ ent characteristics. The L 1 regularization term, which is mandatory in P ULSE , penalizes 1 Recall that in the case of L 1 -regularized SGD optimization, the penalty term is not directly added to the objective (see section 2.3.3). PyPulse for Music 48 weights linear to their size. T o discourage larger weights disproportionately , I added an L 2 regularization term (in Bayesian terms a Gaussian prior) to the objective. Per-featur e r egularization allows to penalize certain featur es more than others, based on knowledge of the problem domain. Specifically , it can guide feature selection more pr ecisely . Assuming that the next tone in a melody depends more on the direct pr edecessors than on far back tones, I introduce a range of r egularization factors ρ ( f ) that depend on the features’ maximum temporal extent. At this stage of resear ch, all featur e types are tr eated equally . The maximum temporal extent ∆ f of a feature f ( x , y ) is the maximum time that the feature is looking back in x . The value ∆ f also constitutes an upper bound to the length of the featur e. Let λ 1 and λ 2 be the global r egularization factors for L 1 and L 2 regularization, r espectively . The per-featur e r egularization factor λ f for L 1 and L 2 regularization is then computed with λ f ,1 /2 = λ 1/2 · ρ ( f ) . (4.8) Let α > 0 be a free parameter . The following functions ρ wer e implemented: constant: ρ ( f ) = 1 (4.9) linear: ρ ( f ) = α · ∆ f (4.10) linear without zero: ρ ( f ) = α · ∆ f + 1 (4.11) polynomial: ρ ( f ) = ( ∆ f ) α (4.12) exponential: ρ ( f ) = ( α ) ∆ f (4.13) exponential with zero: ρ ( f ) = ( α ) ∆ f ∆ f > 0 0 otherwise (4.14) Note that in this work the anchored features are defined to have ∆ f = 0. As a consequence, they remain unregularized for the linear and polynomial function, and are r egularized accor ding to factor λ 1/2 for the other functions. In the STM, the r egularization situation changes a lot during the pr ogr ession of a song. Most notably , the amount of training data in the beginning and end of a song dif fers considerably . Consequently , the STM requires a time dependent regularization that is adapted to the amount of data. This was implemented by temporally decaying the r egularization factor λ 1/2 . Assuming a stronger Gaussian prior in the beginning of the song, injects the prior knowledge that it is initially more likely that new melodic patterns ar e intr oduced than that old ones ar e repeated. The new dynamical factor λ 1/2 , which serves as input for the per-feature function in PyPulse for Music 49 equation 4.8, is computed as λ 1/2 = λ init 1/2 · exp ( − t τ 1/2 ) , (4.15) given time index t , initial global regularization factor λ init 1/2 , and temporal decay parameter τ 1/2 . 4.5 Inference One may use inference on models of music to employ them as a cognitive model, to generate music, or to evaluate their performance. This section focuses on the latter two usages, and specifically on proving that the learned models af ford a fruitful basis for music synthesis. Additionally , I intend to round off this thesis of Computer Science by making the learned models audible. My motivation however is clearly distinct fr om the generation of music in the sense of algorithmic composition, which is sur ely out of scope for this thesis (for a review of composition methods see Papadopoulos and W iggins (1999)). In PyPulse , pr edictions are made one note at a time. The synthesis of entire sequences requir es additional thought. In line with my goals, I am not inter esting in sampling a musical extravaganza, but rather to use the simplest method for finding a minimal cross-entr opy sequence s 0: m , m ∈ N for a given model. I consider two methods that are briefly outlined in the following. Beam sear ch (Manning 2017) maintains k slots (beams) holding one sequence each. In every round, each of these sequences is extended with the k likeliest subsequent events. All k × k extensions then compete for the k slots in the next round. This allows the algorithm to recover from greedy choices that otherwise would have lead to a local optimum. Manning reports the method to fr equently perform very well, although it is not guaranteed to find the global optimum. Iterative random walk (Whorley , W iggins et al. 2013) is an extension of the math- ematical random walk. Starting with an initial event or sequence s 0: t − 1 at time t , firstly , the conditional distribution p ( s t | s 0: t − 1 ) is computed. Secondly , the next event is sampled with pr obabilities accor ding to the computed conditional distribution. The event is concatenated to the context and the whole process is repeated. In iterative random walk, random walks are r un repeatedly until suf ficiently good en- tropy r esults ar e achieved. T o prevent low pr obability choices that thwart the result, Whorley and Conklin (2016) intr oduced the constraint that a sample’s likelihood has to exceed a certain threshold. Chapter 5 Model Selection In the scope of this thesis, the PyPulse for music framework was thoroughly fine-tuned for musical data by optimizing the free variables and selecting the best regularization functions as well as N + operations. The impact of each hyperparameter , that means meta-variable of the learning algorithm, is discussed and its optimal value is determined. This chapter is structured as follows: Sections 5.1.1 and 5.1.2 introduce the corpus and evaluation measure used for assessing the model’s predictive capacities. In section 5.1.3, I outline Gaussian processes which ar e used for the optimization of the regularization parameters. Cr oss-validation is explained in section 5.1.4. It is used in the computation of model benchmarks to ensure comparability . Section 5.2 is concerned with the tuning of all SGD r elated hyperparameters to facilitate a quick learning, and with the choosing conver gence criteria for the SGD and featur e discov- ery loops. Finally , sections 5.3 and 5.4 compare the various per -featur e regularization terms and N + operations of the PyPulse for music framework. 5.1 Methodology This section introduces the evaluation corpus and measure, cr oss-validation, and Gaussian process based hyperparameter optimization. The intr oduced methodolo- gies are used for the experiments in the r emainder of this chapter and in chapter 6. 5.1.1 Corpus PyPulse for music operates on symbolic music r epr esentations in the 12-tone equal temperament system, most notably on sequences of chromatic pitches. A vast 50 Model Selection 51 ID Description Melodies Mean events/melody | X | 0 Canadian folk songs/ballads 152 56.270 26 1 Bach chorales (BWV 253-438) 185 49.876 21 2 Alsatian folk songs (EFSC) 91 49.407 32 3 Y ugoslavian folk songs (EFSC) 119 22.613 25 4 Swiss folk songs (EFSC) 93 49.312 34 5 Austrian folk songs (EFSC) 104 51.019 35 6 German nursery r hymes (EFSC) 213 39.404 27 7 Chinese folk songs (EFSC) 237 46.650 41 T otal Events: 54308 1194 45.484 45 T able 5.1: The benchmark datasets, as first introduced by Pearce and W iggins (2004), which I refer to as Pear ce corpus in the following. amount of digitized sheet music is available online, in a variety of formats. The Center for Computer Assisted Resear ch in the Humanities at Stanford University hosts more than 100,000 **kern files (Hur on 1997), and makes them freely available. Other notable music notation formats are: abc, for which more than 500,000 digital music sheets are available, the widely supported MusicXML format, and the MIDI format which poses the de facto standard in digital music r epr esentation. Pearce and W iggins (2004) selected and established a benchmarking corpus of 1,194 multifaceted melodies from the **kern repertoir e. The Pear ce corpus 1 comprises eight sets of melodies of dif fer ent style and origin (see table 5.1). These are: Canadian folk songs and ballads fr om Nova Scotia, soprano lines of chorales BWV 253-438 harmonized by J. S. Bach, and folk melodies of Helmut Schaffrath’s (EFSC). The EFSC datasets are Alsatian, Y ugoslavian, Swiss and Austrian folk songs, German nursery rhymes and Chinese pieces fr om the pr ovince Shanxi. I parse the data using the Python musicology toolkit music21 (Cuthbert and Ariza 2010), which supports the most popular symbolic music file formats MusicXML, MIDI, **kern and abc. Respecting the prior work on the Pearce corpus, I modify the music notation by mer ging all ties into single notes and deleting all rests. The alphabet X is defined for each of the eight datasets to be the respective set of uniquely occurring pitch values. 1 http://webprojects.eecs.qmul.ac.uk/marcusp/ Model Selection 52 5.1.2 Evaluation Measures The performance of a computational model for music is measured by its outputs, which are the pr edictive distributions. Differ ent kinds of measur es have been used in the past: • Information theoretic cr oss-entr opy has been used as a quantitative measure in the majority of prior r esear ch; for example Cherla, T ran, Gar cez et al. (2015), Conklin and W itten (1995) and Pearce and W iggins (2004), just to name a few . In melody pr ediction, the cr oss-entropy H c ( p , q ) between the learned model p and the data distribution q cannot be computed directly , as the true data distributions is unknown. Thus, typically H c is approximated by a Monte Carlo estimate between p and the test dataset D test with H c ( p , D test ) = − ∑ x , y ∈ D test log 2 p ( x | y ) | D test | . (5.1) This approximation is dir ectly linked to the geometrical mean G M with H c = − log 2 ( G M ) . Note that cross-entr opy is a natural choice in PyPulse for music as it matches the employed negative log-likelihood objective ` ( θ ; D test ) with no r egularization (see section 2.2.2): H c ( p , D test ) = ` ( θ ; D test ) / | D test | (5.2) Shannon’s coding theorems fr om 1948 motivate the interpretation of the mod- els from a data compression perspective. There, entr opy describes the lower bound for the number of bits needed to encode a symbol of the alphabet X . Lower values thus stand for better compression. In the context of prediction, a lower number of bits means that the model is more likely to pr edict the true outcome. • Regarding the cognitive sciences, a good model is one that accurately simulates human expectations. Agres et al. (2017), Pear ce (2005) and Pear ce and W iggins (2006) compared the outputs of computational models with psychological data. • Evaluation by synthesis of new original pieces is a measur e mostly used in algorithmic composition. Conklin and W itten (1995) noted that a better pr e- dictive model will generally be able to generate a better piece. However , T riviño-Rodriguez and Morales-Bueno (2001) remarked that it is hard to quan- tify the quality of generated pieces. Instead, they used auditory experiments as Model Selection 53 criteria of goodness. Whorley and Conklin (2016) evaluate their compositions by counting violations of a set of rules, in addition to using cr oss-entropy . • The classification accuracy is a simple machine learning measur e for multiclass classifiers. For classifier g and data label pairs ( x , y ) ∈ D test , it is computed as the unweighted empirical classification err or 1 | D test | ∑ x , y ∈ D test I ( g ( x ) , y ) . Conklin (2013) uses this measure to classify folk tune genr es and r egions. I will use all of the above measures in this thesis, but focus on cross-entropy as a reliable benchmark for comparing my results internally and with state-of-the- art models. 5.1.3 Gaussian Process Based Optimization It is hard to determine the optimal hyperparameter values manually . Thus, algo- rithms such as grid search, random search or Gaussian process (GP) based Bayesian hyperparameter optimization are employed. Especially when the search space is of high dimensionality and when samples ar e expensive to obtain, GP based opti- mization seems most appealing as it samples based on educated guesses. GP based optimization is a Bayesian technique in which a GP prior distribution is chosen to describe the unknown function under optimization (Snoek et al. 2012). A GP surrogate model is maintained for the unknown function, and updated with every newly obtained sample value in the course of optimization. Based on the surrogate model’s uncertainty and mean, which are known in every point, exploration of the parameter space and exploitation of the surrogate are balanced to determine the optimal next sampling location. The over head of computing the surr ogate model is in my case easily outweighed by the sampling costs. I utilize the Scikit-Optimize framework 2 for GP based optimization based on a Matern kernel and with using expected improvement as acquisition function. I would like to conclude by discussing the advantages and disadvantages of grid search and GP based hyperparameter optimization. Grid search persuades by shorter runtimes for coarsely spaced grids, easily interpretable results when interpolated as curves over the grid, and few hyperparameters. However , it is almost certain that the optimum is never hit pr ecisely , which intr oduces noise into the benchmarks. Prior experiments using grid search showed an impaired comparability , irrespective of the grid spacing (I tested a grid of 5, 7 and 11 samples). In contrast to that, GP based optimization can be expected to find the optimum 2 https://scikit- optimize.github.io Model Selection 54 precisely , but requir es a multiple in samples (compared to the afor ementioned grid sizes). As samples are expensive to acquire, the increased precision comes at the cost of a higher runtime. On the downside, GP based algorithms are more complex than grid search as they have several fr ee hyperparameters themselves. For finding the best N + configuration, comparability between performances for differ ent configurations is vital. Thus, GP based optimization was used for precisely finding the regularization parameter optima in the L TM and STM. 5.1.4 Cross-V alidation T o evaluate the test performance of a model, one should always utilize left-out data that the model has not been trained on. Thus, the dataset is split into a training and test dataset. T raining the model on one dataset and evaluating it on the other one is called a split-sample or hold-out approach. Hold-out evaluation has the considerable disadvantage that, if data is not abundant, performances calculated in this way do not generalize well. Consequently , the results will vary with the choice of the two sets and their validity will be limited. Smaller training sets induce a higher bias, and smaller test sets induce a higher variance of the model. Dietterich (1998) introduced k -fold cross-validation (CV), a model selection method that makes better use of the data than hold-out validation. The data is split into k equally sized folds. In each of k iterations, one varying fold is used as test set whereas the r emaining k − 1 are used as training set. The r esulting k performances are averaged to obtain the final CV performance. Along with their benchmarking corpus, Pear ce and W iggins (2004) established the use of 10-fold CV 3 . Using k = 10 folds is considered to be a good balance of the bias-variance trade-off. T o facilitate comparability with other work on the Pearce corpus, I use 10-fold CV and identical fold indices wher ever I compute corpus benchmarks. Per fold, I use GP based hyperparameter optimization on a held out validation set (a small subset of the training set), to find the best values for the regularization strength λ 1/2 . For the majority of the remaining hyperparameters, I fr equently fall back on hold-out validation with grid search instead of GP based optimization minimize the computing time. 3 See http://webprojects.eecs.qmul.ac.uk/marcusp/ for the fold indices of the Pearce corpus. Model Selection 55 5.2 Reducing Computational Expenses The PyPulse for music framework ships with a whole range of free hyperparameters. In this section, the SGD optimization’s hyperparameters are tuned. This is important to ensure the learning success and further aims at accelerating the pace of learning. In section 5.2.1, firstly , the SGD optimizers AdaGrad and AdaDelta ar e tuned to achieve minimal objective values within a given time frame. Secondly , the two optimizers ar e compar ed against each other with r espect to these values. The convergence parameters ar e set in section 5.2.2, to prevent computational r esources being spent on insignificant improvements. Last but not least, the potential in hot-starting the optimization for reducing computational expenses is explored in section 5.2.3. T able 5.2 gives an overview of the best found hyperparameters. W e assume all hyperparameters tuned in this section to be music specific but corpus independent. Hence, the 185 Bach chorales (dataset 1) are used for all experiments. Realm Best Parameters Optimization AdaGrad, η = 1.0, igsav = 10 − 10 Hot-Starting activated Convergence SGD γ inner , active = 5 · 10 − 3 , τ inner , active = 0.9 γ inner , loss = 5 · 10 − 5 , τ inner , loss = 0.9 Convergence Featur e Selection by featur e set fluctuation, γ outer = 0.01 T able 5.2: The tuning results for the optimizer and conver gence parameters. 5.2.1 T uning and Comparing AdaGrad and AdaDelta This section aims at giving answers to the following questions: (1) How do the optimization parameters influence learning? (2) How fast is a relative convergence achieved? And (3), within a given number of training epochs, does AdaGrad or AdaDelta perform better? For that, AdaDelta’s enhancement with a learning rate parameter as described in section 3.2.1 is considered, too. The negative log-likelihood (see section 2.2.2) of the training data serves as optimization objective and as performance measure in this section. The results show that, after tuning, AdaGrad achieves better objective values than AdaDelta, and does so significantly faster . Model Selection 56 Experiments The basic experimental setup was to have both optimizers minimize the objective for a limited number of 100 and 500 training epochs. The set of the 1-, 2- and 3-grams of all possible pitch sequences within this corpus was precomputed (9,723 featur es), without using the N + operator , and served as the feature set. The fr ee parameters of each optimizer wer e tuned in a combined grid sear ch: For AdaGrad, the free parameters are the learning rate η and the initial gradient squar ed accumulator value igsav (see section 2.3.1), which were evaluated over the two- dimensional grid with η ∈ { 0.01, 0.1, 1.0, 10.0 } and igsav ∈ { 10 − 6 , 10 − 7 , . . . , 10 − 12 } . V anilla AdaDelta has decay rate parameter ρ and conditioning constant e in the computation of the EMA (see section 2.3.2). AdaDelta was evaluated on the grid over ρ ∈ { 0.85, 0.9, 0.95, 0.99 } and e ∈ { 10 − 3 , 10 − 4 , . . . , 10 − 9 } , while keeping the additional learning rate parameter η = 1.0 to obtain the original update scheme. Subsequently , with the best values for ρ and e , the learning rate η was evaluated over the values η ∈ { 1, 10, 100, 1000 } . Results T able 5.3 shows the results from the described experiments. The objective values on the two-dimensional parameter grid were interpolated and color encoded to pr ovide an intuitive view on the results. Red colors repr esent high objective values, gray colors low values. Contour lines are drawn in intervals of 0.02. The interpolation encourages the sensible intuition that the values between the computed grid points can be assumed to continue smoothly . However , this representation disr egar ds that an optimum may lie in between grid points. The exact objective values are given in appendix B. T able 5.3a and 5.3b show the r esults for the AdaGrad optimization. Regarding (1), the first observation to make is that the learning rate η has a lar ger influence than igsav . Especially , values of igsav smaller than 10 − 9 do not alter the results noticeably . For optimal values η and igsav , the gain from training for another 400 epochs is small. T o answer (2), the optimization appears to have converged before or ar ound 100 training epochs. In table 5.3c and 5.3d the r esults for the decay rate parameter ρ and conditioning constant e are pr esented. The results confirm Zeiler (2012)’s findings that AdaDelta is robust in the choice of ρ and e . T o answer (1), we can say that the parameters effect on the performance is negligible, especially if e is chosen between 10 − 3 and 10 − 7 . For question (2) however , we r ealize that the optimization did not conver ge after 100 epochs and presumably also not after 500 epochs. Model Selection 57 igsav 10 − 6 10 − 7 10 − 8 10 − 9 10 − 10 10 − 11 10 − 12 η 0.01 0.1 1.0 • 1.549 10.0 (a) AdaGrad after 100 epochs igsav 10 − 6 10 − 7 10 − 8 10 − 9 10 − 10 10 − 11 10 − 12 η 0.01 0.1 1.0 • 1.540 10.0 (b) AdaGrad after 500 epochs e 10 − 3 10 − 4 10 − 5 10 − 6 10 − 7 10 − 8 10 − 9 ρ 0.85 0.90 0.95 0.99 • 2.011 (c) AdaDelta after 100 epochs ( η = 1) e 10 − 3 10 − 4 10 − 5 10 − 6 10 − 7 10 − 8 10 − 9 ρ 0.85 0.90 0.95 0.99 • 1.776 (d) AdaDelta after 500 epochs ( η = 1) η 1 2.011 10 1.716 100 1.595 1000 1.605 (e) AdaDelta for differ - ent learning rates after 100 epochs η 1 1.776 10 1.616 100 1.554 1000 1.601 (f) AdaDelta for differ- ent learning rates after 500 epochs 1.5 1.6 1.7 1.8 1.9 2.0 2.1 2.2 T able 5.3: The objective values (negative log-likelihood) after 100 and 500 epochs of minimization using AdaGrad and AdaDelta with various hyperparameter settings. The values are color encoded accor ding to the above legend. For the exact values please see appendix B. Model Selection 58 T able 5.3e and 5.3f show that the tuning of the added learning rate η has a tremendous ef fect on the convergence speed of AdaDelta. Choosing η = 100 makes the objective values significantly mor e competitive. Still, training for 500 instead 100 epochs improves the performance further . Regarding (3), AdaGrad achieves immensely better results than vanilla AdaDelta, after both 100 and 500 epochs. T uning the learning rate parameter for AdaDelta starkly reduces this gap, but still leaves AdaGrad to be the clear winner . In summary of AdaDelta’s benefits, Zeiler writes that good – though less than optimal – results can be achieved without tuning any of the algorithm’s parameters. In this experi- ment, we observe that a suboptimally tuned AdaGrad still outperforms an optimally tuned AdaDelta. W e will use the AdaGrad optimizer with η = 1 and igsav = 10 − 10 in the following. 5.2.2 Detecting Convergence The next hyperparameters we look at address the convergence of SGD optimization and the featur e discovery loop. As described in section 3.2, the SGD optimization loop runs until convergence of either (1) the objective or (2) the active featur e set, whatever comes first. The feature discovery loop is exited when the feature set converges, that means when it stops altering. The convergence criteria are chosen to avoid futile loop iterations to save computational expenses. An early (pr ematur e) stopping (Prechelt 1998) of the optimization or feature discovery is avoided, as it introduces another layer of regularization which may distort the results of the regularization parameter selection in section 5.3. The decay rate parameter τ inner , loss and the convergence thr eshold γ inner , loss of the inner loop criterion (1) (see equation 3.3) were determined in preliminary ex- periments. Parameters γ inner , loss = 5 · 10 − 5 and τ inner , loss = 0.9 for criterion (1) wer e chosen strictly to ensure a tight convergence. T ypically criterion (2) (see equation 3.4) will end the optimization much earlier than criterion (1), which then serves as a lower bound. In the following, the thr ee conver gence criteria for the feature discovery loop (see section 3.2.5) are analyzed in combination with the inner loop criterion (2). Experiments T o analyze the interplay of the outer loop criteria and the inner loop criterion (2), we consider a two-dimensional grid with value ranges γ inner , active , γ outer ∈ { 0.05, 0.01, 0.005, 0.001 } in each dimension. This is repeated for all three outer Model Selection 59 loop convergence criteria. Decay rate τ inner , active is chosen equal to τ inner , active to 0.9. As performance measure serves the cr oss-entropy on a randomly drawn test set of 10% size of the full corpus. The model was configured to use exponential per-featur e L 1 regularization (see section 4.4), with λ 1 = 10 − 8.5 , α = 2.0 and a PI*C*-N + configuration. Results The computed test entropy values are given in table 5.4. The three tested convergence criteria show similar performances, with criterion (a) being the short winner . For all three criteria, the prime observation to make is that the influence of γ outer on the result is smaller than that of γ inner , active . W e can further observe, that the minimum value for γ inner , active did not lead to the best performances. I speculate that this is due to a regularizing ef fect caused by early stopping of the optimization. Note that choosing either conver gence threshold smaller leads to a big incr ease of execution time. On the one hand, we want to avoid a bleeding of the convergence parame- ters into the regularization parameters. On the other hand, stopping early saves computational resources. As a trade-off between time and performance I choose γ inner , active = 0.005 to be at its optimum, but save resour ces by setting the less influential γ outer = 0.01. 5.2.3 Hot-Starting AdaGrad W e saw that tuning the SGD optimizer ’s parameters can have a tr emendous ef fect on the speed of learning. Now , we will consider another means to reduce computational expenses linked to the optimization. In PyPulse , the optimizer is called in every feature discovery loop iteration. Hot-starting of the optimizer was proposed in section 3.2.4 as a means to speed up each run by taking over the accumulator values from the previous run. In this section, we will see that hot-starting AdaGrad can lead to a noticeable reduction of training epochs and impr ove the objective value. Experiments P ULSE was run for 10 featur e discovery loop iterations with and without hot-starting. The learner was configur ed to use exponential L 1 regularization with λ 1 = 10 − 8.5 , α = 2.0, PI*C* N + and the same training and validation set as in section 5.2.2. The inner loop convergence parameters (optimization) were set to the optima fr om above Model Selection 60 γ inner , active 0.05 0.01 0.005 0.001 γ outer 0.05 2.309 2.274 2.264 2.272 0.01 2.292 2.273 2.261 2.273 0.005 2.292 2.270 2.261 2.271 0.001 2.287 2.267 2.257 2.269 (a) Convergence by featur e set fluctuation. γ inner , active 0.05 0.01 0.005 0.001 γ outer 0.05 2.281 2.279 2.277 2.269 0.01 2.275 2.275 2.268 2.272 0.005 2.271 2.276 2.268 2.269 0.001 2.271 2.273 2.266 2.269 (b) Convergence by featur e set size. γ inner , active 0.05 0.01 0.005 0.001 γ outer 0.05 2.280 2.282 2.266 2.280 0.01 2.275 2.275 2.268 2.272 0.005 2.275 2.276 2.268 2.271 0.001 2.271 2.273 2.266 2.269 (c) Convergence by validation err or . T able 5.4: The test entr opies for differ ent feature discovery loop convergence criteria and convergence thr esholds for the inner and outer loop. and the outer loop was set to r un for 10 iterations. As measure of goodness serves the objective values and number of training epochs until convergence. Results From the r esults shown in table 5.5, we learn that hot-starting results in small gains in terms of the loss function as well as optimization duration. The featur e set expansion stagnated from iteration 6 on; the improvements up to then are ∼ 1% for the loss (in iteration 5) and ∼ 1% for the number of epochs (iteration 1 to 5). From iteration 6 to 10, the number of new features ceases to gr ow and the effect of hot-starting shows in a faster convergence: The weights and accumulator values are close to an optimum, the repeated expansion with almost identical candidate sets is not impr oving the objective, and ther efor e the loss-based conver gence criterion Model Selection 61 hot-start off hot-start on iteration objective epochs objective epochs 1 1.902 58 1.902 58 2 1.678 69 1.678 62 3 1.563 59 1.563 57 4 1.477 57 1.476 55 5 1.441 55 1.433 54 6 1.429 54 1.421 53 7 1.427 53 1.417 41 8 1.426 53 1.414 28 9 1.426 53 1.413 20 10 1.420 90 1.412 2 T able 5.5: The objective values and number of training epochs per featur e discovery loop with (hot-start off) and without reset (on) of the AdaGrad and L 1 accumulators between iterations. stops the learning. In contrast, without hot-starting, the optimizer has to r elearn the accumulator and what features ar e the most meaningful ones. Note that SGD conver gence by the active featur e set never got trigger ed before epoch 53. This is due to the inertia of the EMA with decay rate τ inner , active = 0.9 in combination with a small choice of γ inner , active . Thus, the benefits of hot-starting were in this experiment partially hidden by the small convergence thr eshold. Repetitions of the experiment with differ ent convergence parameters showed a similar picture. Having higher convergence threshold showed even stronger ef fects in the number of saved training epochs ( > 10%). Due to its side-effect free benefits, I will use hot-starting in all remaining experiments and benchmarks. 5.3 Reducing Overfitting T uning the r egularization parameters means reducing overfitting. Additionally , employing per-featur e regularization terms, as introduced in section 4.4, injects top-down knowledge into the model and improves performance in general. W e assume that the regularization terms are specific for music but dataset independent, and that only the global regularization factors depend on the r espective dataset. The Bach chorales (dataset 1) were used for all experiments in this section. It is shown that the L TM and STM perform best with L 1 plus L 2 regularization. Because of the temporal nature of the STM, a time dependent L 1 and L 2 regulariza- tion is additionally investigated, and thought to be good. Model Selection 62 Model Best Regularization Parameters L TM exponential L 1 ( α = 2.0), constant L 2 (per-featur e L 2 not tested) STM exponential L 1 ( α = 1.2), constant L 2 , temporal decay of L 1 and L 2 , τ 1 can be kept fixed T able 5.6: Overview of the tuning results for the r egularization hyperparameters. 5.3.1 L TM Regularization T erms It is shown that for the L TM, the performance of the L 1 -regularized P ULSE model can be impr oved by penalizing the maximum featur e depth exponentially , and by adding L 2 regularization to the objective. Experiments In a first step, to learn by what degree L 2 regularization can impr ove the model, the best combination of L 1 and L 2 regularization was found on the grid λ 1 ∈ { 10 − 6 , 10 − 7 , 10 − 8 , 10 − 9 } and λ 2 ∈ { 0.0, 10 − 12 , 10 − 11 , 10 − 10 , 10 − 9 , 10 − 8 , 10 − 7 } . In a second step, the differ ent feature depth dependent regularization functions (see section 3.2.2) were compar ed for L 1 regularization and dif fer ent parameterizations. For that, a finer spaced grid with λ 1 ∈ { 10 − 7 , 10 − 7.5 , 10 − 8 , 10 − 8.5 , 10 − 9 } was used. The convergence parameters were set to γ outer = 0.05, γ inner , loss = 5 · 10 − 5 and γ inner , active = 0.01. As N + configuration, PI*C* was used. The performance was measured in cr oss-entropy bits, on a randomly drawn test set of 10% size of the full dataset (as in section 5.2.2). For computational reasons, the feature discovery loop was stopped after the feature set size exceeded 2,000. Hence, the found performances are worse or equal to their true optimum. Results The prime observation to be made fr om table 5.7 is that adding L 2 regularization con- siderably impr oves the performance of the L TM. On the downside, L 2 regularization increases the featur e count and with it the runtime. L 2 regularization encourages many features with small weights, whereas L 1 regularization encourages smaller feature sets with lar ger weights. In consequence, the two counteract each other . For the following two r easons I use L 1 regularization despite the worse perfor- mance regar ding the L TM: (1) According to Occam’s razor , the simpler model is preferable. The L 1 -only model has less hyperparameters and much fewer weights. Model Selection 63 Benefits may include a better generalization performance, and an increased musico- logical interpretability of less but mor e expressive features. (2) The practicability of the model and method is at stake when the runtime exceeds the user ’s patience. Especially , the hyperparameter selection during 10-fold CV is immensely time- consuming. λ 2 0 10 − 12 10 − 11 10 − 10 10 − 9 10 − 8 10 − 7 λ 1 10 − 6 2.743 2.743 2.743 2.743 2.743 2.745 2.767 10 − 7 2.386 2.386 2.386 2.386 2.381 2.384 2.452 10 − 8 2.374 2.379 2.376 2.380 2.347 2.287 2.376 10 − 9 2.460 2.459 2.451 2.417 2.354 2.335 2.422 T able 5.7: Joint L 1 and L 2 regularization in the L TM. T able 5.8 lists the r esult of the per-featur e regularization terms, for differ ent parameterizations. It is striking that all depth dependent terms performed better than a constant global factor (const.). The exponential factor with α = 2.0 is the tight winner . In general, the polynomial and exponential appr oaches performed better than the linear ones. Whether featur es with depth zer o ar e regularized or not was deemed relevant. However , the results show that neither shifting the linear factor up by one to reg- ularize zero-depth features (lin-no-0), nor modifying the exponential term to not regularize zer o-depth featur es (exp-0), performed better than the original functions. 5.3.2 STM Regularization T erms From the analysis of combined L 1 and L 2 regularization, we learn the significance of L 2 for the STM. Furthermore, we see that a temporal decay of the r egularization parameters improves the performance. Experiments The many free parameters of the STM were evaluated one-by-one, instead of jointly . I determined, (1) whether L 2 regularization is beneficial on a combined grid over λ 1 and λ 2 with λ 1 ∈ { 10 − 2 , 10 − 3 , . . . , 10 − 7 } and λ 2 ∈ { 10 − 2 , 10 − 3 , 10 − 4 , 10 − 5 , 0.0 } , (2) the best L 1 per-featur e r egularization term and parameter α , Model Selection 64 const. linear lin-no-0 λ 1 1.0 0.5 1.0 2.0 4.0 0.5 1.0 2.0 4.0 10 − 7 2.386 2.346 2.427 2.485 2.533 2.441 2.490 2.516 2.563 10 − 7.5 2.360 2.302 2.313 2.367 2.442 2.313 2.344 2.393 2.463 10 − 8 2.374 2.340 2.301 2.294 2.327 2.343 2.307 2.300 2.333 10 − 8.5 2.368 2.333 2.357 2.328 2.300 2.359 2.330 2.354 2.301 10 − 9 2.460 2.441 2.377 2.328 2.333 2.378 2.346 2.330 2.328 polynomial exponential exp-0 λ 1 0.5 2.0 4.0 1.2 1.5 2.0 2.5 2.0 10 − 7 2.387 2.460 2.511 2.407 2.463 2.499 2.518 2.493 10 − 7.5 2.324 2.363 2.455 2.306 2.328 2.382 2.426 2.378 10 − 8 2.351 2.308 2.392 2.363 2.287 2.301 2.333 2.300 10 − 8.5 2.343 2.276 2.333 2.331 2.321 2.274 2.290 2.289 10 − 9 2.423 2.307 2.302 2.420 2.362 2.318 2.292 2.301 T able 5.8: Comparison of dif ferent per -featur e regularization functions and parame- terizations in the L TM. (3) the best L 2 per-featur e r egularization term and parameter α , (4) whether temporal decay of λ 1 and λ 2 improves the performance, and (5) the impact of each of the parameters λ init 1 , λ init 2 , τ 1 and τ 2 on a four -dimensional grid over λ init 1 ∈ { 10 − 2 , 10 − 3 , 10 − 4 , 10 − 5 } , λ init 2 ∈ { 10 − 1 , 10 − 2 , 10 − 3 , 10 − 4 } and τ 1 , τ 2 ∈ { 1, 10, 100 } . Note that for (2) and (3) only the exponential term was evaluated based on the experience from the L TM per-feature regularization results. For the value ranges see tables 5.10 and 5.11. Experimental setup for (5): For each parameter ϕ ∈ { λ init 1 , λ init 2 , τ 1 , τ 2 } and value within its value range, a three-dimensional grid sear ch was performed over the r emaining parameters and their value ranges r espectively . The best achieved performance for each value of ϕ was stor ed. For computational reasons, the training/test dataset was made up of only 10 out of 185 randomly chosen Bach chorales. The P*IC-N + configuration was employed. Results (1): It is striking how much performance was gained by adding L 2 regularization (see table 5.9). Compared to the L TM, the gain is mor e than four times larger . This can be explained as follows: In the beginning, due to very little training data, the STM is falsely certain in its beliefs. That means the probability vectors have high Model Selection 65 peaks (low entropy). A wrong guess seriously impairs the performance, as every class besides the peak has very low likelihood. Adding L 2 regularization enfor ces a Gaussian prior over the weight distribution, and the probability vectors become more leveled (higher entropy). Hence, wrong guesses have a reduced impact with L 2 regularization. λ 2 0 10 − 5 10 − 4 10 − 3 10 − 2 λ 1 10 − 2 4.327 4.328 4.325 4.286 4.263 10 − 3 3.677 3.688 3.641 3.579 3.965 10 − 4 4.534 4.325 3.581 3.288 3.857 10 − 5 6.328 4.597 3.628 3.299 3.835 10 − 6 7.223 4.722 3.716 3.300 3.838 10 − 7 8.647 4.872 3.731 3.310 3.842 T able 5.9: Joint L 1 and L 2 regularization in the STM. (2) and (3): T able 5.10 and 5.11 reveal that L 1 regularization performs best with exponential per-featur e factor and α = 1.2. Further , we see that L 2 regularization performs best with a global factor . These results ar e in accor dance with the intent behind the implementation of feature depth dependent regularization; to guide feature selection (see section 4.4). L 2 regularization does not drive weights to zer o, and should thus penalize all features equally . const. exponential λ 1 1.0 1.2 1.5 2.0 2.5 10 − 5 3.299 3.248 3.263 3.275 3.293 10 − 6 3.300 3.246 3.251 3.252 3.254 10 − 7 3.310 3.267 3.277 3.262 3.252 T able 5.10: Per-featur e L 1 regularization with λ 2 = 10 − 3 in the STM. const. exponential λ 2 1.0 1.2 1.5 2.0 2.5 10 − 2 3.807 3.825 3.849 3.865 3.873 10 − 3 3.246 3.246 3.264 3.277 3.283 10 − 4 3.581 3.493 3.456 3.435 3.438 10 − 5 4.377 4.318 4.250 4.193 4.156 T able 5.11: Per-feature L 2 regularization with λ 1 = 10 − 6 and exponential λ 1 per- feature factor with α = 1.2 in the STM. Model Selection 66 (4): Adding a temporal decay to both regularization vectors lead to a considerable improvement fr om 3.246 to 2.964 bits. (5): For each experiment, one parameter ϕ ∈ { λ init 1 , λ init 2 , τ 1 , τ 2 } was held constant while performing hyperparameter optimization over the remaining thr ee. The box plot in figur e 5.1 visualizes the mean and variance of the best achieved performances. From the small variances of λ init 1 and τ 1 , we conclude that the optimization r esults barely depended on the value of either . T o reduce the hyperparameter search space, we will keep τ 1 = 100 constant in the following. Consequently , the PyPulse STM will from her eon have the fr ee parameters λ init 1 , λ init 2 and τ 2 . 2 . 9 5 3 . 0 0 3 . 0 5 3 . 1 0 3 . 1 5 3 . 2 0 3 . 2 5 L 1 i n i t L 2 i n i t L 1 r a t e L 2 r a t e e n t r o p y p a r a m e t e r Figure 5.1: Box plots of the best attainable performances if one STM regularization parameter is held constant (for several values), and grid search is done over the remaining thr ee hyperparameters. The white dots represent the r espective achieved entropy values. 5.4 Comparing N + Operators and Feature Combinations This section compar es several N + operators that use a variety of featur e combina- tions, to find the best performing model. I aimed at covering a relevant subspace of all possible L TM and STM N + operators. An automated search for the best com- bination was not possible because of high computational costs. The best feature combinations found are given in table 5.12. The L TM experiments were conducted on the Bach chorales, the STM experiments on the German nursery rhymes dataset. Model Selection 67 Model Features L TM PI*C*KM K STM PI*F 1 T able 5.12: The best found N + configurations per model. 5.4.1 L TM The space of all N + operators is sear ched in two steps. First, the best set of viewpoint features (see section 4.2.1) was uncover ed to be PI*C*, by testing musically sensible combinations. Next, this set was used as basis for further extension with anchored and linked features (see sections 4.2.2 and 4.2.3). Overall, PI*C*KM K is the best performing feature combination. Experiments T able 5.13 lists all tested N + combinations. For computational reasons, two compr o- mises had to be made: (1) Only L 1 regularization was used, with the exception of two pr oofs of concept in table 5.13c. (2) The benchmarks were run on one out of eight datasets of the Pearce corpus only . The Bach chorales were chosen as benchmarking dataset, as they contain a large number of well formed melodies, and are the most widely used set. As performance measure served the average cross-entr opy over 10 CV folds. In every fold, 10% of the training data was left out to validate λ 1 ∈ [ 10 − 9 , 10 − 6 ] using GP optimization for 30 samples. Results The entr opy values for all tested L TM configuration ar e listed in table 5.13. Amongst them, PI*C*KM K is the overall winner . The remainder of the results allow for several observations and insights (for a music theoretic model analysis please see 6.2.1): • PI*C*, the highest performing configuration in table 5.13a, has a persuasive musical interpretation and motivation: P learns tone profile, I* learns motifs in a transposition invariant way and C* learns melody contours. • The superiority of I* to P* mirrors findings for melody learning in humans. Children start off with learning melodies based on absolute pitches, but will evolve to memorize melodies using relative pitches as they become adults (Saffran and Griepentr og 2001). Model Selection 68 • W e observe that O* performs surprisingly poorly on its own. It is now evident that octave invariant intervals alone are unsuitable for learning melodies. • Adding anchor ed featur es that learn tonic or key specific tone pr ofiles was a natural candidate to improve the performance. It is inter esting to see, that using the first note(s) as tonic estimator performs very similar to using the tonic as computed by the Kr umhansl-Schmuckler algorithm. However , additionally using the computed mode leads to a much better performance. • M K was designed based on the hypothesis that there are corr elations between metrical weights and scale degree fr equencies. Compared to pure K features, we can observe an improvement, and hence corroborate this hypothesis. Simi- larly , but to a smaller extent, M P features impr ove the performance and hint at a correlation between pitch values and the position in bar . • In several instances having more features or higher value ranges lead to worse results, despite a potential higher expr essiveness. For example F 1,2,3 compared to F 1 , PI*X* compared to PI*C*, P*I* compared to PI*. Moreover , all combinations expanded in an intermingled fashion: P(IC)* compared to PI*C*, (PI)* compared to P*I* and (PIC)* compar ed to PI*C*. Ng (2004) showed that for featur e selection scenarios in logistic regr ession, the number of training samples needs to grow at least logarithmically with the number of irr elevant features. I suspect that a similar relationship holds for log-linear models, and that the fairly small datasets inhibit the full potential of several – especially the intermingled – configurations. • The differ ence in feature set size between configurations is striking. For example, P* learned a model of 1236 features (averaged over the CV folds), while PI*C*K r eached appr oximately the same training entr opy and a much better test entropy with only 384 featur es. The best performing configuration PI*C*KM K converged to a set of 447 features. I attribute a low number of features to a well balanced set of expressive features. For example, P* is not as suited to memorize melodies as I*. A beneficial side ef fect of having smaller feature sets is a significantly r educed runtime. • Additionally using L 2 regularization turned out to achieve only marginal improvements in performance, paid for with much higher training durations ( ∼ 1.5 − 2 × as long). In consequence, the number of features for P* rose up to 1,583. Besides cross-entr opy , another metric worth considering is the empirical classifi- cation error . Its advantage is its intuitiveness. A veraged over all CV folds, 47.24% Model Selection 69 N + Entropy P 3.617 P* 2.393 I 3.020 I* 2.382 O 3.719 O* 3.149 P* I 2.387 I* 2.307 O* 2.331 P O* 2.588 (IC)* 2.305 I* – 2.302 C 2.300 C* 2.295 X* 2.297 (PI)* 2.330 (PO)* 2.366 (PIC)* 2.331 (a) V iewpoints features. N + Entropy PI*C* F 1 2.263 F 1,2,3 2.264 T 2.266 K 2.209 M P 2.289 M K 2.188 TM T 2.250 KM K 2.187 (b) Anchored featur es. N + Entropy P* 2.384 PI*C* 2.290 (c) Results for combined L 1 and L 2 regularization. T able 5.13: Entropy values for the Bach chorales dataset using 10-fold CV and GP optimized L 1 regularization for dif fer ent N + configurations in the L TM. Each path from left to right in the N + column describes one configuration. of the pitches in the test set have been corr ectly guessed by PI*C*KM K . P* classi- fied 43.40% of all pitches correctly . Most misclassifications naturally occur in the beginning of each song where the contexts ar e smallest. 5.4.2 STM Using the same approach as for the L TM, we assess differ ent STM N + configurations. This time the German nursery rhymes dataset was used, which pr oved to be the easiest dataset to pr edict for the STM (Pearce and W iggins 2004). In an additional preliminary step, forwar ds and continuous expansion wer e compared. Then, build- ing on knowledge gained fr om the L TM, a smaller set of feature combinations was chosen and evaluated. The N + operator PI*F 1 with forwards expansion performed best. Model Selection 70 Experiments Firstly , the best N + mode was determined by running benchmarks for forwar ds and continuous expansion using P*. Secondly , several viewpoint and anchor ed features were combined and the performances compar ed. Due to high computational costs, it was infeasible to optimize the hyperparameters for every CV fold. Thus, the hy- perparameters λ init 1 ∈ [ 10 − 5 , 10 − 2 ] , λ init 2 ∈ [ 10 − 3 , 10 − 1 ] , τ 2 ∈ [ 5, 12 ] (see section 5.3.2) were selected via GP based optimization for 40 samples on the whole corpus. Let τ 2 = 100 be fixed. The reported benchmarks are the average over the 10 test set performances in 10-fold CV . The German nursery rhymes dataset was used as benchmarking corpus because the best results of prior work on the STM have been achieved for this dataset. Moreover , it is rich in repetitions which makes it a fr uitful application gr ound for the STM. Results At first, we consider the differ ences between the N + expansion modes. The best performance achieved for the forwards mode was 2.737, whereas the continuous mode only achieved 3.055 bits. The expectation that continuous expansion would perform reasonably well has not been met (see section 4.3). Forwar ds expansion, which captures motifs instantly in contrast to continuous expansion, pr oved to be the superior strategy . The benchmarks for differ ent N + operators using forwards expansion ar e given in table 5.14. The first observation to make is that the STM benefits from an absolute learning of motifs with P* featur es, in contrast to the L TM, in which a r elative learning of pitch sequences performed better . It is sensible to assume that the L TM generalizes better between songs by describing melodies in a relative manner , and that the STM memorizes a single song better by storing motifs using absolute pitches. Similar to the concept that a fish cannot ponder about the significance of water , the concept of musical keys only makes sense when songs are compared to one another . Thus, in the STM, the concept of musical key does not exist, and it is sur- prising that the combination of PI* with F 1 resulted in the overall best performance. The N + operator F 1 describes nothing mor e than P , namely the value of a pitch in refer ence to the first tone or to MIDI pitch zer o, r espectively . I make the conjecture that this finding is caused by the GP optimizer exploiting a local optimum and by 40 samples not being enough to sufficiently explor e a thr ee-dimensional space. More- Model Selection 71 N + Entropy P* 2.737 I* 3.061 P*I 2.685 PI* 2.657 P*I* 2.677 PI*C 2.684 PI*C* 2.705 PI*F 1 2.590 PI*K 2.675 PI*C*F 1 2.624 T able 5.14: Entr opy values for differ ent STM N + configurations on the German nursery rhymes dataset. The benchmarks were computed using 10-fold CV and GP optimized L 1 and L 2 regularization with temporal decay . over , this could mean that other reported results are not globally optimal neither . Due to a lack of time, this was not further investigated. 5.5 Comparison of Hybrid Models Ensembles of classifiers have been shown to surpass their source models in the past. For example, MVS (see section 2.1.2 ) using the mean and product rule (see section 2.1.2) to combine single viewpoint models, or the top Netflix Prize performer Bell et al. (2008) combing over a hundred models building on W olpert (1992)’s stacking method. In this section, I analyze the combination of P ULSE L TMs and STMs as well as L TMs with L TMs. The combinations were performed using the mean and product r ule using differ ent parameterizations. All tested hybrid models wer e found to perform better than each of the sour ce models. P ULSE L TMs were also combined with n -gram (C*I) and (X*UI)-STM (see Pearce and W iggins (2004) for an explanation of the shorthand model identifiers). The combination of the PI*C*KM K -L TM with the n -gram (C*I)-STM using the mean rule performed best. The combination of the P* and the I* L TMs outperformed the joint PI*-L TM. Model Selection 72 5.5.1 L TM+STM Augmenting L TM with STM predictions is a natural way to improve performance. The L TM captures style dependent patterns, wher eas the STM learns song specific motifs. The combination of the best P ULSE L TM with the best P ULSE STM (see sections 5.4.1 and 5.4.2) and with two n -gram STMs taken from Pear ce and W iggins (2004) are analyzed in this section. The combination rules come with the free parameter b which assigns a bias to the lower entropy distribution (see equation 2.3). In pr eliminary experiments, the effect of separate parameters b for the L TM and STM, as well as the ef fect of a time-dependent shift to the L TM in the beginning and the STM in the end, were investigated. Both approaches were outperformed by hybrids using the original single parameter b . Experiments The following hybrids were combined: (1) The P ULSE PI*C*KM K -L TM with the P ULSE PI*F 1 -STM, (2) the P ULSE PI*C*KM K -L TM with the n -gram (C*I)-STM, and (3) the P ULSE PI*C*KM K -L TM with the n -gram (X*UI)-STM. The mean and product combination rule from section 2.1.2 were used. For the L TM+STM hybrids the entropies wer e computed on the whole Pearce corpus, for the L TM+L TM hybrid the Bach chorales were used. Bias parameter b was determined for each combination rule over the grid b ∈ { 0, 1, 2, 3, 4, 5, 6, 16, 32 } on the training set of each CV fold (in Cherla, T ran, W eyde et al. (2015) and Pearce and W iggins (2004) b was determined over the same grid but on the test set). The distributions for the n -gram STMs were obtained with IDyOM (version 1.4). Note that the pitch sequences parsed by IDyOM did not match the **kern files in five out of 54,308 events. This disaccord was resolved by making the affected IDyOM distributions uniform. Results The results for the L TM+STM hybrids (1) to (3) are given in table 5.15. In all cases, the mixture performed much better than either of the source models. The P ULSE + P ULSE hybrid performed better than the P ULSE + n -gram (X*UI) but worse than the P ULSE + n -gram (C*I) hybrid. It is intriguing, that the n -gram (C*I)-STM, that performs worse on its own, leads to an overall better performance when employed in a hybrid. I make the conjecture that this is due to the heter ogeneity of the Model Selection 73 Ensemble Rule Entr opy Source Entropies P ULSE L TM PI*C*KM K + P ULSE STM PI*F 1 m 2.387 2.542 / 3.092 p 2.397 P ULSE L TM PI*C*KM K + n -gram STM (C*I) m 2.357 2.542 / 3.152 p 2.394 P ULSE L TM PI*C*KM K + n -gram STM (X*UI) m 2.407 2.542 3.149 p 2.400 P ULSE L TM P*+ P ULSE L TM I* m 2.299 2.393 / 2.382 p 2.282 T able 5.15: Entropy values for ensemble models using mean (m) and product (p) combination rule. The values are computed on the whole Pearce corpus for the L TM+STM hybrids and on the Bach chorales dataset for the L TM+L TM hybrid. source models, which facilitates a lar ger gain of information during the combination, compared to combining models of the same br eed. 5.5.2 L TM+L TM Combining models of the same paradigm, such as L TMs with L TMs or STMs with STMs, stands in contrast to a joint approach as pursued with P ULSE . The former ap- proach is used by n -gram MVS as depicted in figure 2.2. Here, the joint approach of P ULSE is tested by benchmarking a joint model against the mixture of its constituent models. Experiments The L TMs P* and I* wer e combined using the product and mean rule, and the same approach was used for setting parameter b as above. Then, the results wer e compared to the PI* L TM, the best joint model that uses pitch and interval featur es. Results I expected that a well crafted joint model would outperform an ensemble of its source models, as the joint model was tuned to maximize the joint performance whereas the sour ce models were tuned to maximize each source’s performance. It is striking and counter to my expectations that the L TM ensemble performed better than the joint model PI* (2.302 bits). Model Selection 74 This finding allows me to draw the conclusion that (1) the best reported per- formance may be outperformed by an ensemble of smaller P ULSE models with the same features, or (2) PyPulse is not operating in its optimum yet, as the joint model should be able to learn a superset of statistical patterns compared to the sub-models. Considering the number of features of each model, we see that PI* conver ged to only 633 features (average over the CV folds), compar ed to 791 of I* and 1,236 of P*. It seems that the worse performance of the joint model might be caused by the feature culling of L 1 regularization and the S H R I N K operator . I leave it up to futur e work, to analyze whether weaker L 1 regularization closes the gap between the mixtur e and joint model. Chapter 6 Evaluation In this chapter , I assess the PyPulse learning algorithm for music that was presented and tuned in the previous chapters. The assessment is performed in two steps. Firstly , the best PyPulse models are compar ed with state-of-the-art results in mono- phonic melody pr ediction and cognitive modeling. Secondly , the learned featur e sets and weightings are analyzed musicologically and str ucturally . 6.1 Literature Comparison Results gain real significance only when consider ed in r elation to other work. This section chiefly reports the results of a quantitative comparison with state-of-the- art models. Section 6.1.1 compares the best PyPulse L TM, STM and hybrid models to the state-of-the-art. Ensemble models ( n -gram MVS) and joint PyPulse models using corresponding feature types are compar ed in section 6.1.2. In section 6.1.3, PyPulse ’s suitability as cognitive model of expectation is evaluated. Please refer to section 5.1 for an introduction of the utilized corpus, the evaluation measure, Gaussian process (GP) based hyperparameter optimization and cross-validation (CV). 6.1.1 Comparison with State-of-the-Art Methods The best PyPulse performances for L TM, STM and hybrid models were compared to the state-of-the-art models for melody pr ediction. All three P ULSE models outper- formed the state-of-the-art models significantly . 75 Evaluation 76 Experiments The best PyPulse models were evaluated on the eight datasets of the Pearce cor- pus. The models were the PI*C*KM K -L TM (see section 5.4.1), the PI*F 1 -STM (see section 5.4.2) and the hybrid of the PI*C*KM K -L TM and (C*I) n -gram STM (see section 5.5). The corpus cross-entr opy served as the performance measure. It is computed as the average entropy over the eight dataset entr opies. The hyperparameters were determined as follows: In the L TM, the global L 1 reg- ularization factor λ 1 was determined per fold on a small held out part (10%) of the training set, using GP based optimization. Parameter λ 1 was the only one tuned on a per-dataset (and fold) basis. All remaining hyperparameters were tuned on the Bach chorales dataset as described in section 5.2 and 5.3.1. In the STM it was planned to tune λ init 1 , λ init 2 and τ 2 on a per-dataset basis which turned out to be computation- ally infeasible. Only for the German nursery rhymes dataset, the hyperparameters were tuned on the actual dataset. For the other datasets fixed values λ init 1 = 10 − 5 , λ init 2 = 0.01 and τ 2 = 8 were assumed based on pr eliminary runs. The remaining hyperparameters were tuned on the German nursery r hymes dataset as described in section 5.3.2. Results W e compar e the state-of-the-art performances with the P ULSE L TM, STM and hybrid performances in table 6.1. The P ULSE L TM and hybrid model improve the state- of-the-art by a leap lar ger than that between the RTDRBM (Cherla, T ran, Garcez et al. 2015; Cherla, T ran, W eyde et al. 2015) and n -gram (Pearce and W iggins 2004) models. The P ULSE L TM performed 0.17 bits, the P ULSE hybrid 0.064 bits better than the recor d holder R TDRBM. The n -gram STM has been surpassed for the first time; the P ULSE STM performed 0.047 bits better . L TM L TM + STM Hybrid P ULSE 2.542 – 3.092 2.357 R TDRBM 2.712 2.756 3.363 2.421 RBM 2.799 – – – FNN 2.830 – – – n -gram 2.878 2.614 3.139 2.479 T able 6.1: Benchmark of the best melody pr ediction models P ULSE , R TDRBM (Cherla, T ran, W eyde et al. 2015), RBM (Cherla, W eyde, Garcez and Pear ce 2013), FNN (Cherla, W eyde and Gar cez 2014) and n -grams (Pearce and W iggins 2004). Evaluation 77 All PyPulse L TM and STM configurations that have been benchmarked on the entire Pear ce corpus ar e reported in table 6.2. Note that the comparison in table 6.1 compares single (or joint) model performances with each other . A comparison of PyPulse with the best performing ensemble methods is undergone in the next section. L TM STM Dataset P* PI*C* PI*C*K PI*C*M K PI*C*KM K P* PI*C PI*F 1 0 2.792 2.685 2.493 2.489 2.490 3.126 3.118 3.041 1 2.393 2.295 2.209 2.188 2.187 3.228 3.106 3.047 2 3.206 2.889 2.664 2.672 2.659 3.177 3.074 2.996 3 2.770 2.605 2.476 2.498 2.489 3.595 3.570 3.396 4 3.149 2.870 2.691 2.696 2.715 3.219 3.183 3.087 5 3.446 3.182 2.956 2.951 2.952 3.342 3.305 3.218 6 2.402 2.331 2.234 2.202 2.203 2.737 2.684 2.590 7 2.920 2.770 2.656 2.653 2.646 3.567 3.442 3.363 A verage 2.885 2.703 2.547 2.544 2.542 3.249 3.185 3.092 T able 6.2: P ULSE benchmarks on the Pearce corpus. 6.1.2 Comparison with n -gram MVS In this section we compare PyPulse models to n -gram models with matching feature and viewpoint sets. The n -gram models under investigation are: (1) Single model n -grams using linked viewpoints (see section 2.1.2), the direct n -gram equivalents to PyPulse models. (2) The best reported melody pr ediction ensembles, namely n -gram MVS (Pearce 2005), using the best values from literatur e and IDyOM. While P ULSE is clearly the winner in (1), the comparison (2) pr ovides mixed results. I give arguments that P ULSE models have the potential to outperform either . Experiments PyPulse models were compared to ensemble and linked viewpoint n -gram MVS that used the same viewpoints. Specifically , a PyPulse P*-L TM, STM and L TM+STM hy- brid was compared to the best viewpoint pitch n -gram models; and a PyPulse PI*C*- L TM and STM were compar ed to the best pitch-interval-contour n -gram ensemble, as well as linked viewpoint models. The best n -gram performances wer e taken from Pearce and W iggins (2004) or generated using the IDyOM framework 1 . 1 https://code.soundsoftware.ac.uk/projects/idyom- project Evaluation 78 Results All r esults are given in table 6.3. Fr om table 6.3a we learn that n -grams with the single viewpoint pitch outperform the equivalent P ULSE L TM, STM and hybrid. However , if we restrict ourselves to comparing the datasets that the majority of hyperparameters was tuned on, then P ULSE is leading in the L TM case (dataset 1) and both models perform similarly in the STM case (dataset 6). I assume that the n -grams can be outperformed with a dataset specific hyperparameter tuning for the L TM, and that both models will be tied in the STM. W e can also interpret this experiment to be a comparison of generalized n -grams to n -grams; the same results apply here. The r esults for the comparison of pitch-interval-contour viewpoint with PI*C* feature models as shown in table 6.3b are intriguing: If we compare P ULSE to its direct single model n -gram equivalent, the pitch-interval-contour linked viewpoint models, then P ULSE is winning with a lar ge margin. In fact, the linked n -gram model deteriorated to the pitch-alone version. This emphasizes the capabilities of the P ULSE method to join several viewpoints within a single model. In contrast to that, we observe that P ULSE loses the comparison with the n - gram ensemble models. However , if we again consider only the results of dataset 1 for the L TM and dataset 6 for the STM, then P ULSE outperforms the ensemble methods. I assume that single P ULSE models have the potential to beat L TM and STM ensembles if the hyperparameter tuning is improved. It is left to futur e work to validate my hypothesis that unified P ULSE models can outperform ensembles of n -grams with the corresponding featur e and viewpoint sets. 6.1.3 Comparison with Psychological Data In the past sections, I have thoroughly assessed PyPulse ’s quantitative performance as a predictive model of melody . Here, I make an attempt to confirm its suitability as cognitive model of pitch expectation. For that we use PyPulse to compute an entropy profile and compar e it with Pearce and W iggins (2006)’s results to the simulation of human predictive uncertainty . Entropy profiles are the entr opies (i.e. the negative base-2 logarithms of the likelihoods) ascribed to the respective next notes in a song. Pearce and W iggins used an n -gram MVS, highly tuned to the task, to simulate an entropy pr ofile obtained from an experimental study by Manzara et al. (1992). In the study , a betting paradigm was used that, given a context, asked participants to distribute their bets on the most likely continuations. The results confirm a general suitability of PyPulse to the task of cognitive modeling, although the achieved performance was worse than prior work using Evaluation 79 L TM STM L TM+STM hybrid Dataset P ULSE n -gram i , c P ULSE n -gram p , x P ULSE n -gram p , c 0 2.792 2.863 3.126 2.977 2.509 2.468 1 2.384 2.443 3.228 3.117 2.368 2.34 7 2 3.206 3.089 3.177 3.090 2.632 2.540 3 2.770 2.720 3.595 3.411 2.691 2.588 4 3.149 2.982 3.219 3.137 2.628 2.454 5 3.446 3.307 3.342 3.244 2.804 2.651 6 2.402 2.427 2.737 2.731 2.114 2.106 7 2.920 3.097 3.567 3.406 2.706 2.681 A verage 2.885 2.866 3.249 3.139 2.557 2.479 (a) The best models based on P viewpoints/features only . L TM STM Dataset P ULSE n -gram i , c , e n -gram i , c , l P ULSE n -gram i , c , e n -gram i , c , l 0 2.685 2.724 2.878 3.118 3.032 3.377 1 2.290 2.358 2.458 3.106 3.053 3.418 2 2.889 2.847 3.105 3.074 3.086 3.570 3 2.605 2.580 2.745 3.570 3.529 3.924 4 2.870 2.687 2.995 3.183 3.140 3.602 5 3.182 3.053 3.358 3.305 3.223 3.735 6 2.331 2.300 2.450 2.684 2.703 3.128 7 2.770 2.892 3.129 3.442 3.373 3.950 A verage 2.703 2.680 2.890 3.185 3.142 3.588 (b) The best models based on P , I and C viewpoints/featur es. The n -gram performance is computed once for an ensembles of viewpoints and once for a single linked viewpoint. T able 6.3: P ULSE with viewpoint featur e configurations compared to n -gram models with matching viewpoints. i Generated using IDyOM. c Escape method C and interpolated smoothing (C*I). x Escape method X, update exclusion, and interpolated smoothing (X*UI). p Pearce and W iggins (2004). l Linked viewpoint cpitch-cpint-contour . e Ensemble of viewpoints cpitch, cpint, and contour . n -gram MVS. However , the reported results ar e of a preliminary natur e and should be considered to be a pr oof of concept. Experiments The best performing PyPulse L TM from section 5.4.1 (PI*C*KM K ) was trained on the Bach chorales dataset minus chorale 126 (BWV 379). The r esulting entropy pr ofile Evaluation 80 for test chorale 126 was compared to the behavioral entropy profile of Manzara et al. (1992) and the n -gram MVS pr ofile, as they wer e r eported by Pear ce and W iggins (2006). The goodness of fit was measured by the proximity of the model and the human profile. Results Figure 6.1 shows the entropy pr ofiles of Manzara et al. and Pear ce et al., superim- posed by the P ULSE profile in blue. From the curves it can be confirmed that the human and P ULSE entropy pr ofiles are positively corr elated. The profile contours of both, the n -gram and P ULSE model, deviate from the human contour in five notes ( n -gram: note 9, 12, 19, 21, 28; P ULSE : note 9,13, 18, 22, 28). The n -gram entropy values are closer to the human values for the majority of notes. I consider this experiment to be a proof of concept and to be of a preliminary nature. The evaluation on a single benchmarking piece is of limited expressiveness and cannot be considered to generalize well. Thus, a diligent quantitative analysis was omitted. Moreover , the three entr opy profiles wer e obtained based on differ ent preconditions. The training corpus for humans is unknown, but presumably was very large. P ULSE was trained on only 184 Bach chorales, and the n -gram models were trained on a corpus of 152 Canadian folk songs, 184 Bach chorales, and 566 German folk songs. The number of prediction classes differed as well: 20 for humans, 21 for P ULSE , and is of unknown size for the n -grams. Last but not least, the P ULSE model was not specifically tuned to gain the highest performance on this very test piece. On the contrary , the viewpoints of the n -gram MVS were selected to fit the entropy pr ofiles optimally . Such a model and featur e selection for PyPulse was left for future work. Generally , the best performing model entropy-wise is not necessarily the best cognitive model of auditory expectation. Pearce and W iggins (2012) r emark that the statistical models’ memories never fail. Rohrmeier and Koelsch (2012) similarly criticize that n -gram models outperform the learning skills of humans and thus provide an inaccurate surr ogate. 6.2 Analysis of the Learned Models A black box learner might bristle with performance, but it does not provide any further insights. One chief advantage of the P ULSE method is that it affor ds the extraction of valuable music theor etic insights fr om the learned models. After the training one can observe how the data was memorized and, furthermore, if the Evaluation 81 Figure 6.1: Entropy profile of a P ULSE L TM (blue) plotted on top of figure 7 fr om Pearce and W iggins (2006) which shows the entropy profiles of human pitch expec- tation in comparison to those of an n -gram MVS model for the chorale Meinen Jesum laß’ ich nicht, Jesu (BWV 379). algorithm was primed with the right feature building blocks, one can gain new understanding of the underlying data. In this section, several trained models ar e analyzed by submitting the discover ed feature sets to a musicological analysis (section 6.2.1), and to a technical analysis with a focus on their temporal composition (section 6.2.2). Last but not least, the models are br ought to life thr ough the generation of sequences (section 6.2.3). 6.2.1 Musicological Analysis The musicological analysis covers (1) the estimation of each feature type’s contribu- tion to the model predictions, (2) the music theoretic interpretation of the weightings of zero-or der featur es, (3) the extraction of the motifs with heaviest weights, and (4) the correlation between the metrical weight and tonic triad. In the following PI*C*K-L TM are used, trained on the Bach chorale and Chinese folk tunes datasets. These datasets were chosen due to their cultural and regional distinction to elicit multifaceted models. The regularization factor λ 1 was set to the over the CV folds averaged L 1 factor from the N + benchmark in section 5.4.1. Evaluation 82 Relevance of Feature T ypes The used models were given four differ ent types of features to learn the data: pitch, interval, contour , and key features. T o further understand each type’s r elevance, it is important to know how much weight – figuratively as well as mathematically – is given to each type. T able 6.4 shows the accumulated weights given to all features of each type, in percent of all assigned weights to any type. This metric presumes that a feature type with a higher weight has a higher influence on the pr ediction. W e observe that interval features are assigned more than 70% of all weights in either model. It is surprising to see that K features have a higher importance for Chinese folk tunes than the Bach chorales, considering that keys are a western concept. Feature T ype Bach Chorales Chinese Folk T unes P 0.084 0.125 I* 0.744 0.702 C* 0.056 0.042 K 0.116 0.131 T otal #Featur es 312 399 T able 6.4: The weight allocation to each feature type in percent of the total allotted weights. W eight Analysis for Zero-Order Features Zero-or der or length-one viewpoint features carry a special status, as they model the occurrence fr equencies of the r espective viewpoint values. Figure 6.2 plots the heat encoded weights for each length-one feature value in the model. Note that gaps in the plots are featur es that did not occur in the dataset or wer e regularized away . Let us consider the weights of the pitch features first. W e can infer the regularity that in both, Chinese and W estern styles, the center of the register is preferr ed while exceptionally high or low pitches are discouraged. W e further observe that the range of pitches is much larger for Chinese tunes then for Bach chorales. Looking at the interval features’ weights, we see that in both models smaller in- tervals ar e pr eferred over larger ones, which is in accor dance with general principles of voice leading (Huron 2001). For the Chinese folk tunes model, the discovered interval range is distinctly lar ger . In the Chinese model, large ascending steps are preferr ed over lar ge descending steps, wher eas there is no distinct pr edilection in the direction of small intervals. In contrast to that, small intervals ar e encouraged to descend in the Chorales model. That is consistent with V os and T roost (1989) Evaluation 83 (a) Chinese folk melodies dataset (b) Bach chorales dataset Figure 6.2: Qualitative plot of the feature weights for length-one P and I viewpoint features as well as K anchored features of the PI*C*K-L TM . For the values of I and K features, C5 was chosen as reference tone. The color scale is normalized for every feature type to make use of the maximum range (red to blue, lowest negative to highest positive weight). Positive weights ascribe a high likelihood to the corresponding musical event, negative weights attribute low likelihood. that reported small intervals in western music to have the tendency to go down. W e further observe that the Bach chorale model discourages the tritone step ( ± 6 semitones) which was seldomly used to express anger or sadness in W estern music, and did not even occur in the Chinese melodies in the first place. Unisons (0) are less attractive than small steps in both models. It is striking to see that key profiles have been learned by the features of type K. The tonic featur es for major (M) and minor (m) represent interval fr equencies Evaluation 84 relative to a key . In consequence, the model can use song specific absolute pitch frequencies. W e can observe almost identical weightings in both models. The tones of the major and minor triad ar e preferr ed; those outside the respective diatonic scale are discouraged, as it was typical during Bach’s times. The minor (m)/major (M) triad ar e tonic (0 semitones), minor thir d (3 semitones)/major thir d (4 semitones) and fifth (7 semitones). Exemplary Motifs Motifs are contiguous transposition-invariant melody snippets (i.e. n -gram). As learned from table 6.4, features generated by N + operator I* are of particular impor- tance for the pr ediction. This section can merely give a taste of the motifs learned, due to the large number of features. Hence, table 6.5 shows only the motif of highest weight for lengths three to five, r espectively (featur e length two to four). Dataset Motifs Bach Chorales Chinese Folk T unes T able 6.5: The type I* contiguous compound featur es of highest weight for featur e length two to four , instantiated with start pitch C5. At first sight, the listed motifs do not appear to be the likeliest ones in the respec- tive genr es. However , one should keep in mind that the motifs are CRF features and not n -grams. Given a context x and an outcome y , each model prediction for y is assembled fr om the set of features that evaluate to true for ( x , y ) . In a motif, x are all intervals but the last one, and y is the last interval. In consequence, a heavy weighted feature that matches x puts in its weight to promote y to be the next interval, amongst all other features that match x and promote the same or differ ent outcomes. Bearing that in mind, the stepwise continuation that five out of six features advocate seems sensible. Furthermore, we can discover two simple claims of Narmour (1992)’s Implication- Realization model: In the second motif for the Chinese folk tunes, a lar ge interval implies a change of direction. In the first and third interval of both models, small intervals imply the continuation of direction. Evaluation 85 Correlations Between Metrical W eight and T onic T riad W e will now assess the linked featur es of type M K , specifically the interplay of metrical structure and key . For that we employ a PI*C*KM K -L TM learned on the Bach chorales dataset. It is pertinent to ask: What is the advantage of M K compared to K? From a mathematical point of view the advantage stems from a higher spatial pr ecision. In addition to K, M K also r epresents wher e in the metrical structur e the chr omatic scale degrees of the reference key lie. From a music theory point of view these features are motivated by findings that ther e is a pr edilection for tones of the tonic triad to lie on heavier counts (Caplin 1983). W e make the following r elevant observation from the M K features for the dif fer - ent metrical weights (see figure 6.3): : The tones of the major and minor triad are encouraged. : No particular prevalence can be deduced. Furthermore several M K features did not occur or were regularized away which indicates a neutrality towards the occurrence of scale degrees for this metrical weight. : All tones of the triads are encouraged with the exception of the tonics. In particular the dominant (fifth diatonic scale degr ee) which in music theory is said to be of lighter metrical weight than the tonic. : In striking contrast to the stronger beats in the metrical str ucture, this one firmly disfavors the tones of the major and minor triad. In conclusion, we saw that in several instances in-scale tones were encouraged to lie on the heavier metrical weights of depth four and two, and especially , that the weakest beats in the structur e strongly discourage all in-scale tones. 6.2.2 T emporal Model Analysis For any system that is designed to predict the continuation of a sequence, it is intriguing to know how much of the available context the system uses in practice. This section will answer this question, examine the temporal weight distribution, and analyze the extent of use of generalized n -gram features. Conceptually , P ULSE can built features of arbitrary depth, but the N + opera- tions that we use limit the featur e size by the number of outer loop iterations. The Evaluation 86 Figure 6.3: The weight distribution as learned for the linked metrical weight and key features M K . The weights of the intervals relative to the major (M) and minor (m) tonics are given for every metrical weight, if the featur e was selected. constructed featur es ar e generalized n -grams which ar e compounds of viewpoint features (see section 4.2.1). A generalized n -gram feature dif fers from an n -gram fea- ture by not being contiguous, meaning that it has gaps or holes. How Much T emporal Context Does PyPulse for Music Use? The temporal context is made up of the past musical events that P ULSE bases its predictions on. W e answer the question under consideration by analyzing figure 6.4. The figure visualizes the temporal weight distribution of a set of compound featur es as follows: Each compound consist of one or several basis features f σ , ν which each carry a time component σ (for a detailed explanation see section 4.2). The basis features f σ , ν are attributed the weight of their r espective compound feature. For all basis features of all compound features, the absolute weights ar e accumulated in the bin for time σ (x-axis) and the total number of basis features in its par ent-compound (y-axis). The accumulated values ar e color encoded and plotted in a matrix. The plot is repeated for the four N + configurations P*, PI*C*, PI*C*K and PI*C*KM K , trained on the Bach chorales dataset. The first observation to make – and the answer to the question – is that the maximum temporal extent over all models is six steps in the past. The feature length is limited by five. The majority of the weight is assigned to featur es with time of two Evaluation 87 0 1 2 3 4 5 4 3 2 1 cumulative weight high low (a) PI*C*K 4 3 2 1 # basis f eatur es 0 1 2 3 4 5 6 (b) PI*C*KM K 0 1 2 3 4 5 6 time of ba sis fea tur e 5 4 3 2 1 (c) P* 5 4 3 2 1 # basis f eatur es 0 1 2 3 4 5 6 time of ba sis fea tur e (d) PI*C* Figure 6.4: This plot shows the feature weight distribution over features of differ ent length and temporal extent. Every field contains the sum of the absolute weights of all basis features f σ , ν that have the r espective temporal depth σ and occur in a compound of the respective number of basis featur es. The models were learned on the Bach chorales dataset. 4 3 2 1 9 2 5 3 3 3 4 2 8 6 3 5 1 6 8 6 4 0 1 2 3 featur e co unt mor e less (a) PI*C*K 4 3 2 1 # b asis featur es 8 3 6 3 3 2 6 2 1 5 3 3 8 1 5 6 1 6 3 0 1 2 3 4 5 (b) PI*C*KM K 0 1 2 3 4 5 n u m b e r o f h o l e s 5 4 3 2 1 2 5 4 8 2 8 6 1 4 3 4 6 4 2 4 1 1 2 5 1 0 0 6 1 1 9 1 2 1 (c) P* 0 1 2 3 4 5 n u m b e r o f h o l e s 5 4 3 2 1 # b asis featu r es 2 3 1 7 1 1 0 4 7 6 2 8 4 1 3 0 6 1 3 8 1 6 5 3 4 3 (d) PI*C* Figure 6.5: This plot visualizes the distribution of generalized n -gram features’ length and number of holes. Each r ow r epresents the length of a compound feature, each column the number of holes in the compound. The fields contain the accumulated number of features per length and number of holes. n -gram alike features have zero holes. Evaluation 88 or less and with length three or less. Note that length-one features are compelled to have time zero, and that anchored and linked features were defined to have zer o temporal extent. The differ ences between the four models are minuscule. W e can observe that the more complex models (a) and (b) cope with shorter features of less temporal extent. Also, in (a) and (b), the length-one featur es are assigned a relatively higher weight, which is presumably caused by the additional length-one featur es K and M K . Frequency of Holes in Generalized n -gram Features Do generalized n -gram features have holes in practice? T o answer this question we consider figure 6.5. The matrix has the two dimensions number of holes (x-axis), and number of basis features (y-axis) of compound features. The number of holes is defined as the count of missing basis featur es compared to the r espective contiguous n -gram. The heat encoded values repr esent the count of compound features with a given number of holes and basis features. I analyze the same models as above. The column labeled with zero holes depicts all compound features that corre- spond to standard n -grams. The values in the other columns list the number of generalized n -gram features. W e can compute that the generalized n -gram version on average makes up 37% of the feature set. W e observe further that the majority of generalized n -grams has length two, and up to five holes. This is a compr ehensible observation, as sets of generalized 2-grams are flexible and can describe the same as any longer featur es. For example “two steps ago there was a C5, now there is a C5” and “one step ago there was an A4, now there is a C5” is a versatile way of saying “two steps ago ther e was a C5, one step ago there was an A4, now ther e is a C5”. Up on comparing the dif ferent models we note that (a) and (b) mostly dif fer in the count of zero hole featur es with length two. The reason for this is that the linked M K features ha ve length two but ar e defined to have time zero, and thus no holes. W e further observe that the number of featur es decr eases from (c) to (d) and (d) to (a) despite that feature types have been added. This can be explained by the higher expressiveness of the added types that affor d a more efficient repr esentation and learning. For example repeated learning of an interval in dif fer ent transpositions requir es mor e P* than I* features. Evaluation 89 6.2.3 Sequence Generation In the final experiment, the learned models ar e made audible. For this the two infer- ence and sampling methods presented in section 4.5 ar e applied and the generated sequences compared and discussed. The comparison in performance between the two method provides mixed results. The results of both methods resemble specimen of the respective style, although no musical extravaganzas should be expected. Experiments Sequences were generated from a PI*C*KM K -L TM trained on the Bach chorales, German nursery rhymes, as well as Chinese folk tunes, using beam search and iterative random walk. The number of beams was set to k = 5 and the threshold level of iterative random walk to 0.65. All sequences were primed with the first 7 tones of a melody of the same genre that has not been part of the training set, following the example of Conklin and W itten (1995). For music generation, Whorley and Conklin (2016) linked a higher audible quality with sequences of lower entropy . Resting upon these findings, entropy was used as performance measur e, instead of a more dif ficult rule based or audible evaluation (see section 5.1.2 for a more detailed description of evaluation measures). Results The best sequence inferred from the PI*C*KM K Bach chorale model attained an entropy of 1.112/1.130 bits for the beam sear ch/iterative random walk method, the German nursery rhymes model attained 1.170/1.210 and the Chinese folk tunes model 1.529/1.314. Examples of generated melodies ar e provided in appendix C. The results are mixed: Beam search performed slightly better in two, and iterative random walk performed much better in one out of three test cases. In theory , iterative random walk has the advantage that it can generate an arbi- trary number of sequences, wher eas beam sear ch only r eturns as many sequences as there are slots per initialization. In practice, however , we observe that sampled sequences with minimal entropy are almost identical in iterative random walk. Furthermore, the best results of both methods ar e nearly equal. In these cases, the deterministic operation of beam sear ch becomes an advantage as it guarantees stable runtimes that ar e also faster than those of iterative random walk. V arious statistical patterns can be observed in the sequences: For example, the chorale models favored small steps with major seconds. Unisons were the most frequent intervals, followed by perfect fifth and fourth. The most frequent motifs Evaluation 90 were tone repetitions and p erfect fifths up followed by a perfect fourth down. The melody line meandered ar ound B4. The Chinese folk tunes model had a preference to downwards movement in the chr omatic scale. In contrast to the chorales, very large intervals occurr ed as well. Aurally , the generated melodies were pleasant to the ear , with the exception of the melodies that were generated from the German nursery rhymes model. In this specific model, the melodies instantly conver ged to a continuous repetition of the same intervals. I can only speculate at this point that this was caused by the repetitive character of the dataset. The listener can intuit the genr e of each generated melody , although the lack of note durations is making such an endeavor difficult. The melodies’ nonobservance of the musical scale, despite the usage of key featur es, is noticeable. In summary , I conclude that the audible impression of the generated models affirms the suitability of PyPulse as base model for algorithmic composition. Chapter 7 Conclusion 7.1 Thesis Review The task of monophonic melody prediction is a subfield of musical style modeling, which involves melody , harmony and rhythm. In this thesis, the P ULSE feature discovery and learning method was adapted to the r ealm of music to pr edict time series of pitches, while operating on feature spaces that are too lar ge for standar d feature selection appr oaches for conditional random fields (CRFs). The resulting learning algorithm outperformed the state-of-the-art methods for long-term, short- term and hybrid models. An object oriented framework for P ULSE was designed and realized for the task of music modeling, using L 1 -regularized stochastic gradient descent (SGD) optimiza- tion. The presented framework is the best performing single-model framework for multiple viewpoint systems (MVS) to date. The achieved increase in performance for the long-term model and hybrid models is similar to that reached by Cherla, T ran, W eyde et al. (2015) compared to Pearce and W iggins (2004). For the first time, the proposed method outperformed the state-of-the-art for short-term models since it was set by Pearce and W iggins (2004). Furthermore, the method affor ds interpretable models, which wer e shown to r eflect music theoretic insights. Compared to standard approaches for feature selection using CRFs, the P ULSE framework can sear ch and select featur es fr om a feature space that is significantly larger . The explicit listing of the entir e feature space is circumvented by alternatingly expanding and culling a small set of candidate featur es. Effectively , the N + operator serves as a heuristic for the search thr ough featur es spaces of possibly infinite size. 91 Conclusion 92 On the downside, PyPulse is much slower than its n -gram competition and requir es a laborious hyperparameter tuning. Thus, having a capable computing infrastructur e is a prer equisite for PyPulse ’s application. While PyPulse was shown to outperform hybrids of long- and short-term models, it has not yet been proven to outperform ensembles of several single-viewpoint n -gram models with viewpoints corresponding to the P ULSE features. The reported results give grounds for assuming that P ULSE could principally outperform its n - gram-ensemble counterpart, but to date this is practically out of limits due to the expensive hyperparameter optimization. In addition, it is pertinent to ask, whether the proposed generalized n -gram features are mor e suited to melody prediction than standard n -grams, as the conducted experiments provided mixed r esults. Further , I would like to point out that the decision to utilize SGD over quasi-Newton optimization methods based on Laver gne et al. (2010)’s benchmarks, was made in the anticipation of very large models. The models proved to be of medium size and thus a quasi-Newton method might perform faster . 7.2 Future Research There are several open leads for future resear ch that were not possible to tackle in this work. First and foremost, measures to reduce the runtime require further investigation. I propose the following approaches: • T weaking the log-linear model and objective: The size of the prediction space is limited because the computation of the partition function Z (see equation 2.5) requir es the summation over the entire space which rapidly becomes very costly . Methods that avoid the computation of Z are explained in Sutton, McCallum et al. (2010). • T weaking the optimization: On the one hand, the speed of OWL-QN BFGS (Andrew and Gao 2007) should be evaluated on the task of learning a musical model to either confirm or negate the superiority of SGD. On the other hand, I consider the present optimization problem in which only a small number of features is updated per step suitable to be parallelized using Hogwild (Recht et al. 2011). • T weaking hyperparameter optimization: Instead of speeding up the learn- ing process, the hyperparameter optimization – being the computational bottleneck of the framework – can be targeted directly . Especially for cases with a large number of hyperparameters, the gradient descent based hyper- parameter learning approach by Foo et al. (2008) appears prom ising. Besides, Conclusion 93 Langhabel, W olf f et al. (2016) propose a surrogate based method to optimize hyperparameters faster by transfer learning from prior optimizations with similar parameters. Surrogate based methods could speed up hyperparameter tuning significantly by generalizing over the cross-validation folds and even musical styles. • T weaking the featur e matrix creator: Currently , not all viewpoint featur e types are precomputed. Further precomputing will gain further improvement in performance. • Changing the objective in hyperparameter optimization: Large speedups can be achieved by selecting the hyperparameters with the focus on speed instead of performance. From the musicological side, I deem the following augmentations and future r e- search most inter esting: • T wo improvements can be made on the utilized benchmark corpus: (a) T o affor d proper modeling, the rest events should be consider ed, and (b) the target alphabet should be a contiguous interval of pitches rather than the subset of events that occurs in the dataset. • Following Pearce, Ruiz et al. (2010), it would be interesting to see if P ULSE is a reliable model for neur ophysiological data. • Following the lead of prior research, the next step would be the application of P ULSE to homophonic or polyphonic melody modeling. P ULSE poses an intriguing new case as it operates on a single model in contrast to MVS that are typically implemented as ensembles of dif fer ent viewpoint models. • A lack of time prevented the exploration of a Metropolis-Hastings based approach to generate globally optimal sequences. Note however , that for algorithmic composition this method is suboptimal, similar to the methods analyzed in this thesis, as the likeliest sequences constitute rather conserva- tive samples of the model. Computational creativity could be introduced by injecting events of distinguished unexpectedness using Bayesian surprise (Abdallah and Plumbley 2009) to find the requir ed balance between the known and unknown for the listener ’s ear (Meyer 1956). The model itself provides ample possibilities for futur e investigations: • Currently , the model uses binary feature functions. As the underlying CRF allows the usage of arbitrary feature functions, the benefits of using real valued functions should be evaluated. Conclusion 94 • Additionally , feature functions of higher complexity could be used. The choice of neural networks as feature functions appears particularly attractive as their capabilities in music related tasks were already substantiated (Cherla, T ran, Garcez et al. 2015; Thickstun et al. 2016). The N + operator ’s objective could be the discovery of network architectures. T raining can be done by backpropagating thr ough P ULSE ’s optimization gradients. • The single model approach of P ULSE can be complemented by learning a joint short- and long-term model, which is opposed to current approaches where both models are optimized separately and the r esulting distributions are combined. This means that currently , the optimization objective is not the maximum performance of the combined but of each separate model. It would be preferable to dir ectly optimize the joint hybrid performance. It is my hope that the framework presented in this thesis will serve as a basis for future r esear ch on interpretable cognitive models of music using P ULSE . Bibliography Abadi, Martín et al. (2015). T ensorFlow: Large-scale machine learning on heterogeneous systems . Software available fr om tensorflow .or g (cit. on p. 32). Abdallah, Samer and Mark Plumbley (2009). “Information dynamics: Patterns of expectation and surprise in the perception of music.” In: Connection Science 21.2-3, pp. 89–117 (cit. on p. 93). Agres, Kat, Samer Abdallah and Marcus Pearce (2017). “Information-theor etic prop- erties of auditory sequences dynamically influence expectation and memory .” In: Cognitive Science (cit. on pp. 11, 52). Alexandre, Luís A., Aurélio C. Campilho and Mohamad Kamel (2001). “On combin- ing classifiers using sum and product rules.” In: Pattern Recognition Letters 22.12, pp. 1283–1289 (cit. on p. 17). Andrew , Galen and Jianfeng Gao (2007). “Scalable training of l1-regularized log- linear models.” In: Proceedings of the 24th International Confer ence on Machine Learning . ACM, pp. 33–40 (cit. on pp. 27, 92). Behnel, Stefan et al. (2011). “Cython: The best of both worlds.” In: Computing in Science & Engineering 13.2, pp. 31–39 (cit. on p. 38). Bell, Robert M., Y ehuda Kor en and Chris V olinsky (2008). “The bellkor 2008 solution to the netflix prize.” In: Statistics Research Department at A T&T Research (cit. on p. 71). Bergstra, James et al. (2010). “Theano: A CPU and GPU math compiler in Python.” In: Proc. 9th Python in Science Confer ence (SciPy) , pp. 1–7 (cit. on p. 32). Bosley , Sam, Peter Swire, Robert M. Keller et al. (2010). “Learning to create jazz melodies using deep belief nets.” In: First International Conference on Computational Creativity (cit. on p. 20). Bottou, Léon (2010). “Large-scale machine learning with stochastic gradient de- scent.” In: Proceedings of COMPST A T 2010 . Springer, pp. 177–186 (cit. on p. 31). Brooks, Fr ederick P . et al. (1957). “An experiment in musical composition.” In: IRE T ransactions on Electronic Computers 3, pp. 175–182 (cit. on p. 18). Caplin, W illiam (1983). “T onal function and metrical accent: A historical perspec- tive.” In: Music Theory Spectrum 5, pp. 1–14 (cit. on p. 85). 95 Bibliog raph y 96 Carpenter , Bob (2008). Lazy sparse stochastic gradient descent for regularized mul tinomial logistic regr ession . T ech. r ep. Alias-i Inc., pp. 1–20 (cit. on p. 27). Cherla, Srikanth, Son N. T ran, Artur S. d’A vila Garcez et al. (2015). “Discriminative learning and inference in the recurr ent temporal RBM for melody modelling.” In: Neural Networks (IJCNN), International Joint Conference on . IEEE, pp. 1–8 (cit. on pp. 11, 20, 21, 52, 76, 94). Cherla, Srikanth, Son N. T ran, T illman W eyde et al. (2015). “Hybrid long-and short- term models of folk melodies.” In: International Society for Music Information Retrieval (ISMIR) , pp. 584–590 (cit. on pp. 14, 21, 72, 76, 91). Cherla, Srikanth, T illman W eyde and Artur S. d’A vila Garcez (2014). “Multiple view- point melodic pr ediction with fixed-context neural networks.” In: International Society for Music Information Retrieval (ISMIR) , pp. 101–106 (cit. on pp. 20, 76). Cherla, Srikanth, T illman W eyde, Artur S. d’A vila Garcez and Marcus Pearce (2013). “A distributed model for multiple-viewpoint melodic prediction.” In: Interna- tional Society for Music Information Retrieval (ISMIR) , pp. 15–20 (cit. on pp. 20, 76). Cleary , John and Ian W itten (1984). “Data compression using adaptive coding and partial string matching.” In: IEEE transactions on Communications 32.4, pp. 396– 402 (cit. on p. 19). Conklin, Darrell (1990). Pr ediction and entropy of music . Master ’s thesis. Department of Computer Science, University of Calgary (cit. on pp. 14, 15, 17). Conklin, Darr ell (2013). “Multiple viewpoint systems for music classification.” In: Journal of New Music Research 42.1, pp. 19–26 (cit. on pp. 15, 53). Conklin, Darrell and Christina Anagnostopoulou (2011). “Comparative pattern analysis of Cretan folk songs.” In: Journal of New Music Resear ch 40.2, pp. 119–125 (cit. on p. 11). Conklin, Darrell and Ian H. W itten (1995). “Multiple viewpoint systems for music prediction.” In: Journal of New Music Research 24.1, pp. 51–73 (cit. on pp. 14–17, 52, 89). Cuthbert, Michael Scott and Christopher Ariza (2010). “music21: A toolkit for computer-aided musicology and symbolic music data.” In: International Society for Music Information Retrieval (ISMIR) , pp. 637–642 (cit. on p. 51). Dietterich, Thomas G. (1998). “Approximate statistical tests for comparing super - vised classification learning algorithms.” In: Neural computation 10.7, pp. 1895– 1923 (cit. on p. 54). Duchi, John, Elad Hazan and Y oram Singer (2011). “Adaptive subgradient methods for online learning and stochastic optimization.” In: Journal of Machine Learning Research 12, pp. 2121–2159 (cit. on pp. 26, 32). Bibliog raph y 97 Duchi, John and Y oram Singer (2009). “Efficient online and batch learning using forward backward splitting.” In: Journal of Machine Learning Research 10, pp. 2899– 2934 (cit. on p. 27). Durand, Simon and Slim Essid (2016). “Downbeat detection with conditional ran- dom fields and deep learned features.” In: International Society for Music Informa- tion Retrieval (ISMIR) , pp. 386–392 (cit. on p. 23). Foo, Chuan-sheng, Chuong B. Do and Andrew Y . Ng (2008). “Efficient multiple hy- perparameter learning for log-linear models.” In: Advances in Neural Information Processing Systems , pp. 377–384 (cit. on p. 92). Gal, Y arin (2016). “Uncertainty in deep learning.” PhD thesis. University of Cam- bridge, UK (cit. on p. 21). Gal, Y arin and Zoubin Ghahramani (2016). “Dropout as a Bayesian appr oximation: Representing model uncertainty in deep learning.” In: Proceedings of the 33rd International Conference on Machine Learning , pp. 1050–1059 (cit. on p. 21). Hansen, Niels C. and Mar cus T . Pear ce (2014). “Pr edictive uncertainty in auditory sequence processing.” In: Fr ontiers in Psychology 5 (cit. on pp. 11, 20). Hedges, Thomas and Geraint A. W iggins (2016). “Improving pr edictions of derived viewpoints in multiple viewpoints systems.” In: International Society for Music Information Retrieval (ISMIR) , pp. 420–426 (cit. on p. 15). Hiller , Lejaren and Leonar d Maxwell Isaacson (1959). Experimental music . McGraw- Hill Book Company (cit. on p. 18). Hillewaere, Ruben, Bernar d Manderick and Darrell Conklin (2009). “Global featur e versus event models for folk song classification.” In: International Society for Music Information Retrieval (ISMIR) (cit. on p. 15). Huron, David B. (1997). “Humdrum and Kern: Selective feature encoding.” In: Beyond MIDI . MIT Press, pp. 375–401 (cit. on p. 51). Huron, David B. (2001). “T one and voice: A derivation of the rules of voice-leading from per ceptual principles.” In: Music Perception: An Interdisciplinary Journal 19.1, pp. 1–64 (cit. on p. 82). Huron, David B. (2006). Sweet anticipation: Music and the psychology of expectation . MIT press (cit. on pp. 10, 11). Kittler , Josef et al. (1998). “On combining classifiers.” In: T ransactions on Pattern Analysis and Machine Intelligence 20.3, pp. 226–239 (cit. on p. 17). Krumhansl, Car ol L. (1990). Cognitive foundations of musical pitch . Oxford Psychology 17. New Y ork / Oxfor d: Oxford University Pr ess (cit. on p. 42). Lafferty , John D., Andrew McCallum and Fernando C. N. Pereira (2001). “Condi- tional random fields: Probabilistic models for segmenting and labeling sequence data.” In: Pr oceedings of the 18th International Conference on Machine Learning . Morgan Kaufmann Publishers Inc., pp. 282–289 (cit. on p. 23). Bibliog raph y 98 Langford, John, Lihong Li and T ong Zhang (2009). “Sparse online learning via truncated gradient.” In: Journal of Machine Learning Resear ch 10, pp. 777–801 (cit. on p. 27). Langhabel, Jonas, Robert Lieck et al. (2017). “Feature discovery for sequential predic- tion of monophonic music.” In: International Society for Music Information Retrieval (ISMIR) (cit. on pp. 13, 39). Langhabel, Jonas, Jannik W olff and Raphaël Holca-Lamarr e (2016). Learning to optimise: Using Bayesian deep learning for transfer learning in optimisation . W orkshop on Bayesian Deep Learning, NIPS (cit. on p. 93). Larochelle, Hugo and Y oshua Bengio (2008). “Classification using discriminative restricted Boltzmann machines.” In: Proceedings of the 25th International Conference on Machine Learning . ACM, pp. 536–543 (cit. on p. 21). Lavergne, Thomas, Olivier Cappé and François Y von (2010). “Practical very lar ge scale CRFs.” In: Pr oceedings of the 48th Annual Meeting of the Association for Com- putational Linguistics . Association for Computational Linguistics, pp. 504–513 (cit. on pp. 31, 92). Lavrenko, V ictor and Jeremy Pickens (2003). “Polyphonic music modeling with random fields.” In: Proceedings of the 11th International Conference on Multimedia . ACM, pp. 120–129 (cit. on p. 23). Lehne, Moritz et al. (2013). “The influence of differ ent structural features on felt musical tension in two piano pieces by Mozart and Mendelssohn.” In: Music Perception: An Interdisciplinary Journal 31.2, pp. 171–185 (cit. on p. 11). Lerdahl, Fr ed and Ray Jackendoff (1985). A generative theory of tonal music . MIT press (cit. on pp. 10, 40, 45). Lerdahl, Fr ed and Ray Jackendof f (2006). “The capacity for music: What is it, and what’s special about it?” In: Cognition 100.1, pp. 33–72 (cit. on p. 45). Lieck, Robert and Marc T oussaint (2016). “T emporally extended featur es in model- based reinfor cement learning with partial observability.” en. In: Neurocomputing 192, pp. 49–60 (cit. on pp. 12, 22, 23, 35, 38, 45). Manning, Christopher (2017). Maximum entropy models . U R L : https://web.stanford. edu / class / archive / cs / cs224n / cs224n . 1162 / handouts / MaxentTutorial - 16x9- MEMMs- Smoothing.pdf (visited on 07/23/2017) (cit. on p. 49). Manzara, Leonard C., Ian H. W itten and Mark James (1992). “On the entropy of music: An experiment with Bach chorale melodies.” In: Leonardo Music Journal , pp. 81–88 (cit. on pp. 78, 80). Meyer , Leonard B. (1956). Emotion and meaning in music. University of Chicago Press (cit. on pp. 11, 93). Mozer , Michael C. (1991). “Connectionist music composition based on melodic, stylistic and psychophysical constraints.” In: Music and Connectionism , pp. 195– 211 (cit. on p. 20). Bibliog raph y 99 Narmour , Eugene (1992). The analysis and cognition of melodic complexity: The implication- realization model . University of Chicago Pr ess (cit. on pp. 10, 40, 84). Ng, Andrew Y . (2004). “Feature selection, l1 vs. l2 regularization, and rotational invariance.” In: Pr oceedings of the 21st International Conference on Machine Learning . ACM, p. 78 (cit. on p. 68). Ogihara, Mitsunori and T ao Li (2008). “ N -Gram chord profiles for composer style identification.” In: International Society for Music Information Retrieval (ISMIR) , pp. 671–676 (cit. on p. 18). Oord, Aar on van den et al. (2016). W avenet: A generative model for raw audio . arXiv: 1609.03499 (cit. on p. 22). Papadopoulos, George and Geraint W iggins (1999). “AI methods for algorithmic composition: A survey , a critical view and future pr ospects.” In: Symposium on Musical Creativity . AISB, pp. 110–117 (cit. on pp. 10, 49). Pearce, Mar cus T . (2005). “The construction and evaluation of statistical models of melodic structure in music perception and composition.” PhD thesis. Department of Computing, City University , London, UK (cit. on pp. 14, 15, 17, 19, 52, 77). Pearce, Mar cus T ., Darrell Conklin and Geraint A. W iggins (2004). “Methods for combining statistical models of music.” In: International Symposium on Computer Music Modeling and Retrieval . Springer, pp. 295–312 (cit. on p. 17). Pearce, Marcus T ., Daniel Müllensiefen and Geraint A. W iggins (2010). “The role of expectation and probabilistic learning in auditory boundary perception: A model comparison.” In: Perception 39.10, pp. 1367–1391 (cit. on p. 20). Pearce, Mar cus T . and Martin A. Rohrmeier (2012). “Music cognition and the cogni- tive sciences.” In: T opics in Cognitive Science 4.4, pp. 468–484 (cit. on p. 11). Pearce, Marcus T ., María Herrojo Ruiz et al. (2010). “Unsupervised statistical learning underpins computational, behavioural, and neural manifestations of musical expectation.” In: NeuroImage 50.1, pp. 302–313 (cit. on p. 93). Pearce, Mar cus T . and Geraint A. W iggins (2004). “Improved methods for statistical modelling of monophonic music.” In: Journal of New Music Resear ch 33.4, pp. 367– 385 (cit. on pp. 11, 14, 15, 19, 51, 52, 54, 69, 71, 72, 76, 77, 79, 91). Pearce, Mar cus T . and Geraint A. W iggins (2006). “Expectation in melody: The influence of context and learning.” In: Music Perception: An Interdisciplinary Journal 23.5, pp. 377–405 (cit. on pp. 11, 52, 78, 80, 81). Pearce, Marcus T . and Geraint A. W iggins (2012). “Auditory expectation: The in- formation dynamics of music per ception and cognition.” In: T opics in Cognitive Science 4.4, pp. 625–652 (cit. on pp. 11, 20, 44, 80). Peng, Fuchun, Fangfang Feng and Andrew McCallum (2004). “Chinese segmenta- tion and new wor d detection using conditional random fields.” In: Pr oceedings of the 20th International Conference on Computational Linguistics . Association for Computational Linguistics, p. 562 (cit. on p. 23). Bibliog raph y 100 Pinkerton, Richard C. (1956). “Information theory and melody .” In: Scientific Ameri- can (cit. on p. 18). Prechelt, Lutz (1998). “Automatic early stopping using cr oss validation: quantifying the criteria.” In: Neural Networks 11.4, pp. 761–767 (cit. on p. 58). Recht, Benjamin et al. (2011). “Hogwild: A lock-free approach to parallelizing stochastic gradient descent.” In: Advances in Neural Information Pr ocessing Systems , pp. 693–701 (cit. on p. 92). Rohrmeier , Martin A. (2007). “A generative grammar approach to diatonic harmonic structur e.” In: Proceedings of the 4th Sound and Music Computing Conference , pp. 97– 100 (cit. on pp. 10, 45). Rohrmeier , Martin A. (2011). “T owar ds a generative syntax of tonal harmony.” In: Journal of Mathematics and Music 5.1, pp. 35–53 (cit. on pp. 10, 45). Rohrmeier , Martin A. and Ian Cross (2008). “Statistical properties of harmony in Bach’s chorales.” In: 10th International Conference on Music Perception and Cognition (ICMPC) , pp. 619–627 (cit. on p. 18). Rohrmeier , Martin A. and Thore Graepel (2012). “Comparing feature-based models of harmony.” In: Proceedings of the 9th International Symposium on Computer Music Modelling and Retrieval . Citeseer, pp. 357–370 (cit. on p. 15). Rohrmeier , Martin A. and Stefan Koelsch (2012). “Predictive information processing in music cognition. A critical r eview.” In: International Journal of Psychophysiology 83.2, pp. 164–175 (cit. on pp. 11, 14, 18, 80). Rohrmeier , Martin A. and Patrick Rebuschat (2012). “Implicit learning and acquisi- tion of music.” In: T opics in Cognitive Science 4.4, pp. 525–553 (cit. on p. 10). Rumbaugh, James, Ivar Jacobson and Grady Booch (2004). Unified modeling language refer ence manual . Pearson Higher Education (cit. on p. 29). Saffran, Jenny R. and Gregory J. Griepentr og (2001). “Absolute pitch in infant au- ditory learning: evidence for developmental r eorganization.” In: Developmental psychology 37.1, p. 74 (cit. on p. 67). Saffran, Jenny R., Elizabeth K. Johnson et al. (1999). “Statistical learning of tone sequences by human infants and adults.” In: Cognition 70.1, pp. 27–52 (cit. on p. 10). Schellenberg, Glenn E. (1997). “Simplifying the implication-realization model of melodic expectancy .” In: Music Perception: An Interdisciplinary Journal 14.3, pp. 295– 318 (cit. on p. 10). Sertan, S. and Parag Chor dia (2011). “Modeling melodic impr ovisation in T urkish folk music using variable-length Markov models.” In: 12th International Society for Music Information Retrieval Conference , pp. 269–274 (cit. on p. 11). Shalev-Shwartz, Shai and Ambuj T ewari (2011). “Stochastic methods for l1-regularized loss minimization.” In: Journal of Machine Learning Research 12.Jun, pp. 1865–1892 (cit. on p. 27). Bibliog raph y 101 Sidorov , Kirill A., Andrew Jones and A. David Marshall (2014). “Music analysis as a smallest grammar pr oblem.” In: International Society for Music Information Retrieval (ISMIR) , pp. 301–306 (cit. on p. 45). Snoek, Jasper, Hugo Lar ochelle and Ryan P . Adams (2012). “Practical Bayesian optimization of machine learning algorithms.” In: Advances in Neural Information Processing Systems , pp. 2951–2959 (cit. on p. 53). Spiliopoulou, Athina and Amos Storkey (2011). “Comparing probabilistic models for melodic sequences.” In: Machine Learning and Knowledge Discovery in Databases , pp. 289–304 (cit. on p. 20). Srinivasamurthy , Ajay and Parag Chordia (2012). “Multiple viewpoint modeling of north Indian classical vocal compositions.” In: Pr oceedings of the International Symposium on Computer Music Modeling and Retrieval (cit. on p. 11). Steedman, Mark J. (1984). “A generative grammar for jazz chord sequences.” In: Music Perception: An Interdisciplinary Journal 2.1, pp. 52–77 (cit. on p. 10). Steinbeis, Nikolaus, Stefan Koelsch and John A. Sloboda (2006). “The role of har - monic expectancy violations in musical emotions: Evidence from subjective, physiological, and neural responses.” In: Journal of cognitive neuroscience 18.8, pp. 1380–1393 (cit. on p. 11). Sutskever , Ilya, Geoffr ey E. Hinton and Graham W . T aylor (2009). “The recurrent temporal r estricted Boltzmann machine.” In: Advances in Neural Information Processing Systems . MIT Pr ess, pp. 1601–1608 (cit. on p. 21). Sutton, Charles and Andrew McCallum (2006). An introduction to conditional random fields for relational learning . MIT Pr ess (cit. on p. 23). Sutton, Charles, Andrew McCallum et al. (2010). An intr oduction to conditional random fields . arXiv: 1011.4088 (cit. on p. 92). T eahan, W illiam J. and John G. Cleary (1996). “The entr opy of English using PPM- based models.” In: Data Compr ession Confer ence (DCC) . IEEE, pp. 53–62 (cit. on p. 14). T emperley , David (1999). “What’s key for key? The Krumhansl-Schmuckler key- finding algorithm reconsider ed.” In: Music Perception: An Interdisciplinary Journal 17.1, pp. 65–100 (cit. on p. 42). Thickstun, John, Zaid Harchaoui and Sham Kakade (2016). Learning featur es of music from scratch . arXiv: 1611.09827 (cit. on pp. 22, 94). T ibshirani, Robert (1996). “Regression shrinkage and selection via the lasso.” In: Journal of the Royal Statistical Society , pp. 267–288 (cit. on p. 26). T riviño-Rodriguez, José Luis and Rafael Morales-Bueno (2001). “Using multiat- tribute prediction suffix graphs to predict and generate music.” In: Computer Music Journal 25.3, pp. 62–79 (cit. on p. 52). T suruoka, Y oshimasa, Jun’ichi T sujii and Sophia Ananiadou (2009). “Stochastic gradient descent training for l1-r egularized log-linear models with cumulative Bibliog raph y 102 penalty.” In: Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP . Association for Computational Linguistics, pp. 477–485 (cit. on pp. 27, 32). V ishwanathan, S. V . N. et al. (2006). “Accelerated training of conditional random fields with stochastic gradient methods.” In: Proceedings of the 23rd International Conference on Machine Learning . ACM, pp. 969–976 (cit. on p. 31). V os, Piet G. and Jim M. T roost (1989). “Ascending and descending melodic intervals: Statistical findings and their per ceptual relevance.” In: Music Perception: An Interdisciplinary Journal 6.4, pp. 383–396 (cit. on p. 82). Whorley , Raymond P . et al. (2013). “The construction and evaluation of statistical models of melody and harmony.” PhD thesis. Goldsmiths, University of London, UK (cit. on pp. 14, 15). Whorley , Raymond P . and Darrell Conklin (2016). “Music generation from statistical models of harmony.” In: Journal of New Music Research 45.2, pp. 160–183 (cit. on pp. 15, 49, 53, 89). Whorley , Raymond P ., Geraint A. W iggins et al. (2013). “Multiple viewpoint sys- tems: T ime complexity and the construction of domains for complex musical viewpoints in the harmonisation problem.” In: Journal of New Music Resear ch 42, pp. 237–266 (cit. on pp. 15, 49). W olpert, David H. (1992). “Stacked generalization.” In: Neural networks 5.2, pp. 241– 259 (cit. on p. 71). W olpert, David H. and W illiam G. Macready (1997). “No fr ee lunch theorems for optimization.” In: T ransactions on Evolutionary Computation 1.1, pp. 67–82 (cit. on p. 23). W olpert, David H., W illiam G. Macr eady et al. (1995). No free lunch theorems for sear ch . T ech. r ep. SFI-TR-95-02-010, Santa Fe Institute (cit. on p. 23). Xiao, Lin (2010). “Dual averaging methods for regularized stochastic learning and online optimization.” In: Journal of Machine Learning Research , pp. 2543–2596 (cit. on p. 27). Zeiler , Matthew D. (2012). Adadelta: An adaptive learning rate method . arXiv: 1212.5701 (cit. on pp. 26, 56). Appendix A UML Class Diagram Please view on the next page. The colored containers are specializations of the general model: for melody prediction and time series data (green), CRF models (orange), and SGD optimization (red), respectively . A discussion of the general model can be found in section 3.1, the melody prediction specializations ar e discussed in chapter 4. 103 C o n d i t i o n a l R a n d o m F i e l d M o d e l M o n o p h o n i c M e l o d i e s M o d e l - n p l u s : N P l u s - o p t i m i z e r : L 1 O p t i m i z e r - m o d e l : M o d e l - f e a t u r e M a t r i x C r e a t o r : F e a t u r e M a t r i x C r e a t o r - u s e d F e a t u r e s : L i s t < F e a t u r e T y p e I D > - v a l u e R a n g e s : M a p < F e a t u r e T y p e I D , O b j e c t > - f e a t u r e S e t : F e a t u r e S e t - p u l s e I t e r a t i o n : i n t - m a x P u l s e I t e r a t i o n s : i n t - f e a t u r e S e t C o n v e r g e n c e F a c t o r P u l s e : f l o a t - f e a t u r e S e t C o n v e r g e n c e F a c t o r O p t i m i z a t i o n : f l o a t - g l o b a l L 1 F a c t o r : f l o a t - p e r F e a t u r e L 1 M o d e : s t r i n g - c l a s s L a b e l s : L i s t < L a b e l > P u l s e F o r w a r d s - t e m p o r a l H o r i z o n : i n t B a c k w a r d s - o p e r a n d s : L i s t < N P l u s > + L i s t N P l u s ( o p e r a n d s : L i s t < N P l u s > ) L i s t N P l u s - f e a t u r e s : L i s t < F e a t u r e > - w e i g h t s : L i s t < f l o a t > + F e a t u r e S e t ( ) + a d d F e a t u r e ( f e a t u r e : F e a t u r e ) + u p d a t e W e i g h t s ( o p t i m i z e d W e i g h t s : L i s t < f l o a t > ) + s h r i n k ( ) + g e t A l l F e a t u r e s ( ) : L i s t < F e a t u r e s > + g e t A l l W e i g h t s ( ) : L i s t < f l o a t > F e a t u r e S e t + p i t c h : i n t + d u r a t i o n : i n t + f i r s t I n B a r : b o o l + m e t r i c a l W e i g h t : i n t E v e n t C R F + P i t c h F e a t u r e = 0 + I n t e r v a l F e a t u r e = 1 + K e y A n c h o r F e a t u r e = 2 < < e n u m e r a t i o n > > F e a t u r e T y p e I D I * P i t c h F e a t u r e + p i t c h : i n t + d u r a t i o n : i n t T a r g e t E v e n t + F e a t u r e M a t r i x C r e a t o r ( ) + c o m p u t e F e a t u r e M a t r i x ( c o r p u s : L i s t < D a t a P o i n t , L a b e l > , f e a t u r e s : L i s t < F e a t u r e > , c l a s s L a b e l s : L i s t < L a b e l > ) : M a t r i x < f l o a t > + c o m p u t e C l a s s M a t c h I n d i c e s ( c o r p u s : L i s t < D a t a P o i n t , L a b e l > , f e a t u r e s : L i s t < F e a t u r e > , c l a s s L a b e l s : L i s t < L a b e l > ) : L i s t < i n t > F e a t u r e M a t r i x C r e a t o r -objective : Obje ct ive < < I n t e r f a c e > > L 1 O p t i m i z e r - m o d e l : M o d e l < < I n t e r f a c e > > O b j e c t i v e < < I n t e r f a c e > > M o d e l N e g L o g L i k e l i h o o d P C * < < C o n s t a n t > > + t y p e : F e a t u r e T y p e I D + F e a t u r e ( ) + f e a t u r e F u n c t i o n ( x : D a t a P o i n t , y : L a b e l ) : f l o a t < < I n t e r f a c e > > F e a t u r e < < C o n s t a n t > > - v i e w p o i n t : V i e w p o i n t < < I n t e r f a c e > > V i e w p o i n t F e a t u r e < < C o n s t a n t > > - v i e w p o i n t : V i e w p o i n t < < C o n s t a n t > > - a n c h o r : V i e w p o i n t < < I n t e r f a c e > > A n c h o r e d F e a t u r e + P i t c h = 0 + D u r a t i o n = 1 + K e y = 1 2 < < e n u m e r a t i o n > > V i e w p o i n t I n t e r v a l F e a t u r e K e y A n c h o r e d F e a t u r e S G D - l e a r n i n g R a t e : f l o a t - i n i t i a l G r a d i e n t S q u a r e d A c c u m u l a t o r : f l o a t - m a x T r a i n i n g E p o c h s : i n t - l o s s C o n v e r g e n c e F a c t o r : f l o a t A d a g r a d L 1 O p t i m i z e r - x : O b j e c t D a t a P o i n t - y : O b j e c t L a b e l - m e l o d y : L i s t < E v e n t > - p r e d i c t i o n T a r g e t : T a r g e t E v e n t + T i m e S e r i e s V i e w ( m e l o d y : L i s t < E v e n t > , p r e d i c t i o n T a r g e t : T a r g e t E v e n t ) + m a k e P a i r s ( t i m e s e r i e s : L i s t < E v e n t > ) : I t e r a t o r < D a t a P o i n t , L a b e l > T i m e S e r i e s V i e w - v a l u e R a n g e s : M a p < F e a t u r e T y p e I D , O b j e c t > - u s e d F e a t u r e s : L i s t < F e a t u r e T y p e I D > + N P l u s ( v a l u e R a n g e s : M a p < F e a t u r e T y p e I D , O b j e c t > , u s e d F e a t u r e s : L i s t < F e a t u r e T y p e I D > ) + g r o w ( f e a t u r e S e t : F e a t u r e S e t ) : f e a t u r e S e t : F e a t u r e S e t - m a k e I n i t i a l F e a t u r e S e t ( e m p t y F e a t u r e S e t : F e a t u r e S e t ) : f e a t u r e S e t : F e a t u r e S e t < < I n t e r f a c e > > N P l u s . . . . . . - c o n s t i t u e n t s : L i s t < F e a t u r e > + C o m p o u n d F e a t u r e ( c o n s t i t u e n t s : L i s t < F e a t u r e > ) + o p e r a t i o n ( ) C o m p o u n d F e a t u r e . . . 1 1 . . n 1 1 1 1 . . k 1 1 1 1 1 1 1 1 1 1 1 1 1 1 < < u s e > > P o w e r e d B y V i s u a l P a r a d i g m C o m m u n i t y E d i t i o n +L1Opt i mizer(objective : O bjective) Appendix B SGD Hyperparameter T able 5.3 visualizes the AdaGrad and AdaDelta hyperparameter optimization as contour plots. The exact performances are stated here, serving as a r efer ence. B.1 AdaGrad igsav 10 − 6 10 − 7 10 − 8 10 − 9 10 − 10 10 − 11 10 − 12 η 0.01 1.7881 1.7286 1.6948 1.6796 1.6744 1.6732 1.6730 0.1 1.6005 1.5747 1.5615 1.5553 1.5533 1.5529 1.5529 1.0 1.5550 1.5516 1.5499 1.5491 1.5488 1.5487 1.5488 10.0 1.6374 1.6426 1.6429 1.6428 1.6428 1.6428 1.6428 (a) AdaGrad after 100 epochs igsav 10 − 6 10 − 7 10 − 8 10 − 9 10 − 10 10 − 11 10 − 12 η 0.01 1.6610 1.6287 1.6117 1.6047 1.6026 1.6021 1.6020 0.1 1.5568 1.5482 1.5444 1.5429 1.5425 1.5425 1.5426 1.0 1.5411 1.5397 1.5396 1.5396 1.5395 1.5395 1.5396 10.0 1.5849 1.5855 1.5855 1.5855 1.5855 1.5855 1.5855 (b) AdaGrad after 500 epochs T able B.1: The objective values (negative log-likelihood) after 100 and 500 epochs for AdaGrad with various hyperparameter settings. 105 SGD Hyper parameter 106 B.2 AdaDelta e 10 − 3 10 − 4 10 − 5 10 − 6 10 − 7 10 − 8 10 − 9 ρ 0.85 2.0105 2.0105 2.0106 2.0107 2.0124 2.0286 2.1361 0.90 2.0105 2.0105 2.0106 2.0107 2.0118 2.0227 2.1014 0.95 2.0105 2.0105 2.0106 2.0106 2.0112 2.0167 2.0606 0.99 2.0105 2.0105 2.0105 2.0106 2.0107 2.0118 2.0216 (a) AdaDelta after 100 epochs ( η = 1) e 10 − 3 10 − 4 10 − 5 10 − 6 10 − 7 10 − 8 10 − 9 ρ 0.85 1.7760 1.7760 1.7761 1.7762 1.7772 1.7882 1.8775 0.90 1.7760 1.7760 1.7761 1.7761 1.7768 1.7839 1.8472 0.95 1.7760 1.7760 1.7761 1.7761 1.7764 1.7799 1.8129 0.99 1.7760 1.7760 1.7760 1.7761 1.7768 1.7768 1.7833 (b) AdaDelta after 500 epochs ( η = 1) T able B.2: The objective values (negative log-likelihood) after 100 and 500 epochs for AdaDelta with various hyperparameter settings. Appendix C Generated Melodies C.1 Generated Bach Chorales The model used for generation was learned from the Bach chorales dataset with the PI*C*KM K -L TM. The sequences were inferr ed using beam search with k = 5 slots. Figure C.1: A generated Bach chorale initialized with start pitch value 65. Figure C.2: A generated Bach chorale initialized with the first seven tones of Meinen Jesum laß’ ich nicht, Jesu (BWV 379). 107 Generated Melodies 108 C.2 Generated Chinese Folk Melodies The model was learned fr om the Chinese folk melodies dataset, using the PI*C*KM K - L TM. The sequences were generated using iterative random walk with a threshold level of 0.65. Figure C.3: A generated Chinese folk melody initialized with start pitch value 72. Figure C.4: A generated Chinese folk melody initialized with the first seven tones of the tune Y ila yiche hao nanhuo from Hequ County , Shanxi.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment