Large-scale weakly supervised audio classification using gated convolutional neural network
In this paper, we present a gated convolutional neural network and a temporal attention-based localization method for audio classification, which won the 1st place in the large-scale weakly supervised sound event detection task of Detection and Class…
Authors: Yong Xu, Qiuqiang Kong, Wenwu Wang
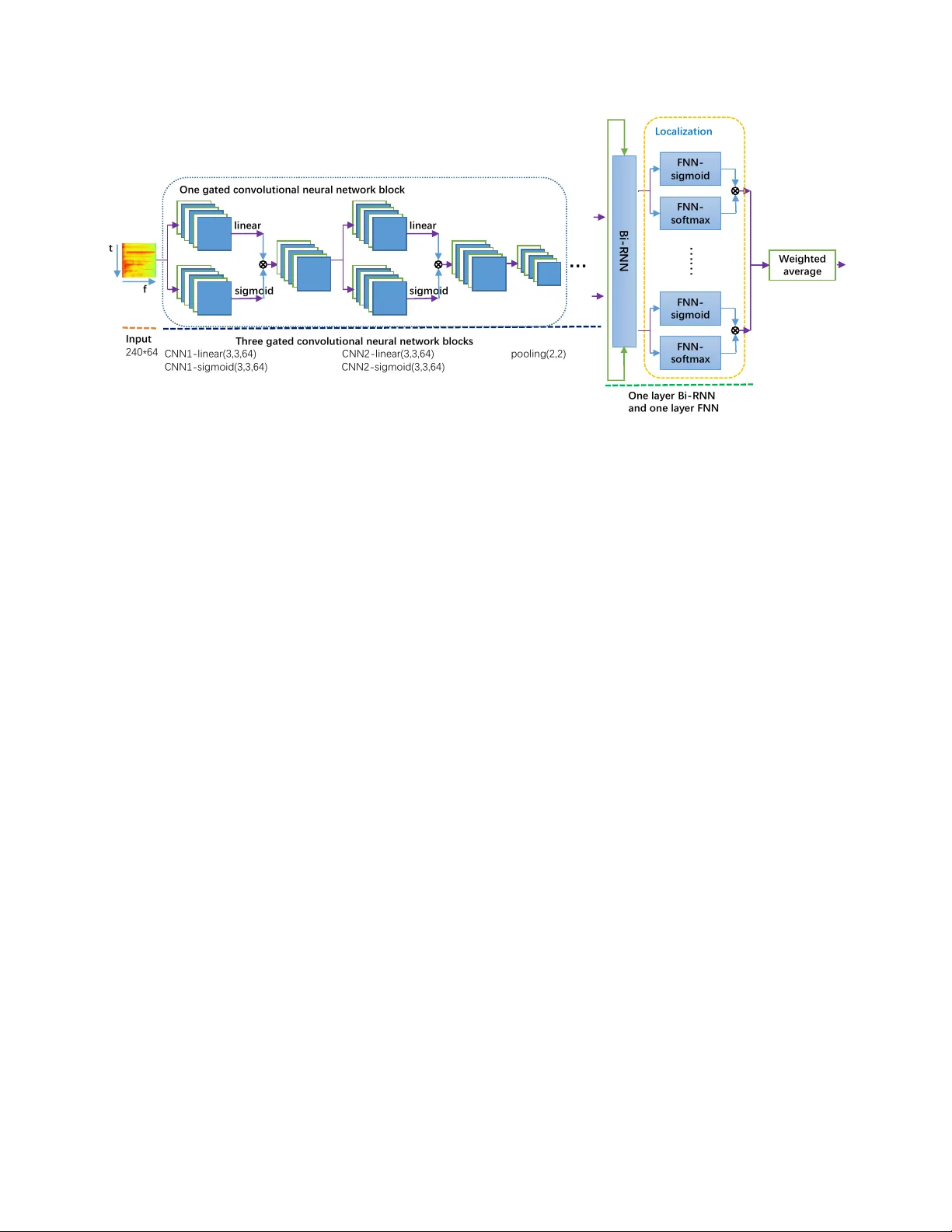
LARGE-SCALE WEAKL Y SUPER VISED A UDIO CLASSIFICA TION USING GA TED CONV OLUTIONAL NEURAL NETWORK Y ong Xu*, Qiuqiang K ong*, W enwu W ang, Mark D. Plumble y Center for V ision, Speech and Signal Processing, Uni versity of Surre y , UK { yong.xu, q.kong, w .wang, m.plumbley } @surre y .ac.uk ABSTRA CT In this paper , we present a gated con volutional neural net- work and a temporal attention-based localization method for audio classification, which won the 1st place in the large-scale weakly supervised sound ev ent detection task of Detection and Classification of Acoustic Scenes and Events (DCASE) 2017 challenge. The audio clips in this task, which are ex- tracted from Y ouT ube videos, are manually labelled with one or a few audio tags but without time stamps of the audio ev ents, which is called as weakly labelled data. T wo sub- tasks are defined in this challenge including audio tagging and sound e vent detection using this weakly labelled data. A con v olutional recurrent neural network (CRNN) with learn- able gated linear units (GLUs) non-linearity applied on the log Mel spectrogram is proposed.In addition, a temporal at- tention method is proposed along the frames to predicate the locations of each audio event in a chunk from the weakly la- belled data. W e ranked the 1st and the 2nd as a team in these two sub-tasks of DCASE 2017 challenge with F v alue 55.6% and Equal error 0.73, respectiv ely . Index T erms — DCASE2017 challenge, weakly super- vised sound ev ent detection, audio tagging, attention, gated linear unit 1. INTR ODUCTION Audio classification is a task to classify audio recordings into different classes. W eakly labelled audio data contains only the presence or absence of the audio ev ents but without the time stamps of the audio e vents [1]. W eakly labelled audio classification has many applications in information retriev al [2], surveillance of abnormal sound in public area and indus- try use [3]. Some challenges divide the audio classification to subtasks including audio scene classification [4] and sound ev ent detection [4]. Recently a lar ge-scale weakly supervised sound event detection task of Detection and Classification of Acoustic Scenes and Events (DCASE) 2017 challenge [5] was proposed where the data set is a subset of Google AudioSet [6] containing both transportation and warnings * These first two authors contributed equally to this w ork. sounds. This task includes an audio tagging (A T) [7] subtask and a weakly supervised sound event detection (SED) [8] subtask. The A T task aims to predict one or a fe w labels of an audio recording and SED needs to predict the time stamps of the audio ev ents. Many audio classification methods are based on the bag of frames [9] assumption, where an audio recording is cut into segments and each segment inherits the labels of the au- dio recording. Howe ver this assumption is incorrect because some audio ev ents only happen a short time in an audio clip. Multi-instance learning (MIL) [1] has been applied to train on the weakly labelled data. Recently state-of-the-art audio classification methods [10, 11] transform the wav eform to the time-frequency (T -F) representation. Then the T -F representa- tion is treated as an image which is fed into CNNs. Howe ver , unlike image classification where the objects are usually cen- tered and occupies a dominant part of the image, audio ev ents may only occur a short time in an audio recording. T o solv e this problem, some attention models [12] for audio classifica- tion are applied to attend to the audio ev ents and ignore the background sounds. In this paper , we propose a unified neural network model which fits for both of the audio tagging task and the weakly sound event detection task, simultaneously . The first contri- bution of this paper is to apply the learnable gated linear unit (GLU) [13] to replace the ReLU activ ation [14] after each layer of the conv olutional neural network for audio classifi- cation. This learnable gate is able to control the information flow to the next layer . When a gate is close to 1, then the corresponding T -F unit is attended. When a gate is close to 0, then the corresponding T -F unit is ignored. Following the con v olutional layers, the recurrent layer is follo wed to uti- lize the temporal information. Then the temporal attention method is proposed to localize the audio ev ents in a chunk. This attention part will attend to the audio events and ignore unrelated audio segments hence it is able to do sound ev ent detection from weakly labeled data. The paper is organized as follows. Section 2 introduces the gated linear units in the neural network. Section 3 pro- posed the localization method for audio events from the weakly labeled data. Section 4 shows experiments. Section 5 summaries and forecasts the future work. In put 240*64 line ar sigmoid line ar sigmoid Thre e ga ted c o n volu tion al n eu r al n etwor k bl o c ks … One ga ted c o n volu tion al n eu r al n etwor k bl o c k CNN 1 - li n ear(3,3,64) CNN 2 - li n ear(3,3,64) pooli n g (2,2) CNN 1 - si gmoid(3,3, 64) CNN 2 - si gmoid( 3,3,64) One la yer Bi - R NN a n d o n e la yer FNN FNN - sigmoid FNN - so ftmax L o c al ization We ig ht ed aver ag e FNN - sigmoid FNN - so ftmax …… Bi - RNN t f Fig. 1 . The diagram of the proposed unified model for audio tagging and weakly supervised sound e vent detection (SED). The final outputs are the audio tagging predictions. SED predictions are extracted from the intermediate localization module. 2. PR OPOSED GA TED LINEAR UNITS IN CRNN FOR A UDIO T A GGING In this section, the Con volution recurrent neural networks (CRNNs) baseline, gated linear unit (GLU), mini-batch data balancing and system fusion will be introduced. 2.1. CRNN baseline CRNN has been successfully used in audio classification task [15, 11]. For the audio tagging task, a CRNN-based method has been proposed in [16, 12] to predict the audio tags. First the wav eform of the audio recordings are transformed to T -F representation such as log Mel spectrogram. Then con volu- tional layers are applied on the T -F representation to extract high lev el features. Then a bi-directional recurrent neural network (Bi-RNN) are adopted to capture the temporal con- text information followed by a feed-forward neural network (FNN) with the number of audio classes to predict the poste- riors of each audio class at each frame. Finally , the predicti on probability of each audio tag is obtained by av eraging the pos- teriors of all the frames. In the training phase, we apply the binary cross-entropy loss between the predicted probability and the ground truth of an audio recording. The weights of the neural network can be updated by the gradient of the weights computed using back- propagation. The loss can be defined as: E = − N X n =1 ( P n log O n + (1 − P n ) log (1 − O n )) (1) where E is the binary cross-entropy , O n and P n denote the estimated and reference tag vector at sample index n , re- spectiv ely . The bunch size is represented by N . Adam [17] is used as the stochastic optimization method. 2.2. Gated linear units in CNNs W e propose to use the gated linear units (GLUs) [13] as ac- tiv ation to replace the ReLU [14] activ ation in the CRNN model. GLUs are first proposed in [13] for language mod- eling. The motiv ation of using GLUs in audio classification is to introduce the attention mechanism to all the layers of the neural network. The GLUs can control the amount of infor- mation of a T -F unit flow to the next layer . If a GLU is close to 1, then the corresponding T -F unit should be attended. If a GLU is close to 0, then the corresponding T -F unit should be ignored. By this means the network will learn to attend to the audio ev ents and ignore the unrelated sounds. GLUs are defined as: Y = ( W ∗ X + b ) σ ( V ∗ X + c ) (2) where σ is the sigmoid non-linearity and is the element- wise product and ∗ is the conv olution operator . W and V are the con volutional filters, b and c are the biases. X denotes the input T -F representation in the first layer or the feature maps of the interval layers. The framework of the model is shown in Fig. 1, a pair of con v olutional networks are used to generate the gating out- puts and the linear outputs. These GLUs can reduce the gra- dient vanishing problem for deep networks by providing a linear path for the gradients while retaining non-linear capa- bilities through the sigmoid operation. The output of each layer is a linear projection ( W ∗ X + b ) modulated by the gates σ ( V ∗ X + c ) . Similar to the gating mechanisms in long short-term memories (LSTMs) [18] or gated recurrent units (GR Us) [19], these gates multiply each element of the matrix ( W ∗ X + b ) and control the information passed on in the hier- archy [13]. From the feature selection vie w , the GLUs can be regarded as an attention scheme on the time-frequency (T -F) bin of each feature map. It can attend to the T -F bin with re- lated audio ev ents by setting its value close to one otherwise close zero. 2.3. Mini-batch data balancing The data set defined in this challenge is highly unbalanced, that means the number of samples of each class varies a lot. For example, the ‘car’ class occurred 25744 times in the data set while ‘car alarm’ only occurred 273 times. This highly unbalanced data will bias the training to the class with a large number of occurrences. As we are using mini-batch to train the network, there is a extreme situation where all the samples in a mini-batch are ‘car’. T o solve this problem we balance the frequency of different classes in a mini-batch to ensure that the number of most frequent samples is at most 5 times than the least frequent samples in a mini-batch av eragely . 2.4. System results fusion System results fusion is important to improve the robustness of systems. In this work, we adopt two lev el fusion strate- gies. As neural networks are trained by the stochastic gradient descent (SGD)algorithm with a fixed or dynamically chang- ing learning rate, the performance will be gradually better b ut fluctuant along the epochs. Hence, our first fusion strategy is conducted among the epochs in the same system. This will improv e its stability of the system. The second fusion strat- egy is to av erage the posteriors from different systems with different configurations. 3. PR OPOSED LOCALIZA TION FOR WEAKL Y SUPER VISED SOUND EVENT DETECTION Different from the audio tagging task without knowing the temporal locations of each audio ev ent which is presented in Sec. 2, the sound ev ent detection (SED) task needs to predict the temporal locations of each occurring audio event. The problem w ould be more dif ficult if there was no strong labels, namely frame-lev el labels. This is the so-called weakly super - vised SED defined in the task 4 of DCASE2017 challenge. As shown in Fig. 1, an additional feed-forw ard neural net- work with softmax as the activ ation function is introduced to help to infer the temporal locations of each occurring class. T o keep the time resolution of the input whole audio spec- trogram, we adjust the pooling steps in CNNs sho wn in Fig. 1 by only pooling on the spectral axis while not pooling on the time axis. So the feed-forward with sigmoid as the acti- vation function shown in Fig. 1 will do classification at each frame, meanwhile the feed-forward with softmax as the acti- vation function sho wn in Fig. 1 will attend on the most salient frames for each class. If we define the FNN-softmax output, Z loc ( t ) , as the lo- calization vector , then it is multiplied with the classification output O ( t ) at each frame as, O 0 ( t ) = O ( t ) Z loc ( t ) (3) where represents the element-wise multiplication. T o get the final acoustic ev ent tag predictions, O 0 ( t ) should be aver - aged across the audio chunk to get the final output O 00 . O 00 is defined as the weighted av erage of O 0 ( t ) as following, O 00 = P T − 1 t =0 O 0 ( t ) P T − 1 t =0 Z loc ( t ) (4) where T is final frame-lev el resolution along the spectrogram. If there is no pooling along the time axis, T will be the same with the frame number of the whole audio spectrogram con- sidering that the input is the whole spectrogram. Note that there is no frame-lev el strong labels, the tem- poral locations of each occurring class can only be weakly- supervised inferred as intermediate variables. The back- propagate loss is the same with the audio tagging task by comparing the reference labels with the final output O 00 . 4. EXPERIMENTS AND RESUL TS 4.1. Experimental setup The task employs a subset of Google Audioset [20]. AudioSet consists of an e xpanding ontology of 632 sound event classes and a collection of 2 million human-labeled 10-second sound clips (less than 21% are shorter than 10-seconds) drawn from 2 million Y ouT ube videos. The ontology is specified as a hi- erarchical graph of event categories, covering a wide range of human and animal sounds, musical instruments and gen- res, and common ev eryday environmental sounds. The sub- set consists of 17 sound ev ents divided into two categories: “W arning” and “V ehicle”. Log-Mel filter banks and Mel-frequency cepstral coeffi- cients (MFCCs) are used as our features. Each chunk has 240 frames by 64 mel frequency channels. As sho wn in Fig. 1, three gated conv olutional neural network blocks are adopted. Each conv olutional network has 64 filters with 3*3 size. The pooling size is 2*2 for the audio tagging sub-task while it is 1*2 for the sound event detection sub-task. One bi-directional gated recurrent neural network with 128 units is used. The feed-forward neural network has 17 output nodes where each of them is corresponding to each audio e vent class. The learn- ing rate is fixed to be 0.001. The source codes for this paper can be downloaded from Github 1 . 1 https://github.com/yongxuUSTC/dcase2017_task4_ cvssp 4.2. Results In this section, the audio tagging results and then the weakly supervised sound ev ent detection results will be gi ven. 4.2.1. Audio tag ging T able 1 presents the F1, Precision and Recall comparisons for the audio tagging sub-task on the development set and the e v aluation set. “CRNN-logMel-noBatchBal” denotes the CRNN system trained without mini-batch data balanc- ing strategy . The DCASE2017 baseline model was multi- layer perceptron (MLP) based method [5]. Our proposed CRNN systems sho w much better performance. Compared the CRNNs with/without mini-batch balancing, data balanc- ing is important to get higher F1, precision and recall scores. The proposed gated CRNN also gains effecti ve improvement. The final fusion system is conducted by combining the system trained on different features, namely log Mel and MFCC. On the ev aluation set which is a blinding test, our system ranks 1st in this audio tagging challenge according to the more comprehensiv e score, namely F1. CNN-ensemble [21] and Frame-CNN [22] ranks 2nd and 3rd as a team, respectively . Note that our system has a notable absolute 3% i mprovement ov er the 2nd system [21]. T able 1 . F1, Precision and Recall comparisons for the audio tagging sub-task on the dev elopment the ev aluation sets. Dev-set F1 Precision Recall DCASE2017 Baseline [5] 10.9 7.8 17.5 CRNN-logMel-noBatchBal 42.0 47.1 38.0 CRNN-logMel (i) 52.8 49.9 56.1 Gated-CRNN-logMel (ii) 56.7 53.8 60.1 Gated-CRNN-MFCC (iii) 52.1 51.7 52.5 Fusion (ii+iii) 57.7 56.5 58.9 Eval-set F1 Precision Recall DCASE2017 Baseline [5] 18.2 15.0 23.1 CNN-ensemble [21] 52.6 69.7 42.3 Frame-CNN [22] 49.0 53.8 45.0 Our gated-CRNN-logMel 54.2 58.9 50.2 Our fusion system 55.6 61.4 50.8 4.2.2. W eakly supervised sound event detection (SED) The results of F1 and Error rate comparisons on the de- velopment set and the ev aluation set are given in T able 2. Our proposed gated-CRNN-logMel method outperforms the DCASE2017 baseline [5]. W ith the fusion system, we ranks 2nd as a team in the sound ev ent detection sub-task. The 1st place team achieves 0.66 Error rate and 55.5% F1 score [21]. Howe ver , [21] used segment input for SED, separately . It assumed that audio ev ents occured e verywhere along the Ground truth Predict ion Train Train Train horn Train horn …… …… Fram e 17 classes Fig. 2 . An example for predicting locations along 240 frames for “10i60V1RZkQ 210.000 220.000.wav” using the proposed localization method. chunk. Our method is a unified method without any assump- tion. Attention based localization seems to be reasonable for weakly supervised SED. Fig. 2 shows an example for predicating temporal loca- tions along 240 frames for occurring audio ev ents, namely ‘train’ and ‘train horn’. Our proposed localization method can almost successfully detect the accurate temporal locations for occurring e vents, except for the small segment false alarm for the ‘train horn’. T able 2 . The results of F1 and Error rate comparisons on the dev elopment set and the ev aluation set for the sound event detection sub-task are gi ven in T able 2. among sev eral meth- ods across the 17 audio ev ent tags. Dev-set F1 Error rate DCASE2017 baseline [5] 13.8 1.02 Gated-CRNN-logMel 47.20 0.76 Fusion 49.7 0.72 Eval-set F1 Error rate DCASE2017 baseline [5] 28.4 0.93 Gated-CRNN-logMel 47.50 0.78 Fusion 51.8 0.73 5. CONCLUSIONS In this paper , we proposed a unified method for audio tagging and weakly supervised sound ev ent detection. Gated CRNN method is proposed, where the learnable gated linear units can help to select the most related features corresponding to the final labels. The temporal attention based localization method is also proposed to localize the occured e vents along the chunk in a weakly supervised mode. The final system puts us as in the 1st place with 57.7% F1 score on the audio tag- ging sub-task of DCASE2017 challenge. W e also ranks 2nd as a team in the SED sub-task. In the future, we will ev aluate our proposed method on Audioset [20]. 6. REFERENCES [1] Anurag K umar and Bhiksha Raj, “ Audio ev ent detection using weakly labeled data, ” in Pr oceedings of A CM on Multimedia Confer ence . A CM, 2016, pp. 1038–1047. [2] Dmitry Bogdanov , Nicolas W ack, Emilia G ´ omez, Sankalp Gulati, Perfecto Herrera, Oscar Mayor , Ger- ard Roma, Justin Salamon, Jos ´ e R Zapata, Xavier Serra, et al., “Essentia: An audio analysis library for music information retriev al., ” in ISMIR , 2013, pp. 493–498. [3] Svilen Dimitrov , Jochen Britz, Boris Brandherm, and Jochen Frey , “ Analyzing sounds of home en vironment for device recognition., ” in AmI . Springer, 2014, pp. 1– 16. [4] Annamaria Mesaros, T oni Heittola, and T uomas V irta- nen, “T ut database for acoustic scene classification and sound ev ent detection, ” in EUSIPCO . IEEE, 2016, pp. 1128–1132. [5] Annamaria Mesaros, T oni Heittola, Aleksandr Diment, Benjamin Elizalde, Ankit Shah, Emmanuel V incent, Bhiksha Raj, and T uomas V irtanen, “Dcase 2017 chal- lenge setup: T asks, datasets and baseline system, ” in Pr oceedings of DCASE2017 W orkshop . [6] Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, W ade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter , “ Audio set: An on- tology and human-labeled dataset for audio events, ” in ICASSP , 2017. [7] Y Xu, Q Huang, W W ang, , P Foster , S Sigtia, PJB Jack- son, and MD Plumbley , “Unsupervised feature learning based on deep models for en vironmental audio tagging, ” in IEEE/ACM T rans. on audio, speech and language pr ocessing , 2017. [8] Q Kong, Y Xu, W enwu W ang, and Mark D Plumbley , “ A joint detection-classification model for audio tagging of weakly labelled data, ” ICASSP , 2017. [9] Jiaxing Y e, T akumi Kobayashi, Masahiro Murakawa, and T etsuya Higuchi, “ Acoustic scene classification based on sound textures and ev ents, ” in Pr oceedings of A CM on Multimedia confer ence . ACM, 2015, pp. 1291– 1294. [10] Keunwoo Choi, George Fazekas, and Mark Sandler, “ Automatic tagging using deep con volutional neural net- works, ” arXiv preprint , 2016. [11] Giambattista Parascandolo, T oni Heittola, Heikki Hut- tunen, T uomas V irtanen, et al., “Conv olutional recurrent neural networks for polyphonic sound e vent detection, ” IEEE/A CM T ransactions on Audio, Speech, and Lan- guage Pr ocessing , vol. 25, no. 6, pp. 1291–1303, 2017. [12] Y ong Xu, Qiuqiang K ong, Qiang Huang, W enwu W ang, and Mark D. Plumbley , “ Attention and localization based on a deep con volutional recurrent model for weakly supervised audio tagging, ” in INTERSPEECH , 207, pp. 3083–3087. [13] Y ann N Dauphin, Angela Fan, Michael Auli, and Da vid Grangier , “Language modeling with gated con volu- tional networks, ” arXiv preprint , 2016. [14] V inod Nair and Geoffre y E Hinton, “Rectified linear units improve restricted boltzmann machines, ” in ICML , 2010, pp. 807–814. [15] Sharath Adav anne, Pasi Pertil ¨ a, and T uomas V irtanen, “Sound ev ent detection using spatial features and con- volutional recurrent neural network, ” arXiv pr eprint arXiv:1706.02291 , 2017. [16] Y ong Xu, Qiuqiang K ong, Qiang Huang, W enwu W ang, and Mark D. Plumbley , “Con v olutional gated recurrent neural network incorporating spatial features for audio tagging, ” in IJCNN , 2017, pp. 3461–3466. [17] Diederik Kingma and Jimmy Ba, “ Adam: A method for stochastic optimization, ” arXiv pr eprint arXiv:1412.6980 , 2014. [18] Sepp Hochreiter and J ¨ urgen Schmidhuber, “Long short- term memory , ” Neural Computation , vol. 9, no. 8, pp. 1735–1780, 1997. [19] Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Y oshua Bengio, “Empirical ev aluation of gated re- current neural networks on sequence modeling, ” arXiv pr eprint arXiv:1412.3555 , 2014. [20] Jort F . Gemmeke, Daniel P . W . Ellis, Dylan Freedman, Aren Jansen, W ade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter , “ Audio set: An on- tology and human-labeled dataset for audio events, ” in ICASSP , 2017. [21] Kyogu Lee, Donmoon Lee, Subin Lee, and Y oonchang Han, “Ensemble of con volutional neural networks for weakly-supervised sound ev ent detection using multi- ple scale input, ” T ech. Rep., DCASE2017 Challenge, September 2017. [22] Szu-Y u Chou, Jyh-Shing Jang, and Y i-Hsuan Y ang, “FrameCNN: a weakly-supervised learning framework for frame-wise acoustic e vent detection and classifica- tion, ” T ech. Rep., DCASE2017 Challenge, 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment