Consensus based Detection in the Presence of Data Falsification Attacks
This paper considers the problem of detection in distributed networks in the presence of data falsification (Byzantine) attacks. Detection approaches considered in the paper are based on fully distributed consensus algorithms, where all of the nodes …
Authors: Bhavya Kailkhura, Swastik Brahma, Pramod K. Varshney
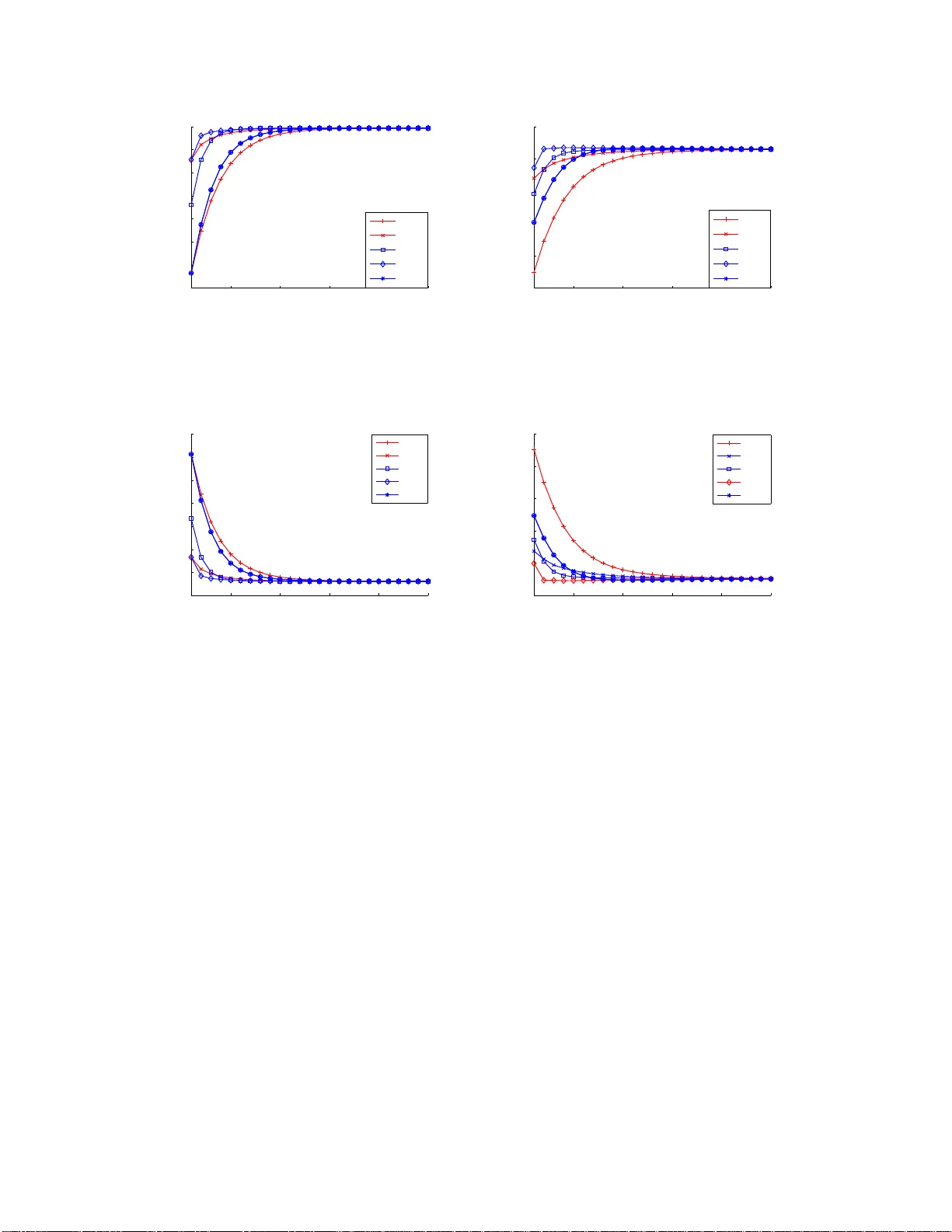
1 Consensus based Dete ction in the Pr esenc e of Data F alsification Attacks Bhavya Kailkhura, Student Member , I EEE , Swastik Br ahma, Member , IEEE , Pramod K. V arshney , F ellow , IEEE Abstract This paper c onsiders the pr oblem of detection in distributed n etworks in the presen ce of data falsification (Byzantine) attacks. Detection approa ches con sidered in the paper are based on fully distributed con sensus algorithm s, where all of th e nodes exchange in formation o nly with their n eighbo rs in the absence of a fusion center . In such networks, we character ize the negativ e effect of Byzan tines on the steady -state an d tr ansient detection pe rforman ce of the conventional consensus b ased detection algorithm s. T o ad dress this issue, we study th e prob lem from the network design er’ s perspec ti ve. M ore specifically , we first prop ose a distributed weighted average consensus alg orithm that is robust to Byzantine attac ks. W e show that, un der rea sonable assumption s, the g lobal test statistic for detection can be com puted lo cally at each no de u sing our pro posed con sensus alg orithm. W e exploit the statistical distribution of the n odes’ data to devise techniques for m itigating the influ ence of data falsifyin g Byzantines on the distrib uted detection system. Since some pa rameters of the statistical distribution of the no des’ data mig ht n ot be kn own a priori , w e prop ose learnin g based tech niques to enable an adaptive design of the local fu sion or update rules. Index T erms distributed detection , consensu s algo rithms, d ata falsification a ttacks, By zantines This work w as supported by the Center for A dv anced Systems and Engineering at Syracuse Uni ve rsity . The authors would like to thank Aditya V empaty and Arun Subramanian for their v aluable comments and suggestions to improv e the quality of the paper . B. Kailkhu ra, S. Brahma and P . K . V arshney are with Department of EECS, Syracuse University , Syracuse, NY 13244. (email: bkailkhu@syr .edu; skbrahma@syr .edu; v arshney @syr .edu) March 1, 2022 DRAFT 2 I . I N T RO D U C T I O N Distributed detection is a well studied topic in the detection theory lit erature [1]–[3]. The traditional distributed detectio n frame work comprises of a group of spatiall y distributed nodes which acquire t he o bserva tions regarding the phenomenon of int erest and send th em to the fusion center (FC) where a global decision is made. Ho we ver , in many scenarios a centralized FC may not be av ailable or i n large networks, t he FC can b ecome an i nformation bottleneck that m ay cause degradation of system performance, and m ay e ven lead to system failure. Also, due to the distributed nature of future com munication networks, and various practical cons traints, e.g., absence of the FC, transmit power o r hardware constraints and dynam ic characteristic of wireless medium, it may be d esirable to empl oy alternate peer-to-peer local information exchange in order to reach a gl obal decisio n. One such distributed approach for peer -to-peer local information exchange and inference is the use of a consensus algorit hm [27]. Recently , d istributed detection based on consensus al gorithms has been explored in [4]–[9]. In consensus based detection approaches, each n ode communi cates only wit h its neighbors and updates its local state informati on about the p henomenon (sum mary statistic) by a local fusion rule that employs a weighted com bination of its own value and those receive d from its nei ghbors. Nodes continue with t his consensus it eration until the w hole network con ver ges to a st eady-state value whi ch is the global test s tatistic. In particul ar , the authors in [5], [6] cons idered ave rage consensus based distributed d etection and emphasized n etwork desi gns based on th e small world phenomenon for faster con ver gence [7]. A bio-insp ired consensus scheme was introduced for spectrum s ensing in [8]. Howe ver , these consensus -based fus ion algori thms only ensure equal gain combin ing of local m easurements. The authors in [9] propos ed to use dist ributed weighted fusion algorit hms for cognitive radi o spectrum s ensing. They showed that weig hted av erage consensus based schemes outperform aver age consensus based schemes and achieve much better detection performance than the equal g ain combini ng based schemes. Howe ver , th e weight ed a verage consensus based detection schemes are qu ite vulnerable to diffe rent types of attacks. One typ ical attack on such networks is a Byzantine attack. While Byzantine attacks (originally proposed in [10 ]) m ay , in general, refer to many types of mali cious behavior , our focus in t his paper is on data-falsification at tacks [11]–[18]. Thus far , research on detection i n th e presence of Byzantine attacks has predominantly focused on addressing these attacks under the centralized March 1, 2022 DRAFT 3 model [13], [14], [18], [19]. A few attem pts h a ve been made to address the security threats in the di stributed or consensus b ased schemes in recent research [20]–[25]. Most of these existing works on coun tering Byzantine or data falsification att acks in distributed networks rely on a threshold for d etecting Byzantines. The main idea is t o exclude nodes from neighbors l ist whose state inform ation deviates s ignificantly from the mean value. In [22] and [25], two different defense schemes against data falsification attacks for dis tributed cons ensus-based detection were proposed. In [22], the scheme elimi nates th e state value wit h the largest deviation from the lo cal mean at each iteratio n step and, therefore, it can only deal wi th the situatio n in whi ch onl y one Byzantine node exists. It excludes one s tate value ev en if there is no Byzantine no de. In [25], the vuln erability o f distributed cons ensus-based spectrum sensi ng was analyzed and an out lier detection algorithm with an adaptive thresho ld was proposed. The authors i n [24] proposed a Byzantine mitigation technique based on adaptive lo cal thresholds. This s cheme mitigates the misbehavior of Byzantine no des and tolerates the occasional large de viation int roduced by ho nest users. It adaptiv ely reduces t he corresponding coefficients so that the Byzantines will e ventually be iso lated from the network. Excluding t he Byzantine n odes from the fusio n process may not be t he best strategy from the network designer’ s perspectiv e. As shown in our earlier work [18] in the cont ext of d istributed detection wi th one-bi t measurements under a centralized model, an intelli gent way to imp rove the performance of th e network is to u se t he info rmation of th e ident ified Byzantines to the network’ s benefit. More s pecifically , learning based t echniques have the potential to outperform the existing exclusion based techniques. In thi s paper , we pursue such a design phi losophy in the cont ext of raw data based fusion in decentralized networks. T o design methodologies for defending against Byzantine att acks, fundament al chal lenges that arise are two-fold. First, how do nodes recognize the presence of attackers? Second, after identification of an attacker or group of attacker s, how do nodes adapt their opera ting parameters? Due to the large n umber of nodes and complexity of the distributed network, we develop and analyze schemes that would update their own operatin g parameters autonom ously . Our approach further introd uces an adapt iv e fusion based detectio n algorith m wh ich suppo rts the learning of the att acker’ s behavior . Our scheme differs from all existing work on Byzantine m itigation based on exclusion strategies [21]–[25], where the onl y defense is to i dentify and exclude the attackers from t he consensus process. March 1, 2022 DRAFT 4 A. Main Contri butions In this paper , we focus on the susceptibilit y and prot ection of consensus based detection algorithms. Our main cont ributions are summarized as follows: • W e characterize th e effe ct of Byzantines on the steady-state performance of the con ventional consensus based detection algorithms. More specifically , we qu antify the minimum fraction of Byzantines needed to make the deflection coef ficient of the global stati stic equal to zero. • Using probability of detection and probabili ty of false alarm as measures of detection perfor - mance, we in vestigate the de gradation of transient detection performance of the con ventional consensus algori thms with Byzantin es. • W e propose a robust d istributed weighted average consensus alg orithm and obtain closed- form expressions for op timal weight s to m itigate the effect of data falsification attacks. • Finally , we propose a techniqu e based on the e xpectation-maximi zation algorithm and maximum likelihood estimati on t o learn t he operating parameters (or weights) of the nodes in the network to enable an adapt iv e design of t he local fusion or update rules. The rest of t he paper is organized as follows. In Sections II and III, we int roduce our syst em model and B yzantine attack model, respectively . I n Section IV, we study the security per formance of weigh ted av erage consensus based detection schemes. In Section V, we propose a protection mechanism to mit igate the ef fect of data falsification att acks on consensus based d etection schemes. Finally , Section VI concludes the paper . I I . S Y S T E M M O D E L First, we define t he network model us ed in this paper . A. Network Model W e mod el the network topo logy as an undi rected graph G = ( V , E ) , where V = { v 1 , · · · , v N } represents the set of nodes in the network with | V | = N . The set of comm unication links in the network correspond to the set of edges E , where ( v i , v j ) ∈ E , if and onl y if there is a communication lin k between v i and v j (so that, v i and v j can directly com municate with each other). The adjacency matrix A of t he graph is defined as a ij = 1 if ( v i , v j ) ∈ E , 0 otherwise. March 1, 2022 DRAFT 5 1 2 4 3 5 6 Figure 1. A distributed network with 6 nodes The neigh borhood of a node i is defined as N i = { v j ∈ V : ( v i , v j ) ∈ E } , ∀ i ∈ { 1 , 2 , · · · , N } . The degree of a node v i in a graph G , denoted by d i , is the number of edges in E whi ch include v i as an endpoint, i.e., d i = P N j =1 a ij . The degree matrix D is defined as a diagonal m atrix with diag ( d 1 , · · · , d N ) and the Laplacian matrix L is defined as l ij = d i if j = i, − a ij otherwise. or , in other words, L = D − A . For example, consid er a network wit h six n odes trying to reach consensus (see Figure 1). The Laplacian matrix L for this network is given by 1 − 1 0 0 0 0 − 1 3 − 1 − 1 0 0 0 − 1 2 − 1 0 0 0 − 1 − 1 4 − 1 − 1 0 0 0 − 1 1 0 0 0 0 − 1 0 1 . The consensus based distributed detection scheme usually contains th ree ph ases: sens ing, information fus ion, and d ecision making . In the sensing phase, each node acquires the sum mary statistic about the phenomenon of interest. In this paper , we adopt the energy detecti on m ethod so that the local summ ary s tatistic is t he receiv ed signal energy . Next, in the information fusion March 1, 2022 DRAFT 6 phase, each node comm unicates with its neighbors to update th eir state values (summary statistic) and continues wit h th e consensus iteration until the whole network con ver ges t o a steady state which is the glo bal test statis tic. Finally , i n the decisi on maki ng phase, no des make their own decisions about the presence of the phenomenon. Next, we describe each of these phases in more detai l. B. Sensing Phase W e consider an N -node network using t he energy detection s cheme [26]. For th e i th node, the sens ed signal x k i at ti me instant k is given by x k i = n k i , under H 0 h i s k + n k i under H 1 where h i is the channel gain, s k is the signal a t time instant k , n k i is A WGN, i.e., n k i ∼ N (0 , σ 2 i ) and independent across time. Each node i calculates a summary statist ic Y i over a detection interval of M sampl es, i.e., Y i = P M k =1 | x k i | 2 where M is det ermined by the ti me-bandwidth product. Since Y i is the sum of the square of M i.i.d. Gauss ian random variables, it can be shown that Y i σ 2 i follows a central chi -square dist ribution with M degrees of freedom ( χ 2 M ) und er H 0 , and, a non-central chi-sq uare distri bution with M degrees of freedom and parameter η i under H 1 , i.e., Y i σ 2 i ∼ χ 2 M , under H 0 χ 2 M ( η i ) under H 1 where η i = E s | h i | 2 /σ 2 i is the local SNR at the i th node and E s = P M k =1 | s k | 2 represents the sensed s ignal energy over M detection ins tants. Note that the local SNR is M times the average SNR at the ou tput of th e energy detector , which i s E s | h i | 2 M σ 2 i . C. Information Fusi on Phase Next, we gi ve a brief introduction to con ventional con sensus algo rithms [27]. Consensus is reached in two steps. March 1, 2022 DRAFT 7 Step 1: All nodes establish comm unication links with thei r neighbors, and b roadcast their information state x i (0) = Y i . Step 2: Each node u pdates it s local state information by a local fusion rule (weigh ted com- bination of it s own value and those recei ved from its neighbors). W e denote nod e i ’ s u pdated information at i teration k by x i ( k ) . No de i cont inues to broadcast informati on x i ( k ) and update its local information state until consensus is reached. This information state updating process can be written in a compact form as x i ( k + 1) = x i ( k ) + ǫ w i X j ∈N i ( x j ( k ) − x i ( k )) (1) where ǫ is the time step and w i is the w eight assigned to nod e i ’ s information. Usi ng the notation x ( k ) = [ x 1 ( k ) , · · · , x N ( k )] T , network dyn amics in t he matrix form can be represented as, x ( k + 1) = W x ( k ) where, W = I − ǫ diag (1 /w 1 , · · · , 1 /w N ) L is referred to as a Perron m atrix. The consensu s algorithm is nothin g but a local fusion or update rule that fuses t he nodes’ local information state wi th i nformation com ing from neighb or nodes and every no de asymp totically reaches the same in formation state for arbitrary i nitial values. D. Decision Makin g Phase The final i nformation s tate after reaching cons ensus for the above consensus algorithm will be the weigh ted av erage of the initi al states of all th e nodes [27] or x ∗ i = P N i =1 w i Y i / P N i =1 w i , ∀ i . A verage consensus can be seen as a special case of weig hted av erage consensus with w i = w , ∀ i . After the whole network reaches a consens us, each node m akes its o wn d ecision about the hypothesis usin g a predefined threshold λ 1 Decision = H 1 if x ∗ i > λ H 0 otherwise 1 In practice, parame ters such as threshold λ and consensus time step ǫ can be set of f-line. This study is beyond the scope of this work. March 1, 2022 DRAFT 8 where weights are giv en by [9] w i = η i /σ 2 i P N i =1 η i /σ 2 i . (2) Note that, after reaching consensus x ∗ i = Λ , ∀ i . Thu s, in rest the of the p aper , Λ is referred to as the final test statis tic. Next, we discus s Byzantine attacks on consensus based detection schemes and analyze the performance degradation of the weighted average consensu s based detection algorithm due to these att acks. I I I . A T T AC K S O N C O N S E N S U S BA S E D D E T E C T I O N A L G O R I T H M S When there are no adversaries in the network, we noted i n the last sectio n that consens us can be accompli shed to the weighted ave rage of arbit rary init ial values by having the nodes use the update s trategy x ( k + 1) = W x ( k ) with an appropriate weight m atrix W . Suppos e, howe ver , that instead of broadcasting the true sensing s tatistic Y i and applying t he update strategy (1), some nodes (referred to as Byzantines ) deviate from t he prescribed strategies. Accordingl y , Byzantines can attack in t wo ways: data falsification (nodes falsify their init ial data o r weight values) and consensus disrupt ion (nodes do no t follow update rule given by (1)). More specifically , Byzantine node i can d o the following Data falsification: x i (0) = Y i + ∆ i , or w i → ˜ w i Consensus disrup tion: x i ( k + 1) = x i ( k ) + ǫ w i X j ∈N i ( x j ( k ) − x i ( k )) + u i ( k ) , where (∆ i , ˜ w i ) and u i ( k ) are int roduced at t he ini tialization step and at the updat e step k , respectiv ely . The attack model considered above is extremely general, and allows Byzantine nod e i to update i ts value in a completely arbit rary manner (vi a appropriate choices of (∆ i , ˜ w i ) , and u i ( k ) , at each time s tep). An adversary performing consensus disru ption attack has th e objective to disrupt the consensus o peration. Howe ver , consensus disrupti on at tacks can be easily detected because of the nature o f the attack. The identification of consensus disruption attackers has been in vestigated in the past li terature (e.g., see [7], [28]) where control theoretic techniques were dev eloped to identify disruption attackers in a single consensus iteration. Knowing t he existence of such an id entification mechanism, a sm art adversary will aim to dis guise itself while degrading the detection performance. In contrast to d isruption attackers, data falsification attackers are mo re March 1, 2022 DRAFT 9 capable and can manage to dis guise themselves while degrading the detecti on performance of the network by falsifying their data. Suscepti bility and protection of cons ensus s trategies t o data falsification at tacks has recei ved scant att ention, and t his is the focus of our work. In t his paper , we assume t hat a n attacker performs only a data falsification attack by introducing (∆ i , ˜ w i ) during initializatio n. W e exploit the stati stical distribution of the ini tial values and devise t echniques to mitigate the influence of Byzantines on the di stributed detection system. A. Data F alsificatio n Attack In data falsification attacks, attacke rs try to manipulate the final test statisti c (i.e., Λ = ( P N i =1 w i Y i ) / ( P N i =1 w i ) ) i n a way that t he detection performance is degraded. W e cons ider a network wit h N nodes that uses Algorithm (1) for reaching consensus. Algorithm (1) can be interpreted as, weigh t w i , given to no de i ’ s data Y i in the final test stat istic, is assigned by n ode i itself. So by falsifying init ial values Y i or weights w i , the attackers can mani pulate the final test statistic. Detection performance will be degraded because Byzantine nodes can alw ays set a higher weight to their mani pulated i nformation. Thus, the final stat istic’ s value across t he whole network will be dominated by the Byzantine node’ s local statist ic that will lead to degraded detection performance. Next, we define a m athematical model for data falsification attackers. W e analyze th e degra- dation in detection performance o f th e network when Byzantines falsify their in itial values Y i for fixed arbitrary weights ˜ w i . B. Attack Model The objecti ve of Byzantines is to degrade the detection performance of the network by falsifying their data ( Y i , w i ) . By assuming that Byzantines are intelligent and know the true hypothesis, we analyze the worst case detection performance of the data fusion schemes. W e consider the case when weights of the Byzantines have already been tampered to ˜ w i and analyze the effect of falsifying the initial values Y i . Thi s analys is provides the most fav o rable case from t he point of view of Byzantines and yields the m aximum performance degradation that the Byzantines can cause. N ow a mathematical model for a Byzantine attack i s presented. Byzantines tamper wi th t heir initial values Y i and send ˜ Y i such that the detection performance is degraded. March 1, 2022 DRAFT 10 Under H 0 : ˜ Y i = Y i + ∆ i with probabil ity P i Y i with probabil ity (1 − P i ) Under H 1 : ˜ Y i = Y i − ∆ i with probabil ity P i Y i with probabil ity (1 − P i ) where P i is the attack probability and ∆ i is a constant value which represents the attack strength, which is zero for honest nodes. As we show later , Byzantine nodes will use a large va lue of ∆ i so that the final st atistic’ s v alue is domi nated by the Byzantine node’ s local statistic that will lead to a degraded detection performance. W e u se deflection coefficient [29] to characterize the security performance of t he detection s cheme due to its simpl icity and its strong relati onship with the gl obal d etection performance. Deflection coefficient of the global test st atistic is defined as: D (Λ) = ( µ 1 − µ 0 ) 2 σ 2 (0) , where µ k = E [Λ | H k ] is th e condi tional m ean and σ 2 ( k ) = E [(Λ − µ k ) 2 | H k ] is the conditional variance. The deflection coeffic ient i s also closely related to other performance measures, e.g., the Recei ver Operating Characteristics (R OC) curve. In general, the detection performance monotonically in creases wit h an increasing value of th e deflection coefficient. W e define the critical point of the distrib uted detection netw ork as the minimum fra ction of Byzantine nodes needed to make the d eflection coefficient of gl obal test stati stic equal to zero (in which case, we say that t he network becomes bli nd ) and denote it by α blind . W e ass ume that t he communication between nodes is error -free and our network topology is fixed during the whol e consensus process and, th erefore, consensus can be reached wit hout disruptio n. In the next section, we analy ze the securit y performance of consensus b ased detection schem es in the presence of data falsifying Byzantines. I V . P E R F O R M A N C E A N A LY S I S O F C O N S E N S U S BA S E D D E T E C T I O N A L G O R I T H M S In this section, we analyze the effect of data falsification att acks o n con ventional consensus based detectio n algorithm s. First, in Section IV -A, we characterize the effect of Byzantines on the steady-state performance of the consensus based detecti on algorithm s and determine α blind . Next, in Section IV -B , usi ng probability of detection and probability o f false alarm as m easures of detectio n performance, we March 1, 2022 DRAFT 11 µ 0 = N 1 X i =1 P i ˜ w i sum ( w ) ( M σ 2 i + ∆ i ) + (1 − P i ) ˜ w i sum ( w ) ( M σ 2 i ) + N X i = N 1 +1 w i sum ( w ) ( M σ 2 i ) (3) µ 1 = N 1 X i =1 P i ˜ w i sum ( w ) (( M + η i ) σ 2 i − ∆ i ) + (1 − P i ) ˜ w i sum ( w ) (( M + η i ) σ 2 i ) + N X i = N 1 +1 w i sum ( w ) (( M + η i ) σ 2 i ) (4) σ 2 (0) = N 1 X i =1 ˜ w i sum ( w ) 2 P i (1 − P i )∆ 2 i + 2 M σ 4 i + N X i = N 1 +1 w i sum ( w ) 2 2 M σ 4 i (5) in vestigate the degradation of transient detection performance of th e consensus algorithm s wit h Byzantines. A. Steady-State P erforman ce Analysis with Byzanti nes W ith out loss of generality , we assume that the nodes correspondi ng to the first N 1 indices i = 1 , · · · , N 1 are Byzantines and the rest correspon ding t o indices i = N 1 + 1 , · · · , N are honest nodes. Let us define w = [ ˜ w 1 , · · · , ˜ w N 1 , w N 1 +1 · · · , w N ] T and sum ( w ) = P N 1 i =1 ˜ w i + P N i = N 1 +1 w i . Lemma 1 . F or data fusion schemes, the con dition t o blind the n etwork or to make the d eflection coefficient zer o is given b y N 1 X i =1 ˜ w i (2 P i ∆ i − η i σ 2 i ) = N X i = N 1 +1 w i η i σ 2 i . Pr oo f: The local test st atistic Y i has th e mean mean i = M σ 2 i if H 0 ( M + η i ) σ 2 i if H 1 and th e var iance March 1, 2022 DRAFT 12 0 0.25 0.5 0.75 1 0 5 10 15 0 1 2 3 4 5 6 Attack Strength ’D’ Attack Probability ’P’ Deflection Coefficient 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 5.5 Figure 2. Deflection Coef ficient as a function of attack parameters P and D . V ar i = 2 M σ 4 i if H 0 2( M + 2 η i ) σ 4 i if H 1 . The goal of Byzantine nodes is to m ake the deflection coefficient as small as possible. Since t he Deflection Coeffi cient is always non-negative ; the Byzantines seek to make D (Λ) = ( µ 1 − µ 0 ) 2 σ 2 (0) = 0 . The conditional mean µ k = E [Λ | H k ] and conditional variance σ 2 (0) = E [(Λ − µ 0 ) 2 | H 0 ] of the gl obal t est stati stic, Λ = ( P N 1 i =1 ˜ w i ˜ Y i + P N i = N 1 +1 w i Y i ) / ( sum ( w )) , can be com- puted and are given by (3) , (4) and (5), respectiv ely . After su bstitutin g values from (3), (4) and (5), the conditi on to make D ( Λ ) = 0 becomes N 1 X i =1 ˜ w i (2 P i ∆ i − η i σ 2 i ) = N X i = N 1 +1 w i η i σ 2 i Note that, wh en w i = ˜ w i = z , η i = η , σ i = σ , P i = P , ∆ i = D , ∀ i , the blinding condition simplifies to N 1 N = 1 2 η σ 2 P D . This condition indicates that by appropriately choosing attack parameters ( P , D ) , an adversary needs less than 50% of sensing data falsifying Byzantines to make th e deflection coefficient zero. Next, to gain insight s int o the sol ution, we present some n umerical results in Figure 2. W e plot the deflection coefficient of global test statistic as a functio n o f attack parameters P i = P , ∆ i = D , ∀ i . W e consider a 6 -nod e network with the t opology given by the undirected graph March 1, 2022 DRAFT 13 shown in Figure 1 to detect a phenomenon. Nodes 1 and 2 are considered to be Byzantines. Channel gains of the nodes are assumed to be h = [0 . 8 , 0 . 7 , 0 . 72 , 0 . 61 , 0 . 69 , 0 . 9] and weights are given b y (2). W e also assume that M = 12 , E s = 5 and σ 2 i = 1 . Notice that, t he deflection coef ficient i s zero when the conditio n in Lemm a 1 is satisfied. Another o bserva tion to make is that the deflection coef ficient can be made zero e ven when on ly two out of six nodes are Byzantines. Thus, by appropriately choo sing attack parameters ( P , D ) , less th an 50% of data falsifying Byzantines are needed to blind the n etwork. B. T ransient P erfo rmance Analysis with Byza ntines Next, we analyze the detection performance of the d ata fusion schemes, denoted as x ( t + 1) = W t x (0) , as a function of consensus it eration t in the presence of Byzantines. For analytical tractability , we assu me th at P i = P , ∀ i . W e denote by w t j i the element of matrix W t in the j th row and i th column . Using th ese notations , we calculate th e probability o f detection and the probability of false alarm at the j th no de at consensus i teration t . For suf ficiently lar ge M , the distribution of Byzantine’ s data ˜ Y i giv en H k is a Gaussian mi xture which comes from N (( µ 1 k ) i , ( σ 1 k ) 2 i ) wit h prob ability (1 − P ) and from N (( µ 2 k ) i , ( σ 2 k ) 2 i ) wit h probability P , wh ere N denotes the no rmal distribution and ( µ 10 ) i = M σ 2 i , ( µ 20 ) i = M σ 2 i + ∆ i ( µ 11 ) i = ( M + η i ) σ 2 i , ( µ 21 ) i = ( M + η i ) σ 2 i − ∆ i ( σ 10 ) 2 i = ( σ 20 ) 2 i = 2 M σ 4 i , and ( σ 11 ) 2 i = ( σ 21 ) 2 i = 2( M + η i ) σ 4 i . Now , the p robability densi ty function (PDF) of x t j i = w t j i ˜ Y i conditioned on H k can b e derive d as f ( x t j i | H k ) = (1 − P ) φ ( w t j i ( µ 1 k ) i , ( w t j i ( σ 1 k ) i ) 2 ) + P φ ( w t j i ( µ 2 k ) i , ( w t j i ( σ 2 k ) i ) 2 ) (6) where φ ( x | µ, σ 2 ) (for notatio nal con venience denoted as φ ( µ , σ 2 ) ) is th e PDF of X ∼ N ( µ, σ 2 ) and φ ( x | µ, σ 2 ) = 1 σ √ 2 π e − ( x − µ ) 2 / 2 σ 2 . Ne xt, for clarity of exposition, we first deriv e ou r results for a sm all network w ith two Byzantine nodes and one ho nest node. Later we generalize our March 1, 2022 DRAFT 14 results for an arbit rary number of nodes, N . Notice that, for the three node case, the transi ent test statisti c ˜ Λ t j = w t j 1 ˜ Y 1 + w t j 2 ˜ Y 2 + w t j 3 Y 3 , is a summation of independent random variables. The condi tional PDF of X t j i = w t j i ˜ Y i is given in (6). Notice that, PDF of ˜ Λ t j is the con v olution ( ∗ ) of f ( x t j 1 ) = (1 − P ) φ ( µ 1 1 , ( σ 1 1 ) 2 ) + P φ ( µ 2 1 , ( σ 2 1 ) 2 ) , f ( x t j 2 ) = (1 − P ) φ ( µ 1 2 , ( σ 1 2 ) 2 ) + P φ ( µ 2 2 , ( σ 2 2 ) 2 )) and f ( x t j 3 ) = φ ( µ 1 3 , ( σ 1 3 ) 2 ) . f ( z t j ) = f ( x t j 1 ) ∗ f ( x t j 2 ) ∗ f ( x t j 3 ) f ( z t j ) = [(1 − P ) φ ( µ 1 1 , ( σ 1 1 ) 2 ) + P φ ( µ 2 1 , ( σ 2 1 ) 2 )] ∗ [(1 − P ) φ ( µ 1 2 , ( σ 1 2 ) 2 ) + P φ ( µ 2 2 , ( σ 2 2 ) 2 )] ∗ φ ( µ 1 3 , ( σ 1 3 ) 2 ) = (1 − P ) 2 [ φ ( µ 1 1 , ( σ 1 1 ) 2 ) ∗ φ ( µ 1 2 , ( σ 1 2 ) 2 ) ∗ φ ( µ 1 3 , ( σ 1 3 ) 2 )] +( P ) 2 [ φ ( µ 2 1 , ( σ 2 1 ) 2 ) ∗ φ ( µ 2 2 , ( σ 2 2 ) 2 )) ∗ φ ( µ 1 3 , ( σ 1 3 ) 2 )] + P (1 − P )[ φ ( µ 2 1 , ( σ 2 1 ) 2 ) ∗ φ ( µ 1 2 , ( σ 1 2 ) 2 ) ∗ φ ( µ 1 3 , ( σ 1 3 ) 2 )] +(1 − P ) P [ φ ( µ 1 1 , ( σ 1 1 ) 2 ) ∗ φ ( µ 2 2 , ( σ 2 2 ) 2 ) ∗ φ ( µ 1 3 , ( σ 1 3 ) 2 )] Now , u sing the fact that con volution of two normal PDFs φ ( µ i , σ 2 i ) and φ ( µ j , σ 2 j ) is again normally dist ributed with mean ( µ i + µ j ) and variance ( σ 2 i + σ 2 j ) , we can deriv e t he results below . f ( z t j ) = (1 − P ) 2 [ φ ( µ 1 1 + µ 1 2 + µ 1 3 , ( σ 1 1 ) 2 + ( σ 1 2 ) 2 + ( σ 1 3 ) 2 )] + P 2 [ φ ( µ 2 1 + µ 2 2 + µ 1 3 , ( σ 2 1 ) 2 + ( σ 2 2 ) 2 + ( σ 1 3 ) 2 )] + P (1 − P )[ φ ( µ 2 1 + µ 1 2 + µ 1 3 , ( σ 2 1 ) 2 + ( σ 1 2 ) 2 + ( σ 1 3 ) 2 )] +(1 − P ) P [ φ ( µ 1 1 + µ 2 2 + µ 1 3 , ( σ 1 1 ) 2 + ( σ 2 2 ) 2 + ( σ 1 3 ) 2 )] . Due to the probabi listic nature of the Byzantine’ s beha vior , it may beha ve as an honest node with a probabilit y (1 − P i ) . Let S denote the set of all com binations of s uch Byzantine strategies: S = {{ b 1 , b 2 } , { h 1 , b 2 } , { b 1 , h 2 } , { h 1 , h 2 }} (7) March 1, 2022 DRAFT 15 where by b i we m ean t hat Byzantine node i behaves as a Byzantine and by h i we m ean t hat Byzantine nod e i behaves as an ho nest node. Let A s ∈ U denote the indices o f honest nod es in the st rategy combinati on s , then, from (7) we h a ve U = { A 1 = {} , A 2 = { 1 } , A 3 = { 2 } , A 4 = { 1 , 2 }} U c = { A c 1 = { 1 , 2 } , A c 2 = { 2 } , A c 3 = { 1 } , A c 4 = {}} where {} i s used to denote the null set and m s to denote t he cardinality of subset A s ∈ U . Using these no tations, we g eneralize our results for any arbitrary N . Lemma 2. The test stati stic of node j at consensus iteration t , i.e., ˜ Λ t j = P N 1 i =1 w t j i ˜ Y i + P N i = N 1 +1 w t j i Y i is a Gaussian mixtu r e with PDF f ( ˜ Λ t j | H k ) = X A s ∈ U P N 1 − m s (1 − P ) m s φ ( µ k ) A s + N X i = N 1 +1 w t j i ( µ 1 k ) i , N X i =1 ( w t j i ( σ 1 k ) i ) 2 ) ! with ( µ k ) A s = P u ∈ A s w t j u ( µ 1 k ) j + P u ∈ A c s w t j u ( µ 2 k ) j . The performance of the detection s cheme in the presence of Byzantines can be represented in terms of the probabilit y of detection and the probabili ty o f false alarm of the network. Pr oposition 1. The pr obability of detection and the probability of fals e alarm of node j at consensus it eration t in the pr esence of Byza ntines can b e r epr esented as P t d ( j ) = X A s ∈ U P N 1 − m s (1 − P ) m s Q λ − ( µ 1 ) A s − P N i = N 1 +1 w t j i ( µ 11 ) i q P N i =1 ( w t j i ( σ 11 ) i ) 2 ) , P t f ( j ) = X A s ∈ U P N 1 − m s (1 − P ) m s Q λ − ( µ 0 ) A s − P N i = N 1 +1 w t j i ( µ 10 ) i q P N i =1 ( w t j i ( σ 10 ) i ) 2 ) . Remark 1. Notice tha t, t he ex pr essions o f pr obability of detection P t d ( j ) and pr obabilit y of fa lse alarm P t f ( j ) for the N 1 Byzantine nod e case in volves 2 N 1 combinations (car dinality of U is 2 N 1 ). It, ho wev er , can be r epr esented compactly by vectorizing the expr essions, i.e., P t d ( j ) = 1 T b ⊗ Q λ 1 - µ 1 q P N i =1 ( w i ( σ 10 ) i ) 2 ) March 1, 2022 DRAFT 16 with µ 1 = [ A w t j µ 11 + A c w t j µ 21 − N P i = N 1 +1 w t j i ( µ 11 ) i ] , B = ( 1 − P ) A + P A c and b = [ B 1 ⊗ · · · ⊗ B N 1 ] , wher e boldface lett ers r epr esent vectors, ⊗ symbol repr esents element -wise multi plication, Q ( · ) r epr esents element wise Q functio n operation, i.e., Q ( x 1 , · · · , x N 1 ) = [ Q ( x 1 ) , · · · , Q ( x N 1 )] T , B i is i th column of matri x B , w t j µ u 1 = [ w t j 1 µ 1 u 1 , · · · , w t j N 1 µ N 1 u 1 ] T , matrix A (2 N 1 ∗ N 1 ) is t he binary r epre sentation of decimal numbers f r om 0 to N 1 − 1 and A c is the ma trix after int er changing 1 and 0 in matr ix A . Similarly , the expr ession for the pr obability of false alarm P t f ( j ) can be vectori zed into a compact form. Next, to gain i nsights in to the results given i n Proposit ion 1, we present some numerical results in Figures 3 and 4. W e consi der the 6 -node network sh own i n Figure 1 where t he nodes employ the consensus algorithm 1 with ǫ = 0 . 689 7 to detect a phenomenon. Nodes 1 and 2 are considered to be Byzantines. W e als o assume th at η i = 10 , σ 2 i = 2 , λ = 3 3 and w i = 1 . Attack parameters are assumed to be ( P i , ∆ i ) = (0 . 5 , 6) and ˜ w i = 1 . 1 . T o characterize the transient performance of t he weighted average consensus algorith m, i n Figure 3(a), we plot the probability of detectio n as a functi on of the n umber o f consensus it erations w hen Byzantines are not falsifying their d ata, i.e., (∆ i = 0 , ˜ w i = w i ) . Next, in Figure 3(b), we plo t the probability of detection as a functio n of the number of consensus i terations in the presence of Byzantines. It can be seen that t he detection performance degrades in the presence of Byzantines. In Figure 4(a), we plo t th e probability of false alarm as a fun ction of the number of consensus it erations when Byzantines are no t falsifying thei r data, i.e., (∆ i = 0 , ˜ w i = w i ) . Next, i n Figure 4(b), we plot the probabilit y of false alarm as a function of the numb er o f consensus iterations in the presence of Byzantines. From both Figures 3 and 4, it can be seen that the Byzantine attack can sev erely degrade transient detectio n performance. From the dis cussion in thi s sectio n, we can see that Byzantines can seve rely degrade both the steady-state and the transi ent detection performance of con ventional consensus based detectio n algorithms. As ment ioned earlier , a data falsifying Byzantine i can tamper its weig ht w i as well as it s sensing data Y i to degrade detection performance. One approach to mi tigate the effect of sensing data falsification is t o assign weight s based on the quality o f the data. In other words, lower weight is assigned to the data of the node id entified as a Byzantine. Howe ver , to impl ement this approach one has to address the following two is sues. March 1, 2022 DRAFT 17 5 10 15 20 25 0.84 0.86 0.88 0.9 0.92 0.94 0.96 0.98 Iteration Steps Probability of Detection Node1 Node 2 Node 3 Node 4 Node 5 (a) 5 10 15 20 25 0.75 0.8 0.85 0.9 0.95 1 Iteration Steps Probability of Detection Node1 Node 2 Node 3 Node 4 Node 5 (b) Figure 3. (a) P robability of detection as a function of consensus i teration steps. (b) Probability of detection as a function of consensus iteration steps with Byzantines. 5 10 15 20 25 0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 Iteration Steps probability of False Alarm Node 1 Node 2 Node 3 Node 4 Node 5 (a) 5 10 15 20 25 0 0.05 0.1 0.15 0.2 0.25 Iteration Steps Probability of False Alarm Node 1 Node 2 Node 3 Node 4 Node 5 (b) Figure 4. (a) P robability of false alarm as a function of consensu s iteration steps. (b) Probability of false alarm as a function of consen sus iteration steps with Byzantine s. First, i n th e con ventional weighted av erage consensus algorithm, weight w i giv en to nod e i ’ s data is assi gned by the node itself. Thu s, a Byzantine node can always set a higher weight to its manipulated i nformation and the final stat istics wil l be dominated b y the Byzantine nodes’ lo cal statistic that will lead to degraded detection performance. It will be impo ssible for any algorit hm to detect th is type of m alicious behavior , sin ce any weig ht that a Byzantin e chooses for itself is a legitimate value t hat could also hav e b een chosen by a node t hat is functionin g correctly . Thus, the con ventional consensus algorithm cannot be used in t he presence of an attacker . Second, as will be seen later , the optimal weights assigned to nodes’ sensing data depend on the foll owing unknown parameters: i dentity of the nodes (i.e., honest or Byzantine) and underlying st atistical distribution of the nodes’ data. In the next section, we address these concerns by proposing a learning based robust wei ghted March 1, 2022 DRAFT 18 a verage consensus algo rithm. V . A R O B U S T C O N S E N S U S B A S E D D E T E C T I O N A L G O R I T H M In order to address the first issue, we propose a cons ensus algorith m in which the weig ht for node i ’ s information is ass igned (or u pdated) by neighbo rs of th e node i rather than by node i itself. N ote that, networks depl oying such an alg orithm is more robust to w eight m anipulation because if a Byzantine node j wants to l ower the w eight assigned to t he data o f its hon est neighbor i in the global t est stati stic, it has to m ake s ure that a majo rity of t he neighbors of i put the sam e l ower weight as j . In other words, e very ho nest no de shou ld have majority o f its neighbors that are Byzantines, otherwise, it can be treated as a consens us disrupti on attack and Byzantines can be easily identified d etected by techniques such as those given in [7], [28]. A. Distributed Algor ithm for W eighted A vera ge Consensus In this section, we address t he fol lowing questions: does there exist a d istributed algo rithm that solves the weighted av erage consens us p roblem while satisfying the conditi on t hat weigh ts must be ass igned or updated by neighbors N i of the n ode i rather than by th e node i it self? If it exists, then, under what condition s or constraints do es the algorithm con ver ge? W e cons ider a network with N nodes with a fixed and connected topology G ( V , E ) . Next, we state Perron-Frobenius th eorem [30], which will be used later for t he design and analysis of our robust weighted a verage consensus alg orithm. Theor em 1 ( [30]) . Let W be a primi tive nonne gative matrix with left and right eigen vectors u and v , r espectively , sati sfying W v = v and u T W = u T . Then, lim k →∞ W k = vu T v T u . Using th e above theorem, we take a reve rse-engineering approach to design a modi fied Perron matrix ˆ W whi ch has the weig ht vector w = [ w 1 , w 2 , · · · , w N ] T , w i > 0 , ∀ i as its left eigen vector and ~ 1 as i ts right eigen vector correspond ing to eigenv alue 1 . From the above theorem, if the modified Perron m atrix ˆ W i s primitive and no nnegati ve, then, a weighted av erage consensus can be achie ved. Now , the problem bo ils do wn t o designing such a ˆ W which meets our requirement that weights are assi gned or updated by the neighbors N i of node i rather than b y node i it self. March 1, 2022 DRAFT 19 Next, we propose a m odified Perron matrix ˆ W = I − ǫ ( T ⊗ L ) where L is the original graph Laplacian, ⊗ is el ement-wise matrix multiplicati on operator , and T is a transformation giv en by [ T ] ij = P j ∈N i w j l ii if i = j w j otherwise . Observe that, the above transformation T satisfies the condition that weights are assigned or updated by neighbo rs N i of node i rather than by nod e i itself. Based on the above transform ation T , we propose our distributed consensus algorithm : x i ( k + 1) = x i ( k ) + ǫ P j ∈N i w j ( x j ( k ) − x i ( k )) . Let us denote the modified Perron matri x by ˆ W = I − ǫ ˆ L . Next, we explore th e properties of the modified Perron m atrix ˆ W and s how that it sati sfies the requirements of the Perron-Frobenius theorem [30]. These properti es wi ll later be uti lized to prove th e con ver g ence of our proposed con sensus algorit hm. Lemma 3. Let G be a connected graph with N nodes. Then, the modified P err o n matrix ˆ W = I − ǫ ( T ⊗ L ) , with 0 < ǫ < 1 max i ( X j ∈N i w j ) satisfies the following pr operties. 1) ˆ W is a nonne gative matrix with left eigen vector w and ri ght eigen vector ~ 1 corresponding to eigen value 1 ; 2) All eigen val ues of ˆ W ar e in a unit circ le; 3) ˆ W is a pr imitive matri x 2 . Pr oo f: Notice that, ˆ W ~ 1 = ~ 1 − ǫ ( T ⊗ L ) ~ 1 = ~ 1 and w T ˆ W = w T − ǫw T ( T ⊗ L ) = w T . This implies t hat ˆ W has left eigen vector w and right eigen vector ~ 1 corresponding to eigen value 1 . T o show that ˆ W = I + ǫT ⊗ A − ǫT ⊗ D is non-negativ e, it is sufficient to show that: w > 0 , ǫ > 0 and ǫ (max i ( P j ∈N i w j )) ≤ 1 , ∀ i . Since w is t he left eig en vector of ˆ L and w > 0 , ˆ W is non-negative if and only if 0 < ǫ ≤ 1 max i ( P j ∈N i w j ) . 2 A matrix is primiti ve if it is non-negati ve and its m th po wer is positi ve for some natural number m . March 1, 2022 DRAFT 20 T o prove part 2) , notice that all the eigen vectors of ˆ W and ˆ L are the same. Let γ j be the j th eigen value of ˆ L , then, the j th eigen value of ˆ W is λ j = 1 − ǫγ j . Now , part 2) can be proved by applying Gershg orin theorem [30] to t he mod ified Laplacian m atrix ˆ L . T o prove part 3) , note that G is strongly connected and, therefore, ˆ W is an i rreducible matrix [30]. Thus, to prov e that ˆ W is a p rimitive matri x, it is sufficient 3 to show that ˆ W has a single eigen value with maxim um m odulus of 1 . In [27], the authors showed that when 0 < ǫ < max i ( X j 6 = i a ij ) , the original Perron matrix W has only one eigen value with maximum modulus 1 at its spectral radi us. Using a sim ilar logic, ˆ W is a prim itive matrix if 0 < ǫ < 1 max i ( X j ∈N i w j ) . Theor em 2. Consider a network with fixed and st r ong ly con nected undir ected topology G ( V , E ) that employs the d istributed consensus a lgorithm x i ( k + 1) = x i ( k ) + ǫ P j ∈N i w j ( x j ( k ) − x i ( k )) wher e 0 < ǫ < 1 max i ( X j ∈N i w j ) . Then, consensu s with x ∗ i = P N i =1 w i x i (0) P n i =1 w i , ∀ i i s r eached as ymptotically . Pr oo f: A consensus is reached asymptotically , if t he li mit lim k →∞ ˆ W k exists. According to Perron-Frobenius t heorem [30], t his li mit exists for primi tiv e matrices. Not e that, ~ 1 = [1 , · · · , 1] T and w are right and l eft eigen vectors of th e primi tiv e nonnegati ve matrix ˆ W respectiv ely . Thus, 3 An irreducible stochastic matrix i s primitiv e if it has only one eigen v alue with maximum modulus. March 1, 2022 DRAFT 21 5 10 15 20 25 30 1 2 3 4 5 6 7 8 9 Iteration Steps State Value Node 1 Node 2 Node 3 Node 4 Node 5 Node 6 Figure 5. Con vergence of the network wit h a 6-nodes ( ǫ = 0 . 3 ). from [30] lim k →∞ x ( k ) = lim k →∞ ( ˆ W ) k x (0) x ∗ = ~ 1 w T x (0) w T ~ 1 x ∗ = ~ 1 P N i =1 w i x i (0) P n i =1 w i Next, to gain insights into the con ver gence prop erty o f t he proposed algorithm, we present some numerical results in Figure 5. W e consider the 6 -n ode network shown in Figure 1 where the no des empl oy the proposed algo rithm (with ǫ = 0 . 3 ) to reach a consensus. Next, we plot the updated st ate values at each node as a function of con sensus it erations. W e assume th at t he init ial data v ector is x (0) = [5 , 2 , 7 , 9 , 8 , 1] T and the weight v ector is w = [0 . 65 , 0 . 55 , 0 . 4 8 , 0 . 95 , 0 . 93 , 0 . 90] T . Note that, the parameter ǫ satis fies t he conditi on mentio ned in Theorem 2. Figu re 5 shows the con vergence of the propo sed al gorithm iterations for a fixed com munication graph. It i s observed that within 2 0 i terations consensu s has been reached on the global decision st atistics or weight ed a verage of th e init ial values (states). In the proposed consens us algorithm, weig hts assigned to node i ’ s data are updated by neighbors of the node i rather than by nod e i itself which addresses th e first is sue. March 1, 2022 DRAFT 22 B. Adaptive Desi gn of th e Update Rules based on Learnin g of Nodes’ Behavior Next, to address the second issue, we exploit th e statis tical distri bution of t he sensi ng data and devise techniques to mitig ate the influence of Byzantines on the distri buted detectio n system. W e propose a three-tier m itigation s cheme where the following three steps are performed at each node: 1 ) i dentification of Byzantine neighbors, 2 ) estim ation of parameters of identified Byzan- tine neighbors, and 3 ) adaptation of consensus algorithm (or update weight s) u sing estimated parameters. W e first present the design of dis tributed optimal weights for the ho nest/Byzantine nodes assuming that the i dentities of the nodes are known. Later we will explain h ow the identit y of nodes (i.e., honest/Byzantine) can be determined. 1) Design of Distr ibuted Optimal W eights in the Pr esence of Byzanti nes: In this su bsection, we deriv e closed form expressions for the distributed opt imal weights whi ch maximize th e deflection coef ficient. First, we consider the global test statisti c Λ = P N 1 i =1 w B i ˜ Y i + P N i = N 1 +1 w H i Y i P N 1 i =1 w B i + P N i = N 1 +1 w H i and obtain a closed form solutio n for o ptimal centralized weights . T hen, we extend our anal- ysis to the distributed s cenario. Let us denote by δ B i , the centralized weight giv en to the Byzantine node and by δ H i , the cent ralized weight gi ven to the Honest node. By consi dering δ B i = w B i / N 1 P i =1 w B i + N P i = N 1 +1 w H i and δ H i = w H i / N 1 P i =1 w B i + N P i = N 1 +1 w H i , the optimal weight design problem can be stated form ally as: max { δ B i } N 1 i =1 , { δ H i } N i = N 1 +1 ( µ 1 − µ 0 ) 2 σ 2 (0) st. N 1 X i =1 δ B i + N X i = N 1 +1 δ H i = 1 where µ 1 , µ 0 and σ 2 (0) are g iv en as in (3), (4) and (5), respectively . T he sol ution of the above problem is presented i n the next l emma. March 1, 2022 DRAFT 23 0 0.2 0.4 0.6 0.8 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Probability of false alarm Probability of detection Proposed approach Equal gain combining Cuttoff combining Figure 6. R OC for dif ferent protection approaches Lemma 4. Op timal centralized weights which maximi ze the deflection coefficient ar e given as δ B i = w B i N 1 P i =1 w B i + N P i = N 1 +1 w H i , δ H i = w H i N 1 P i =1 w B i + N P i = N 1 +1 w H i wher e w B i = ( η i σ 2 i − 2 P i ∆ i ) ∆ 2 i P i (1 − P i ) + 2 M σ 4 i and w H i = η i 2 M σ 2 i . Pr oo f: The abov e results can be obt ained by equati ng the deri vati ve of the deflection coef ficient to zero. Remark 2. Dist ributed opt imal weights can be chosen as w B i and w H i . Thus, th e valu e of the global test s tatistic (or fi nal weight ed avera ge consens us) is the same as the optimal centralized weighted combi ning 4 . Next, to gain ins ights into the solutio n, we present som e numerical results in Figure 6 that corroborate o ur t heoretical results. W e assume that M = 12 , η i = 3 , σ 2 i = 0 . 5 and t he attack 4 Note that, weights w B i can be negati ve and in that case con ver gence of the proposed algorithm is not guaranteed . Howe v er , this situation can be dealt of f-line by adding a constant value to make w B i ≥ 0 and changing the threshold λ accord ingly . More specifically , by choosing a constant c such that w B i + c x i (0) ≥ 0 , ∀ i and λ ← λ + β c w here β is number of nodes wit h w B i < 0 . March 1, 2022 DRAFT 24 parameters are ( P i , ∆ i ) = (0 . 5 , 9) . In Figure 6, we compare our proposed weight ed a verage consensus based detection schem e with the equal gain combini ng scheme 5 and the scheme where Byzantines are cut off or removed from the fus ion process. It can b e clearly seen from th e figure that our prop osed s cheme performs better than th e rest of the schemes. Notice that, the optimal weights for the Byzanti nes are functions of the attack parameters ( P i , ∆ i ) , which may no t be known to the neighboring nodes in practice. In addition, the parameters o f th e hon est nodes mi ght also not be known. Thus, we propose a t echnique to learn or est imate these parameters. W e then use these estimates t o adaptively design the lo cal fusion rule which are updated after each learning it eration. 2) Identification, Est imation, and Adaptive F usion Rule: The first step at each n ode m is to determine the identity ( I i ∈ { H , B } ) of its n eighboring nod es i ∈ N m . Not ice that, if nod e i is an honest node, its data under hypothesis H k is normally distributed N (( µ 1 k ) i , ( σ 1 k ) 2 i ) . On the other hand, if node i is a Byzanti ne node, its data under hypothesi s H k is a Gauss ian mixture which comes from N (( µ 1 k ) i , ( σ 1 k ) 2 i ) with probability ( α i 1 = 1 − P i ) and from N (( µ 2 k ) i , ( σ 2 k ) 2 i ) with probabili ty α i 2 = P i . Therefore, determi ning the identity ( I i ∈ { H , B } ) of neighboring nodes i ∈ N m can be posed as a hy pothesis t esting probl em: I 0 ( I i = H ) : Y i is generated from a Gaussian d istribution un der each hypothesis H k ; I 1 ( I i = B ) : Y i is generated from a Gaussian m ixture dist ribution under each hypothesis H k . Node classification can t hen be achieved usi ng the maxi mum likelihood decision rule: f ( Y i | I 0 ) H ≷ B f ( Y i | I 1 ) (8) where f ( ·| I l ) i s the probability density fun ction (PDF) under each hypothesis I l . Howe ver , the parameters of the di stribution are not known. Next, we p ropose a technique to learn these parameters. For an honest node i , the parameters t o be est imated are (( µ 1 k ) i , ( σ 1 k ) 2 i ) and for Byzantines the unknown parameter set t o b e estimated is θ = { α i j , ( µ j k ) i , ( σ j k ) 2 i } , where k = { 0 , 1 } , j = { 1 , 2 } and i = 1 , · · · , N m , for N m neighbor nodes. These parameters are estimated by observing the data ov er m ultiple learning iterations. In each i teration t , ev ery node in the 5 In equal gain combinin g scheme, all the nodes (including Byzantines) are assigned t he same weight. March 1, 2022 DRAFT 25 ( ˆ σ 10 ) 2 i ( t + 1) = ( t P r =1 D 1 ( r ))[( ˆ σ 10 ) 2 i ( t ) + (( ˆ µ 10 ) i ( t + 1) − ( ˆ µ 10 ) i ( t )) 2 ] + D 1 ( t +1) P d =1 [ y 0 i ( d ) − ( ˆ µ 10 ) i ( t + 1)] 2 t +1 P r =1 D 1 ( r ) (9) ( ˆ σ 11 ) 2 i ( t + 1) = t P r =1 ( D − D 1 ( r ))[( ˆ σ 11 ) 2 i ( t ) + (( ˆ µ 11 ) i ( t + 1) − ( ˆ µ 11 ) i ( t )) 2 ] + D − D 1 ( t +1) P d =1 [ y 1 i ( d ) − ( ˆ µ 11 ) i ( t + 1 )] 2 t +1 P r =1 ( D − D 1 ( r )) (10) network o bserves the data comin g from t heir neighbors for D detectio n intervals to learn their respectiv e parameters. It is assumed t hat each nod e has t he kn owledge of the true hypothesis for D detection intervals (or history) throu gh a feedback mechanism. First, we explain how the unknown parameter set for the dist ribution under the null hypothesis ( I 0 ) can be estim ated. Let us denote the data coming from an hon est nei ghbor n ode i as Y i ( t ) = [ y 0 i (1) , · · · , y 0 i ( D 1 ( t )) , y 1 i ( D 1 ( t ) + 1) , · · · , y 1 i ( D )] where D 1 ( t ) denotes th e number of t imes H 0 occurred in l earning iteration t and y k i denotes th e data of node i when the true hypot hesis was H k . T o esti mate the parameter set, (( µ 1 k ) i , ( σ 1 k ) 2 i ) , of an honest neighb oring node, one can employ a maximum likelihood based estimator (MLE). W e use (( ˆ µ 1 k ) i ( t ) , ( ˆ σ 1 k ) 2 i ( t )) to denote the estimates at learning iteration t , where each learning iteration consist s of D detection intervals. The ML estimate of (( µ 1 k ) i , ( σ 1 k ) 2 i ) can be wri tten in a recursive form as following: ( ˆ µ 10 ) i ( t + 1) = t P r =1 D 1 ( r ) t +1 P r =1 D 1 ( r ) ( ˆ µ 10 ) i ( t ) + 1 t +1 P r =1 D 1 ( r ) D 1 ( t +1) X d =1 y 0 i ( d ) (11) ( ˆ µ 11 ) i ( t + 1) = t P r =1 ( D − D 1 ( r )) t +1 P r =1 ( D − D 1 ( r )) ( ˆ µ 11 ) i ( t ) + 1 t +1 P r =1 ( D − D 1 ( r )) D X d = D 1 ( t +1) y 1 i ( d ) (12) where expressions for ( ˆ σ 10 ) 2 i and ( ˆ σ 11 ) 2 i are given in (9) and (10). Observe that, by writi ng these expressions in a recursi ve manner , we need to store only D data samples at any giv en learning iteration t , but effec tive ly use all tD data samples t o determine t he estim ates. March 1, 2022 DRAFT 26 Next, we explain how the unknown parameter set for the d istribution un der the alt ernate hy- pothesis ( I 1 ) can be esti mated. Since the data is d istributed as a Gaussian mi xture, we employ the expectation-maximization (EM) alg orithm to estim ate the unknown parameter set for Byzantines. Let us denote the data com ing from a B yzantine neighbor i as ˜ Y i ( t ) = [ ˜ y 0 i (1) , · · · , ˜ y 0 i ( D 1 ( t )) , ˜ y 1 i ( D 1 ( t )+ 1) , · · · , ˜ y 1 i ( D )] where D 1 ( t ) denot es the numb er of times H 0 occurred in learning i teration t and ˜ y k i denotes th e data of node i when the true hypothesi s was H k . Let us denot e th e hidden var iable as z j with j = { 1 , 2 } or ( Z = [ z 1 , z 2 ] ). Now , the joi nt conditi onal PDF of ˜ y k i and z j , give n the parameter set, can b e calculated to be P ( ˜ y k i ( d ) , z j | θ ) = P ( z j | ˜ y k i ( d ) , θ ) P ( ˜ y k i ( d ) | ( µ j k ) i , ( σ j k ) 2 i ) = α i j P ( ˜ y k i ( d ) | ( µ j k ) i , ( σ j k ) 2 i ) In th e expectation step of EM , we com pute the expectation of the log-likelihood fun ction with respect to th e hidden variables z j , give n the measurements ˜ Y i , and the current est imate of the parameter set θ l . Thi s is given by Q ( θ , θ l ) = E [log P ( ˜ Y i , Z | θ ) | ˜ Y i , θ l ] = 2 X j =1 D 1 ( t ) X d =1 log[ α i j P ( ˜ y 0 i ( d ) | ( µ j 0 ) i , ( σ j 0 ) 2 i ) P ( z j | ˜ y 0 i ( d ) , θ l )] + 2 X j =1 D X d = D 1 ( t )+1 log[ α i j P ( ˜ y 1 i ( d ) | ( µ j 1 ) i , ( σ j 1 ) 2 i ) P ( z j | ˜ y 1 i ( d ) , θ l )] where P ( z j | ˜ y k i ( d ) , θ l ) = α i j ( l ) P ( ˜ y k i ( d ) | ( µ j k ) i ( l ) , ( σ j k ) 2 i ( l ) ) 2 P n =1 α i n ( l ) P ( ˜ y k i ( d ) | ( µ nk ) i ( l ) , ( σ nk ) 2 i ( l ) ) . (13) In the maximizati on step of EM algorithm , we maximize Q ( θ , θ l ) w ith respect to the parameter set θ so as to compute th e next parameter set: θ l +1 = arg max θ Q ( θ , θ l ) . March 1, 2022 DRAFT 27 First, we maxi mize Q ( θ , θ l ) subj ect to the constraint 2 P j =1 α i j = 1 ! . W e define the Lagrangian L as L = Q ( θ , θ l ) + λ { 2 X j =1 α i j − 1 } . Now , we equ ate the deriva tive of L to zero: d dα i j L = λ + D 1 ( t ) P d =1 P ( z j | ˜ y 0 i ( d ) , θ l ) α i j + D P d = D 1 ( t )+1 P ( z j | ˜ y 1 i ( d ) , θ l ) α i j = 0 . Multiply ing both sides by α i j and s umming over j giv es λ = − D . Simil arly , we equate the deriv ative of Q ( θ , θ l ) with respect to ( µ j k ) i and ( σ k ) 2 i to zero. Now , an iterativ e algorithm for all the parameters is α i j ( l + 1) = 1 D D 1 ( t ) X d =1 P ( z j | ˜ y 0 i ( d ) , θ l ) + D X d = D 1 ( t )+1 P ( z j | ˜ y 1 i ( d ) , θ l ) (14) ( µ j 0 ) i ( l + 1) = D 1 ( t ) P d =1 P ( z j | ˜ y 0 i ( d ) , θ l ) ˜ y 0 i ( d ) D 1 ( t ) P d =1 P ( z j | ˜ y 0 i ( d ) , θ l ) (15) ( µ j 1 ) i ( l + 1) = D P d = D 1 ( t )+1 P ( z j | ˜ y 1 i ( d ) , θ l ) ˜ y 1 i ( d ) D P d = D 1 ( t )+1 P ( z j | ˜ y 1 i ( d ) , θ l ) (16) ( σ j 0 ) 2 i ( l + 1) = 2 P j =1 D 1 ( t ) P d =1 P ( z j | ˜ y 0 i ( d ) , θ l )( ˜ y 0 i ( d ) − ( µ j 0 ) i ( l + 1)) 2 2 P j =1 D 1 ( t ) P d =1 P ( z j | ˜ y 0 i ( d ) , θ l ) (17) ( σ j 1 ) 2 i ( l + 1) = 2 P j =1 D P d = D 1 ( t )+1 P ( z j | ˜ y 1 i ( d ) , θ l )( ˜ y 1 i ( d ) − ( µ j 1 ) i ( l + 1)) 2 2 P j =1 D P d = D 1 ( t )+1 P ( z j | ˜ y 1 i ( d ) , θ l ) (18) In the learning iteration t , let th e estimates after the con vergence of the above algorithm be denoted by ˆ θ ( t ) = { ˆ α i j ( t ) , ( ˆ µ j k ) i ( t ) , ( ˆ σ j k ) 2 i ( t ) } . These estimates are then used as the initial values March 1, 2022 DRAFT 28 0 0.2 0.4 0.6 0.8 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 P f P d Learning Iteration 1 Learning Iteration 2 Learning Iteration 3 Learning Iteration 4 Optimal weights Figure 7. R OC for dif ferent learning it erations for the next learning it eration t + 1 that uses a new set of D data samples. After learning the unknown parameter s et under I 0 and I 1 , node classification can be achiev ed using th e following maxim um likelihood decision rule: ˆ f ( Y i | I 0 ) H ≷ B ˆ f ( Y i | I 1 ) (19) where ˆ f ( · ) is the PDF based on estim ated parameters. Using the above estimates and n ode classification, th e opti mal d istributed weights for honest nodes after learning it eration t can be written as w H i ( t ) = ( ˆ µ 11 ) i ( t ) − ( ˆ µ 10 ) i ( t ) ( ˆ σ 10 ) 2 i ( t ) . (20) Similarly , the optimal di stributed weights for Byzantines after l earning it eration t can b e written as w B i ( t ) = 2 P j =1 ˆ α i j ( t )[( µ j 1 ) i ( t ) − ( ˆ µ j 0 ) i ( t )] ˆ α i 1 ( t ) ˆ α i 2 ( t ) (( ˆ µ 10 ( t )) i − ( ˆ µ 20 ( t )) i ) 2 + ˆ α i 1 ( t ) ( ˆ σ 10 ) 2 i ( t ) + ˆ α i 2 ( t ) ( ˆ σ 20 ) 2 i ( t ) (21) Next, we present some numerical results in Figu re 7 to ev aluate the performance o f our proposed scheme. Consi der the scenario where 6 nodes organized in an undirected g raph (as shown in Figu re 1) are trying to detect a ph enomenon. Node 1 and node 2 are considered March 1, 2022 DRAFT 29 to be Byzantines. W e assume that (( µ 10 ) i , ( σ 10 ) 2 i ) = (3 , 1 . 5 ) , (( µ 11 ) i , ( σ 11 ) 2 i ) = (4 , 2) and the attack parameters are ( P i , ∆ i ) = (0 . 5 , 9 ) . In Figure 7, we plot R OC curves for different learning iterations. For eve ry learning iteration, w e assum e th at D 1 = 10 and D = 2 0 . It can be seen from Figure 7 that with in 4 l earning iterations, detection performance o f the learning based weig hted gain com bining scheme approaches the d etection performance o f weighted gain combinin g wit h known opt imal weight based scheme. Note that, the above learning based scheme can be used in conj unction with th e propo sed weighted aver age consens us based algorithm to m itigate the ef fect of Byzantines. V I . C O N C L U S I O N A N D F U T U R E W O R K In this paper , we analyzed the security performance of con vention al consensus based algo- rithms in the presence of data falsification attacks. W e showed that above a certain fraction of Byzantine attackers i n the network, existing consensus based detection algo rithm are inef fectiv e. Next, we proposed a robust di stributed weighted av erage consensus algorithm and devised a learning technique to estimate the operating parameters (or weights) of the nodes. This enables an adaptive design of the l ocal fusion or update rul es to mi tigate t he eff ect of data falsification attacks. There are still many i nteresting questions that remain to b e explored in the future work such as an analysis of the problem for time varying topologies. Note that, some analyt ical methodologi es used in this paper are certainl y exploitable for stu dying the attacks i n time varying topologies. Other questi ons such as the optim al topology w hich incurs the fastest conv er gence rate can also b e in vestigated. R E F E R E N C E S [1] P . K. V arshney , Distributed Detection and Data F usion . New Y ork:Springer-V erlag, 1997. [2] R. V iswanatha n and P . K. V arshney , “Distri buted detection with multiple sensors: Part I - Fundamentals, ” Proc. IEEE , vol. 85, no. 1, pp. 54 –63, Jan 1997. [3] V . V eerav alli and P . K. V arshney , “Distributed inference in wi reless sensor networks, ” Philosophical T ransaction s of t he Royal Society A: Mathematica l, Physical and Engineering Sciences , vol. 370, pp. 100–117, 2012. [4] G. Xiong and S. Kishore, “Consensus-based distrib uted detection algorithm in wireless ad hoc networks, ” i n Signal Pr ocessing and Communication Systems, 2009 . ICSPCS 2009. 3r d International Conferen ce on , Sept 2009, pp. 1–6. [5] S. Aldosari and J. Moura, “Distributed Detection in S ensor Networks: Connectiv ity Graph and S mall W orld Networks, ” in Signals, Systems and Computers, 2005 . Confer ence Recor d of the Thirty-Ninth Asilomar Conferen ce on , Oct 2005, pp. 230–23 4. March 1, 2022 DRAFT 30 [6] S. Kar, S. Aldosari, and J. Moura, “T opology for Distributed Inference on Graphs, ” Signal Pr ocessing, IE EE T ran sactions on , vol. 56, no. 6, pp. 2609–2613, June 2008. [7] F . Pasqualetti, A. Bi cchi, and F . B ullo, “Consensus Computation in Unreliable Network s: A System Theoretic Approac h, ” Automatic Control, IEE E T ransactions on , vol. 57, no. 1, pp. 90–104, Jan 2012. [8] F . Y u, M. Huang , and H. T ang, “Biologically inspired consensus-ba sed spectrum sensing in mobile Ad Hoc netw orks with cogniti ve radios, ” Network, IEEE , vo l. 24, no. 3, pp. 26–30, May 2010. [9] W . Zhang, Z. W ang, Y . Guo, H. Liu, Y . Chen, and J. Mitola, “Distributed Cooperati ve S pectrum Sensing Based on W eighted A verage Consensus, ” in Global T elecommunications Conferen ce (GLOB ECOM 201 1), 2011 IEEE , Dec 2011, pp. 1–6. [10] L. L amport, R. Shostak, and M. Pease, “The byzantine generals problem, ” ACM T rans. Pro gra m. Lang. Syst. , vol. 4, no. 3, pp. 382–40 1, Jul. 1982. [Online]. A vailab le: http://doi.acm.org/10.1145/35 7172.357 176 [11] A. Fragkiadakis, E . T ragos, and I. Askoxylakis, “ A survey on security threats and detection techniques in cognitive radio networks, ” IE EE Communication s Surveys T utorials , vol. 15, no. 1, pp. 428–445, 2013. [12] H. Rif ` a-Pous, M. J. Blasco, and C. Garrigues, “Rev iew of robust coope rativ e spectrum sensing techniques for cogniti ve radio networks, ” W ir el. P ers. Commun. , vol. 67, no. 2, pp. 175–198 , Nov . 2012. [Online]. A vailab le: http://dx.doi.org/10 .1007/s1127 7- 011- 0372- x [13] S. Marano, V . Matta, and L. T ong, “Distributed detection in the presence of byzantine attacks, ” IEE E T rans. Signal Pro cess. , vol. 57, no. 1, pp. 16 –29, Jan. 2009. [14] A. Rawat, P . Anand, H. Chen, and P . V arshney , “Collaborati ve spectrum sensing in the presence of byzantine attacks in cogniti ve radio netw orks, ” IEEE T ran s. Signal Pr ocess. , v ol. 59, no. 2, pp. 774 –786, Feb 2011. [15] B. Kailkhura, S . Brahma, Y . S. Han, and P . K. V arshney , “Distributed Detection in Tree T opologies With Byzantines, ” IEEE T rans. Signal Pr ocess. , vol. 62, pp. 3208–3 219, June 2014. [16] B. Kailkhura, S . Brahma, and P . K. V arshney , “Optimal byzantine attack on distributed detection in tree based topologies, ” in Pr oc. International Confer ence on Computing, Networking and Communications W orkshops (IC NC-2013) , San Diego, CA, January 2013, pp. 227– 231. [17] B. Kailkhura, S. Brahma, Y . S . Han, and P . K. V arshney , “Optimal distributed detection in the presence of byzantines , ” in Pr oc. The 38th International Confere nce on A coustics, Speech, and Signal Pro cessing (ICASSP 2013) , V ancouv er , Canada, May 2013. [18] A. V empaty , K. Agrawal, H. Chen, and P . K. V arshney , “Adaptiv e l earning of Byzantines’ behavior in cooperativ e spectrum sensing, ” in Pr oc. I EEE W ir eless Comm. and Networking Conf. (WCN C) , march 201 1, pp. 1310 –1315. [19] A. Min, K.-H. Kim, and K. Shin, “Robust cooperati ve sensing via state estimati on in cogniti ve radio networks, ” in New F rontier s in Dynamic Spectrum Access Networks ( DySP AN), 2011 IEEE Symposium on , May 2011 , pp. 185–196. [20] Z. Li , F . Y u, and M. Huang, “A Di stributed Consensus-Base d Cooperati ve Spectrum-Sensing Scheme in Cognitiv e Radios, ” V ehicular T echnolo gy , IEEE T ransactions on , vol. 59, no. 1, pp. 383–393, Jan 2010. [21] H. T ang, F . Y u, M. Huang, and Z. Li, “Distributed consensus-based security mechanisms in cogniti ve radio mobile ad hoc networks, ” Communications, IET , v ol. 6, no. 8, pp. 974–9 83, May 2012. [22] F . Y u, H. T ang, M. Huang, Z. Li, and P . Mason, “Defense against spectrum sensing data falsification attacks in mobile ad hoc networks with cognitive radios, ” in Milit ary Communications Confer ence, 2009. MILCOM 2009. IEE E , Oct 2009, pp. 1–7. [23] F . Y u, M. Huang, and H. T ang, “Biologically inspired consensus-based spectrum sensing in mobile Ad Hoc networks with cogniti ve radios, ” Network, IEEE , vo l. 24, no. 3, pp. 26–30, May 2010. March 1, 2022 DRAFT 31 [24] S. Liu, H. Z hu, S. Li, X. Li , C. Chen , and X. Guan, “ A n adap tiv e de viation-tolerant secure scheme for dist ributed cooperati ve spectrum sensing, ” in Global Communications Confer ence (GLOBECOM), 2012 IEEE , Dec 2012 , pp. 603–608. [25] Q. Y an, M. L i, T . Jiang, W . Lou, and Y . Hou, “V ulnerability and protection for distributed consensus-based spectrum sensing in cogniti ve radio netw orks, ” in INFOCOM, 2012 Pr oceedings IE EE , March 2012 , pp. 900–908. [26] F . Digham, M.-S. Al ouini, and M. K. Simon, “On t he energy detection of unkno wn signals over fading channels, ” in Communications, 2003. ICC ’03. IEEE Internation al Conferen ce on , vol. 5, May 2003, pp. 3575–3579 vol.5. [27] R. Olfati-Saber , J. Fax, and R. Murray , “Consen sus and Cooperation i n Networked Multi-Agent S ystems, ” Pro ceedings of the IEEE , vo l. 95, no. 1, pp. 215–2 33, Jan 2007. [28] S. Sundaram and C. Hadjicostis, “Dist ributed F unction Calculation via Linear Iterativ e Strategies in the Presence of Malicious Agents, ” Automatic C ontr ol, IE EE T ransactions on , vol. 56, no. 7, pp. 1495 –1508, July 2011. [29] S. M. Kay , Fundamentals of Statistical Signal Pr ocessing , V olume 2: Detection Theory . ser . Prentice Hall Signal Processing Series, A. V . Oppenheim, Ed. Prentice Hall PTR, 1998 . [30] R. A. Horn and C. R . Johnson , Matrix Analysis . Cambridge, U.K.: Cambridge Univ . P ress, 1987. March 1, 2022 DRAFT
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment