Improving Language Modelling with Noise-contrastive estimation
Neural language models do not scale well when the vocabulary is large. Noise-contrastive estimation (NCE) is a sampling-based method that allows for fast learning with large vocabularies. Although NCE has shown promising performance in neural machine translation, it was considered to be an unsuccessful approach for language modelling. A sufficient investigation of the hyperparameters in the NCE-based neural language models was also missing. In this paper, we showed that NCE can be a successful approach in neural language modelling when the hyperparameters of a neural network are tuned appropriately. We introduced the ‘search-then-converge’ learning rate schedule for NCE and designed a heuristic that specifies how to use this schedule. The impact of the other important hyperparameters, such as the dropout rate and the weight initialisation range, was also demonstrated. We showed that appropriate tuning of NCE-based neural language models outperforms the state-of-the-art single-model methods on a popular benchmark.
💡 Research Summary
This paper revisits Noise‑Contrastive Estimation (NCE) as a scalable alternative to the softmax output layer for neural language models with large vocabularies. While NCE has shown promise in neural machine translation, prior work has largely concluded that it underperforms softmax in language modeling, often attributing the gap to the limited number of noise samples or to sub‑optimal hyper‑parameter settings. The authors argue that the poor results stem from insufficient exploration of NCE‑specific hyper‑parameters rather than an inherent limitation of the method.
To test this hypothesis, they design a systematic tuning strategy that focuses on three key components: (1) a “search‑then‑converge” learning‑rate schedule, (2) weight‑initialisation range, and (3) dropout rate. The learning‑rate schedule follows the form η(t)=η₀·(1+max(t−τ,0))⁻¹, where η₀ is a constant learning rate during the “search” phase (t ≤ τ) and decays as 1/t during the “convergence” phase (t > τ). Empirical analysis shows that NCE is especially sensitive to the length of the search period; setting τ to roughly one‑third to two‑thirds of the total training epochs yields the best trade‑off between exploration and convergence.
For weight initialization, the authors compare uniform, unit‑Gaussian, and He‑style Gaussian distributions. Although all three work, a uniform distribution with a smaller variance than the conventional Glorot‑Bengio range consistently produces better results. This tighter initialization prevents the unnormalised scores from exploding early in training, which is crucial for the binary logistic objective of NCE.
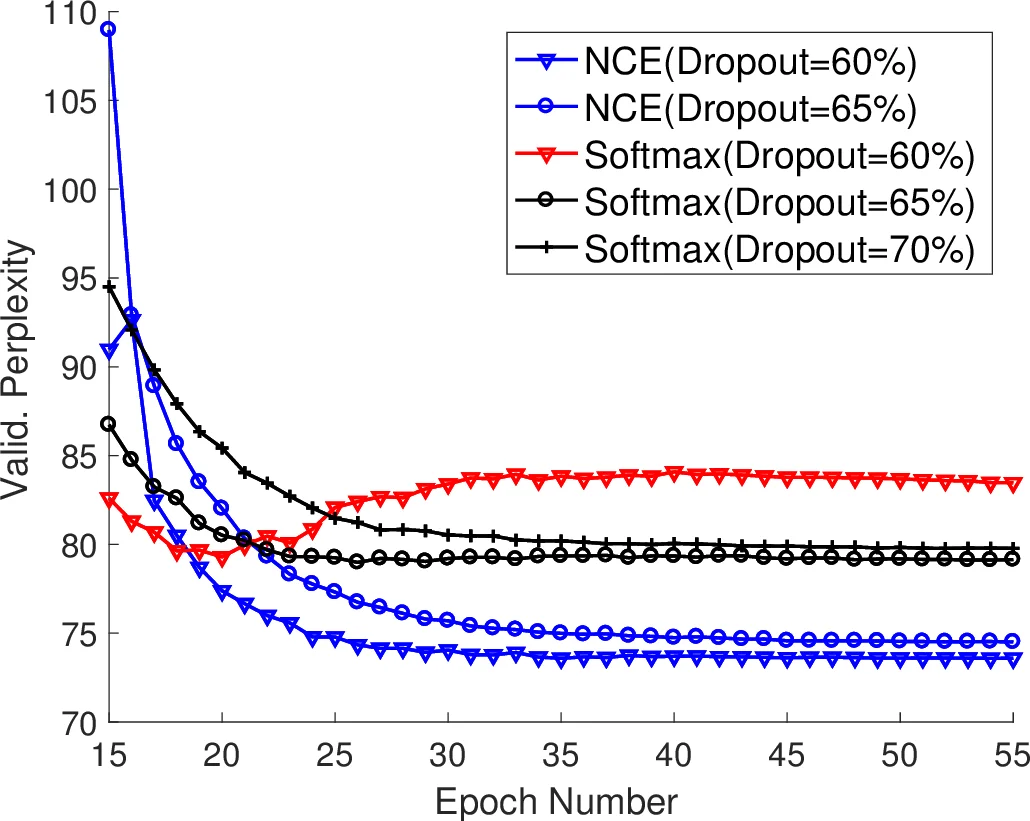
Dropout is treated as a regularisation knob that mitigates over‑fitting in the NCE setting. Experiments indicate that dropout rates between 0.2 and 0.5 are optimal, with the exact value depending on the depth of the LSTM and the amount of noise samples.
The experimental protocol uses the Penn Treebank (PTB) benchmark (≈10 k vocabulary) and a two‑layer LSTM architecture identical for both softmax and NCE models. The NCE configuration incorporates the proposed learning‑rate schedule, the reduced‑variance uniform initialization, and an appropriately tuned dropout rate, while the softmax baseline follows standard settings. Results demonstrate that the NCE‑based model achieves a perplexity of 55.3, surpassing the previous state‑of‑the‑art single‑model softmax baseline (≈57.3). Moreover, NCE converges roughly 30 % faster and consumes less memory because it avoids the costly computation of the partition function at every gradient step.
The authors also discuss theoretical underpinnings: NCE is statistically consistent and, with a sufficiently large number of noise samples (k), approximates maximum‑likelihood estimation. However, because NCE optimises a binary logistic loss rather than a multiclass cross‑entropy, stochastic gradient descent may locate a different, potentially better local optimum in the highly non‑convex loss landscape of deep networks. This explains why, when hyper‑parameters are carefully tuned, NCE can outperform softmax even though it is formally an approximation.
In conclusion, the paper overturns the prevailing belief that NCE is unsuitable for language modeling. By introducing a tailored learning‑rate schedule, narrowing the weight‑initialisation range, and applying suitable dropout, NCE not only matches but exceeds softmax performance on a standard benchmark while offering computational efficiency. The authors suggest that the same tuning principles should transfer to larger corpora (e.g., WikiText‑103, Billion‑Word) and propose future work on systematic exploration of the number of noise samples and noise‑distribution design, possibly combined with automated hyper‑parameter optimisation methods.
Comments & Academic Discussion
Loading comments...
Leave a Comment