Automatic Organisation, Segmentation, and Filtering of User-Generated Audio Content
Using solely the information retrieved by audio fingerprinting techniques, we propose methods to treat a possibly large dataset of user-generated audio content, that (1) enable the grouping of several audio files that contain a common audio excerpt (…
Authors: Gonc{c}alo Mordido, Jo~ao Magalh~aes, Sofia Cavaco
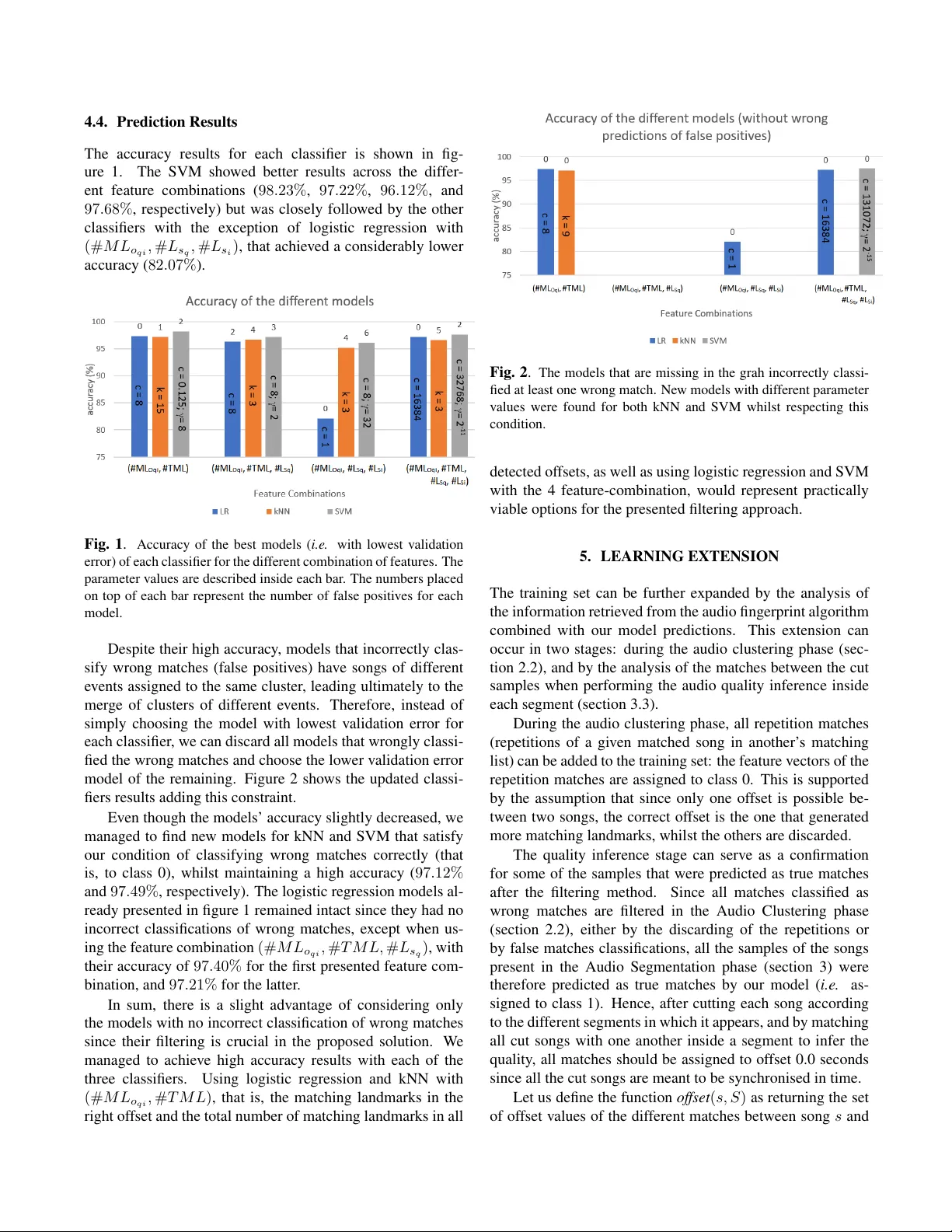
A UTOMA TIC ORGANISA TION, SEGMENT A TION, AND FIL TERING OF USER-GENERA TED A UDIO CONTENT Gonc ¸ alo Mor dido, Jo ˜ ao Magalh ˜ aes, Sofia Cavaco NO V A LINCS, Departamento de Inform ´ atica Faculdade de Ci ˆ encias e T ecnologia, Uni versidade No va de Lisboa 2829-516 Caparica, Portugal goncalomordido@gmail.com, { jm.magalhaes, scav aco } @fct.unl.pt ABSTRA CT Using solely the information retriev ed by audio finger- printing techniques, we propose methods to treat a possibly large dataset of user-generated audio content, that (1) enable the grouping of se veral audio files that contain a common au- dio excerpt ( i.e . are relativ e to the same e vent), and (2) give information about ho w those files are correlated in terms of time and quality inside each ev ent. Furthermore, we use su- pervised learning to detect incorrect matches that may arise from the audio fingerprinting algorithm itself, whilst ensuring our model learns with pre vious predictions. All the presented methods were further v alidated by user-generated recordings of se veral dif ferent concerts manually crawled from Y ouT ube. Index T erms — audio fingerprinting, user-generated con- tent, audio synchronisation, supervised learning 1. INTR ODUCTION Giv en the abundance and ubiquity of video-oriented content (and, consequently , audio content) experienced in most social networks now adays, it is important to understand such large amount of information in a meaningful way . One important step to achieve such understanding is to group the content in sev eral clusters based on similarity , which in the context of this work is based on e vents. When we consider several user - generated recordings of different lengths reporting the same ev ent, which is very lik ely to happen due to the nature of user-generated content, the existence of overlapping sections between two of such recordings means that they should be- long to the same cluster/ev ent. Audio fingerprinting has been primarily used to detect if a gi ven query song matches other songs in a preexisting database [1, 2, 6, 8]. Nonetheless, this algorithm retrie ves very v aluable information, that can be used for several other purposes. Here, we propose to use it to perform the organ- isation (clustering), se gmentation and alignment, of audio recordings of music ev ents. 978-1-5090-3649-3/17/$31.00 c 2017 IEEE The main contributions of this paper are then the organ- isation of a large dataset of audio recordings into the dif- ferent e vents they portrait (section 2), with additional infor- mation regarding how each event’ s recordings are distributed ov er time (section 3), and the detection and filtering of incor- rect matches possibly retrie ved from the audio fingerprinting algorithm using a supervised learning approach (section 4), whilst ensuring our model learns with previous predictions (section 5). Moreov er , finding correlations between the content inside each cluster can also be v ery beneficial to achiev e a better comprehension of the data. In this work we propose to align all event’ s song clips over time and we further use a quality inference technique already presented in pre vious work to or- der them in terms of their relativ e quality [7]. 2. D A T A ORGANISA TION Considering the abundant and ubiquitous nature of user- generated content, it is very likely to deal with a database of sev eral different ev ents ( e.g . audio recordings of several con- certs), in which each event has sev eral recordings reporting it ( e.g . relative to a certain concert song). Our goal is then to gather all song clips of a given e vent into the same cluster . Our technique to group clips of a given ev ent is based on them having common excerpts of audio. Giv en the lik ely noisy and time sparse nature of user-generated content ( i.e . the different recordings capture different parts of the ev ent, with possible ov erlaps), we need to use a technique that is resistant to noise and at the same time can identify overlapping excerpts in music recordings from the same ev ent. Audio fingerprinting enables synchronising a query song s q against sev eral other audio clips present in a formerly cre- ated database, whilst being relati vely resistant to noise. Note that when we refer to a query song, we do not mean that we are dealing with the whole song, instead, we are referring to a portion of the whole song that has been recorded in an au- dio clip. Section 2.1 explains in more detail why using audio fingerprinting to characterise and compare the dif ferent audio files (similarly to what already proposed in our previous work [7]) is appropriate when dealing with possibly very noisy au- dio files, which is likely to be experienced in the context of our problem. Once the audio fingerprints of the dif ferent audio files are compared and possibly matched, we use this information to identify ov erlapping excerpts and cluster our data into the dif- ferent e vents. Section 2.2 takes a deeper look on how the grouping of the different recorded clips is indeed achie ved and internally represented. 2.1. A udio Fingerprinting The first step of our algorithm is to characterise the data with audio fingerprints. Using a fingerprint to characterise each recorded clip enables to efficiently represent and compare dif- ferent clips, which is essential considering the v ast occurrence of user-generated data experienced no wadays. Since the gen- eration of this fingerprint in volv es the direct usage, or a com- bination of features from the audio signal, it is important to pick the features that are the most representati ve and, to some extent, inv ariant to distortion. Similarities between finger - prints of different song clips lead to a match of the clips. Our algorithm uses Cotton and Ellis’ landmark-based audio fingerprinting algorithm 1 , which is based in the well- known approach formerly proposed by W ang [3, 8]. A fin- gerprint is composed of se veral landmarks, which in turn are generated through the analysis of two frequency peaks with high energy in a small period of time. More specifically , a landmark is a pair of two peaks, and contains information about each peak frequency , the time at which the first peak occurred, and the time offset between them. Giv en a query song s q , our algorithm uses the audio fin- gerprints information to match it against the song clips s in the database [7]. Since each audio clip’ s fingerprints are a list of landmarks, our algorithm considers that two song clips, s q and s , contain the same audio excerpt if more than a certain number of landmarks are equal in both of their fingerprints; the threshold used is normally a small value ( e.g. 5) since wrong matches are unlikely . T o discov er the time offset be- tween the two clips we simply need to analyse the time dif- ference between the timestamp of the equal landmarks in s q and s . 2.2. A udio Clustering The second step of our algorithm is to or ganise the data into clusters, such that the clips from the same e vent ( i.e . from the same whole music) are in the same cluster . This is achieved using the information retriev ed from the fingerprinting stage. Moreov er , since the different recordings will very likely be in different ranges of quality , from extremely noisy to clean 1 This landmark-based audio fingerprinting algorithm is available in https://github .com/dpwe/audfprint. recordings, audio fingerprinting permits the synchronisation of the lo w-quality recordings against better quality recordings in the database, conceiv ably in common audio portions that might not be too af fected by noise in the low-quality record- ing. In order to organise the audio clips in the database, we match each clip to all the other ones present in the database, ensuring all clips are tested against one another . In other words, for each clip in the database we consider it as a query song and use the fingerprints information to match it against all other clips in the database. Since there may be multiple clips for the same ev ent ( i.e. , whole song) each query song will likely hav e sev eral song matches, that together compose the matching list of the query song. The fingerprints information is used to b uild a graph, G = ( V , E ) , with the nodes, V , representing all song clips in our database and each edge in E representing a match between two clips. Since each clip is represented by a node, we will use the same name ( s ) to refer to song clip s and the node that represents that clip. Moreover , each edge is assigned a weight that consists of the offset (in seconds) between the tw o connected clips. In other words, if edge ( s 1 , s 2 , o 12 ) ∈ E , then there is a match between clips s 1 and s 2 with offset o 12 . Isolated nodes in the graph represent clips that ha ve an empty matching list and that are not present in any of the other clips’ matching lists. Ev en though the analysis of the weights of the paths is not necessary to performing the clustering, it will be essential to perform the audio segmentation presented in section 3. The basis to detect and distribute the clips to the dif ferent clusters resides in the notion that if there is a path between two clips, then they should belong to the same cluster . This is an adaptation of Kennedy and Naaman’ s algorithm, that uses this graph-based representation to detect different episodes inside a giv en event [5]. 3. A UDIO SEGMENT A TION Analysing ho w the dif ferent clips of each ev ent are scattered ov er each event’ s timeline is of e xtreme importance to better manage the different audio files. Therefore this section fo- cuses on finding the time interv als ( i.e. se gments) in which the different clips are distributed inside each cluster . An impor- tant aspect of this synchronisation task is that it only requires information already obtained from the audio fingerprinting al- gorithm that was used to perform the clustering described in section 2. 3.1. A udio Synchronisation The offsets returned by the audio fingerprinting algorithm were further used to perform the alignment of the audio clips. This task uses the graph-based representation of our clips, G described in section 2.2. As mentioned above, the weights of the edges are the offset (returned by the audio fingerprint- ing) between tw o clips. Follo wing the paths in G , we can deriv e the offsets between any two clips in the same cluster by adding the weights in the path ( i.e., by calculating the cost of the path). It is important to notice that this only works because if there is a positi ve edge in the graph connecting two nodes, there is also a negativ e edge in the opposite direction. W e can then represent the offset o ij between any two nodes s i and s j that are in the same cluster , as o ij = cost ( G, s i , s j ) . The actual way the synchronisation of all clips inside a cluster is made is by electing a representativ e song clip and by getting the of fset of all the other clips relati ve to this one (that is, o ir for e very song clip s i in the cluster). Note that the representati ve clip can be an y of the cluster’ s clips, since all clips of a gi ven event (cluster) are connected in the graph. After all of fsets are obtained, if the representativ e clip is not the recording that has the earliest starting timestamp, the off- set values are updated according to the clip with the earliest timestamp ( i.e. the clip that starts first in the e vent’ s timeline). W e can define the earliest starting song clip s e as the clip with the minimum distance to the reference clip s r : ∀ s i ∈ V o er ≤ o ir . This minimum distance can either be 0, if the representati ve song is indeed the earliest starting clip (since o rr = 0 ), or a negati ve number , if s e starts before song s r . Afterwards, we calculate all offsets o ie .These can be obtained by adding the value of o er to the previously calculated of fsets o ir : ∀ s i ∈ V o ie = o ir + o er Using this approach, all offsets are greater or equal than 0 and correctly aligned in terms of their starting point along the e vent’ s timeline, since all of fsets are no w relati ve to the earliest starting clip. 3.2. Time-based Segmentation By having the overall offsets of all clips of a giv en cluster, together with the duration of each clip, one has the knowledge of which clips exist in a gi ven moment of time. Thus, we can organise an ev ent with segments , such that se gments coincide with the time interval of o verlapping clips. The ov erall event’ s timeline will be segmented into sev- eral non-overlapping segments. Given all offsets o ie (for all s i in the cluster), a new segment from time t start to time t end is created when one of the follo wing situations occurs: (1) A ne w song clip s i starts at time t start ( o ie = t start ). (2) A clip s i with duration d ( s i ) ends at time t end (that is, o ie + d ( s i ) = t end ). As a consequence, whenever a ne w seg- ment starts at t start , there is a segment ending at t start − 1 , except when t start = 0 meaning that it is the first segment of that ev ent. The song clips can then be cut according to the times- tamps of each of the se gments they are part of. F or instance, if song s 1 belongs to segment A and B , then the song is cut into song s 1 A and s 1 B ( s 1 is equal to the concatenation of s 1 A and s 1 B ). This information is encapsulated in a tuple that represents a segment. The tuple contains an initial and final times- tamp, and all clips that overlap between that period of time, ( t start , t end , s 1 A , s 2 A , . . . ) . Each cluster , or event, is then composed by sev eral segments, that give information on which clips are av ailable in the different time intervals and therefore at any moment of time in the e vent’ s timeline. 3.3. Quality Inference In previous work we proposed a method to infer the quality of each song clip relative to all the other clips inside a giv en cluster by analysing the sum of each clip’ s number of match- ing landmarks against the rest of the clips in the database [7]. This method can be further used to infer the quality of the clips inside each segment by matching them using the audio fingerprinting algorithm (that is, the algorithm is called once more b ut with the clips within the segment and not all clips in the database). Howe ver , given the possible small time length of the se g- ments, together with the possible small number of clips within each segment, matches are less likely to happen. Thus, in- creasing the number of landmarks by increasing the number of landmarks/sec performed by the algorithm for each clip, generates a higher number of matching landmarks between different song clips and therefore increases the likeliness of matches to occur . Since the clusters were formed based on song clips with common excerpts, and after the filtering of false matches that will be presented in section 4, we can eliminate the match- ing landmarks threshold leading a match to be declared ev en with only 1 matching landmark between two clips. Since all clips inside a segment are time-aligned, the expected offset returned by the algorithm should be 0 seconds, meaning all the other matching landmarks with different offsets can be discarded and not considered for the clip’ s quality score. This quality inference step enables ultimately for song clips to be ordered based on their relative quality inside each segment. Thus, on top of having information to which clips are av ailable at a giv en time in the overall ev ent’ s timeline, we no w know ho w the different song clips inside the segment relate in terms of their relativ e quality . 4. FIL TERING METHOD Even though unlik ely , the probability of a false match be- tween two clips from the audio fingerprinting algorithm is still greater than 0. W e propose a method to filter out such false matches from the clusters. In previous w ork, we proposed a filtering approach based on the analysis of significant drops on the deri vati ves of the percentage of matching landmarks between the query and matched song relati ve to the ov erall number of the matched clip’ s landmarks [7]. Here, we present an alternative method that uses machine learning to detect such false matches. 4.1. Featur e Selection Our samples, or feature vectors, are deriv ed from the finger - printing algorithm’ s output, and e very song is represented by sev eral samples. Each sample corresponds to a match re- turned by the fingerprinting algorithm. Giv en a query song s q , the fingerprinting algorithm re- turns the following for every song s i in the database: (1) the number of landmarks, # L s q , of the query song s q , (2) the off- set between s q and s i , that is o q i , (3) the number of matching landmarks with of fset o q i , which we call # M L o qi , and (4) the number of total matching landmarks in all offsets, # T M L . Note that when a song is added to the database, the number of landmarks computed for that song is also retriev ed from the algorithm, hence the number of landmarks of all songs are known. Thus, (5) the number of landmarks , # L s i , of song s i is also kno wn. Since the actual value of the of fset does not directly influence if a match is correct or incorrect, it is not considered to enter the feature space. Howe ver , all the other referred features might be a good indicator of a false match. The set of available and possibly relev ant features, for each pair ( s q , s i ), is then the following: F = { # M L o qi , # T M L, # L s q , # L s i } . W e tested our mod- els with sev eral subsets of F , more specifically: • { # M L o qi , # T M L } • { # M L o qi , # T M L, # L s q } • { # M L o qi , # L s q , # L s i } • { # M L o qi , # T M L, # L s q , # L s i } Each one of our classifiers was trained with these features subsets to access which combination generates the best model. 4.2. T raining Data Since the goal of our models is to predict whether a sample is a false match or a true match, there are only two classes: 0 and 1, respectiv ely . False matches are incorrect matches. These can be wrong matches , if the two matched songs do not ha ve any common audio e xcerpt, or repetition matches , if the y hav e indeed a common excerpt b ut the assigned of fset is not correct. The latter case can be easily detected as it happens when a song s i appears in the matching list of a query s q sev eral times with different offsets, described as repetitions. In this case, the match of fset ( o q i ) with the highest number of matching landmarks is considered a true match ( i.e., assigned to class 1), whilst all other match offsets ( o 0 q i , o 00 q i , o 000 q i , . . . ) are considered false matches ( i.e., assigned to class 0). A dataset of 198 audio recording files, retriev ed from 23 dif ferent concert songs from Y ouT ube, was used as the database of the audio fingerprinting algorithm, which corre- sponded to an av erage of 8.6 different recordings per concert song ( i.e. ev ent). This database generated 3098 matches, which were used to train, v alidate, and test our models. From these, there were 1071 true matches (class 1) and 2027 false matches (class 0) from which 2021 were repetition matches and 6 were wrong matches. Note that we balanced the train- ing set e very time a ne w model was trained ( i.e. the number of samples of class 0 was equal to the number of samples of class 1). 4.3. Model Estimation W e used three different methods to solve this classification problem: logistic regression, k-nearest neighbours (kNN), and support vector machines (SVM). The purpose of using different classifiers is to hav e a broader way of comparison on ho w the different features used influence the outcome of the ov erall predictions of the dif ferent methods. Apart from trying different feature vectors, we also vari ed the classifiers parameters. F or logistic re gression, we dou- bled the v alue of the regularisation parameter c during 20 it- erations (with its initial v alue being set to 1.0). W e tried all odd numbers between 1 and 39 for the number of neighbours k in the kNN classifier . Regarding the SVM classifier , we used the RBF kernel and the optimal values for c and γ were obtained by executing an exhaustiv e search ov er all possible combinations of a subset of possible v alues for each parame- ter . For this we follo wed the methodology of using exponen- tially growing sequences [4]. More specifically v arying c to the follo wing values 2 − 5 , 2 − 3 , ... , 2 15 , 2 17 and γ to 2 − 15 , 2 − 13 , ... , 2 3 , 2 5 . This searching process is often described as Grid-search, and it returns the best value of each parameter of a gi ven model ( i.e . the hypothesis that achie ves the highest accuracy). W e used double cross-validation to retriev e the model with lowest validation error for each classifier (v arying the parameters as explained above): we start by performing leav e-one-song-out cross-v alidation, in which ev ery song in the training set e xcept one are used to train the model with a k -fold cross-validation, with k = 10 , whilst the left-out song is used to test the model; this process is then repeated until all songs ha ve been left-out and repeated in every combination of possible parameters assigned for each classifier . The training and validation error of each model is the a verage of the error occurred in all the leav e-one-song-out iterations, with the accuracy of the model being tested on the overall predictions of all left-out songs’ samples. Follo wing these steps for all designated ranges of possible values for the different classi- fiers’ parameters, we assign the model with lowest validation error in the 10-fold validation for each classifier as the most suitable model. 4.4. Pr ediction Results The accurac y results for each class ifier is sho wn in fi g- ure 1. The SVM sho wed better results across the di f fer - ent feature combinations ( 98 . 23% , 97 . 22% , 96 . 12% , and 97 . 68% , respecti v ely) b ut w as closely follo wed by the other classifiers with the e xception of logistic re gression wit h (# M L o q i , # L s q , # L s i ) , that achie v ed a considerably lo wer accurac y ( 82 . 07% ). Fig . 1 . Accurac y of the best models ( i.e . with lo west v alidation error) of each classifier for the dif ferent combination of features. The parameter v alues are described inside each bar . The numbers placed on top of each bar represent the number of f alse positi v es for each model. Despite their high accurac y , models that incorrectly clas - sify wrong matches (f alse positi v es) ha v e songs of dif ferent e v ents assigned to the same cluster , leading ultimately to t h e mer ge of clusters of dif ferent e v ents. Therefore, instead of simply choosing the model with lo west v alidation error for each classifier , we can discard all models that wrongly classi- fied the wrong matches and choose the lo wer v alidation error model of the remaining. Figure 2 sho ws the updated class i- fiers results adding this constraint. Ev en though the models’ accurac y slightly decreased, we managed to find ne w models for kNN and SVM that sati sfy our condition of classifying wrong matches correctly (that is, to class 0), whilst maintaining a high accurac y ( 97 . 12% and 97 . 49% , respecti v ely). The logistic re gression models al- ready presented in figure 1 remained intact since the y had no incorrect classificat ions of wrong matches, e xcept when us - ing the feature combination (# M L o q i , # T M L, # L s q ) , with their accurac y of 97 . 40% for the first presented feature com- bination, and 97 . 21% for the latter . In sum, there is a slight adv antage of considering only the models with no incorrect classification of wrong matches since their filtering is crucial in the proposed solution. W e managed to achie v e high accurac y results with each of t he three classifiers. Using logistic re gression and kNN wit h (# M L o q i , # T M L ) , that is, the matching landmarks in the right of fset and the total number of matching landmarks in al l Fig . 2 . The models that are missing in the grah incorrectly classi- fied at least one wrong match. Ne w models with dif ferent parameter v alues were found for both kNN and SVM whils t respecting this condition. detected of fsets, as well as using logistic re gression and SVM with the 4 feature-combination, w ould represent practically viable options for the presented filtering approach. 5. LEARNING EXTENSION The trai ning set can be further e xpanded by the analysis of the information retrie v ed from the audio fingerprint algorithm combined with our model predictions. This e xtension can occur in tw o stages: during the audio clustering phase (sec- tion 2.2), and by the analysis of the matches between the cut samples when performing the audio quality inference inside each se gment (section 3.3). During the audio clustering phase, all repetition matches (repetitions of a gi v en matched song in another’ s matching list) ca n be added to the training set: the feature v ectors of the repetition matches are assigned to class 0. This is supported by the assumption that since only one of fset is possible be- tween tw o songs, the correct of fset is the one that generated more matching landmarks, whilst the others are discarded. The quality inference stage can serv e as a confirmation for some of the samples that were predicted as true matches after the filtering method. Since all matches classified as wrong matches are filtered in the Audio Clustering phase (section 2.2), either by the discarding of the repetitions or by f alse matches classifications, all the samples of the songs present in the Audio Se gmentation phase (section 3) were therefore predicted as true matches by our model ( i.e . as- signed to class 1). Hence, after cutting each song according to the dif ferent se gments in which it appears, and by matching all cut songs with one another inside a se gment to infer the quality , all matches should be assigned to of fset 0.0 seconds since all the cut songs are meant to be synchronised in time. Let us define the function of fset ( s, S ) as returning the set of of fset v alues of the dif ferent matches between song s and each song in set S . Function count ( A, v ) retrie ves the number of occurrences of the real number v in set A , and T M ( m ) assigns sample match m to class 1 in the training set. Then, we can define the following e xpression for every cluster c : ∀ t ∈ T c ∀ s ∈ S t count ( offset ( s, S t \ { s } ) , 0) = k S t \ { s }k ⇒ ∀ m ∈ M c : T M ( m ) where t is a segment in T c , which in turn is the set of (time) segments of cluster c , and S t is the set of songs in segment t . M c is the set of all matches ( i.e. samples) in that cluster . T o sum up, one can then assume that, if for each cut song inside each cluster’ s segments there is a match to each of the other cut songs with of fset of 0 seconds, then all samples that previously contributed to the formation of that gi ven cluster are considered true matches and added to the training set with their class assigned to 1. 6. CONCLUSION In this work we propose dif ferent methods that manipulate and correlate different user-generated recordings in a possi- bly large dataset of audio files, contributing ultimately for a better comprehension of the data. The basis of all presented work relied upon the direct analysis of the information re- triev ed by the matches of the different audio files from the audio fingerprinting algorithm. Although using audio fingerprinting to org anise dif ferent audio files with common audio excerpts was initially pro- posed by Kennedy and Naaman [5] and further extended in our previous work [7], here we introduced a novel filtering approach by using machine learning techniques and achieving optimal filtering results ( i.e. successfully filtering all wrong matches) whilst also achieving high prediction accuracy in our considerable large test setup ( e.g . 97 . 49% using SVM and 4 features). Moreo ver , we introduce the possibility of ex- tending our learning by increasing the training set in dif ferent possible stages, more concretely in the Audio Or ganisation and Audio Segmentation phases, by the detection of repeti- tions and by the analysis of the previous predictions. W e additionally proposed Audio Segmentation inside each cluster/e vent which provides valuable insight on how the different ev ent’ s audio files are correlated in terms of time. This can be extremely useful since it provides the knowl- edge of which audio files are available at a gi ven moment of time. Moreov er , using a previously proposed audio inference approach [7] with parameter adaptations in the audio finger- printing algorithm, we also represent how the different audio files relate in terms of their relati ve audio quality inside each segment of a gi ven cluster . Acknowledgments This work was partially funded by the H2020 ICT project COGNITUS with grant agreement No 687605 and by the Por- tuguese Foundation for Science and T echnology under project NO V A-LINCS PEest/UID/CEC/04516/2013. Refer ences [1] AcoustID. Chr omaprint — AcoustID . U R L : https:// acoustid.org/chromaprint . [2] A CRCloud. Automatic Content Recognition Cloud Ser- vices . U R L : https://www.acrcloud.com . [3] V . Cotton and D. Ellis. “Audio fingerprinting to identify multiple videos of an event.” In: ICASSP . IEEE, 2010, pp. 2386–2389. [4] C. Hsu, C. Chang, C. Lin, et al. “A practical guide to support vector classification”. In: (2003). [5] L. Kennedy and M. Naaman. “Less T alk, More Rock: Automated Or ganization of Community-contributed Collections of Concert V ideos”. In: Pr oceedings of the 18th International Confer ence on W orld W ide W eb . WWW ’09. A CM, 2009, pp. 311–320. [6] Midomi. Searc h for Music Using Y our V oice . U R L : http://www.midomi.com/index.php . [7] G. Mordido, J. Magalh ˜ aes, and S. Cavaco. “ Automatic Organisation and Quality Analysis of User-Generated Content with Audio Fingerprinting”. In: 2017 25th Eu- r opean Signal Pr ocessing Confer ence (EUSIPCO) (EU- SIPCO 2017) . 2017, pp. 1864–1868. [8] A. L. W ang. “An industrial-strength audio search algo- rithm”. In: Pr oceedings of the 4 th International Confer- ence on Music Information Retrieval . 2003.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment