Abnormal Event Detection in Videos using Generative Adversarial Nets
In this paper we address the abnormality detection problem in crowded scenes. We propose to use Generative Adversarial Nets (GANs), which are trained using normal frames and corresponding optical-flow images in order to learn an internal representation of the scene normality. Since our GANs are trained with only normal data, they are not able to generate abnormal events. At testing time the real data are compared with both the appearance and the motion representations reconstructed by our GANs and abnormal areas are detected by computing local differences. Experimental results on challenging abnormality detection datasets show the superiority of the proposed method compared to the state of the art in both frame-level and pixel-level abnormality detection tasks.
💡 Research Summary
This paper tackles the challenging problem of abnormal event detection in crowded video scenes by leveraging the generative capabilities of conditional Generative Adversarial Networks (cGANs). The authors propose a dual‑network architecture: one generator (NF→O) learns to synthesize optical‑flow maps from raw video frames, while a second generator (NO→F) learns to reconstruct frames from optical‑flow inputs. Both generators are paired with patch‑based discriminators and trained jointly using a combination of an L1 reconstruction loss and the standard adversarial loss. Crucially, training data consist exclusively of normal video sequences, allowing the networks to internalize the distribution of normal appearance and motion without ever seeing abnormal examples.
During inference, each test frame and its corresponding optical‑flow map are fed through the trained generators to obtain reconstructed counterparts (p_O and p_F). Because the generators have never observed abnormal patterns, they fail to accurately reproduce regions containing anomalous objects or motions. The authors quantify this failure in two complementary ways. First, a pixel‑wise difference ΔO = O – p_O directly measures discrepancies in the motion domain. Second, a semantic difference ΔS is computed by passing the original frame F and its reconstruction p_F through a pre‑trained AlexNet and subtracting the conv5 feature maps (h(F) – h(p_F)). ΔS captures higher‑level appearance inconsistencies that may be missed by raw pixel differences, especially in low‑resolution settings.
Both ΔO and ΔS are normalized by their respective maximum values across the entire test video, producing N_O and N_S. The final abnormality heatmap A is obtained by a weighted sum A = N_S + λ·N_O, with λ empirically set to 2. This fused map highlights regions where either motion or appearance deviates from the learned normal patterns, enabling both frame‑level anomaly scoring and pixel‑level localization.
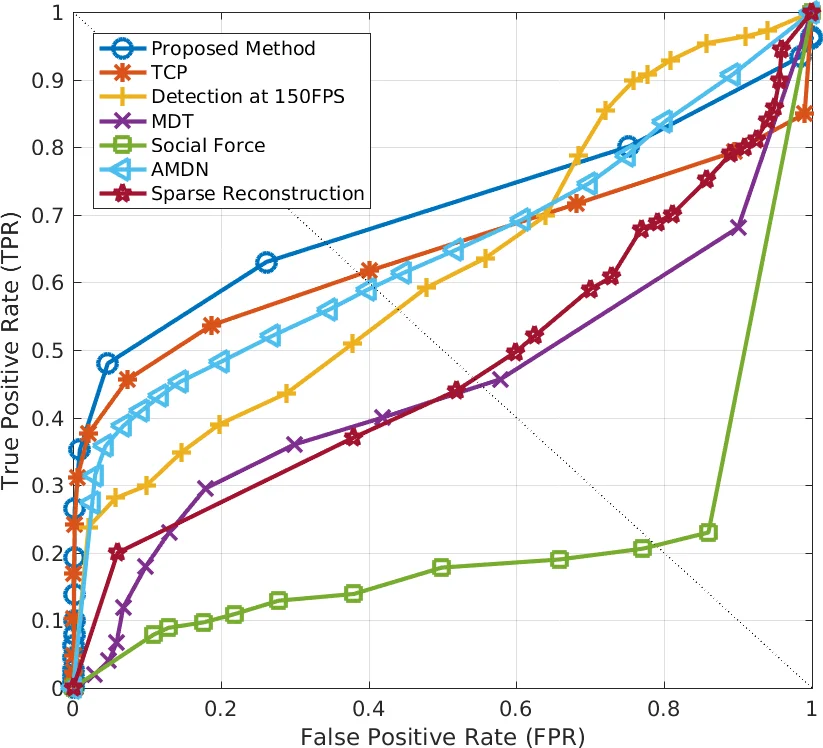
The method is evaluated on two widely used benchmarks: the UCSD Ped1/Ped2 datasets and the UMN SocialForce dataset. Experiments follow both the frame‑level protocol (a frame is labeled abnormal if any pixel exceeds a threshold) and the pixel‑level protocol (requiring at least 40 % overlap with ground‑truth abnormal pixels). The proposed approach achieves an AUC of 0.99 on UCSD Ped1 and 0.97 on UMN, surpassing all previously reported results. In pixel‑level evaluation, it reaches an AUC of 0.97 on Ped1, again outperforming state‑of‑the‑art methods. An ablation study shows that each generator alone yields respectable performance (NF→O: 95.3 % AUC, NO→F: 84.1 % AUC on frame‑level), but the fusion of motion and appearance cues provides the best results, confirming their complementary nature.
Qualitative examples illustrate that normal pedestrians and background elements are faithfully reconstructed, while abnormal entities such as a vehicle in a pedestrian‑only scene generate conspicuous reconstruction errors, appearing as “blobs” or missing motion vectors. A failure case involving a small skateboard demonstrates the method’s limitation when the abnormal object is both tiny and exhibits motion similar to normal pedestrians.
The paper’s contributions are threefold: (1) introducing a fully unsupervised, dual‑cGAN framework that learns normal crowd behavior directly from raw pixels; (2) proposing a simple yet effective reconstruction‑difference based anomaly scoring that combines low‑level motion and high‑level semantic cues; (3) achieving state‑of‑the‑art performance on standard benchmarks without requiring any abnormal training samples or external classifiers.
In conclusion, the authors demonstrate that conditional GANs can serve not only as generative models but also as powerful normality learners for video anomaly detection. Future work is suggested to replace optical‑flow with Dynamic Images or other multi‑frame motion representations, potentially improving robustness to subtle or slowly evolving anomalies.
Comments & Academic Discussion
Loading comments...
Leave a Comment