Unified Host and Network Data Set
The lack of data sets derived from operational enterprise networks continues to be a critical deficiency in the cyber security research community. Unfortunately, releasing viable data sets to the larger com- munity is challenging for a number of reasons, primarily the difficulty of balancing security and privacy concerns against the fidelity and utility of the data. This chapter discusses the importance of cyber secu- rity research data sets and introduces a large data set derived from the operational network environment at Los Alamos National Laboratory. The hope is that this data set and associated discussion will act as a catalyst for both new research in cyber security as well as motivation for other organizations to release similar data sets to the community.
💡 Research Summary
The paper addresses a critical gap in cybersecurity research: the scarcity of high‑fidelity, operational‑network datasets that can be freely used by the research community. To mitigate this, the authors release a comprehensive “Unified Host and Network Data Set” derived from the Los Alamos National Laboratory (LANL) enterprise environment, covering approximately 90 days of activity. The dataset combines two distinct sources: (1) Windows host event logs collected from the majority of LANL workstations, and (2) Cisco NetFlow version 9 records exported from core routers.
The NetFlow component captures bi‑directional communication summaries between devices, containing fields such as start/end timestamps, source and destination IP addresses, protocol, source and destination ports, packet counts, and byte counts. Because NetFlow records are inherently unidirectional, the authors applied a stitching process to merge complementary uniflows into single bi‑flows. Directionality was inferred using a hierarchy of port‑based heuristics: (i) destination ports below 1024 with non‑ephemeral source ports, (ii) the top 90 most frequent ports treated as destinations, and (iii) the smaller of the two ports considered the destination. After direction assignment, matching 5‑tuples were aggregated, preserving the earliest start time, latest end time, and summing packet/byte counters. This streaming aggregation evicts idle entries after 30 minutes and periodically emits long‑lived flows.
To protect privacy and operational security, the dataset underwent a two‑stage de‑identification. First, IP addresses were mapped to fully‑qualified domain names (FQDNs) using DNS and DHCP logs, preserving temporal consistency. When mapping failed, the IP was retained with a “IP.” prefix. Second, all host identifiers (source/destination devices, ports) were replaced with random tokens, except for well‑known service ports (e.g., 80, 443, 22) and system‑level usernames/process names, which were left intact to retain analytical value. Records with protocols other than TCP (6), UDP (17), or ICMP (1) were discarded. The final product is delivered as CSV files with fields ordered as described in the paper’s Table 1.
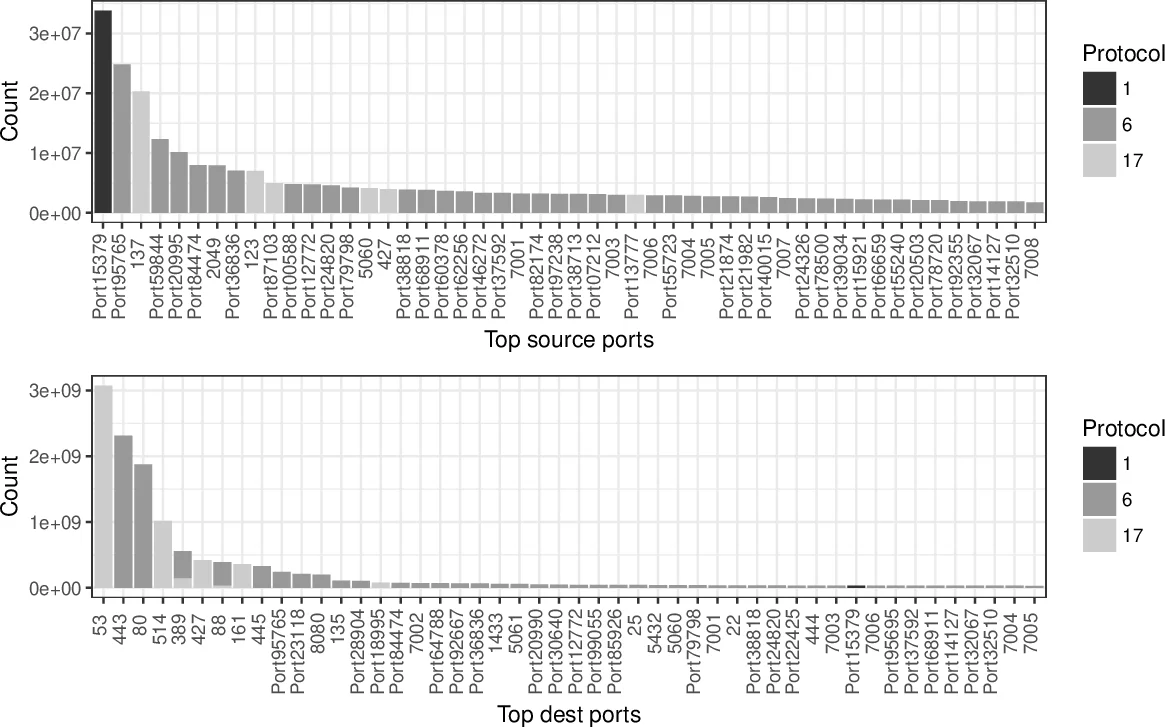
Data‑quality analyses reveal several characteristics. Approximately 57 % of TCP bi‑flows have zero packets in one direction, reflecting LANL’s router configuration that often exports only a single direction and the prevalence of one‑sided scans. Mapping failures are more common for destination devices, indicating incomplete DNS coverage. Protocol distribution shows roughly 30 % TCP, 60 % UDP, and 10 % ICMP, with notable long‑lived UDP and ICMP flows—an artifact of aggregating all uniflows regardless of protocol. Port histograms illustrate a non‑uniform source‑port distribution, suggesting occasional mis‑stitching or protocols that use fixed source ports (e.g., NTP). In‑degree/out‑degree visualizations for selected days highlight hub hosts and potential lateral‑movement pathways.
The authors outline multiple research avenues enabled by the dataset: (a) flow‑based anomaly detection and lateral‑movement identification, (b) joint host‑log and flow analysis for behavior‑based threat modeling, (c) evaluation of anonymization techniques and privacy‑preserving data sharing, (d) reconstruction of network topology and service mapping, and (e) comparative studies between synthetic datasets and real operational data. They also acknowledge limitations, such as transient IP addresses, imperfect direction inference, and incomplete host‑name mappings, urging researchers to apply additional preprocessing as needed.
In conclusion, this work provides a valuable, openly accessible resource that bridges the gap between theoretical cybersecurity research and real‑world operational data. By releasing a richly annotated, de‑identified, and well‑documented dataset, the authors not only enable immediate experimental work but also set a precedent encouraging other organizations to share comparable data, thereby fostering a more collaborative and empirically grounded security research ecosystem.
Comments & Academic Discussion
Loading comments...
Leave a Comment