Deep Binary Reconstruction for Cross-modal Hashing
With the increasing demand of massive multimodal data storage and organization, cross-modal retrieval based on hashing technique has drawn much attention nowadays. It takes the binary codes of one modality as the query to retrieve the relevant hashing codes of another modality. However, the existing binary constraint makes it difficult to find the optimal cross-modal hashing function. Most approaches choose to relax the constraint and perform thresholding strategy on the real-value representation instead of directly solving the original objective. In this paper, we first provide a concrete analysis about the effectiveness of multimodal networks in preserving the inter- and intra-modal consistency. Based on the analysis, we provide a so-called Deep Binary Reconstruction (DBRC) network that can directly learn the binary hashing codes in an unsupervised fashion. The superiority comes from a proposed simple but efficient activation function, named as Adaptive Tanh (ATanh). The ATanh function can adaptively learn the binary codes and be trained via back-propagation. Extensive experiments on three benchmark datasets demonstrate that DBRC outperforms several state-of-the-art methods in both image2text and text2image retrieval task.
💡 Research Summary
The paper addresses a fundamental challenge in cross‑modal hashing: how to learn binary hash codes that simultaneously preserve intra‑modal and inter‑modal similarity without resorting to a two‑stage pipeline that first learns continuous embeddings and then thresholds them. The authors first provide a theoretical analysis based on the Multi‑modal Restricted Boltzmann Machine (MRBM). By formulating the MRBM’s maximum‑likelihood learning objective, they show that the joint likelihood decomposes into two KL‑divergence terms—one enforcing the distribution of each single modality and the other enforcing the conditional distribution across modalities. Consequently, a shared hidden layer in an MRBM‑style network inherently captures both intra‑modal and inter‑modal consistency, offering a solid foundation for cross‑modal hashing.
Building on this insight, the authors propose Deep Binary Reconstruction (DBRC), a deep auto‑encoder architecture with separate encoders/decoders for each modality (image and text) and a shared hashing layer. The key novelty is the Adaptive Tanh (ATanh) activation function, defined as f(s)=tanh(α·s)+λ·|α−1|², where α>0 is a learnable scaling factor for each bit and λ is a regularization constant. When α is small, ATanh behaves like a smooth tanh, allowing gradients to flow; as training progresses α is driven larger, making ATanh approach the sign function and thus producing near‑binary outputs (−1, +1). Because ATanh is differentiable, the entire network—including the binary hashing layer—can be trained end‑to‑end via back‑propagation. The regularization term penalizes deviation of α from 1, stabilizing the learning of binary codes.
Optimization proceeds by computing the gradient of the reconstruction loss with respect to each α_i and updating α_i using RMSprop, which adapts the step size based on historical gradients. The loss consists of reconstruction errors for both modalities, encouraging the shared binary representation to retain enough information to rebuild the original inputs while simultaneously serving as an effective hash code.
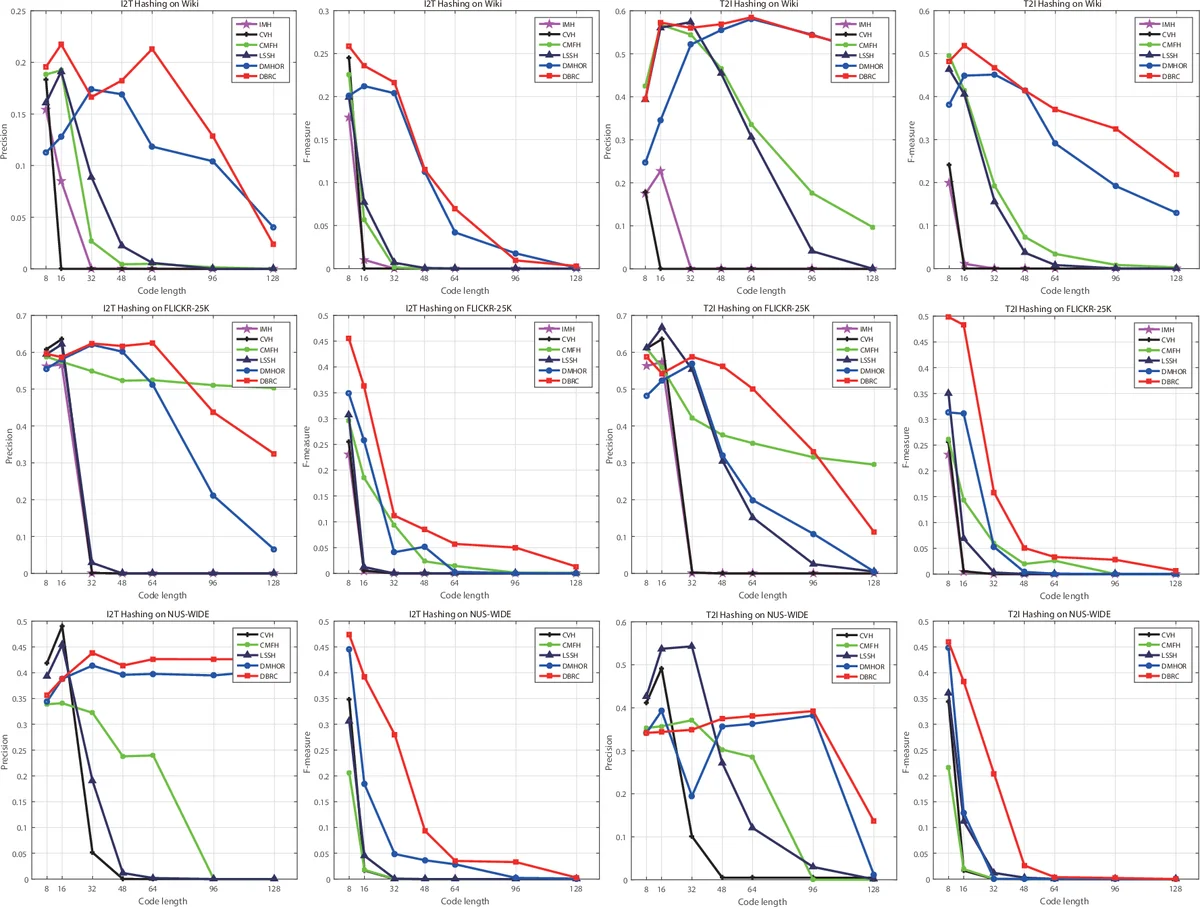
Experiments are conducted on three large‑scale benchmark datasets—Flickr30K, NUS‑WIDE, and MS‑COCO—covering both image‑to‑text and text‑to‑image retrieval. The authors evaluate mean average precision (MAP), precision@K, and recall@K for hash lengths of 32, 64, and 128 bits. DBRC consistently outperforms a wide range of state‑of‑the‑art unsupervised cross‑modal hashing methods, including linear approaches (CVH, CMFH, LSSH) and deep approaches (MDAE‑based hashing, stacked auto‑encoders). Gains range from 5 % to 12 % in MAP, and the method remains robust even at the shortest 32‑bit code length, demonstrating the effectiveness of ATanh in learning compact binary representations.
The paper’s contributions are threefold: (1) a rigorous theoretical justification that MRBM‑style shared layers naturally enforce both intra‑ and inter‑modal consistency; (2) the introduction of ATanh, a learnable, differentiable activation that bridges continuous representations and binary hash codes without a separate quantization step; (3) an end‑to‑end deep reconstruction framework (DBRC) that directly optimizes binary codes via reconstruction loss. Limitations include sensitivity to the hyper‑parameters α initialization and λ, the current focus on only two modalities, and potential vulnerability to noisy data due to reliance on reconstruction fidelity. Future work may explore automated hyper‑parameter scheduling, extension to more than two modalities, and robustness enhancements. Overall, DBRC offers a compelling new direction for efficient, high‑quality cross‑modal retrieval by integrating binary constraints directly into deep network training.
Comments & Academic Discussion
Loading comments...
Leave a Comment