Emotion Intensities in Tweets
This paper examines the task of detecting intensity of emotion from text. We create the first datasets of tweets annotated for anger, fear, joy, and sadness intensities. We use a technique called best–worst scaling (BWS) that improves annotation consistency and obtains reliable fine-grained scores. We show that emotion-word hashtags often impact emotion intensity, usually conveying a more intense emotion. Finally, we create a benchmark regression system and conduct experiments to determine: which features are useful for detecting emotion intensity, and, the extent to which two emotions are similar in terms of how they manifest in language.
💡 Research Summary
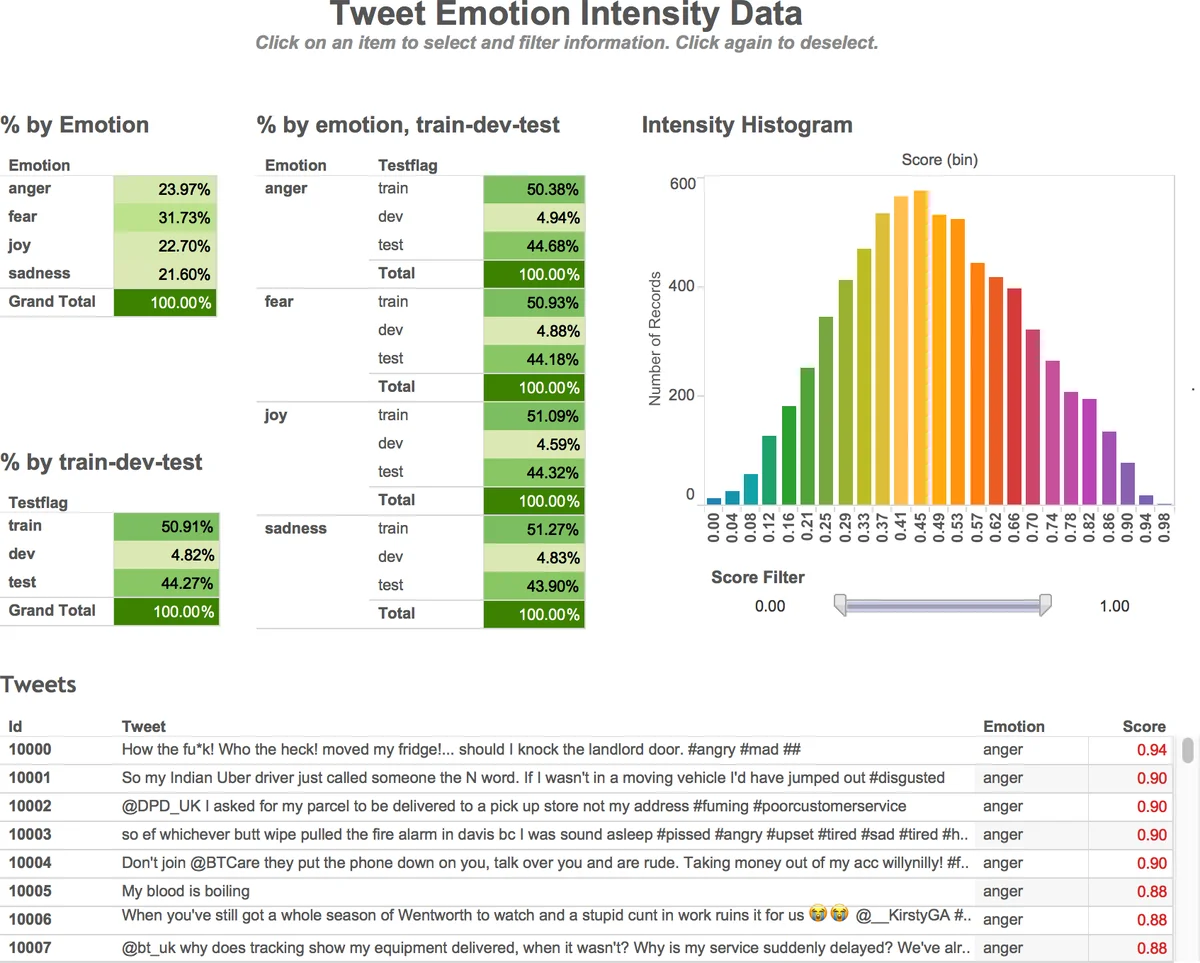
The paper “Emotion Intensities in Tweets” tackles the problem of estimating the degree of emotion expressed in short social media messages, a task that has received little attention compared to categorical emotion detection. The authors focus on four basic emotions—anger, fear, joy, and sadness—and define the goal as assigning each tweet a real‑valued intensity score between 0 (no presence of the target emotion) and 1 (maximum intensity).
To obtain reliable fine‑grained annotations, the authors adopt Best‑Worst Scaling (BWS), a comparative annotation scheme originally used for lexical items. In BWS, annotators are shown a set of four items (4‑tuples) and asked to pick the one that exhibits the highest intensity of the target emotion and the one that exhibits the lowest. By generating 2 N distinct 4‑tuples (where N is the number of tweets) through a Random Maximum‑Diversity Selection (RMDS) algorithm, each tweet appears in eight different tuples, and each tuple is annotated by three independent crowd workers on the CrowdFlower platform. The resulting “best‑minus‑worst” proportion is transformed from a –1 to 1 scale to a 0‑1 scale, yielding a continuous intensity score for every tweet. Split‑half reliability (SHR) analysis shows an average correlation of 0.91 across the four emotion sets, confirming the high consistency of the BWS‑derived scores.
Data collection proceeds by first selecting 50‑100 “query terms” per emotion from Roget’s Thesaurus (e.g., angry, mad, frustrated for anger). Tweets containing any of these terms are harvested via the Twitter API, with retweets and URLs removed. To avoid over‑representation, the authors limit each query term to at most 50 tweets and enforce a one‑tweet‑per‑user‑per‑term rule. The final master corpus comprises 7,097 tweets, split into three categories: (1) Hashtag Query Tweets (HQT) where the emotion term appears as a trailing hashtag, (2) No Query Tweets (NQT) which are copies of HQT with the hashtag removed, and (3) Query Tweets (QT) where the term appears as a normal word or in a mixed hashtag context. This design enables a controlled study of how emotion‑related hashtags affect perceived intensity.
The authors find that hashtags systematically increase intensity scores by roughly 0.07–0.12 on the 0‑1 scale, indicating that users often use hashtags to amplify emotional expression.
For the predictive component, the paper introduces the “AffectiveTweets” regression system. Features include: (i) word n‑grams (1‑ to 3‑grams), (ii) scores from emotion lexicons such as the NRC Emotion Lexicon, (iii) part‑of‑speech distributions, (iv) lexical richness measures (token count, type‑token ratio), and (v) character‑level cues (capitalization ratio, presence of emoticons/emojis). Linear regression and support vector regression are evaluated. The best configuration—combining n‑grams with lexicon scores—achieves Pearson correlations around 0.71 for all four emotions, with the lexicon alone accounting for roughly 30 % of the performance gain.
A cross‑emotion analysis reveals that models trained on one emotion can partially predict another’s intensity (e.g., an anger model yields r ≈ 0.45 on sadness), suggesting shared linguistic patterns across emotions.
All resources—raw tweets, BWS questionnaires, scoring scripts, regression code, and an interactive visualization—are released publicly via a GitHub repository and a CodaLab shared task (WASSA‑2017 Emotion Intensity). The shared task attracted 22 participating teams, establishing a benchmark for future work.
In summary, the paper makes four major contributions: (1) formulation of emotion‑intensity regression for tweets, (2) creation of the first large‑scale, high‑quality tweet datasets with continuous emotion scores using BWS, (3) empirical evidence that emotion‑related hashtags amplify perceived intensity, and (4) a baseline regression system with thorough feature analysis and cross‑emotion transfer experiments. The work opens avenues for multilingual extensions, deep neural models (e.g., Transformers) trained on BWS‑derived scores, and real‑time monitoring applications in customer service, public health, and crisis response.
Comments & Academic Discussion
Loading comments...
Leave a Comment