Application Level High Speed Transfer Optimization Based on Historical Analysis and Real-time Tuning
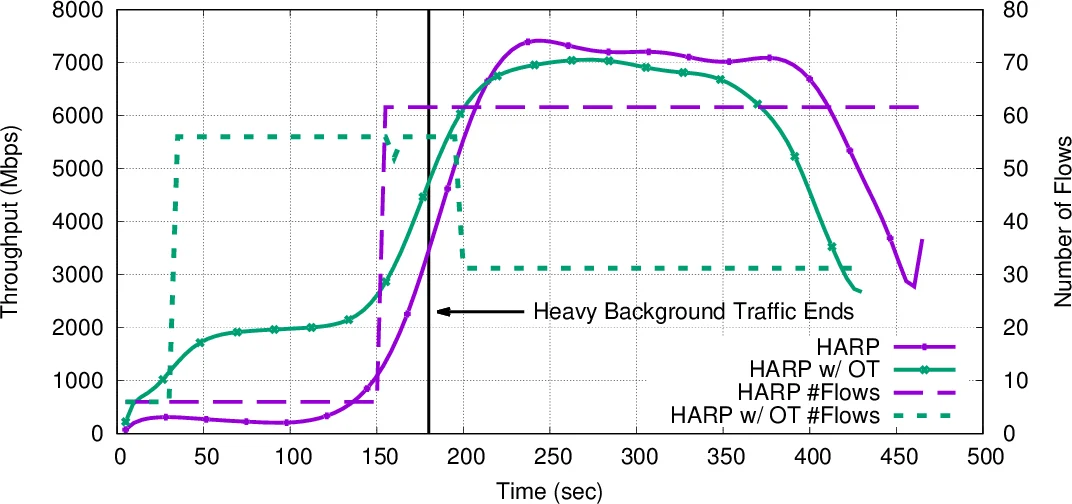
Data-intensive scientific and commercial applications increasingly require frequent movement of large datasets from one site to the other(s). Despite growing network capacities, these data movements rarely achieve the promised data transfer rates of the underlying physical network due to poorly tuned data transfer protocols. Accurately and efficiently tuning the data transfer protocol parameters in a dynamically changing network environment is a major challenge and remains as an open research problem. In this paper, we present predictive end-to-end data transfer optimization algorithms based on historical data analysis and real-time background traffic probing, dubbed HARP. Most of the previous work in this area are solely based on real time network probing which results either in an excessive sampling overhead or fails to accurately predict the optimal transfer parameters. Combining historical data analysis with real time sampling enables our algorithms to tune the application level data transfer parameters accurately and efficiently to achieve close-to-optimal end-to-end data transfer throughput with very low overhead. Our experimental analysis over a variety of network settings shows that HARP outperforms existing solutions by up to 50% in terms of the achieved throughput.
💡 Research Summary
The paper addresses the persistent problem that large‑scale scientific and commercial data transfers rarely achieve the theoretical bandwidth of modern high‑speed networks because application‑level transfer protocols (e.g., GridFTP) are often poorly tuned. Parameters such as concurrency (number of simultaneous file streams), parallelism (multiple TCP connections per file), and pipelining (queuing of control commands) have a strong impact on throughput, but their optimal values depend on a complex mix of factors: file size distribution, total dataset size, network bandwidth‑delay product, round‑trip time, background traffic, and end‑system I/O characteristics. Existing solutions fall into three categories: (i) heuristic formulas that use static metrics, (ii) real‑time probing that repeatedly runs sample transfers to discover optimal settings, and (iii) historical‑data modeling that builds predictive models from past transfers. Heuristics ignore dynamic network conditions, probing incurs high overhead, and pure historical models lack adaptability to new environments.
The authors propose HARP (Historical Analysis and Real‑time Probing), a hybrid framework that combines the strengths of all three approaches while mitigating their weaknesses. HARP consists of two main components: a Scheduler and an Optimizer.
Scheduler
- The incoming file list is partitioned into size‑based chunks (tiny, small, medium, large).
- For each chunk, a single “sample transfer” is executed to gauge current network load. The sample size is not fixed; instead it is chosen proportionally to the measured bandwidth (e.g., BW/4, BW/2, BW) to keep the probing time short while maintaining acceptable estimation error.
- Initial sample‑transfer parameters are derived from existing heuristics (e.g., pipelining ≈ BDP / average file size) to avoid random or default settings that could severely degrade performance.
- The measured throughput of each sample (ST
Comments & Academic Discussion
Loading comments...
Leave a Comment