Referenceless Quality Estimation for Natural Language Generation
Traditional automatic evaluation measures for natural language generation (NLG) use costly human-authored references to estimate the quality of a system output. In this paper, we propose a referenceless quality estimation (QE) approach based on recurrent neural networks, which predicts a quality score for a NLG system output by comparing it to the source meaning representation only. Our method outperforms traditional metrics and a constant baseline in most respects; we also show that synthetic data helps to increase correlation results by 21% compared to the base system. Our results are comparable to results obtained in similar QE tasks despite the more challenging setting.
💡 Research Summary
The paper tackles the problem of automatically evaluating the quality of natural language generation (NLG) outputs without relying on costly human‑written references. Traditional automatic metrics such as BLEU, METEOR, ROUGE‑L and CIDEr compute word‑level overlap against multiple references, which are expensive to obtain and often unreliable at the sentence level. The authors propose a referenceless quality estimation (QE) model that directly predicts a continuous quality score (on a 1–6 Likert scale) by comparing the source meaning representation (MR) with the generated utterance.
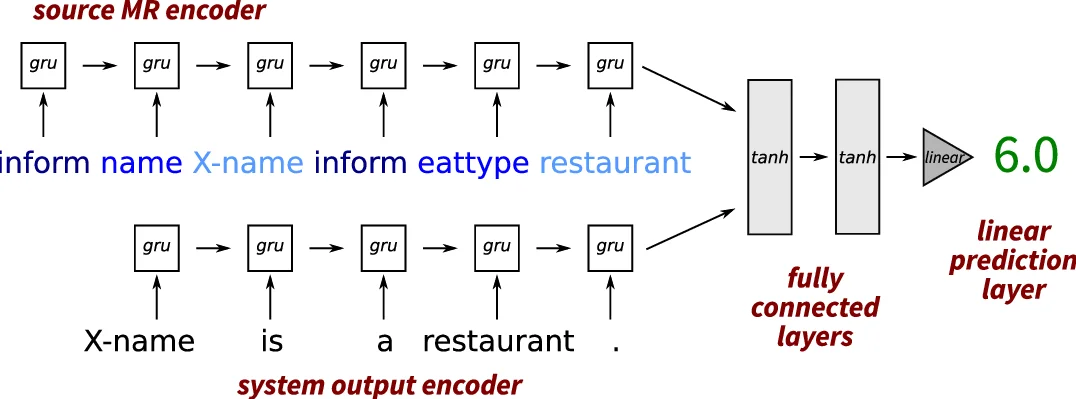
The architecture consists of two separate GRU (Gated Recurrent Unit) encoders: one processes the tokenised MR, the other processes the tokenised system output. The final hidden states of both encoders are concatenated and fed through two tanh‑activated fully‑connected layers followed by a linear regression layer that outputs the predicted score. Token embeddings are randomly initialised and learned jointly with the rest of the network; dropout (p = 0.5) is applied to the encoder inputs for regularisation. The model is trained in a supervised fashion by minimising mean‑squared error against median human ratings collected via crowdsourcing.
The experimental data comprise outputs from three recent NLG systems—LOLS, RNNLG, and TGen—across three dialogue‑domain datasets (restaurant and hotel). Each system output was evaluated by at least three crowd workers on a 1–6 scale, yielding a moderate inter‑rater agreement (ICC = 0.45). The authors adopt a 5‑fold cross‑validation scheme, ensuring that each fold contains distinct training, development, and test splits.
A key contribution is the use of synthetic data augmentation. For each original training instance, the authors generate multiple “noisy” variants by applying five heuristics: word deletion, word duplication (in‑place or random position), random word insertion, and random word substitution. Each introduced error reduces the original human rating by one point (with a floor at 4 for high‑scoring instances). This process expands the training set from under 2 000 examples to over 45 000, effectively tripling the amount of data. Additional experiments also treat human‑authored references as perfect (score = 6) and apply the same error generation to them, providing further synthetic material.
Results show that even the baseline model (no synthetic data) outperforms all traditional word‑overlap metrics in Pearson correlation (0.273 vs. 0.07–0.09) and Spearman rank correlation, while achieving lower mean absolute error than a constant baseline that always predicts the overall average rating (4.5). Adding synthetic errors to the original system outputs yields a modest gain (Pearson = 0.283). Incorporating synthetic errors on additional in‑domain references raises Pearson to 0.330, and the most extensive configuration (including test‑set references) reaches 0.354, a 21 % improvement over the baseline. All improvements are statistically significant according to the Williams test (p < 0.01). RMSE is slightly higher than the constant baseline, indicating occasional large prediction errors despite overall better performance.
In summary, the study demonstrates that a simple GRU‑based referenceless QE model can reliably estimate NLG quality without any reference texts, and that synthetic data generation is an effective strategy for mitigating data scarcity. The approach is suitable for rapid quality feedback during system development, runtime reranking, or triggering rule‑based fallback mechanisms in dialogue systems. Future work may explore incorporating dialogue context, richer error modeling, and cross‑domain generalisation.
Comments & Academic Discussion
Loading comments...
Leave a Comment