Boosting Metrics for Cloud Services Evaluation -- The Last Mile of Using Benchmark Suites
Benchmark suites are significant for evaluating various aspects of Cloud services from a holistic view. However, there is still a gap between using benchmark suites and achieving holistic impression of the evaluated Cloud services. Most Cloud service evaluation work intended to report individual benchmarking results without delivering summary measures. As a result, it could be still hard for customers with such evaluation reports to understand an evaluated Cloud service from a global perspective. Inspired by the boosting approaches to machine learning, we proposed the concept Boosting Metrics to represent all the potential approaches that are able to integrate a suite of benchmarking results. This paper introduces two types of preliminary boosting metrics, and demonstrates how the boosting metrics can be used to supplement primary measures of individual Cloud service features. In particular, boosting metrics can play a summary Response role in applying experimental design to Cloud services evaluation. Although the concept Boosting Metrics was refined based on our work in the Cloud Computing domain, we believe it can be easily adapted to the evaluation work of other computing paradigms.
💡 Research Summary
The paper addresses a persistent gap in cloud‑service evaluation: while benchmark suites are routinely employed to capture multiple performance dimensions (CPU, memory, network, storage, etc.), most studies report only the individual benchmark results, leaving customers to manually synthesize a holistic view. Inspired by the boosting technique in machine learning—where many weak learners are combined into a stronger predictor—the authors introduce the concept of “Boosting Metrics” as a family of methods that aggregate a suite of benchmark outcomes into a single, summary performance indicator.
Two elementary approaches are presented. The first treats the set of benchmark results as a point in an n‑dimensional Euclidean space, each dimension representing a distinct service aspect. By considering the geometric attributes of the hyper‑rectangular box formed between this point and the origin, classic means can be mapped to intuitive properties: the arithmetic mean corresponds to the box’s perimeter, the geometric mean to its volume, the harmonic mean to the ratio of volume to surface area, and the quadratic (root‑mean‑square) mean to the Euclidean distance from the origin. These means are easy to compute and work well when all benchmarks share the same unit and scale (homogeneous primary metrics).
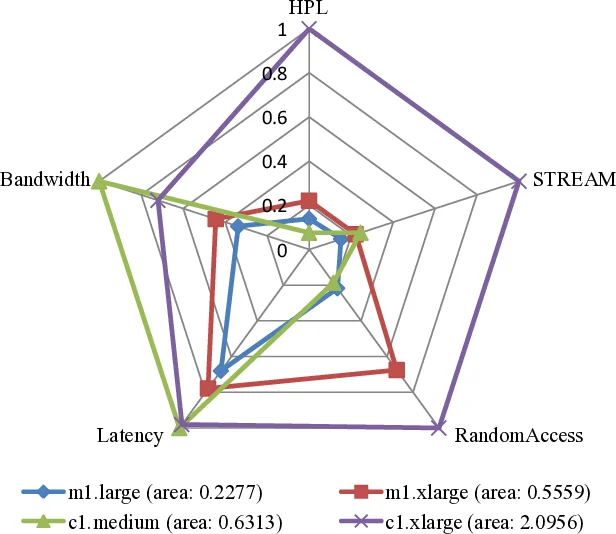
The second approach handles heterogeneous metrics by normalizing each benchmark result to a 0‑1 range. Results that are “Higher‑Better” (HB) are divided by the maximum observed value; “Lower‑Better” (LB) results are transformed via reciprocal scaling, thereby converting all dimensions into a “higher‑better” orientation. The normalized values are plotted on a radar (spider) chart, forming a polygon whose area is calculated as the sum of the areas of adjacent triangles. This polygon area serves as a single numeric Boosting Metric, directly usable as a response variable in experimental designs (e.g., ANOVA).
The authors demonstrate the utility of these metrics through two case studies. First, they reuse HPCC benchmark data for four Amazon EC2 instance types (m1.large, m1.xlarge, c1.medium, c1.xlarge). After HB/LB standardization, the radar‑plot areas are 0.2277, 0.5559, 0.6313, and 2.0956 respectively, clearly indicating that c1.xlarge provides the best overall performance. The area values are presented as concise summary responses that could replace a table of five separate metrics in decision‑making.
Second, they evaluate two instance types (m1.xlarge vs. m2.xlarge) using the NPB‑Java benchmark suite. Because NPB reports homogeneous metrics (runtime and FLOP‑rate), the geometric mean is applied as the Boosting Metric for each dimension. The analysis shows that while m1.xlarge has lower runtimes, m2.xlarge offers a better price‑performance trade‑off, illustrating how Boosting Metrics can support nuanced selection criteria.
The paper discusses limitations: the choice of normalization or weighting can bias the resulting metric; the simple geometric means may not capture complex, non‑linear interactions among dimensions; and extending the approach to multi‑objective optimization (e.g., performance vs. cost vs. energy) requires systematic weight determination.
In conclusion, Boosting Metrics provide a practical, mathematically grounded way to convert a multi‑dimensional benchmark suite into a single, interpretable performance figure that can serve both as a decision‑support tool for cloud customers and as a response variable in rigorous experimental designs. Future work is outlined to explore automated weight optimization, multi‑objective aggregation, and machine‑learning‑based non‑linear combination methods, thereby broadening the applicability of Boosting Metrics beyond cloud computing to other emerging computing paradigms.
Comments & Academic Discussion
Loading comments...
Leave a Comment