Domain Aware Neural Dialog System
We investigate the task of building a domain aware chat system which generates intelligent responses in a conversation comprising of different domains. The domain, in this case, is the topic or theme of the conversation. To achieve this, we present DOM-Seq2Seq, a domain aware neural network model based on the novel technique of using domain-targeted sequence-to-sequence models (Sutskever et al., 2014) and a domain classifier. The model captures features from current utterance and domains of the previous utterances to facilitate the formation of relevant responses. We evaluate our model on automatic metrics and compare our performance with the Seq2Seq model.
💡 Research Summary
The paper addresses the challenge of building a conversational agent that can handle multiple domains within a single dialogue and generate domain‑appropriate responses. While standard sequence‑to‑sequence (Seq2Seq) chatbots produce fluent language, they typically ignore the broader conversational context and therefore fail to adapt when the topic shifts. To remedy this, the authors propose DOM‑Seq2Seq, a modular architecture that explicitly models domain information for each utterance and leverages it during response generation.
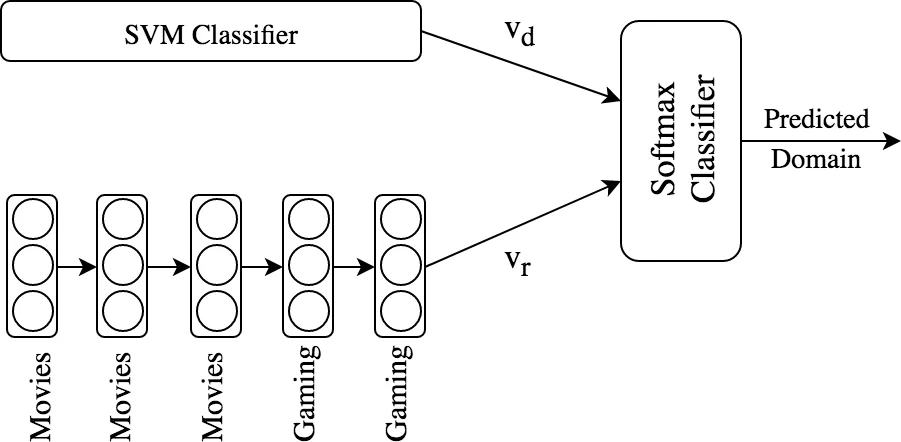
DOM‑Seq2Seq consists of four main components: (1) a domain classifier, (2) domain‑specific response generators, (3) a re‑ranking module, and (4) a feedback loop that feeds the predicted domain back into the classifier for subsequent turns. Two variants of the domain classifier are explored. The first is an ensemble approach that combines a tf‑idf based supervised SVM (which captures lexical cues from the current utterance) with a logistic regression model that takes the three most recent true domain labels as features. The second is an RNN‑based classifier that encodes the entire sequence of past domain labels using a single‑layer RNN (8 hidden units) to capture long‑range dependencies; its final hidden state is concatenated with the SVM’s probability vector and passed through a softmax layer to obtain domain probabilities.
For response generation, separate LSTM‑based Seq2Seq models with attention are trained for each domain (Movies, Gaming, and an Out‑of‑Domain (OOD) fallback). Each generator produces a candidate response and a confidence score derived from the sigmoid‑scaled logit of the decoder’s final time step. The re‑ranker then multiplies the domain probability p(d_i) from the classifier with the response confidence p(r_i) from the corresponding generator, selecting the pair with the highest product (argmax_i {p(d_i)·p(r_i)}). This simple multiplicative scheme ensures that both domain certainty and response quality influence the final output.
The authors collected a large corpus from Reddit AMA threads and Twitter. Movie and Gaming domains contain 1.33 M and 0.54 M query‑response pairs respectively; OOD uses 0.30 M Twitter pairs. An additional 0.54 M posts (Reddit Movies, Gaming, and Twitter) are used to train the SVM classifier. Domain labels for each utterance are generated automatically via Latent Dirichlet Allocation; utterances whose dominant topic proportion exceeds 0.5 are assigned that domain, otherwise they are marked OOD. Past domains are weighted with an exponential decay to reflect recency.
Evaluation employs two automatic metrics: (1) domain classification accuracy, and (2) Word Embedding Greedy Match using GloVe vectors, which measures semantic similarity between generated and reference responses. Results show that the ensemble DOM‑Seq2Seq (En‑DOM‑Seq2Seq) achieves 77.57 % domain accuracy and a Greedy Match score of 0.801, outperforming the baseline Seq2Seq (no domain classifier, 0.760 Greedy) and the RNN‑based variant (67.8 % accuracy, 0.797 Greedy). Qualitative examples demonstrate that DOM‑Seq2Seq produces more context‑aware and informative replies (e.g., “I’m a fan of them” versus a generic or missing response from the baseline).
The paper concludes that incorporating explicit domain modeling and leveraging prior conversational domains significantly improves both the relevance and consistency of generated responses. Limitations include the small set of domains (three) and reliance on automatically inferred LDA labels, which may introduce noise. Future work is suggested in scaling to many domains, refining label quality, personalizing responses based on user domain‑shift patterns, and developing more sophisticated re‑ranking mechanisms (e.g., learned meta‑rankers). Overall, DOM‑Seq2Seq offers a practical and effective framework for domain‑aware dialogue generation.
Comments & Academic Discussion
Loading comments...
Leave a Comment