Deep Reinforcement Learning for Inquiry Dialog Policies with Logical Formula Embeddings
This paper is the first attempt to learn the policy of an inquiry dialog system (IDS) by using deep reinforcement learning (DRL). Most IDS frameworks represent dialog states and dialog acts with logical formulae. In order to make learning inquiry dialog policies more effective, we introduce a logical formula embedding framework based on a recursive neural network. The results of experiments to evaluate the effect of 1) the DRL and 2) the logical formula embedding framework show that the combination of the two are as effective or even better than existing rule-based methods for inquiry dialog policies.
💡 Research Summary
The paper tackles the problem of learning policies for Inquiry Dialog Systems (IDS), where participants collaboratively answer shared questions without possessing complete domain knowledge. Traditional IDS approaches rely on handcrafted, rule‑based policies that work only in limited scenarios. This work introduces two major contributions: (1) the application of Deep Reinforcement Learning (DRL), specifically Deep Q‑Learning with experience replay (DQL), to automatically learn dialog policies, and (2) a novel logical‑formula embedding framework that compresses first‑order predicate logic representations into low‑dimensional vectors suitable for DRL.
In the proposed IDS model, beliefs are expressed as logical formulae (atoms, ground atoms, or their negations). Dialog states consist of the system’s belief set Σₛʸˢ, a commitment store (CS) that accumulates shared beliefs, and a stack of query stores (cQS) that tracks the current agenda. Dialog acts are limited to three types: Assert(Φ, φ) (assert a claim φ supported by a minimal consistent set Φ), Open(Ω) (introduce a new sub‑agenda Ω), and Close() (terminate the current agenda). Legal moves for each turn are defined based on the current agenda and the contents of Σₛʸˢ and CS.
The reinforcement learning formulation treats each turn as a step in a Markov Decision Process (MDP). The state is the current collection of logical formulae, the action is any legal dialog act, and the reward is designed to encourage rapid resolution: a large positive reward (wₚₒₛ = 20) is given when either participant asserts a formula that exactly matches the query, while a small negative reward (wₙₑg = 1) is incurred at every turn to penalize unnecessary length. An ε‑greedy exploration strategy is employed, with ε annealed from 1.0 to 0.05 over the first 50 epochs.
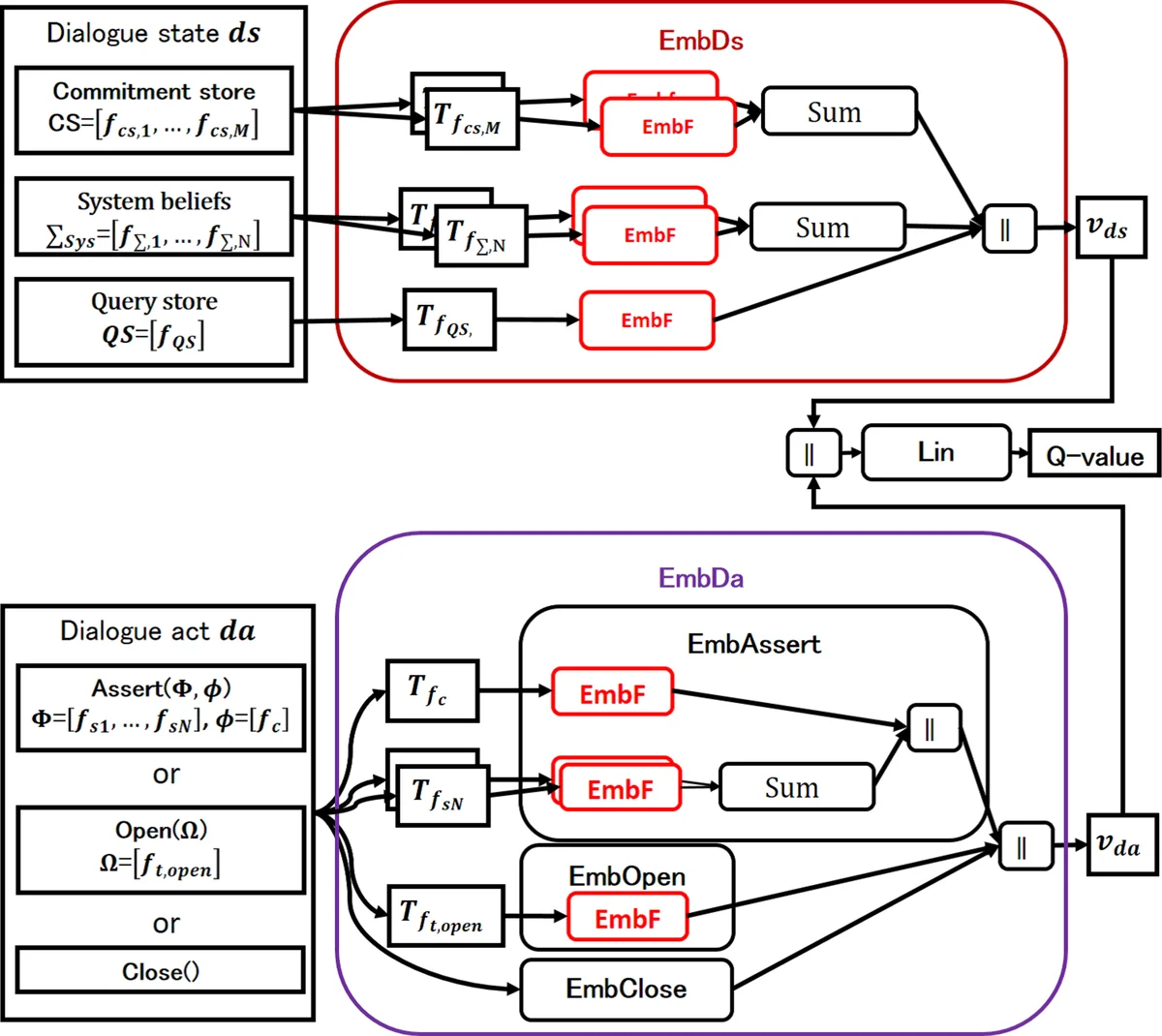
A central challenge is that representing logical formulae as binary “bag‑of‑formula” vectors leads to extremely sparse and high‑dimensional state/action spaces, hampering learning. To address this, the authors propose a recursive neural network (RNN) based embedding framework (EmbF). Each logical formula f is parsed into an abstract syntax tree T_f. Leaf nodes correspond to predicate arguments, and internal nodes represent predicates or logical operators (∧, →). Atom embeddings are computed by linearly combining a one‑hot predicate vector and one‑hot argument vectors, followed by a sigmoid activation. Operator embeddings recursively combine the vectors of their child sub‑formulae using separate weight matrices W∧ and W→, again followed by sigmoid. The root node’s vector v_f serves as a compact representation of the entire formula.
Two parallel embedding modules, EmbDs for dialog states and EmbDa for dialog acts, apply EmbF to every logical formula contained in the state or action, producing vectors v_ds and v_da. These vectors are fed into a Q‑function that first concatenates them (and an additional one‑hot flag indicating the presence of a Close act), then passes the concatenated vector through a linear layer to output the estimated Q‑value. All parameters—including the operator weight matrices and the final linear layer—are learned via standard DQL updates using experience replay.
Training is performed against a user simulator that mixes a rule‑based exhaustive policy (derived from prior work by Black and Hunter) with a random policy. With probability p (typically 0.8) the simulator follows the rule‑based policy, which exhaustively shares all beliefs; with probability 1 − p it selects a random legal move that does not conflict with its belief base. This hybrid approach provides both structured guidance and exploratory variability.
The experimental evaluation compares four policies across six configurations (varying user behavior and the system’s initial belief set): (i) Baseline (pure rule‑based), (ii) DQL without logical embedding (bag‑of‑formula representation), (iii) DQL with 5‑dimensional embeddings (DQLwE‑5d), and (iv) DQL with 10‑dimensional embeddings (DQLwE‑10d). Each epoch consists of 2,000 dialogs; training runs for 100 epochs (200 k dialogs). Results show that both embedding‑enhanced DQL variants outperform the baseline and the non‑embedding DQL, achieving higher success rates (i.e., correctly answering the query) and requiring fewer turns on average. The 10‑dimensional embedding yields a modest additional gain over the 5‑dimensional version, indicating that relatively low‑dimensional embeddings already capture sufficient logical structure for effective policy learning. Notably, the advantage of embedding‑based policies is most pronounced when the system starts with a limited belief base, suggesting that the compact representation facilitates faster discovery of useful inference paths.
The paper acknowledges several limitations. First, evaluation relies entirely on simulated users; real‑world user studies are needed to confirm generalization. Second, the reward function only accounts for answer correctness and turn count, ignoring qualitative aspects such as naturalness or user satisfaction. Third, the current embedding handles only conjunction and implication; extending it to handle quantifiers, negation, or more complex logical operators remains an open challenge. Finally, the scalability of the approach to domains with substantially larger belief vocabularies has not been empirically tested.
In conclusion, this work demonstrates that deep reinforcement learning, when coupled with a recursive neural network‑based logical formula embedding, can effectively learn inquiry dialog policies that rival or surpass traditional rule‑based methods. Future research directions include incorporating human user data, designing richer multi‑objective reward structures, and extending the embedding framework to broader classes of logical expressions, thereby moving toward more robust and adaptable conversational agents capable of collaborative reasoning.
Comments & Academic Discussion
Loading comments...
Leave a Comment