A Lightweight Front-end Tool for Interactive Entity Population
Entity population, a task of collecting entities that belong to a particular category, has attracted attention from vertical domains. There is still a high demand for creating entity dictionaries in vertical domains, which are not covered by existing knowledge bases. We develop a lightweight front-end tool for facilitating interactive entity population. We implement key components necessary for effective interactive entity population: 1) GUI-based dashboards to quickly modify an entity dictionary, and 2) entity highlighting on documents for quickly viewing the current progress. We aim to reduce user cost from beginning to end, including package installation and maintenance. The implementation enables users to use this tool on their web browsers without any additional packages — users can focus on their missions to create entity dictionaries. Moreover, an entity expansion module is implemented as external APIs. This design makes it easy to continuously improve interactive entity population pipelines. We are making our demo publicly available (http://bit.ly/luwak-demo).
💡 Research Summary
The paper presents LUWAK, a lightweight front‑end tool designed to support interactive entity population without requiring any installation of external packages or libraries. Implemented entirely in pure JavaScript and relying on the browser’s LocalStorage, LUWAK can be run simply by opening an HTML file in any modern web browser, thereby removing the “installation‑cost” barrier that often prevents non‑technical users from adopting entity‑population systems.
LUWAK’s workflow revolves around two dashboards: an Entity table and a Feedback table. The Entity table displays the current dictionary, where each row contains an entity, a label indicating whether it is a positive or negative example, the original seed that generated it, and a confidence score. Users can add, rename, delete, or deactivate entries directly; deactivated entities are ignored by the expansion algorithms, helping to curb semantic drift. The table also supports pagination, search, and column sorting to remain usable when the dictionary grows large.
The Feedback table shows candidate entities returned by an external Expansion API. In the initial implementation, the API uses pre‑trained GloVe embeddings (trained on CommonCrawl and Twitter corpora) to compute cosine similarity between the set of positive seed entities and potential candidates, ranking them by similarity score. LUWAK also supports a category‑based expansion module that leverages is‑a relationships from the YAGO knowledge base; for example, if most seeds belong to the “Programming Language” category, the system can suggest additional programming languages. Because the expansion logic is encapsulated in an external API, users can replace or augment it with any algorithm that conforms to the simple request/response interface, including pattern‑based, graph‑based, or transformer‑based methods.
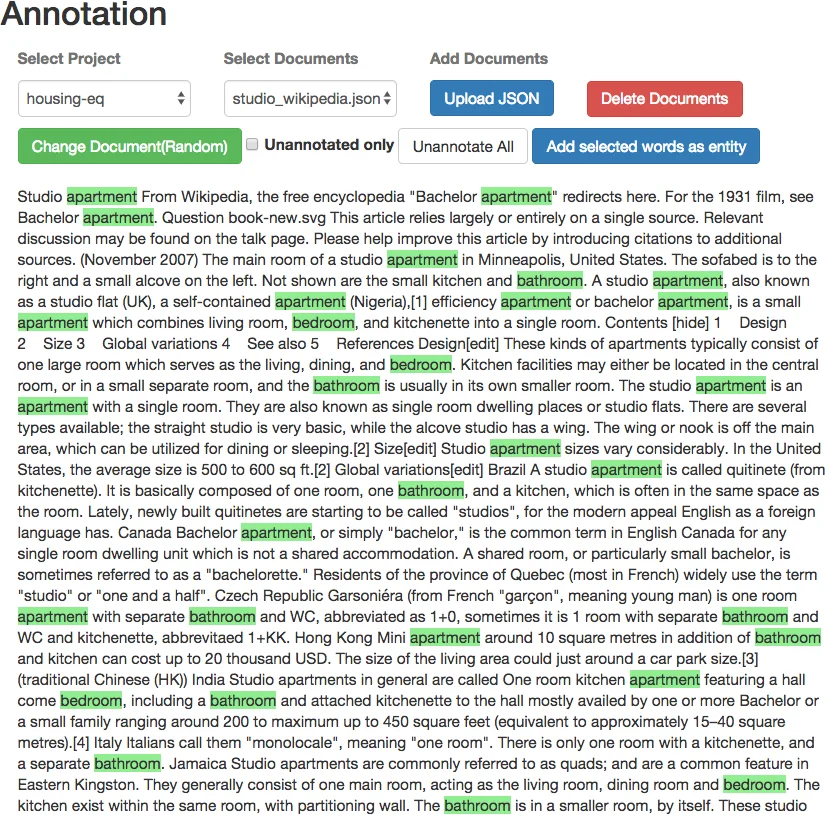
The interactive loop proceeds as follows: (1) the user uploads or manually creates an initial seed set; (2) the user triggers an expansion request, sending the positive seeds to the selected API; (3) the API returns a list of candidates, which appear in the Feedback table; (4) the user assigns positive (“+”) or negative (“–”) labels to each candidate, optionally inspecting the original seed that generated it to detect drift; (5) upon submitting feedback, LUWAK updates the Entity table with newly accepted entities; (6) the user can view the current dictionary highlighted in a sample document, providing immediate visual feedback on coverage; (7) steps 2‑6 are repeated until the dictionary reaches the desired size and quality; finally, the dictionary can be exported as a CSV file.
A concrete use case is presented for populating a housing‑equipment dictionary for a real‑estate search engine. Starting with roughly ten seed terms such as “kitchen” and “bath”, the system suggests related equipment like “dishwasher”, “shower head”, and “microwave”. Users iteratively accept relevant items, reject noise, and deactivate problematic seeds, thereby steering the expansion process and preventing semantic drift. The document‑highlighting feature shows how the growing dictionary matches actual property descriptions, allowing rapid quality assessment.
Compared with prior interactive entity‑population systems, LUWAK offers several distinct advantages. SPIED (Gupta & Manning, 2014) requires a large document collection and performs costly pattern matching on the server side, while also lacking fine‑grained user feedback in each iteration, making it prone to drift. IKE (Dalvi et al., 2016) focuses on relation‑extraction patterns and still depends on a server‑side setup. LUWAK, by contrast, is completely client‑side, corpus‑free, and requires only a web browser. Its modular API design encourages community contributions of new expansion methods, and its support for multiple expansion models (embedding‑based, category‑based, etc.) provides flexibility to adapt to different domains.
The authors argue that the reduction of total user workload—measured in installation effort, maintenance, and interaction steps—is the primary metric of success for an entity‑population tool. By offering an intuitive UI, immediate visual feedback, and the ability to edit the dictionary at any time, LUWAK aims to make domain‑specific entity dictionary creation accessible to a broad audience, including those without deep NLP expertise.
In conclusion, LUWAK demonstrates that a fully client‑side, installation‑free front‑end can effectively support interactive entity population. Its design principles—lightweight implementation, modular expansion APIs, and user‑centric feedback mechanisms—address the practical needs of industry practitioners who must quickly build high‑quality, domain‑specific entity dictionaries for downstream applications such as search, named‑entity recognition, and entity linking. Future work is suggested to integrate more sophisticated expansion algorithms (e.g., transformer‑based contextual embeddings), automatic drift detection, and real‑time collaborative editing to further enhance the system’s applicability.
Comments & Academic Discussion
Loading comments...
Leave a Comment