Familia: An Open-Source Toolkit for Industrial Topic Modeling
Familia is an open-source toolkit for pragmatic topic modeling in industry. Familia abstracts the utilities of topic modeling in industry as two paradigms: semantic representation and semantic matching. Efficient implementations of the two paradigms are made publicly available for the first time. Furthermore, we provide off-the-shelf topic models trained on large-scale industrial corpora, including Latent Dirichlet Allocation (LDA), SentenceLDA and Topical Word Embedding (TWE). We further describe typical applications which are successfully powered by topic modeling, in order to ease the confusions and difficulties of software engineers during topic model selection and utilization.
💡 Research Summary
The paper introduces Familia, an open‑source toolkit designed to bridge the gap between academic topic‑modeling research and real‑world industrial applications. The authors first identify two major obstacles that have limited the adoption of topic models in industry: (1) most research focuses on a handful of classic models such as PLSA and LDA, while implementations of newer models are rarely released, and (2) there is a lack of practical guidance on how to integrate topic‑model outputs into downstream systems. To address these issues, Familia provides two core utility paradigms—semantic representation and semantic matching—together with three pre‑trained models (LDA, SentenceLDA, and Topical Word Embedding, TWE) that have been trained on massive industrial corpora.
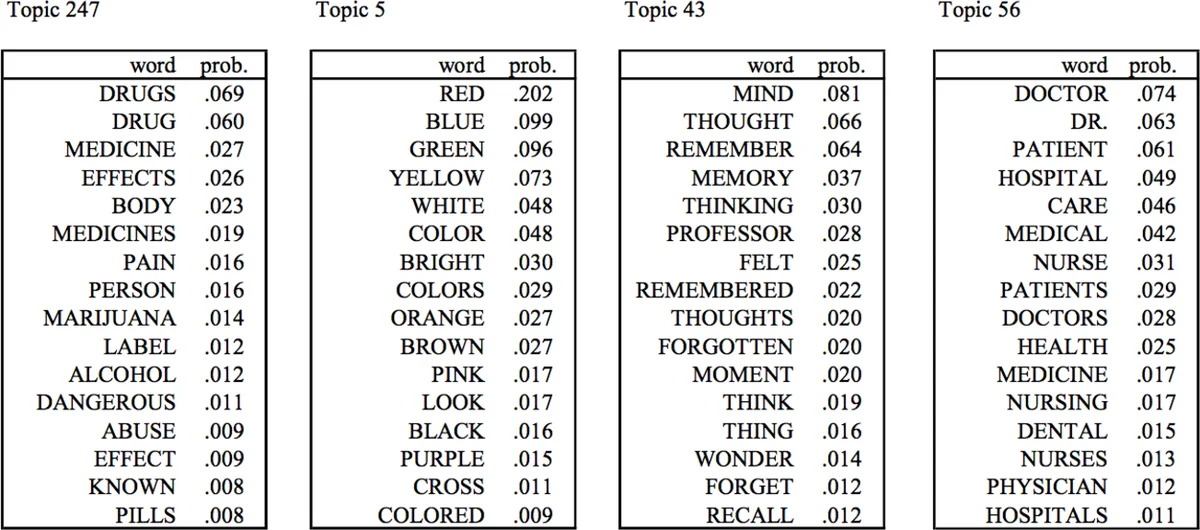
Semantic representation converts documents into topic‑distribution vectors or topic‑aware embeddings that can be used as features for other machine‑learning models. Familia offers two MCMC inference algorithms—Gibbs sampling and Metropolis‑Hastings—allowing users to trade off between accuracy and speed. It also supplies helper functions for nearest‑word queries, topic‑word lookups, and visualisation of model outputs.
Semantic matching covers three scenarios: short‑short, short‑long, and long‑long text similarity. For short‑short matching (e.g., query vs. title) the toolkit recommends embedding‑based similarity using Word2Vec or TWE with cosine similarity, while also pointing to deeper neural models such as DSSM and CLSM. For short‑long matching (e.g., query vs. document) Familia implements a probabilistic similarity measure that sums the likelihood of query words generated from the document’s topic distribution (Equation 3). For long‑long matching it provides distance metrics on topic distributions, namely Hellinger Distance and Jensen‑Shannon Divergence, to quantify semantic closeness.
The three bundled models each have distinct strengths. LDA is the classic bag‑of‑words topic model, suitable for large corpora but prone to high‑frequency word bias. SentenceLDA treats each sentence as a single topic, yielding finer‑grained topic assignments that work well for short, sentence‑level texts such as ad snippets. TWE augments word embeddings with LDA‑derived topic information, improving representations of low‑frequency words.
The authors illustrate the toolkit’s practicality through several industrial case studies:
-
Document Classification – Using 7 k manually labeled news articles, they augment handcrafted features with LDA topic vectors and train a Gradient Boosting Decision Tree (GBDT). The topic‑augmented model outperforms the baseline, demonstrating the value of topic features for classification.
-
Document Clustering – By converting 1 k news articles into LDA topic distributions and applying K‑means, they obtain coherent clusters (e.g., interior design vs. stock market), showing that topic vectors enable meaningful unsupervised grouping.
-
Information Richness Evaluation – They compute the entropy of a document’s topic distribution as a proxy for content richness. Higher entropy correlates with richer information and is used as a feature in ranking models for web retrieval.
-
Semantic Matching –
- Short‑short: Query “recommend good movies” vs. title “2016 good movies in China” are compared via TWE embeddings, achieving higher relevance than raw word overlap.
- Short‑long: In online advertising, each ad page’s textual fields are modeled with SentenceLDA; the probabilistic similarity (Eq. 3) between a user query and an ad is used as a ranking feature, improving click‑through rates.
- Keyword Extraction: Using TWE, they compute similarity between each word and the whole document (Eq. 4) to extract semantically meaningful keywords, outperforming TF‑IDF.
- Long‑long: For personalized news recommendation, a user’s recent reads are aggregated into a pseudo‑document; Hellinger Distance between this profile and incoming articles selects personalized feeds, yielding measurable performance gains. In fiction recommendation, they integrate Jensen‑Shannon Divergence between user and item topic distributions as a global feature in the SVDFeature matrix‑factorization framework, achieving higher Precision and NDCG.
Overall, Familia delivers a comprehensive, ready‑to‑use solution: open‑source code for inference, pre‑trained high‑quality models, and a suite of APIs for both representation and matching tasks. The paper emphasizes that the toolkit reduces engineering effort, accelerates experimentation, and provides concrete guidance for model selection. Limitations include a modest discussion of hyper‑parameter tuning and the absence of comparisons with newer neural topic models. Future work is suggested to incorporate such models as plug‑ins and to add automated parameter optimization tools, further solidifying Familia as a go‑to platform for industrial topic modeling.
Comments & Academic Discussion
Loading comments...
Leave a Comment