Fighting Sample Degeneracy and Impoverishment in Particle Filters: A Review of Intelligent Approaches
During the last two decades there has been a growing interest in Particle Filtering (PF). However, PF suffers from two long-standing problems that are referred to as sample degeneracy and impoverishment. We are investigating methods that are particul…
Authors: Tiancheng Li, Shudong Sun, Tariq P. Sattar
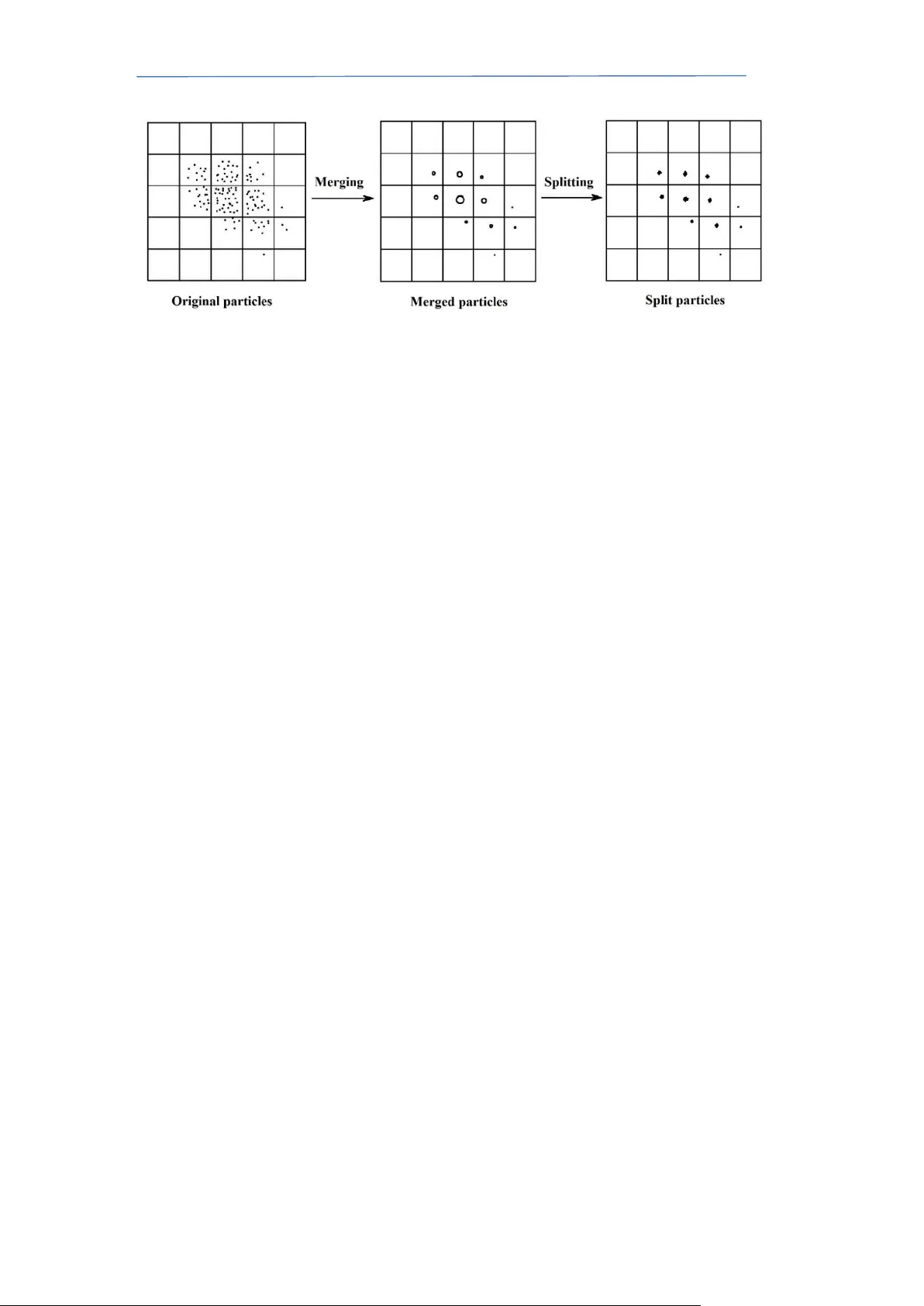
To appear o n “ Expert Systems With Applicatio ns ” , 20 14 1 Fight sample degeneracy and impoverishment in particle filters: A review of intelligent approaches Tiancheng Li T. Li is with the Sch ool of Mech atronics, Northwe stern Polytech nical University, Xi’an, 710072, China. (Cor responding autho r to prov ide e-mail: t.c.li@ mail.nwpu.edu.cn ; lit3@lsbu.ac.uk; Tel: +86(029) 884 9 4701) Shudong Sun S. Sun is with the Scho ol of Mech atronics, No rthwestern Poly technical Un iversity, Xi’an, 710072, China (e-m ail: sdsun@ nwpu.edu.cn) Tariq Pervez Sat tar T. P. Sattar is w ith the Cent er for Autom ated and Robo tics NDT, London S outh Bank University, London, SE1 0A A, UK (e-mail: sa ttartp@lsbu.ac.uk ) Juan Manuel Cor chado Bioinformatic, I ntelligent S ystems and Educational Technology (BI SITE) / Biomedical Research Institut e of Salamanca (IBSA L), University of Salam anca, Plaza de la M erced S/N, 37008, Salamanca, Sp ain (e-m ail: corchado@usal. es) Abstract — during the last tw o decades there ha s been a g rowing interest in Partic le Filtering (PF). However, PF suf fers f rom two long-standing problem s that are referred to as sample degeneracy and im poverishm ent. We are investigating methods that are p articularl y efficient at Particle Dist ribution Opti miz ation (PDO) to fight sam ple degeneracy and im poverishm ent, with an emphasis on i ntellig ence choices. These m ethods benefit from such meth ods as Markov Chain Mont e Carlo m ethods, Mean-shift alg orithm s, artificial inte lligence alg orithms (e.g., Particle Swa rm Optim ization, Gene tic Algorithm and Ant Colony Optim ization), machine learning approaches (e.g ., clustering, sp litting and m erging) and their hybrids, forming a coheren t standpoint to enhan ce the particle filter . The working m echanism, interrelationship, pros and cons of these approach es are provided. I n addition, App roaches that are effectiv e for dealing w ith high-dimensionali ty are reviewed. Wh ile improv ing the filter perform ance in terms of accur acy, robustn ess and conv ergence, it is noted th at advanced techniques employ ed in PF often ca uses additional com putation al req uirement that w ill in turn sacrifice improvem ent obtained in real life filte ring. This fact, hidden in pure sim ulations, deserves the atten tion of the use rs and designer s of new filte rs. Keywords — Part icle filter; sequent ial Monte Carlo; M arkov Chain Monte Carlo; impov erishment ; artific ial intelligence; machi ne learning To appear o n “ Expert Systems With Applicatio ns ” , 20 14 2 1. Introduction The Sequen tial Mo nte Carlo (SMC) approa ch allows inference of fu ll posterior distributions via Bayesian filtering in general nonlinear state-space models where the noises of the model can be non- Gaussi an. There has been grea t interest in applying the SMC approac h to deal with a wide variety of nonlinear f iltering problem s. This m ethod is normally called the Par ticle Filter(ing) (PF) [1], also referred to as Sequential imputations [2], the Monte Carlo filter [3], the Condensation filter [4], and the survival of fittest and the likelihood weighting algorithm [5]. To date, particle filters have been successfully applied in different areas including finance [6], paramete r estimation [7, 19], geophysical system s [8], wireless communica tion [9], decision making [10, 21], tracking and defense [11, 23, 31], robotics [12] and some nontrivial applications [ 18 , 19]. Additionally, a variety of strate gies have been proposed to improve the performance of the particle filter in terms of accuracy, converg ence, computational speed, etc. The staged survey of different years can be se en; exam ples include 2000[13], 2002 [ 14], 2007[15], 200 9[16], 2010 [17], e tc. Howev er, PF contin ues to suffer f rom two notorious problems: sample degenera cy and impoverishment, which is arguably a long-standing topic in the community. A variety of methods have been investigated to fight the se t wo problems in order to com bat the weakness of the particle filter. This study does not purport to give either a comprehensive review o f the development of general particle filte rs or its special applications. Both are covered in the aforementioned survey papers. Our aim is to investig ate a group of emerg ing ‘ intelligent ’ ways employed within PF that have benef ited from a variet y of intelligent and heurist ic algorithm s. These variations of techniques, ac ting in different ways to optimize the spatial distribution of particles namely Particle Distributi on Optim i zation (PDO), are particularly effec ti ve in alleviating sam pl e degeneracy and impoverishment, f orming a very systematic standpoint that is both mathem atically sound and practically efficient to enhance PF . I n addition, approaches that are effective in dealing with high- dimensional filtering, another obstacle for the SMC, are reviewed. This study aims to coordinate these developments in to a unifying framework, unveiling their To appear o n “ Expert Systems With Applicatio ns ” , 20 14 3 pros and cons and thereby directing further improvements of existing schemes. This survey is specifically expected to ser ve as the first comprehensiv e coverage of artificial intelligence a nd machine learning technique s applied in PF . The basic background of PF is pre sented in s ection 2 with em phasis on its two fu ndamental difficulties: sample degeneracy and impoverishment. These two difficulties have m otivated th e development of a v ariety of PDO approaches, which are reviewed in the categorie s identified in section 3. Furth er discussions on the PDO f ramework including the computation al efficiency and high dim ensionality challeng e are given in section 4. The conclusion i s given in sect ion 5. 2. Sample degenera cy and impove rishment Before we proceed, we provide a brie f r eview o f PF and define the notation. T he primary notations used are summ arized in Table I. Table I. Prim ary Notations The state of inter est at time t , the history pa th of the stat e Observation at tim e t , the history pa th of the observ ation the state trans ition equation at tim e t the observation equa tion at tim e t Noise affecting th e system dy na mic equation , at tim e t Noise affecting th e observation equa tion , at tim e t The state of particl e i , at tim e t The weight of pa rticle i , at tim e t The total num ber of particles at tim e t The delta-Dirac m ass located in x ( : , ) ab N Gaussian density with mea n a and covariance b , To appear o n “ Expert Systems With Applicatio ns ” , 20 14 4 K h (∙) A kernel function w ith bandwidth h Nonlinear f iltering is a class of signal process ing t hat widely exists in engineering, and is therefore a very broad re search topic. The solution of th e con tinuous time fi ltering problem ca n be represented as a ratio of two expectations of certain functions of the signal process. However, in practice, only the values of the observation corresponding to a discrete time par tition are available; the continuous-time dynamic system has to be converted into a discrete-time simulation model, e.g. di screte Markov System, by di scretely sampling t he outputs through discretization. T his paper is concerned with the prob lem of discrete filtering, which can be described in the St ate Space Mod el ( SS M) that consists of two equ ations: 11 , , (s ta te tr an si ti o n e qu at io n ) t t t t x g t x u (1) , , (o b se r v at io n e qu a tio n) t t t t y h t x v (2) The filtering problem rec ursively solving the marginal posterior density can be determined by the recursive Baye sian estimation , whi ch has two step s: (1) Prediction 1 1 1 1 1 n x t t t t t t t p x Y p x x p x Y dx (3) (2) Updating or co rrection 1 1 n x t t t t tt t t t t t p y x p x Y p x Y p y x p x Y dx (4) In ( 3 ) and ( 4), the integration of often unknown and maybe high-dimensional functions is required, which can be com putationally very difficult . This makes analytic optim al solutions such as the Kalm an filter intracta ble. One f lexible so lution is t he Monte Carlo app roach, as the topic of this paper, which uses random number generation t o compute integrals. That is, the integral, expr essed as an expecta tion of over the density , is approximat ed by a number of random variable s (cal led sam ples o r par ticles) that are drawn from the density (if possible), then To appear o n “ Expert Systems With Applicatio ns ” , 20 14 5 1 1 ˆ , N ii px s f f x p x d x f x f x x p x N (5) This is an unbiased estimate and, prov ided the variance of is finite, it has a variance which is proportional t o 1/ N . However, one limitation in applying Monte Carlo integration (5) in Bayesian inference ( 3) and (4) is that sampling directly from is di fficult, ev en impossible, if hig h dens ity r egions in do not m atch up with ar eas where it has a large m agnitude . A convenient so lution for thi s is the Importance S ampling (IS). A ssuming the density roughly appro ximates th e density (of inter est) , then ˆ qx p x p x f f x q x dx f x q x q x (6) This forms the basis of Monte Carlo IS which uses the weight sum of a set of samples fr om to approxim ate (6): 1 1 ˆ s S s s s px f f x S qx (7) An alternativ e formulation of IS is to use 11 ˆ ˆ / , i NN i i i i i ii px f I w f x w w qx (8) with the variance g iven by 2 2 () ˆ v ar i p f x p x f w d x f x qx (9) where is drawn f rom the proposal density . T he variance is minimized to zero if = [20, 24]. There are many potential choices for leading to various integration and optimization algorithms, as shown in the summary provided in [38]. In general, should have a relatively heavy tail so that it is ins ensitive to the outliers. In the importance sampling the estimator not only depends on t he values of but also on the entirely arbitrary choice of the proposal density . This results in heavy dependence To appear o n “ Expert Systems With Applicatio ns ” , 20 14 6 on i rrelevant information . This sampling difficulty seems inevitable as the density of interest i s g enerally always unk nown; therefore, i t is impossible to direct the sam pling. For this reason, some advanced important sampling methods have been proposed , such as annealed importance sampling [25], Bayesian importance sam pling [24], adaptive im portance sampling [34], numerically accelerated im portance sam pling [26], and nonparam etric importance sampling [22]. Alternative ly, sampling strategies such as rejec tion sampling [27], block sampling [28], Markov Cha in Monte Carlo (MCMC) sampling [37, 38] and factor ed sampling [4, 29] have also been used, in addition to ad -hoc strategies such as multiple stages of importan t sampling [35]. SMC samplers are specifically developed to sample sequentially from a sequence of p robability distributions that allows the calculation of a weight update equation for different proposal kernel [ 38 ]. To avoid an over ly broad discussion, th e r eader i s referred to the given references for further deta ils. The importance sampling implemented under the recursiv e Bayesian i nterferen ce is referred to as Sequential Importance Sampling (SIS), which is the basis of PF . Formally, the core i dea of PFs is t o capture t he statistics o f the st ate probability distribution by a set of random part icles with associated w eights, i.e. 1 t i t N i t t t t x i p x Y w x (10) 1 1 1 , i i i t t t t ii tt ii t t t p y x p x x ww q x x y ( 11 ) The weights wil l be normal ized to sum to one (for the one-state output case). Classical Monte Carlo pr ocedures entirely ignore t he st ate values of particles in the state space when form ing the estimate, see [24]. In the process of propagation, par ticles perform a step of Markov jump for prediction and then the approximation density need to be adjusted through re-weighting the particles. After a few iterations in the particle propagation process , the weig ht will concentrat e on a few particles only and most particles will have negligible weight, resulting i n nam ely sample de generacy, see [30]. This is an inherent default of the SIS. To address sample degeneracy, t he standard PF i s comm only accompanied with the resampling To appear o n “ Expert Systems With Applicatio ns ” , 20 14 7 procedure (referred to Sam pling-Importance Resampling, SIR or Sequential Importance Sampling and Resampling, SISR) to force particles to areas of high likelihood by multiplying high weighted particles while abandoning low weighted partic les. T his, however, may cause another problem : sample i mpoverishment, which occurs when very few particles h ave significant w eight while most other particles with sm all weight are abandon ed during the resampling process. To a lleviate this, it is possib le to balance the trade-off by applying resampling only at de terminis tic s teps; tha t is, to execute resam pl ing only when the v ariance of the non-normalized weights is superior t o a pre-specified threshold (which is taken as a signal of sample degeneracy). I n the general si ngle -target case, a simple estimation of the Eff ective Sample Size (ESS) criterion is g iven by 1 2 11 s.t. = 1 tt NN ii tt ii ES S w w (12) The ESS takes values between 1 and and the resampling is implemented only when it is below a threshold , e.g. , is the sam ple size at tim e t . Figure 1. Sample d egenerac y and impov er ishment illustrated in 1-dim ensional state space The relationship between degeneracy and impoverishm ent can be depi cted as shown in Figure 1 in which the size of the circles represents the weight of the particles ; in the bottom row, connected circles share the sam e st ate after generic resampling. I n the resampling process, only particles with si gnificant weight (shown i n green in Figure 1) are sampled, while other small weighted particles (shown in red) are aba ndoned. As shown therein, sample degeneracy To appear o n “ Expert Systems With Applicatio ns ” , 20 14 8 is apparent ly the resu lt of particles b ei ng distr ibuted too widely, while sam ple im poverish ment can be viewed as particles being over concentrated. The degeneracy converts to impov erishment as a direct result of resampling. If the resampling i s unb iased, then the more serious the degeneracy , the more serious the im poverishm ent . In more general t erms to remark on their r elativity , sam ple degeneracy and im poverishm ent are a pair o f contradiction s that c an be collectively described as a trade-off between the need of diversity and the need of focus in [32], as a problem in managing the spread of t he particle set i n t he st ate space to balance conflicting requirements i n [33], or in another perspe ctive, as the com put ing resource converging prem at urely either by weight o r by state in [30]. Sample degeneracy and impov erishment are arguably a pair of f undamenta l difficultie s of PFs, which manifests themselves as 'unsatisfactory' particle distribution. Quite intuitively, the solution t o m itigate th is pro blem is to optimiz e the distribution of particles either in adv ance or in hindsight. This form s the basis of our survey. In what follows, efforts devoted in this discipline are reviewed i n different categorizes t o illustrate the motivation, implementations and implications of PDO. T heir interrelationsh ips, pros, cons and high-dimensionality challenge are prov ided. 3. P ARTICLE DISTRIBUTION OPTIMIZATION To deal with sample degener acy and im poverishment, there are m ainly two kinds o f information abou t the weighted particles tha t can be ta ken into account w hen one optim ization operation is executed: we ight and state. The PDO appr oaches presented in this paper are especially interested in the st ate of particles. Compared to distribution smoothing methods, most approaches act in a more int elligent m anner and benefit from a variety of intelligent or heuristic techniques such as MCMC methods, Mean-shift algorithms, Artificial Intelligence (AI) algorithms e.g. Particle Swarm Optimization (PSO), Genetic Alg orithm (GA) and Ant Colony Optimization (ACO) a nd Machine Learning (ML) approaches e.g., clustering, splitting and merg ing, etc. They form a coherent p erspective to opt im ize the distribution of p articles. In g eneral term s , the m oving of particles c an be ‘ blind ’ (par ticle are moved without a To appear o n “ Expert Systems With Applicatio ns ” , 20 14 9 specific direction) or ‘ sighted ’ (particle s ar e m oved in a specific direction). In the latter case, new observ ations are used to direct the moving operation that can be referred to as data-dri ven methods, which is the main part of this study. In par ticular, various AI and ML optimiz ations for PF are special ly rev iewed. It is worth noting that, there i s g enerally no standard implem entation of each method; instead, one intelligen t technique can b e applied in many different ways within PF . I n this case, too m uch is as bad as too little. The study em phasizes the sim ilarity of all works in ord er to form the comm o n PDO principle, and it w ill not cover all of the possible implementations. T he primary PDO techniques that will be reviewed in this paper are ca tegorized as shown in Table II . I n each category , typical exam pl es will be g iven as an explanation if p ossible . The basic idea will be briefly in troduced first, and then the interrelationship and special a chievem ent s of different im plementatio ns are presented for further elaboration. Table II . Categories of prim ar y PDO approaches to re view PDO tool Typical PDO prope rty Primary referen ces Kernel smoothing Blind [41-45, 48] Data-driven method MCMC Sighted [16, 25, 33, 37, 40, 50- 52] Mean -shift Sighted [33, 53-56] AI algorithm s (Evolution and population) GA Blind [57-60, 71] PSO Sighted [63-66, 91] ACO Sighted [67-70] ML techniques Clustering Blind [53, 77-83] Merging/splitting Blind [36, 39, 76] Others scatter search process [61 , 72], support vector machines & s upport vector data description [29] , etc. To appear o n “ Expert Systems With Applicatio ns ” , 20 14 10 Hybrid PDO Evolution + clustering [77], artificial immune system + PSO [92], kernel mean-shift + annealed PF [33], artificial neural networks + genetic algorithm [89]. 3.1. Roughening, Kerne l smoothing and regularization Resampling, which is a type of re-selection and re-weighting of particles [84], i s originally adopted to force particles to areas of high likelihood from low l ikelihood areas. However, as early as resampling was fi rst proposed for PF in [42], its side effect (i.e. sample i mpov erishment) was apparen tly found to cause gaps between particles a nd accor dingly a solution calle d roughening was proposed t o smooth the posterior. Smoothness, here ac ting as the fitness, results in a continuous state probability distribution, which per mits a better distribution diversity of the p articles [15, 41]. The roughening procedure (the term s jittering [43], diffusing [ 72 ], diversifying [ 87 ] etc. are also use d) basically adds an independent Gaussian jitter noise with zero mean and constant covariance, say , to each re sampled particle. Suppose t hat the original posterior dens ity is denoted as . Since the addition of two independent random variables corresponds to a convolution operation in the density domain, the approxim ate posterior density obtained after th e roughening process can be f actored as [3 9] 0 : 0 : : 0 , , t t t t t t p x y x J p x y N (13) where denote s the conv olution ope ration, de fined as , ( ) ( ) ( ) f g x f u g x u du . Simply, if is Gaussian w ith mean and covariance , then 0: :, t t t t t t p x y x x J P N (14) In (14) we can see that, the roughening strategy may be implem ented more directly by increasing the simulation noise of the dynamic propagat ion of particles, called direct roughening [ 48]. Fu rthermore, in target track ing cases, roughening m ay be employed only i n selected steps, on partial particles and in partial dimensions [ 84]. It is also sugg ested to em pl oy To appear o n “ Expert Systems With Applicatio ns ” , 20 14 11 the observation noise t o scale the jitt ering strength so that jittering would not blur the position estimates out o f the range of th e observation. With regard to scattering the multiple copies of the same particles , r oughening is very equivalent to using a Gaussian kernel to smooth the posterior density. The basic principle of kernel smoothing is that local averaging or smoothing is performed with respect t o a kernel functio n. T o implement kernel smoothing mathematically, each particle is co nvolved with a diffusion kernel. The distribution i s given as fol lows 0: 1 t N ii t t h t t t i p x y w K x x (15) with the rescaled Kernel densi ty 1 h d x K x K hh (16) where t he bandwidth , is the dimensional ity. Under mild conditions ( must decrease with increasing ) the kernel estim ate converges in prob ability to the tru e density. The kernel and bandwidth a re chosen so as to minim ize the mean intergraded error or the m ean integrated square error betwe en the posterior distribution and the corresponding regularized weighted empirical m easure. Based on t he Kernel m ethod, the so -called regularization (of the em pirical distribution associated to the particles) t echnique calcula tes a continuous analytica l expres sion for t he particle probability distribution [14]. There are two different approxim ations called pre- regularized PF (pr e-RPF) and pos t-regularized PF (p ost-RPF), depend ing on whether the regularization step is taken before or after the correction step, see [44]. While the optimal kernel is intuitively appealing, and also satisfies an optimality criterion of some sort, it should be noted that it is possible to sample directly from such a kernel and to evaluate the w eight integral analytically only in sp ecific classes of m odel [15]. The selection of smoothing para meters ( e.g. kernel bandw idth or roughening v ariance) is customiz ed to spe cific prob lems and seem s easier than it is. For a special review of the kernel based PDF estimation algorithm s and their respective perfo rmance, th e reader is referred to [45]. To appear o n “ Expert Systems With Applicatio ns ” , 20 14 12 3.2. Data-driven m et hods Kernel smoothing is a straightforward albeit ' blind' way to rejuvenate the diversity o f particles to fight the sam ple degeneracy and impov erishment, in which no new information is employed. It is more reasonable to adjust the distribution of particles in a data-driven/' sighted' manner, e.g. move the particl e to a better position by using the newest observations , namely new-observ ation-driven m ethods as discussed below. The aim of new-observ ation-driven PDO m et hods is t o use t he newest observ ation, in which the particles tend t o cluster in regions where the conditional posterior distribution for the current state has a high probability mass. There are two well- known data-driven approaches to building better proposal den sity. One is the auxiliary v ariable method [46 ] which aug ments the e xisting “good” particles in t he sense that the predict ive likelihoods are large f or the “good” particles, which is quite sim ilar to t he prior editing proposed in [42]. The second approach uses the look- ahead strategies [47] or local perturbed sampling [49] to construct efficient proposal distributions. Both incorporate the information of the state dynamics and t he current observation to combat the blindness of SIS. Muc h of this content is well docum ented in literature and wi ll not be re peated here. We will now consider some of the more profound variants of the principles exposed so far for sam pling fr om the desi red dist ribution and/or im proving the diver sity of par ticles. They are Markov chain tra nsition, mean-shi ft and some arti ficial inte lligence alg orithms. MCMC : MCMC m ethods i ncluding rand om walk Monte Carlo are a class of algori thms for sampling fr om probabi lity distributions based on constructing a Markov Chain that has the desired distribut ion as its equilibrium distribution. Relying upon Mark ov kernels with appropriate invariant distributions, MCMC will gener ate collections of correlated sam ples. To cope with the sampling difficulty, since we wish particles to be drawn from , it seem s reasonable to design Markov chain t ransition kernels, having as the stationary distribution. As with other Monte Carlo methods, the empirical average taken over the sam ples is used to estim ate the expectation o f interes t. Un like sequen tial importance To appear o n “ Expert Systems With Applicatio ns ” , 20 14 13 sampling, the sam pl es f rom MCMC are ex act (dra wn from the desired distr ibution) and outstandingly , are free o f sample degeneracy and impov erishment, although the M CMC suffers from other disadvantages. One of them is that, MCMC methods cannot be used i n an online sequential Bay esian estimat ion context [38] . A s with IS , where a good importance function encour ages more sa mples to be drawn from high probabi lity r egions, MCMC random walks spend m ore time in regions of the parameter space with h igh probabiliti es, produc ing m ore samples from those areas. There are many well- kn own ways to achiev e this, includ ing the Metropolis-Hastings (MH) m et hods and Gibb s sampler [18]. Den oting inv ariant distribut ion and proposal distri bution , whi ch involves sampling a candidate value given the current value , the Markov chain then moves towards with acceptance p robability ** * * m in 1 , i i ii p x q x x A x x p x q x x (17) otherwise it remains at . In any case, t he algorithm will tend to favor samples that increase the likelihood ratio, however its stochastic nature allows it t o sometim es accept values that decrease th e likelihood ratio, al lowing it to escape local minima. In m athematics, the transitio n kernel for the MH a l gorithm i s () 1 1 1 1 MH i i i i i i i i i x K x x q x x A x x x r x (18) where is the term associated w ith rejection * * * 1 i i i r x q x x A x x dx (19) However, there are situatio ns where a very lar ge number of MCMC iterations would be required in order to reach t he target distribution, especially when the li kelihood for the new data point is far from t he points sampled from the importance distribution . To overcome this, a s eries of sm aller transition s is replaced by a single large tran sition in [50]; t he Monte Ca rlo v ariation of the i mportance weig hts is al so red uced there. Fu r therm ore, t he simulated annealing [25] can be used in MCMC for handling i solated modes and finding the To appear o n “ Expert Systems With Applicatio ns ” , 20 14 14 maximum of a com plex function with multiple peak s. Sim ulated annealing is very closely related to Metropolis sam pling (but does not require designing the propo sal di stribution in M H sampling), differi ng only in that the probab ility of a move is giv en by 1/ * * m in 1 , Tt i i px A x x px (20) where the function is called the cooling sched ule (setting = 1 recovers Me tropolis sampling). In fact, the simulated annealing strategy itself can be employed in PF , such as in [33, 56] which will be described later in detail. It is generally difficult to assess when the Markov chain, even the simulated annealing, has reached its stationary regime and on the contrary it can bec ome easily trapped i n local m odes. In spite of the successful employment of t he MCMC sampling to r eplace the i mportant sampling [37, 38, 50] , there are other ar eas where MCMC could benefit SMC, especially to rejuvenate the particle diversity ([51] for example) and i n t urn SMC can also benefit MCMC , typically such a s par ticle M CMC [52]. For exam ple, th e Resam pl e-Mov e algorithm that a dds a MCMC move step after the resampling step of the SMC algorithm forms a principled way to jitter the parti cle locations, and t hus reduce impov erishment [37]. I n addition to the Resam pl e- Move method, block sam pling is proposed; it aims to sample only component at time in regions of h igh probability mass (whil e the previously -sam pled values of the components sampled are simply discarded), and then use MCMC moves t o rejuvenate after a r esampling step [ 16, 28], where is the length of the lag. Both resample-m ove procedure and block sam pling are ofte n taken as correct ly weighted Mon te Carlo upd ating schem es . The MCMC transition which is naturally parallel processing can be employed to execute resampling which is the primary obstacle for parallelization of PF [40]. For the parallelization of the resam pling and PF , the reader is referred to [84] for a comprehensive review. We believe there will be more potential hybrid of MCMC and SMC for further benefits of both. Before proceeding to t he AI and ML categories, the following se ction will review another class of data- driven method for PD O, based on the Mean-shift algor ithm. To appear o n “ Expert Systems With Applicatio ns ” , 20 14 15 Mean-shift : Mean -shift is a gradient based i terative non-parameter opt imization method for locating the maxima of a density function given disc rete data sa mpled from that function. Given an initia l estim ate and a specified kernel function with bandw idth , the weig hted m ea n of the density is i i i i x N x i x N x xx Kx h mx xx K h (21) where is t he neighborhood of , a set of points f or which . In particular, is called mean shift. T he m ean -shift alg orithm recursively set as , and repeats the estimation until converges to . In this way, kernel m ean -shift hill climbs t owards the target, minim izing the dista nce between ta rget and m odel candida tes. Particles are redistributed (termed as herded in [53], moved in [54] and derived in [55] ) to their l ocal mode of t he posterior density (or observat ion) by similar m ean - shif t analysis in hybrid PFs [53, 54, 55]. For example, t he kernel PF (KPF) [54] i s similar to RP F in the sense that a kernel density estimate [44] is used to ap proximate the posterior PDF. Howev er, unlike RPF, which uses samples from the k ernel density esti mate to replace t he original particles, KPF estimates th e gradient of the kernel density and m o ves particles t oward the modes of the posterior by the m ean - shif t algorithm , leading to a m ore effective a llocation of par ticles. To summ ar ize, the Kernel m ean -shift can be viewed as an attempt t o cluste r spread particles with Kernel m ean - shif t; ho wever, if PF tends towards an incorrect local maxim um the m ean - shift step will accelerate the process. To m itigate this, the kernel m ean -Shift algorithm ca n be combined with th e Annealed PF rather th an with the b asic PF as in [33]. The annealed PF [56] uses annealing to smooth out th e evaluation function, making the g lobal maxim um clearer and allowing particles to spread further by incre asing t he process noise (i nspired by the roughenin g approach). T his will not be caught on local clutter since the m ean - shift component could pull particles back towards the true target. Th is meticulo us optimization of the distr ibution of To appear o n “ Expert Systems With Applicatio ns ” , 20 14 16 particle s shows, to a great extent, a type of ‘intellig ence’ , for which more direct solutions are presented in the fo llowing subsec tion. 3.3. AI Optim ization: Evolution and Populatio n As a natural combination of artificial intelligence and si ngle pr ocessing , the Evolution and Population optimization strategies rooted in AI algorithm s m ay be em ployed for PD O; this will be refer red to as AI PDO in this p aper. The evolutiona ry heuristics and population- b ased search solves complex op tim ization pro blems by maintain ing a population of candidate solut ions, and are feasible for obtaining efficient PDO. Ever si nce earlier attempts to use t he genetic algorithm filter were i ntroduced, there have b een m any efforts de voted to this task [57], the A nnealed PF [56] (also the annealed importance sam pling [25]) and the LS -N-I PS [49]. Recently, these emerging AI-PF h ybrid app roaches hav e been extensiv ely studied. In the following section, we review some re presentative studies t o consider their common characteristics in order to develop a profound understanding of AI PDO. The AI algorithms t hat will be reviewed include GA , PSO and ACO. We will put emphas is on how these artificial intelligent algorithm s work to optimize the dis tribution of par ticles to com bat sample deg eneracy and im poverishm ent. GA : GA is governed by the Schema Theorem , which was originally derived from bi nary string represen tation of the g enes of a chromosome withi n an individual. The Sche ma Theorem can be expressed a s follows , see also [60]. , 1 , 1 1 1 o є cm f є є m є tm є t p p fL (22) where is the number of schema at generation t , is t he averag e fitness of chromosom es having t he sam e schema, is the aver age fitness of the whole population, is the Crossover probability, is the length of a schema, is the chromosom e length, is the Mutation probab ility and is the order of a schem a. The popul ation of the GAs evolv es i n a competition for survival by dif ferent genetic operations including Selection , Crossover , and Mutation . GA is a Monte Carlo method. I n accordance with t he fitnes s values, the individuals are selected to undergo Crossover and To appear o n “ Expert Systems With Applicatio ns ” , 20 14 17 Mutation and search for an opt imal solution. Crossover pairs two individuals and mates them, and Mutation randomly alters t he selected individual. Genetic operators are use d in PF , either separately or in combination, to op timize t he positio n o f the particles by the gene tic operations ; they are used to deal with the situation in which most par ticles have coll apsed at a single (i.e. sample impov erishment) point. These have been partl y achieved since [57], and improved in different ways by [60], [71] and [58]. For an intuitiv e understanding, one evolutionary PF depicted in pseudo codes is given in [58] where a new form of the importance weight is deriv ed. To further avoid premature concentration of the particles, the search region of particles can be enlarged within GA [ 59]. PSO : I n the basic PSO alg orithm, a set of particles are generated randomly , and their positions (states) are i teratively updat ed according to their own experien ce and t he experience of t he swarm (or neighboring particles). The part icles are updated according to the following equations: 1 1 be st 1 2 gbe st 1 t t i t t v qv x x x x (23) 1 t t t x x v (24) where, i s the current iterati on step, is the flying speed of particles, is the particle’s location at which the best fitness has been achieved, the population global location (or local neighbor hood position , in a neighborhood version of the algorithm ) at which the best fitness so far has been achieved and , , are weight ing f actors. As a rule of thumb, the two random control factors , in equation (23) are typically drawn from the uniform distribution . A l arge inertia weight facilitates a global search w hile a small i nertia weight facilitates a local search. As a result, the follow ing linearly decreasing weighting function is usual ly utilized in (23 ) ma x m ax m in i q q q q I (25) where, is the initia l weight, is the final w eight, and i s m aximum iteration num ber. To appear o n “ Expert Systems With Applicatio ns ” , 20 14 18 By exploring the likelihood distribution of the recent observations, the PSO particle fl ying strategy can help PF to obtain samples with high l ikelihoods [63, 64, 65]. The PSO algorith m distributes the particles in high likelihood area , r egardless of the weight of particles in case of the dynamic model is unavailable. In addition, two dif ferent base points are used to distribute particles in order to a chiev e diversity and co nvergence in [63]. I t is ev en shown that in a Bayesian inference view the sequential PSO framework is a swarm-intelligence guided multilayer importance sampling strategy [65]. However, applying PSO direct ly to PF involves two problem s that have to be dealt with. One is the loss of particle diversity after the PSO procedure. To mitigate this, particles can be redistributed t o increase the diversit y af ter PSO [65]. The second problem is that a single swarm might not be enoug h due to the variation of the m axi mum likelihood po int. T o handle this, a mul ti -swarm m echanism maintaining multipl e trajectories for a possible target position has been added to the generic PSO algorithm for robust tracking in [66]. Unlike the evolutiona ry programming and evolutionary strategies in GA, PSO does not implem ent the principle of the survival of t he fittest, as there is no selection and crossover operation. T o enhance this, the p article flying strategy combined with the m ut ation operation is proposed in [91] for PDO. ACO : The ACO meta -heurist ic t hat i s initially proposed for solving co mbinator ial optimization problem s (COPs) can benefit PF for PDO as well, especially after it is defined in the co ntinuous dom ains ( ACO ) [69]. T he c entral component of ACO alg orithm s is the pheromone m odel, w hich is used to probabilistically sa mple t he search space. AC O attem pts to solve the problem by iterati ng two steps: Step 1: A num ber of artifi cial ants b uild soluti ons to th e problem by sampling a PD F which is derived from the pheromone information. In t he basic Ant Syst em (AS), t he i th ant mov es from state to state with probabi lity ** * ** ii i ii x x x x A x x x x x x (26) To appear o n “ Expert Systems With Applicatio ns ” , 20 14 19 where and are, r espectiv ely, the amount of pheromone deposited and t he desirability (heuristic value) associated with the state transition from state to state while are positive real parameters whose values determine the r elative importance of pheromone versus heu ristic info rmation. Step 2: The solutions are used to modify t he pheromone such that the probability to construct high quality solut ions is increased. This is ach ieved by increasing the phero mone lev els associated with chosen good sol ution by a certain value , and by decreasing all the pheromone values through pherom one evaporation * ** * 1 if 1 othe rwis e i ii ch i xx x x x x s xx (27) where is the pheromone evaporation co efficient. In addition to the above two steps, problem specific and/or centralized actions (Daemon actions) may be r equired [69]. ACO and ACO are incorporat ed into PF f or mov ing particles to their loca l highest posterior density function in [70], which is to say , towards the region of the state space with the new observation [ 68]. T he convergence result of ant stochastic decision based PF is presen ted in [67], in which each particle evolves in either of the two pr oposed ways to accomm odate model variations. Particles ar e then selected (r e-sam pling) according to ant empiricism acquired from av ailable observation. It is v ery interest ing to notice that A CO PDO works in a data- driven manner that is very si milar to the MCMC transition, m ean -shift, and the PSO PD O as well. They all appea r to have o bvious pa rticle moving cha racter, differing only in implem entation techniques and environments. However, there m ust be a balance point to optimize the particle distribution to avoid over-moving . T his is reflected in the proper parameter setting evolved, as ver ified in the PSO em bedded PF [66]. It should be noted that, very less evidence i s available to demonstrate the converg ence or even the optimality property of the se AI PD O st rategies reviewed so f ar within PF . T his is because rigorous convergence analysis is often infeasible for heuristic and intelligent To appear o n “ Expert Systems With Applicatio ns ” , 20 14 20 algorithms. Even so, one needs to be careful when applying i ntellig ent techn iques in PF otherwise the results may the exact opposite of what is desired. For this, reasonable parameter settings are critical to achiev e the maximum bene fit with the least side effects. This has been noticed i n [69] in which the pheromone evaporation was applied to avoid too rapid a convergence of the GA algori thm (here the convergence is loosely defined). Further extension of ev olution algorithm s, cal led co evolution based on the interaction be tween species [73], is an option to preserv e diversity w ithin the populat ion of evolution ary algorithm s. 3.4. ML Optim ization: clusterin g, merg ing and splitting The diversity of p articles and the est imated uncertainty of PFs are essentially manifested in the sp atial distribut ion ( density) of p articles, w hich is therefor e w orth considering for a djusting the sample si ze and m aint aining the di versity o f particles. A g eneral idea for s etting a n appropriate sample size is to choose a small number of particles (i .e. samples) if the density is focused on a small part of the state space, otherwise a large number of particl es should be chosen, see [ 75, 90]. Particles di stributed in the same partition of the state space ar e cons idered to provide the same contribution to the diversity of particles [30] , and more specifically, the Euclidean distance is used as a measur e of the diversi ty of particles [61 ]. For example, when the state uncertainty is high, particles will be decentral ized and distributed to a wider state space. When the state uncertainty is low, par ticles will be centralized and di stributed to a sm al l state sp ace. Based on this understand ing, the KLD ( Kullback – Leib ler Distance) -sampling approach [75] and KLD-resampling [90] determine t he required number of particles so that the KLD between sample- based maximum likelihood estimate (MLE) and the true posterior does not exceed a pre-specified error bound threshold by using the following equation 3 1 1 2 2 1 2 9 1 9 1 t k Nz kk (28) where, is the number of grids with support, and is the upper quantile of the standard normal distribution. The eq uation shows that the number of p articles is nearly proportional t o To appear o n “ Expert Systems With Applicatio ns ” , 20 14 21 the num ber of grid w ith sup port, whi ch is based on the grid-partitioning of t he s tate space. O ne case of grid par titioning in a 2- di mensional state s pace is shown in Figure 2. In what follows, we consider a new c lass of PD O techniques that benefit much from techniques such as clusteri ng , m erging and spl itting an d that need to handle the di mensionality of the state space. Unlike the AI PDO techniques, these approaches may not be data- driven or heuristic, but a re instead, a pparently , ad -hoc as they ar e tailored to their pa rticular app lications e.g. robot localization ( term ed as Monte Carlo Localiz ation, MCL) and t arget tracking, which are of relativ ely low dimensiona lity. Clustering is a na tural logic analysis based stati stic decision. By definition, cluster analysis or clustering is the assign m ent of a giv en set of data points into different g roups, or cl usters, based on some common properties of the points. The fact that spatially close pa rticles represent a similar state raises t he idea of clustering spatially close particles together to consider their common property. Clustering of particles is not only a means t o reduc e the sample size, but also a means to superv ise the tracking conv ergence, to m ai ntain the diversity of p articles (wit h the potenti al ability to solve special problem s such as t he kidnapped-robot problem , which refers to a situation where the robot is carried to an arbitrary locat ion and the tracking is completely lost) an d to extract m ulti-estim ates, etc. One probl em with MCL is t hat the plain bootstrap filte r som etimes i ncorrectly conv erges to a unimodal distribution that is unable to maintain m ultimodal distributions. T o solve this problem, spatially close p articles are clustered together; each cluster is considered t o be a hypothesis o f the true state and is independen tly pro cessed [79]. This al lows for the solution o f the kidnapped robot problem. Whil e each cluster possesses a probability t hat represents t he belief of the rob ot being at that loc ation, the cl uster with the hig hest probability w ould be used to de termine the robot ’ s location a t t hat instant in tim e. It shoul d be noted that both the filtering type and the clustering method are not specified and may be any advanced choice, such as the Uniform MCL [80], Sum- Of - Norms (SON) clustering [81]. The distribution of the particles provides an awareness about the degree of tr acking convergence [78] which is helpful to know t he progress of the localization in MCL. Based on To appear o n “ Expert Systems With Applicatio ns ” , 20 14 22 this, the particle clustering technique is used to guarantee t hat the estimates are feasible at all times and positions [82]. The dynamical nature of clusters can be used to gua rantee better coverage of the environm ent, allowing attention to be focused only where the probability to find the rea l robot is hig her [53, 77] . In addition, in t he m ul ti-object tracking case based on the SMC-PHD (probability hypothesis density) filter [ 83], estimates are often extracted by peak searching of the particle distribution via clustering ( k -m eans, Expected Maximum , etc.) albei t with its computational slowness and unreliabili ty. A m ore sophisticated implem entation of clustering allows more accurate and reliable est imate ext raction, especially for the case of group/extended targets [23]. In contrast to employing clustering within PF, PF can in turn serve for clustering [74]. Merging and Splitting : Like the clustering t echnique, the merging and splitting (M&S) techniques are also based on the spatial similarity of particles t o carry out PDO. They appear in v ariations based on different subjects: particles [36, 39] or particle clusters [76]. In the so- called particle M&S PF [36], different numbers of particles are used f or prediction and updating separately to c ircumvent the contradiction between the estimation accuracy ( the more pa rticles, the b etter accuracy ) and computational speed (the few er particles, the fas ter speed). This works under the premise that weight updating is more computationally expensive than the prediction step , in which the computing speed wil l be highly i mproved when the number of part icles for updating is reduced (by merging particles, s ee the left part of Fig. 2) wh ile the prediction robustness and es timation accuracy can still be well maintained with a bigger prediction number of particles (by spl itting particles , see the right part of Fig. 2 ). The merg ing and splitting in spirit execut e a k ind of thre shold-based resam pling [84] that can av oid the discardi ng of sm all- weighted particles. In addit ion, an appropriat e smoothing e.g. roughening applied on the split particles, will be fu rther helpful for th e diversity of particles. To appear o n “ Expert Systems With Applicatio ns ” , 20 14 23 Figure 2. Particle m er ging and spli tting illustrate d in 2-dim ensional state space Furthermore, by means of merging and splitting the formed clusters in t he Cluster PF, a dynamic clu stered PF i s pro posed in [76]. Many other machine learning algorithms such as the scatter search process are available to execute PDO for PF ; the implementation can al so be quite flexible see [61, 72]. To improve the speed o f the k ernel density estimators in the aforementioned kernel smoothing strategy, machine learning approaches such as support vector machines (SVMs) and the support vector data description ( SVDD) density estimation method [29] have been developed in PF . Despite tremendous ef fort, PDO based on mach ine l earning still has m uch room to develop, not only for the b enefit of bet ter particle di versity (convergence and robustness) and faster s peed, but also fo r improvin g estimation accuracy. 4. C OMPUTATIONAL E FFICIENCY , H IGH D IMENSIONALITY AND B EYOND We cannot expect to enumerate all the PDO effects not only because the literature is quite rich and will continually expand for some time to come, but also because it is hard to arrive at a rigorous defini tion of P DO that is sim ultaneously excl usive, exhaustive, s eparable and satisfying. To concentrate on a more coherent and intuitive understanding of PDO, less attention is placed on wel l-k nown work such as auxiliary v ariable m ethods [98], reg ularization methods [44, 99], d ecentralized and look-ahead PF [1 00]. The efforts we have reviewed so far allow a novel standpoint to improve PF that are particularly eff ective in dealing with sample degeneracy and impov erishment. In addi tion, the filtering reliability and convergence of PF m i ght be improved accordingly . It is necessary to note t hat, t he benefit of PDO techniques is generally problem- dependent and param et er-sensitive: To appear o n “ Expert Systems With Applicatio ns ” , 20 14 24 1) Each PDO t echnique may onl y work well on limited models, especially when it is initially designed for a sp ecific prob lem, e.g. tracking los t (kidnapped robo t) problem [79]. 2) The benefits highly depend on the parameter setting. For the problem-specified PDO techniques, a very different per formance may be achi eved under different problem models or different param eter setting . 3) The benefits are not i ndependent but instead highly interactively related to each other. e.g., to increase estim ation accuracy is o ften a ccompan ied w ith a decrease in computing speed. A more thorough discussion on the impact of computing speed to the estimation accuracy is given in the followi ng subsection. 4.1 Hybrid PDO and Computational e fficiency Instead of utilizing a single PDO technique, there are som e further hy brid appr oaches us ing two or m ore techniques to augm ent each othe r for hybri d optimiz ation. For exam ple, a method based on training artificial neural networks is introduced in [89] to implement the local sear ch in th e LS -N-I PS of [49]. Other hy brid PDO approach es include evolution along with cluste ring [77], artificial im mune system with PS O [92], and k ernel m ea n -shift alg orithm with the annealed PF [33], etc., to nam e a few. There are in fact other ideas involved with P DO that m ay not seem so obv ious. However, it is nec essary to note that approaches that are too com plex may suffer f rom high computational burden that can heavily sacrifice the estimation quality in practice, although there does not appear to be anything wrong in sim ulations . This is because a complex filter design often accompanies a slow ed -dow n sampling speed, which indicates a longer iteration period and heav ier interval noise ( e.g. the state transition noise). The increased noise can in turn sacrifice the performance of the filt er. T he good perform ance of complex filters, reported in many of t he PDO strategies when using the same dynamic noise in the si mulatio n, is highly suspicious. If the f iltering speed is considered in pr actice, their improvem ents may not be obtained at all. T his fact is ov erlooked in pure si mulations wher e the simulati on noise is constant r egardless of th e fi ltering speed . In fact, both theoretical and practica l evi dences sh ow To appear o n “ Expert Systems With Applicatio ns ” , 20 14 25 that choices t hat seem to be intuitively correct may lead to performances even worse than that of the plain bootstrap filter, see [62, 97]. This reminds us that tho rough attention should be paid to the design and evaluation of a n ew filter, otherw ise it may be overstated. For fair evaluatio n and comparison in simulations, the state transition noise should be simulated according to the sampling speed of each filter which is no easy task. This is elaborated in detail in [101] . For this reason, a traditional simulation comparison of different PDO approaches does not form part of our review. 4.2 High-dimensionality It has been shown in [ 102- 105 ] that, accor ding t o ( 8), the standard Monte Carl o error satisfies | | 1 ˆ su p E| ( ) ( )| tt f C ff N (29) where N is the number of particles, is the empirical measure f unction, the constant C typically does not depend o n tim e t but m ust be exp onential i n the d imension o f the state sp ace of t he underlying model. The exponential growth i n the number of particles for increasing dimensions (known a s the cure- of -dimensionality , see t he evidence provided i n [1 02 ]) is one o f the biggest challenges for PDO, as well as one of the primary obstacles for the applica tion of PF . It has been widely recognized t hat Monte Carlo m ethods may fail in large scale systems [88, 105], especially in geoscie nces [8, 106, 107] which could have one million or even more space – tim e dimensions. The stress for PDO application to high dimensiona l systems is laid on space partitioning, indexing and searching of particles in the state space. To release this stress, advanced techniques and solutions can be roughly catalogued as follows: 1) reduce the performing dimensionality by functi onally similar techniqu es such as Rao – Blackwellisation (RB) [108, 47, 93], decentraliz ation [109], subspace hierarchy [110, 85], partitioned sampling [111] , etc., 2) design heuristics procedures [72] suitable for high dimensional state space or curse-of- dimensionality- free operators [ 107], etc., 3) avoid the problem by e mploying more sa tisfied sampling of each particle t o a llow a sm al l n umber of p articles [10 6, 112] or by parallel To appear o n “ Expert Systems With Applicatio ns ” , 20 14 26 computing [95]. We only provide brief introductio ns to each of these i n the following paragraphs ; fo r further det ails, reade rs are referred to the refe rences prov ided . The RB [108] approach partitions the state vector so that the Kalman filter is used for the part of the state space model that is taken as linear, while PF is used for the other part. For example, the s tate vector in the inertial navig ation can have as m any as 27 states, and here, th e Kalman fi lter can be used for the 24 states, whereas PF is applied to the 3-D position state [ 17]. In order to remove the l inear dependence using Kalman filter, the Decentralized PF (DPF) [109 ] splits the filtering problem into two nested sub-problem s, and then hand les the t wo nested sub- problems using PFs, which differs from RB in that the distribu tion of the second group of va riables is also approximated by a conditiona l PF . Furthe rmore, t he state space may be partitioned into more subspaces and run PF separately in each subspace [85]. Similarly, splitting the state space to reduce the important sampling dimension [88, 30], ext racting hierarchical subspace to filter separately [110], partitioned sampling based on hierarchical search [1 11 ], and running SMC samplers in p arallel in different regions of the state s pace w ith further poss ibility to interact with each other [113], are all similar and can be classified i nto the computationally efficient techn ique partitioning and paralle lization to alleviate the b urden of d imensionality in the high- dimensional searc h space as the terminologies suggest. It has been argued that it i s often po ssible, a t least in principle , to develop a local particle f iltering algorithm w hose approximation er ror is dim ension-free [104]. On the other hand, efforts have been devoted t o reinforce the use of each particle and t hus to reduce the total num ber of particles required. A better proposal density using t he so -called "nudging" method (f uture observations are employed in the proposal density to draw particles toward the obse rvations) is explored , allowing the part icles to know wher e t he observations are in order to reduce the required number of particles [106]. Furthermore, Path Relinking (PR) and scatter search are evolutionary meta-heuristics that have been success fully applied to PF for high dimensional estimation problems, see [72]. The Smolyak oper ator underlying the sparse grids approach, which frees global approxim ation f rom the curse of dim ensionality, is proposed for multivariate integration in [107] . These can afford m ore flexibility to PF for To appear o n “ Expert Systems With Applicatio ns ” , 20 14 27 dealing with high dimensionality, espec ially in the cas e that only a small num ber of particles are allowed or preferred. Multiple ‘Stochastic Meta - Descent’ tracker are developed as ‘smart particles ’ to track high -dimensional articulated structures with far f ewer particles [114 ]. The box particle [115] occupies a sm all and controllable rectangular region hav ing a non -zero volum e i n the state space w hich reduc es the com putational complexity and is suitable for solving high dimensional problems. Clearly, approaches that are effective for sample optimization i n the state space of e ither low di mensiona lity or h i gh dimensionality are all wo rth considering. As stated already, the resulting sam pling speed of the filter should be taken int o account. 5. Conclusions This paper has rev iewed a seri es of intelligent efforts that have b een made on o ptim izing the distribution of particles in their propag ation process in the particle filter. These efforts are particularly efficient for present ing or alleviating sa mple degeneracy and impov erishment. The survey emphasizes t he similarity, interrelationships, pros and cons of these appro aches rather than p rovide details on the variety of applications of each algorithm. An understan ding of PDO was develo ped by cons idering all algor ithms and techn iques that s hare the sam e ch aracteristics within a well- f ounded perspective, prov iding a syst ematic and co herent standpoin t to study PF and allowing further improvements to be made. Some i ssues were not discussed including the rigorous reliabi lity and con vergence proper ty of the P DO approach. Finding more effective solution s for PDO in high dimensional problems remains , undoubtedly , an active and cha llenging topic in which there is s till m uch more to do, especi ally in cas es where only a small num ber of par ticles are allowed. For example, t he new ly appearing Cubature method [116] and quantum filtering [86] m ay ha ve a potential benefit for PF . If high dimensionality is inevitable, the use of r eal-tim e techniques like parallel pro cessing and ad-ho c techniques related to ha rdware improvem ent is suggest ed. Ev en, alternatives to the SI R such as MCMC are consider able. To appear o n “ Expert Systems With Applicatio ns ” , 20 14 28 We have noticed that most of advanced techniques used to enhanc e PF do not work for all cases but are problem- dependent and param eter-sensitive. In particular, t he increased computational cos t due to complex algorithm design may sacrifice performance qu ality in real life estim ation, which i s often overlook ed in a pu re simulation that u ses constant p aram eters f or all filte rs. As a r esult , the si mulation outcom e is not i ntended to represent the outcom e of a rea l life situation. T his deserves the attention of t he users and designers of new discret e filters, not only PF . To overcome th e gap bet ween simulation and real l ife pr actice, a c ritical s tep involved is to s etup the s imulation m odel with re spect to the computing speed of d ifferent filters . This i s the key point to seamlessly connec t simulat ion and reality and requires an urgent solution. A CKNOWLEDGMENT This work was supp orted i n part by the N ational Natural Sc ience Foundation of China (Grant No.51075337; Gr ant No. 71271170 ) and the 111 P roject (Gran t No. B13044). R EFERENCES [1] Del Mor al, P. (1996). Nonlinear filtering: interacting parti cle solution. Markov Process, Rela ted Fields , 2 , 555 – 579 . [2] L iu, J. & Chen, R. (1995) . Blind deconvolution via sequenti al imputations . J. Ro y. Statist. So c. Ser. B , 430 , 567 – 576. [3] Kitagawa, G. (1996). Monte-Carlo filter a nd smoother fo r non- Gaussian n onlinear state s pace models. J. Compu t. Graph. Statist. , 1 ,1 – 25 . [4] Isard, M. & B lake, A. (1998). CONDENSATION – conditional den sity pr opagation for visual tracking. Internation al Journal of Compu ter Vision , 29 (1), 5 – 28 . [5] Kanazawa, K. , Koller, D. & Russel, S. (1995). Stochastic simulation algorithms for dynamic probabilistic networks . Proc. 11 th Conf. UAI, 1995, 346 – 351 . [6] L opes, H. F. & Tsa y, R. S. (2 011). Particle Filters and Bayesian Inference in Fina ncial Econo metrics. Journal o f Forecasting , 3 0, 168 – 209 . [7] Kantas, N. , Doucet, A. , Singh, S. S. & Maciejo wski, J. M. (2009). An overview of sequential Monte Carlo methods for parameter esti mation in general state - space models. Engin eering , 44 (Ml), 774- 785 . [8] Van L eeuwen, P. J. (2009). Particle filtering in geoph ysical systems. Mon thly Weather Rev iew , 137 (12) , 4089 – 4114. [9] Djuric, P. M. , Kotecha, J. H. , Zhang, J., Huan g, Y., Ghirmai, T. , B ugallo, M. F. & Migu ez, J. (2003) . Particle filtering. I EEE signa l processing magazine , 20 (5), 19 – 38 . To appear o n “ Expert Systems With Applicatio ns ” , 20 14 29 [10] Kostanjčar, Z. , Jeren, B. & Cero vec, J. (2009). P article Filters in Decision Making P roblems under Uncertainty. AU TOMATIKA: Journal for Control, Measurement, Electronics, Computi ng a nd Communication s , 50 (3 – 4), 245 - 251 . [11] Ristic, B. , Arula mpalam, S. & Gordo n, N. (2004) . Beyond the Kal man Filter: Particle Filters for Tracking Applications, Artech House . [12] Thrun, S. (2002) Particle Filters in Robotics. In P roc . the 18th Annual Conference on Un certainty in AI (UAI), Edmonton, Canada, 51 1 - 518 . [13] Doucet, A., Godsill S. & Andrieu, C. (20 00). On sequential Monte Car lo sampling methods for Bayesian filtering. Statistics an d Computing , 10, 197- 208 . [14] Arulampalam, M. S., Maskell , S. , Gordon, N. & Clapp, T. (20 02). A tutorial on par ticle filters for online nonlinear/non- Gaussian Bayesia n tracking. IEEE Transa ctions on Signal P rocessing , 50 (2) , 174 – 1 88 . [15] Cappé , O. , Godsill, S. J., Moulines, E. (2007). An overvie w o f existin g m e thods and recent ad vances in sequential Monte Carlo . Proce edings of th e IEEE , 95 (5), 899 – 924 . [16] Doucet, A. & Johanse n, A. M . (200 9). A t utorial on particle filtering a nd smoothing: Fif teen years later. In: Handbo ok of Nonlinear Filteri ng, E. D. Crisan, B . Rozovsky, E d. Oxford: Oxford University Press. [17] Gustafsson, F. (2 010). Particle filter theor y and practice with positionin g app lications . IEEE Aerospace an d Electronic Systems Maga zine , 25 (7) , 53 – 81 . [18] Johansen, A. M . (2 006). Some Non-Standard Sequential Monte Carlo Methods a nd Their Applications [PhD thesis], U niversity of Cambridge, Cambrid ge, UK . [19] Andrieu, C. , Do ucet, A. , Singh, S. S. & Tad ic, V. (2004). Particle Method s for Change Dete ction, System Identification, a nd Control. Proceeding s of the IEEE , 92(3) , 423 - 438 . [20] Doucet, A., de Freitas, N. & Go rdon, N. (2001 ). Sequential Monte Carlo Methods in Practice, Springer, New York, NY, US A. [21] Caesarendra, W. , Niu, G. & Yang, B. -S. (20 10). Machine condition p rognosis based on sequential Monte Carlo method . Expert S ystems with Applica tions , 37(3 ), 2412 – 2420. [22] Neddermeyer, J. C. (20 11). Nonparametric particle filtering and smoothing with quasi-Mo nte Carlo sampling. Jou rnal of Statistical Compu tation and S imulation , 81 (11) , 1361-1379. [23] Mihaylova, L., Car mi, A.Y., Septier, F., Gnin g, A., Pang, S. K. & Go dsill, S . ( 2014), Overview of Bayesian seque ntial Monte Carlo methods for group and extended o bject tracking. Digital S ignal Processing , http://dx.doi.o rg/10.1 016/j.dsp.2013.11 .006. [24] Rasmussen, C. E. & G hahramani, Z. (2003). Bayesian Monte Carlo. In: Adv. Neural Inf orm. Process. Syst. 15, Ca mbridge, MA: MIT P ress. [25] Radford, M. N. (2001). Annealed importance sa mpling . Statistics and Computing , 11(2), 125 – 139. [26] Koopman, S. J. , Lucas, A. & Schart h, M. (2011 ). Numerically accelerated importa nce sampling for nonlinear n on -Gaussian state spac e models. Available at SSRN: http://ssrn.co m/abstract=1 790472 [27] Gilks, W. R. Richardson, S. & Spiegelhalter, D. J. (1996) Ma rkov C hain Monte Carlo in practice. London, U.K.: Chap man & Hall . To appear o n “ Expert Systems With Applicatio ns ” , 20 14 30 [28] Doucet, A. Br iers, M. & Sé né cal, S. (200 6). Ef ficient block sampling strate gies f or sequential Monte Carlo. Journ al of Computational a nd Graphical Statistics , 15 (3) , 693 – 711 . [29] Banerjee, A. & Burlina, P. (2010). Efficient particle filtering via sparse Ker nel density esti mation. IEEE Transaction s on Image Processing , 1 9 (9), 248 0 – 2490. [30] Li, T. Sattar, T . P. & Su n, S. (2 012). Deterministic r esampling: unbiased sa mpling to avoi d sample impoverishment in p article filter s. Signa l Processing , 92(7), 1637 -1645. [31] Yin, M. , Zh ang, J., Sun, H. & Gu, W. (2011) Multi- cue- based CamShift guided particle filter tracking. Expert System s with App lications , 38(5), 6313 – 6318. [32] Liu, J. , Chen, R. & Logvine nko, T. (2 001) A theo retical framew ork for sequential importance sampling and resampling . In [ 20 ] pp. 225 – 246 . [33] Naeem, A. , P ridmore, T. & Mills, S. ( 2007). Managing p article spread via hybrid particle filter / Kernel mean shift trac king. Pr oceedings of the British Mach ine Vision Confere nce . [34] Liu, J. & West, M. (2001). C ombined para meter and state estimation in si mulation base d filtering. In [ 20 ], Chapter 10 . [35] Li, Y., Ai, H., Yamashita, T ., Lao, S. & Ka wade, M. (2008). Tracking in low frame rate v ideo: A cascade p article filter with di scriminative o bservers o f diff erent li fe spans. IEEE Transa ctions on Pattern Analysis an d Machine Intelligence , 30 (10) , 1728-1740 . [36] Li, T. , Sun, S. & Duan, J. (2010 ) Monte Carlo localization for mobile ro bot using adap tive p article merging and splitting technique. In: 2010 IEEE Internat ional Conference on Information and Automation, Harbin, C hina, 1913 – 1918. [37] Gilks, W. R. & Berzuini, C. (200 1). “ Following a moving target -Monte Carlo inf erence for d ynamic Bayesian models,” J. R. Statist Soc. B , 63, part 1, pp. 127 -146. [38] Del Moral, P, Doucet, A & Jasra, A. (2006) Sequential Monte Carlo Samplers, Journal of the Royal Statistical Society : Series B ( Statistical Methodolo gy ), 68 (3), 411 – 436. [39] Orguner, U. & Gustaf sson, F. (20 08). Risk-sensitive particle filters for mitigating sample impoverishment. IEEE Transaction s on Signal P rocessing , 56 (10) , 5001 – 5012. [40] Murray, L. (2012). GPU acceleration of th e par ticle f ilter: the Metropolis resampler . [online] arXiv:1202.6163 v1 [stat.CO] 28 Feb 2012. [41] Martí , E. , Garcí a, J. , Molina , J. M. (2011). Neighborho od-based r egularization of proposal distribution for improving r esampling q uality in p ar ticle filters. In: P roc. 14 th International Conference on Information F usion, Chicago, US A, 1 -8. [42] Gordon, N. , Salmond, D. & S mith, A. (1 993) novel approach to nonlinear/non -Gaussian Bayesian state estimation. I EE Proc. F Rada r Signal Process ., 140 ( 2), 107 -113. [43] Thomas, F. & Neil, S. (2009) . Learning and filteri ng via simulation: smoothl y jittered par ticle filters. ReCALL , 1 – 27 . [44] Musso, C. , Oudj ane, N. & Legland, F. (2001) Improving regularized particle filters. In [ 20 ], pp. 247 – 272 . [45] Freund, D. , Burlina, P. , Banerjee, A . & Justin, E. (2009). Comparison of Kernel based PDF estimation methods . In: Pro ceedings of the SPIE, 7335 , 8 – 14 . To appear o n “ Expert Systems With Applicatio ns ” , 20 14 31 [46] Pitt, M. K., Sh ephard, N. (1999) Filtering via s imulation: Auxiliary particle filter. Journal of American Statistical A ssociation , 94 , 590 – 599. [47] Freitas, N. de , Dearden, R. , Hutter, F. , Morales-Mené ndez, R. , Mu tch, J. & Poole, D. (2004) Diagnosis by a waiter and a Mars explorer . Pro c. of the IEEE , 9 2(3), 455 -468. [48] Li, T. , Sattar, T . P ., Han Q. & Sun, S. (2 013) . Rough ening methods to prevent sample impoverishment in the par ticle PHD filter, FUSION 20 13 , Istanbul Turkey, 9 -12 July. [49] Torma, P. & Szepesvá ri, C. (2 001) . LS -N-IP S: an improvement of particle filters b y means of local search . I n Proc. No n-Linear Control Syste ms (NOLCOS'01) St. P etersburg, Russia. [50] Godsill, S. J . & Clapp. T. (2 001). Improvement strategie s for Mo nte Carlo particle filters . In [ 20 ], pp. 139 – 158 . [51] Chopin. N. (2002) A sequential particle filter method for static models. Biometrika , 89:539 – 552. [52] Andrieu, C. , Do ucet, A. & H olenstein, R. (2010). Particle Markov c hain Mo nte Carlo methods . J. R. Statist. Soc. B , 72, 2 69 – 342. [53] Shan, C. , Wei, Y. & Ojardias, F. (2004). Real time ha nd tracking b y combining particle filtering and mean shift. In : Proceedings of the sixth IEEE Internat ional Conf. on Automatic Face a nd Gesture Recognition, 669 – 674. [54] Chang, C. & Ansari, R. (2 005). Kernel p article filter for visual tracking. IEEE S ignal Pro cessing Letters , 12(3 ), 242 – 245 . [55] Maggio, E. & Cavallaro, A. (2 005). Hybrid particle filter and m ea n shift tracker with adaptive transition model. I n: P roceedings of IEEE International Conference o n Acoustics, Spe ech, and Signal Processing (IC ASSP '05), 2 . 221 – 224. [56] Deutscher, J. , B lake, A. & Reid, I. ( 2000). Articulated bo dy motion ca pture by anneale d particle filtering . I n: Proc. IEEE Conf. Comp. Vis. Pattern Reco g. , 2, 126 – 133. [57] Higuchi, T . (199 6). Genetic algorithm a nd Monte Carlo filter . Proc. Inst. S tatist. Math . , 44 (1) 19 – 30 . [58] Park, S. , Hw a ng, J. P., Kim, E. & Kang, H. (2009) A ne w evolutio nary p article filter for the prevention of sample i mpoverishment . IEEE Transactio ns on Sig nal Processing , 13 (4) , 801 – 809. [59] Kootstra, G. & d e Boer, B. (2009) T ackling the pr emature convergence prob lem i n Monte -Carlo localization . Robo tics and Autonomou s Systems, 57 (11), 1107 – 1118. [60] Kwok, N. M., Gu, F. & Zhou, W. (2005). Evolutionar y particle filter: re -sampli ng from t he genetic algorithm perspective, 2005 IEEE/RSJ International Conference on I ntelligent Robots and Systems, (IROS 2005) . 2935 – 294 0. [61] Pantrigo, J. J ., Sá nchez, A. , Monte mayor, A. S. & Duarte, A. (2008). Multi-dimensional visual tracking using scatter search p article filter . Pattern R ecognition Letters , 29 , 1160 – 11 74. [62] Cornebise, J. , Moulines, É. & Olsson, J. (2008) . Adaptive m et hods f or sequential im portance sampling with app lication to state spac e models. Stat. Comp ut. , 18 (4) , 461 – 480. [63] Zhao, J. & Li, Z. (2010). Particle filter based on par ticle warm opti mization r esampling for vision tracking. Expert System s with Application s , 37 ( 12 ), 8910- 8914. To appear o n “ Expert Systems With Applicatio ns ” , 20 14 32 [64] Tong, G. , Fang, Z. & Xu, X. (2006). A particle swarm optimized particle filter for nonlinear system state estimation. In: P roc. IEEE Congress o n Evolutionar y Computation, Vancouver, Canada, 438 – 442 . [65] Zhang, X. , Hu, W. , Maybank, S. , L i, X. & Zhu, M. (2008). Sequen tial Particle Swarm Optimization for Visual Tracking. Computer Vision and Pattern Recognition (CVPR 2008), Anchorage AK, 1 – 8. [66] Lee, H. S. & Lee, K. M. (2 011). Mutiswarm particle filter for ro bust tracking under observation ambiguity. 17th Korea -Japan Jo int Workshop on Frontier s of Computer Vision (F CV 2011), 1 – 6. [67] Xu, B. , Zhu , J. & Xu, H. (2010). An a nt stochastic decision based particle fi lter and its convergence . Signal Pro cessing , 90 , 2731 – 2748 . [68] Yu, Y. & Zh eng, X. (2011). Particle filter w it h ant colony optimization for frequency off set estimation in OFDM s ystems with u nknown noise distributio n. S ignal Processing , 91 (3), 1339 – 1342 . [69] Socha, K. & Dorigo, M. (2008). Ant co lony opti mization for continuous domains . Eu r. J. Oper. Res. , 185 , 1155 – 1173 . [70] Zhong, J. & Fung, Y. -F. (2012). Case study and proofs of ant colony optimisation improved particle filter algorithm. I ET Control Th eory and App lications, 6 (5), 689 – 697 . [71] Uosaki, K. , Kimura, Y. & Hatanaka, T. (2004). Nonlinear State Estimation b y Evolution S trategies based Par ticle Filters. Proc. Congress on Evo lutionary Computa tion , 1 , 884 – 890. [72] Pantrigo, J . J., Sá nchez, A. & Montemayor , A. S. (2005) . Combining particle filter and po pulation - based metaheuristics for visual articulated motion tracki ng. Electronic Letters on Comp uter Vision and Image Analysis , 5 (3), 68 – 83. [73] Luo, R. , Hong, B. & Li, M. (2005) . Coevolution B ased Adaptive Monte C arlo Localization . Cutting Edge Robotics , 279 – 290 . [74] Schubert, J. & Sidenbladh, H. (2005) . Sequential clustering with particle filters -Estimating the number of clusters from data. In: Proc. 8th International Conference o n I nformation Fusion (FUSION 2005 ), 1 – 8 . [75] Fox, D. (2 003). Adapting the sample size in particle filters through KLD - sa mpling. The Internationa l Journal of Robotics Research, 22 (1 2), 985 – 1003. [76] Liu, Z. , Shi, Z. , Zhao, M. & Xu, W. ( 2008). Adaptive Dynamic Clustered Particle Filtering for Mobile Robo ts Global Localization. J. Intell. Ro bot Syst., 53 , 57 – 85 . [77] Gasparri, A. , Panzieri, S. , Pascucci, F. & Uli vi, G. (2 006). Mo nte Carlo Filter in Mo bile Robotics Localization: A C lustered Evolutionar y P oint of View . Jou rnal of Intelligen t & Ro botic Systems , 47 (2), 155 – 174 . [78] Wu, D. , C hen, J. & Wa ng, Y. (2009). Bring Consciousness to Mobile Robot Being Localized. In: Proceedings of the 2009 IEEE International Confere nce on Robo tics and Bio mimetics, 741 – 746. [79] Milstein, A. , S nchez, J. N. & Williamson, E. T. (2002). Rob ust global localization using clustered particle filtering. In: P roc. 1 8th national conference on Artif icial intelligence, 581 - 586 . [80] Yang, T. & Aitken, V. (2005 ). Unifor m Clustered P article Filtering for Robot Localization, 20 05 American Control Co nference, P ortland, OR, US, 4607 – 4612. To appear o n “ Expert Systems With Applicatio ns ” , 20 14 33 [81] Lindsten, F. , Ohlsson, H. & Ljung, L. (201 1). Clustering using sum- of -n orms regularizatio n; with application to p article filter output co mputation, Technical report from Automatic C ontrol at Linkö ping Uni versity. [82] Ceranka, S. & Niedzwiecki, M. (2003). Application of Particle Filtering i n Navi gation S ystem for Blind. In: T he 7th International S ymposium on Signal Pr ocessing and Its Applicatio ns, 2 , 495 – 498. [83] Clark, D. E. & Bell, J. (2007). Multi-tar get sta te estimation a nd track co ntinuity for the particle PHD filter. IEEE Transa ctions on Aerospace and Electronic S ystems . 43 (4) 1441 – 1452 . [84] Li, T. , Boli ć , M . & Djuri ć , P . (2014) . Resampling methods for particle filtering, accepted by IEEE Signal Processing Ma gazine , Preprint is available at https://sites.google.co m/site/tianchengli85/p ublications/current -w ork/prepr int [85] Djuric, P . M. , Lu, T . & B ugallo, M. F. (2007) . Multiple par ticle filtering. In: Pr oc. IEEE 32nd ICASSP, pp. II I-1181 – III -1184. [86] Bouten, L. Va n Ha ndel, R. & Ja mes, M. R. (20 06). A n introduction to quantu m filtering. arXiv:math/0601 741. [87] Vadakkepat, P. & J ing, L. ( 2006). Improved Particle Filter in Sensor Fusion for Tracking Randomly Moving Object . IEEE Transa ction on instrumentation and measurement, 55 (5), 1823-1832. [88] Vaswan, N. (2 008). Particle Filtering for Large-Dimensio nal State Space with Multi modal Observation Likelihood . I EEE Transactions on Signal Processing , 56 (10) 4583 – 4597. [89] Torma, P. & Szepesvá ri, C. (2 003). Combining Local Sear ch, Neural Net works and Particle Filters to Achieve Fast and Reliab le Contour T racking, IEEE, J anuary 2003 [90] Li, T. , Sun S. & Sattar, T. P. (2013). Adapting sample size in particle filters throu gh K LD - resampling. Elect ronics Letters, 46 (12), 740 - 742 . [91] Wang, Q. , Xie, L. , Liu, J. & Xiang, Z. (2 006). E nhancing Particle Swarm Opti mization Based Particle Filter Trac ker, ICIC 2006, 1216 – 1221. [92] Akhtar, S. , Ahmad, A. R., Abdel-Rahman, E. M. & Naq vi, T . (2011). A PSO Accelerated Imm une Particle Filter for Dynamic State Estimation. In: Proc. 2011 Can adian Confere nce on Computer and Robot Vision, 72 – 79 . [93] Schö n T. , Gusta fsson F. , & No rdlund, P. J. ( 2005). Marginalized P article Filters for Mixed Linear/Nonlinear State -Space Mo dels. IEE E Transactions on sign al processing , 53 (7 ), 2279- 2289 . [94] Li, T. , Han, Q., Siyau, M. F. & Sun, S. (20 14). Adjust the number of particles while guara ntee the ir diversity in particle filters. ICASSP 2014 , Florence, Italy, Ma y 4-9. [95] Simonetto, A. & Keviczky, T. (2009). Recent Dev elop ments in Dis tributed Particle Filtering: Towards Fast and Accurate Algorithms. Estimation and Control of Networked Systems , 1 . [96] Bolić , M. (2004) . Architectures for Efficie nt Implementatio n of Particle Filters [PhD thesis ], Stony Brook University, Ne w York, US A. [97] Douc, R. & Mouli nes, E. (200 8). Limit theorems for weighted samples with appli cations to sequential Monte Carlo . Ann . Stat., 36 (5 ), 2344 – 2376. [98] Whiteley, N. & J ohansen, A. M. (2011 ). Auxiliary p article filtering: recent develop ments. In: D. Barber, A . T. Cemgil, S. C hiapp a, Bayesian time serie s models, C ambridge U niversity Press, Cambridge. 52- 81 . To appear o n “ Expert Systems With Applicatio ns ” , 20 14 34 [99] Liu, J. , Wang, W. & Ma, F. (2 011). A regularized auxiliar y particle filtering appro ach for system state estimation and batter y life pred iction. Smart Mater. Struct . 20 (7) , 1-9. [100] Ahmed, M. O., B ibalan, P. T., Fre itas, N.de & Fauvel, S. (2012 ). Decentralized, Adaptive, Look - Ahead Particle Filterin g. Computing Resear ch Repositor y (CoRR), arXiv:1203. 2394v1 [stat.ML] [101] Li, T . & Sun, S. (2013) A Gap bet ween Simulation and P ractice fo r Recursive Filter s: On the State Transition Noise, sub mitted to Electronics L etters, P reprint published on arXiv .org: http://arxiv .org/abs/1308.1056. [102] Chris, S., Bengtsson, T ., Bickel, P. & Anderson, J. (2008) Obstacles to High -Dimensional P article Filtering. Mon. Wea. Rev., 1 36, 4629 – 46 40. [103] Bickel, P., L i, B. & B engtsso n, T. ( 2008). Sharp failure rates for th e bootstrap particle f ilter in h igh dimensions. In: Pushing the Limits of Contemporary Statistics: Contributions in Honor of Ja yanta K. Ghosh , Vo l. 3, B. Clarke and S. Ghosal Eds., Instit ute of Mathematical Statist ics, 318 – 329. [104] Rebeschini P. & Van Ha ndel R. ( 2013). Can local par ticle filters beat the c urse of dimensio nality? arXiv:1301.6585 v1. [105] Bengtsson, T. , Bickel, P. & Li, B. (2008). Curse- of - dimensio nality revisited: Collapse of the particle filter in ver y large scale syste ms. IMS Collectio ns , 2 , 316 – 334. [106] Leeuwen, P. J. v an (2 010). Nonli near data assimilation in geoscie nces: an extremely efficient particle f ilter. Quarterly Journal of the Royal Meteorolo gical Society, part B . 136 (653) , 1991- 1999 . [107] Winschel, V. & Krä tzi g, M. (2010). Solving, E stimating, and Selectin g No nlinear D ynamic Models without the Curse of Di mensionality. E conometrica , 78 (2), 803 – 821 . [108] Doucet, A. , Freitas, N. de , Mu rphy, K. & Russell, S. (2 000). Rao-Blackwellised particle filteri ng for dynamic Bayesian n etworks. In: Proc. 16th Conference on Un certainty in Artificial Intelligence, 2 (2), 176 – 183. [109] Chen, T ., Schö n, T . B. , Oh lsson, H. & Ljung, L . (2 011). Decentralized Particle Filter with Arb itrary State Decomposition, IEEE T. S ignal Proce ssing, 59 (2) , 465- 478. [110] Brandã o, B. C. , Wainer, J. & Goldenstein, S. K. (2 006). Subspace Hierarchical Particle Filter. In: Proc. 19 th Brazilian Symposium on Computer Grap hics and I mage P rocessing, 194 - 204 . [111] MacCormick, J. & Blake, A. (1999 ). A pr obabilistic exclu sion pr inciple for tracking multiple objects. In : Pro c. 7th International Conf. Computer Vi sion, 572 – 578 . [112] Van Der Merwe R., Doucet, A., De Freitasz N. & Wan E. (2 000). The Unscented Particle Filter . Technical Report CUED/F -INFENG/T R 380 . Cambridge University Engineerin g Department. [113] Jasra, A., Doucet, A., Stephens, D. A. & Holmes, C. C. (2008). Interacting sequential Monte Carlo samplers for trans-dimensional simulation. Computational Statistics & Data Analysis, 52 (4), 1765- 1791 . [114] Bray, M. , Koller -Meier, E. & Van Go ol L. (200 7). Smart P article Filtering for Hi gh -Dimensional Tracking. Computer Vis ion and Image Understa nding, 106(1), 1 16 - 129. [115] Gning, A., Ri stic, B., Miha ylova, L. & Abdallah, F. (201 3). An introd uction to b ox particle filtering. IEEE Signal Pro cess. Mag. , 30 (4), 1 – 7. [116] Arasaratnam, I. & Haykin, S. (2009). Cubature Kal man Fi lters. IEEE Transactions on automatic control , 54 (6), 1254- 1269.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment